Redis中的BigKey
Redis中的BigKey
什么是BigKey?
大 key 并不是指 key 的值很大,而是 key 对应的 value 很大。
一般而言,下面这两种情况被称为大 key:
- String 类型的值大于 10 KB;
- Hash、List、Set、ZSet 类型的元素的个数超过 5000个;
BigKey的危害
- 网络阻塞
- 对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
- 数据倾斜
- BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis阻塞
- 对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞
- CPU压力
- 对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用
找到Bigkey
1、redis-cli --bigkeys 查找大key
可以通过 redis-cli --bigkeys 命令查找大 key:
redis-cli -h 127.0.0.1 -p6379 -a "password" -- bigkeys
使用的时候注意事项:
- 最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点;
- 如果没有从节点,那么可以选择在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。
该方式的不足之处:
- 这个方法只能返回每种类型中最大的那个 bigkey,无法得到大小排在前 N 位的 bigkey;
- 对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大;
2、使用 SCAN 命令查找大 key
使用 SCAN 命令对数据库扫描,然后用 TYPE 命令获取返回的每一个 key 的类型。
对于 String 类型,可以直接使用 STRLEN 命令获取字符串的长度,也就是占用的内存空间字节数。
对于集合类型来说,有两种方法可以获得它占用的内存大小:
- 如果能够预先从业务层知道集合元素的平均大小,那么,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。List 类型:
LLEN命令;Hash 类型:HLEN命令;Set 类型:SCARD命令;Sorted Set 类型:ZCARD命令; - 如果不能提前知道写入集合的元素大小,可以使用
MEMORY USAGE命令(需要 Redis 4.0 及以上版本),查询一个键值对占用的内存空间。
3、使用 RdbTools 工具查找大 key
使用 RdbTools 第三方开源工具,可以用来解析 Redis 快照(RDB)文件,找到其中的大 key。
比如,下面这条命令,将大于 10 kb 的 key 输出到一个表格文件。
rdb dump.rdb -c memory --bytes 10240 -f redis.csv
删除BigKey
1、分批次删除
如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey
2、异步删除
从 Redis 4.0 版本开始,可以采用异步删除法,用 unlink 命令代替 del 来删除。
这样 Redis 会将这个 key 放入到一个异步线程中进行删除,这样不会阻塞主线程。
优化BigKey
假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
| key | field | value |
| someKey | id:0 | value0 |
| ..... | ..... | |
| id:999999 | value999999 |
存在的问题:
- hash的entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多
- 可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会导致BigKey问题
拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash
BigKey对持久化的影响
对AOF日志的影响
Redis 提供了 3 种 AOF 日志写回硬盘的策略,分别是:
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
总结一下:
- Always 策略就是每次写入 AOF 文件数据后,就执行 fsync() 函数;
- Everysec 策略就会创建一个异步任务来执行 fsync() 函数;
- No 策略就是永不执行 fsync() 函数;
当 AOF 写回策略配置了 Always 策略,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。
当使用 Everysec 策略的时候,由于是异步执行 fsync() 函数,所以大 Key 持久化的过程(数据同步磁盘)不会影响主线程。
当使用 No 策略的时候,由于永不执行 fsync() 函数,所以大 Key 持久化的过程不会影响主线程。
对AOF重写和RDB的影响
AOF 重写机制和 RDB 快照(bgsave 命令)的过程,都会分别通过 fork() 函数创建一个子进程来处理任务。会有两个阶段会导致阻塞父进程(主线程):
- 创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 创建完子进程后,如果父进程修改了共享数据中的大 Key,就会发生写时复制,这期间会拷贝物理内存,由于大 Key 占用的物理内存会很大,那么在复制物理内存这一过程,就会比较耗时,所以有可能会阻塞父进程。
相关文章:
Redis中的BigKey
Redis中的BigKey 文章目录 Redis中的BigKey什么是BigKey?BigKey的危害找到Bigkey删除BigKey优化BigKeyBigKey对持久化的影响对AOF日志的影响对AOF重写和RDB的影响 什么是BigKey? 大 key 并不是指 key 的值很大,而是 key 对应的 value 很大。…...

MySQL中的存储过程详解(上篇)
使用语言 MySQL 使用工具 Navicat Premium 16 代码能力快速提升小方法,看完代码自己敲一遍,十分有用 拖动表名到查询文件中就可以直接把名字拉进来中括号,就代表可写可不写 目录 1.认识存储过程 1.1 存储过程的作用 1.2 存储过程简介…...

面试官:说一说CyclicBarrier的妙用!我:这个没用过...
写在开头 面试官:同学,AQS的原理知道吗? 我:学过一点,抽象队列同步器,Java中很多同步工具都是基于它的… 面试官:好的,那其中CyclicBarrier学过吗?讲一讲它的妙用吧 我&…...
MySQL高可用搭建方案MHA
MHA架构介绍 MHA是Master High Availability的缩写,它是目前MySQL高可用方面的一个相对成熟的解决方案,其核心是使用perl语言编写的一组脚本,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中&am…...

【vue】用vite创建vue项目
前置要求 要有Node.js 1. 用vite创建vue项目 在cmd中,进入一个文件夹 在文件资源管理器上面的文件目录中,输入cmd,回车在cmd中通过cd命令进入对应文件夹 创建项目 npm create vitelatest # 创建项目创建项目过程中的一些选项 Ok to pro…...
内网渗透-内网环境下的横向移动总结
内网环境下的横向移动总结 文章目录 内网环境下的横向移动总结前言横向移动威胁 威胁密码安全 威胁主机安全 威胁信息安全横向移动威胁的特点 利用psexec 利用psexec.exe工具msf中的psexec 利用windows服务 sc命令 1.与靶机建立ipc连接2.拷贝exe到主机系统上3.在靶机上创建一个…...

Linux命令学习—linux 的常用命令
1.1、改变目录 cd 目录的表达方法: /根目录 .当前目录 .. 上一级目录 ~家目录 #cd / 进入到系统根目录 #cd . 进入当前目录 #cd .. 进入当前目录的父目录,返回上层目录 #cd /tmp 进入指定目录/tmp #cd ~ 进入当前用户的家目录 #cd …...

【Git教程】(十)版本库之间的依赖 —— 项目与子模块之间的依赖、与子树之间的依赖 ~
Git教程 版本库之间的依赖 1️⃣ 与子模块之间的依赖2️⃣ 与子树之间的依赖🌾 总结 在 Git 中,版本库是发行单位,代表的是一个版本,而分支或标签则只能被创建在版本库这个整体中。如果一个项目中包含了若干个子项目,…...
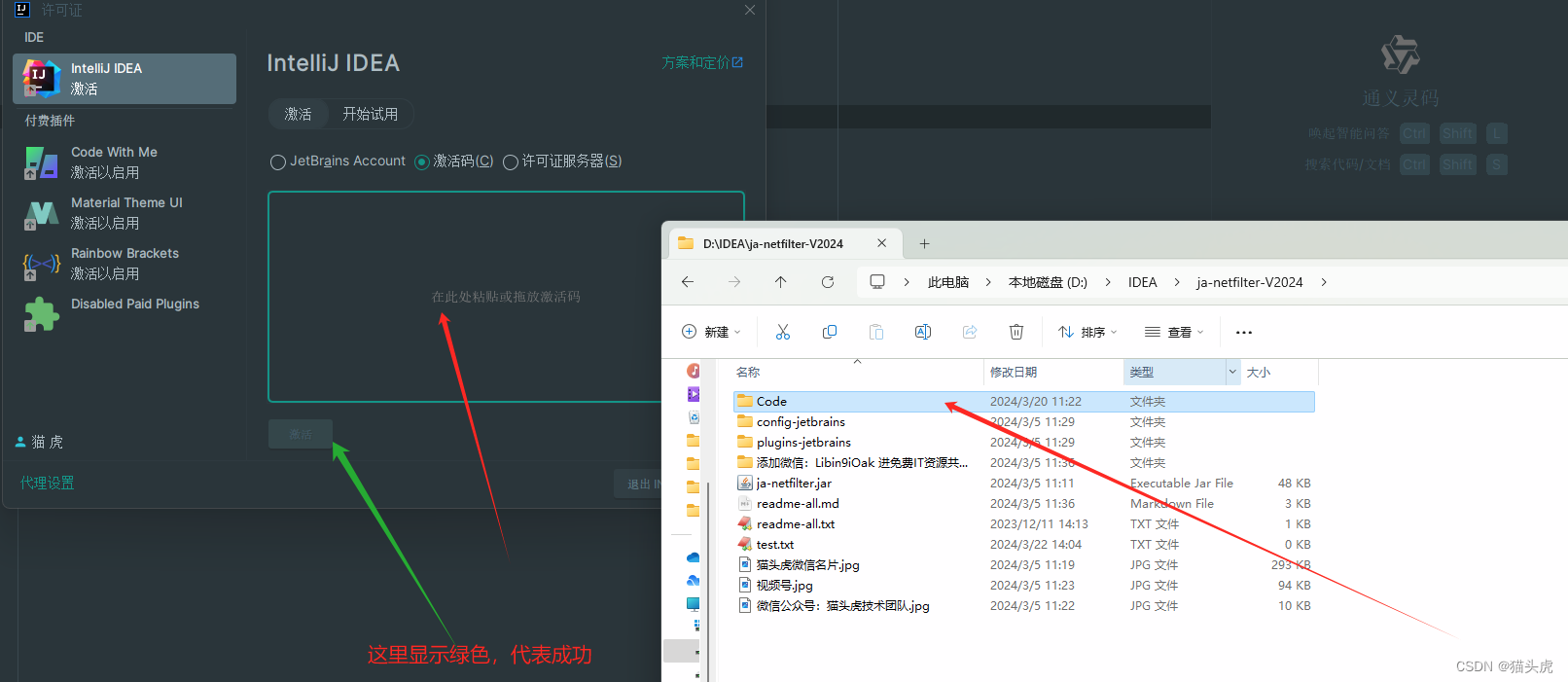
最新版IntelliJ IDEA 2024.1安装和配置教程 详细图文解说版安装教程
IntelliJ IDEA 2024.1 最新版如何快速入门体验?IntelliJ IDEA 2024.1 安装和配置教程 图文解说版 文章目录 IntelliJ IDEA 2024.1 最新版如何快速入门体验?IntelliJ IDEA 2024.1 安装和配置教程 图文解说版前言 第一步: IntelliJ IDEA 2024.1安装教程第 0 步&…...

JVM常用参数一
jvm启动参数 JVM(Java虚拟机)的启动参数是在启动JVM时可以设置的一些命令行参数。这些参数用于指定JVM的运行环境、内存分配、垃圾回收器以及其他选项。以下是一些常见的JVM启动参数: -Xms:设置JVM的初始堆大小。 -Xmx࿱…...

分布式锁-redission可重入锁原理
5.3 分布式锁-redission可重入锁原理 在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state0,假如有人持有这把锁,那么state1,如果持有这把锁的…...
 :Kotlin DSL)
Android Gradle开发与应用 (八) :Kotlin DSL
1. 前言 本文介绍了Gradle Kotlin DSL相关的一些知识点 2. DSL是什么 DSL是为特定领域设计的专门的语言,也就是设计了一门语言,然后解决某个特定的领域的特定问题。 2.1 举例说明 以下的这些都可以称之为DSL 正则表达式 :用于文本处理的特定语言SQ…...

phpstorm 快捷键
PHPstorm最常用的快捷键,提高开发效率 - 知乎 (zhihu.com) 四年精华PHP技术文章整理合集——PHP框架篇 (qq.com) 四年精华PHP技术文合集——微服务架构篇 (qq.com) Vue3 打印票据 预览的库:vue3打印解决方案:Vue-Plugin-HiPrint - 掘金 (j…...

浦大喜奔APP8.0智能升级,发力数字金融深化五大金融篇章服务
1. 浦大喜奔立足科技赋能持续迭代升级,筑牢用户体验护城河 浦发信用卡中心坚持数字科技与客户体验双轮驱动,以科技赋能发展,优化整体系统性能,全方位支撑浦大喜奔 APP提高线上客户服务能力与体验,积极服务民生消费&a…...
自然语言处理、大语言模型相关名词整理
自然语言处理相关名词整理 零样本学习(zero-shot learning)词嵌入(Embedding)为什么 Embedding 搜索比基于词频搜索效果好? Word2VecTransformer检索增强生成(RAG)幻觉采样温度Top-kTop-p奖励模…...
移动开发避坑指南——内存泄漏
在日常编写代码时难免会遇到各种各样的问题和坑,这些问题可能会影响我们的开发效率和代码质量,因此我们需要不断总结和学习,以避免这些问题的出现。接下来我们将围绕移动开发中常见问题做出总结,以提高大家的开发质量。本系列文章…...

太好玩了,我用 Python 做了一个 ChatGPT 机器人
毫无疑问,ChatGPT 已经是当下编程圈最火的话题之一,它不仅能够回答各类问题,甚至还能执行代码! 或者是变成一只猫 因为它实在是太好玩,我使用Python将ChatGPT改造,可以实现在命令行或者Python代码中调用。…...
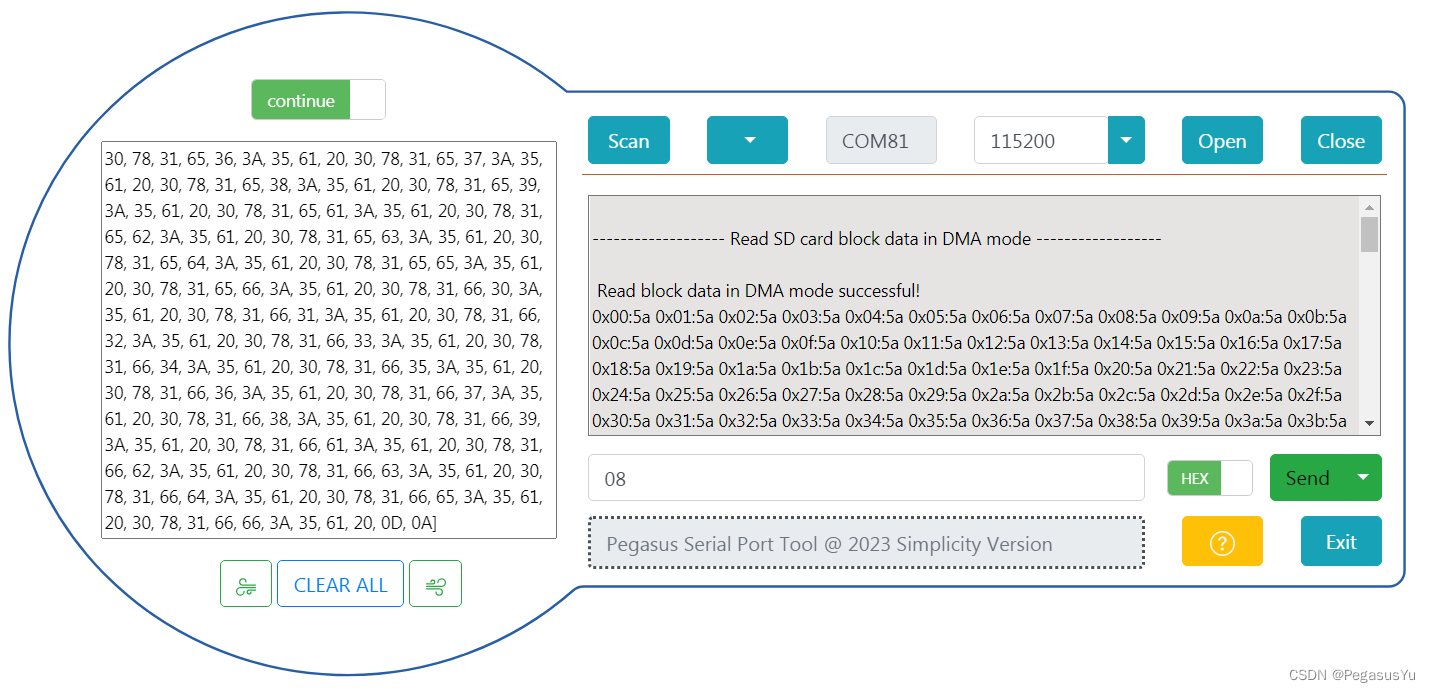
STM32存储左右互搏 SDIO总线读写SD/MicroSD/TF卡
STM32存储左右互搏 SDIO总线读写SD/MicroSD/TF卡 SD/MicroSD/TF卡是基于FLASH的一种常见非易失存储单元,由接口协议电路和FLASH构成。市面上由不同尺寸和不同容量的卡,手机领域用的TF卡实际就是MicroSD卡,尺寸比SD卡小,而电路和协…...
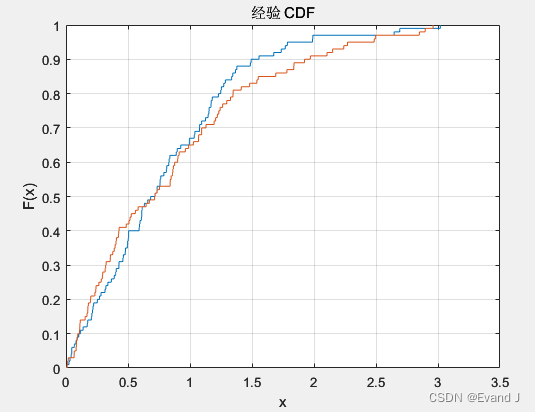
累积分布函数图(CDF)的介绍、matlab的CDF图绘制方法(附源代码)
在对比如下两个误差的时候,怎么直观地分辨出来谁的误差更低一点?: 通过这种误差时序图往往不容易看出来。 但是如果使用CDF图像,以误差绝对值作为横轴,以横轴所示误差对应的累积概率为纵轴,绘制曲线图&am…...

代码随想录算法训练营第四十一天|343.整数拆分、96不同的二叉搜索树
文档链接:https://programmercarl.com/ LeetCode343.整数拆分 题目链接:https://leetcode.cn/problems/integer-break/ 思路: j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘…...

Backtrader 终极指南:Python量化交易回测的完整解决方案
Backtrader 终极指南:Python量化交易回测的完整解决方案 【免费下载链接】backtrader Python Backtesting library for trading strategies 项目地址: https://gitcode.com/gh_mirrors/ba/backtrader 你是否曾想过用Python构建自己的量化交易策略,…...
)
为什么你的Midjourney账单暴涨200%?3个被官方文档隐瞒的计费临界点曝光(含--tile模式下的隐性显存倍增机制)
更多请点击: https://intelliparadigm.com 第一章:Midjourney GPU时间计算的本质与计费范式重构 Midjourney 的 GPU 时间并非基于物理设备的实时秒级占用,而是通过抽象化的“任务单元”(Task Unit, TU)进行计量。每个…...

Cursor Pro破解工具:5步实现永久免费使用的终极指南
Cursor Pro破解工具:5步实现永久免费使用的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

别只玩AI换脸了!用腾讯云‘云毕业照’和FaceApp,带你5分钟搞懂Deepfake到底怎么‘伪造’你的脸
从云毕业照到Deepfake:5分钟掌握人脸伪造技术的核心玩法 毕业季的校园里少了往年的喧嚣,却多了一种新奇的仪式感——云毕业照。当我在朋友圈看到第一张AI合成的学士服照片时,立刻被那种自然到几乎察觉不出破绽的效果震惊了。这背后隐藏的正是…...

一键获取学术引用数据:Zotero引用统计插件完整指南
一键获取学术引用数据:Zotero引用统计插件完整指南 【免费下载链接】zotero-citationcounts Zotero plugin for auto-fetching citation counts from various sources 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-citationcounts 你是否曾为手动追踪…...
)
树莓派物联网实战:避开TCP连接OneNet的3个常见坑(鉴权、脚本、心跳)
树莓派物联网实战:避开TCP连接OneNet的3个常见坑(鉴权、脚本、心跳) 在物联网项目开发中,树莓派作为边缘计算设备与云平台对接是常见需求。OneNet作为国内主流物联网平台,其TCP透传协议因其简单高效备受开发者青睐。然…...

Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台
Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台 【免费下载链接】dev-gpt Your Virtual Development Team 项目地址: https://gitcode.com/gh_mirrors/de/dev-gpt Dev-GPT是一款强大的虚拟开发团队工具,能够帮助开发者快速构建和部署微服务…...

GraphAgent:大语言模型与图数据融合的智能体框架解析与实践
1. 项目概述:当大语言模型遇上图数据最近在折腾一些涉及复杂关系数据的项目,比如学术文献网络、社交关系分析,甚至是企业内部的知识库梳理。这些场景里,数据不只是孤立的文本或数字,它们之间充满了各种显式的连接&…...

Loop:Mac免费窗口管理神器,彻底告别桌面混乱的终极解决方案
Loop:Mac免费窗口管理神器,彻底告别桌面混乱的终极解决方案 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是否曾因Mac桌面上堆满的窗口而感到困扰?当多个应用程序…...

MCP Jenkins Intelligence:基于AI的Jenkins智能运维与效率提升实践
1. 项目概述:当Jenkins遇上AI,DevOps的“副驾驶”来了如果你和我一样,每天都要和Jenkins打交道,盯着那些流水线看构建状态、查失败日志、分析性能瓶颈,那你肯定也幻想过:要是能像聊天一样问它问题就好了。比…...