百川2模型解读
简介
Baichuan 2是多语言大模型,目前开源了70亿和130亿参数规模的模型。在公开基准如MMLU、CMMLU、GSM8K和HumanEval上的评测,Baichuan 2达到或超过了其他同类开源模型,并在医学和法律等垂直领域表现优异。此外,官方还发布所有预训练模型的checkpoints,帮助研究社区更好地理解Baichuan 2的训练过程。总结下Baichuan 2特点:
- 多语言支持:Baichuan 2专注于训练在多种语言中表现优异的模型,包括不仅限于英文。这使得Baichuan 2在处理各种语言的任务时能够取得显著的性能提升。
- 广泛的训练数据:Baichuan 2 是从头开始训练的,训练数据约有2.6万亿个token。相对于以往的模型,Baichuan 2 提供了更丰富的数据资源,从而能够更好地支持多语言的开发和应用。
- 垂直领域优化:Baichuan 2不仅在通用任务上表现出色,还在特定领域(如医学和法律)的任务中展现了卓越的性能。这为特定领域的应用提供了强有力的支持。
GitHub:
https://github.com/baichuan-inc/Baichuan2
技术报告:
https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
预训练
Baichuan 2 base模型(即基座模型)和其他模型的对比评测结果如下,可以看出多数评测数据上Baichuan 2遥遥领先!

预训练数据集
在构建数据的时候,本着追求数据的全面性和代表性,从多个来源收集数据,包括一般的互联网网页,书籍,研究论文,代码库等。训练语料库的组成如Figure 1所示:

可以看出,数据类型比较广泛,Top3数据类型是科技、商业和娱乐。
数据处理:主要关注数据的数量和质量。
- 数量:构建了一个大规模的聚类和去重系统,支持LSH(局部敏感哈希)类和embedding类形式的数据特征。该系统能够在几小时内对万亿级的数据进行聚类和去重,从而保证数据的高效利用。基于聚类技术对文档、段落和句子进行去重和评分。这些分数用于后续预训练步骤的数据抽样。不同数据处理阶段的训练数据规模如Figure 2 所示:

- 质量:句子级别质量过滤,过滤暴力、色情、种族歧视、仇恨言论等有害内容。
模型架构
在模型架构层面,主要还是基于Transformer,但是做了如下修改:
Tokenizer
分词器Tokenizer需要平衡两个关键因素:高压缩率以实现高效推理,以及适当大小的词汇表以确保每个词嵌入被充分训练。为此,Baichuan 2的词汇表大小从 Baichuan 1的 64,000 扩展到 125,696。
在Tokenizer方面使用来自 SentencePiece 的字节对编码(BPE)。需要补充说明的是,不对输入文本使用任何规范化,也不像 Baichuan 1那样添加虚拟前缀。此外,将数值分割成单个数字以更好地编码数值数据。为了处理包含额外空格的代码数据,在Tokenizer中添加了仅包含空格的token。字符覆盖率设置为0.9999,稀有字符回退到 UTF-8 字节。将token到最大长度设置为32,以兼容较长的中文短语。Baichuan 2 Tokenizer的训练数据来自 Baichuan 2 预训练语料库,为了提高覆盖范围采样更多代码示例和学术论文数据。Table 2展示了Baichuan 2分词器与其他分词器的详细比较。

位置编码。在 Baichuan 1 的基础上,为 Baichuan 2-7B 采用 Rotary Positional Embedding(RoPE),为 Baichuan 2-13B 采用 ALiBi。ALiBi是一种较新的位置编码技术,可以改善外推性能。然而,大多数开源模型使用 RoPE 作为位置embeddings,像 Flash Attention这样的注意力机制优化方法。这是因为Flash Attention是基于乘法的,无需将 attention_mask 传递给注意力操作,所以采用RoPE更合适。尽管如此,从初步实验结果发现,位置嵌入的选择对模型性能影响不大。为了促进关于bias-based 和 multiplication-based注意力机制的进一步研究,在 Baichuan 2-7B 上应用 RoPE,在 Baichuan 2-13B 上应用 ALiBi(与Baichuan 1 保持一致)。
激活函数和归一化
使用 SwiGLU 激活函数,这是一种 switch-activated 的 GLU 变体。然而,SwiGLU有一个“双线性”层,并包含三个参数矩阵,与 原始Transformer的前馈层有两个矩阵不同,因此将隐层尺寸从 4 倍隐层尺寸减少到 8/3 隐层尺寸,并四舍五入为 128 的倍数。
对于 Baichuan 2 的注意力层,采用由 xFormers2 实现的内存高效注意力。通过利用 xFormers 的优化注意力和偏置能力,可以在降低内存开销的同时有效地结合 ALiBi 的基于偏置的位置编码。这为 Baichuan 2 的大规模训练提供了性能和效率优势。
在Transformer Block的输入应用层归一化(Layer Normalization),这对于warm-up更具鲁棒性。此外,使用 RMSNorm(均方根归一化),这种方法只计算输入特征的方差,效率更高。
优化器
选用AdamW优化器,β1 和 β2 分别设置为 0.9 和 0.95。使用 0.1 的权重衰减,并将梯度范数剪切到 0.5。模型先用 2,000 个线性缩放step进行warmed up,达到最大学习率,然后应用余弦衰减直到最小学习率。参数和学习率详情见于Table 3:

混合精度: 模型训练使用 BFloat16 混合精度,在前向和反向计算中使用BFloat16,而在优化器更新中使用Float32。与Float16相比,BFloat16 具有更好的动态范围,使其对训练大型语言模型中的大值更具鲁棒性。然而,BFloat16 的低精度在某些设置中会引发一些问题。例如,在一些 RoPE 和 ALibi 的实现中,当整数超过 256 时,torch.arange 操作会由于碰撞而失败,导致无法区分附近位置。因此,对于一些对于值敏感的操作,如位置嵌入,使用完整精度。
NormHead: 为了稳定训练并提高模型性能,对输出嵌入(也称为“head”)进行归一化。NormHead在实验中有两个优点。
- 稳定训练。在实验中发现head的范数容易不稳定,训练过程中稀有token嵌入的范数变小,会扰乱训练动态。NormHead 可以显著稳定训练动态。
- 降低了L2距离在计算logits时的影响。实验中发现语义信息主要通过嵌入的余弦相似性而不是 L2 距离编码。由于当前的线性分类器通过点积计算 logits,它是 L2 距离和余弦相似性的混合。NormHead 减轻了在计算 logits 时 L2 距离的干扰。
Max-z 损失: 在训练过程中,LLM 的 logits 可能变得非常大。虽然 softmax 函数对于绝对 logits 值是不可知的,因为它只依赖于它们的相对值。大的 logits 在推理过程中会带来问题,因为常见的重复惩罚实现(如 Hugging Face 实现3中的 model.generate)直接将标量应用于 logits。以这种方式收缩非常大的 logits 可以显著改变 softmax 之后的概率,使模型对重复惩罚超参数的选择敏感。受到 NormSoftmax 和 PaLM 中的辅助 z-损失的启发,添加一个max-z loss 对logit值进行归一化:
其中z是最大的logit值。这有助于稳定训练并使推理时对超参数更具鲁棒性。
Scaling Laws
随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,所有三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系。当这种幂率关系出现时,可以提前对模型的性能进行预测。基于该定律可以在深度学习和大型语言模型的训练代价变得越来越昂贵的当下确保性能。
具体如何操作呢?在训练数十亿参数的大型语言模型之前,先训练一些小型模型,并为训练更大模型拟合缩放定律。训练了从 10M 到 3B 一系列模型(最终模型的 1/1000 到 1/10),并且每个模型最多训练 1 万亿个token,使用的超参数和数据集与Baichuan 2相同。根据不同模型的最终损失,可以获取从训练 flops 到目标损失的映射。为了拟合模型的缩放定律,采用了 Henighan 等人(2020)给出的公式:
其中是不可约损失,第一项是可约损失,它被表示为一个幂律缩放项。是训练 flops, 是在该 flops 中模型的最终损失。使用 SciPy4 库的 curve_fit函数来拟合参数。最终拟合的缩放曲线以及预测的 70 亿和 130 亿参数模型的最终损失如Figure 4 所示。可以看到,拟合的缩放定律准确地预测了 Baichuan 2 的最终损失。

通过这个实验,研究人员可以确定最终的模型规模,并为训练提供相应的资源配置,以保证训练的高效性和性能表现。
Infrastructure
为了实现GPU资源的高效利用,研究人员为弹性训练框架和智能集群调度策略开发了一种协同设计方法。
由于 GPU 在多用户和任务之间共享,每个任务的具体行为不可预测,这通常导致集群中出现空闲的 GPU 节点。由于配置8块A800 GPUs的单个机器足以满足 Baichuan 7B 和 Baichuan 13B模型的内存需求,因此训练框架的设计主要集中在机器级弹性。机器级弹性使其能够根据集群状态动态修改任务资源,从而为智能调度算法奠定基础。
为满足机器级弹性的要求,训练框架集成了张量并行和ZeRO 驱动的数据并行。在每台机器内部设置张量并行,并使用ZeRO共享数据并行,以实现机器之间的弹性缩放。
此外,采用张量分割技术。通过分割某些计算以减少峰值内存占用,如大词汇表的交叉熵计算。这种方法使其能够在不增加额外计算和通信的情况下满足内存需求,使系统更高效。
为了在不影响模型准确性的前提下进一步加速训练,研究人员实现了混合精度训练,在这里使用 BFloat16 执行前向和反向计算,而在优化器更新时使用Float32。此外,为了有效地将训练集群扩展到数千个GPU,整合了以下技术,以避免降低通信效率:
- 拓扑感知的分布式训练。在大规模集群中,网络连接经常跨越多层交换机。通过策略性地安排分布式训练的排名,以最大程度地减少不同交换机之间的频繁访问,从而减少延迟并提高整体训练效率。
- ZeRO 的混合和分层分区。通过将参数分区到 GPU,ZeRO3 以增加全收集通信开销为代价,减少内存消耗。当扩展到数千个 GPU 时,这种方法会带来显著的通信瓶颈。为了解决这个问题,研究人员提出了一种混合和分层分区方案。具体来说,首先将优化器状态分区到所有 GPU, 然后自适应地决定哪些层需要激活ZeRO3,以及是否分层分区参数。
通过整合这些策略,该系统能够在 1,024 个 NVIDIA A800 GPU 上高效地训练 Baichuan 2-7B 和 Baichuan 2-13B 模型,实现超过 180 TFLOPS 的计算效率。
对齐
Baichuan 2 还引入了对齐过程,从而产生了两个Chat模型:Baichuan 2-7B-Chat 和 Baichuan 2-13B-Chat。Baichuan 2的对齐过程包括两个部分:有监督微调(SFT)和来自人类反馈的强化学习(RLHF)。
监督微调
在监督微调阶段,标注人员为各种数据源的提示(Prompt)进行注释,每个提示根据与Claude类似的关键原则,被标记为有帮助或无害。使用交叉验证到方式验证数据质量:会让一位权威的标注者检查特定标注工作组标注的批次样本的质量,拒绝任何不符合质量标准的批次数据。最终收集超过 100k 的监督微调样本,并基于这些数据训练基座模型。接下来,通过 RLHF做强化学习以进一步改进结果。整个 RLHF 过程,包括 RM 和 RL 训练,如Figure 5 所示。

Reward Model(RM)
为提示(Prompt)设计一个3层次的分类系统,包括6个主要类别、30个次要类别和超过200个三级类别。从用户的角度来看,希望分类系统能够全面覆盖所有类型的用户需求;从训练奖励模型的角度来看,每个类别中的提示应具有足够的多样性,以确保奖励模型能够很好地泛化。给定一个提示,用不同大小和阶段(SFT,PPO)的 Baichuan 2 模型生成多样化的回应。在训练RM时,只使用由 Baichuan 2 模型族生成的回应。用于训练奖励模型的损失函数与InstructGPT的损失函数一致。训练得到的奖励模型表现与LLaMA 2一致,这表明两个回应之间的分数差距越大,奖励模型的区分准确性越高,
PPO
获得奖励模型之后,使用PPO算法进一步训练语言模型。具体使用了4种模型:actor模型(负责生成回应)、reference模型(用于计算固定参数的KL惩罚)、reward模型(提供整个回应的总体奖励,固定参数)以及 critic模型(用于学习每个token的值)。
在RLHF训练过程中,critic模型在初始训练时先做20个step的warmed up。再通过标准PPO算法更新critic和actor模型。对于所有模型,使用了0.5的梯度裁剪、5e-6的恒定学习率、PPO裁剪阈值ϵ = 0.1。将KL惩罚系数β设为0.2,并随着step的增加逐渐减小到0.005。对于所有Chat模型包括Baichuan 2-7B-Chat和Baichuan 2-13B-Chat进行350次迭代。
安全
百川的研究人员认为模型的安全性改进不仅在于数据清洗或对齐阶段的约束,还在于所有训练阶段中积极获取正面知识并识别负面知识。在整个Baichuan 2训练过程基于这一理念增强了模型的安全性。
预训练阶段
在预训练阶段,主要关注数据的安全性。整个预训练数据集进行严格的数据过滤流程,从而增强安全性。官方制定了一套规则和模型,以去除有害内容,如暴力、色情、种族歧视、仇恨言论等。
此外,策划了一个中英文双语数据集,包括数百家知名网站的数百万网页,这代表了各种正面价值领域,涵盖政策、法律、弱势群体、普遍价值观、传统美德等。同时提高对该数据集的采样概率。
对齐阶段
建立了一个包含6种类型攻击和100多种细粒度安全价值类别的红队程序,由10名具有传统互联网安全经验的专家标注团队初始化安全对齐提示(Prompt)。这些初始化提示是从预训练数据集中检索相关片段,然后创建回应,最终产生了约1,000个初始化的标注提示数据。
- 专家标注团队通过初始化的对齐模型引导了一个50人的外包标注团队,进行红蓝对抗,生成了20万个攻击提示。
- 通过使用专门的多值监督采样方法,最大程度地利用攻击数据,以生成不同安全级别的回应。
在RL优化阶段,也将安全性作为首要考虑:
- 在安全性强化的开始,DPO 方法有效地利用了有限数量的标注数据,以增强对特定脆弱性问题的性能。
- 通过使用集成有益和无害目标的奖励模型,进行了PPO安全性强化训练。
总结
| 模型 | 百川2 |
|---|---|
| 参数量 | 7b,13b |
| 训练token数 | 2.6万亿 |
| tokenizer | BPE |
| 词表大小 | 125696 |
| 位置编码 | 7b:RoPE ; 13b:ALiBi (影响不大) |
| 最长上下文 | 4096 |
| 激活函数 | SwiGLU |
| 归一化 | Layer Normalization + RMSNorm |
| 注意力机制 | xFormers2 |
| 优化器 | AdamW+NormHead+Max-z损失 |
参考:
【论文阅读】《Baichuan 2: Open Large-scale Language Models》
相关文章:
百川2模型解读
简介 Baichuan 2是多语言大模型,目前开源了70亿和130亿参数规模的模型。在公开基准如MMLU、CMMLU、GSM8K和HumanEval上的评测,Baichuan 2达到或超过了其他同类开源模型,并在医学和法律等垂直领域表现优异。此外,官方还发布所有预…...
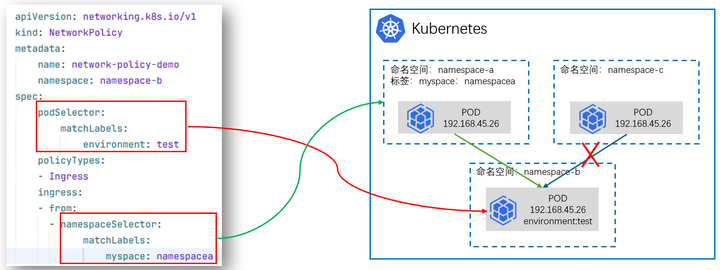
云原生专栏丨基于K8s集群网络策略的应用访问控制技术
在当今云计算时代,Kubernetes已经成为容器编排的事实标准,它为容器化应用提供了强大的自动化部署、扩展和管理能力。在Kubernetes集群中,网络策略(Network Policy)作为对Pod间通信进行控制的关键功能,对保障应用安全和隔离性起到了…...

MySQL 优化 - index_merge 导致查询偶发变慢
文章目录 前言问题描述原因分析总结 前言 今天遇到了一个有意思的问题,线上数据库 CPU 出现了偶发的抖动。定位到原因是一条查询语句偶发变慢造成的,随后通过调整表中的索引解决。 问题描述 下方是脱敏后的 SQL 语句: select oss_path f…...

SpringBoot自动连接数据库的解决方案
在一次学习设计模式的时候,沿用一个旧的boot项目,想着简单,就把数据库给关掉了,结果报错 Consider the following: If you want an embedded database (H2, HSQL or Derby), please put it on the classpath. 没有数据库的需…...

Docker-10 Docker Compose
一、前言 通过前面几篇文章的学习,我们可以通过Dockerfile文件让用户很方便的定义一个单独的应用容器。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况,或者开发一个Web应用,除了Web服务容器本身,还需要数据库服务容器、缓存容器,甚至还包括负…...

new mars3d.control.MapSplit({实现点击卷帘两侧添加不同图层弹出不同的popup
new mars3d.control.MapSplit({实现点击卷帘两侧添加不同图层弹出不同的popup效果: 左侧: 右侧: 说明:mars3d的3.7.12以上版本才支持该效果。 示例链接: 功能示例(Vue版) | Mars3D三维可视化平台 | 火星科技 相关代…...

数据库中虚拟表和临时表的区别?
虚拟表(Virtual Table)和临时表(Temporary Table)在数据库系统中都用于处理暂时性的数据存储需求,但它们的概念和用途有所不同: 虚拟表(通常是视图View): 虚拟表&#…...

Node.js -- mongoose
文章目录 1. 介绍2. mongoose 连接数据库3. 插入文件4. 字段类型5. 字段值验证6. 文档处理6.1 删除文档6.2 更新文档6.3 读取文档 7. 条件控制8. 个性化读取9. 代码模块化 1. 介绍 Mongoose是一个对象文档模型库,官网http://www.mongoosejs.net/ 方便使用代码操作mo…...
保持亮灯:监控工具如何确保 DevOps 中的高可用性
在快速发展的 DevOps 领域,保持高可用性 (HA) 至关重要。消费者期望应用程序具有全天候响应能力和可访问性。销售损失、客户愤怒和声誉受损都是停机的后果。为了使 DevOps 团队能够在问题升级为中断之前主动检测、排除故障并解决问题,监控工具成为这种情…...
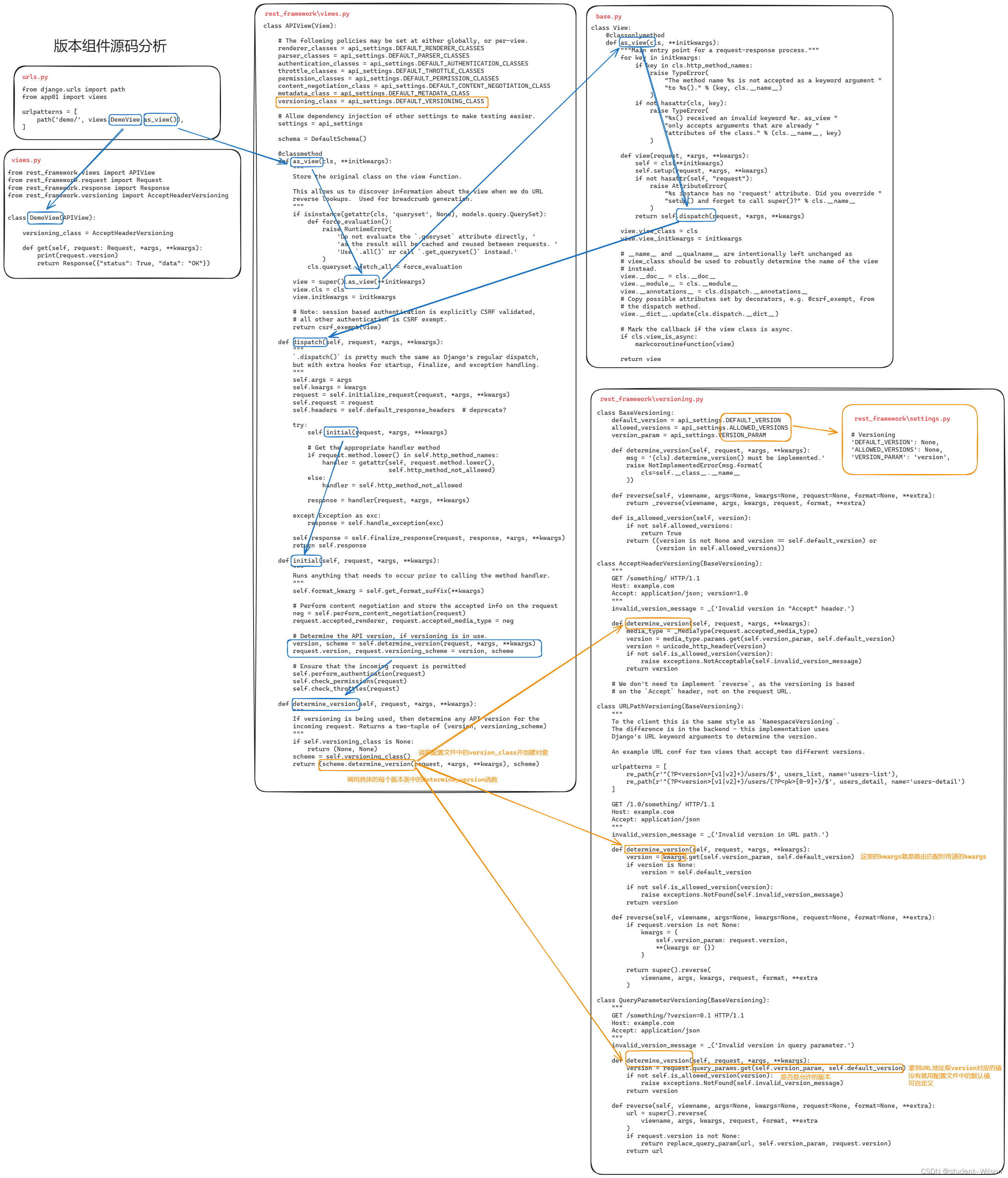
DRF版本组件源码分析
DRF版本组件源码分析 在restful规范中要去,后端的API中需要体现版本。 3.6.1 GET参数传递版本 from rest_framework.versioning import QueryParameterVersioning单视图应用 多视图应用 # settings.pyREST_FRAMEWORK {"VERSION_PARAM": "versi…...

C#算法之希尔排序
算法释义:希尔排序,也被称为缩小增量排序,是一种有效的排序算法,它是插入排序的一种更高效的改进版,通过比较一定间隔的元素来工作,然后逐步较少间隔来排序。 小编的理解啊,希尔排序的本质就是不…...
)
校园餐厅预约系统(请打开git自行访问)
校园餐厅预约系统详细介绍 项目地址:https://gitee.com/zhang—xuan/online_booking_system 服务端部分 Socket类 作用:创建socket连接,作为服务端与客户端通信的基础。 Sock_Obj类 基类:定义了服务端需要的基本操作和属性。 派生…...
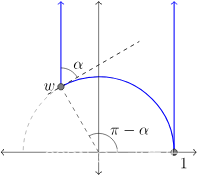
【双曲几何-05 庞加莱模型】庞加来上半平面模型的几何属性
文章目录 一、说明二、双曲几何的上半平面模型三、距离问题四、弧长微分五、面积问题 一、说明 庞加莱圆盘模型是表示双曲几何的一种方法,对于大多数用途来说它都非常适合几何作图。然而,另一种模型,称为上半平面模型,使一些计算变…...

Bookends for Mac:文献管理工具
Bookends for Mac,一款专为学术、研究和写作领域设计的文献管理工具,以其强大而高效的功能深受用户喜爱。这款软件支持多种文件格式,如PDF、DOC、RTF等,能够自动提取文献的关键信息,如作者、标题、出版社等,…...

SpringEL表达式编译模式SpelCompilerMode详解
目前网上没有搜到关于SpringEL表达式编译模式SpelCompilerMode的详细讲解,都是对官方文档的翻译,并没有详细说明根本差异。 该文章为个人原创,谢绝抄袭 SpringEL表达式官方文档:https://docs.spring.io/spring-framework/reference/core/expressions.html 在构建SpringE…...
物联网实战--平台篇之(一)架构设计
本项目的交流QQ群:701889554 物联网实战--入门篇https://blog.csdn.net/ypp240124016/category_12609773.html 物联网实战--驱动篇https://blog.csdn.net/ypp240124016/category_12631333.html 一、平台简介 物联网平台这个概念比较宽,大致可以分为两大类&#x…...

spi 驱动-数据发送流程分析
总结 核心函数是spi_sync, 设备驱动->核心函数-> 控制器驱动 实例分析 (gdb) c Continuing.Thread 115 hit Breakpoint 1, bcm2835_spi_transfer_one (master0xffffffc07b8e6000, spi0xffffffc07b911800, tfr0xffffff8009f53c40) at drivers/spi/spi-bcm2835…...
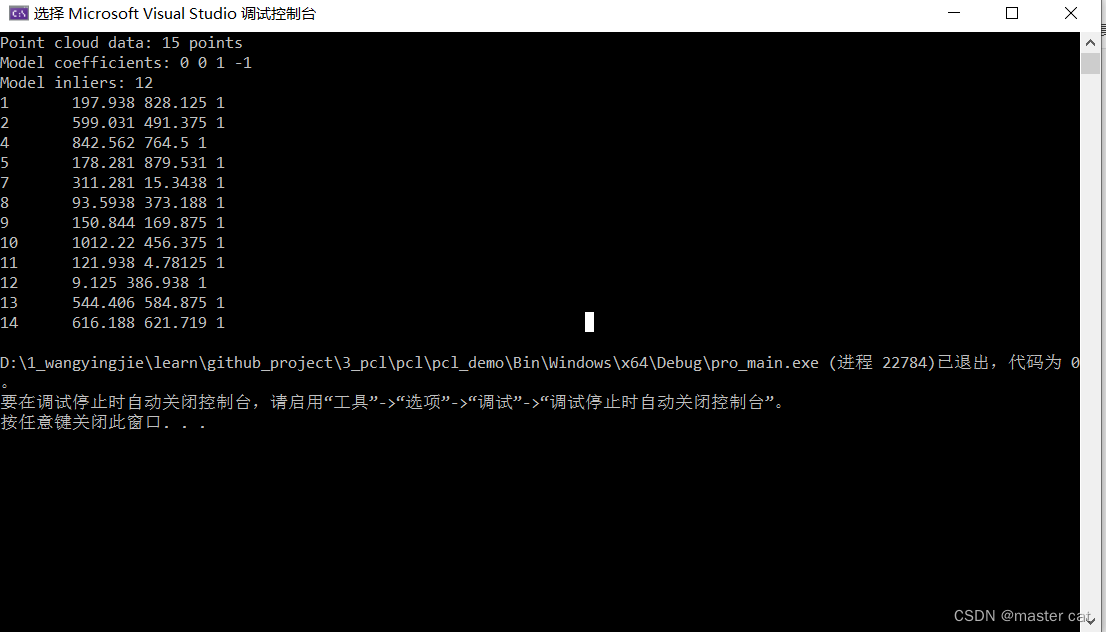
平面分割--------PCL
平面分割 bool PclTool::planeSegmentation(pcl::PointCloud<pcl::PointXYZ>::Ptr cloud, pcl::ModelCoefficients::Ptr coefficients, pcl::PointIndices::Ptr inliers) {std::cout << "Point cloud data: " << cloud->points.size() <<…...
前端之深拷贝
前提: 就是在实际开发中,我有一个编辑的弹窗,可以查看和编辑,因为弹窗里面是一个步骤条,点击下一步就要向对应的接口发送请求,考虑到就比如我点击下一步,此次表箱信息其实不需要修改࿰…...

2024年 Java 面试八股文——SpringCloud篇
目录 1.Spring Cloud Alibaba 中的 Nacos 是如何进行服务注册和发现的? 2.Spring Cloud Alibaba Sentinel 的流量控制规则有哪些? 3.Spring Cloud Alibaba 中如何实现分布式配置管理? 4.Spring Cloud Alibaba RocketMQ 的主要特点有哪些&…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...