大数据框架之Hive:第3章 DDL(Data Definition Language)数据定义
第3章 DDL(Data Definition Language)数据定义
3.1 数据库(database)
3.1.1 创建数据库
1)语法
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
2)案例
(1)创建一个数据库,不指定路径
hive (default)> create database db_hive1;
注:若不指定路径,其默认路径为 ${hive.metastore.warehouse.dir}/database_name.db
(2)创建一个数据库,指定路径
hive (default)> create database db_hive2 location '/db_hive2';
(2)创建一个数据库,带有dbproperties
hive (default)> create database db_hive3 with dbproperties('create_date'='2022-11-18');
3.1.2 查询数据库
1)展示所有数据库
(1)语法
SHOW DATABASES [LIKE 'identifier_with_wildcards'];
注:like通配表达式说明:*表示任意个任意字符,|表示或的关系。
(2)案例
hive> show databases like 'db_hive*';
OK
db_hive_1
db_hive_2
2)查看数据库信息
(1)语法
DESCRIBE DATABASE [EXTENDED] db_name;
(2)案例
①查看基本信息
hive> desc database db_hive3;
OK
db_hive hdfs://101:8020/user/hive/warehouse/db_hive.db vagrant USER
②查看更多信息
hive> desc database extended db_hive3;
OK
db_name comment location owner_name owner_type parameters
db_hive3 hdfs://hadoop102:8020/user/hive/warehouse/db_hive3.db vagrant USER {create_date=2022-11-18}
3.1.3 修改数据库
用户可以使用alter database命令修改数据库某些信息,其中能够修改的信息包括dbproperties、location、owner user。需要注意的是:修改数据库location,不会改变当前已有表的路径信息,而只是改变后续创建的新表的默认的父目录。
1)语法
--修改dbproperties
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...);--修改location
ALTER DATABASE database_name SET LOCATION hdfs_path;--修改owner user
ALTER DATABASE database_name SET OWNER USER user_name;
2)案例
(1)修改dbproperties
hive> ALTER DATABASE db_hive3 SET DBPROPERTIES ('create_date'='2022-11-20');
3.1.4 删除数据库
1)语法
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];
注:RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。
CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除。
2)案例
(1)删除空数据库
hive> drop database db_hive2;
(2)删除非空数据库
hive> drop database db_hive3 cascade;
3.1.5 切换当前数据库
1)语法
USE database_name;
3.2 表(table)
3.2.1 创建表
3.2.1.1 语法
1)普通建表
(1)完整语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
(2)关键字说明:
①TEMPORARY
临时表,该表只在当前会话可见,会话结束,表会被删除。
②EXTERNAL(重点)
外部表,与之相对应的是内部表(管理表)。管理表意味着Hive会完全接管该表,包括元数据和HDFS中的数据。而外部表则意味着Hive只接管元数据,而不完全接管HDFS中的数据。
③data_type(重点)
Hive中的字段类型可分为基本数据类型和复杂数据类型。
基本数据类型如下:
| Hive | 说明 | 定义 |
|---|---|---|
| tinyint | 1byte有符号整数 | |
| smallint | 2byte有符号整数 | |
| int | 4byte有符号整数 | |
| bigint | 8byte有符号整数 | |
| boolean | 布尔类型,true或者false | |
| float | 单精度浮点数 | |
| double | 双精度浮点数 | |
| decimal | 十进制精准数字类型 | decimal(16,2) |
| varchar | 字符序列,需指定最大长度,最大长度的范围是[1,65535] | varchar(32) |
| string | 字符串,无需指定最大长度 | |
| timestamp | 时间类型 | |
| binary | 二进制数据 |
复杂数据类型如下;
| 类型 | 说明 | 定义 | 取值 |
|---|---|---|---|
| array | 数组是一组相同类型的值的集合 | array | arr[0] |
| map | map是一组相同类型的键-值对集合 | map<string, int> | map[‘key’] |
| struct | 结构体由多个属性组成,每个属性都有自己的属性名和数据类型 | struct<id:int, name:string> | struct.id |
注:类型转换
Hive的基本数据类型可以做类型转换,转换的方式包括隐式转换以及显示转换。
方式一:隐式转换
具体规则如下:
a. 任何整数类型都可以隐式地转换为一个范围更广的类型,如tinyint可以转换成int,int可以转换成bigint。
b. 所有整数类型、float和string类型都可以隐式地转换成double。
c. tinyint、smallint、int都可以转换为float。
d. boolean类型不可以转换为任何其它的类型。
详情可参考Hive官方说明:Allowed Implicit Conversions
方式二:显示转换
可以借助cast函数完成显示的类型转换
a.语法
cast(expr as <type>)
b.案例
hive (default)> select '1' + 2, cast('1' as int) + 2;_c0 _c1
3.0 3
④PARTITIONED BY(重点)
创建分区表
⑤CLUSTERED BY … SORTED BY…INTO … BUCKETS(重点)
创建分桶表
⑥ROW FORMAT(重点)
指定SERDE,SERDE是Serializer and Deserializer的简写。Hive使用SERDE序列化和反序列化每行数据。详情可参考 Hive-Serde。语法说明如下:
**语法一:**DELIMITED关键字表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的SERDE对每行数据进行序列化和反序列化。
ROW FORAMT DELIMITED
[FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char]
注:
- fields terminated by:列分隔符
- collection items terminated by :map、struct和array中每个元素之间的分隔符
- map keys terminated by :map中的key与value的分隔符
- lines terminated by :行分隔符
**语法二:**SERDE关键字可用于指定其他内置的SERDE或者用户自定义的SERDE。例如JSON SERDE,可用于处理JSON字符串。
ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value,property_name=property_value, ...)]
⑦STORED AS(重点)
指定文件格式,常用的文件格式有,textfile(默认值),sequence file,orc file、parquet file等等。
⑧LOCATION
指定表所对应的HDFS路径,若不指定路径,其默认值为
${hive.metastore.warehouse.dir}/db_name.db/table_name
⑨TBLPROPERTIES
用于配置表的一些KV键值对参数
2)Create Table As Select(CTAS)建表
该语法允许用户利用select查询语句返回的结果,直接建表,表的结构和查询语句的结构保持一致,且保证包含select查询语句放回的内容。
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
3)Create Table Like语法
该语法允许用户复刻一张已经存在的表结构,与上述的CTAS语法不同,该语法创建出来的表中不包含数据。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[LIKE exist_table_name]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
3.2.1.2 案例
1)内部表与外部表
(1)内部表
Hive中默认创建的表都是的内部表,有时也被称为管理表。对于内部表,Hive会完全管理表的元数据和数据文件。
创建内部表如下:
create table if not exists student(id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';
准备其需要的文件如下,注意字段之间的分隔符。
[atguigu@hadoop102 datas]$ vim /opt/module/datas/student.txt1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
1011 student11
1012 student12
1013 student13
1014 student14
1015 student15
1016 student16
上传文件到Hive表指定的路径
[atguigu@hadoop102 datas]$ hadoop fs -put student.txt /user/hive/warehouse/student
删除表,观察数据HDFS中的数据文件是否还在
hive (default)> drop table student;
(2)外部表
外部表通常可用于处理其他工具上传的数据文件,对于外部表,Hive只负责管理元数据,不负责管理HDFS中的数据文件。
创建外部表如下:
create external table if not exists student(id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';
上传文件到Hive表指定的路径
[atguigu@hadoop102 datas]$ hadoop fs -put student.txt /user/hive/warehouse/student
删除表,观察数据HDFS中的数据文件是否还在
hive (default)> drop table student;
2)SERDE和复杂数据类型
本案例重点练习SERDE和复杂数据类型的使用。
若现有如下格式的JSON文件需要由Hive进行分析处理,请考虑如何设计表?
注:以下内容为格式化之后的结果,文件中每行数据为一个完整的JSON字符串。
{"name": "dasongsong","friends": ["bingbing","lili"],"students": {"xiaohaihai": 18,"xiaoyangyang": 16},"address": {"street": "hui long guan","city": "beijing","postal_code": 10010}
}
我们可以考虑使用专门负责JSON文件的JSON Serde,设计表字段时,表的字段与JSON字符串中的一级字段保持一致,对于具有嵌套结构的JSON字符串,考虑使用合适复杂数据类型保存其内容。最终设计出的表结构如下:
hive>
create table teacher
(name string,friends array<string>,students map<string,int>,address struct<city:string,street:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/user/hive/warehouse/teacher';
创建该表,并准备以下文件。注意,需要确保文件中每行数据都是一个完整的JSON字符串,JSON SERDE才能正确的处理。
[atguigu@hadoop102 datas]$ vim /opt/module/datas/teacher.txt{"name":"dasongsong","friends":["bingbing","lili"],"students":{"xiaohaihai":18,"xiaoyangyang":16},"address":{"street":"hui long guan","city":"beijing","postal_code":10010}}
上传文件到Hive表指定的路径
[atguigu@hadoop102 datas]$ hadoop fs -put teacher.txt /user/hive/warehouse/teacher
尝试从复杂数据类型的字段中取值
3)create table as select和create table like
(1)create table as select
hive> create table teacher1 as select * from teacher;
(2)create table like
hive> create table teacher2 like teacher;
3.2.2 查看表
1)展示所有表
(1)语法
SHOW TABLES [IN database_name] LIKE ['identifier_with_wildcards'];
注:like通配表达式说明:*表示任意个任意字符,|表示或的关系。
(2)案例
hive> show tables like 'stu*';
2)查看表信息
(1)语法
DESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name
注:EXTENDED:展示详细信息
FORMATTED:对详细信息进行格式化的展示
(2)案例
①查看基本信息
hive> desc stu;
②查看更多信息
hive> desc formatted stu;
3.2.3 修改表
1)重命名表
(1)语法
ALTER TABLE table_name RENAME TO new_table_name
(2)案例
hive (default)> alter table stu rename to stu1;
2)修改列信息
(1)语法
①增加列
该语句允许用户增加新的列,新增列的位置位于末尾。
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)
②更新列
该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name
column_type [COMMENT col_comment] [FIRST|AFTER column_name]
③替换列
该语句允许用户用新的列集替换表中原有的全部列。
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type
[COMMENT col_comment], ...)
2)案例
(1)查询表结构
hive (default)> desc stu;
(2)添加列
hive (default)> alter table stu add columns(age int);
(3)查询表结构
hive (default)> desc stu;
(4)更新列
hive (default)> alter table stu change column age ages double;
(5)替换列
hive (default)> alter table stu replace columns(id int, name string);
3.2.4 删除表
1)语法
DROP TABLE [IF EXISTS] table_name;
2)案例
hive (default)> drop table stu;
3.2.5 清空表
1)语法
TRUNCATE [TABLE] table_name
注意:truncate只能清空管理表,不能删除外部表中数据。
2)案例
hive (default)> truncate table student;
相关文章:
数据定义)
大数据框架之Hive:第3章 DDL(Data Definition Language)数据定义
第3章 DDL(Data Definition Language)数据定义 3.1 数据库(database) 3.1.1 创建数据库 1)语法 CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPER…...

概率论小课堂:统计学是大数据方法的基础
文章目录 引言I 统计学1.1 统计学的内容1.2 统计学的目的II 用好数据的五个步骤2.1 设立研究目标2.2 设计实验,选取数据。2.3 根据实验方案进行统计和实验,分析方差。2.4 通过分析进一步了解数据,提出新假说。2.5 使用研究结果III 数据没用好的原因3.1 霍桑效应3.2 数据的稀…...

监控集群概念讲解
监控概述 1、监控的重要性 监控是运维日常的重要工作之一; 监控是有多重要? 监控可以帮助运维监控服务器的状态;要及时解决; 如果淘宝、腾讯宕机了1个小时? 损失是无法估量的; 服务器是否故障、宕不…...
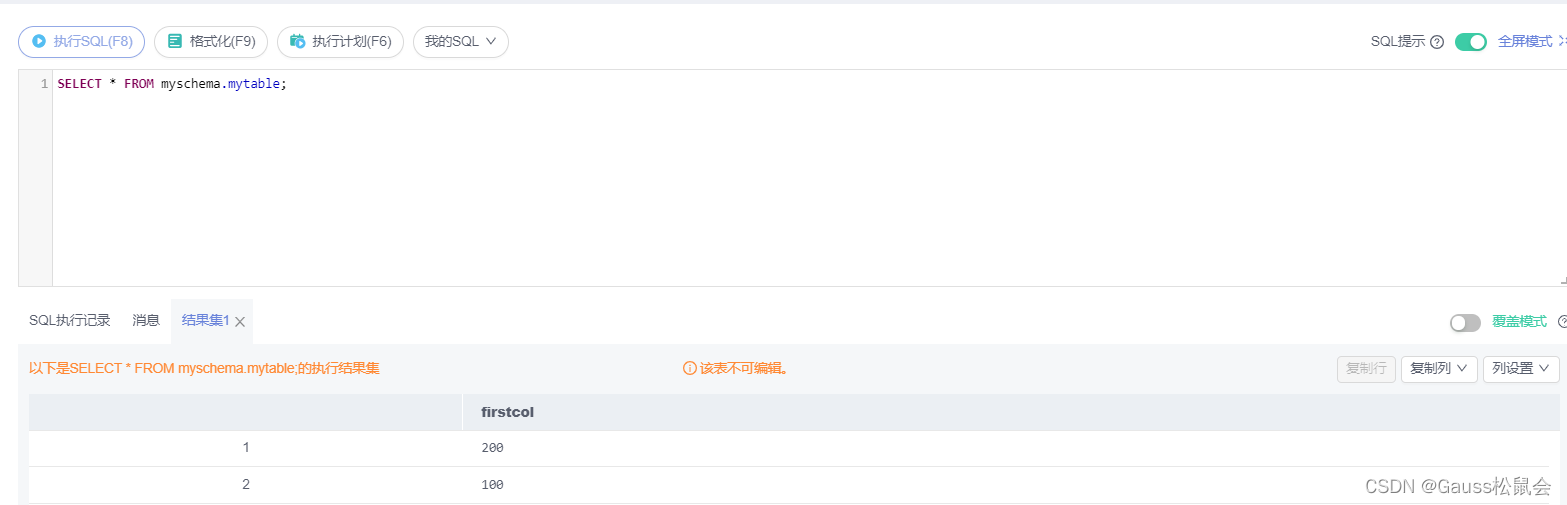
如何通过DAS连接GaussDB
文章目录1 实验介绍2 实验目的3 配置DAS服务4 SQL使用入门1 实验介绍 本实验主要描述如何通过华为云数据管理服务 (Data Admin Service,简称DAS) 来连接华为云GaussDB数据库实例,DAS是一款专业的简化数据库管理工具,提供优质的可视化操作界面…...
支持在局域网使用的项目管理系统有哪些?5款软件对比
一、选择私有部署的原因以及该方案的优点有很多可能的原因导致人们更倾向于使用私有部署的企业管理软件,其中一些原因可能包括:1.数据安全性要求:一些企业管理软件包含敏感的商业数据和隐私信息,为了保护这些信息不被未经授权的第…...

Linux CentOS7 MySQL 5.7安装
准备工作 //创建目录 mkdir /opt/mysql //跳转目录 cd /opt/mysql下载MySQL 请耐心等待,也可以在Windows下载以后上传到 /opt/mysql目录 wget http://dev.mysql.com/get/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar解压 tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-b…...
控制器)
Kubernetes学习(四)控制器
ReplicaSet ReplicaSet的目的是维护一组在任何时候都处于运行状态的Pod副本的稳定集合。因此,它通常用来保证给定数量的、完全相同的Pod的可用性。 ReplicaSet的工作原理 ReplicaSet是通过一组字段来定义的,包括一个用来识别可获得的pod的集合的选择符…...

vue组件间通信的几个方法
一,props属性传递数据 适用场景:父组件传递数据给子组件 子组件设置props属性,定义接收父组件传递过来的参数 父组件在使用子组件标签中通过字面量来传递值 Children.vue props:{ // 字符串形式 name:String // 接收的类型参数 // 对象…...
)
商品价格区间设置与排序--课后程序(Python程序开发案例教程-黑马程序员编著-第4章-课后作业)
实例2:商品价格区间设置与排序 在网上购物时,面对琳琅满目的商品,我们应该如何快速选择适合自己的商品呢?为了能够让用户快速地定位到适合自己的商品,每个电商购物平台都提供价格排序与设置价格区间功能。假设现在某平…...

mybatis中sqlSession的使用
文章目录sqlsession的使用依赖jdbc.propertiesmysql-config.xml配置逆向工程创建sqlSessionsqlsession的使用 在最开始我们使用jdbcUtil的方式进行硬编码,sql字符串写的很难受,使用mybatis可以解决这个问题,它提供了数据库与实体类的关系映射…...
 API简介)
TPOT(Tree-based Pipeline Optimization Tool) API简介
文章目录TPOT简介TPOT APIClassification接口形式:Parameters:Attributes:Functions:Regression接口形式Parameters:(只列与分类任务有差异的参数)TPOT简介 TPOT是一个Python自动机器学习(AML)…...

Java 19和IntelliJ IDEA,如何和谐共生?
Java仍然是目前比较流行的编程语言,它更短的发布节奏让开发者每六个月左右就可以试用新的语言或平台功能,IntelliJ IDEA帮助我们更流畅地发现和使用这些新功能。IntelliJ IDEA v2022.3正式版下载(Q技术交流:786598704)在本文中&am…...

js循环判断的方法
js循环判断的方法if语句if else语句if else if else if......三元表达式switchswitch语句和if语句的区别for循环while循环do while循环for inforEachfor of性能问题if语句 条件满足就执行,不满足就不执行 if(条件){语句}if else语句 条件满足,执行语句…...
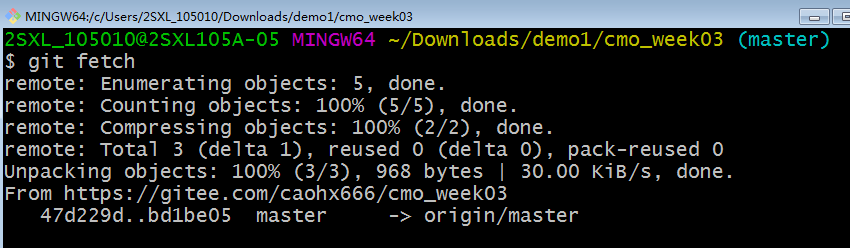
git快速入门(1)
1 git的下载与安装1)下载git安装包下载路径:https://git-scm.com/我的操作系统是window,64位的,我下载的Git-2.33.0-64-bit.exe,从官网下载或者从网址下载链接:链接地址:https://pan.baidu.com/…...

韩国绿芯1~16通道触摸芯片型号推荐
随着技术的发展,触摸感应技术正日益受到更多关注和应用,目前实现触摸感应的方式主要有两种,一种是电阻式,另一种是电容式。电容式触摸具有感应灵敏、功耗低、寿命长等特点,因此逐步取代电阻式触摸,成为当前…...

Go语言设计与实现 -- http服务器编程
Go http服务器编程 初始 http 是典型的 C/S 架构,客户端向服务端发送请求(request),服务端做出应答(response)。 golang 的标准库 net/http 提供了 http 编程有关的接口,封装了内部TCP连接和…...

MySQL-视图
视图是什么? 一张虚表,和真实的表一样。视图包含一系列带有名称的行和列数据。视图是从一个或多个表中导出来的,我们可以通过insert,update,delete来操作视图。当通过视图看到的数据被修改时,相应的原表的数…...

都工作3年了,怎么能不懂双亲委派呢?(带你手把手断点源码)
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...

Hive 运行环境搭建
文章目录Hive 运行环境搭建一、Hive 安装部署1、安装hive2、MySQL 安装3、Hive 元数据配置到 Mysql1) 拷贝驱动2) 配置Metastore 到 MySQL3) 再次启动Hive4) 使用元数据服务的方式访问Hive二、使用Dbaver连接HiveHive 运行环境搭建 HIve 下载地址:http://archive.a…...
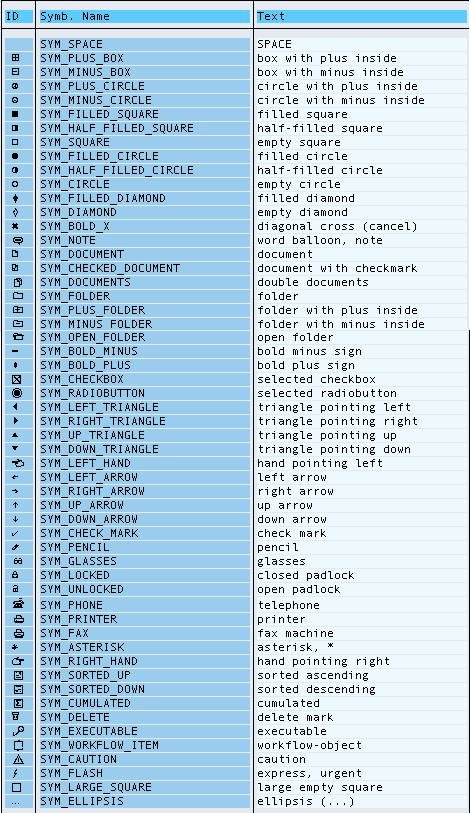
SAP ABAP 深度解析Smartform打印特殊符号等功能
ABAP 开发人员可以在 Smartform 输出上显示 SAP 图标或 SAP 符号。例如,需要在 SAP Smart Forms 文档上显示复选框形状的输出。SAP Smartform 文档上可以轻松显示空复选框、标记复选框以及 SAP 图标等特殊符号。 在 SAP Smartform 文档中添加一个新的文本节点。 1. 单击“更…...

终极指南:使用compressorjs实现专业级前端图片压缩与编辑功能
终极指南:使用compressorjs实现专业级前端图片压缩与编辑功能 【免费下载链接】compressorjs compressorjs: 是一个JavaScript图像压缩库,使用浏览器原生的canvas.toBlob API进行图像压缩。 项目地址: https://gitcode.com/gh_mirrors/co/compressorjs…...

永磁同步电机双矢量模型预测电流MPCC控制仿真:传统与现代控制策略的对比分析
永磁同步电机双矢量模型预测电流MPCC控制仿真【参考文献】 (1)参考文献:《永磁同步电机鲁棒双矢量模型预测电流控制_郭鑫》 (2)描述:传统单矢量预测电流控制在单个控制周期内只能输出单个电压矢量ÿ…...

AI智能体实战:从入门到企业级自动化应用
摘要 本文基于我过去一年多在企业级AI智能体落地的实战经验,从核心架构设计、从零到一的落地实战、生产环境踩坑避坑,到企业级进阶优化,完整拆解AI智能体从玩具Demo到生产级自动化应用的全流程。本文不搞空泛的理论堆砌,所有内容均…...

告别手动调参!模糊PID如何让直流电机在负载突变时稳如泰山?
模糊PID控制:让直流电机在负载突变时稳如泰山的实战指南 引言:工业自动化中的电机控制痛点 在自动化产线上,直流电机突然遭遇负载变化时,你是否也经历过这样的场景?——机械臂正在精准抓取工件,突然因为物料…...

高效PDF处理:用PDF Arranger实现极简文档管理
高效PDF处理:用PDF Arranger实现极简文档管理 【免费下载链接】pdfarranger Small python-gtk application, which helps the user to merge or split PDF documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical int…...

若依前后端分离系统生产环境部署:从零到上线的保姆级教程
若依前后端分离系统生产环境部署实战指南 引言:为什么选择若依框架? 对于刚接触企业级开发的新手来说,若依(RuoYi)框架无疑是一个绝佳的起点。这个基于Spring Boot和Vue.js的前后端分离架构,不仅提供了完善的权限管理、代码生成等…...
TranslucentTB:轻量任务栏视觉增强工具,让Windows桌面颜值提升300%
TranslucentTB:轻量任务栏视觉增强工具,让Windows桌面颜值提升300% 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB …...

ComfyUI图片生成视频大模型技术选型与实战:从原理到生产环境部署
最近在搞一个AI视频生成的项目,用到了ComfyUI这个可视化工作流工具。说实话,刚开始选模型的时候真是眼花缭乱,Stable Diffusion Video、ModelScope、RunwayML……每个都说自己好,但实际用起来坑真不少。今天就把我趟过的路和总结的…...

Llama-3.2V-11B-cot惊艳效果:多对象遮挡场景下的因果关系链推演
Llama-3.2V-11B-cot惊艳效果:多对象遮挡场景下的因果关系链推演 1. 视觉推理新标杆 在计算机视觉领域,多对象遮挡场景下的因果关系推演一直是个技术难题。传统方法往往只能识别可见部分,而无法理解遮挡背后的逻辑关系。Llama-3.2V-11B-cot的…...

国产64G超大显存GPU,海光K100
长城永不倒,国货当自强! 海光K100 AI是7nm国产GPU加速卡,主打大显存高AI算力信创国产适配高性价比: • 64GB大显存,适合大模型训练/推理 • INT8 392 TOPS、FP16 196 TFLOPS,算力强劲 • PCIe 5.0、350W&am…...