4.2、ipex-llm(原bigdl-llm)进行语音识别
ipex-llm环境配置及模型下载
由于需要处理音频文件,还需要安装用于音频分析的 librosa 软件包。
pip install librosa
下载音频文件
!wget -O audio_en.mp3 https://datasets-server.huggingface.co/assets/common_voice/--/en/train/5/audio/audio.mp3
!wget -O audio_zh.mp3 https://datasets-server.huggingface.co/assets/common_voice/--/zh-CN/train/2/audio/audio.mp3
播放下载完成的音频:
import IPythonIPython.display.display(IPython.display.Audio("audio_en.mp3"))
IPython.display.display(IPython.display.Audio("audio_zh.mp3"))
1、加载预训练好的 Whisper 模型
加载一个经过预训练的 Whisper 模型,例如 whisper-medium 。OpenAI 发布了各种尺寸的预训练 Whisper 模型(包括 whisper-small、whisper-tiny 等),您可以选择最符合您要求的模型。
只需在 ipex-llm 中使用单行 transformers-style API,即可加载具有 INT4 优化功能的 whisper-medium(通过指定 load_in_4bit=True),如下所示。请注意,对于 Whisper,我们使用了 AutoModelForSpeechSeq2Seq 类。
from ipex_llm.transformers import AutoModelForSpeechSeq2Seqmodel = AutoModelForSpeechSeq2Seq.from_pretrained(pretrained_model_name_or_path="openai/whisper-medium",load_in_4bit=True,trust_remote_code=True)
2、加载 Whisper Processor
无论是音频预处理还是将模型输出从标记转换为文本的后处理,我们都需要 Whisper Processor。您只需使用官方的 transformers API 加载 WhisperProcessor 即可:
from transformers import WhisperProcessorprocessor = WhisperProcessor.from_pretrained(pretrained_model_name_or_path="openai/whisper-medium")
3、转录英文音频
使用带有 INT4 优化功能的 IPEX-LLM 优化 Whisper 模型并加载 Whisper Processor 后,就可以开始通过模型推理转录音频了。
让我们从英语音频文件 audio_en.mp3 开始。在将其输入 Whisper Processor 之前,我们需要从原始语音波形中提取序列数据:
import librosadata_en, sample_rate_en = librosa.load("audio_en.mp3", sr=16000)
对于 whisper-medium,其 WhisperFeatureExtractor(WhisperProcessor 的一部分)默认使用
16,000Hz 采样率从音频中提取特征。关键的是要用模型的 WhisperFeatureExtractor
以采样率加载音频文件,以便精确识别。
然后,我们就可以根据序列数据转录音频文件,使用的方法与使用官方的 transformers API 完全相同:
import torch
import time# 定义任务类型
forced_decoder_ids = processor.get_decoder_prompt_ids(language="english", task="transcribe")with torch.inference_mode():# 为 Whisper 模型提取输入特征input_features = processor(data_en, sampling_rate=sample_rate_en, return_tensors="pt").input_features# 为转录预测 token idst = time.time()predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)end = time.time()# 将 token id 解码为文本transcribe_str = processor.batch_decode(predicted_ids, skip_special_tokens=True)print(f'Inference time: {end-st} s')print('-'*20, 'English Transcription', '-'*20)print(transcribe_str)
forced_decoder_ids 为不同语言和任务(转录或翻译)定义上下文 token 。如果设置为 None,Whisper 将自动预测它们。
4、转录中文音频并翻译成英文
现在把目光转向中文音频 audio_zh.mp3。Whisper 可以转录多语言音频,并将其翻译成英文。这里唯一的区别是通过 forced_decoder_ids 来定义特定的上下文 token:
# 提取序列数据
data_zh, sample_rate_zh = librosa.load("audio_zh.mp3", sr=16000)# 定义中文转录任务
forced_decoder_ids = processor.get_decoder_prompt_ids(language="chinese", task="transcribe")with torch.inference_mode():input_features = processor(data_zh, sampling_rate=sample_rate_zh, return_tensors="pt").input_featuresst = time.time()predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)end = time.time()transcribe_str = processor.batch_decode(predicted_ids, skip_special_tokens=True)print(f'Inference time: {end-st} s')print('-'*20, 'Chinese Transcription', '-'*20)print(transcribe_str)# 定义中文转录以及翻译任务
forced_decoder_ids = processor.get_decoder_prompt_ids(language="chinese", task="translate")with torch.inference_mode():input_features = processor(data_zh, sampling_rate=sample_rate_zh, return_tensors="pt").input_featuresst = time.time()predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)end = time.time()translate_str = processor.batch_decode(predicted_ids, skip_special_tokens=True)print(f'Inference time: {end-st} s')print('-'*20, 'Chinese to English Translation', '-'*20)print(translate_str)
相关文章:
进行语音识别)
4.2、ipex-llm(原bigdl-llm)进行语音识别
ipex-llm环境配置及模型下载 由于需要处理音频文件,还需要安装用于音频分析的 librosa 软件包。 pip install librosa下载音频文件 !wget -O audio_en.mp3 https://datasets-server.huggingface.co/assets/common_voice/--/en/train/5/audio/audio.mp3 !wget -O a…...

上海亚商投顾:创业板指低开低走 黄金、家电股逆势大涨
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指4月12日震荡调整,创业板指尾盘跌超1%。黄金板块延续强势,莱绅通灵9连板࿰…...
AIGC革新浪潮:大语言模型如何优化企业运营
在当今快速发展的商业环境中,企业对于有效管理知识资产的需求日益增长。知识管理作为企业核心竞争力的关键组成部分,对于提高决策质量、增强创新能力和优化运营流程起着至关重要的作用。随着数字化转型的推进,企业对知识管理系统提出了新的要…...

Golang基础-12
Go语言基础 介绍 目录操作 创建 删除 重命名 遍历目录 修改权限 文件操作 创建 打开关闭 删除 重命名 修改权限 读文件 写文件 文件定位 拷贝 测试 单元测试 基准测试 示例 介绍 本文介绍Go语言中目录操作(创建目录、删除目录、重命名、遍历…...

python递归统计文件夹下pdf文件的数量
python递归统计文件夹下pdf文件的数量 import os from docx import Documentdef count_all_pages(root_dir):total_pages 0# 遍历文件夹for dirpath, dirnames, filenames in os.walk(root_dir):for filename in filenames:# if filename.endswith(.docx) or filename.endswit…...

Kafka 硬件和操作系统
目录 一. 前言 二. Kafka 硬件和操作系统(Hardware and OS) 2.1. 操作系统(OS) 2.2. 磁盘和文件系统(Disks and Filesystem) 一. 前言 Kafka 是 I/O 密集型而非计算密集型的框架,所以对 CP…...

Kolla-ansible部署OpenStack集群
0. OpenStack 部署 系统要求 单机部署最低配置: 2张网卡8G内存40G硬盘空间 主机系统: CentOS Stream 9Debian Bullseye (11)openEuler 22.03 LTSRocky Linux 9- Ubuntu Jammy (22.04) 官方不再支持CentOS 7作为主机系统,我这里使用的是R…...

SHARE 203S PRO:倾斜摄影相机在地灾救援中的应用
在地质灾害的紧急关头,救援队伍面临的首要任务是迅速而准确地掌握灾区的地理信息。这时,倾斜摄影相机成为了救援测绘的利器。SHARE 203S PRO,这款由深圳赛尔智控科技有限公司研发的五镜头倾斜摄影相机,以其卓越的性能和功能&#…...
(附R语言和python代码实现))
MATLAB算法实战应用案例精讲-【数模应用】中介效应分析(补充篇)(附R语言和python代码实现)
目录 前言 几个高频面试题目 中介效应分析与路径分析的区别 1.中介效应分析 2.路径分析 注意事项...
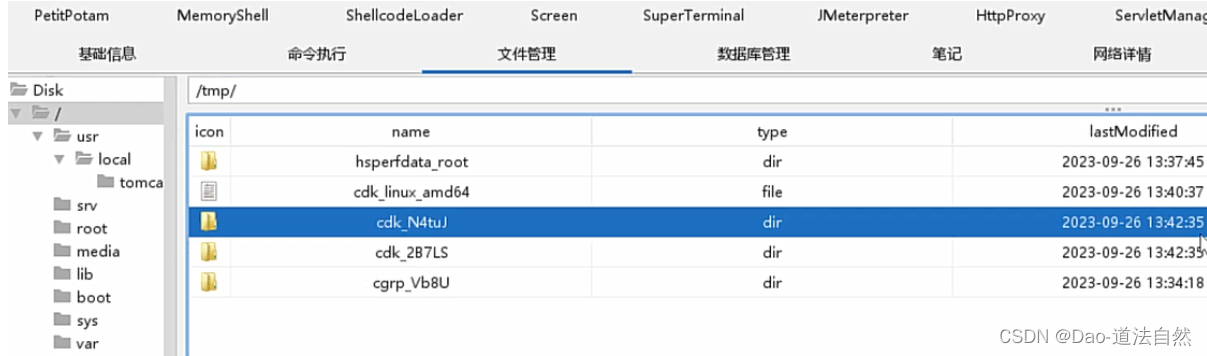
Day96:云上攻防-云原生篇Docker安全系统内核版本漏洞CDK自动利用容器逃逸
目录 云原生-Docker安全-容器逃逸&系统内核漏洞 云原生-Docker安全-容器逃逸&docker版本漏洞 CVE-2019-5736 runC容器逃逸(需要管理员配合触发) CVE-2020-15257 containerd逃逸(启动容器时有前提参数) 云原生-Docker安全-容器逃逸&CDK自动化 知识点࿱…...

python botos s3 aws
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html AWS是亚马逊的云服务,其提供了非常丰富的套件,以及支持多种语言的SDK/API。本文针对其S3云储存服务的Python SDK(boto3)的使用进行介绍。 …...
python画神经网络图
代码1(画神经网络连接图) from math import cos, sin, atan import matplotlib.pyplot as plt # 注意这里并没有用到这个networkx这个库,完全是根据matploblib这个库来画的。 class Neuron():def __init__(self, x, y,radius,nameNone):self.x xself.y …...

Bash 编程精粹:从新手到高手的全面指南之逻辑控制
在 Unix 和 Linux 系统中,Bash(Bourne-Again Shell)是一种广泛使用的 shell,提供了强大的脚本编程能力。本文将详细介绍 Bash 脚本中的逻辑控制结构,包括条件判断、分支选择、循环控制以及退出控制等内容。 条件判断&…...
Ansible 实战之自定义插件)
自动化运维(三十)Ansible 实战之自定义插件
Ansible 自定义插件允许你扩展其功能,以满足特定的自动化需求。Ansible 支持多种类型的插件开发,如动态库存、查找、回调、过滤器、变量等。这里我们将通过实例,介绍如何开发、部署和使用一个自定义插件。 开发自定义查找插件 查找插件用于在 Ansible 任务中动态获取数据。…...

实习僧网站的实习岗位信息分析
目录 背景描述数据说明数据集来源问题描述分析目标以及导入模块1. 数据导入2. 数据基本信息和基本处理3. 数据处理3.1 新建data_clean数据框3.2 数值型数据处理3.2.1 “auth_capital”(注册资本)3.2.2 “day_per_week”(每周工作天数…...
C语言中局部变量和全局变量是否可以重名?为什么?
可以重名 在C语言中, 局部变量指的是定义在函数内的变量, 全局变量指的是定义在函数外的变量 他们在程序中的使用方法是不同的, 当重名时, 局部变量在其所在的作用域内具有更高的优先级, 会覆盖或者说隐藏同名的全局变量 具体来说: 局部变量的生命周期只在函数内部,如果出了…...
小程序中配置scss
找到:project.config.json 文件 setting 模块下添加: "useCompilerPlugins": ["sass","其他的样式类型"] 配置完成后,重启开发工具,并新建文件 结果:...

ZYNQ-Vitis(SDK)裸机开发之(四)PS端MIO和EMIO的使用
目录 一、ZYNQ中MIO和EMIO简介 二、Vivado中搭建block design 1.配置PS端MIO: 2.配置PS端EMIO: 三、Vitis中新建工程进行GPIO控制 1. GPIO操作头文件gpio_hdl.h: 2.GPIO操作源文件gpio_hdl.c: 3.main函数进行调用 例程开发…...
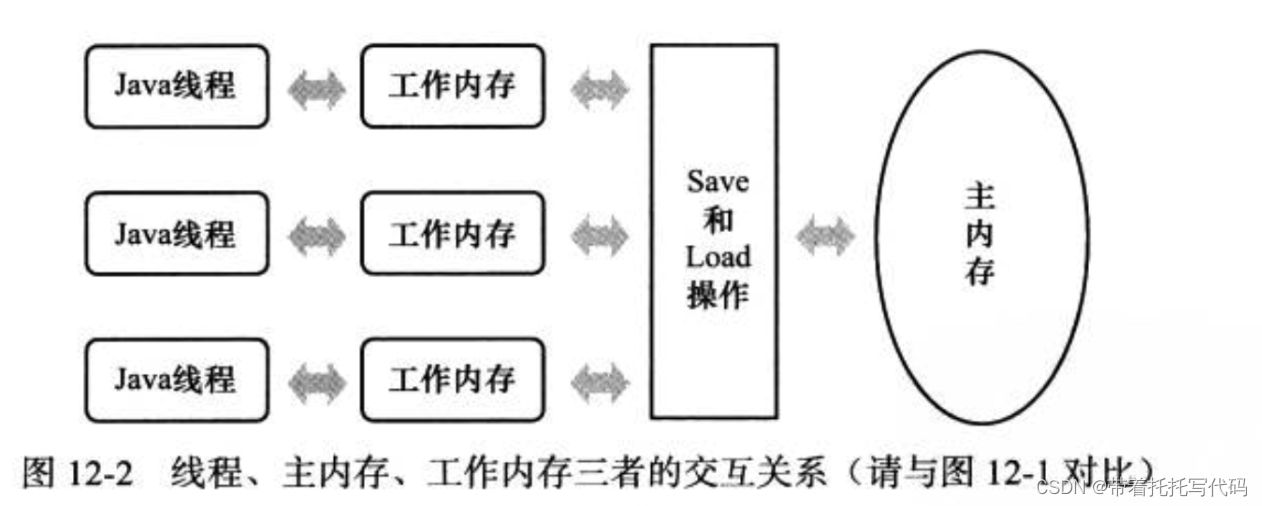
聊聊jvm中内存模型的坑
jvm线程的内存模型 看图,简单来说线程中操作的变量是副本。在并发情况下,如果数据发生变更,副本的数据就变为脏数据。这个时候就会有并发问题。 参考:https://www.cnblogs.com/yeyang/p/12580682.html 怎么解决并发问题 解决的…...
DevOps已死?2024年的DevOps将如何发展
随着我们进入2024年,DevOps也发生了变化。新兴的技术、变化的需求和发展的方法正在重新定义有效实施DevOps实践。 IDC预测显示,未来五年,支持DevOps实践的产品市场继续保持健康且快速增长,2022年-2027年的复合年增长率࿰…...

FanControl终极指南:从风扇噪音到静音大师的蜕变之旅
FanControl终极指南:从风扇噪音到静音大师的蜕变之旅 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

VSCode AI编程助手FlexPilot:从智能代码生成到实战配置全解析
1. 项目概述:一个AI驱动的VSCode智能编程伴侣如果你和我一样,每天大部分时间都泡在Visual Studio Code里,那你肯定也经历过这样的时刻:面对一个复杂的重构任务,或者一个陌生的API,需要频繁地在浏览器、文档…...
)
告别Unity/UE4,用Love2D和VSCode开启你的独立游戏开发之旅(附详细配置流程)
轻量化游戏开发革命:用Love2D与VSCode打造高效创作环境 当Unity和Unreal Engine在游戏行业占据主导地位时,越来越多的独立开发者开始寻找更轻便、更灵活的替代方案。大型商业引擎虽然功能强大,但对于小型团队或个人开发者而言,它…...

深度解构:如何基于PX4-Autopilot构建高性能无人机控制系统
深度解构:如何基于PX4-Autopilot构建高性能无人机控制系统 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot 在无人机系统开发中,实时性、可靠性和扩展性一直是开发团队面临的…...
)
别再到处找了!2024年最全的开源工业以太网协议栈清单(EtherCAT/Profinet/Modbus)
2024年开源工业以太网协议栈全景指南:从选型到实战 工业自动化领域正经历着数字化转型的浪潮,而开源协议栈的成熟让中小企业和开发者能够以更低成本实现专业级工业通信。作为一名在工控领域摸爬滚打多年的工程师,我深刻理解选择合适协议栈时…...

抖音下载器完整指南:免费批量下载无水印抖音视频、图集和音乐终极教程
抖音下载器完整指南:免费批量下载无水印抖音视频、图集和音乐终极教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser…...
)
前端联调总报跨域错误?5分钟搞定Flask后端CORS配置(附Chrome/Postman排查技巧)
Flask后端CORS配置实战:从报错到联调畅通的完整指南 当你在本地开发环境中看到浏览器控制台抛出"CORS policy"红色报错时,那种联调被硬生生阻断的烦躁感,每个全栈开发者都深有体会。本文将从实际开发场景出发,带你快速解…...

Bambu Lab X1:AI与激光雷达重塑3D打印技术
1. Bambu Lab X1:当3D打印遇上AI与激光雷达的革命作为一名折腾过十几台3D打印机的老玩家,第一次看到Bambu Lab X1的规格表时,我的反应和大多数从业者一样——这要么是场骗局,要么就是真正的行业颠覆者。传统3D打印机需要手动调平、…...

多处理器JTAG实时分析技术解析与优化
1. 多处理器实时分析的技术背景与挑战在嵌入式系统开发领域,实时分析(Real-Time Analysis, RTA)是确保应用程序满足时序和逻辑正确性的关键技术。传统调试方法如断点调试会中断程序执行,无法满足实时性要求;而逻辑分析…...

开源AI智能体框架CL4R1T4S:构建可靠多智能体系统的架构与实践
1. 项目概述:一个开源AI智能体框架的诞生最近在GitHub上闲逛,又被我挖到了一个宝藏项目:elder-plinius/CL4R1T4S。这名字乍一看有点神秘,像是某种代号,但点进去一看,好家伙,这又是一个瞄准了当前…...