AI神助攻!小白也能制作自动重命名工具~
我们平时从网上下载一些文件,文件名很多都是一大串字母和数字,不打开看看,根本不知道里面是什么内容。

我想能不能做个工具,把我们一个文件夹下面的所有word、excel、ppt、pdf文件重命名为文件内容的第一行。
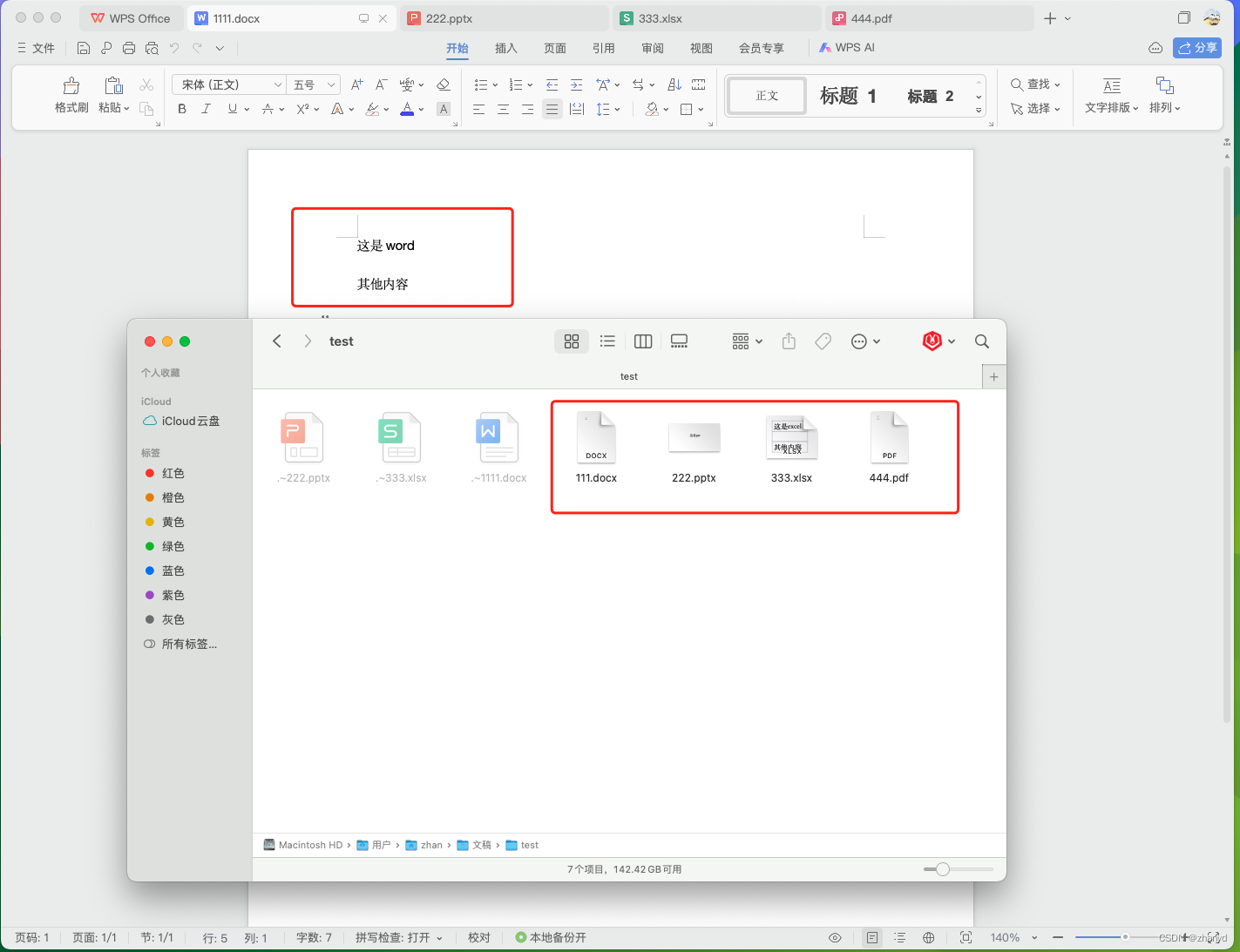
我们有些朋友可能不会编程,别慌,不会编程也没关系,我们可以让AI帮我们写一个Python程序。
下面我就让Kimi帮我们写一个程序:

我把上面这段代码复制到vscode中,把‘path_to_your_directory’替换成自己的文件夹路径,直接运行一下。
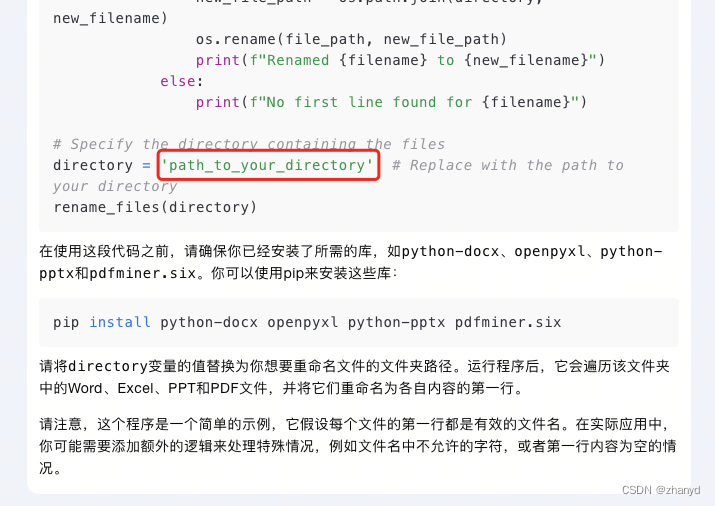
很不幸,报错了,没事,把错误提示复制出来,继续问Kimi:
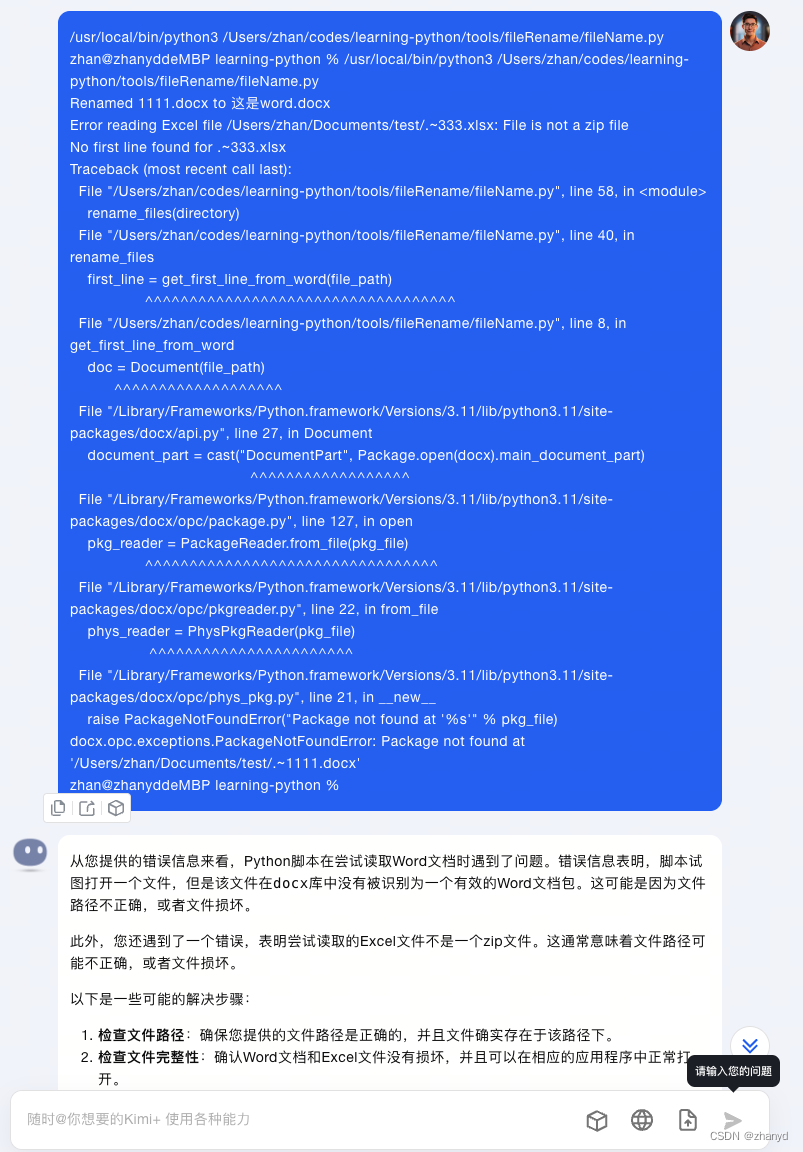
再报错,再问:
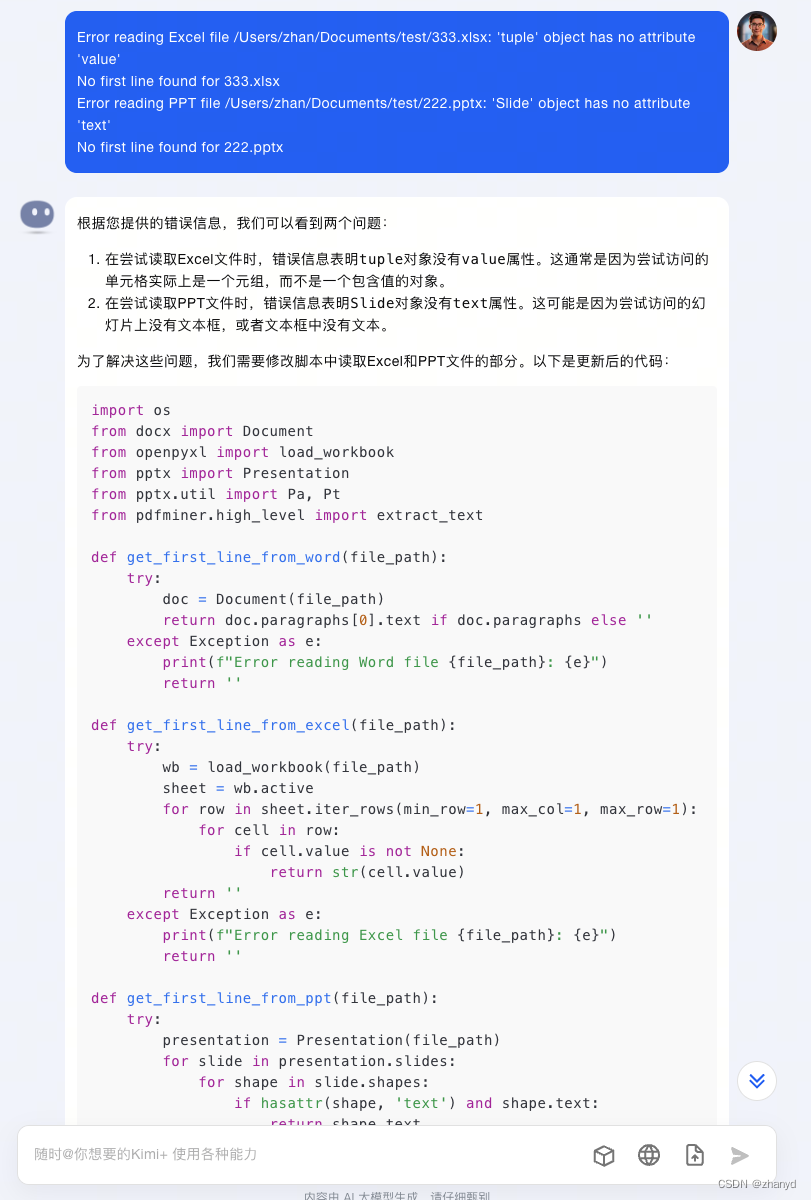
你就不厌其烦的问。
AI的一个好处是他永远不会发脾气,哈哈,你只管问就行,不管你的问题有多白痴,它总是会耐心回答,也不会笑话你,这点AI比人类要强百倍。
最终AI给出了一个可运行的版本:
import os
from docx import Document
from openpyxl import load_workbook
from pptx import Presentation
from pdfminer.high_level import extract_textdef get_first_line_from_word(file_path):try:doc = Document(file_path)return doc.paragraphs[0].text if doc.paragraphs else ''except Exception as e:print(f"Error reading Word file {file_path}: {e}")return ''def get_first_line_from_excel(file_path):try:wb = load_workbook(file_path)sheet = wb.activefor row in sheet.iter_rows(min_row=1, values_only=True):for value in row:if value is not None:return str(value)return ''except Exception as e:print(f"Error reading Excel file {file_path}: {e}")return ''def get_first_line_from_ppt(file_path):try:presentation = Presentation(file_path)for slide in presentation.slides:for shape in slide.shapes:if hasattr(shape, 'text') and shape.text:return shape.text[:shape.text.index('\n')] if '\n' in shape.text else shape.textreturn ''except Exception as e:print(f"Error reading PPT file {file_path}: {e}")return ''def get_first_line_from_pdf(file_path):try:text = extract_text(file_path)return text.split('\n', 1)[0] if text else ''except Exception as e:print(f"Error reading PDF file {file_path}: {e}")return ''def rename_files(directory):for filename in os.listdir(directory):if filename.lower().endswith(('.docx', '.xlsx', '.pptx', '.pdf')) and not filename.lower().startswith('.~') :file_path = os.path.join(directory, filename)first_line = ''if filename.lower().endswith('.docx'):first_line = get_first_line_from_word(file_path)elif filename.lower().endswith('.xlsx'):first_line = get_first_line_from_excel(file_path)elif filename.lower().endswith('.pptx'):first_line = get_first_line_from_ppt(file_path)elif filename.lower().endswith('.pdf'):first_line = get_first_line_from_pdf(file_path)if first_line:new_filename = first_line.strip() + os.path.splitext(filename)[1]new_file_path = os.path.join(directory, new_filename)os.rename(file_path, new_file_path)print(f"Renamed {filename} to {new_filename}")else:print(f"No first line found for {filename}")# Specify the directory containing the files
directory = '/Users/zhan/Documents/test' # Replace with the path to your directory
rename_files(directory)
运行效果如下:

我们还需要一个UI界面,让我们可以在图形界面上操作,我们继续问Kimi:

最终代码如下:
import os
from docx import Document
from openpyxl import load_workbook
from pptx import Presentation
from pdfminer.high_level import extract_text
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttkdef get_first_line_from_word(file_path):try:doc = Document(file_path)return doc.paragraphs[0].text if doc.paragraphs else ''except Exception as e:print(f"Error reading Word file {file_path}: {e}")return ''def get_first_line_from_excel(file_path):try:wb = load_workbook(file_path)sheet = wb.activefor row in sheet.iter_rows(min_row=1, values_only=True):for value in row:if value is not None:return str(value)return ''except Exception as e:print(f"Error reading Excel file {file_path}: {e}")return ''def get_first_line_from_ppt(file_path):try:presentation = Presentation(file_path)for slide in presentation.slides:for shape in slide.shapes:if hasattr(shape, 'text') and shape.text:return shape.text[:shape.text.index('\n')] if '\n' in shape.text else shape.textreturn ''except Exception as e:print(f"Error reading PPT file {file_path}: {e}")return ''def get_first_line_from_pdf(file_path):try:text = extract_text(file_path)return text.split('\n', 1)[0] if text else ''except Exception as e:print(f"Error reading PDF file {file_path}: {e}")return ''def rename_files(directory):for filename in os.listdir(directory):if filename.lower().endswith(('.docx', '.xlsx', '.pptx', '.pdf')) and not filename.lower().startswith('.~') :file_path = os.path.join(directory, filename)first_line = ''if filename.lower().endswith('.docx'):first_line = get_first_line_from_word(file_path)elif filename.lower().endswith('.xlsx'):first_line = get_first_line_from_excel(file_path)elif filename.lower().endswith('.pptx'):first_line = get_first_line_from_ppt(file_path)elif filename.lower().endswith('.pdf'):first_line = get_first_line_from_pdf(file_path)if first_line:new_filename = first_line.strip() + os.path.splitext(filename)[1]new_file_path = os.path.join(directory, new_filename)os.rename(file_path, new_file_path)print(f"Renamed {filename} to {new_filename}")else:print(f"No first line found for {filename}")# Specify the directory containing the files
directory = '/Users/zhan/Documents/test' # Replace with the path to your directory # 这里是之前定义的rename_files函数和子函数
def choose_directory():directory = filedialog.askdirectory()if directory:entry.delete(0, tk.END)entry.insert(0, directory)def rename_files_with_ui():directory = entry.get()if not directory:messagebox.showerror("错误", "请选择一个文件夹")returnif not os.path.isdir(directory):messagebox.showerror("错误", "所选路径不是一个文件夹")returntry:rename_files(directory)messagebox.showinfo("完成", "文件重命名完成")except Exception as e:messagebox.showerror("错误", f"发生错误: {e}")# 创建主窗口
root = tk.Tk()
root.title("文件批量重命名工具")# 创建一个标签和输入框用于显示选择的文件夹路径
label = ttk.Label(root, text="请选择文件夹:")
label.pack()
entry = tk.Entry(root, width=30)
entry.pack()# 创建一个按钮,点击时弹出选择文件夹的对话框
browse_button = ttk.Button(root, text="浏览", command=choose_directory)
browse_button.pack()# 创建一个按钮,点击时执行重命名操作
rename_button = ttk.Button(root, text="确定", command=rename_files_with_ui)
rename_button.pack()# 设置窗口的尺寸
width = 350 # 宽度
height = 200 # 高度# 获取屏幕的宽度和高度
screen_width = root.winfo_screenwidth()
screen_height = root.winfo_screenheight()# 计算窗口的中心坐标
x = (screen_width / 2) - (width / 2)
y = (screen_height / 2) - (height / 2)# 将窗口放置在屏幕中心
root.geometry(f'{width}x{height}+{int(x)}+{int(y)}')# 运行主循环
root.mainloop()我们看下运行效果:
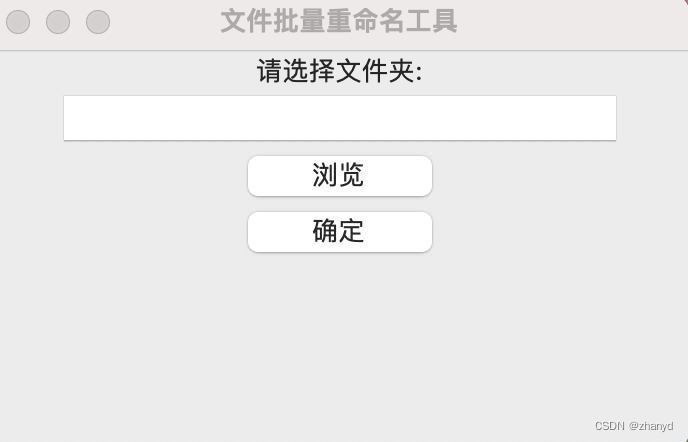
试了一下,功能和上面的程序是一样的。
最后一步就是打包程序了,同样我们问下AI:
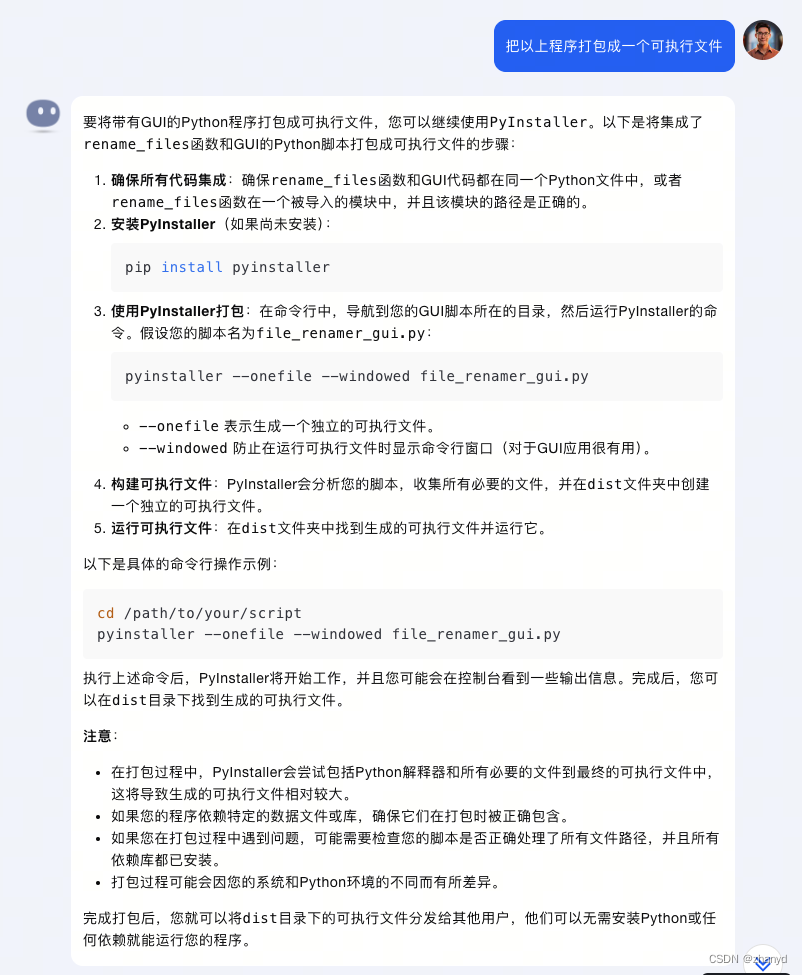
一共就两步:
- 安装PyInstaller
pip install pyinstaller
- 使用PyInstaller打包
pyinstaller --onefile --windowed file_renamer_gui.py
注意要把“file_renamer_gui.py"替换成你自己的文件名。
打包好之后,在项目目录的dist文件夹下就可以找到打包好的文件。
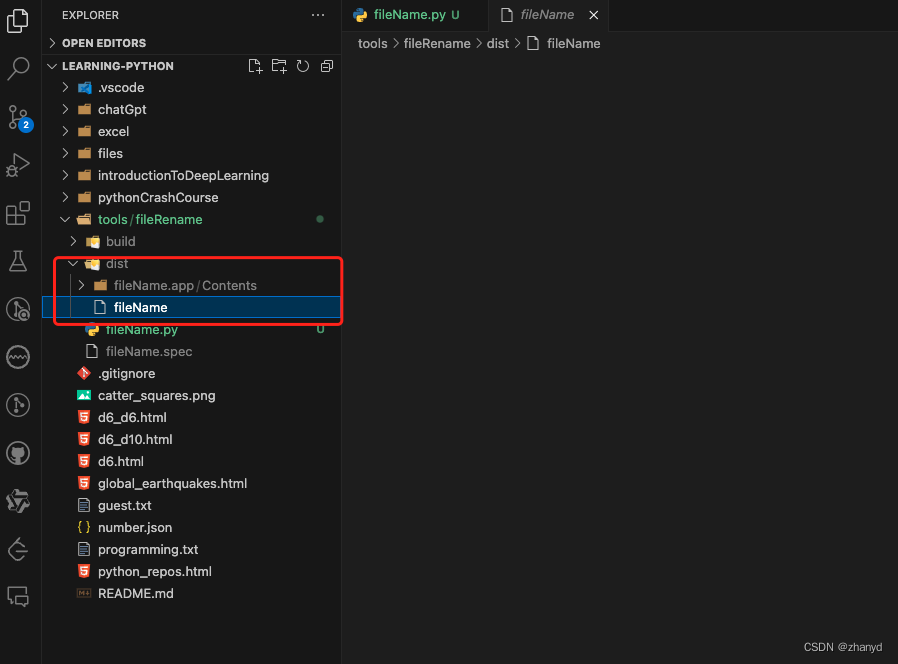
双击打开即可运行,效果是一样的。
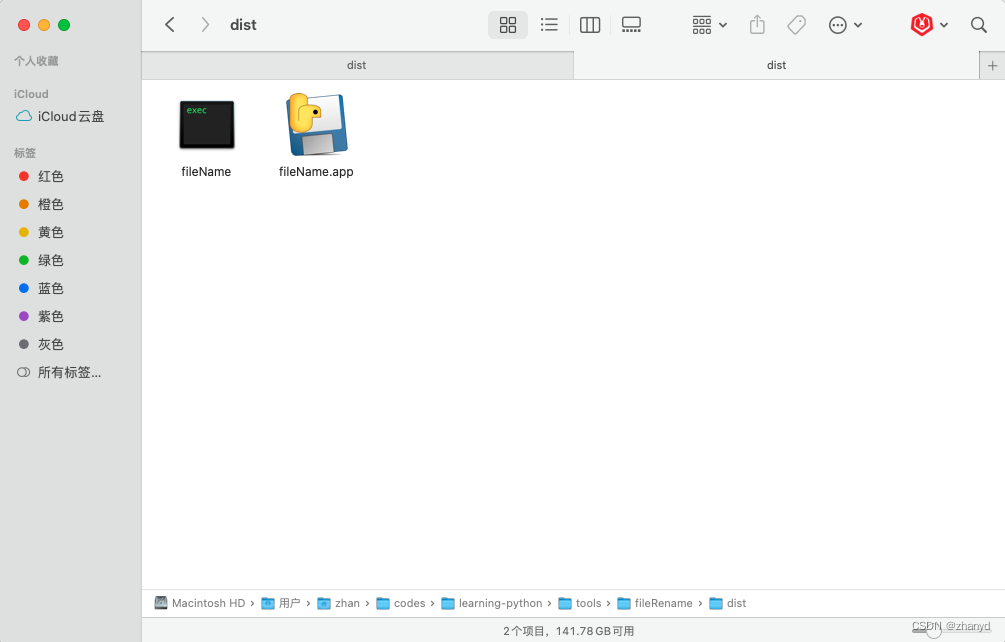
好了,这个工具就写好了。
有了AI的助攻,我们想写什么工具直接让AI帮我们写就好了,是不是给了你很大的信心?
原来编程也不难,编程我也会啊~
上面的代码亲测可用,如果你想直接下载exe文件,关注公众号“编程我也会”,回复“重命名”即可下载。
相关文章:
AI神助攻!小白也能制作自动重命名工具~
我们平时从网上下载一些文件,文件名很多都是一大串字母和数字,不打开看看,根本不知道里面是什么内容。 我想能不能做个工具,把我们一个文件夹下面的所有word、excel、ppt、pdf文件重命名为文件内容的第一行。 我们有些朋友可能不会…...
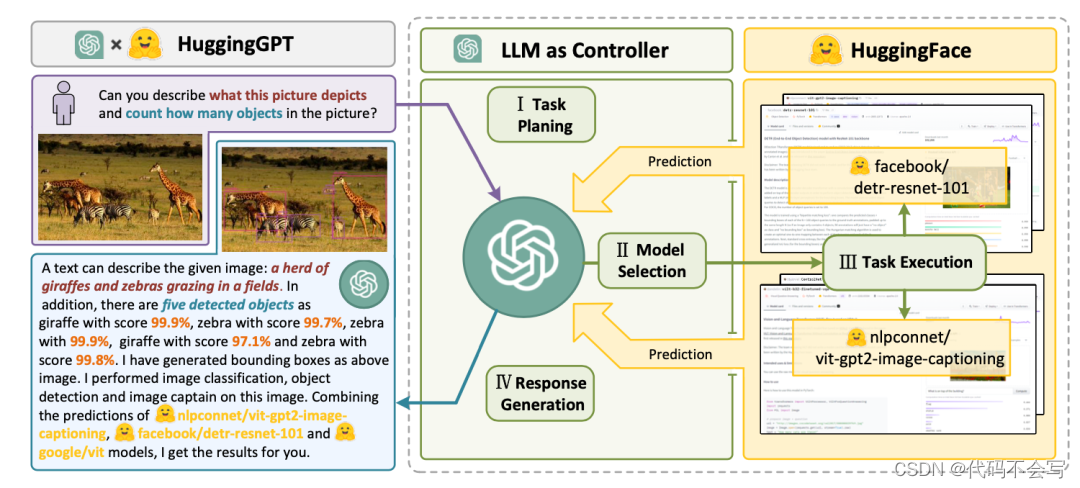
(读书笔记-大模型) LLM Powered Autonomous Agents
目录 智能体系统的概念 规划组件 记忆组件 工具组件 案例研究 智能体系统的概念 在大语言模型(LLM)赋能的自主智能体系统中,LLM 充当了智能体的大脑,其三个关键组件分别如下: 首先是规划,它又分为以下…...

超分辨率重建——BSRN网络训练自己数据集并推理测试(详细图文教程)
目录 一、BSRN网络总结二、源码包准备三、环境准备3.1 报错KeyError: "No object named BSRN found in arch registry!"3.2 安装basicsr源码包3.3 参考环境 四、数据集准备五、训练5.1 配置文件参数修改5.2 启动训练5.2.1 命令方式训练5.2.2 配置Configuration方式训…...
C语言实现贪吃蛇
目录 前言一 . 游戏背景1. 背景介绍2. 项目目标3. 技术要点 二 . 效果演示三 . 游戏的设计与分析1. 核心逻辑2. 设计与分析游戏开始Gamestart()函数游戏运行Gamerun()函数游戏结束Gameend()函数 四 . 参考代码五 . 总结 前言 本文旨在使用C语言和基础数据结构链表来实现贪吃蛇…...

高可用系列四:loadbalancer 负载均衡
负载均衡可以单独使用,也常常与注册中心结合起来使用,其需要解决的问题是流量分发,这是就需要定义分发策略,当然也包括了故障切换的能力。 故障切换 故障切换是负载均衡的基本能力,和注册中心结合时比较简单…...

Ruby递归目录文件的又一种方法
经常派得上用场,记录一下。 递归文件做一些操作 #encoding:utf-8require pathnamedef recursive_enum_files(from_path)from_path Pathname.new(from_path)raise ArgumentError,must start at a directory. unless from_path.directory?from_path.enum_for(:fin…...
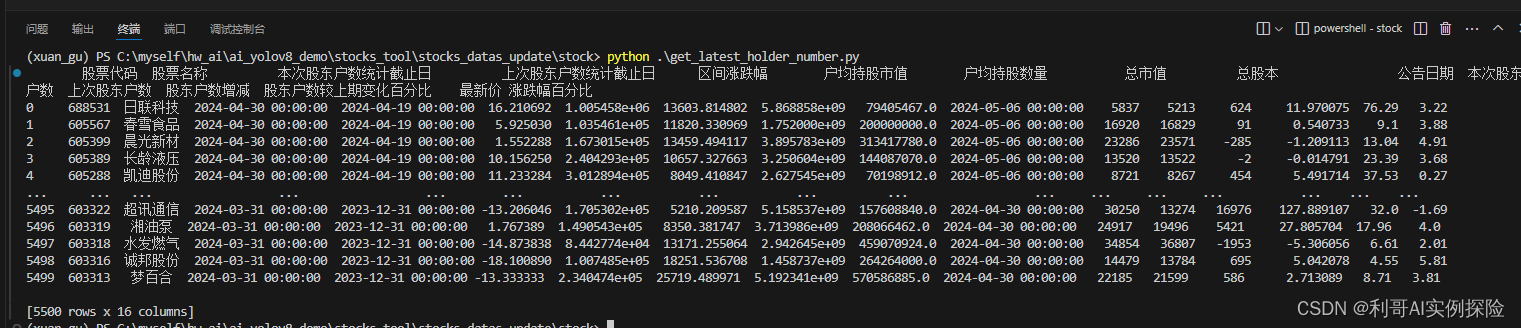
【爬虫】爬取A股数据写入数据库(一)
1. 对东方财富官网的分析 步骤: 通过刷新网页,点击等操作,我们发现https://datacenter-web.eastmoney.com/api/data/v1/get?请求后面带着一些参数即可以获取到相应数据。我们使用python来模拟这个请求即可。 我们以如下选择的页面为切入点…...
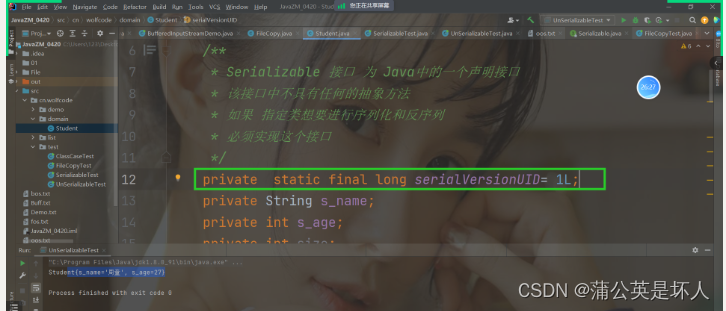
1-38 流资源类结构
一 简介 1. Java中所说的流资源--IO流 2.为什么学习留资源? --要操作文件中的数据 将数据写入指定的文件 将数据从指定的文件读取 3.分类 -- 四大基流 , 八大子流 (重点) 按照流向分 : 输入流 和输出流 按照操作数据资源的类型划分 字符流 (重点) Reader -- 字符…...

nginx的前世今生(二)
书接上回: 上回书说到,nginx的前世今生,这回我们继续说 3.缓冲秘籍,洪流控水 Nginx的缓冲区是其处理数据传输和提高性能的关键设计之一,主要用于暂存和管理进出的数据流,以应对不同组件间速度不匹配的问题…...

浏览器跨域详解
一、什么是跨域 浏览器跨域是指当一个Web应用程序试图访问另一个协议、主机或端口不同的资源时,所发生的情况。这主要是由于浏览器的同源策略造成的,它是为了网站的安全而设置的安全限制,防止一个网站恶意访问另一个网站的资源。当然这是比较…...
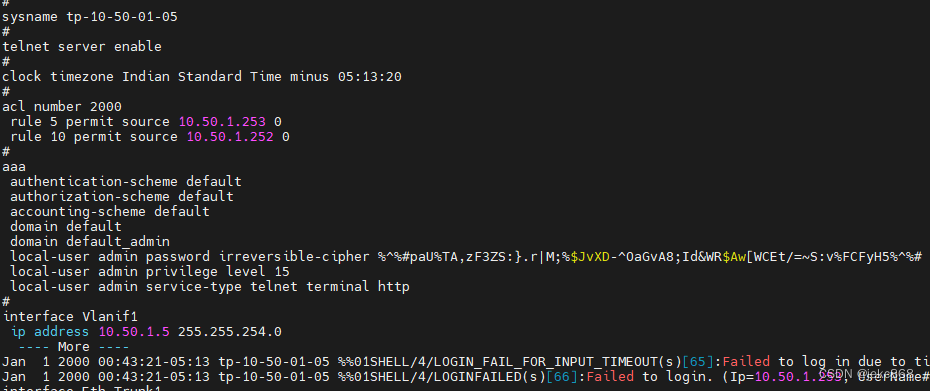
华为5700配置
恢复出厂设置,清空配置 1、更改名字 system-view sysname tp-10-50-01-04 2、配置管理接口 int vlan 1 ip add 10.50.1.4 255.255.254.0 quit 2、链路汇聚 interface eth-trunk 1 mode lacp quit 3、绑定端口 interface eth-trunk 1 trunkport gigabitethernet …...

使用Axios从前端上传文件并且下载后端返回的文件
前端代码: function uploadAndDownload(){showLoading();const fileInput document.querySelector(#uploadFile);const file fileInput.files[0];const formData new FormData()formData.append(file, file)return new Promise((resolve, reject) > {axios({…...
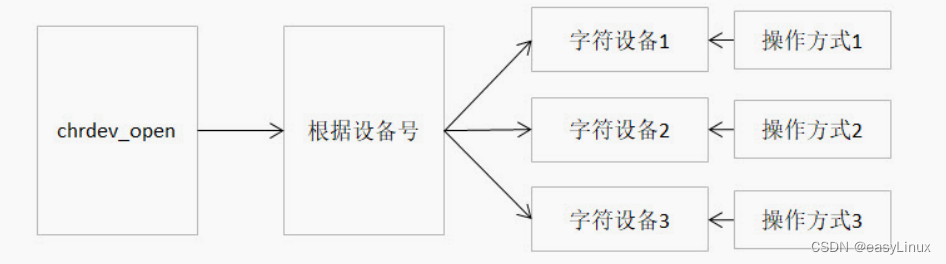
open 函数到底做了什么
使用设备之前我们通常都需要调用 open 函数,这个函数一般用于设备专有数据的初始化,申请相关资源及进行设备的初始化等工作,对于简单的设备而言,open 函数可以不做具体的工作,你在应用层通过系统调用 open 打开设备…...

ue引擎游戏开发笔记(32)——为游戏添加新武器装备
1.需求分析: 游戏中角色不会只有一种武器,不同武器需要不同模型,甚至可能需要角色持握武器的不同位置,因此需要添加专门的武器类,方便武器后续更新,建立一个武器类。 2.操作实现: 1.在ue5中新建…...
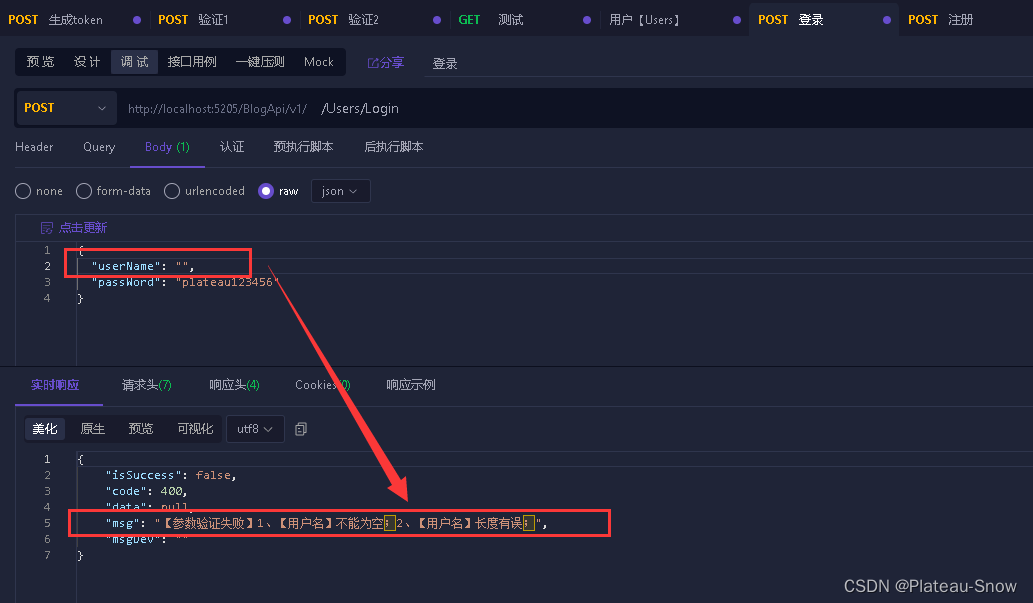
【个人博客搭建】(17)使用FluentValidation 参数校验
FluentValidation 是一个用于 .NET 的开源验证库,它提供了一种流畅的接口和强类型验证规则,使得验证逻辑表达得更加清晰和简洁。(Apache-2.0) FluentValidation 的主要作用包括: 提高代码可读性:通过使用 F…...

数据结构===散列表
文章目录 概要散列思想散列函数散列冲突开放寻址法装载因子 链表法 代码Java小结 概要 散列表是一种很有趣的数据结构。 散列表是一个很有用的数据结构。它是数组演练而来的,又是一个基于数组的扩展的数据结构。接下来看看。 散列思想 散列表用的是数组支持按照下…...
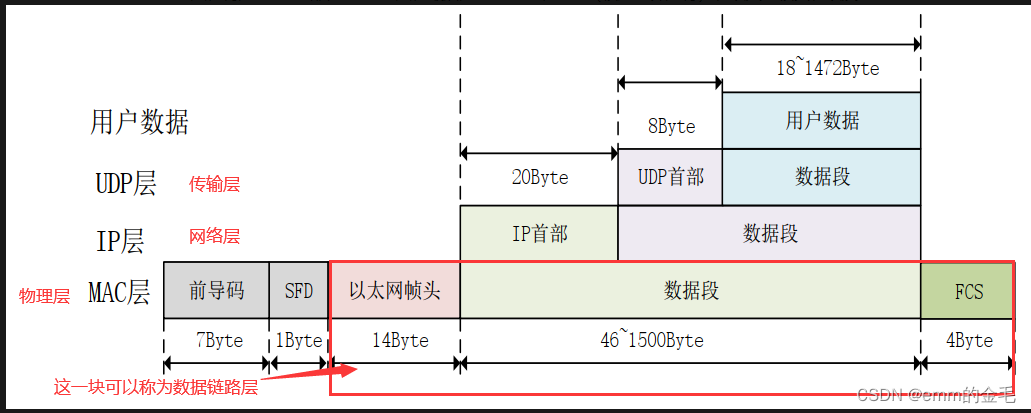
10G MAC层设计系列-(2)MAC RX模块
一、概述 MAC RX模块的需要进行解码、对齐、CRC校验。 因为在空闲的时候10G PCS/PMA会一直向外吐空闲符(x07)所以需要根据开始符、结束符将有效数据从码流中截取,也就是解码。 因为开始字符的所在位置有两种形式,而结束字符的位…...

解码Starknet Verifier:深入逆向工程之旅
1. 引言 Sandstorm为: 能提交独立proof给StarkWare的Ethereum Verifier,的首个开源的STARK prover。 开源代码见: https://github.com/andrewmilson/sandstorm(Rust) L2Beat 提供了以太坊上Starknet的合约架构图&…...
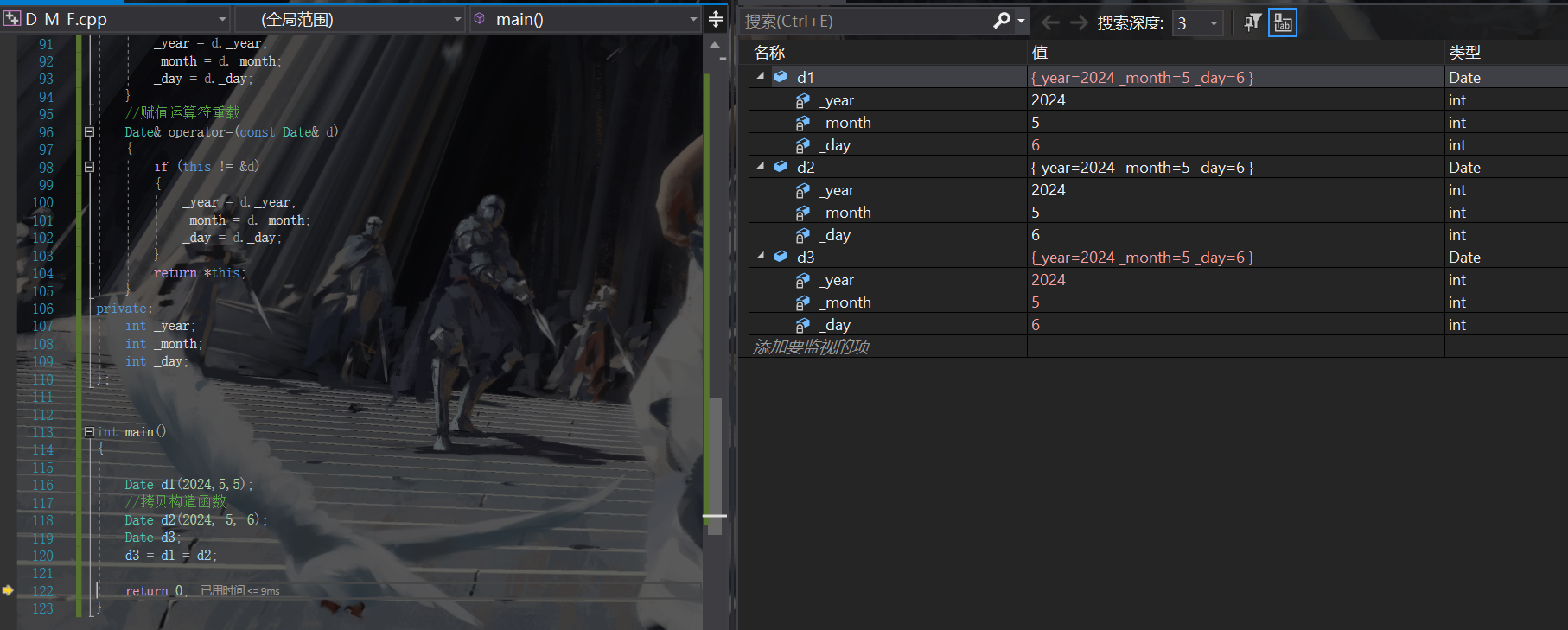
【C++语言】类和对象--默认成员函数 (中)
文章目录 前言类的六个默认成员函数:1. 构造函数概念特性做了什么?易错注意:显式定义和默认构造函数 2. 析构函数概念特征做了什么?注意事项: 3.拷贝构造函数概念特征做了什么?注意事项: 4.赋值运算符重载…...

前端递归常见应用
概览 在 JavaScript 中,递归是一种编程技术,指的是函数直接或间接调用自身的过程。 递归通常用于解决可以分解为相同子问题的问题。通过不断地将问题分解成更小的、相似的子问题,直到达到某种基本情况(不再需要进一步递归的简单情…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...