【intro】图卷积神经网络(GCN)
本文为Graph Neural Networks(GNN)学习笔记-CSDN博客后续,内容为GCN论文阅读,相关博客阅读,kaggle上相关的数据集/文章/代码的阅读三部分,考虑到本人是GNN新手,会先从相关博客开始,进一步看kaggle,最后阅读论文。
引入
GNN缘起
1. CNN的缺陷
CNN的核心特点在于局部连接(local connection),权重共享(shared weights)和多层叠加(multi-layer)。(之前在李沐老师的课上也提到过,之所以可以权重共享,是因为用的卷积核是一样的,虽然听起来有点抽象,但是换个角度直接想边缘检测的canny算子,按x y方向分别的检测,每个方向上都使用同一个,局部连接我猜作者在这里的意思是没办法连接整张图?多层叠加的话,这个很正常吧,哪怕只是普通的DNN也是多层的呀)
传统的方法被应用在提取欧氏空间数据特征,但是很多实际用用场景中的数据是从非欧式空间中获得的,此时传统的深度学习方法就有点不够用了。
在前面关于GNN的介绍中,提到图片可以被表示在图中,每个像素作为顶点,邻接的像素就连一条边,但是CNN对于更为一般性的图结构可能就不那么好用了。(我贫瘠的想想出现了比如两张图片,虽然拍的是同样的东西,而且也都是平面图,但是怎么表示其中相对应点点关系呢?之前的诸如关键点检测的方法超神奇,那么图是否会给出新的答案捏?期待看完之后我能得到一个答案)
2. 图嵌入的缺陷
图嵌入大致可以分为三类:矩阵分解、随机游走、深度学习
作者在这里提到的图嵌入的常见模型(DeepWalk、Node2Vec)我都没听过,所以看过再更新这里。
3. GNN的优点
1)节点
对于图结构,没有天然的顺序(CNN和RNN都需要一定的顺序,图片肯定是按照一定顺序排列的像素,自然语言也肯定是有顺序的),因此GNN采用再每个节点上分别传播的方式进行学习,忽略节点的顺序,正因如此输出会随着输入的不同而不同。
2)边
可以通过图结构进行传播,而不是仅仅将其作为节点特征的一部分。
4. GNN的局限性
1)对不动点使用迭代方法来更新节点的隐藏状态,效率不高
2)原始的GNN在迭代中使用相同的参数,其他比较著名的模型在不同的网络层采用不同的参数进行分层特征提取,使得模型能够学到更加深的特征表达。
3)一些边上保存的某些信息可能不能被有效的考虑进去(如知识图中的边具有关系类型,并且通过不同边的消息传播应根据其类型而不同)。且如何学习边的隐藏状态也是一个重要问题。
4)如果我们需要学习节点的向量表示而不是图的表示,则不适合使用固定点,因为固定点中的表示分布将在值上非常平滑并且用于区分每个节点的信息量较少。
(大部分都没看懂,期待后期看完后补充)
5. framework
在一个图结构中,每个节点由自身的特征以及与其相连的节点特征来定义该节点。
(不确定这样理解对不对,比如我们现在想推送广告给A,已知A关注了B、C、D,其中C、D和A互关,C点开了广告a,D点开了广告b,是否可以合理猜测A大概率也会想看广告ab呢?)
GNN的目的就是为每一个节点学习到一个状态嵌入向量,这个向量包含每个节点的邻居节点的信息,
表示该节点的状态向量,这个向量可以用于产生输出
。
按照这篇文章前面的定义,表示顶点v的隐藏状态,
表示的是顶点v的输出。
指的应该是s-欧几里得空间(但是这里有个疑问,之前说图可以解决非欧式空间的问题,这里属于欧式空间不就没啥特殊了吗?所以这个定义存疑)
这里f是局部转移函数(local transition function),在所有节点中共享,根据邻居节点的输入来更新节点状态。
g为局部输出函数(local output function),用于描述输出的产生方式。
表示节点v 的特征向量,
表示与节点v关联的边的特征向量(不清楚是否按照图论中incident的定义),
表示节点v的邻居节点的状态向量,
表示节点v的邻居节点的特征向量。(浅总结一下,一共有两种向量:特征向量和状态向量。其中特征向量主要有三个来源:节点v自己,与节点v相连的边,节点v的邻居,状态向量仅仅来源于邻居节点。这里有个小问题,为什么只有邻居节点需要提供状态向量?)
现在,离开局部模式,进入all叠加模式:
小结:和前面关于GNN的intro感觉差不太多捏。需要关注的点是两种向量分别储存的是什么信息,是同等重要吗?是类似图片不同的通道可以独立考虑,还是类似NLP里面对于同一段文字的不同的embedding,某一个embedding可能决定其他embedding的重要程度,这都是希望后面可以回答的问题。
GCN是做什么的
GCN是一种能够直接作用于图并利用其结构信息的卷积神经网络,这一思想是又图像领域迁移到图领域的。
GCN设计了一种从图数据中提取特征的方法,让我们可以使用这些特征对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding)。
对于图数据,一般常见的任务类型:
节点分类(node classification):给定一个节点,预测其类型(比如之前那个教练分开,判断学员会跟哪个的)
边预测(link prediction):预测两个节点之间是否存在连接(可能类似于猜你喜欢?)
网络相似度(network similarity):衡量两个网络或者子网络之间的相似性。
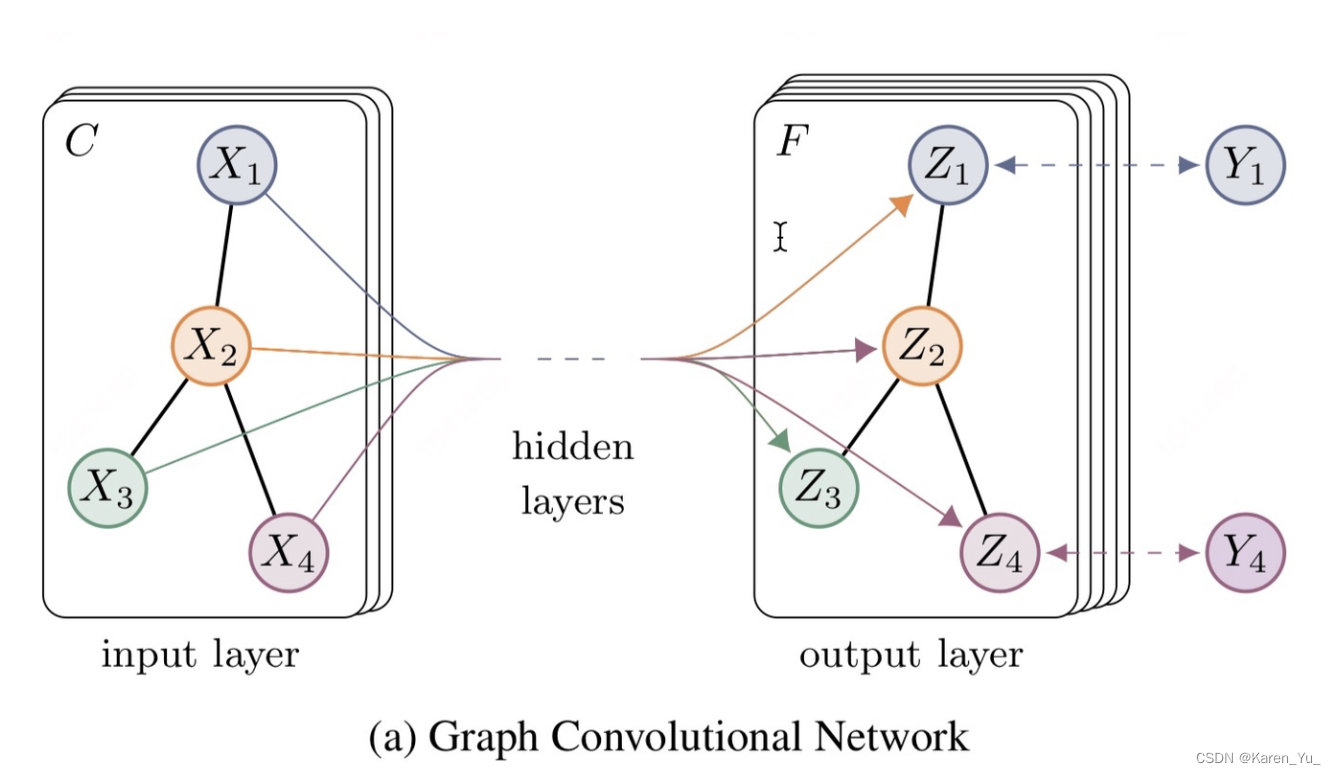
一个拥有C个input channel的graph作为输入,经过中间的hidden layers,得到F个output channel的输出。
->输入一个图,通过若干层GCN每个node特征都从X变成了Z,这里无论中间的hidden layers有多少层,node之间的连接关系都是共享的(但是不一定层数越多越好)。
应用举例:
graph convolutional network有什么比较好的应用task? - 知乎
1. 空手道俱乐部网络(社交网络)
2. 蛋白质交互网络(生物学)
3. 论文引用网络(用户画像)
⬆️本身就是图结构
⬇️本身不是图结构,但是可以构建图结构
比如图片
有一个举例是说可以做人脸聚类,正巧在论文中也提到了,即使不训练、完全使用随机初始化的参数w,GCN提取出来的特征就已经很棒了。这一点与CNN就完全不一样了(相比之下CNN如果完全只使用初始化的参数,那么出来的就很emmm随机)。论文中举例的是俱乐部会员关系聚类,在原数据中同类别的node,经过GCN提取出来的embedding,就已经在空间上自动聚类了,相比之前的DeepWalk、node2vec这种需要复杂训练才能得到的node embedding也没差到哪去。
为什么要用GCN
文章在这里指出CNN的核心在于kernel,通过在图片上滑动一个小窗口计算卷积的方式来提取特征,关键在于图片结构上的平移不变性(小窗口移动到图片的任何位置,其内部结构都是不变的)->参数共享
RNN的对象是自然语言,属于序列信息(一维),通过各种门的操作,使得序列前后的信息互相影响,今儿捕捉序列特征。
以上都属于欧式空间数据。欧式空间的数据结构很规则,但是在现实生活中,还存在很多不规则的数据结构,比如图结构(亦称拓扑结构),比如社交网络、活血分子结构、知识图谱。图结构一般来说十分不规则,可以认为是无限维的一种数据->没有平移不变性。每个节点中为的结构都可能是独一无二的,因此传统的CNN、RNN方法就派不上什么用场了。
为了解决这一问题就提出了很多方法,如DeepWalk,node2vec等(按照上面的文章的介绍,这两个都并非GNN方法),GCN是解决的方案之一。
GCN,图卷积神经网络,与CNN类似,也相当于是一个特征提取器,只不过对象是图。
GCN数学基础
卷积
如何通俗易懂地解释卷积? - 知乎
一般定义函数和
的卷积
如下:
连续形式:
离散形式:
先对g函数进行翻转,在把g函数平移到n,在这个位置对两个函数的对应点相乘,然后相加(注意这里的卷积与CNN的卷积其实是不相同的,CNN中的卷积可以理解为加权求和)
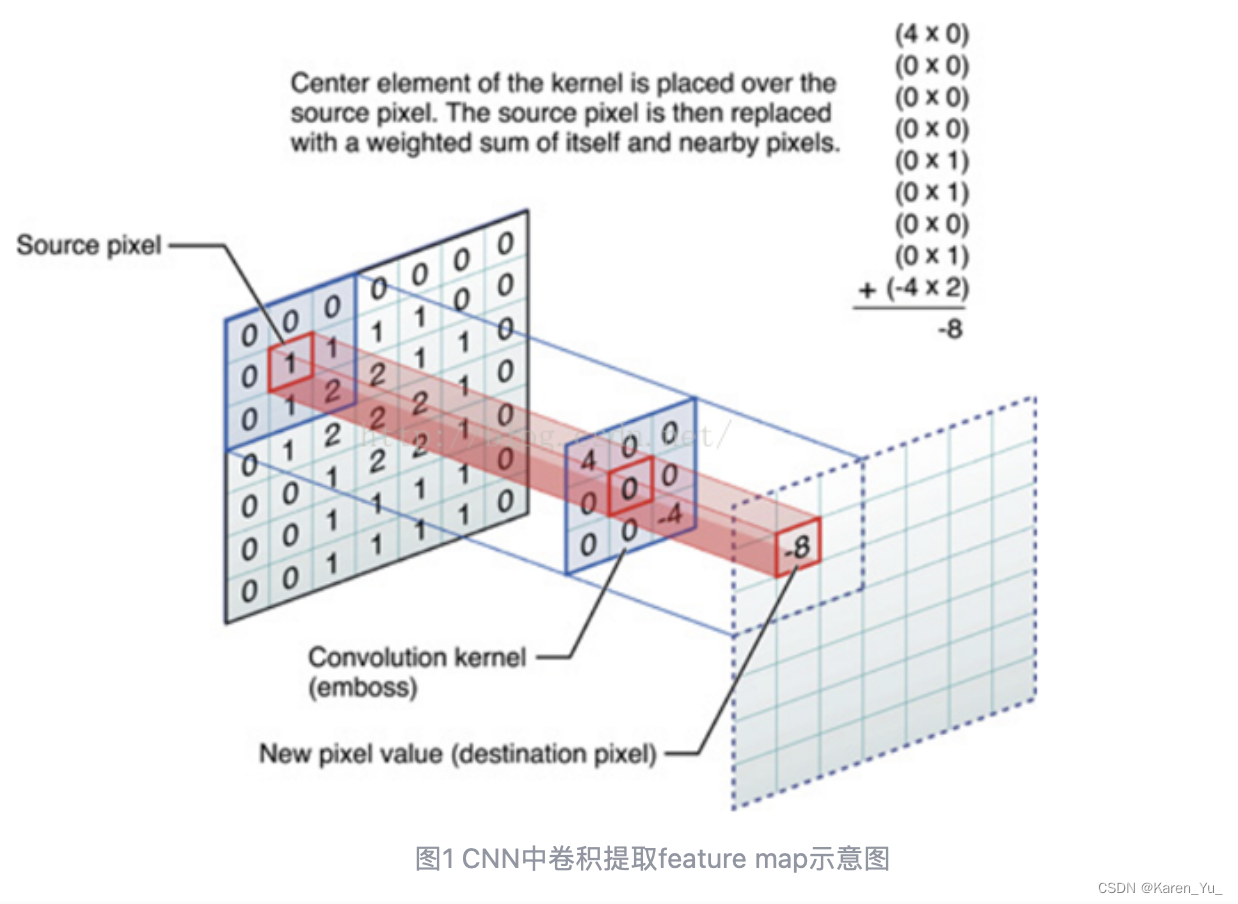
在CNN中。首先随机出实话卷积核的系数,根据误差函数反向传播梯度下降迭代优化->实现特征提取->引入GCN中,可优化的卷积参数
Laplacian矩阵
对于图G=(V,E),其laplacian矩阵的定义为L=D-A,L是laplacian矩阵,D是顶点的度矩阵(对角矩阵),矩阵对角线上的元素依次为各个顶点的度,A是图的邻接矩阵。
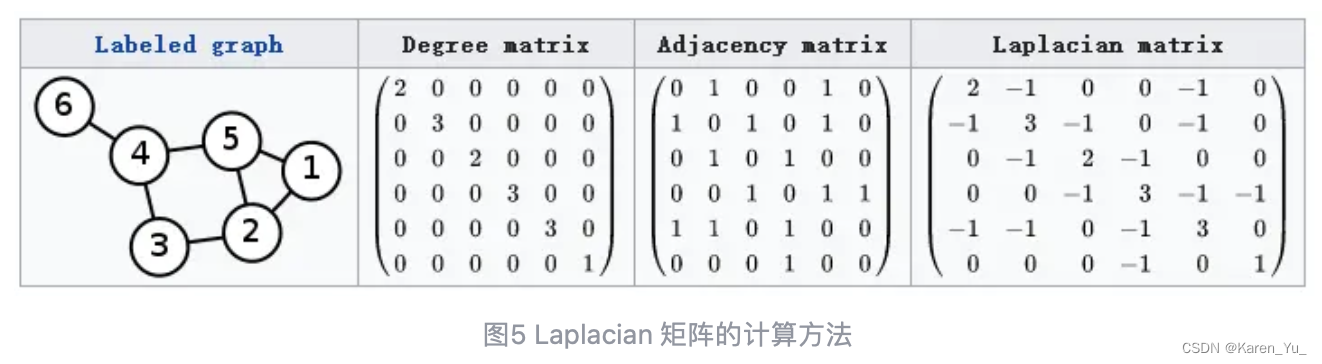
这种laplacian矩阵称为combinatorial laplacian。很多GCN论文中应用更多的是symmetric normalized laplacian,定义为
为什么要使用拉普拉斯矩阵呢?
1. 拉普拉斯矩阵是对称矩阵,可以进行特征分解(谱分解),这与GCN的spectral domain对应。
2. 拉普拉斯矩阵只在中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0
3. 通过拉普拉斯算子与拉普拉斯矩阵进行类比
laplacian矩阵的谱分解(特征分解)
首先是概念:矩阵的谱分解、特征分解、对角化都是同一个概念。
- 线性代数相关知识回顾
特征值&特征向量
设A是一个n阶矩阵,如果存在一个数
及非零的n维列向量
,使得
成立,则称
- 正定矩阵&半正定矩阵
A是n阶方阵,如果对任何非零向量x,都有
,其中
表示x的专职,就称A为正定矩阵。
A是实对称阵,如果对任意的实非零列向量x有
,称A为半正定矩阵。
- 特征分解
并非所有矩阵都可以特征分解<=n阶方阵+存在n个线性无关的特征向量
A的所有特征值的全体叫做A的谱,记作
。
注意:特征向量不能由特征值唯一确定,反之,不同特征值对应的特征向量不会相等,即一个特征向量只能属于一个特征值。
假设矩阵A有n个线性无关的特征向量
,对应着的特征值
,我们将特征向量组成一个矩阵(矩阵中的每一列是一个特征向量:
类似的,我们也可以将特征值组成一个对角阵:
因此A的特征分解(eigen decomposition)可以记作:
实对称阵一定可以形似对角化
相似对角化:一个矩阵与一个对角阵相似,一个n阶矩阵可相似对角化的充要条件是:有n个线性无关的特征向量
实对称阵的不同特征值的特征向量正交
实对称阵一定有n个线性无关的特征向量
半正定矩阵的特征值一定非负
实对称矩阵的特征向量总是可以化成两辆相互正交的正交矩阵
->拉普拉斯矩阵一定可以谱分解,且分解胡有特殊的形式
其中,,是列向量为单位特征向量的矩阵。
是n个特征值构成的对角阵。由于U是正交矩阵,
,E是单位阵。因此还可以写作:
傅立叶变换
傅立叶变换/卷积
傅里叶变换概念及公式推导-CSDN博客
傅里叶变换(Fourier Transform)——附详细推导傅里叶变换和傅里叶级数关系和区别 - 知乎
对于任意时域的信号,其傅立叶变换(Fourier transform)到频域为:
同样,对于已知频域信号,其对应的傅立叶逆变换(inverse Fourier transform)到时域为:
深入理解傅里叶变换
推广傅立叶变换
把传统的傅立叶变换以及卷积迁移到graph上的核心工作是把拉普拉斯算子的特征函数变为graph对应的拉普拉斯矩阵的特征向量。
在前面的补充内容中,对于特征方程的定义为:,其中A是一种变换,V是特征向量/特征函数,
是特征值。那么相应的,对于特征函数
,有:
代表的就是V,
是变换A,
就是
离散拉普拉斯算子与LOG推导_离散的拉普拉斯算子-CSDN博客
相对应的:
这里L表示的局势拉普拉斯矩阵(其实就相当于一种变换)


为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基
GCN
图中的每个结点无时无刻不因为邻居和更远的点的影响而在改变着自己的状态直到最终的平衡,关系越亲近的邻居影响越大。
在图中,我们不仅有节点的特征(节点的数据),还有图的结构(节点之间是如何进行连接的)。将节点的特征与图的结构信息同事作为输入,让机器自己去决定到底使用哪些信息。GCN是一种能够直接作用于图,并且利用其结构信息的卷积神经网络。
假设我们现在有一批图数据,其中与N个节点(node),每个节点都有自己的特征,let这些节点的特征组成一个NxD维的矩阵X,各个节点之间的关系形成一个NxN的矩阵A(邻接矩阵),X和A是我们模型的输入。
GCN层与层之间的传播方式是:
其中,
是单位矩阵
是
的度矩阵(degree matrix),
是每一层的特征,对于输入层,H就是X(节点特征,NxD维矩阵)
是非线性激活函数
回顾:
- 邻接矩阵:
表示顶点之间相邻关系的矩阵(是n阶方阵)。
它是利用矩阵的二维结构,使其中的一维代表其中一个端点,另一维代表另一个端点。
(在有向图中,是一维表示起点,一维表示终点)
- 度矩阵:度矩阵是对角阵,对角上的元素为各个顶点的度。顶点vi的度表示和该顶点相关联的边的数量。无向图中顶点vi的度d(vi)=N(i)。
度矩阵&邻接矩阵:
- 拉普拉斯矩阵
标准拉普拉斯矩阵(是对称阵)的形式为:
->对角线上的取值为节点的度,若节点i和节点j相邻,取值为-1
归一化拉普拉斯矩阵
常见的形式:
这里A表示邻接矩阵,若在邻接矩阵中加入环,即
,矩阵形式可以表示为
->怎么通过邻接矩阵&度矩阵得到拉普拉斯矩阵
图的一些基本知识:图,邻居,度矩阵,邻接矩阵-CSDN博客
数据结构图的邻接矩阵、关联矩阵、度矩阵还有权重矩阵的区别和联系是什么呀? - 知乎
https://www.cnblogs.com/BlairGrowing/p/15658878.html
GNN入门之路: 01.图拉普拉斯矩阵的定义、推导、性质、应用 - 知乎


GCN层与层之间的传播方式是:
这一部分当然就可以提前算出来了

假设我们构造一个两层的GCN,激活函数分别采用ReLU和Softmax,那么整体的正向传播公式为:
这里表示邻接矩阵(size= NxN,有N个节点),
是特征向量矩阵(size=NxC),
分别代表可以训练的参数(size=CxH, HxF)->NxF
针对所有带标签的节点计算cross entropy损失函数:
这样就可以训练一个node classification 模型了由于即使只有很少的标签也可以训练,作者称该方法为半监督分类。
Graph Convolutional Networks | Thomas Kipf | Google DeepMind
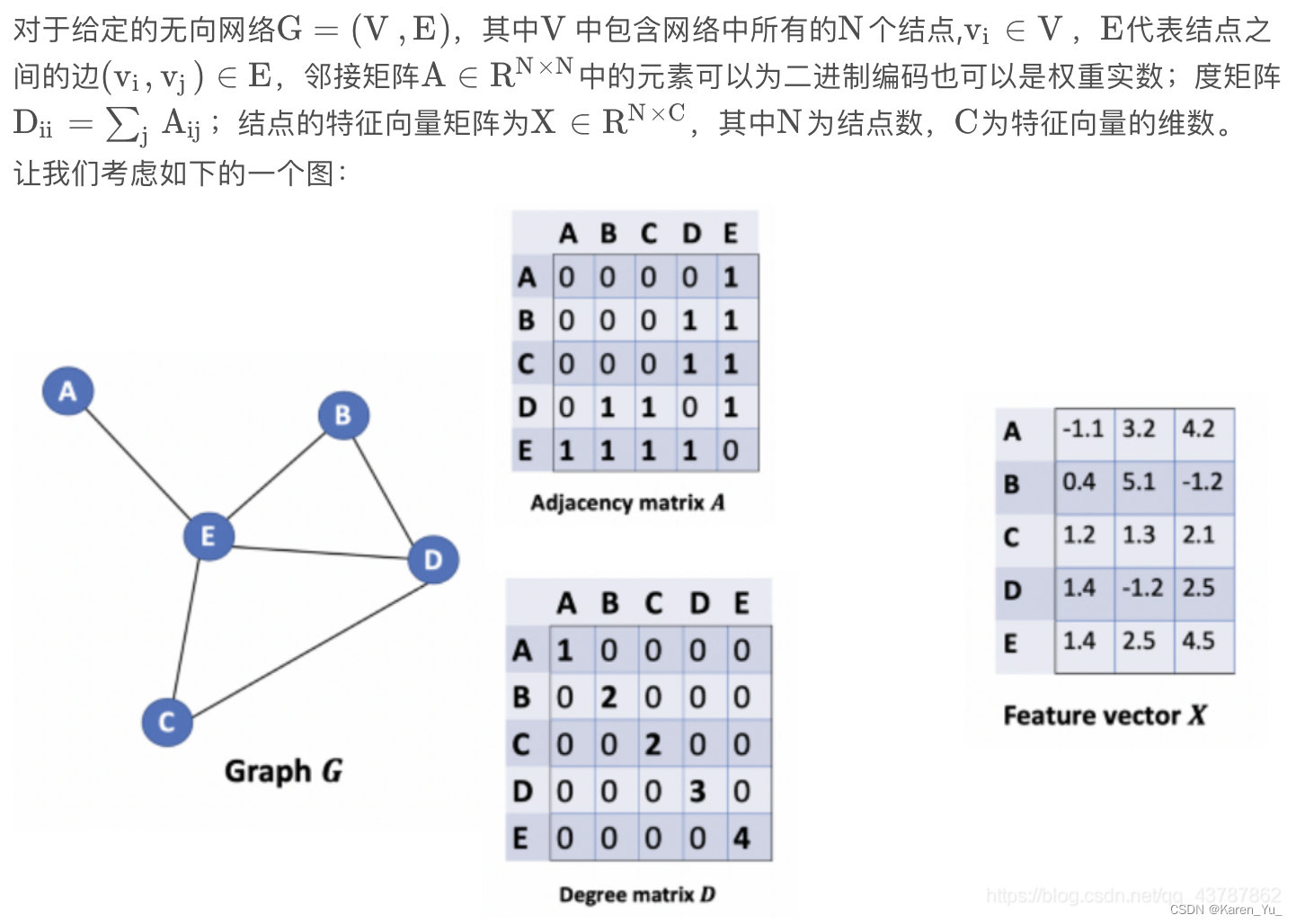
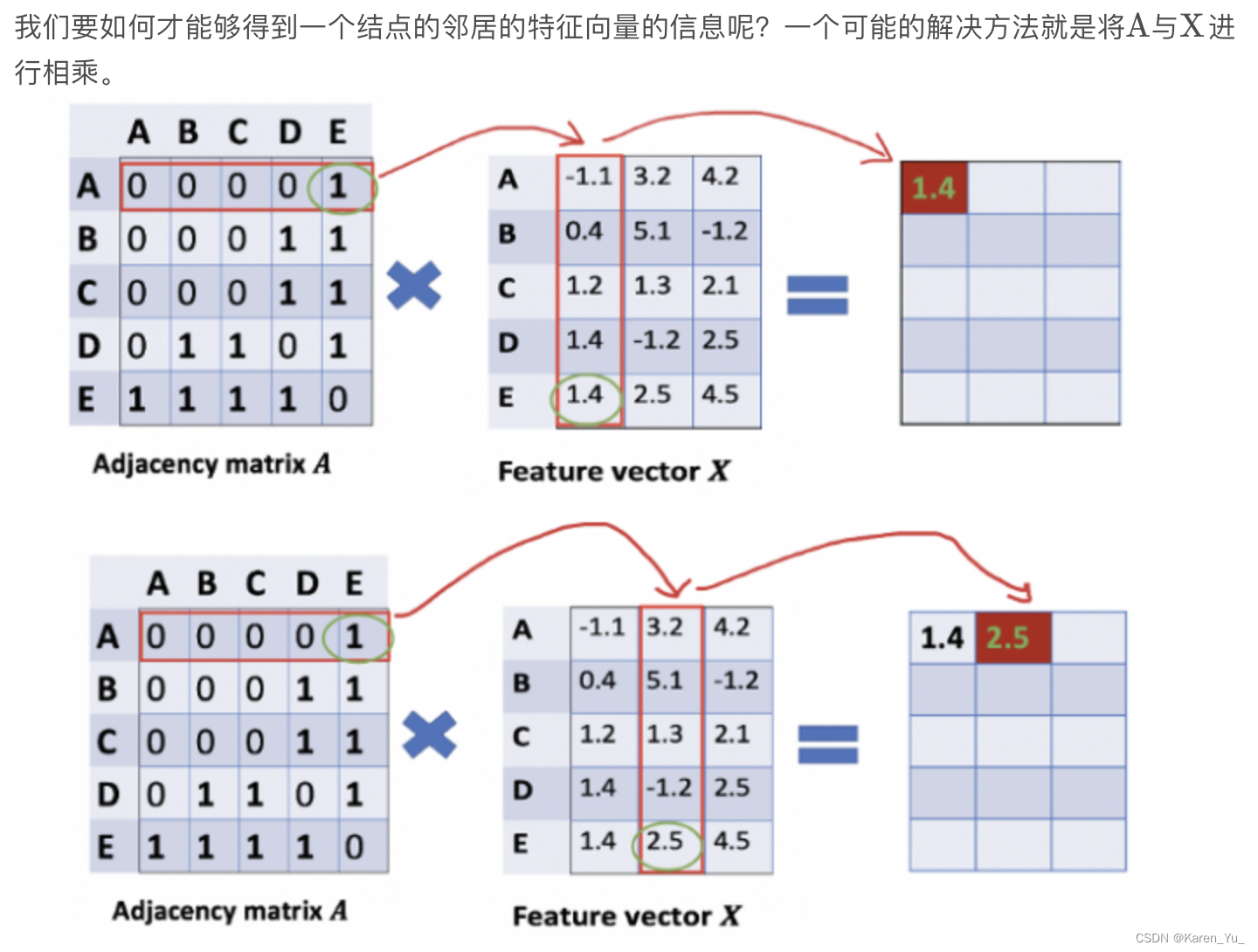
看起来像每个节点的向量的长度为3,对于向量中的每个值都分别看其连接情况。但是如果仅仅这样的话,理论上我们A节点的值应该也挂在A节点的信息里,但是显然,这里由于没有自环,所以A节点反而只有E节点的信息(哦~所以才要加上单位阵构造一个自环出来)
注意:
网络的层数代表着结点特征所能到达的最远距离。比如一层的GCN,每个结点只能得到其一阶邻居身上的信息。对于所有结点来说,信息获取的过程是独立、同时开展的。当我们在一层GCN上再堆一层时,就可以重复收集邻居信息的过程,并且收集到的邻居信息中已经包含了这些邻居结点在上一个阶段所收集的他们的邻居结点的信息。这就使得GCN的网络层数也就是每个结点的信息所能达到的maximum number of hops。因此,我们所设定的层的数目取决于我们想要使得结点的信息在网络中传递多远的距离。需要注意的是,通常我们不会需要结点的信息传播太远。经过6~7个hops,基本上就可以使结点的信息传播到整个网络,这也使得聚合不那么有意义。
Reference
何时能懂你的心——图卷积神经网络(GCN) - 知乎
如何理解 Graph Convolutional Network(GCN)? - 知乎
图神经网络(GNN)模型原理及应用综述-CSDN博客
图卷积网络(GCN)入门详解 - 知乎
图卷积网络(Graph Convolutional Networks, GCN)详细介绍-CSDN博客
Graph Convolutional Networks (GCN)
【Graph Neural Network】GCN: 算法原理,实现和应用 - 知乎
OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction
描述
研究人员观察到RNA分子有自发降解的倾向。这是一个严重的限制——一次切割就可以使mRNA疫苗失效。目前,对于特定RNA的主干中最容易受到影响的位置的细节知之甚少。如果不了解这一点,目前针对COVID-19的mRNA疫苗必须在高度冷藏的条件下制备和运输,除非能够稳定,否则不太可能到达地球上一小部分人的手中。
传统疫苗(比如季节性流感疫苗)包装在一次性注射器中,冷藏后运往世界各地,但mRNA疫苗目前还不可能做到这一点。->如何设计超级稳定的信使RNA分子(mRNA)。
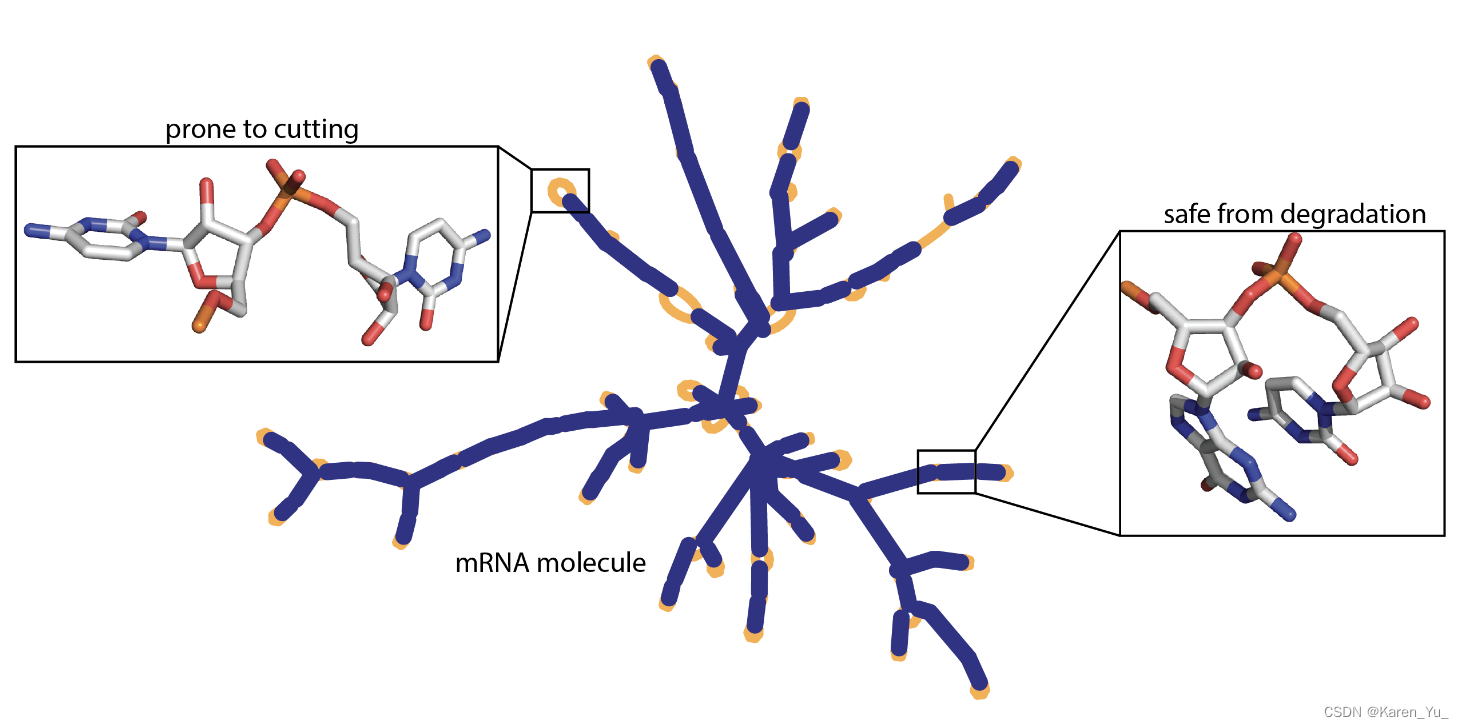
利用Kaggle社区的数据科学专业知识来开发RNA降解的模型和设计规则。设计模型预测RNA分子每个碱基的可能降解率,在Eterna数据集的子集上进行训练,该数据集包含3000多个RNA分子(跨越一系列序列和结构)以及它们在每个位置的降解率。
评估
采用MCRMSE
其中表示评分的ground truth的数量,
和
分别为真实值和预测值
数据集介绍
数据集:
- train.json - the training data
- test.json - the test set, without any columns associated with the ground truth.
数据介绍:
id- 每个sample对应的随机标识符seq_scored- (68 in Train and Public Test, 91 in Private Test)int,表示使用预测值进行评分时所使用的位置数。这应该与reactivity、deg_*和*_error_*列的长度相匹配。用于Private Test的分子将比Train和Public Test数据中的分子长,因此此向量的大小将不同。seq_length- (107 in Train and Public Test, 130 in Private Test) int,表示序列的长度。用于Private Test的分子将比Train和Public Test数据中的分子长,因此此向量的大小将不同。sequence- (1x107 string in Train and Public Test, 130 in Private Test)描述RNA序列,每个样品的a、G、U和C的组合。应该有107个字符长,前68个碱基应该对应于seq_score中指定的68个位置(注意:从0开始索引)。structure- (1x107 string in Train and Public Test, 130 in Private Test) 由“(”,“)”和“.”组成的数组,描述估计碱基是成对还是未成对的字符。成对的碱基由左括号和右括号表示,例如(....)表示碱基0与碱基5配对,而碱基1-4未配对。(从索引0开始)reactivity- (1x68 vector in Train and Public Test, 1x91 in Private Test) 浮点数数组的长度应该与seq_scores相同。这些数字是按顺序表示的前68个碱基的反应性值,用于确定RNA样品的可能二级结构。deg_pH10- (1x68 vector in Train and Public Test, 1x91 in Private Test) 浮点数数组,数组的长度应该与seq_scores相同。这些数字是按顺序表示的前68个碱基的反应性值,用于确定在高pH (pH 10)下无镁孵育后碱基/键降解的可能性。deg_Mg_pH10- (1x68 vector in Train and Public Test, 1x91 in Private Test)浮点数数组,数组的长度应该与seq_scores相同。这些数字是按顺序表示的前68个碱基的反应性值,用于确定碱基/键在高pH (pH 10)下与镁孵育后降解的可能性。deg_50C- (1x68 vector in Train and Public Test, 1x91 in Private Test) 浮点数数组,数组的长度应该与seq_scores相同。这些数字是按顺序表示的前68个碱基的反应性值,用于确定在高温(50摄氏度)下无镁孵育后碱基/键降解的可能性。deg_Mg_50C- (1x68 vector in Train and Public Test, 1x91 in Private Test) 浮点数数组,数组的长度应该与seq_scores相同。这些数字是按顺序表示的前68个碱基的反应性值,用于确定在高温(50摄氏度)下与镁孵育后碱基/键降解的可能性。*_error_*- 浮点数数组,数组应具有与相应的reactivity或deg_*列相同的长度,在reactivity列和deg_*列中得到的实验值的计算误差。predicted_loop_type- (1x107 string) 描述序列中每个字符的结构上下文(也称为“循环类型”)。由Vienna RNAfold 2 structure的bpRNA分配的环路类型。由bpRNA_documentation: S: paired "Stem" M: Multiloop I: Internal loop B: Bulge H: Hairpin loop E: dangling End X: eXternal loopS/N filterIndicates if the sample passed filters described below inAdditional Notes.
数据展示
[COVID-19 mRNA] 4th place solution | Kaggle
train = pd.read_json("../input/stanford-covid-vaccine/train.json",lines=True)
test = pd.read_json("../input/stanford-covid-vaccine/test.json",lines=True)
sub = pd.read_csv("../input/stanford-covid-vaccine/sample_submission.csv")test_pub = test[test["seq_length"] == 107]
test_pri = test[test["seq_length"] == 130]train.head(5)| index | id | sequence | structure | predicted_loop_type | signal_to_noise | SN_filter | seq_length | seq_scored | reactivity_error | deg_error_Mg_pH10 | deg_error_pH10 | deg_error_Mg_50C | deg_error_50C | reactivity | deg_Mg_pH10 | deg_pH10 | deg_Mg_50C | deg_50C |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | id_001f94081 | GGAAAAGCUCUAAUAACAGGAGACUAGGACUACGUAUUUCUAGGUA... | .....((((((.......)))).)).((.....((..((((((...... | EEEEESSSSSSHHHHHHHSSSSBSSXSSIIIIISSIISSSSSSHHH... | 6.894 | 1 | 107 | 68 | [0.1359, 0.20700000000000002, 0.1633, 0.1452, ... | [0.26130000000000003, 0.38420000000000004, 0.1... | [0.2631, 0.28600000000000003, 0.0964, 0.1574, ... | [0.1501, 0.275, 0.0947, 0.18660000000000002, 0... | [0.2167, 0.34750000000000003, 0.188, 0.2124, 0... | [0.3297, 1.5693000000000001, 1.1227, 0.8686, 0... | [0.7556, 2.983, 0.2526, 1.3789, 0.637600000000... | [2.3375, 3.5060000000000002, 0.3008, 1.0108, 0... | [0.35810000000000003, 2.9683, 0.2589, 1.4552, ... | [0.6382, 3.4773, 0.9988, 1.3228, 0.78770000000... |
| 1 | id_0049f53ba | GGAAAAAGCGCGCGCGGUUAGCGCGCGCUUUUGCGCGCGCUGUACC... | .....(((((((((((((((((((((((....)))))))))).)))... | EEEEESSSSSSSSSSSSSSSSSSSSSSSHHHHSSSSSSSSSSBSSS... | 0.193 | 0 | 107 | 68 | [2.8272, 2.8272, 2.8272, 4.7343, 2.5676, 2.567... | [73705.3985, 73705.3985, 73705.3985, 73705.398... | [10.1986, 9.2418, 5.0933, 5.0933, 5.0933, 5.09... | [16.6174, 13.868, 8.1968, 8.1968, 8.1968, 8.19... | [15.4857, 7.9596, 13.3957, 5.8777, 5.8777, 5.8... | [0.0, 0.0, 0.0, 2.2965, 0.0, 0.0, 0.0, 0.0, 0.... | [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ... | [4.947, 4.4523, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ... | [4.8511, 4.0426, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,... | [7.6692, 0.0, 10.9561, 0.0, 0.0, 0.0, 0.0, 0.0... |
| 2 | id_006f36f57 | GGAAAGUGCUCAGAUAAGCUAAGCUCGAAUAGCAAUCGAAUAGAAU... | .....((((.((.....((((.(((.....)))..((((......)... | EEEEESSSSISSIIIIISSSSMSSSHHHHHSSSMMSSSSHHHHHHS... | 8.800 | 1 | 107 | 68 | [0.0931, 0.13290000000000002, 0.11280000000000... | [0.1365, 0.2237, 0.1812, 0.1333, 0.1148, 0.160... | [0.17020000000000002, 0.178, 0.111, 0.091, 0.0... | [0.1033, 0.1464, 0.1126, 0.09620000000000001, ... | [0.14980000000000002, 0.1761, 0.1517, 0.116700... | [0.44820000000000004, 1.4822, 1.1819, 0.743400... | [0.2504, 1.4021, 0.9804, 0.49670000000000003, ... | [2.243, 2.9361, 1.0553, 0.721, 0.6396000000000... | [0.5163, 1.6823000000000001, 1.0426, 0.7902, 0... | [0.9501000000000001, 1.7974999999999999, 1.499... |
| 3 | id_0082d463b | GGAAAAGCGCGCGCGCGCGCGCGAAAAAGCGCGCGCGCGCGCGCGC... | ......((((((((((((((((......))))))))))))))))((... | EEEEEESSSSSSSSSSSSSSSSHHHHHHSSSSSSSSSSSSSSSSSS... | 0.104 | 0 | 107 | 68 | [3.5229, 6.0748, 3.0374, 3.0374, 3.0374, 3.037... | [73705.3985, 73705.3985, 73705.3985, 73705.398... | [11.8007, 12.7566, 5.7733, 5.7733, 5.7733, 5.7... | [121286.7181, 121286.7182, 121286.7181, 121286... | [15.3995, 8.1124, 7.7824, 7.7824, 7.7824, 7.78... | [0.0, 2.2399, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.... | [0.0, -0.5083, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0... | [3.4248, 6.8128, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,... | [0.0, -0.8365, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0... | [7.6692, -1.3223, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0... |
| 4 | id_0087940f4 | GGAAAAUAUAUAAUAUAUUAUAUAAAUAUAUUAUAGAAGUAUAAUA... | .....(((((((.((((((((((((.(((((((((....)))))))... | EEEEESSSSSSSBSSSSSSSSSSSSBSSSSSSSSSHHHHSSSSSSS... | 0.423 | 0 | 107 | 68 | [1.665, 2.1728, 2.0041, 1.2405, 0.620200000000... | [4.2139, 3.9637000000000002, 3.2467, 2.4716, 1... | [3.0942, 3.015, 2.1212, 2.0552, 0.881500000000... | [2.6717, 2.4818, 1.9919, 2.5484999999999998, 1... | [1.3285, 3.6173, 1.3057, 1.3021, 1.1507, 1.150... | [0.8267, 2.6577, 2.8481, 0.40090000000000003, ... | [2.1058, 3.138, 2.5437000000000003, 1.0932, 0.... | [4.7366, 4.6243, 1.2068, 1.1538, 0.0, 0.0, 0.7... | [2.2052, 1.7947000000000002, 0.7457, 3.1233, 0... | [0.0, 5.1198, -0.3551, -0.3518, 0.0, 0.0, 0.0,... |
OpenVaccine - GCN | Kaggle
!conda install -y -c bioconda forgi
!conda install -y -c bioconda viennarnaimport forgi.graph.bulge_graph as fgb
import forgi.visual.mplotlib as fvm
import forgi.threedee.utilities.vector as ftuv
import forgiimport RNAimport matplotlib.pyplot as pltidx = 0
id_= train.iloc[idx].id
sequence = train.iloc[idx].sequence
structure = train.iloc[idx].structure
loops= train.iloc[idx].predicted_loop_type
reactivity = train.iloc[idx].reactivity
bg = fgb.BulgeGraph.from_fasta_text(f'>rna1\n{structure}\n{sequence}')[0]
fig = plt.figure(figsize=(6, 6))fvm.plot_rna(bg, lighten=0.5, text_kwargs={"fontweight":None})
plt.show()
怎么构建邻接矩阵
参考OpenVaccine: GCN (GraphSAGE)+GRU+KFold | Kaggle
这个notebook中是从数据中抽取5列
pred_cols = ['reactivity', 'deg_Mg_pH10', 'deg_pH10', 'deg_Mg_50C', 'deg_50C']# 字符用数字替代
# 字典,字符:对应的位置
token2int = {x:i for i, x in enumerate('().ACGUBEHIMSX')}def get_couples(structure):"""For each closing parenthesis, I find the matching opening one and store their index in the couples list.The assigned list is used to keep track of the assigned opening parenthesis"""# 记录括号的位置,检查是否匹配上opened = [idx for idx, i in enumerate(structure) if i == '(']closed = [idx for idx, i in enumerate(structure) if i == ')']assert len(opened) == len(closed)assigned = []couples = []# 对于每个右括号,匹配其对应的左括号(左括号的位置在右括号前面?)for close_idx in closed:for open_idx in opened:# 如果左括号出现在右括号前面if open_idx < close_idx:# 如果左括号没有出现过(没有完成匹配),那么这个左括号就是待匹配的if open_idx not in assigned:candidate = open_idx# 如果右括号提前出线(那就不对了)else:break# 安排匹配assigned.append(candidate)# 匹配上了,按照左右括号的index存储couples.append([candidate, close_idx])assert len(couples) == len(opened)# 返回左右括号的位置(匹配上的)return couplesdef build_matrix(couples, size):# 构建矩阵,按照制定size,构建size x size方阵mat = np.zeros((size, size))# 连接相邻节点for i in range(size): # neigbouring bases are linked as wellif i < size - 1:mat[i, i + 1] = 1if i > 0:mat[i, i - 1] = 1# 如果匹配上了(左右括号),置1(是无向图呢)for i, j in couples:mat[i, j] = 1mat[j, i] = 1return matdef convert_to_adj(structure):# 首先得到匹配的序号(方便后面把边连上)couples = get_couples(structure)# 得到邻接矩阵mat = build_matrix(couples, len(structure))return matdef preprocess_inputs(df, cols=['sequence', 'structure', 'predicted_loop_type']):# 根据选择的列构建输入,将对应字符embedding# 对于一个正常的三维数据,正常的索引值为(0,1,2),相当于(x,y,z)# 这里(0,2,1)就是交换了索引y和z的位置# 比如现在有一个数字,本来索引所在的位置是[1,2,3],那么调整后就变成了[1,3,2]# 不过这里实际上应该是反常识的,对应的第一个位置是z,一个数的下标是[z,y,x]inputs = np.transpose(np.array(df[cols].applymap(lambda seq: [token2int[x] for x in seq]).values.tolist()),(0, 2, 1))# 根据structure列信息构建邻接矩阵adj_matrix = np.array(df['structure'].apply(convert_to_adj).values.tolist())return inputs, adj_matrix解释一下这里的inputs,首先进行一个简化,现在我们只有三条数据:

将token换成index(int):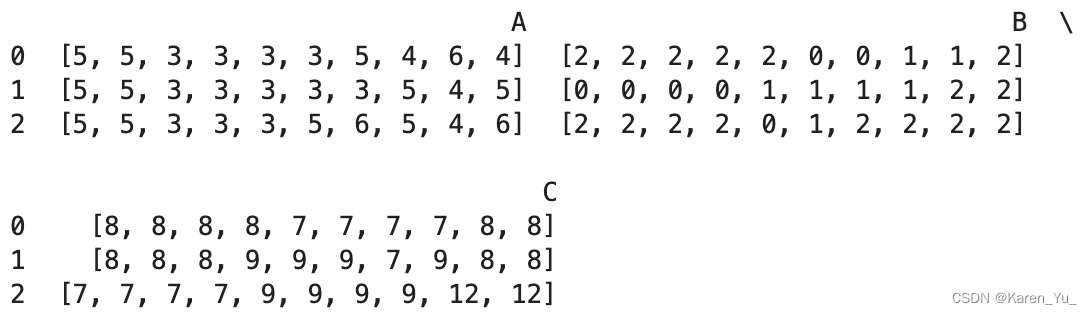
变成list:
[[[5, 5, 3, 3, 3, 3, 5, 4, 6, 4], [2, 2, 2, 2, 2, 0, 0, 1, 1, 2], [8, 8, 8, 8, 7, 7, 7, 7, 8, 8]], [[5, 5, 3, 3, 3, 3, 3, 5, 4, 5], [0, 0, 0, 0, 1, 1, 1, 1, 2, 2], [8, 8, 8, 9, 9, 9, 7, 9, 8, 8]], [[5, 5, 3, 3, 3, 5, 6, 5, 4, 6], [2, 2, 2, 2, 0, 1, 2, 2, 2, 2], [7, 7, 7, 7, 9, 9, 9, 9, 12, 12]]]
交换xy维度

可以看到,最开始每条数据都是dataframe的一行,将对应的token embedding,这时候字符串变成了由数字构成的list,将同一条记录的数据放在一起,转置,此时三个column对应位置token embedding一一对应,此时一整列的数据实际上也是一条数据中一列的数据。
构建网络
class GCN(nn.Module):'''Implementation of one layer of GraphSAGE'''def __init__(self, input_dim, output_dim, aggregator='mean'):super(GCN, self).__init__()self.aggregator = aggregatorif aggregator == 'mean':linear_input_dim = input_dim * 2elif aggregator == 'conv':linear_input_dim = input_dimelif aggregator == 'pooling':linear_input_dim = input_dim * 2self.linear_pooling = nn.Linear(input_dim, input_dim)elif aggregator == 'lstm':self.lstm_hidden = 128linear_input_dim = input_dim + self.lstm_hidden# torch.nn.LSTM(input_size, hidden_size, num_layers=1)# input_size表示输入维度# hidden_size表示隐层状态 h 的维度,也是LSTM的输出维度# num_layers表示LSTM的堆叠层数。如果有多层LSTM堆叠,前一层最后一个时间步的隐层状态作为后一层的输入。self.lstm_agg = nn.LSTM(input_dim, self.lstm_hidden, num_layers=1, batch_first=True)self.linear_gcn = nn.Linear(in_features=linear_input_dim, out_features=output_dim)def forward(self, input_, adj_matrix):# 如果采用convif self.aggregator == 'conv':# set elements in diagonal of adj matrix to 1 with conv aggregator# idx: 索引,起始值0,结束值adj_matrix最后一个维度的长度,out指定输出张量idx = torch.arange(0, adj_matrix.shape[-1], out=torch.LongTensor())# 在前面的代码中,我们知道idx,idx这个位置是xy# 这里就是给对角线赋值为1,相当于加上一个自环(一个节点肯定与自己相连)adj_matrix[:, idx, idx] = 1# pytorch中默认float32,numpy默认float6adj_matrix = adj_matrix.type(torch.float32)# 在第三个维度上求和,可以参考下面的例子,看一下怎么求和# 因此得到的结果代表对应的某张图中的某个节点与其他节点连接的个数sum_adj = torch.sum(adj_matrix, axis=2)# 如果没有与别的节点相连->赋值为1sum_adj[sum_adj==0] = 1# 如果是mean或者convif self.aggregator == 'mean' or self.aggregator == 'conv':# 计算两个tensor的矩阵乘法,torch.bmm(a,b),tensor a 的size为(b,h,w),# tensor b的size为(b,w,m) 也就是说两个tensor的第一维是相等的,# 然后第一个数组的第三维和第二个数组的第二维度要求一样,# 对于剩下的则不做要求,输出维度 (b,h,m)# https://blog.csdn.net/qq_40178291/article/details/100302375# b,h,w,m,这里的b就是sample的个数,h&w是节点的个数,m是feature的长度feature_agg = torch.bmm(adj_matrix, input_)# 作用:扩展维度,参数表示在哪个地方加一个维度feature_agg = feature_agg / sum_adj.unsqueeze(dim=2)# 如果poolingelif self.aggregator == 'pooling':# 起始就是一个linear层,且输入神经元个数=输出神经元个数feature_pooling = self.linear_pooling(input_)# + sigmoidfeature_agg = torch.sigmoid(feature_pooling)feature_agg = torch.bmm(adj_matrix, feature_agg)feature_agg = feature_agg / sum_adj.unsqueeze(dim=2)# 如果lstmelif self.aggregator == 'lstm':feature_agg = torch.zeros(input_.shape[0], input_.shape[1], self.lstm_hidden).cuda()for i in range(adj_matrix.shape[1]):neighbors = adj_matrix[:, i, :].unsqueeze(2) * input__, hn = self.lstm_agg(neighbors)feature_agg[:, i, :] = torch.squeeze(hn[0], 0)if self.aggregator != 'conv':# 一般torch.cat()是为了把多个tensor进行拼接而存在的# torch.cat(tensors, dim=0, *, out=None) feature_cat = torch.cat((input_, feature_agg), axis=2)else:feature_cat = feature_aggfeature = torch.sigmoid(self.linear_gcn(feature_cat))feature = feature / torch.norm(feature, p=2, dim=2).unsqueeze(dim=2)return featureclass Net(nn.Module):# 开始搭积木# 这里的部分值是根据数据决定的def __init__(self, num_embedding=14, seq_len=107, pred_len=68, dropout=0.5, embed_dim=100, hidden_dim=128, K=1, aggregator='mean'):'''K: number of GCN layersaggregator: type of aggregator function'''super(Net, self).__init__()self.pred_len = pred_lenself.embedding_layer = nn.Embedding(num_embeddings=num_embedding, embedding_dim=embed_dim)self.gcn = nn.ModuleList([GCN(3 * embed_dim, 3 * embed_dim, aggregator=aggregator) for i in range(K)])# https://blog.csdn.net/zdx1996/article/details/123532554# 门控循环单元# bidirectional – If True, becomes a bidirectional GRU. Default: False# num_layers -循环层数。# batch_first -如果为True,则输入和输出张量提供为(batch, seq, feature)而不是(seq, batch, feature)。# GRU相对RNN多了许多权重矩阵,因此需要修改初始化模型参数的函数# https://zhuanlan.zhihu.com/p/473208127self.gru_layer = nn.GRU(input_size=3 * embed_dim, hidden_size=hidden_dim, num_layers=3, batch_first=True, dropout=dropout, bidirectional=True)self.linear_layer = nn.Linear(in_features=2 * hidden_dim, out_features=5)def forward(self, input_, adj_matrix):#embeddingembedding = self.embedding_layer(input_)embedding = torch.reshape(embedding, (-1, embedding.shape[1], embedding.shape[2] * embedding.shape[3]))#gcngcn_feature = embeddingfor gcn_layer in self.gcn:gcn_feature = gcn_layer(gcn_feature, adj_matrix)#grugru_output, gru_hidden = self.gru_layer(gcn_feature)truncated = gru_output[:, :self.pred_len]output = self.linear_layer(truncated)return outputy = torch.tensor([[[1, 2, 3],[4, 5, 6]],[[1, 2, 3],[4, 5, 6]],[[1, 2, 3],[4, 5, 6]]])>> torch.sum(y, dim=0) tensor([[ 3, 6, 9],[12, 15, 18]])>> torch.sum(y, dim=1) tensor([[5, 7, 9],[5, 7, 9],[5, 7, 9]]) 横向拍瘪>> torch.sum(y, dim=2) tensor([[ 6, 15],[ 6, 15],[ 6, 15]]) 纵向拍瘪
稍微解释一下,这里之所以用GRU是因为这个notebook的方法就是:
GCN (GraphSAGE)+GRU+KFold
这里,输出是一个,这里L表示序列长度, D(双向?如果bidirectional=true,值为2,否则为1,在这里为2),
是hidden size
相关文章:
【intro】图卷积神经网络(GCN)
本文为Graph Neural Networks(GNN)学习笔记-CSDN博客后续,内容为GCN论文阅读,相关博客阅读,kaggle上相关的数据集/文章/代码的阅读三部分,考虑到本人是GNN新手,会先从相关博客开始,进一步看kaggleÿ…...
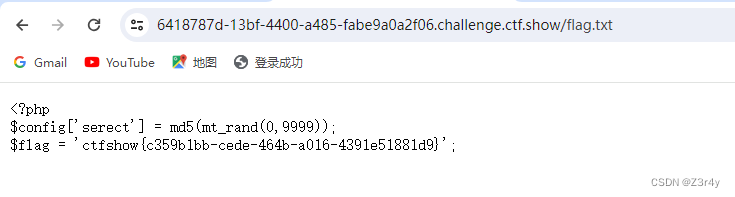
【Web】CTFSHOW 新手杯 题解
目录 easy_eval 剪刀石头布 baby_pickle repairman easy_eval 用script标签来绕过 剪刀石头布 需要赢100轮🤔 右键查看源码拿到提示 一眼session反序列化 打PHP_SESSION_UPLOAD_PROGRESS 脚本 import requestsp1 a|O:4:"Game":1:{s:3:"log…...

react 学习笔记二:ref、状态、继承
基础知识 1、ref 创建变量时,需要运用到username React.createRef(),并将其绑定到对应的节点。在使用时需要获取当前的节点; 注意:vue直接使用里面的值,不需要再用this。 2、状态 组件描述某种显示情况的数据&#…...
[SaaS]建筑领域的sd应用
AirchiDesignhttp://www.aiarchi.art/#/建筑学长——千万建筑师的资源库和AI绘图创作平台建筑学长官网,为青年设计师建立的线上资源共享及AI绘图创作渲染平台,免费提供海量设计案例、CAD图纸、SU模型、PS素材、软件插件下载,提供丰富的设计软件教学与灵感参考素材图库。https:/…...

气象数据nc数据矢量化处理解析及可视化
气象数据可视化是将气象学领域中复杂的数据集转化为图形或图像的过程,以直观展示天气现象、气候模式、趋势和预报结果。气象数据的可视化技术广泛应用于科学研究、气象预报、航空、航海、农业生产、灾害预警系统、城市规划、公众服务等领域。以下是一些关键的气象数…...

APP广告变现,开发者对接百度广告联盟,广告变现收益如何?
百度广告联盟属于广告整合平台,类似的还有穿山甲、优量汇、快手联盟等。 百度广告联盟注册流程: 创建账户:填写用户基本信息,如:用户名、密码、邮箱、手机号; 完善财务信息:填写银行账号、开…...

spring Ai框架整合Ollama,调用本地大模型
Ollama使用 Ollama是一个用于在本地计算机上运行大模型的软件 软件运行后监听11434端口,自己写的程序要调大模型就用这个端口 ollama命令 ollama list:显示模型列表 ollama show:显示模型的信息 ollama pull:拉取模型 ollama pu…...
)
八股spring+springboot+springMVC+Mybatis(一)
目录 1、面试官:Spring框架中的单例bean是线程安全的吗? 2、面试官:什么是AOP 3、面试官:你们项目中有没有使用到AOP 4、面试官:Spring中的事务是如何实现的 5、面试官:Spring中事务失效的场景有哪些 6、面…...

(六)SQL系列练习题(下)#CDA学习打卡
目录 三. 查询信息 16)检索"1"课程分数小于60,按分数降序排列的学生信息 17)*按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩 18)*查询各科成绩最高分、最低分和平均分 19)*按各科成绩…...
)
python数据处理(pandas)
# 新的数据格式,csv纯文本,使用某个字符集,比如都是ASCII、Unicode、EBCDIC或GB2312(简体中文环境)等;由记录组成(典型的是每行一条记录)每条记录被分隔符(英语ÿ…...

微信小程序开发秘籍:玩转麦克风录音与音频上传【代码示例】
微信小程序开发秘籍:玩转麦克风录音与音频上传【代码示例】 基本概念麦克风录音音频上传 实战演练1. 初始化录音功能2. 设计录音界面3. 实现音频上传安全性与性能优化 结语与讨论 在移动互联网时代,语音交互已成为提升用户体验的重要手段之一。微信小程序…...

spring的核心详解
Spring 核心详解 文章目录 Spring 核心详解前言什么是springspring的优点spring用到了哪些设计模式 什么是AOPAOP的实现方式静态代理动态代理 什么是IOCIOC的好处什么是依赖注入 前言 什么是spring Spring是一个开源的Java/Java EE全功能栈(full-stack)…...
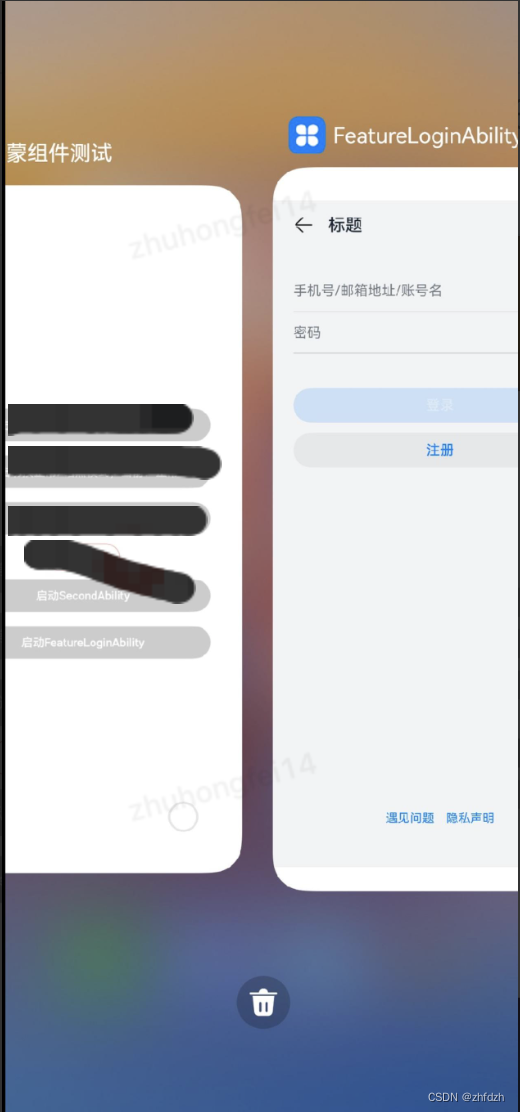
一、写给Android开发者之harmony入门
一、创建新项目 对比 android-studio:ability类似安卓activity ability分为两种类型(Stage模型) UIAbility和Extensionability(提供系统服务和后台任务) 启动模式 1、 singleton启动模式:单例 2、 multiton启动模式࿱…...
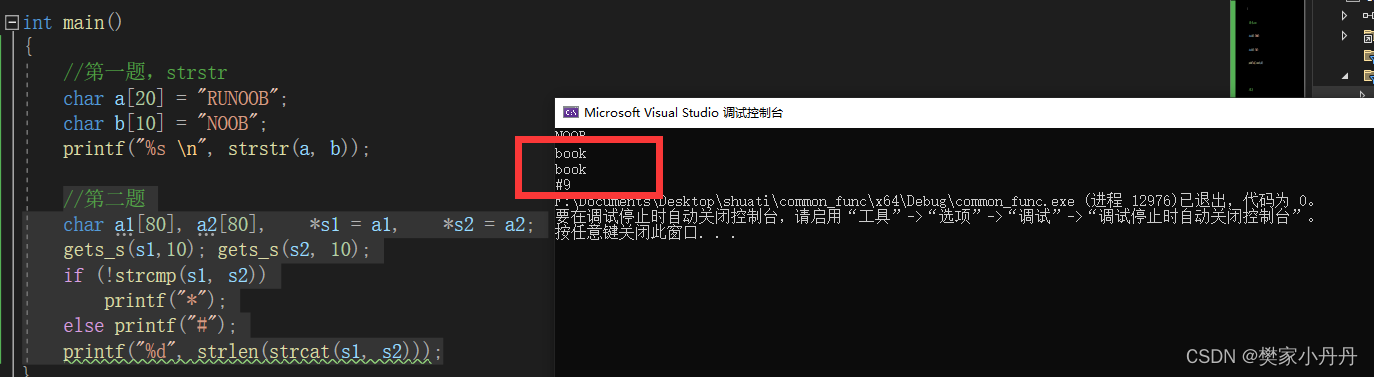
C++常用库函数——strstr、strcat
1、strstr:查找字符串子串函数,查找到的子串中第一个字符的地址,返回值是第一次出现子串字符串的位置。 例如: char a[20] "RUNOOB"; char b[10] "NOOB"; printf("%s", strstr(a, b)); 在这里…...

Kafak 消费异常:The coordinator is not available.
Kafak 消费异常:The coordinator is not available. 1. 问题描述2. 问题排查2.1 Topic 状态异常2.2 `__consumer_offsets` 简介1. 问题描述 在新环境部署 Kafak 时,发现可以正常产生消息,但是无法正常消费消息,消费消息的异常日志如下: 11:59:53.315 [main] DEBUG org.a…...

JavaScript中的对象
这里写目录标题 JavaScript中的对象属性 对象的使用属性和访问方法和调用遍历对象null 内置对象Math属性方法 JavaScript中的对象 对象(object)是JavaScript里的一种数据类型,可以理解为一种无序的数据集合(数组是有序的数据集合…...
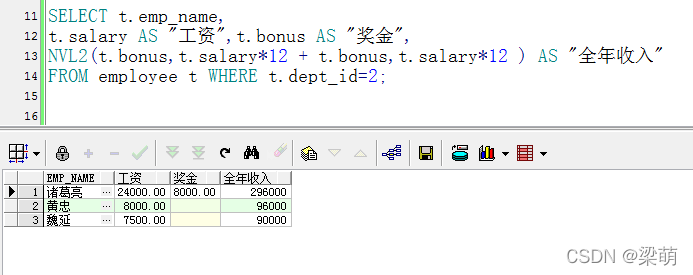
Oracle对空值(NULL)的 聚合函数 排序
除count之外sum、avg、max、min都为null,count为0 Null 不支持加减乘除,大小比较,相等比较,否则只能为空;只能用‘is [not] null’来进行判断; Max等聚合函数会自动“过滤null” null排序默认最大…...
我独自升级崛起下载教程 我独自升级崛起一键下载
动作RPG游戏基于广大喜爱的动画和在线漫画《我独自升级崛起》在5月8日,这款新的游戏首次在全球亮相,意在给那些对游戏情有独钟的玩家带来更加丰富和多种多样的游戏体验。这个网络武侠题材的游戏设计非常具有创意,其主要故事围绕着“独孤求败”…...

RS2057XH功能和参数介绍及规格书
RS2057XH 是一款由润石科技(Runic Semiconductor)生产的模拟开关芯片,其主要功能和参数如下: 产品特点: 低电压操作:支持低至1.8V的工作电压,适用于低功耗应用。 高带宽:具有300MHz的…...
ICML 2024有何亮点?9473篇论文投稿,突破历史记录
会议之眼 快讯 2024年5月1日,第42届国际机器学习大会ICML 2024放榜啦!录用率27.5%!ICML 2024的录用结果受到了广泛的关注,本届会议的投稿量达到了9473篇,创下了历史新高,比去年的6538篇增加了近3000篇&…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...