Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg
本文首发于公众号:机器感知
Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg

Converting Anyone's Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model
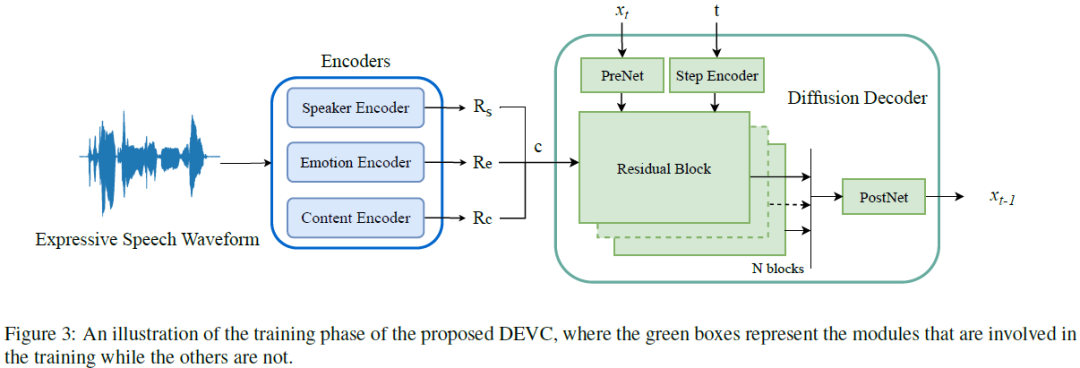
Expressive voice conversion (VC) conducts speaker identity conversion for emotional speakers by jointly converting speaker identity and emotional style. Emotional style modeling for arbitrary speakers in expressive VC has not been extensively explored. Previous approaches have relied on vocoders for speech reconstruction, which makes speech quality heavily dependent on the performance of vocoders. A major challenge of expressive VC lies in emotion prosody modeling. To address these challenges, this paper proposes a fully end-to-end expressive VC framework based on a conditional denoising diffusion probabilistic model (DDPM). We utilize speech units derived from self-supervised speech models as content conditioning, along with deep features extracted from speech emotion recognition and speaker verification systems to model emotional style and speaker identity. Objective and subjective evaluations show the effectiveness of our framework. Codes and samples are publicly available......
DreamScene4D: Dynamic Multi-Object Scene Generation from Monocular Videos

Existing VLMs can track in-the-wild 2D video objects while current generative models provide powerful visual priors for synthesizing novel views for the highly under-constrained 2D-to-3D object lifting. Building upon this exciting progress, we present DreamScene4D, the first approach that can generate three-dimensional dynamic scenes of multiple objects from monocular in-the-wild videos with large object motion across occlusions and novel viewpoints. Our key insight is to design a "decompose-then-recompose" scheme to factorize both the whole video scene and each object's 3D motion. We first decompose the video scene by using open-vocabulary mask trackers and an adapted image diffusion model to segment, track, and amodally complete the objects and background in the video. Each object track is mapped to a set of 3D Gaussians that deform and move in space and time. We also factorize the observed motion into multiple components to handle fast motion. The camera motion can be infe......
X-SLAM: Scalable Dense SLAM for Task-aware Optimization using CSFD
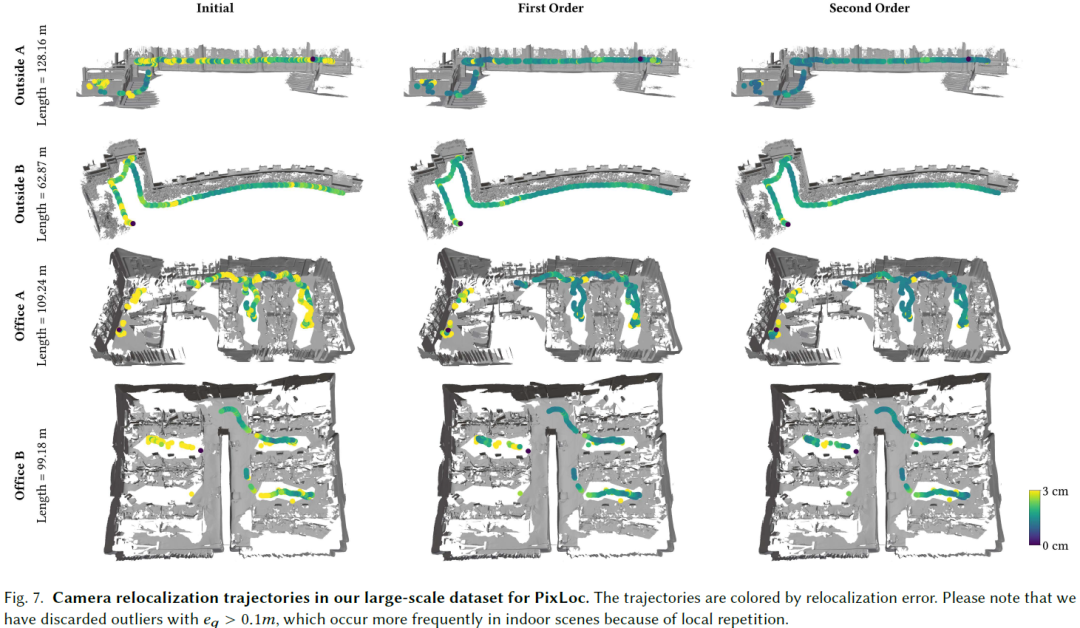
We present X-SLAM, a real-time dense differentiable SLAM system that leverages the complex-step finite difference (CSFD) method for efficient calculation of numerical derivatives, bypassing the need for a large-scale computational graph. The key to our approach is treating the SLAM process as a differentiable function, enabling the calculation of the derivatives of important SLAM parameters through Taylor series expansion within the complex domain. Our system allows for the real-time calculation of not just the gradient, but also higher-order differentiation. This facilitates the use of high-order optimizers to achieve better accuracy and faster convergence. Building on X-SLAM, we implemented end-to-end optimization frameworks for two important tasks: camera relocalization in wide outdoor scenes and active robotic scanning in complex indoor environments. Comprehensive evaluations on public benchmarks and intricate real scenes underscore the improvements in the accuracy of cam......
Panoptic-SLAM: Visual SLAM in Dynamic Environments using Panoptic Segmentation
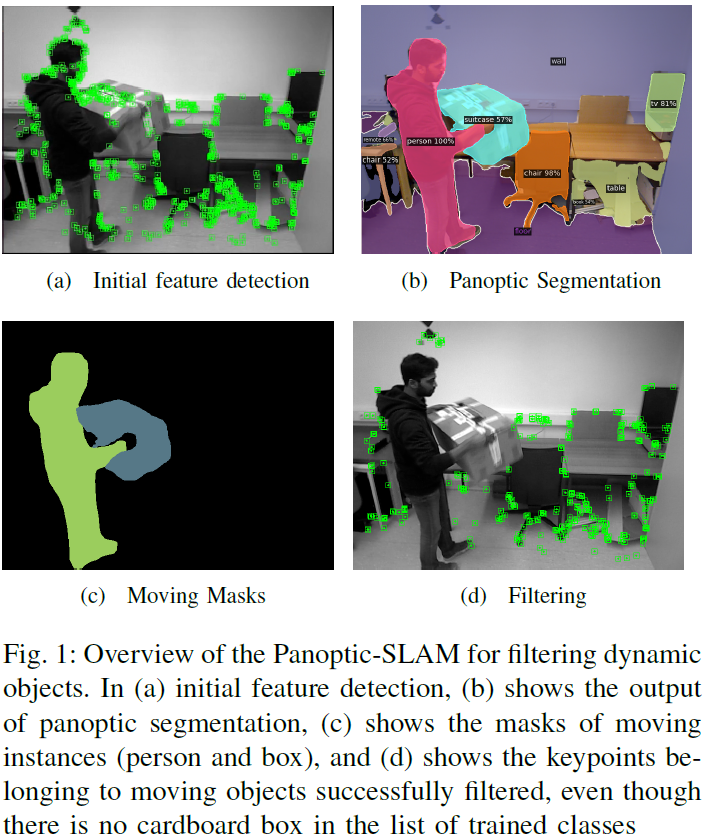
The majority of visual SLAM systems are not robust in dynamic scenarios. The ones that deal with dynamic objects in the scenes usually rely on deep-learning-based methods to detect and filter these objects. However, these methods cannot deal with unknown moving objects. This work presents Panoptic-SLAM, an open-source visual SLAM system robust to dynamic environments, even in the presence of unknown objects. It uses panoptic segmentation to filter dynamic objects from the scene during the state estimation process. Panoptic-SLAM is based on ORB-SLAM3, a state-of-the-art SLAM system for static environments. The implementation was tested using real-world datasets and compared with several state-of-the-art systems from the literature, including DynaSLAM, DS-SLAM, SaD-SLAM, PVO and FusingPanoptic. For example, Panoptic-SLAM is on average four times more accurate than PVO, the most recent panoptic-based approach for visual SLAM. Also, experiments were performed using a quadruped ro......
Characterized Diffusion and Spatial-Temporal Interaction Network for Trajectory Prediction in Autonomous Driving
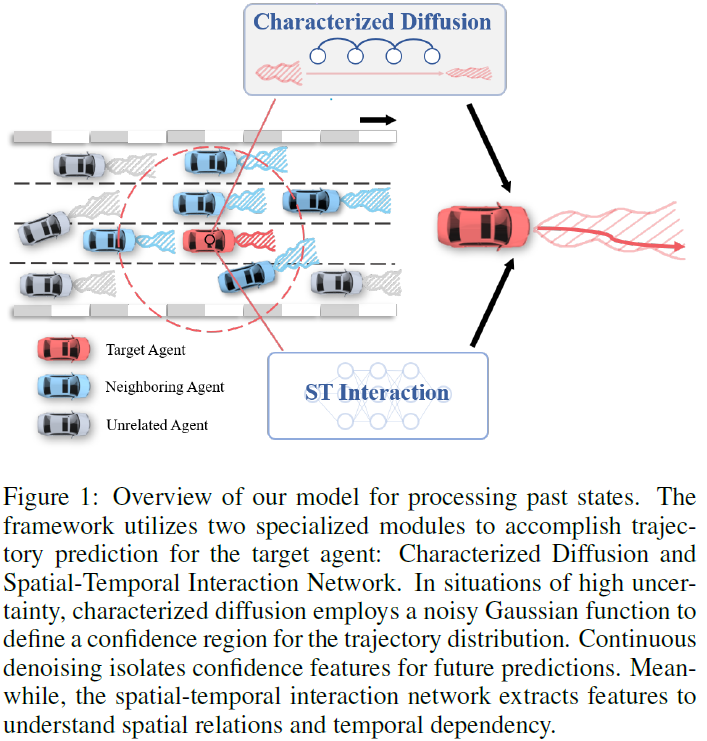
Trajectory prediction is a cornerstone in autonomous driving (AD), playing a critical role in enabling vehicles to navigate safely and efficiently in dynamic environments. To address this task, this paper presents a novel trajectory prediction model tailored for accuracy in the face of heterogeneous and uncertain traffic scenarios. At the heart of this model lies the Characterized Diffusion Module, an innovative module designed to simulate traffic scenarios with inherent uncertainty. This module enriches the predictive process by infusing it with detailed semantic information, thereby enhancing trajectory prediction accuracy. Complementing this, our Spatio-Temporal (ST) Interaction Module captures the nuanced effects of traffic scenarios on vehicle dynamics across both spatial and temporal dimensions with remarkable effectiveness. Demonstrated through exhaustive evaluations, our model sets a new standard in trajectory prediction, achieving state-of-the-art (SOTA) results on t......
Probablistic Restoration with Adaptive Noise Sampling for 3D Human Pose Estimation
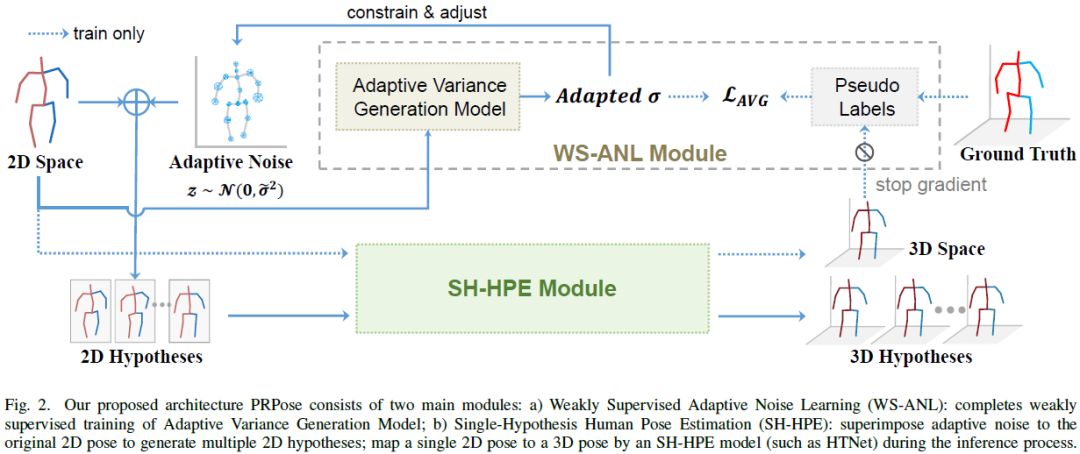
The accuracy and robustness of 3D human pose estimation (HPE) are limited by 2D pose detection errors and 2D to 3D ill-posed challenges, which have drawn great attention to Multi-Hypothesis HPE research. Most existing MH-HPE methods are based on generative models, which are computationally expensive and difficult to train. In this study, we propose a Probabilistic Restoration 3D Human Pose Estimation framework (PRPose) that can be integrated with any lightweight single-hypothesis model. Specifically, PRPose employs a weakly supervised approach to fit the hidden probability distribution of the 2D-to-3D lifting process in the Single-Hypothesis HPE model and then reverse-map the distribution to the 2D pose input through an adaptive noise sampling strategy to generate reasonable multi-hypothesis samples effectively. Extensive experiments on 3D HPE benchmarks (Human3.6M and MPI-INF-3DHP) highlight the effectiveness and efficiency of PRPose. Code is available at: https://github.com......
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
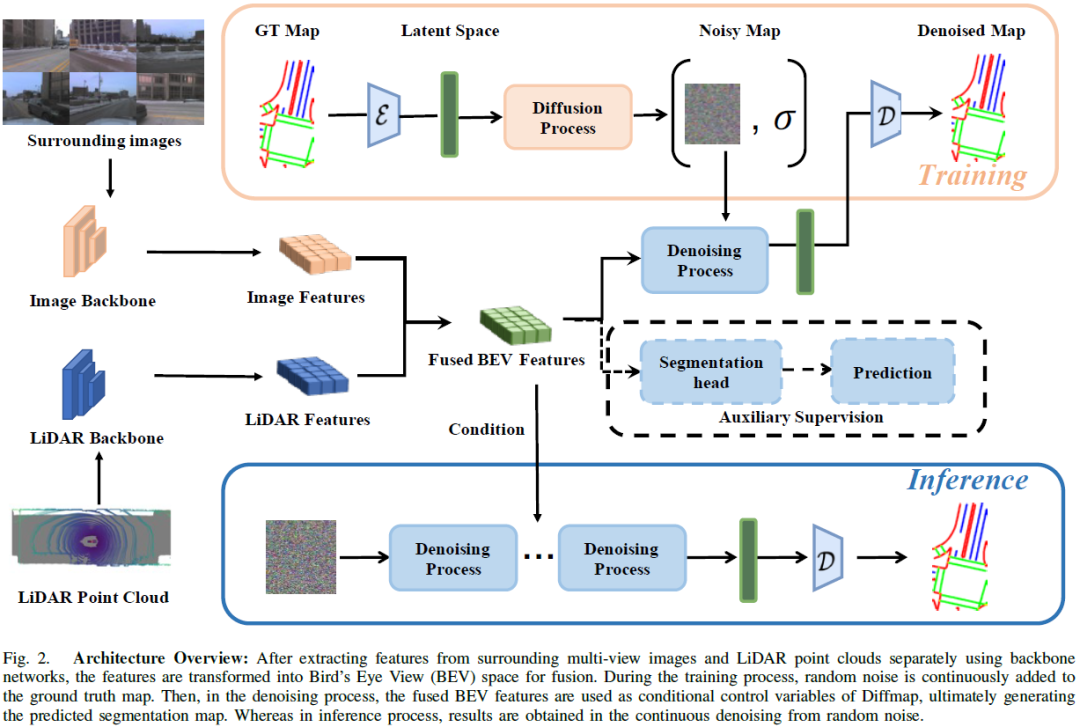
Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately d......
TinySeg: Model Optimizing Framework for Image Segmentation on Tiny Embedded Systems
Image segmentation is one of the major computer vision tasks, which is applicable in a variety of domains, such as autonomous navigation of an unmanned aerial vehicle. However, image segmentation cannot easily materialize on tiny embedded systems because image segmentation models generally have high peak memory usage due to their architectural characteristics. This work finds that image segmentation models unnecessarily require large memory space with an existing tiny machine learning framework. That is, the existing framework cannot effectively manage the memory space for the image segmentation models. This work proposes TinySeg, a new model optimizing framework that enables memory-efficient image segmentation for tiny embedded systems. TinySeg analyzes the lifetimes of tensors in the target model and identifies long-living tensors. Then, TinySeg optimizes the memory usage of the target model mainly with two methods: (i) tensor spilling into local or remote storage and (ii) ......
Efficient and Economic Large Language Model Inference with Attention Offloading
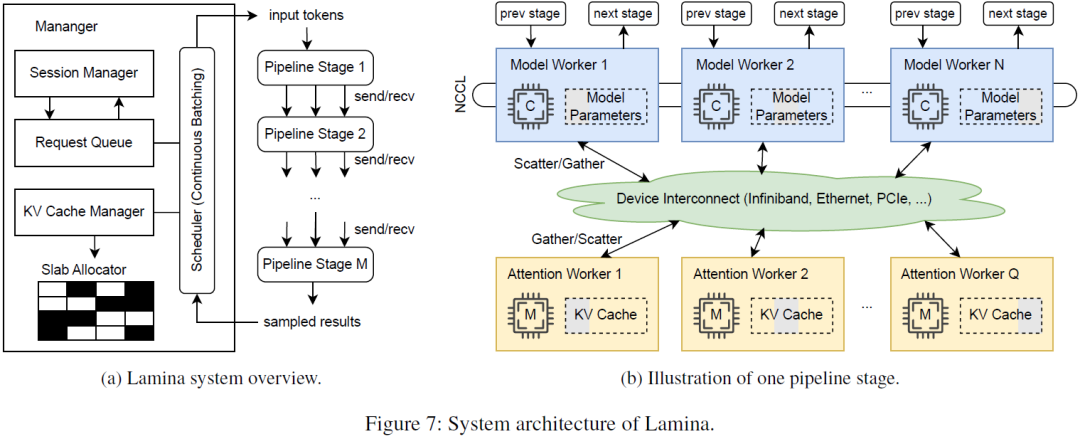
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficienc......
相关文章:
Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg
本文首发于公众号:机器感知 Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg Converting Anyones Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model Expressive voice conversion (VC) conducts speak…...

短信群发平台分析短信群发的未来发展趋势
短信群发平台在当前的移动互联网时代已经展现出了其独特的价值和广泛的应用场景。随着技术的不断进步和市场的不断变化,短信群发的未来发展趋势也将呈现出一些新的特点。 首先,随着5G网络的推广和普及,短信群发的速度和稳定性将得到进一步提…...

supervisord 使用指南
supervisord 使用指南 supervisord的安装 supervisor是一系列python脚本文件,以python package的形式管理,可以用于UNIX类系统的进程管理。 安装supervisor也相当简单,只需要用pip安装即可。 sudo pip install supervisor但是有可能将其安…...
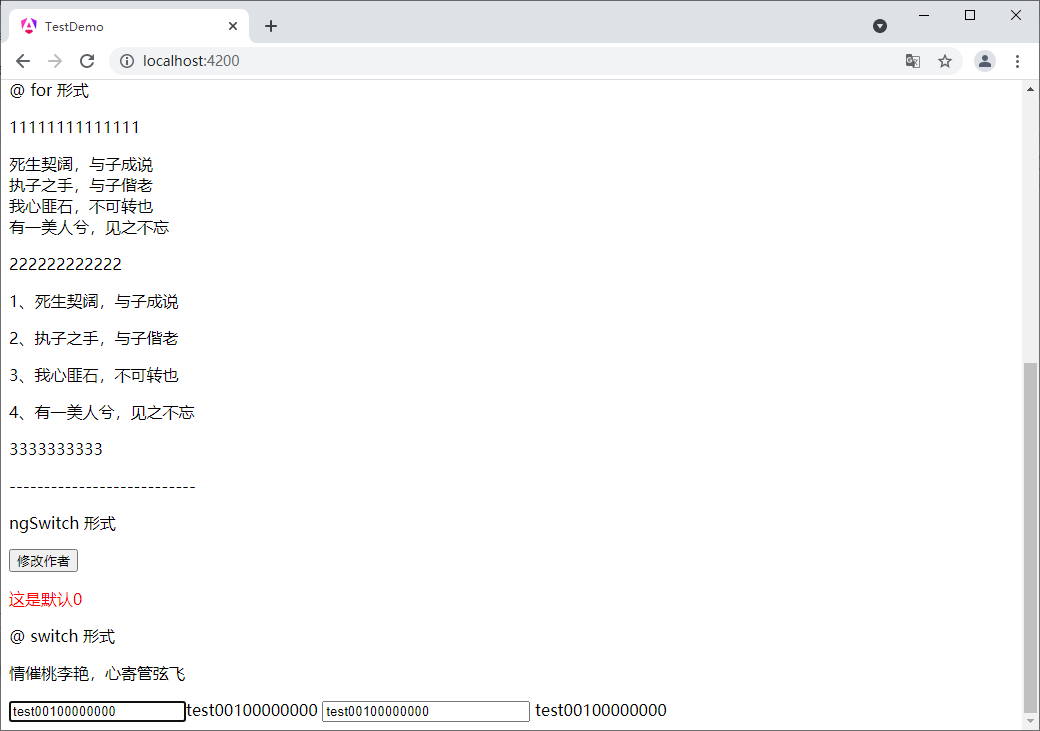
AngularJS 的生命周期和基础语法
AngularJS 的生命周期和基础语法 文章目录 AngularJS 的生命周期和基础语法1. 使用步骤2. 生命周期钩子函数3. 点击事件4. if 语句1. if 形式2. if else 形式 5. for 语句6. switch 语句7. 双向数据绑定 1. 使用步骤 // 1. 要使用哪个钩子函数,就先引入 import { O…...

docker-compose 网络
自定义网络 - HOST 与宿主机共享网络 version: "3" services:web:image: nginx:1.21.6restart: alwaysports:- 80:80network_mode: host自定义网络 - 固定ip version: "3" services:web:image: nginx:1.21.6restart: alwaysports:- 80:80networks:app&am…...

农药生产厂污废水如何处理达标
农药生产厂的污废水处理是确保该行业对环境的负面影响最小化的重要环节。下面是一些常见的处理方法和步骤,可以帮助农药生产厂的污废水达到排放标准: 预处理:将废水进行初步处理,去除大颗粒悬浮物和固体残渣。这可以通过筛网、沉淀…...

根据相同的key 取出数组中最后一个值
数组中有很多对象 , 需根据当前页面的值current 和 数组中的key对比 拿到返回值 数据结构如下 之前写法 const clickedItem routeList.find(item > item.key current) // current是当前页 用reduce遍历数组返回最后一个值 const clickedItem routeList.reduce((lastIte…...
Github Action Bot 开发教程
Github Action Bot 开发教程 在使用 Github 时,你可能在一些著名的开源项目,例如 Kubernetes,Istio 中看到如下的一些评论: /lgtm /retest /area bug /assign xxxx ...等等,诸如此类的一些功能性评论。在这些评论出现…...
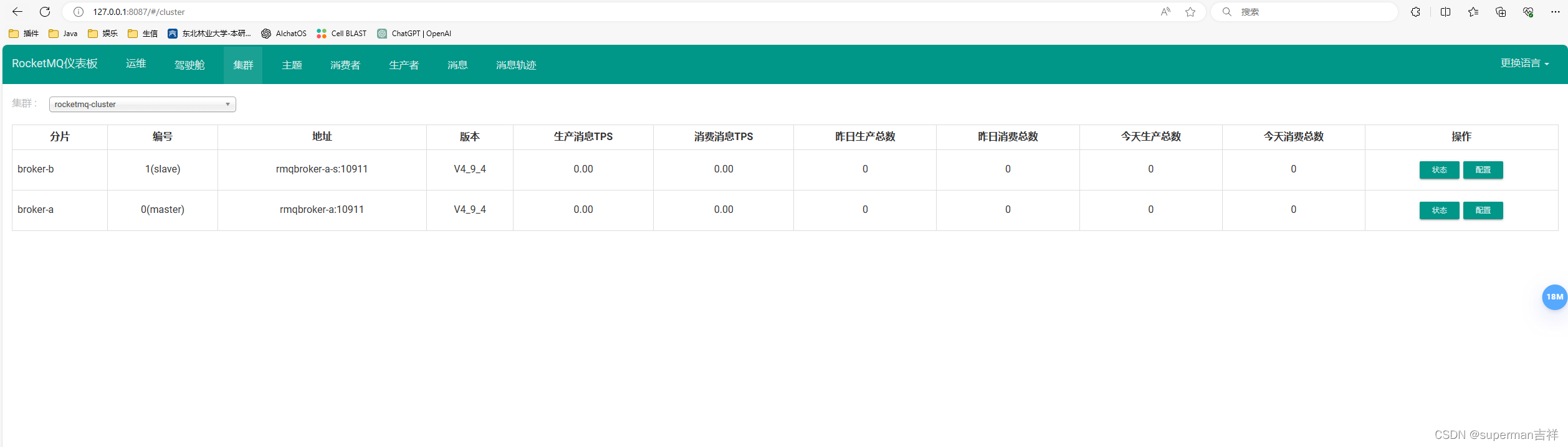
使用docker创建rocketMQ主从结构,使用
1、 创建目录 mkdir -p /docker/rocketmq/logs/nameserver-a mkdir -p /docker/rocketmq/logs/nameserver-b mkdir -p /docker/rocketmq/logs/broker-a mkdir -p /docker/rocketmq/logs/broker-b mkdir -p /docker/rocketmq/store/broker-a mkdir -p /docker/rocketmq/store/b…...

一次完整的 http 请求是怎样的?
一次完整的 http 请求是怎样的? 💖The Begin💖点点关注,收藏不迷路💖 域名解析 --> 发起 TCP 的 3 次握手 --> 建立 TCP 连接后发起 http 请求 --> 服务器响应 http 请求,浏览器得到 html 代码 --…...
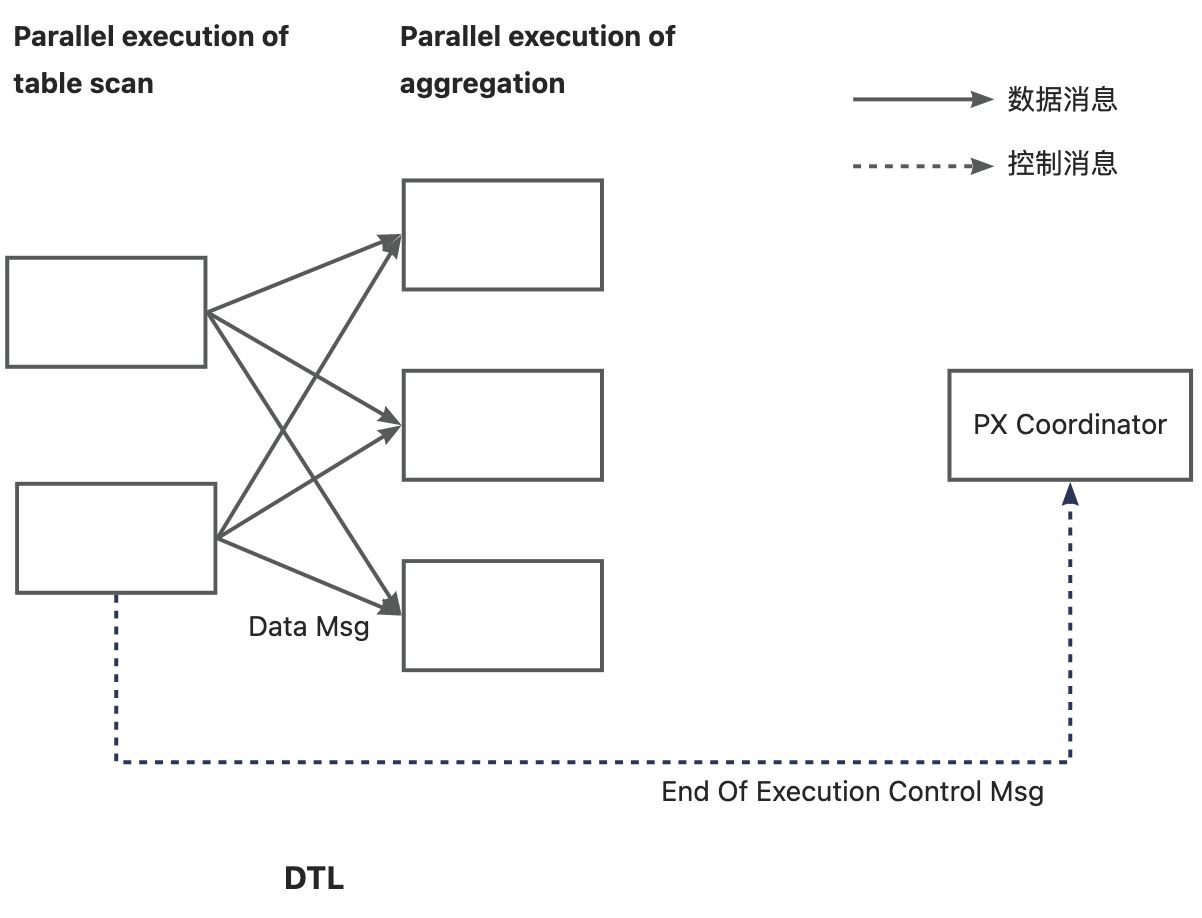
并行执行的概念—— 《OceanBase 并行执行》系列 一
From 产品经理: 这是一份姗姗来迟的关于OceanBase并行执行的系统化产品文档。 自2019年起,并行执行功能已被许多客户应用于多种场景之中,其重要性日益凸显。然而,遗憾的是,我们始终未能提供一份详尽的用户使用文档&…...

使用 ipdb 调试回调函数
一、问题概述 回调函数是指一个函数执行完后,调用另外一个函数的过程。 一般步骤是,回调函数作为参数传递给原始函数,原始函数执行完自己的逻辑后,自动调用回调函数并将自己的执行结果作为参数传递给回调函数。 根据不同的用法&a…...
)
介绍一下mybatis的基本配置(mybatis-config.xml)
src/main/resources/mybatis-config.xml 这句代码,是XML的声明,它指定了,XML的版本 和 编码方式 <?xml version"1.0" encoding"UTF-8" ?>这句代码,声明了XML文档类型,它告诉解析器&#x…...
【MySQL】第一次作业
【MySQL】第一次作业 1、在官网下载安装包2、解压安装包,创建一个dev_soft文件夹,解压到里面。3、创建一个数据库db_classes4、创建一行表db_hero5、将四大名著中的常见人物插入这个英雄表 写一篇博客,在window系统安装MySQL将本机的MySQL一定…...

10个免费视频素材网站,剪辑师们赶紧收藏!
剪辑师们不知道去哪里找免费视频素材,就上这10个网站,免费下载部分还可商用,赶紧收藏起来! 1、菜鸟图库 https://www.sucai999.com/video.html?vNTYwNDUx 菜鸟图库虽然是个设计素材网站,但除了设计类素材之外还有很多…...
【毕业设计】基于SSM的运动用品商城的设计与实现
1.项目介绍 在这个日益数字化和信息化的时代,随着人们购物习惯的转变,传统的实体商店已经无法满足人们日益增长的在线购物需求。因此,基于SSM(Spring Spring MVC MyBatis)框架的运动用品商城项目应运而生࿰…...
【Web】CTFSHOW 中期测评刷题记录(1)
目录 web486 web487 web488 web489 web490 web491 web492 web493 web494 web495 web496 web497 web498 web499 web500 web501 web502 web503 web505 web506 web507 web508 web509 web510 web486 扫目录 初始界面尝试文件包含index.php&am…...
vs配置cplex12.10
1.创建c空项目 2.修改运行环境 为release以及x64 3.创建cpp文件 4.鼠标右键点击项目中的属性 5.点击c/c,点击第一项常规,配置附加库目录 5.添加文件索引,主要用于把路径导进来 6.这一步要添加的目录与你安装的cplex的目录有关系 F:\program…...
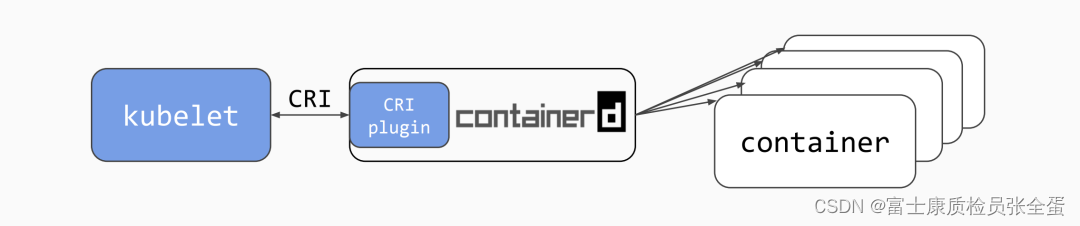
Kubernetes 弃用Docker后 Kubelet切换到Containerd
containerd 是一个高级容器运行时,又名 容器管理器。简单来说,它是一个守护进程,在单个主机上管理完整的容器生命周期:创建、启动、停止容器、拉取和存储镜像、配置挂载、网络等。 containerd 旨在轻松嵌入到更大的系统中。Docke…...

函数模板含有多个模板参数
如果一个模板接受多个参数,用逗号分隔参数。 使用时必要情况下需要主动传入模板参数。 #include <iostream> #include <vector>/* Compute the greatest common divisor of two integers, using Euclids algorithm. */ template<class T, class U&g…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...