【黑马头条】-day06自媒体文章上下架-Kafka
文章目录
- 今日内容
- 1 Kafka
- 1.1 消息中间件对比
- 1.2 kafka介绍
- 1.3 kafka安装及配置
- 1.4 kafka案例
- 1.4.1 导入kafka客户端
- 1.4.2 编写生产者消费者
- 1.4.3 启动测试
- 1.4.4 多消费者启动
- 1.5 kafka分区机制
- 1.5.1 topic剖析
- 1.6 kafka高可用设计
- 1.7 kafka生产者详解
- 1.7.1 同步发送
- 1.7.2 异步发送
- 1.7.3 参数详解
- 1.7.3.1 ack
- 1.7.3.2 retries
- 1.7.3.3 消息压缩
- 1.8 kafka消费者详解
- 1.8.1 消费者组
- 1.8.2 消息有序性
- 1.8.3 提交和偏移量
- 1.8.3.1 同步提交
- 1.8.3.2 异步提交
- 1.8.3.3 同步异步混合提交
- 1.9 Spring集成kafka
- 1.9.1 导入依赖
- 1.9.2 创建配置文件
- 1.9.3 创建生产者
- 1.9.4 创建消费者
- 1.9.5 启动类
- 1.9.6 测试
- 1.10 kafka传递对象
- 1.10.1 创建User
- 1.10.2 添加User的发送和接收
- 2 自媒体文章上下架
- 2.1 接口定义
- 2.2 Controller
- 2.3 Service
- 2.4 通知Article修改文章配置
- 2.4.1 导入kafka依赖
- 2.4.2 在Nacos中配置kafka的生产者
- 2.4.3 自媒体通知Article
- 2.4.4 在Nacos中配置kafka的消费者
- 2.4.5 配置ap_article_config表
- 2.4.6 article端监听
- 2.4.7 测试
今日内容

1 Kafka
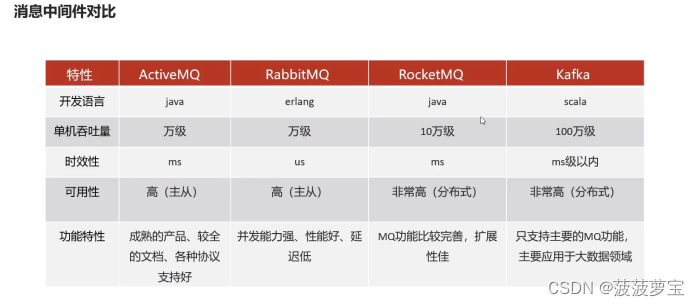
1.1 消息中间件对比

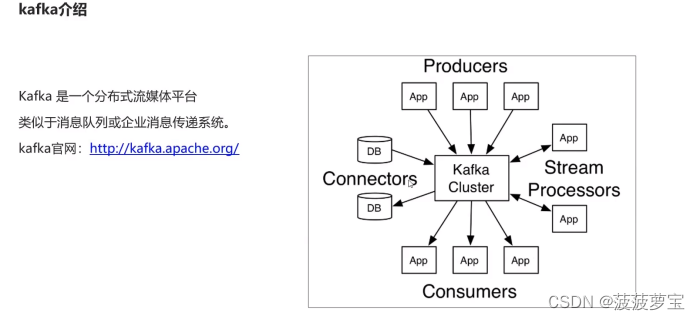
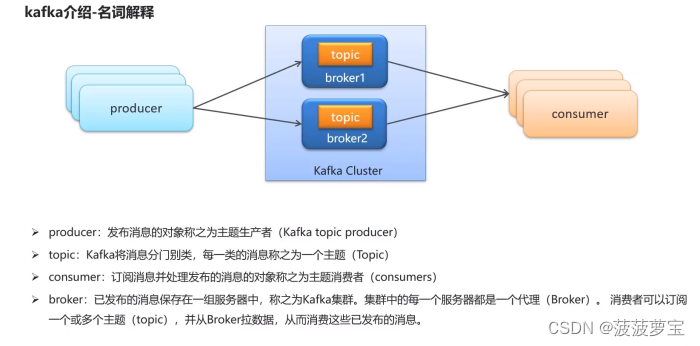
1.2 kafka介绍
1.3 kafka安装及配置

- Docker安装zookeeper
拉取镜像
docker pull zookeeper:3.4.14
创建容器
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14
- Docker安装kafka
下载镜像
docker pull wurstmeister/kafka:2.12-2.3.1
创建容器
docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.204.129 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.204.129:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.204.129:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
--net=host wurstmeister/kafka:2.12-2.3.1

docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.204.129 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.204.129:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.204.129:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
-p 9092:9092 wurstmeister/kafka:2.12-2.3.1
-p 9092:9092做端口映射
1.4 kafka案例
1.4.1 导入kafka客户端
在heima-leadnews-test模块中创建kafka-demo的模块
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
1.4.2 编写生产者消费者
创建com.heima.kafka.sample包
下面两个类ConsumerQuickStart和ProducerQuickStart类
生产者:
package com.heima.kafka.sample;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** 生产者*/
public class ProducerQuickStart {public static void main(String[] args) {//1.kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.204.129:9092");//发送失败,失败的重试次数properties.put(ProducerConfig.RETRIES_CONFIG,5);//消息key的序列化器properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//2.生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);/*** 第一个参数:topic 第二个参数:key 第三个参数:value*///封装发送的消息ProducerRecord<String,String> record = new ProducerRecord<String, String>("topic-first","key-001","hello kafka");//3.发送消息producer.send(record);//4.关闭消息通道,必须关闭,否则消息发送不成功producer.close();}}
消费者:
public class ConsumerQuickStart {public static void main(String[] args) {//1.添加kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.204.129:9092");//消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");//消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//2.消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);//3.订阅主题consumer.subscribe(Collections.singletonList("topic-first"));//当前线程一直处于监听状态while (true) {//4.获取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}}
1.4.3 启动测试
消费者成功收到消息

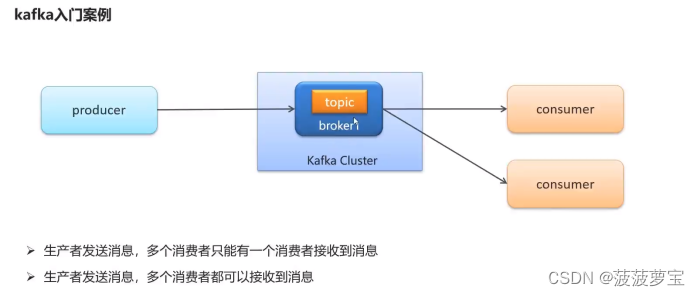
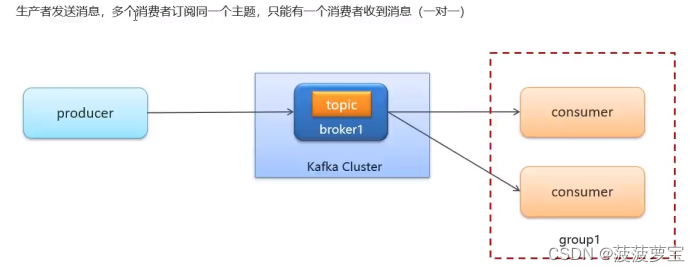
1.4.4 多消费者启动
同一个组下只能有一个消费者的收到消息
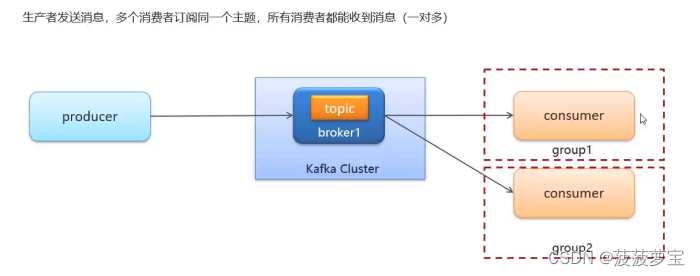
如果想一对多,则需要将消费者放在不同组中
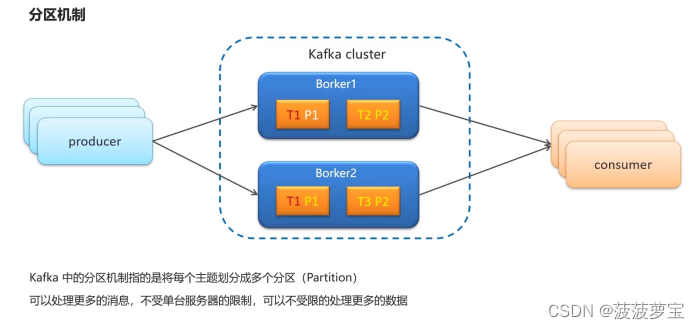
1.5 kafka分区机制
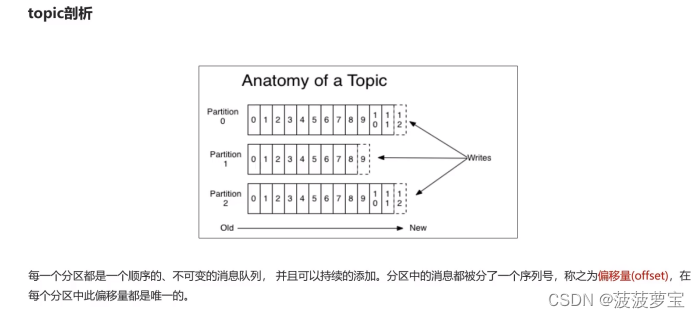
1.5.1 topic剖析

ProducerRecord<String,String> record = new ProducerRecord<String, String>("topic-first","key-001",0,"hello kafka");
在发送消息时可以指定分区partition
1.6 kafka高可用设计
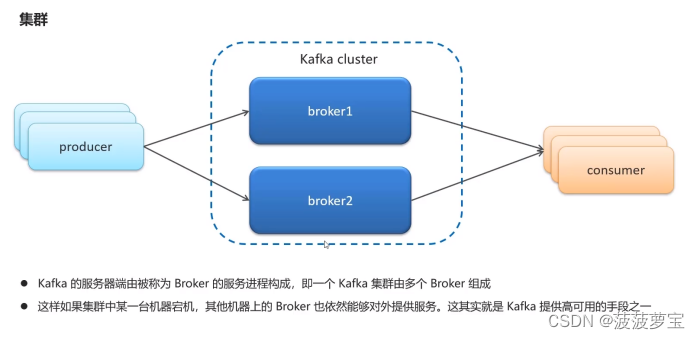
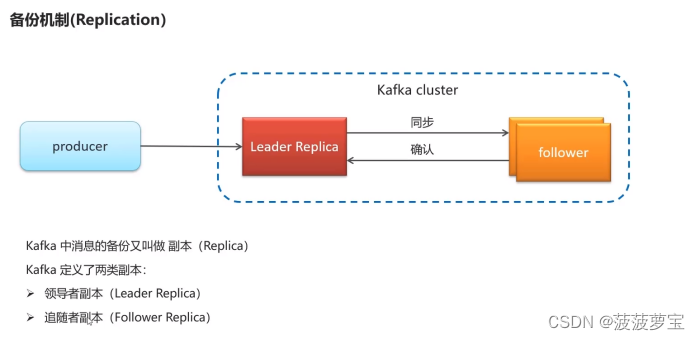
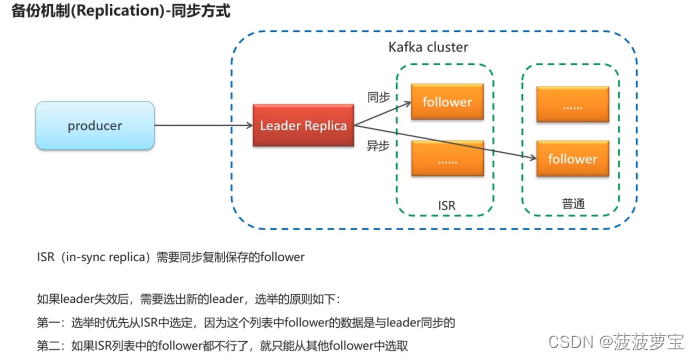

1.7 kafka生产者详解
1.7.1 同步发送
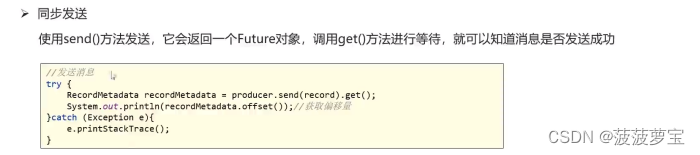
/*** 第一个参数:topic 第二个参数:key 第三个参数:value*/
//封装发送的消息
ProducerRecord<String,String> record = new ProducerRecord<String, String>("topic-first","key-001","hello kafka");//3.发送消息
//producer.send(record);//3.1 同步发送消息
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println("同步发送消息结果:topic="+recordMetadata.topic()+",partition="+recordMetadata.partition()+",offset="+recordMetadata.offset());
发送结果:
同步发送消息结果:topic=topic-first,partition=0,offset=1
1.7.2 异步发送
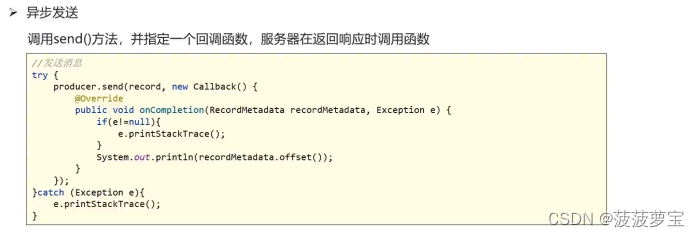
//3.2 异步发送消息
producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(e!=null){e.printStackTrace();}else{System.out.println("异步发送消息结果:topic="+recordMetadata.topic()+",partition="+recordMetadata.partition()+",offset="+recordMetadata.offset());}}
});
发送结果:
异步发送消息结果:topic=topic-first,partition=0,offset=2
1.7.3 参数详解
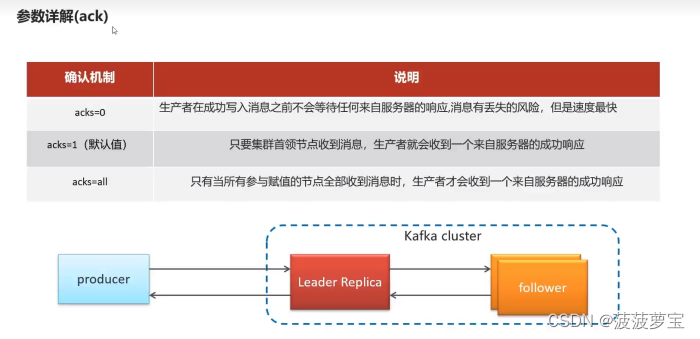
1.7.3.1 ack
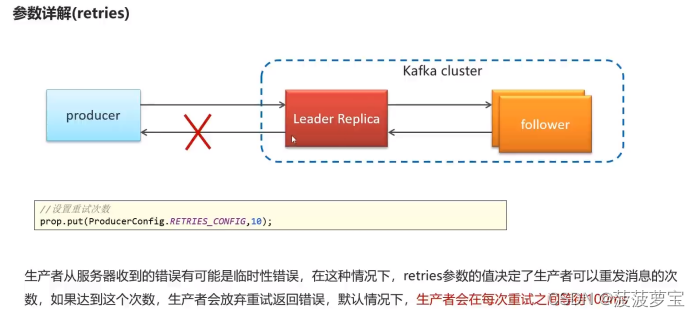
1.7.3.2 retries
1.7.3.3 消息压缩

1.8 kafka消费者详解
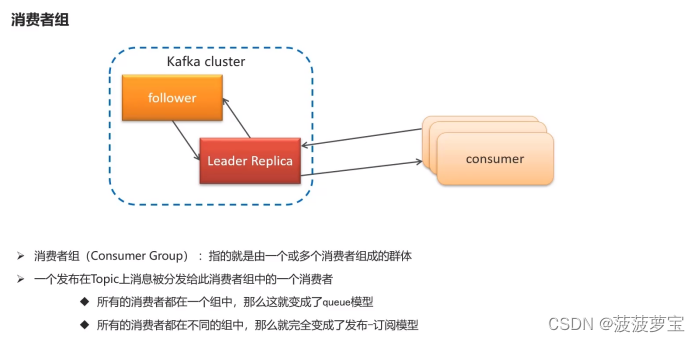
1.8.1 消费者组
1.8.2 消息有序性

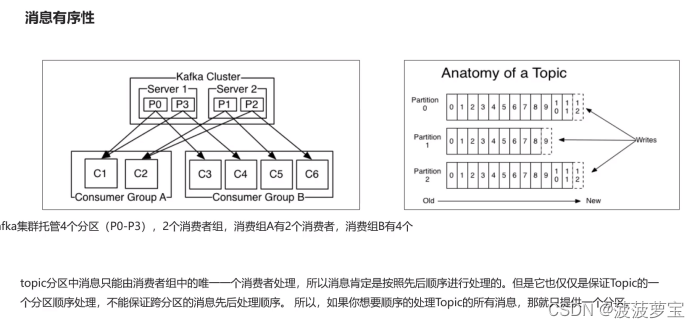
1.8.3 提交和偏移量
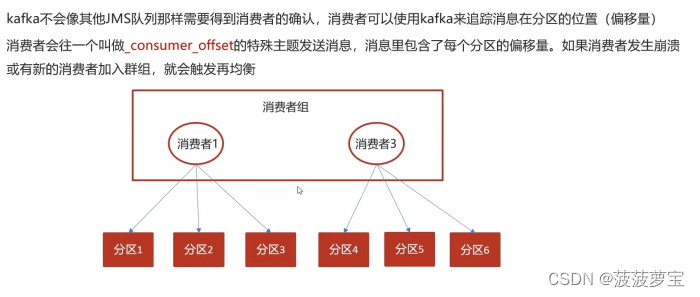
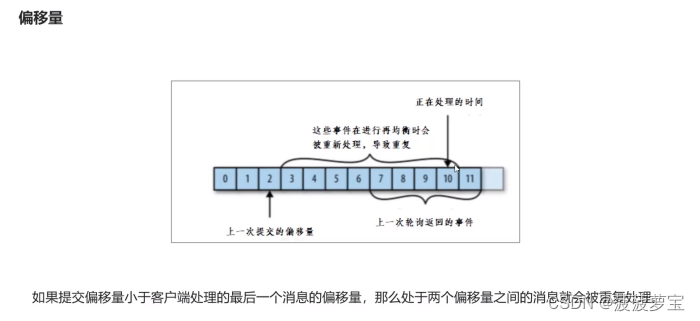
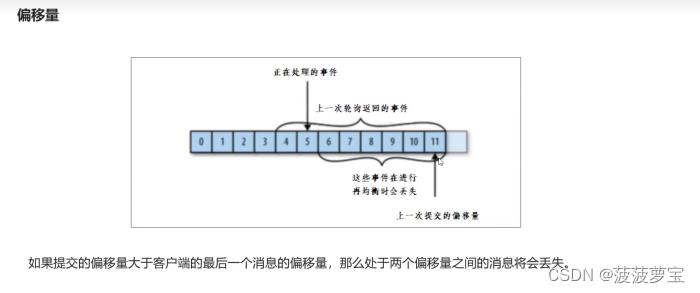

手动提交
//手动提交偏移量
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
1.8.3.1 同步提交
把enable.auto.commit设置为false,让应用程序决定何时提交偏移量。使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。否则还是会有消息丢失的风险。
只要没有发生不可恢复的错误,commitSync()方法会一直尝试直至提交成功,如果提交失败也可以记录到错误日志里。
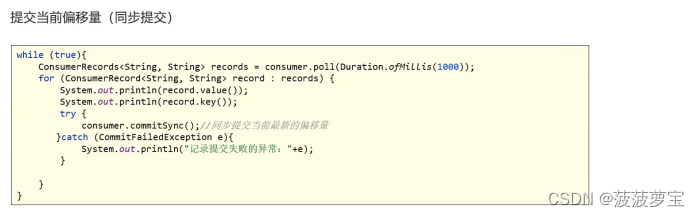
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());try {consumer.commitSync();//同步提交当前最新的偏移量}catch (CommitFailedException e){System.out.println("记录提交失败的异常:"+e);}}
}
1.8.3.2 异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的API :commitAsync()。
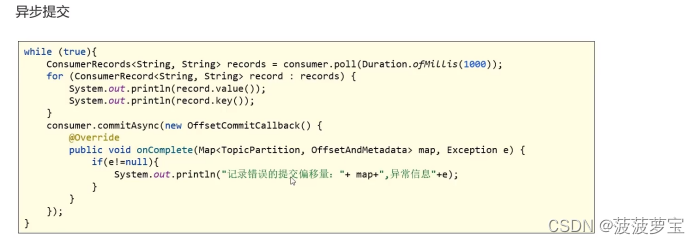
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.out.println("记录错误的提交偏移量:"+ map+",异常信息"+e);}}});
}
1.8.3.3 同步异步混合提交
异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。
相比较起来,同步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
举个例子,假如我们发起了一个异步提交commitA,此时的提交位移为2000,随后又发起了一个异步提交commitB且位移为3000;commitA提交失败但commitB提交成功,此时commitA进行重试并成功的话,会将实际上将已经提交的位移从3000回滚到2000,导致消息重复消费。
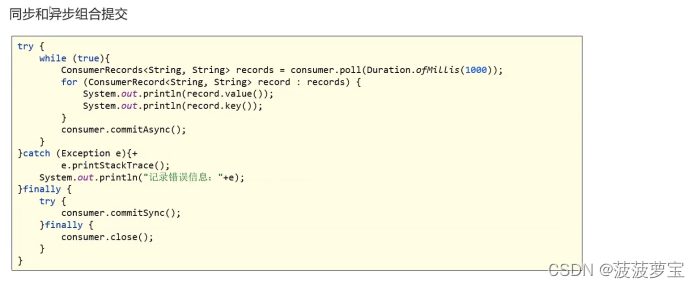
try {while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync();}
}catch (Exception e){+e.printStackTrace();System.out.println("记录错误信息:"+e);
}finally {try {consumer.commitSync();}finally {consumer.close();}
}
1.9 Spring集成kafka
1.9.1 导入依赖
在kafka-demo中导入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency>
</dependencies>
1.9.2 创建配置文件
在resources下创建文件application.yml
server:port: 9991
spring:application:name: kafka-demokafka:bootstrap-servers: 192.168.204.129:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
1.9.3 创建生产者
创建com.heima.kafka.controller.HelloController类,负责发送消息
@RestController
public class HelloController {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@GetMapping("/hello")public String hello() {kafkaTemplate.send("itcast-topic", "hello kafka");return "success";}
}
1.9.4 创建消费者
建com.heima.kafka.listener.HelloListener类,负责监听消息
@Component
public class HelloListener {@KafkaListener(topics = "itcast-topic")public void listen(String message) {if(!StringUtils.isEmpty(message)) {System.out.println("message = " + message);}}
}
1.9.5 启动类
@SpringBootApplication
public class KafkaAppication {public static void main(String[] args) {SpringApplication.run(KafkaAppication.class, args);}
}
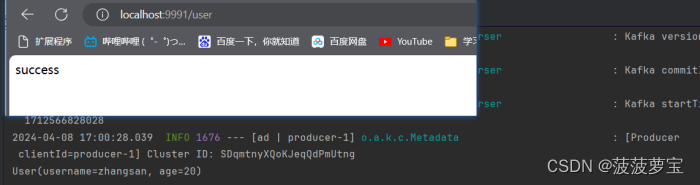
1.9.6 测试
打开localhost:9991/hello
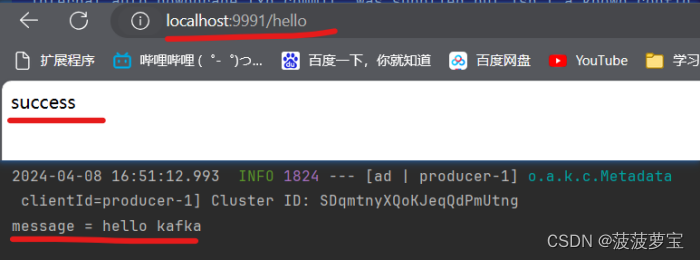
已经接收到消息
1.10 kafka传递对象
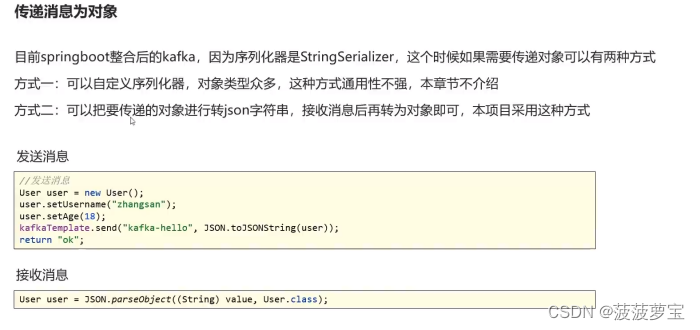
1.10.1 创建User
创建com.heima.kafka.pojo.User
@Data
public class User {private String username;private Integer age;
}
1.10.2 添加User的发送和接收
使用fastjson进行转换
Controller:
@GetMapping("/user")
public String user() {User user = new User();user.setUsername("zhangsan");user.setAge(20);kafkaTemplate.send("user-topic", JSON.toJSONString(user));return "success";
}
Listener:
@KafkaListener(topics = "user-topic")
public void listenUser(String message) {if(!StringUtils.isEmpty(message)) {User user = JSON.parseObject(message, User.class);System.out.println(user);}
}
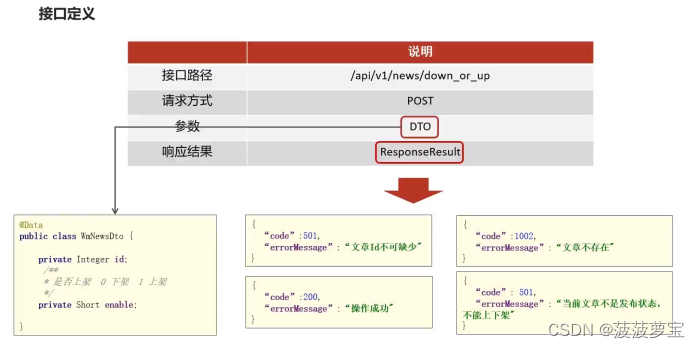
2 自媒体文章上下架

2.1 接口定义
2.2 Controller
@PostMapping("/down_or_up")
public ResponseResult downOrUp(@RequestBody WmNewsDto wmNewsDto){return wmNewsService.downOrUp(wmNewsDto);
}
2.3 Service
接口
ResponseResult downOrUp(WmNewsDto wmNewsDto);
实现
@Override
public ResponseResult downOrUp(WmNewsDto wmNewsDto) {// 1.参数检查if(wmNewsDto.getId()==null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"文章id不能为空");}// 2.查询文章WmNews wmNews = getById(wmNewsDto.getId());if(wmNews == null){return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"文章不存在");}// 3.修改文章状态if(!wmNews.getStatus().equals(WmNews.Status.PUBLISHED.getCode())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"只有已发布的文章才能上下架");}if(wmNewsDto.getEnable()==null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"enable不能为空");}wmNews.setEnable(wmNewsDto.getEnable());updateById(wmNews);// 4.返回结果return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}
2.4 通知Article修改文章配置
2.4.1 导入kafka依赖
在heima-leadnews-common模块下导入kafka依赖
<!-- kafkfa -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>
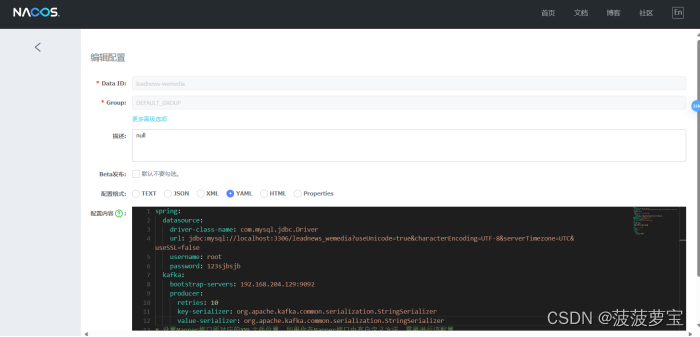
2.4.2 在Nacos中配置kafka的生产者
在自媒体端的nacos配置中心配置kafka的生产者,在heima-leadnews-wemedia下的配置文件中配置kafka
spring:kafka:bootstrap-servers: 192.168.204.129:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
2.4.3 自媒体通知Article
创建com.heima.common.constants.mNewsMessageConstants常量类,保存kafka的topic.
public class WmNewsMessageConstants {public static final String WM_NEWS_UP_OR_DOWN_TOPIC="wm.news.up.or.down.topic";
}
注入kafka
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
发送消息,通知article端修改文章配置
//发送消息,通知article端修改文章配置
if(wmNews.getArticleId() != null){Map<String,Object> map = new HashMap<>();map.put("articleId",wmNews.getArticleId());map.put("enable",dto.getEnable());kafkaTemplate.send(WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC,JSON.toJSONString(map));
}
2.4.4 在Nacos中配置kafka的消费者
在article端的nacos配置中心配置kafka的消费者
spring:kafka:bootstrap-servers: 192.168.204.129:9092consumer:group-id: ${spring.application.name}key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
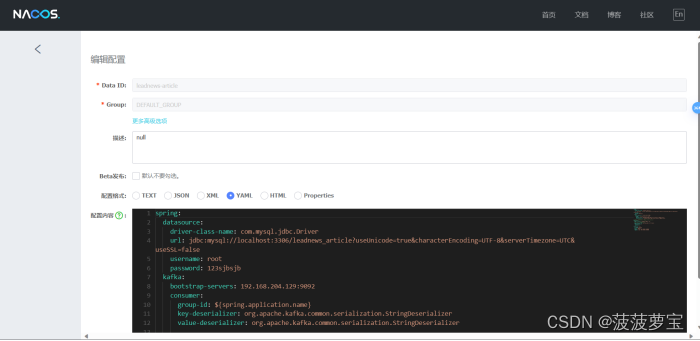
2.4.5 配置ap_article_config表
因为需要修改ap_article_config,所以需要创建对应service和mapper

创捷Service,com.heima.article.service.ApArticleConfigService接口
public interface ApArticleConfigService extends IService<ApArticleConfig> {/*** 修改文章配置* @param map*/public void updateByMap(Map map);
}
实现
@Service
@Slf4j
@Transactional
public class ApArticleConfigServiceImpl extends ServiceImpl<ApArticleConfigMapper, ApArticleConfig> implements ApArticleConfigService {/*** 修改文章配置* @param map*/@Overridepublic void updateByMap(Map map) {//0 下架 1 上架Object enable = map.get("enable");boolean isDown = true;if(enable.equals(1)){isDown = false;}//修改文章配置update(Wrappers.<ApArticleConfig>lambdaUpdate().eq(ApArticleConfig::getArticleId,map.get("articleId")).set(ApArticleConfig::getIsDown,isDown));}
}
2.4.6 article端监听
在article端编写监听,接收数据
@Component
@Slf4j
public class ArtilceIsDownListener {@Autowiredprivate ApArticleConfigService apArticleConfigService;@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)public void onMessage(String message){if(StringUtils.isNotBlank(message)){Map map = JSON.parseObject(message, Map.class);apArticleConfigService.updateByMap(map);log.info("article端文章配置修改,articleId={}",map.get("articleId"));}}
}
2.4.7 测试
启动相应启动类
打开自媒体管理界面,准备下架这个新闻
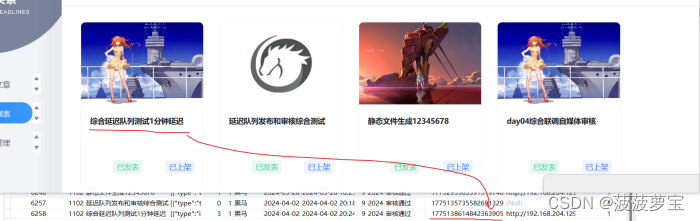
下架该文件,发现两张表都已经修改,完美进行下架
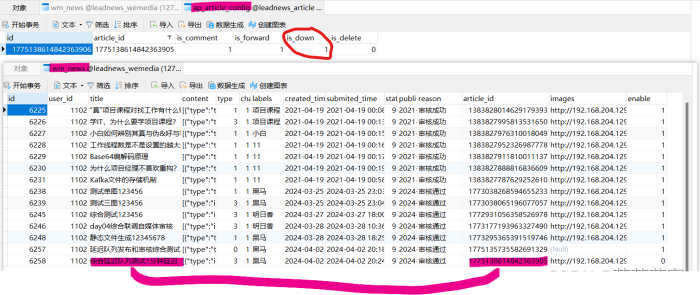
说明我们kafka的消息传递已经成功。
相关文章:
【黑马头条】-day06自媒体文章上下架-Kafka
文章目录 今日内容1 Kafka1.1 消息中间件对比1.2 kafka介绍1.3 kafka安装及配置1.4 kafka案例1.4.1 导入kafka客户端1.4.2 编写生产者消费者1.4.3 启动测试1.4.4 多消费者启动 1.5 kafka分区机制1.5.1 topic剖析 1.6 kafka高可用设计1.7 kafka生产者详解1.7.1 同步发送1.7.2 异…...
非线性特征曲线线性化插补器(CODESYS 完整ST代码)
1、如何利用博途PLC和信捷PLC实现非线性特征曲线的线性化可以参考下面文章链接: 非线性特征曲线线性化(插补功能块SCL源代码+C代码)_scl直线插补程序-CSDN博客文章浏览阅读382次。信捷PLC压力闭环控制应用(C语言完整PD、PID源代码)_RXXW_Dor的博客-CSDN博客闭环控制的系列文章…...
vue3从精通到入门4:diff算法的实现
Vue 3 的 diff 算法相较于 Vue 2 有了一些改进和优化,主要是为了应对更复杂的组件结构和更高的性能需求。 以下是 Vue 3 diff 算法在处理列表更新时的大致步骤: 头头比较:首先,比较新旧列表的头节点(即第一个节点&…...
(三)C++自制植物大战僵尸游戏项目结构说明
植物大战僵尸游戏开发教程专栏地址http://t.csdnimg.cn/ErelL 一、项目结构 打开项目后,在解决方案管理器中有五个项目,分别是libbox2d、libcocos2d、librecast、libSpine、PlantsVsZombies五个项目,除PlantsVsZombies外,其他四个…...
)
动态规划专练( 279.完全平方数)
279.完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 …...
京东商品详情API接口(商品属性丨sku价格丨详情图丨标题等数据)
京东商品详情API接口是京东开放平台提供的一种API接口,通过调用该接口,开发者可以获取京东商品的标题、价格、库存、月销量、总销量、详情描述、图片等详细信息。下面针对您提到的商品属性、SKU价格、详情图以及标题等数据,做具体介绍&#x…...
Springboot+Vue项目-基于Java+MySQL的校园周边美食探索及分享平台系统(附源码+演示视频+LW)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:Java毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计 &…...

折叠面板组件(vue)
代码 <template><div class"collapse-info"><div class"collapse-title"><div class"title-left">{{ title }}</div><div click"changeHide"> <Button size"small" v-if"sho…...

【Canvas技法】蓝底金字北岛诗节选(径向渐变色、文字阴影示例)
【效果图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>北岛诗选</title><style type"text/css">.c…...
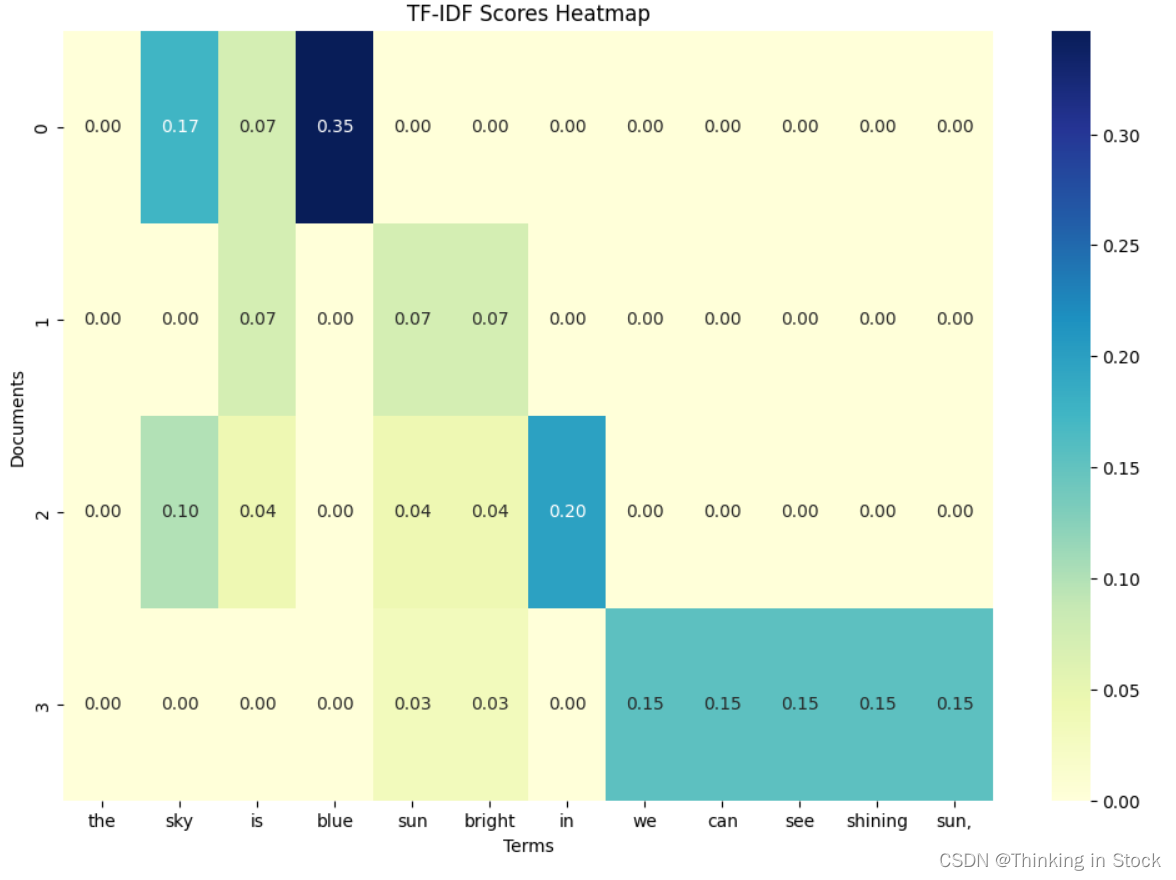
【大语言模型】基础:TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索与文本挖掘的统计方法,用来评估一个词对于一个文件集或一个语料库中的其中一份文件的重要性。它是一种常用于文本处理和自然语言处理的权重计算技术。 原理 TF-IDF 由两部分组成࿱…...
[开发日志系列]PDF图书在线系统20240415
20240414 Step1: 创建基础vueelment项目框架[耗时: 1h25min(8:45-10:10)] 检查node > 升级至最新 (考虑到时间问题,没有使用npm命令行执行,而是觉得删除重新下载最新版本) > > 配置vue3框架 取名:Online PDF Book System 遇到的报错: 第一报错: npm ERR! …...
蓝桥杯 — — 纯质数
纯质数 题目: 思路: 一个最简单的思路就是枚举出所有的质数,然后再判断这个质数是否是一个纯质数。 枚举出所有的质数: 可以使用常规的暴力求解法,其时间复杂度为( O ( N N ) O(N\sqrt{N}) O(NN )&…...
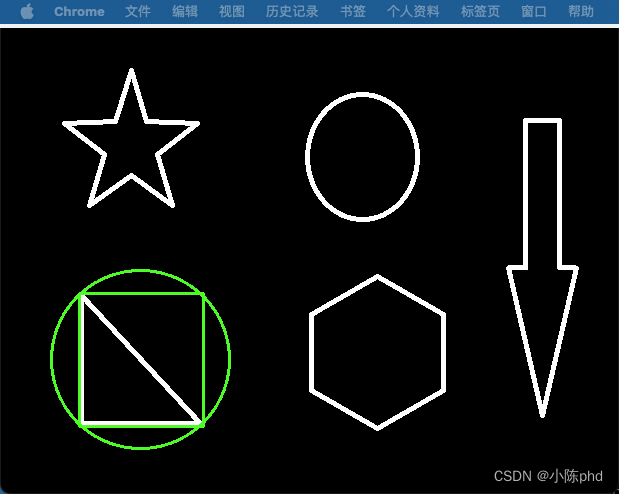
OpenCV基本图像处理操作(三)——图像轮廓
轮廓 cv2.findContours(img,mode,method) mode:轮廓检索模式 RETR_EXTERNAL :只检索最外面的轮廓;RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;RETR_CCOMP:检索所有的轮廓,并将他们组…...

比特币突然暴跌
作者:秦晋 周末愉快。 今天给大家分享两则比特币新闻,也是两个数据。一则是因为中东地缘政治升温,传统资本市场的风险情绪蔓延至加密市场,引发加密市场暴跌。比特币跌至66000美元下方。杠杆清算金额高达8.5亿美元。 二则是&#x…...

使用SpeechRecognition和vosk处理ASR
SpeechRecognition可以支持多种模型语音转文字,感觉vosk还不错,使用起来也简单一些;百度也有PaddleSpeech,但是安装起来太麻烦,不是这个库版本不对就是那个库有问题,用起来不方便; 安装SpeechR…...

【Go】通道:缓冲通道和非缓冲通道
目录 通道的基本概念 缓冲通道 非缓冲通道 总结 通道的基本概念 在Go语言中,通道是一种特殊的类型,用于在goroutine之间传递数据。你可以将通道想象为数据的传输管道。通道分为两种类型: 非缓冲通道(Unbuffered Channels&…...

Java中数组的使用
在Java编程中,数组是一种非常重要的数据结构,它允许我们存储相同类型的多个元素。对于初学者来说,理解数组的基本概念、初始化、遍历、默认值以及内存分配和使用注意事项是非常关键的。 一、数组的概念 数组是一个可以容纳多个相同类型数据…...

CAP5_Monday
A Set to Max (Easy Version) 给定数组 a 和 b,可以执行以下操作任意次 : 让 a l ∼ a r a_l\sim a_r al∼ar 中的所有所有元素变成 a i a_i ai ( l ≤ i ≤ r ) (l\leq i\leq r) (l≤i≤r), 其中 1 ≤ l ≤ r ≤ n 1\leq l \leq r \leq n 1≤…...
科大讯飞星火开源大模型iFlytekSpark-13B GPU版部署方法
星火大模型的主页:iFlytekSpark-13B: 讯飞星火开源-13B(iFlytekSpark-13B)拥有130亿参数,新一代认知大模型,一经发布,众多科研院所和高校便期待科大讯飞能够开源。 为了让大家使用的更加方便,科…...
SpringBoot基于RabbitMQ实现消息延迟队列方案
知识小科普 在此之前,简单说明下基于RabbitMQ实现延时队列的相关知识及说明下延时队列的使用场景。 延时队列使用场景 在很多的业务场景中,延时队列可以实现很多功能,此类业务中,一般上是非实时的,需要延迟处理的&a…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...