【PyTorch】6-可视化(网络结构可视化、CNN可视化、TensorBoard、wandb)
PyTorch:6-可视化
注:所有资料来源且归属于thorough-pytorch(https://datawhalechina.github.io/thorough-pytorch/),下文仅为学习记录
6.1:可视化网络结构
Keras中可以调用model.summary()的API进行模型参数可视化
torchinfo是由torchsummary和torchsummaryX重构出的库,用于可视化网络结构
6.1.1:使用print函数,打印模型基础信息
【案例:resnet18】
模型构建:
import torchvision.models as models
model = models.resnet18()
直接print模型:只能得出基础构件的信息
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))... ...)(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
结果:既不能显示出每一层的shape,也不能显示对应参数量的大小。
6.1.2:使用torchinfo,可视化网络结构
安装:
# 安装方法一
pip install torchinfo
# 安装方法二
conda install -c conda-forge torchinfo
使用:
使用torchinfo.summary()函数,必需的参数分别是model,input_size[batch_size,channel,h,w]。
import torchvision.models as models
from torchinfo import summary
resnet18 = models.resnet18()
# 实例化模型
summary(resnet18, (1, 3, 224, 224))
# 1:batch_size 3:图片的通道数 224: 图片的高宽
结构化输出:
=========================================================================================
Layer (type:depth-idx) Output Shape Param #
=========================================================================================
ResNet -- --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
=========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
=========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
=========================================================================================
注意:使用colab或者jupyter notebook时,想要实现该方法,summary()一定是该单元(即notebook中的cell)的返回值,否则就需要使用print(summary(...))来可视化。
6.2:CNN可视化
可视化内容:可视化特征是如何提取的、提取到的特征的形式、模型在输入数据上的关注点
6.2.1:CNN卷积核可视化
卷积核在CNN中负责提取特征——可视化特征是如何提取的
靠近输入的层提取的特征是相对简单的结构,靠近输出的层提取的特征和图中的实体形状相近
kernel可视化的核心:特定层的卷积核即特定层的模型权重,可视化卷积核即可视化对应的权重矩阵
【案例:VGG11】
【1】加载模型,确定层信息
import torch
from torchvision.models import vgg11model = vgg11(pretrained=True)
print(dict(model.features.named_children()))"""
{'0': Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'1': ReLU(inplace=True),'2': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),'3': Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'4': ReLU(inplace=True),'5': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),'6': Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'7': ReLU(inplace=True),'8': Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'9': ReLU(inplace=True),'10': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),'11': Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'12': ReLU(inplace=True),'13': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'14': ReLU(inplace=True),'15': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),'16': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'17': ReLU(inplace=True),'18': Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),'19': ReLU(inplace=True),'20': MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)}
"""
【2】可视化卷积层的对应参数(第3层)
卷积核对应的应为卷积层(Conv2d)
conv1 = dict(model.features.named_children())['3']
kernel_set = conv1.weight.detach()
num = len(conv1.weight.detach())
print(kernel_set.shape)
"""
torch.Size([128, 64, 3, 3])
"""
for i in range(0,num):i_kernel = kernel_set[i]plt.figure(figsize=(20, 17))if (len(i_kernel)) > 1:for idx, filer in enumerate(i_kernel):plt.subplot(9, 9, idx+1) plt.axis('off')plt.imshow(filer[ :, :].detach(),cmap='bwr')
由于第3层的特征图由64维变为128维,因此共有128*64个卷积核
6.2.2:CNN特征图可视化
特征图:输入的原始图像经过每次卷积层得到的数据
可视化卷积核是为了看模型提取哪些特征,可视化特征图则是为了看模型提取到的特征是什么样子的。
PyTorch提供了一个专用的接口,使得网络在前向传播过程中能够获取到特征图,接口的名称叫hook。
实现过程:
class Hook(object):def __init__(self):self.module_name = []self.features_in_hook = []self.features_out_hook = []def __call__(self,module, fea_in, fea_out):print("hooker working", self)self.module_name.append(module.__class__)self.features_in_hook.append(fea_in)self.features_out_hook.append(fea_out)return Nonedef plot_feature(model, idx, inputs):hh = Hook()model.features[idx].register_forward_hook(hh)# forward_model(model,False)model.eval()_ = model(inputs)print(hh.module_name)print((hh.features_in_hook[0][0].shape))print((hh.features_out_hook[0].shape))out1 = hh.features_out_hook[0]total_ft = out1.shape[1]first_item = out1[0].cpu().clone() plt.figure(figsize=(20, 17))for ftidx in range(total_ft):if ftidx > 99:breakft = first_item[ftidx]plt.subplot(10, 10, ftidx+1) plt.axis('off')#plt.imshow(ft[ :, :].detach(),cmap='gray')plt.imshow(ft[ :, :].detach())
首先实现了一个hook类,之后在plot_feature函数中,将该hook类的对象注册到要进行可视化的网络的某层中。
model在进行前向传播的时候会调用hook的__call__函数,Hook类在此处存储了当前层的输入和输出。
Hook类种的hook(输入为in,输出为out)是一个list,每次前向传播一次,都是调用一次,即 hook 长度会增加1。
6.2.3:CNN class activation map可视化
class activation map (CAM)的作用是判断哪些变量对模型来说是重要的。
在CNN可视化的场景下,即判断图像中哪些像素点对预测结果是重要的。
CAM系列操作的实现可以通过开源工具包pytorch-grad-cam来实现。
- 安装:
pip install grad-cam
- 案例:
加载图片
import torch
from torchvision.models import vgg11,resnet18,resnet101,resnext101_32x8d
import matplotlib.pyplot as plt
from PIL import Image
import numpy as npmodel = vgg11(pretrained=True)
img_path = './dog.png'
# resize操作是为了和传入神经网络训练图片大小一致
img = Image.open(img_path).resize((224,224))
# 需要将原始图片转为np.float32格式并且在0-1之间
rgb_img = np.float32(img)/255
plt.imshow(img)
CAM可视化
from pytorch_grad_cam import GradCAM,ScoreCAM,GradCAMPlusPlus,AblationCAM,XGradCAM,EigenCAM,FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image# 将图片转为tensor
img_tensor = torch.from_numpy(rgb_img).permute(2,0,1).unsqueeze(0)target_layers = [model.features[-1]]
# 选取合适的类激活图,但是ScoreCAM和AblationCAM需要batch_size
cam = GradCAM(model=model,target_layers=target_layers)
targets = [ClassifierOutputTarget(preds)]
# 上方preds需要设定,比如ImageNet有1000类,这里可以设为200
grayscale_cam = cam(input_tensor=img_tensor, targets=targets)
grayscale_cam = grayscale_cam[0, :]
cam_img = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
print(type(cam_img))
Image.fromarray(cam_img)
6.2.4:FlashTorch快速实现CNN可视化
https://github.com/MisaOgura/flashtorch
- 安装
pip install flashtorch
- 可视化梯度
import matplotlib.pyplot as plt
import torchvision.models as models
from flashtorch.utils import apply_transforms, load_image
from flashtorch.saliency import Backpropmodel = models.alexnet(pretrained=True)
backprop = Backprop(model)image = load_image('/content/images/great_grey_owl.jpg')
owl = apply_transforms(image)target_class = 24
backprop.visualize(owl, target_class, guided=True, use_gpu=True)
- 可视化卷积核
import torchvision.models as models
from flashtorch.activmax import GradientAscentmodel = models.vgg16(pretrained=True)
g_ascent = GradientAscent(model.features)# specify layer and filter info
conv5_1 = model.features[24]
conv5_1_filters = [45, 271, 363, 489]g_ascent.visualize(conv5_1, conv5_1_filters, title="VGG16: conv5_1")
6.3:使用TensorBoard可视化训练过程
6.3.1:安装
使用pip安装:
pip install tensorboardX
6.3.2:TensorBoard可视化的基本逻辑
可将TensorBoard看做一个记录员,记录我们指定的数据,包括模型每一层的feature map,权重,训练loss等。
TensorBoard将记录下来的内容保存在一个用户指定的文件夹里,程序不断运行中TensorBoard会不断记录,记录下的内容可以通过网页的形式加以可视化。
6.3.3:TensorBoard的配置和启动
【1】指定保存记录数据的文件夹,调用tensorboard中的SummaryWriter作为记录员
from tensorboardX import SummaryWriter
# from torch.utils.tensorboard import SummaryWriter
# 使用PyTorch自带的tensorboard
writer = SummaryWriter('./runs')
上面的操作实例化SummaryWritter为变量writer,并指定writer的输出目录为当前目录下的"runs"目录。
【2】启动tensorboard
tensorboard --logdir=/path/to/logs/ --port=xxxx
“path/to/logs/"是指定的保存tensorboard记录结果的文件路径
–port是外部访问TensorBoard的端口号,可以通过访问ip:port访问tensorboard
6.3.4:TensorBoard模型结构可视化
【1】定义模型
import torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)self.pool = nn.MaxPool2d(kernel_size = 2,stride = 2)self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))self.flatten = nn.Flatten()self.linear1 = nn.Linear(64,32)self.relu = nn.ReLU()self.linear2 = nn.Linear(32,1)self.sigmoid = nn.Sigmoid()def forward(self,x):x = self.conv1(x)x = self.pool(x)x = self.conv2(x)x = self.pool(x)x = self.adaptive_pool(x)x = self.flatten(x)x = self.linear1(x)x = self.relu(x)x = self.linear2(x)y = self.sigmoid(x)return ymodel = Net()
print(model)"""
Net((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))(flatten): Flatten(start_dim=1, end_dim=-1)(linear1): Linear(in_features=64, out_features=32, bias=True)(relu): ReLU()(linear2): Linear(in_features=32, out_features=1, bias=True)(sigmoid): Sigmoid()
)
"""
可视化模型的思路:给定一个输入数据,前向传播后得到模型的结构,再通过TensorBoard进行可视化
【2】使用add_graph
writer.add_graph(model, input_to_model = torch.rand(1, 3, 224, 224))
writer.close()
6.3.5:TensorBoard图像可视化
- 对于单张图片的显示使用
add_image - 对于多张图片的显示使用
add_images - 有时需要使用
torchvision.utils.make_grid将多张图片拼成一张图片后,用writer.add_image显示
【案例:CIFAR10】
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoadertransform_train = transforms.Compose([transforms.ToTensor()])
transform_test = transforms.Compose([transforms.ToTensor()])train_data = datasets.CIFAR10(".", train=True, download=True, transform=transform_train)
test_data = datasets.CIFAR10(".", train=False, download=True, transform=transform_test)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64)images, labels = next(iter(train_loader))# 仅查看一张图片
writer = SummaryWriter('./pytorch_tb')
writer.add_image('images[0]', images[0])
writer.close()# 将多张图片拼接成一张图片,中间用黑色网格分割
# create grid of images
writer = SummaryWriter('./pytorch_tb')
img_grid = torchvision.utils.make_grid(images)
writer.add_image('image_grid', img_grid)
writer.close()# 将多张图片直接写入
writer = SummaryWriter('./pytorch_tb')
writer.add_images("images",images,global_step = 0)
writer.close()
6.3.6:TensorBoard连续变量可视化
可视化连续变量(或时序变量)的变化过程,通过add_scalar实现
writer = SummaryWriter('./pytorch_tb')
for i in range(500):x = iy = x**2writer.add_scalar("x", x, i) #日志中记录x在第step i 的值writer.add_scalar("y", y, i) #日志中记录y在第step i 的值
writer.close()
如果想在同一张图中显示多个曲线,则需要分别建立存放子路径(使用SummaryWriter指定路径即可自动创建,但需要在tensorboard运行目录下),同时在add_scalar中修改曲线的标签使其一致即可。
writer1 = SummaryWriter('./pytorch_tb/x')
writer2 = SummaryWriter('./pytorch_tb/y')
for i in range(500):x = iy = x*2writer1.add_scalar("same", x, i) #日志中记录x在第step i 的值writer2.add_scalar("same", y, i) #日志中记录y在第step i 的值
writer1.close()
writer2.close()
6.3.7:TensorBoard参数分布可视化
对参数(或向量)的变化,或者对其分布进行研究时,可通过add_histogram实现。
import torch
import numpy as np# 创建正态分布的张量模拟参数矩阵
def norm(mean, std):t = std * torch.randn((100, 20)) + meanreturn twriter = SummaryWriter('./pytorch_tb/')
for step, mean in enumerate(range(-10, 10, 1)):w = norm(mean, 1)writer.add_histogram("w", w, step)writer.flush()
writer.close()
6.3.8:服务器端使用TensorBoard
由于服务器端没有浏览器(纯命令模式),因此需要进行相应的配置,才可以在本地浏览器,使用tensorboard查看服务器运行的训练过程。
方法【1】【2】都是建立SSH隧道,实现远程端口到本机端口的转发。
【1】MobaXterm
- 在MobaXterm点击Tunneling。
- 选择New SSH tunnel。
- 对新建的SSH通道做以下设置,第一栏选择
Local port forwarding,< Remote Server>处填写localhost,< Remote port>处填写6006,tensorboard默认会在6006端口进行显示。也可以根据 tensorboard --logdir=/path/to/logs/ --port=xxxx的命令中的port进行修改,< SSH server>填写连接服务器的ip地址,<SSH login>填写连接的服务器的用户名,<SSH port>填写端口号(通常为22),< forwarded port>填写本地的一个端口号,以便后续进行访问。 - 设定好之后,点击Save,然后Start。再次启动tensorboard,在本地的浏览器输入
http://localhost:6006/对其进行访问。
【2】Xshell
- 连接上服务器后,打开当前会话属性,选择隧道,点击添加。
- 目标主机代表的是服务器,源主机代表的是本地,端口的选择根据实际情况而定。
- 启动tensorboard,在本地127.0.0.1:6006 或者 localhost:6006进行访问。
6.4:使用wandb可视化训练过程
wandb是Weights & Biases的缩写,能自动记录模型训练过程中的超参数和输出指标,然后可视化和比较结果,并快速与其他人共享结果。
6.4.1:安装
【1】使用pip安装
pip install wandb
【2】在官网注册账号并复制API keys:https://wandb.ai/
【3】在本地使用命令登录
wandb login
【4】粘贴API keys
6.4.2:使用
import wandb
wandb.init(project='my-project', entity='my-name')
Quickstart | Weights & Biases Documentation (wandb.ai)
project和entity是在wandb上创建的项目名称和用户名
6.4.3:demo演示
【案例:CIFAR10的图像分类】
【1】导入库
import random # to set the python random seed
import numpy # to set the numpy random seed
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.models import resnet18
import warnings
warnings.filterwarnings('ignore')
【2】初始化wandb
# 初始化wandb
import wandb
wandb.init(project="thorough-pytorch",name="wandb_demo",)
【3】设置超参数
使用wandb.config来设置超参数,这样就可以在wandb的界面上看到超参数的变化。
wandb.config的使用方法和字典类似,可以使用config.key的方式来设置超参数。
# 超参数设置
config = wandb.config # config的初始化
config.batch_size = 64
config.test_batch_size = 10
config.epochs = 5
config.lr = 0.01
config.momentum = 0.1
config.use_cuda = True
config.seed = 2043
config.log_interval = 10 # 设置随机数
def set_seed(seed):random.seed(config.seed) torch.manual_seed(config.seed) numpy.random.seed(config.seed)
【4】构建train和test的pipeline
def train(model, device, train_loader, optimizer):model.train()for batch_id, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)criterion = nn.CrossEntropyLoss()loss = criterion(output, target)loss.backward()optimizer.step()# wandb.log用来记录一些日志(accuracy,loss and epoch), 便于随时查看网路的性能
def test(model, device, test_loader, classes):model.eval()test_loss = 0correct = 0example_images = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)criterion = nn.CrossEntropyLoss()test_loss += criterion(output, target).item()pred = output.max(1, keepdim=True)[1]correct += pred.eq(target.view_as(pred)).sum().item()example_images.append(wandb.Image(data[0], caption="Pred:{} Truth:{}".format(classes[pred[0].item()], classes[target[0]])))# 使用wandb.log 记录你想记录的指标wandb.log({"Examples": example_images,"Test Accuracy": 100. * correct / len(test_loader.dataset),"Test Loss": test_loss})wandb.watch_called = False def main():use_cuda = config.use_cuda and torch.cuda.is_available()device = torch.device("cuda:0" if use_cuda else "cpu")kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}# 设置随机数set_seed(config.seed)torch.backends.cudnn.deterministic = True# 数据预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 加载数据train_loader = DataLoader(datasets.CIFAR10(root='dataset',train=True,download=True,transform=transform), batch_size=config.batch_size, shuffle=True, **kwargs)test_loader = DataLoader(datasets.CIFAR10(root='dataset',train=False,download=True,transform=transform), batch_size=config.batch_size, shuffle=False, **kwargs)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')model = resnet18(pretrained=True).to(device)optimizer = optim.SGD(model.parameters(), lr=config.lr, momentum=config.momentum)wandb.watch(model, log="all")for epoch in range(1, config.epochs + 1):train(model, device, train_loader, optimizer)test(model, device, test_loader, classes)# 本地和云端模型保存torch.save(model.state_dict(), 'model.pth')wandb.save('model.pth')if __name__ == '__main__':main()
其他提供的功能:模型的超参数搜索,模型的版本控制,模型的部署等。
相关文章:
)
【PyTorch】6-可视化(网络结构可视化、CNN可视化、TensorBoard、wandb)
PyTorch:6-可视化 注:所有资料来源且归属于thorough-pytorch(https://datawhalechina.github.io/thorough-pytorch/),下文仅为学习记录 6.1:可视化网络结构 Keras中可以调用model.summary()的API进行模型参数可视化 torchinfo…...

C++容器——map和pair对组
pair(对组) 是一种模板类,允许将两个不同类型的值组合在一起。它由两个数据成员first和second组成,分别用来保存这两个值。 头文件 加头文件 #include<utility> 对于 C11 及以上标准,pair 类型可以在不包含头…...
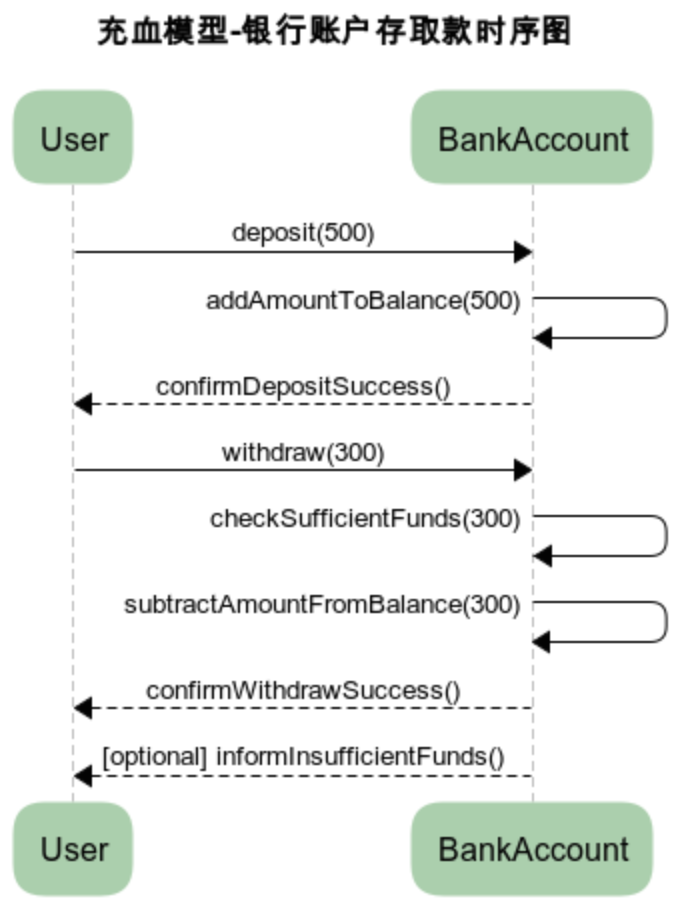
MVC和DDD的贫血和充血模型对比
文章目录 架构区别MVC三层架构DDD四层架构 贫血模型代码示例 充血模型代码示例 架构区别 MVC三层架构 MVC三层架构是软件工程中的一种设计模式,它将软件系统分为 模型(Model)、视图(View)和控制器(Contro…...

如何利用AI提高内容生产效率?
如何利用AI提高内容生产效率? 简介:探讨如何通过AI技术提升内容生产的效率和质量。 方向一:自动化内容生成 自动化内容生成是一种利用人工智能技术来自动创建文本、图像、音频等内容的方法。 以下是一些常见的自动化内容生成方式: 基于…...

C++ stack、queue以及deque
1、stack和queue常用接口 严格来说栈和队列的实现是容器适配器 1、常用接口: 栈:top、push、pop、size、emptystack - C Reference (cplusplus.com) 队列:top、push、pop、swap、size、emptyqueue - C Reference (cplusplus.com) 2、deque&a…...

科沃斯,「扫地茅」荣光恐难再现
作者 | 辰纹 来源 | 洞见新研社 科沃斯恐怕已经很难再回到被市场誉为“扫地茅”时的荣光了。 不久前,科沃斯发布2023年财报,报告期内营业收入155亿,同比仅增长1.16%,归母净利润6.12亿元,同比下降63.96%,直…...

双向BFS算法学习
双向BFS算法学习 推荐练习题 力扣“127”题:单词接龙 “752”题:打开轮盘锁 这里推荐一篇力扣题解 双向BFS 这里使用打开轮盘锁的题干进行举例: 你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: ‘0’, ‘1’, ‘2’,…...
C++从入门到精通---模版
文章目录 泛型编程函数模版模版参数的匹配原则类模版类模版的定义格式类模版的实例化 总结 泛型编程 泛型编程是一种编程范式,旨在实现通用性和灵活性。它允许在编写代码时使用参数化类型,而不是具体的类型,从而使代码更加灵活和可重用。 在…...
Unity数据持久化之Json
Json概述 Json是什么? 全称:JavaScript对象简谱(JavaScript Object Notation) Json是国际通用的一种轻量级的数据交换格式 主要在网络通讯中用于传输数据,或本地数据存储和读取 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率 我们一般使用Json文件来…...

LeetCode 35.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target 5 输出: 2 示例 2: 输入…...
速来get!多微信聚合聊天功能大揭秘!
随着网络时代的发展,微信成为了职场中不可或缺的沟通工具,很多人都有着多个微信号,而要想高效管理这些账号,那就少不了工具的帮忙。 通过微信管理系统,可以轻松实现多个微信号聚合聊天,提高沟通效率。 1、…...
【跟我学RISC-V】(一)认识RISC-V指令集并搭建实验环境
目录 写在前面 一、RISC-V指令集简介 1、什么是ISA 2、有哪些ISA 3、CISC和RISC 4、什么是RISC-V 1. RISC 的起源 2. RISC-I 和 RISC-II 3. RISC 发展和商业化 4. RISC-V 的诞生 5、RISC-V生态的特点 6、RISC-V指令集的特点 1. 开源 2. 社区化 3. 设计简洁 4. 模…...

如何使用google.protobuf.Struct?
google.golang.org/protobuf/types/known/structpb 包提供了一种方式来创建和操作 google.protobuf.Struct 类型的数据。google.protobuf.Struct 是一种灵活的数据类型,可以表示任何结构化数据。 以下是如何使用 structpb 包的一些示例: 创建 Struct&a…...

Vue3 + TS + Element-Plus 封装的 Dialog 弹窗组件
弹窗组件中自定义了header 增加了全屏,svg-icon 没有的话可能会报错,换成自己的图标就可以 <template><el-dialog:dialogHeight"dialogHeight":title"dialogTitle"class"dialog min-w-70"v-model"dialogVi…...

大数据技术概述_4.大数据的应用领域
1.制造业的应用 制造业目前正在向信息化和自动化的方向发展。在产品的设计、生产和销售中,越来越多的企业使用计算机辅助设计(CAD)、计算机辅助制造(CAM)等软件,数控机床、传感器等设备,物料需求…...
ABB RobotStudio学习记录(一)新建工作站
RobotStudio新建工作站 最近遇到 虚拟示教器和 Rapid 代码不能控制 视图中机械臂的问题,其实是由于机械臂和工作站不匹配。以下是解决方法。 名称版本Robot Studio6.08 新建一个”空工作站“; 在目标位置新建一个目标文件夹 C:\solution\test࿰…...
)
雷达通信一体化(含WCSP2023会议论文集学习)
雷达通信一体化,又称雷达通信融合(RADCOM),是一种新兴的技术,它将雷达(通常用于探测和跟踪目标)和无线通信(用于传输信息)的功能结合在一起。这种融合技术的主要目标是提…...

特斯拉擎天柱机器人:工厂自动化的未来
随着技术的进步,工业自动化已经逐步进入了一个新的纪元。特斯拉最近公布的擎天柱机器人Optimus的演示,不仅仅展示了一个高科技机器人的能力,更是向我们揭示了未来工厂的可能性。 特斯拉擎天柱机器人的功能展示 马斯克在最新的演示中向我们展…...
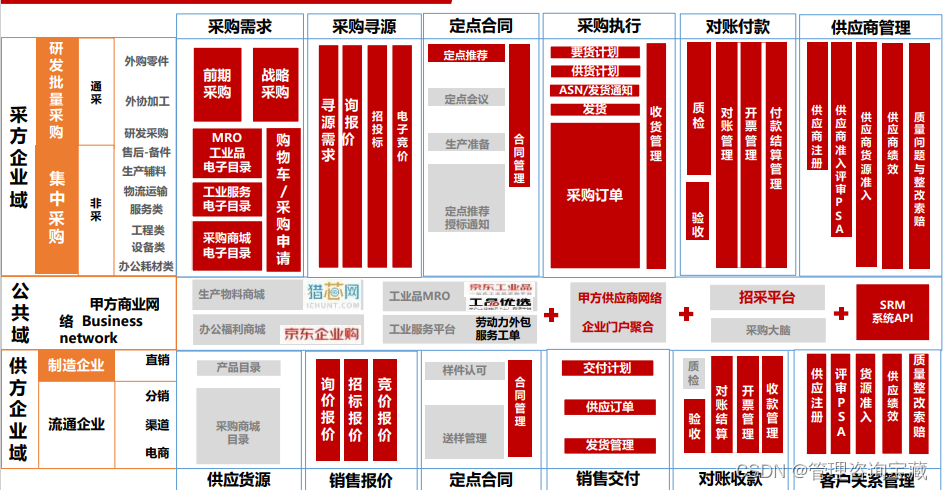
【管理咨询宝藏93】大型制造集团数字化转型设计方案
【管理咨询宝藏93】大型制造集团数字化转型设计方案 【格式】PDF版本 【关键词】国际咨询公司、制造型企业转型、数字化转型 【核心观点】 - 235页大型制造型集团数字化转型方案设计!细节非常详尽,图表丰富! - 系统架构必须采用成熟、具有国…...

【数学建模】天然肠衣搭配问题
2011高教社杯全国大学生数学建模竞赛D题 天然肠衣(以下简称肠衣)制作加工是我国的一个传统产业,出口量占世界首位。肠衣经过清洗整理后被分割成长度不等的小段(原料),进入组装工序。传统的生产方式依靠人工…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...