github中fasttext库README官文文档翻译
参考链接:fastText/python/README.md at main · facebookresearch/fastText (github.com)
fastText模块介绍
fastText 是一个用于高效学习单词表述和句子分类的库。在本文档中,我们将介绍如何在 python 中使用 fastText。
环境要求
fastText 可在现代 Mac OS 和 Linux 发行版上运行。由于它使用了 C++11 功能,因此需要一个支持 C++11 的编译器。您需要 Python(版本 2.7 或 ≥ 3.4)、NumPy & SciPy 和 pybind11。
安装
要安装最新版本,可以执行:
$ pip install fasttext或者,要获取 fasttext 的最新开发版本,您可以从我们的 github 代码库中安装:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ sudo pip install .
$ # or :
$ sudo python setup.py install使用概览
词语表征模型
为了像这里描述的那样学习单词向量,我们可以像这样使用 fasttext.train_unsupervised 函数:
import fasttext# Skipgram model :
model = fasttext.train_unsupervised('data.txt', model='skipgram')# or, cbow model :
model = fasttext.train_unsupervised('data.txt', model='cbow')
其中,data.txt 是包含 utf-8 编码文本的训练文件。返回的模型对象代表您学习的模型,您可以用它来检索信息。
print(model.words) # list of words in dictionary
print(model['king']) # get the vector of the word 'king'保存和加载模型对象
调用函数 save_model 可以保存训练好的模型对象。
model.save_model("model_filename.bin")并通过函数 load_model 加载模型参数:
model = fasttext.load_model("model_filename.bin")文本分类模型
为了使用这里介绍的方法训练文本分类器,我们可以这样使用 fasttext.train_supervised 函数:
import fasttextmodel = fasttext.train_supervised('data.train.txt')其中 data.train.txt 是一个文本文件,每行包含一个训练句子和标签。默认情况下,我们假定标签是以字符串 __label__ 为前缀的单词。模型训练完成后,我们就可以检索单词和标签列表:
print(model.words)
print(model.labels)为了通过在测试集上计算精度为 1 (P@1) 和召回率来评估我们的模型,我们使用了测试函数:
def print_results(N, p, r):print("N\t" + str(N))print("P@{}\t{:.3f}".format(1, p))print("R@{}\t{:.3f}".format(1, r))print_results(*model.test('test.txt'))我们还可以预测特定文本的标签:
model.predict("Which baking dish is best to bake a banana bread ?")默认情况下,predict 只返回一个标签:概率最高的标签。您也可以通过指定参数 k 来预测多个标签:
model.predict("Which baking dish is best to bake a banana bread ?", k=3)如果您想预测多个句子,可以传递一个字符串数组:
model.predict(["Which baking dish is best to bake a banana bread ?", "Why not put knives in the dishwasher?"], k=3)当然,您也可以像文字表示法那样,将模型保存到文件或从文件加载模型。
用量化技术压缩模型文件
当您想保存一个经过监督的模型文件时,fastText 可以对其进行压缩,从而只牺牲一点点性能,获得更小的模型文件。
# with the previously trained `model` object, call :
model.quantize(input='data.train.txt', retrain=True)# then display results and save the new model :
print_results(*model.test(valid_data))
model.save_model("model_filename.ftz")model_filename.ftz 的大小将远远小于 model_filename.bin。
重要:预处理数据/编码约定
一般来说,对数据进行适当的预处理非常重要。特别是根文件夹中的示例脚本可以做到这一点。
fastText 假定使用 UTF-8 编码的文本。对于 Python2,所有文本都必须是 unicode;对于 Python3,所有文本都必须是 str。传入的文本将由 pybind11 编码为 UTF-8,然后再传给 fastText C++ 库。这意味着在构建模型时,使用 UTF-8 编码的文本非常重要。在类 Unix 系统中,可以使用 iconv 转换文本。
fastText 将根据以下 ASCII 字符(字节)进行标记化(将文本分割成片段)。特别是,它无法识别 UTF-8 的空白。我们建议用户将UTF-8 空格/单词边界转换为以下适当的符号之一。
空间
选项卡
垂直制表符
回车
换页
空字符
换行符用于分隔文本行。特别是,如果遇到换行符,EOS 标记就会被附加到文本行中。唯一的例外情况是,标记的数量超过了字典标题中定义的 MAX_LINE_SIZE 常量。这意味着,如果文本没有换行符分隔,例如 fil9 数据集,它将被分割成具有 MAX_LINE_SIZE 的标记块,而 EOS 标记不会被附加。
标记符的长度是UTF-8 字符的数量,通过考虑字节的前两位来识别多字节序列的后续字节。在选择子字的最小和最大长度时,了解这一点尤为重要。此外,EOS 标记(在字典标头中指定)被视为一个字符,不会被分解为子字。
更多实例
为了更好地了解 fastText 模型,请参阅主 README,特别是我们网站上的教程。您还可以在 doc 文件夹中找到更多 Python 示例。与其他软件包一样,您可以使用 help 函数获得有关任何 Python 函数的帮助。
例如
+>>> import fasttext
+>>> help(fasttext.FastText)Help on module fasttext.FastText in fasttext:NAMEfasttext.FastTextDESCRIPTION# Copyright (c) 2017-present, Facebook, Inc.# All rights reserved.## This source code is licensed under the MIT license found in the# LICENSE file in the root directory of this source tree.FUNCTIONSload_model(path)Load a model given a filepath and return a model object.tokenize(text)Given a string of text, tokenize it and return a list of tokens
[...]API——应用程序接口
train_unsupervised (无监督训练参数)
input # training file path (required)model # unsupervised fasttext model {cbow, skipgram} [skipgram]lr # learning rate [0.05]dim # size of word vectors [100]ws # size of the context window [5]epoch # number of epochs [5]minCount # minimal number of word occurences [5]minn # min length of char ngram [3]maxn # max length of char ngram [6]neg # number of negatives sampled [5]wordNgrams # max length of word ngram [1]loss # loss function {ns, hs, softmax, ova} [ns]bucket # number of buckets [2000000]thread # number of threads [number of cpus]lrUpdateRate # change the rate of updates for the learning rate [100]t # sampling threshold [0.0001]verbose # verbose [2]train_supervised parameters(监督训练参数)
input # training file path (required)lr # learning rate [0.1]dim # size of word vectors [100]ws # size of the context window [5]epoch # number of epochs [5]minCount # minimal number of word occurences [1]minCountLabel # minimal number of label occurences [1]minn # min length of char ngram [0]maxn # max length of char ngram [0]neg # number of negatives sampled [5]wordNgrams # max length of word ngram [1]loss # loss function {ns, hs, softmax, ova} [softmax]bucket # number of buckets [2000000]thread # number of threads [number of cpus]lrUpdateRate # change the rate of updates for the learning rate [100]t # sampling threshold [0.0001]label # label prefix ['__label__']verbose # verbose [2]pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []模型对象、
train_supervised、train_unsupervised 和 load_model 函数返回 _FastText 类的一个实例,我们一般将其命名为模型对象。
该对象将这些训练参数作为属性公开:lr、dim、ws、epoch、minCount、minCountLabel、minn、maxn、neg、wordNgrams、loss、bucket、thread、lrUpdateRate、t、label、verbose、pretrainedVectors。因此,model.wordNgrams 将给出用于训练该模型的单词 ngram 的最大长度。
此外,该对象还公开了多个函数:
get_dimension # Get the dimension (size) of a lookup vector (hidden layer).# This is equivalent to `dim` property.get_input_vector # Given an index, get the corresponding vector of the Input Matrix.get_input_matrix # Get a copy of the full input matrix of a Model.get_labels # Get the entire list of labels of the dictionary# This is equivalent to `labels` property.get_line # Split a line of text into words and labels.get_output_matrix # Get a copy of the full output matrix of a Model.get_sentence_vector # Given a string, get a single vector represenation. This function# assumes to be given a single line of text. We split words on# whitespace (space, newline, tab, vertical tab) and the control# characters carriage return, formfeed and the null character.get_subword_id # Given a subword, return the index (within input matrix) it hashes to.get_subwords # Given a word, get the subwords and their indicies.get_word_id # Given a word, get the word id within the dictionary.get_word_vector # Get the vector representation of word.get_words # Get the entire list of words of the dictionary# This is equivalent to `words` property.is_quantized # whether the model has been quantizedpredict # Given a string, get a list of labels and a list of corresponding probabilities.quantize # Quantize the model reducing the size of the model and it's memory footprint.save_model # Save the model to the given pathtest # Evaluate supervised model using file given by pathtest_label # Return the precision and recall score for each label. 属性 words, labels 返回字典中的单词和标签:
model.words # equivalent to model.get_words()
model.labels # equivalent to model.get_labels()该对象重载了 __getitem__ 和 __contains__ 函数,以便返回单词的表示形式和检查单词是否在词汇表中
model['king'] # equivalent to model.get_word_vector('king')
'king' in model # equivalent to `'king' in model.get_words()`相关文章:

github中fasttext库README官文文档翻译
参考链接:fastText/python/README.md at main facebookresearch/fastText (github.com) fastText模块介绍 fastText 是一个用于高效学习单词表述和句子分类的库。在本文档中,我们将介绍如何在 python 中使用 fastText。 环境要求 fastText 可在现代 …...
WouoUIPagePC端实现
WouoUIPagePC端实现 WouoUIPage是一个与硬件平台无关,纯C语言的UI库(目前只能应用于128*64的单色OLED屏幕上,后期会改进,支持更多尺寸)。因此,我们可以在PC上实现它,本文就以在PC上使用 VScode…...

W801学习笔记十九:古诗学习应用——下
经过前两章的内容,背唐诗的功能基本可以使用了。然而,仅有一种模式未免显得过于单一。因此,在本章中对其进行扩展,增加几种不同的玩法,并且这几种玩法将采用完全不同的判断方式。 玩法一:三分钟限时挑战—…...
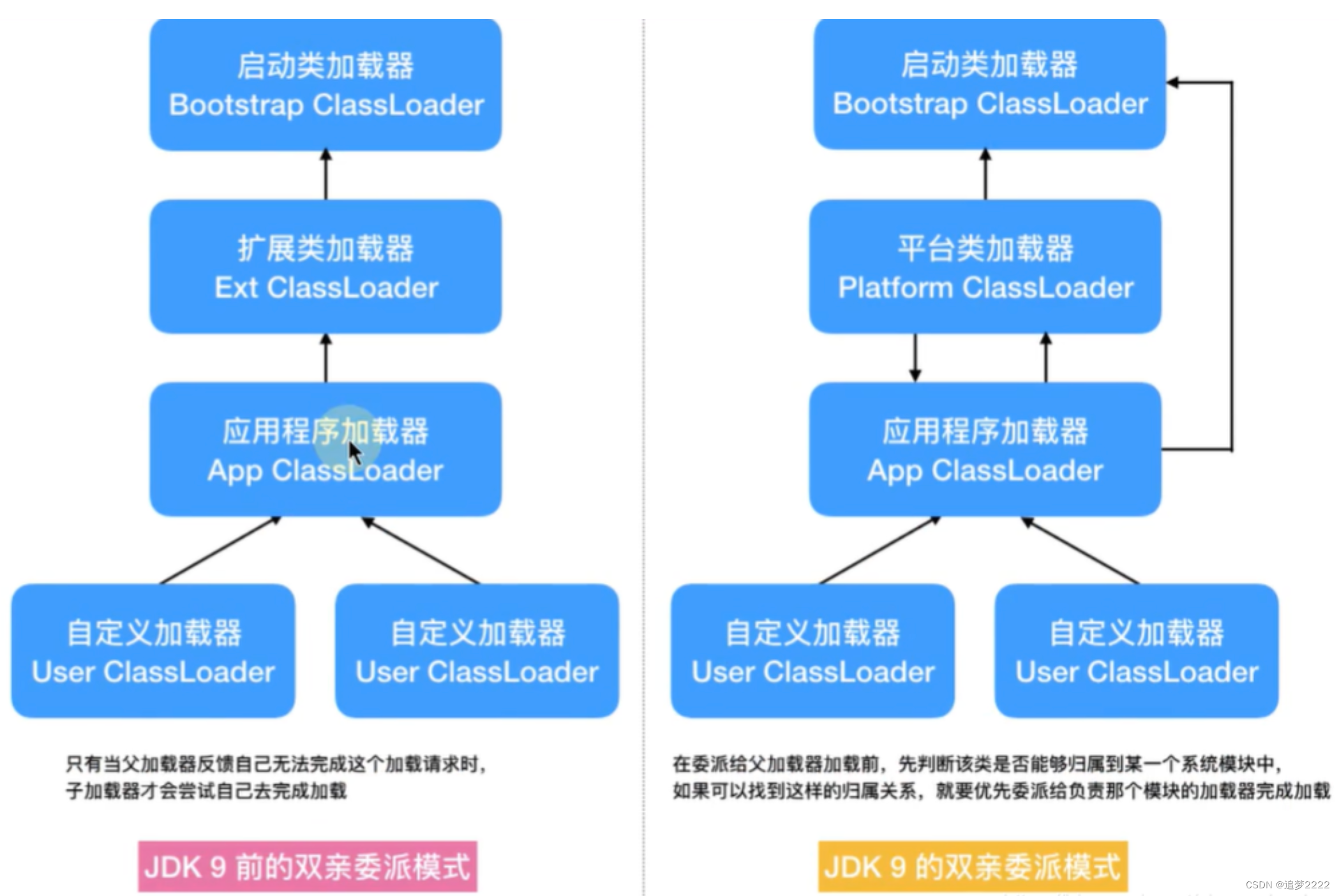
类加载器ClassLoad-jdk1.8
类加载器ClassLoad-jdk1.8 1. 类加载器的作用2. 类加载器的种类(JDK8)3. jvm内置类加载器如何搜索加载类--双亲委派模型4. 如何打破双亲委派模型--自定义类加载器5. 自定义一个类加载器5.1 为什么需要自定义类加载器5.2 自定义一个类加载器 6. java代码加…...
24年最新AI数字人简单混剪
24年最新AI数字人简单混剪 网盘自动获取 链接:https://pan.baidu.com/s/1lpzKPim76qettahxvxtjaQ?pwd0b8x 提取码:0b8x...

免备案香港主机会影响网站收录?
免备案香港主机会影响网站收录?前几天遇到一个做电子商务的朋友说到这个使用免备案香港主机的完整会不会影响网站的收录问题,这个问题也是站长关注较多的问题之一。小编查阅了百度官方规则说明,应该属于比较全面的。下面小编给大家介绍一下使用免备案香…...

低代码工业组态数字孪生平台
2024 两会热词「新质生产力」凭借其主要特征——高科技、高效能及高质量,引发各界关注。在探索构建新质生产力的重要议题中,数据要素被视为土地、劳动力、资本和技术之后的第五大生产要素。数据要素赋能新质生产力发展主要体现为:生产力由生产…...
|爬楼梯(第八期模拟笔试)|零钱兑换|完全平方数)
代码随想录第三十八天(完全背包问题)|爬楼梯(第八期模拟笔试)|零钱兑换|完全平方数
爬楼梯(第八期模拟笔试) 该题也是昨天的完全背包排列问题,解法相同,将遍历顺序进行调换 import java.util.*; public class Main{public static void main (String[] args) {Scanner scnew Scanner(System.in);int nsc.nextInt(…...

idea常用知识点随记
idea常用知识点随记 1. 打开idea隐藏的commit窗口2. idea中拉取Git分支代码3. idea提示代码报错,项目编译没有报错4. idea中实体类自动生成序列号5. idea隐藏当前分支未commit代码6. idea拉取新建分支的方法 1. 打开idea隐藏的commit窗口 idea左上角File→Settings…...
(双指针) 有效三角形的个数 和为s的两个数字 三数之和 四数之和
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 文章目录 前言 一、有效三角形的个数(medium) 1.1、题目 1.2、讲解算法原理 1.3、编写代码 二、和为s的两个数字 2.1、题目 2.2、讲解算…...
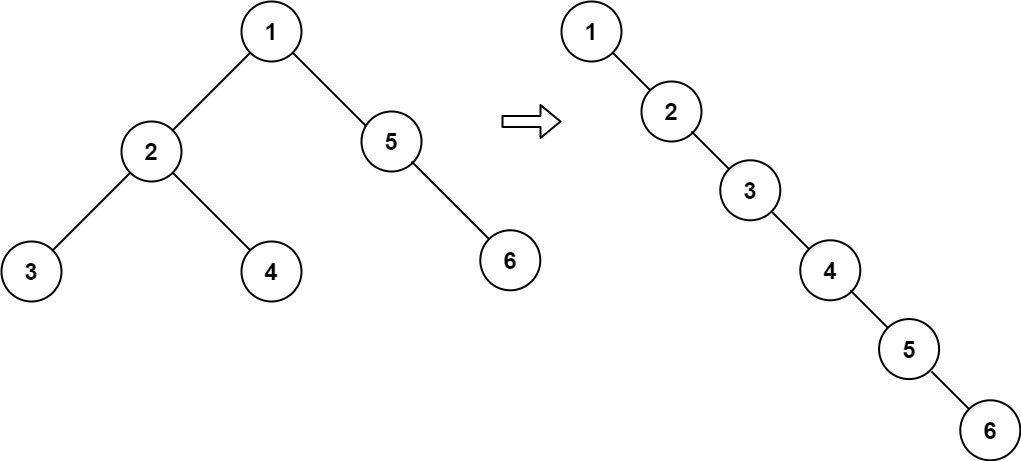
力扣每日一题114:二叉树展开为链表
题目 中等 提示 给你二叉树的根结点 root ,请你将它展开为一个单链表: 展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。展开后的单链表应该与二叉树 先序遍历 顺序相同…...

Linux系统下使用LVM扩展逻辑卷的步骤指南
Linux系统下使用LVM扩展逻辑卷的步骤指南 文章目录 Linux系统下使用LVM扩展逻辑卷的步骤指南前言一、逻辑卷管理(LVM)简介二、扩展逻辑卷步骤1. 检查当前的磁盘布局2. 创建新的分区3. 更新内核的分区表4. 初始化新的物理卷5. 将物理卷添加到卷组6. 调整逻…...
探索AI编程新纪元:从零开始的智能编程之旅
提示:Baidu Comate 智能编码助手是基于文心大模型,打造的新一代编码辅助工具 文章目录 前言AI编程概述:未来已来场景需求:从简单到复杂,无所不包体验步骤:我的AI编程初探试用感受:双刃剑下的深思…...

RustGUI学习(iced)之小部件(三):如何使用下拉列表pick_list?
前言 本专栏是学习Rust的GUI库iced的合集,将介绍iced涉及的各个小部件分别介绍,最后会汇总为一个总的程序。 iced是RustGUI中比较强大的一个,目前处于发展中(即版本可能会改变),本专栏基于版本0.12.1. 概述 这是本专栏的第三篇,主要讲述下拉列表pick_list部件的使用,会…...

【OceanBase诊断调优】—— Unit 迁移问题的排查方法
适用版本:V2.1.x、V2.2.x、V3.1.x、V3.2.x 本文主要介绍 OceanBase 数据集在副本迁移过程中遇到的问题的排查方法。 适用版本 V2.1.x、V2.2.x、V3.1.x、V3.2.x 手动调度迁移问题的排查 OceanBase 数据库的 RootService 模块负责 Unit 迁移的调度,如果…...
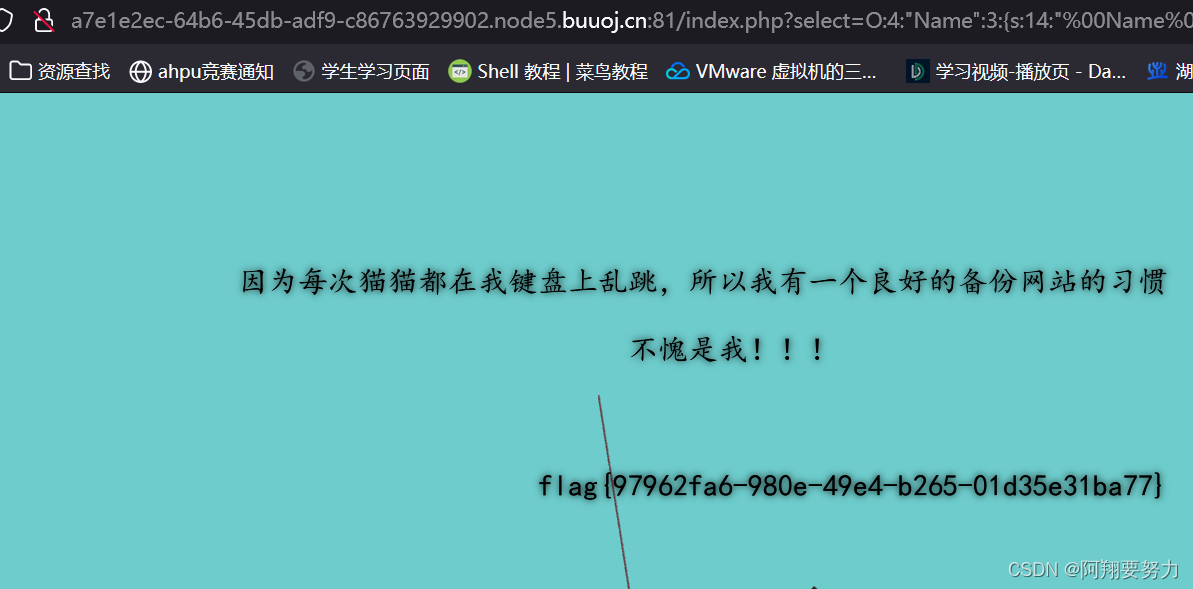
[极客大挑战 2019]PHP
1.通过目录扫描找到它的备份文件,这里的备份文件是它的源码。 2.源码当中涉及到的关键点就是魔术函数以及序列化与反序列化。 我们提交的select参数会被进行反序列化,我们要构造符合输出flag条件的序列化数据。 但是,这里要注意的就是我们提…...
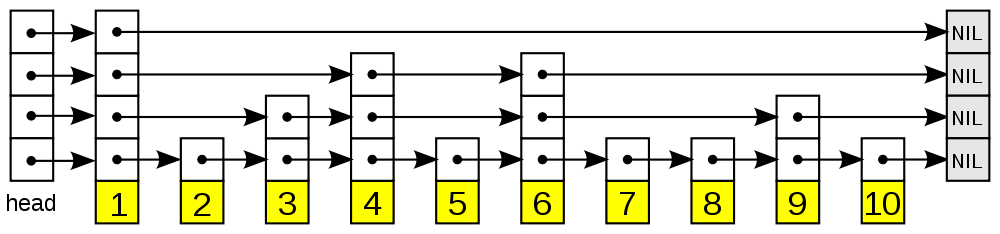
数据结构之跳跃表
跳跃表 跳跃表(skiplist)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— …...

搜维尔科技:动作捕捉解决方案:销售、服务、培训和支持
动作捕捉解决方案:销售、服务、培训和支持 搜维尔科技:动作捕捉解决方案:销售、服务、培训和支持l...
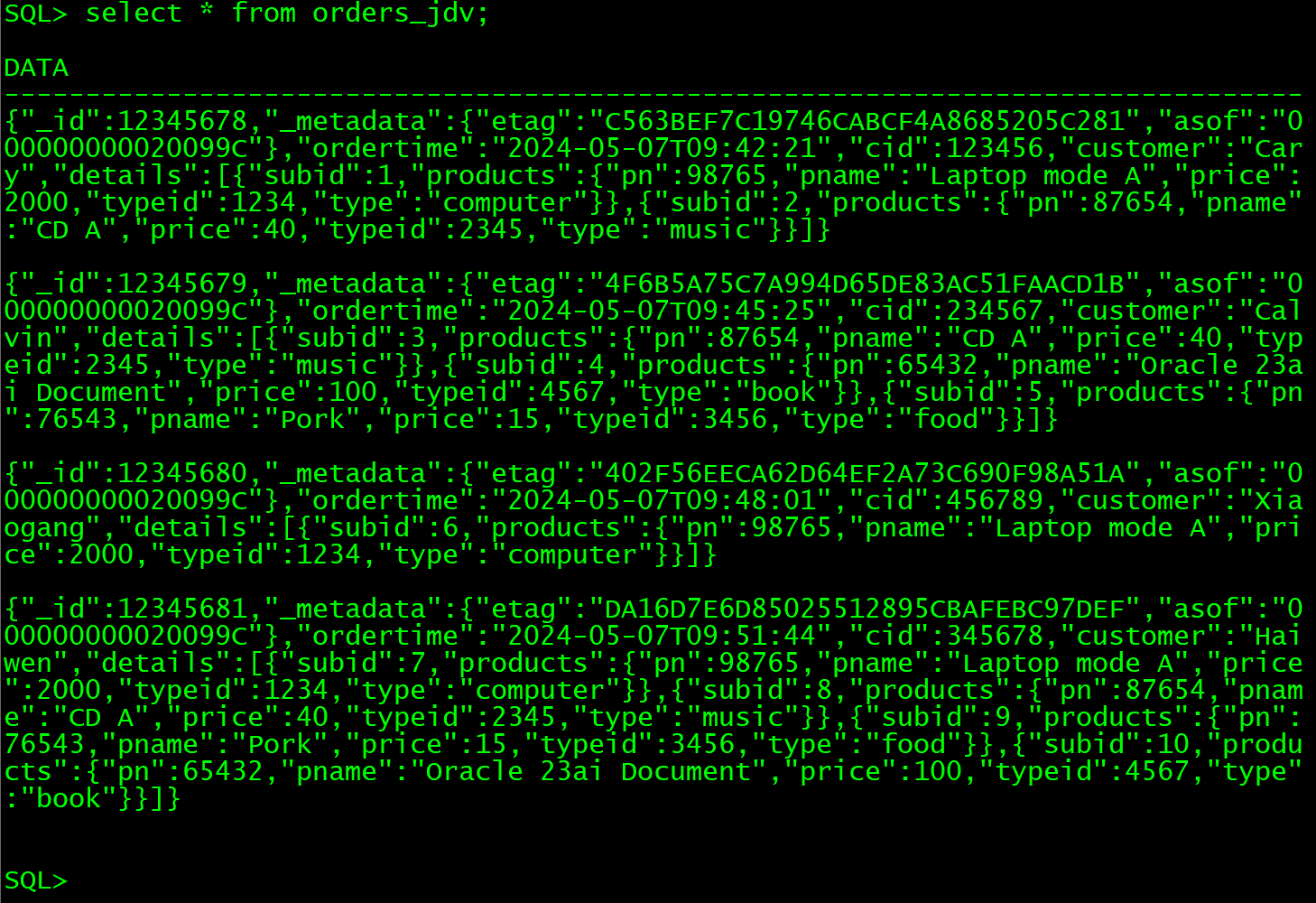
数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20240507)
数据库管理184期 2024-05-07 数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20240507)1 JSON需求2 关系型表设计3 JSON关系型二元性视图3 查询视图总结 数据库管理-第184期 23ai:干掉MongoDB的不一定是另一个JSON数据库(20…...
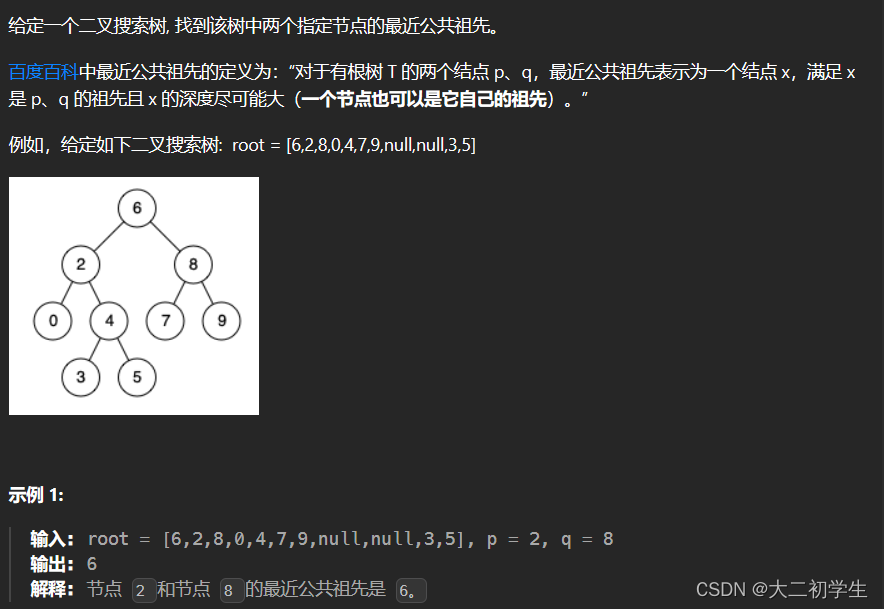
刷代码随想录有感(58):二叉树的最近公共祖先
题干: 代码: class Solution { public:TreeNode* traversal(TreeNode* root, TreeNode* p, TreeNode* q){if(root NULL)return NULL;if(root p || root q)return root;TreeNode* left traversal(root->left, p, q);TreeNode* right traversal(r…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...