gitlab集群高可用架构拆分部署
目录
前言
负载均衡器准备
外部负载均衡器
内部负载均衡器
(可选)Consul服务
Postgresql拆分
1.准备postgresql集群
手动安装postgresql插件
2./etc/gitlab/gitlab.rb配置
3.生效配置文件
Redis拆分
1./etc/gitlab/gitlab.rb配置
2.生效配置文件
Gitaly拆分
1.Praefect Postgresql数据库配置
2.配置Praefect
2.1.部署准备&注意事项
2.2./etc/gitlab/gitlab.rb配置
2.3.生效配置文件
2.4.验证Praefect与gitaly的连接配置状态
3.配置gitaly
3.1.部署准备&注意事项
3.2. /etc/gitlab/gitlab.rb配置
3.3.创建git-data目录
3.4.生效配置文件
NFS配置
Sidekiq拆分
1.部署准备&注意事项
2./etc/gitlab/gitlab.rb配置
3.生效配置文件
Gitlab Rails拆分
1.部署准备&注意事项
2./etc/gitlab/gitlab.rb配置
3.生效配置文件
4.启用增量日志
4.1. 要启用增量日志记录
4.2.要禁用增量日志记录
5.配置确认
5.1.确认节点可以连接到 Gitaly
5.2.(可选)从 Gitaly 服务器确认 Gitaly 可以对内部 API 执行回调
总结
前言
整体架构参考:Reference architecture: up to 50,000 users | GitLab
为了简化部署,Postgresql、Redis等,会使用云厂商提供的服务

(引用gitlab官网架构图)
负载均衡器准备
可以考虑使用云厂商的负载均衡器,提供7层和4层的负载均衡。
如果只是内网使用,或者测试场景。外部负载均衡器和内部负载均衡器可以考虑使用同一个负载均衡器,以节省资源。
配置外部负载均衡器:Reference architecture: up to 50,000 users | GitLab
配置内部负载均衡器:Reference architecture: up to 50,000 users | GitLab
外部负载均衡器
| LB端口 | 后端端口 | 协议 | 说明 |
|---|---|---|---|
| 80 | 80 | HTTP | |
| 443 | 80/443 | HTTPS/TCP | 1.如果在LB卸载SSL证书,则可以通过HTTPS协议,转发至后端80端口 2.如果需要在后端gitlab的nginx卸载证书,则可以通过TCP协议,转发至后端443端口 |
内部负载均衡器
(可选)Consul服务
官方文档中对于Consul服务在gitlab中的作用定位是:数据库服务发现。
由于本示例使用的Postrgresql和Redis都是使用云厂商提供的服务,所以跳过Consul的部署。
Consul部署参考:Reference architecture: up to 50,000 users | GitLab
Consul:https://archives.docs.gitlab.com/16.7/ee/administration/reference_architectures/index.html#available-reference-architectures

Postgresql拆分
参考文档:
1.gitlab版本和支持的postgresql版本对应关系:Installation system requirements | GitLab
2.配置外部postgresql:Configure GitLab using an external PostgreSQL service | GitLab
以下步骤默认已有高可用的pgstgresql数据库
1.准备postgresql集群
- 可以选择云厂商提供的pg集群,根据数据库需求文档,创建合适版本的postgresql高可用集群。
- 创建gitlab用户
- 创建数据库gitlabhq_production,并配置owner为gitlab用户
- 开启插件:pg_trgm、btree_gist、plpgsql
手动安装postgresql插件
#安装插件
gitlabhq_production=# CREATE EXTENSION IF NOT EXISTS pg_trgm
gitlabhq_production=# CREATE EXTENSION IF NOT EXISTS btree_gist
gitlabhq_production=# CREATE EXTENSION IF NOT EXISTS plpgsql#查看插件
gitlabhq_production=# \dx
2./etc/gitlab/gitlab.rb配置
#关闭内置postgresql
postgresql['enable'] = false#连接postgresql配置信息
gitlab_rails['db_adapter'] = 'postgresql'
gitlab_rails['db_encoding'] = 'unicode'
gitlab_rails['db_database'] = 'gitlabhq_production'
gitlab_rails['db_username'] = 'gitlab'
gitlab_rails['db_password'] = 'your_password'
gitlab_rails['db_host'] = 'your_pg_host'
gitlab_rails['db_port'] = 5432
3.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启postgresql,生效TCP端口
gitlab-ctl restartRedis拆分
参考文档:
1.redis版本选择:Installation system requirements | GitLab
2.配置外部redis:Redis replication and failover providing your own instance | GitLab
3.redis驱逐策略:Redis replication and failover providing your own instance | GitLab
- 可以选择云厂商提供的redis,16.x版本的gitlab建议使用6.2及以上的redis版本
- 特别不建议使用Redis集群,单可以使用高可用的Redis Standalone
- 配置适合的驱逐模式
1./etc/gitlab/gitlab.rb配置
#关闭内置redis服务
redis['enable'] = false#配置连接外部redis服务胚子和
gitlab_rails['redis_host'] = "your_redis_host"
gitlab_rails['redis_port'] = redis_port
gitlab_rails['redis_password'] = "your_redis_password"2.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启
gitlab-ctl restart / gitlab-ctl restart redisGitaly拆分
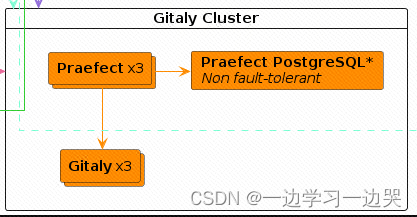
1.Praefect Postgresql数据库配置
1.Praefect数据库配置:Reference architecture: up to 50,000 users | GitLab
Praefect 是 Gitaly Cluster 的路由和事务管理器,需要自己的数据库服务器来存储有关 Gitaly Cluster 状态的数据。
如果您想要高可用性设置,Praefect 需要第三方 PostgreSQL 数据库。
- 已拥有postgresql(复用gitlabhq_production库使用的postgresql)
- 创建praefect用户
- 创建数据库praefect_production,并配置owner为praefect用户
#登陆数据库,创建praefect用户
CREATE ROLE praefect WITH LOGIN CREATEDB PASSWORD '<praefect_postgresql_password>';#切换praefect用户登陆数据库
psql -U praefect -d template1 -h POSTGRESQL_SERVER_ADDRESS#创建数据库praefect_production
CREATE DATABASE praefect_production WITH ENCODING=UTF8;#查看数据库创建结果
\l
2.配置Praefect
1.配置Praefect:
Reference architecture: up to 50,000 users | GitLab
Configure Gitaly Cluster | GitLab
2.1.部署准备&注意事项
- 从您配置的第一个Linux包节点复制/etc/gitlab/gitlab-securts.json文件,并在此服务器上添加或替换同名文件。如果这是您正在配置的第一个Linux包节点,则可以跳过此步骤。
- Praefect必须部署在奇数个3个节点或更高节点中。这是为了确保节点可以将投票作为法定人数的一部分。
- Praefect需要连接Postgresql。
- Praefect 需要运行一些数据库迁移,就像主 GitLab 应用程序一样。为此,您应该仅选择一个 Praefect 节点来运行迁移,也称为部署节点。必须先配置此节点,然后再配置其他节点。
2.2./etc/gitlab/gitlab.rb配置
Praefect 需要运行一些数据库迁移,就像主 GitLab 应用程序一样。为此,您应该仅选择一个 Praefect 节点来运行迁移,也称为部署节点。必须先配置此节点,然后再配置其他节点,如下所示:
- 在/etc/gitlab/gitlab.rb文件中,将praefect['auto_migrate']设置值从更改false为true
- 要确保数据库迁移仅在重新配置期间运行,而不是在升级时自动运行,请运行:
sudo touch /etc/gitlab/skip-auto-reconfigure
- name: 'default'的值,需要和git_data_dirs配置中的name一致。
- storage: 'gitaly-1'...,需要和每个gitaly节点的gitaly['configuration'][:storage]中的name一致。
# Avoid running unnecessary services on the Praefect server
gitaly['enable'] = false
postgresql['enable'] = false
redis['enable'] = false
nginx['enable'] = false
puma['enable'] = false
sidekiq['enable'] = false
gitlab_workhorse['enable'] = false
prometheus['enable'] = false
alertmanager['enable'] = false
gitlab_exporter['enable'] = false
gitlab_kas['enable'] = false# Praefect Configuration
praefect['enable'] = true# Prevent database migrations from running on upgrade automatically
praefect['auto_migrate'] = false
gitlab_rails['auto_migrate'] = false# Configure the Consul agent
#consul['enable'] = true
## Enable service discovery for Prometheus
#consul['monitoring_service_discovery'] = true# START user configuration
# Please set the real values as explained in Required Information section
#praefect['configuration'] = {# ...listen_addr: '0.0.0.0:2305',auth: {# ...## Praefect External Token# This is needed by clients outside the cluster (like GitLab Shell) to communicate with the Praefect clustertoken: '<praefect_external_token>',},# Praefect Database Settingsdatabase: {host: 'POSTGRESQL_HOST',user: 'praefect',port: 5432,password: 'PRAEFECT_SQL_PASSWORD',dbname: 'praefect_production',},# Praefect Virtual Storage config# Name of storage hash must match storage name in git_data_dirs on GitLab# server ('praefect') and in gitaly['configuration'][:storage] on Gitaly nodes ('gitaly-1')# name: 'default'的值,需要和git_data_dirs配置中的name一致# storage: 'gitaly-1'...,需要和每个gitaly节点的gitaly['configuration'][:storage]中的name一致virtual_storage: [{# ...name: 'default',node: [{storage: 'gitaly-1',address: 'tcp://10.6.0.91:8075',token: '<praefect_internal_token>'},{storage: 'gitaly-2',address: 'tcp://10.6.0.92:8075',token: '<praefect_internal_token>'},{storage: 'gitaly-3',address: 'tcp://10.6.0.93:8075',token: '<praefect_internal_token>'},],},],# Set the network address Praefect will listen on for monitoringprometheus_listen_addr: '0.0.0.0:9652',
}# Set the network address the node exporter will listen on for monitoring
#node_exporter['listen_address'] = '0.0.0.0:9100'## The IPs of the Consul server nodes
## You can also use FQDNs and intermix them with IPs
#consul['configuration'] = {
# retry_join: %w(10.6.0.11 10.6.0.12 10.6.0.13),
#}
#
# END user configuration2.3.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启
gitlab-ctl restart / gitlab-ctl restart praefect2.4.验证Praefect与gitaly的连接配置状态
Praefect和Gitlay都配置完成后,可以连接到Praefect节点上执行命令进行验证
sudo /opt/gitlab/embedded/bin/praefect -config /var/opt/gitlab/praefect/config.toml dial-nodes3.配置gitaly
1.配置gitaly:
Reference architecture: up to 50,000 users | GitLab
Configure Gitaly Cluster | GitLab
3.1.部署准备&注意事项
- 从您配置的第一个Linux包节点复制/etc/gitlab/gitlab-securts.json文件,并在此服务器上添加或替换同名文件。如果这是您正在配置的第一个Linux包节点,则可以跳过此步骤。
3.2. /etc/gitlab/gitlab.rb配置
#开启gitaly服务
gitaly['enable'] = true#
gitaly['configuration'] = {#配置gitaly服务监听地址listen_addr: '0.0.0.0:8075',#与Praefect服务中的PRAEFECT_INTERNAL_TOKEN需要一致auth: {token: 'PRAEFECT_INTERNAL_TOKEN',},#配置存储地址,每个gitaly服务应该有不一样的name('gitaly-1')storage: [{name: 'gitaly-1',path: '/var/opt/gitlab/git-data/repositories',},],
}storage配置方法二:
可以在同一配置中包括所有节点的数据目录,因为Praefect只会根据自身配置文件中提供的地址路由(如:storage: 'gitaly-1')请求。
gitaly['configuration'] = {# ...storage: [{name: 'gitaly-1',path: '/var/opt/gitlab/git-data/repositories',},{name: 'gitaly-2',path: '/var/opt/gitlab/git-data/repositories',},{name: 'gitaly-3',path: '/var/opt/gitlab/git-data/repositories',},],
}3.3.创建git-data目录
gitaly-data目录需要git用户拥有权限,否则会报错。
mkdir -p /var/opt/gitlab/git-data/repositorieschown git: /var/opt/gitlab/git-data/repositories3.4.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启
gitlab-ctl restart / gitlab-ctl restart gitalyNFS配置
后续拆分Sidekiq & GitLab Rails集群需要用到NFS共享一些目录
Using NFS with GitLab | GitLab
gitlab官方不建议使用云服务商提供的NFS服务,会对影响有不可预估的影响。
部署NFS server可参考:https://docs.gitlab.com/ee/administration/nfs.html#nfs-server
(本问为了方便,没有部署NFS server,直接是有云服务商提供的NFS服务)
这边不得不吐槽一下官网文档,踩坑踩的很痛苦!
- 文档写有4个路径需要NFS共享,给出来的表格只列出来3个。而一番google之后,实际上最多有5个路径需要NFS共享。
- git-data的路径为什么要共享?也没说清楚。gitaly cluster配置中也没有提到任何需要配置NFS的地方。并且通过Praefect可以配置复制因子来看,gitaly node上存的仓库数据并不一定完全一样的,更像是分布式存储。那为什么需要NFS来共享仓库数据目录?用NFS共享和不用NFS共享的区别是什么?只能自己去探索?
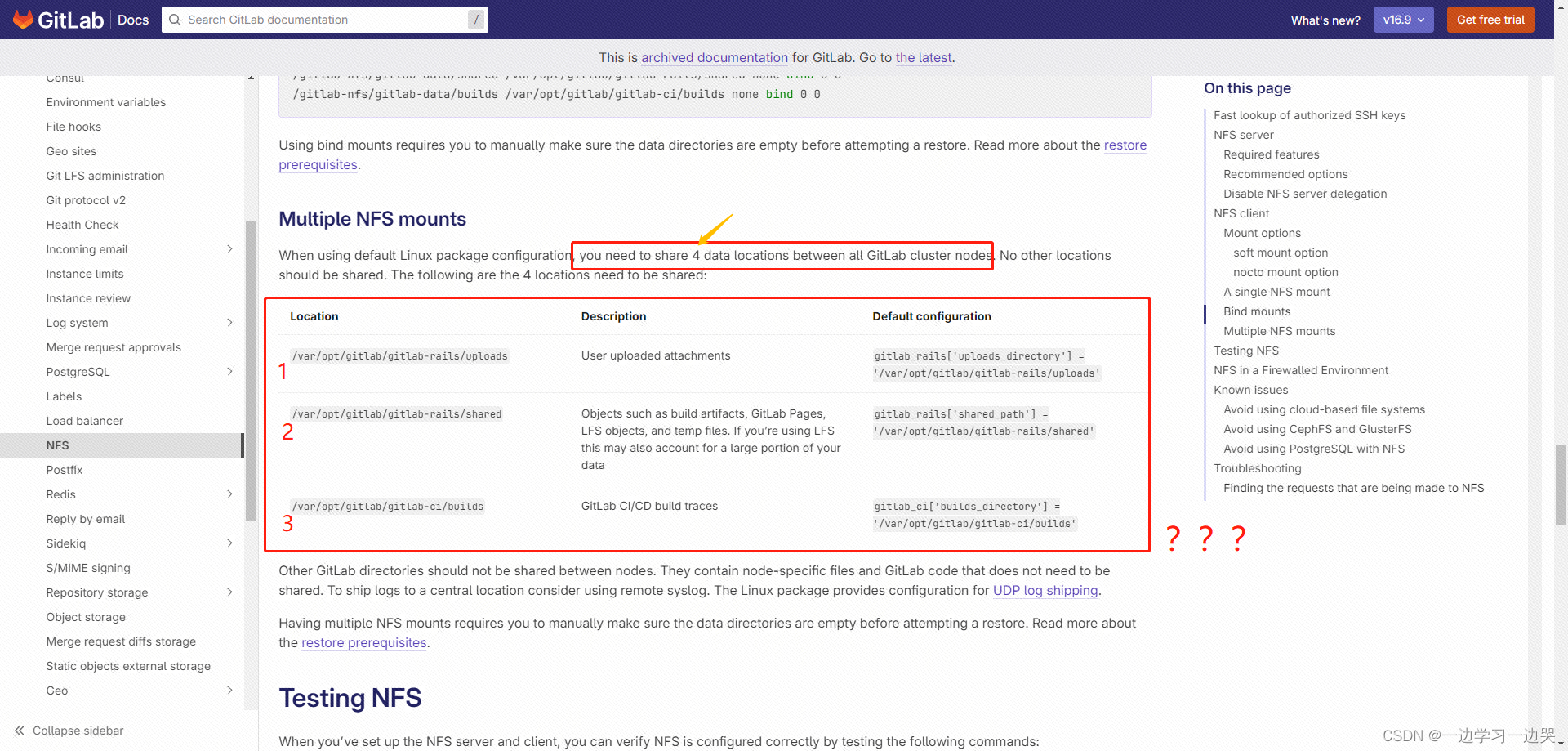
| 位置 | 描述 | 默认配置 |
|---|---|---|
| /var/opt/gitlab/gitlab-rails/uploads | 用户上传的附件 | gitlab_rails['uploads_directory'] = '/var/opt/gitlab/gitlab-rails/uploads' |
| /var/opt/gitlab/gitlab-rails/shared | 诸如构建工件、GitLab 页面、LFS 对象和临时文件等对象。如果您使用 LFS,这也可能占您数据的很大一部分 | gitlab_rails['shared_path'] = '/var/opt/gitlab/gitlab-rails/shared' |
| /var/opt/gitlab/gitlab-ci/builds | GitLab CI/CD 构建跟踪 | gitlab_ci['builds_directory'] = '/var/opt/gitlab/gitlab-ci/builds' |
| /var/opt/gitlab/.ssh | (*可选)SSH authorized_keys文件和用于从其他一些Git服务导入存储库的密钥 | user['home'] = '/var/opt/gitlab/' |
| /var/opt/gitlab/git-data | (*可选)Git存储库数据。这将占你数据的很大一部分。 | git_data_dirs({"default" => "/var/opt/gitlab/git-data"}) |
(可选)/var/opt/gitlab/.ssh
如果没有使用NFS共享此目录,用户上传的public key会存放再sidekiq其中的一个节点的authorized_keys文件中,但是此文件需要在Gitlab Rails集群的每个节点上都有相同的文件。否则,通过ssh的所有操作都将因没有权限而失败(如git clone ...)。
那为什么说是可选?官网提到了“Fast lookup of authorized SSH keys”,通过修改OpenSSH的配置文件(/etc/ssh/sshd_config),可以将原本从authorized_keys查找SSH key,改为从数据库中查找。各人觉得这个方法更合适。
具体配置方式:Fast lookup of authorized SSH keys in the database | GitLab
(可选)/var/opt/gitlab/git-data
为什么这项也是可选?从官网文档中提到可以配置复制因子来看,gitaly cluster上存储的仓库数据,对我来说 gitaly cluster看上去像是可以作为分布式存储。那就不需要NFS来做数据共享。
- Praefect不配置复制因子(default_replication_factor未设置),gitlay集群之间节点会互相同步数据,保持数据一致。
- 官网文档中提到,对于大性的gitaly cluster(多节点),将存储库复制到每个存储节点是不明智的,通常复制因子3就够了,过高的复制因子会对存储容量造成压力。意思就是说,不将存储库复制到每个存储节点,那么gitaly cluster可以通过增加node节点来横向扩容存储量;反之,每个节点数据都一样,则就意味着只能纵向扩容存储量。
- (自己猜想)为什么NFS中,官网提到需要共享git-data目录?在gitaly节点之间用NFS共享数据之后,就省去了在不配置复制因子时,节点之间相互同步数据的动作。也许是这样?
1、2点在官网文档中都可以得到印证,第3点是个人根据官网文档的猜想,目前官网文档中没有明确指出为什么要用NFS共享git-data目录。接下来我会自己测试一下,有结果我会继续更新。
Sidekiq拆分
拆分Sidekiq:
Reference architecture: up to 3,000 users | GitLab
Configure an external Sidekiq instance | GitLab
1.部署准备&注意事项
- 从您配置的第一个Linux包节点复制/etc/gitlab/gitlab-securts.json文件,并在此服务器上添加或替换同名文件。如果这是您正在配置的第一个Linux包节点,则可以跳过此步骤。
- Sidekqi需要连接Redis、Postgresql、Gitaly。数据对象建议使用对象存储,替代NFS。所以也需要连接对象存储。
- 如用NFS共享目录,提前将NFS挂载到对应目录(配置文件中示例为:“/gitlab-nfs/xxx”)
2./etc/gitlab/gitlab.rb配置
# https://docs.gitlab.com/omnibus/roles/#sidekiq-rolesroles(["sidekiq_role"])#### To maintain uniformity of links across nodes, the## `external_url` on the Sidekiq server should point to the external URL that users## use to access GitLab. This can be either:#### - The `external_url` set on your application server.## - The URL of a external load balancer, which routes traffic to the GitLab application server.##external_url 'https://gitlab.example.com'# Configure the gitlab-shell API callback URL. Without this, `git push` will# fail. This can be your 'front door' GitLab URL or an internal load# balancer.gitlab_rails['internal_api_url'] = 'GITLAB_URL'#gitlab_shell['secret_token'] = 'SHELL_TOKEN'############################################ Redis ############################################# Must be the same in every sentinel node.#redis['master_name'] = 'gitlab-redis' # Required if you have setup redis cluster## The same password for Redis authentication you set up for the master node.#redis['master_password'] = '<redis_master_password>'### If redis is running on the main Gitlab instance and you have opened the TCP port as above add the followinggitlab_rails['redis_host'] = '<redis_host>'gitlab_rails['redis_port'] = 6379gitlab_rails['redis_password'] = "<redis_password>"########################################## Gitaly ############################################ Replace <gitaly_token> with the one you set up, see## https://docs.gitlab.com/ee/administration/gitaly/configure_gitaly.html#about-the-gitaly-tokengit_data_dirs({"default" => {"gitaly_address" => "tcp://<praefect_lb_host>:2305","gitaly_token" => "<praefect_external_token>"}})########################################## Postgres ########################################### Replace <database_host> and <database_password>gitlab_rails['db_host'] = '<database_host>'gitlab_rails['db_port'] = 5432gitlab_rails['db_password'] = '<database_password>'## Prevent database migrations from running on upgrade automaticallygitlab_rails['auto_migrate'] = false########################################## Sidekiq configuration ##########################################sidekiq['enable'] = truesidekiq['listen_address'] = "0.0.0.0"## Set number of Sidekiq queue processes to the same number as available CPUssidekiq['queue_groups'] = ['*'] * 4## Set number of Sidekiq threads per queue process to the recommend number of 20sidekiq['max_concurrency'] = 20gitlab_rails['uploads_directory'] = '/gitlab-nfs/gitlab-data/uploads'gitlab_rails['shared_path'] = '/gitlab-nfs/gitlab-data/shared'gitlab_ci['builds_directory'] = '/gitlab-nfs/gitlab-data/builds'要确保数据库迁移仅在重新配置期间运行,而不是在升级时自动运行,请运行:
sudo touch /etc/gitlab/skip-auto-reconfigure
3.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启
gitlab-ctl restartGitlab Rails拆分
1.部署准备&注意事项
- 从您配置的第一个Linux包节点复制/etc/gitlab/gitlab-securts.json文件,并在此服务器上添加或替换同名文件。如果这是您正在配置的第一个Linux包节点,则可以跳过此步骤。
- 从您配置的第一个Linux包节点复制SSH主机密钥(所有密钥的名称格式均为/etc/ssh/ssh_host_*_key*),并在此服务器上添加或替换相同名称的文件。这确保了当用户遇到负载平衡的Rails节点时,不会向用户抛出主机不匹配错误。如果这是您正在配置的第一个Linux包节点,则可以跳过此步骤。
- Rails需要连接Redis、Postgresql、Gitaly。数据对象建议使用对象存储,替代NFS。所以也需要连接对象存储。
- 如用NFS共享目录,提前将NFS挂载到对应目录(配置文件中示例为:“/gitlab-nfs/xxx”)
2./etc/gitlab/gitlab.rb配置
external_url 'https://gitlab.example.com'# git_data_dirs get configured for the Praefect virtual storage
# Address is Internal Load Balancer for Praefect
# Token is praefect_external_token
git_data_dirs({"default" => {"gitaly_address" => "tcp://<praefect_lb_host>:2305", # internal load balancer IP <praefect_service>"gitaly_token" => '<praefect_external_token>'}
})## Disable components that will not be on the GitLab application server
roles(['application_role'])
gitaly['enable'] = false
nginx['enable'] = true
sidekiq['enable'] = false## PostgreSQL connection details
# Disable PostgreSQL on the application node
postgresql['enable'] = false
gitlab_rails['db_host'] = '10.6.0.20' # internal load balancer IP
gitlab_rails['db_port'] = 6432
gitlab_rails['db_password'] = '<postgresql_user_password>'# Prevent database migrations from running on upgrade automatically
gitlab_rails['auto_migrate'] = false## Redis connection details
gitlab_rails['redis_host'] = 'redis_host'
gitlab_rails['redis_port'] = 6379
gitlab_rails['redis_password'] = "redis_password"# Set the network addresses that the exporters used for monitoring will listen on
#node_exporter['listen_address'] = '0.0.0.0:9100'
#gitlab_workhorse['prometheus_listen_addr'] = '0.0.0.0:9229'
#sidekiq['listen_address'] = "0.0.0.0"
puma['listen'] = '0.0.0.0'## Uncomment and edit the following options if you have set up NFS
##
## Prevent GitLab from starting if NFS data mounts are not available
##
#high_availability['mountpoint'] = '/var/opt/gitlab/git-data'
##
## Ensure UIDs and GIDs match between servers for permissions via NFS
##
#user['uid'] = 9000
#user['gid'] = 9000
#web_server['uid'] = 9001
#web_server['gid'] = 9001
#registry['uid'] = 9002
#registry['gid'] = 9002gitlab_rails['uploads_directory'] = '/gitlab-nfs/gitlab-data/uploads'
gitlab_rails['shared_path'] = '/gitlab-nfs/gitlab-data/shared'
gitlab_ci['builds_directory'] = '/gitlab-nfs/gitlab-data/builds'要确保数据库迁移仅在重新配置期间运行,而不是在升级时自动运行,请运行:
touch /etc/gitlab/skip-auto-reconfigure
3.生效配置文件
#reconfigure生效配置文件
gitlab-ctl reconfigure#重启
gitlab-ctl restart4.启用增量日志
GitLab Runner 以块的形式返回作业日志,Linux 包默认将这些日志临时缓存在磁盘上 /var/opt/gitlab/gitlab-ci/builds,即使在使用统一对象存储时也是如此。作业完成后,后台作业将归档作业日志。默认情况下,日志将移至工件目录,或者如果配置,则移至对象存储。
使用默认配置时,虽然支持通过 NFS 共享此目录(作业日志),但建议通过启用增量日志记录(未部署 NFS 节点时需要)来避免使用 NFS。增量日志记录使用Redis而不是磁盘空间来临时缓存作业日志。
启用增量日志:Job logs | GitLab
4.1. 要启用增量日志记录
#打开Rails控制台
gitlab-rails console#启用功能标志
#正在运行的作业的日志继续写入磁盘,但新作业使用增量日志记录。
Feature.enable(:ci_enable_live_trace)4.2.要禁用增量日志记录
#打开Rails控制台
gitlab-rails console#禁用功能标志
#正在运行的作业继续使用增量日志记录,但新作业会写入磁盘。
Feature.disable(:ci_enable_live_trace)5.配置确认
5.1.确认节点可以连接到 Gitaly
确认节点可以连接到Gitaly
sudo gitlab-rake gitlab:gitaly:check在gitlay节点tail查看请求日志
gitlab-ctl tail gitaly
5.2.(可选)从 Gitaly 服务器确认 Gitaly 可以对内部 API 执行回调
- 对于 GitLab 15.3 及更高版本,运行sudo /opt/gitlab/embedded/bin/gitaly check /var/opt/gitlab/gitaly/config.toml.
- 对于 GitLab 15.2 及更早版本,运行sudo /opt/gitlab/embedded/bin/gitaly-hooks check /var/opt/gitlab/gitaly/config.toml.
总结
- Sidekiq和Gitlab Rails需要用到Redis和Postgresql,Praefect需要使用到Postgresql。
- Sidekiq和Gitlab Rails需要配置Praefect的连接信息,Praefect需要配置gitaly的连接信息。(访问存储库)
- 负载均衡器80/443端口后面代理Gitlab Rails(入口)
- 负载均衡器内部使用的话,可以考虑将外部/内部负载均衡器放在同一个LB上,没有必要一定要分开。
- 拆分没有特别强依赖的先后顺序,如果此前是all in one的部署方式(直接yum安装,所有组件默认在同一个node),各个组件也可以通过修改配置文件一步一步单独拆出来。
- 需要Redis6.2以上时,一定要确认Redis是否可以执行Hello 3
- 对于需要通过NFS/对象存储共享的目录,一定要好好共享,不然踩坑。
- 吐槽:对于官网文档,使用NFS还是使用对象存储的选择部分,描述太笼统。只知道使用对象存储能带来更好的性能,但是对于使用NFS和使用对象存储的路径的对应关系描述不清,各个路径如果不共享具体影响也没有描述。不过组件确实很多,文档确实巨长,不能事无巨细的描述清楚也可以理解。
相关文章:
gitlab集群高可用架构拆分部署
目录 前言 负载均衡器准备 外部负载均衡器 内部负载均衡器 (可选)Consul服务 Postgresql拆分 1.准备postgresql集群 手动安装postgresql插件 2./etc/gitlab/gitlab.rb配置 3.生效配置文件 Redis拆分 1./etc/gitlab/gitlab.rb配置 2.生效配置文件 Gitaly拆分 1.…...
STC8增强型单片机开发day01
C51版本Keil环境搭建 搭建流程 环境搭建的基本流程: 从官方网站下载并安装Keil软件。选择安装的软件中的C51工具集并运行。通过从“文件”菜单中选择“项目”来创建新项目。输入项目名称并选择您正在使用的设备。通过从“项目”菜单中选择“添加文件到组”来添加…...

记录: Python解析yml文件,顺序解析,带所有文件等号
记录: Python解析yml文件,顺序解析,带所有文件等号from yaml.composer import Composer from yaml.constructor import Constructor import yamlclass ParseYml:def __init__(self):passstaticmethoddef parse(yml_pathNone):try:loader yaml.Loader(op…...
Npm Install Docusaurus Demo【npm 安装 docusaurus 实践 】
文章目录 1. 简介2. 前提2.1 安装 git2.2 安装 node 3. 安装4. 项目结构5. 访问5.1 localhost 访问5.2 ip 访问 1. 简介 Docusaurus 是一个facebook的开源项目,旨在帮助开发者构建易于维护和部署的文档网站。它提供了一个简单的方法来创建专业的文档网站࿰…...

【工具推荐定制开发】一款轻量的批量web请求命令行工具支持全平台:hey,基本安装、配置、使用
背景 在开发 Web 应用的过程中,作为开发人员,为了确认接口的性能能够达到要求,我们往往需要一个接口压测工具,帮助我们快速地对我们所提供的 Web 服务发起批量请求。在接口联调的过程中,我们通常会用 Postman 等图形化…...

Linux进程——进程的创建(fork的原理)
前言:在上一篇文章中,我们已经会使用getpid/getppid函数来查看pid和ppid,本篇文章会介绍第二种查看进程的方法,以及如何创建子进程! 本篇主要内容: 查看进程的第二种方法创建子进程系统调用函数fork 在开始前ÿ…...

ICode国际青少年编程竞赛- Python-1级训练场-路线规划
ICode国际青少年编程竞赛- Python-1级训练场-路线规划 1、 Dev.step(3) Dev.turnLeft() Dev.step(4)2、 Dev.step(3) Dev.turnLeft() Dev.step(3) Dev.step(-6)3、 Dev.step(-2) Dev.step(4) Dev.turnLeft() Dev.step(3)4、 Dev.step(2) Spaceship.step(2) Dev.step(3)5、…...

uniapp微信小程序1rpx border在某些手机机型上边框显示不出来解决方案
小程序在ios系统中,如果border小于1px的情况下,border就可能显示不全(可能少了上下左右任意一边) 只需要加一个::after或::before伪类,使用绝对定位定在原来元素上边就不会产生问题了! .d_card_line1_tag { padding: 1rpx 14r…...
)
Linux mkfs.ext2命令教程:如何创建ext2文件系统(附实例详解和注意事项)
Linux mkfs.ext2命令介绍 mkfs.ext2是Linux系统中用于创建ext2文件系统的命令。它的作用是在指定的设备上创建一个ext2文件系统,使该设备能够存储文件和目录。创建ext2文件系统的过程包括以下几个步骤。 Linux mkfs.ext2命令适用的Linux版本 mkfs.ext2命令在大多…...
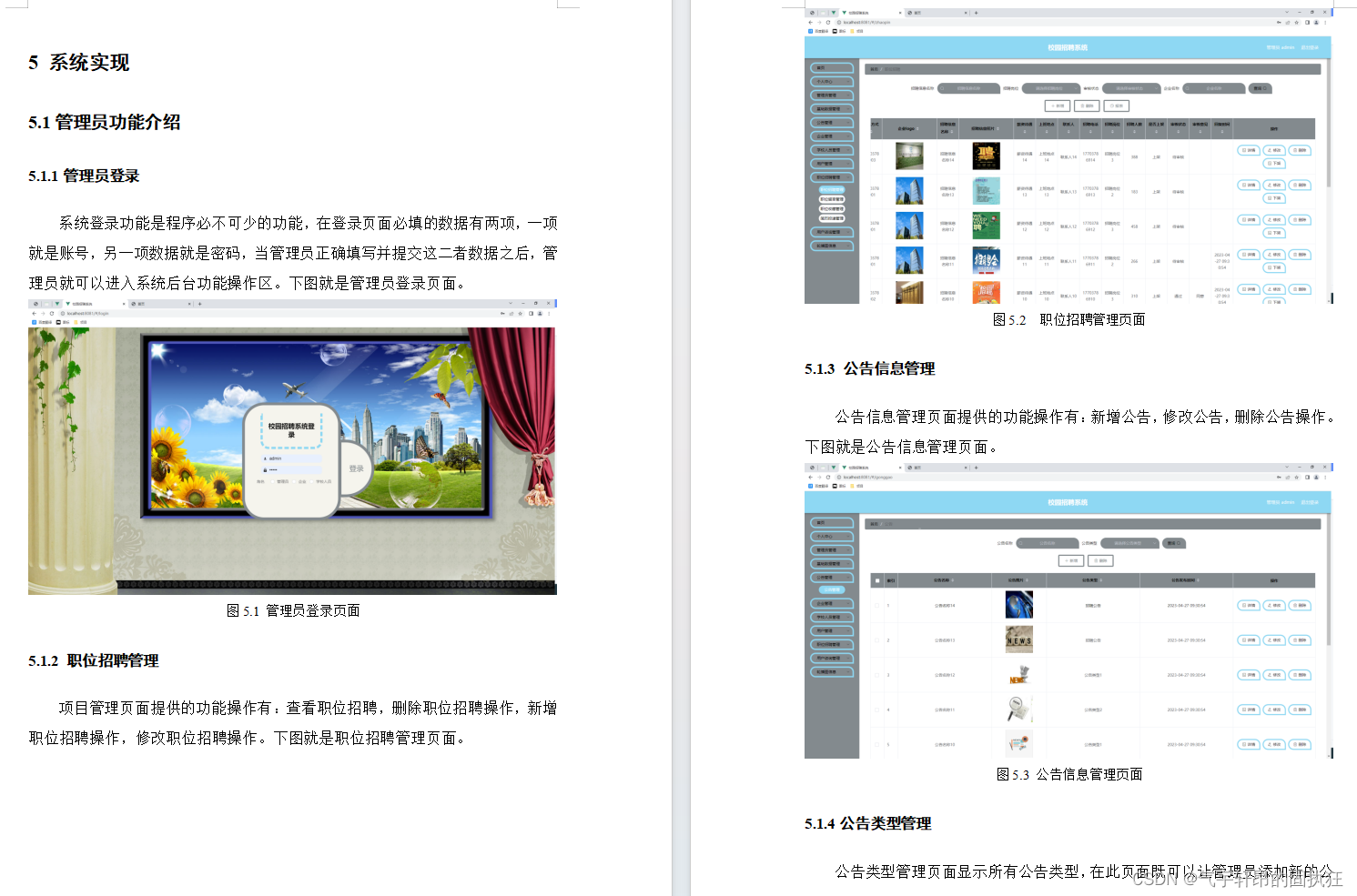
基于Springboot的校园招聘系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的校园招聘系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...

将 Vue、React、Angular、HTML 等一键打包成 macOS 和 Windows 平台客户端应用
应用简介 PPX 基于 pywebview 和 PyInstaller 框架,构建 macOS 和 Windows 平台的客户端。本应用的视图层支持 Vue、React、Angular、HTML 中的任意一种,业务层支持 Python 脚本。考虑到某些生物计算场景数据量大,数据私密,因此将…...
使用 MobaXterm 链接 Ubuntu(Windows子系统)
MobaXterm_Personal_22.1 Ubuntu(Windows子系统)...

QT设计模式:代理模式
基本概念 代理模式(Proxy Pattern)是一种结构型设计模式,它允许你提供一个代理对象,以控制对其他对象的访问。 代理通常在客户端和实际对象之间充当中介,用于控制对实际对象的访问(如登录控制)…...

独热编码One-Hot是什么?在实际应用中具体是如何存储的?
One Hot编码是一种常用的文本或类别数据编码方式,尤其在自然语言处理和机器学习中。在One Hot编码中,每个词(或类别)会被表示为一个二进制的向量,这个向量的长度等于词汇表(或类别总数)的大小&a…...

计算机视觉与深度学习实战之以Python为工具:基于GUI搭建通用视频处理工具
注意:本文的下载教程,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。 下载教程:计算机视觉与深度学习实战-以MATLAB和Python为工具_基于GUI搭建通用视频处理工具_项目开发案例教程.pdf 一、引言 随着计算机视觉和深度学习技术的飞速…...

18.Docker学习
1.Docker应用场景 Docker借鉴了标准集装箱的概念。标准集装箱将货物运往世界各地,Docker(模板)将软件运往各个环境(测试环境和生产环境拉取镜像(实例)),相当于是一个模子刻出来的 …...
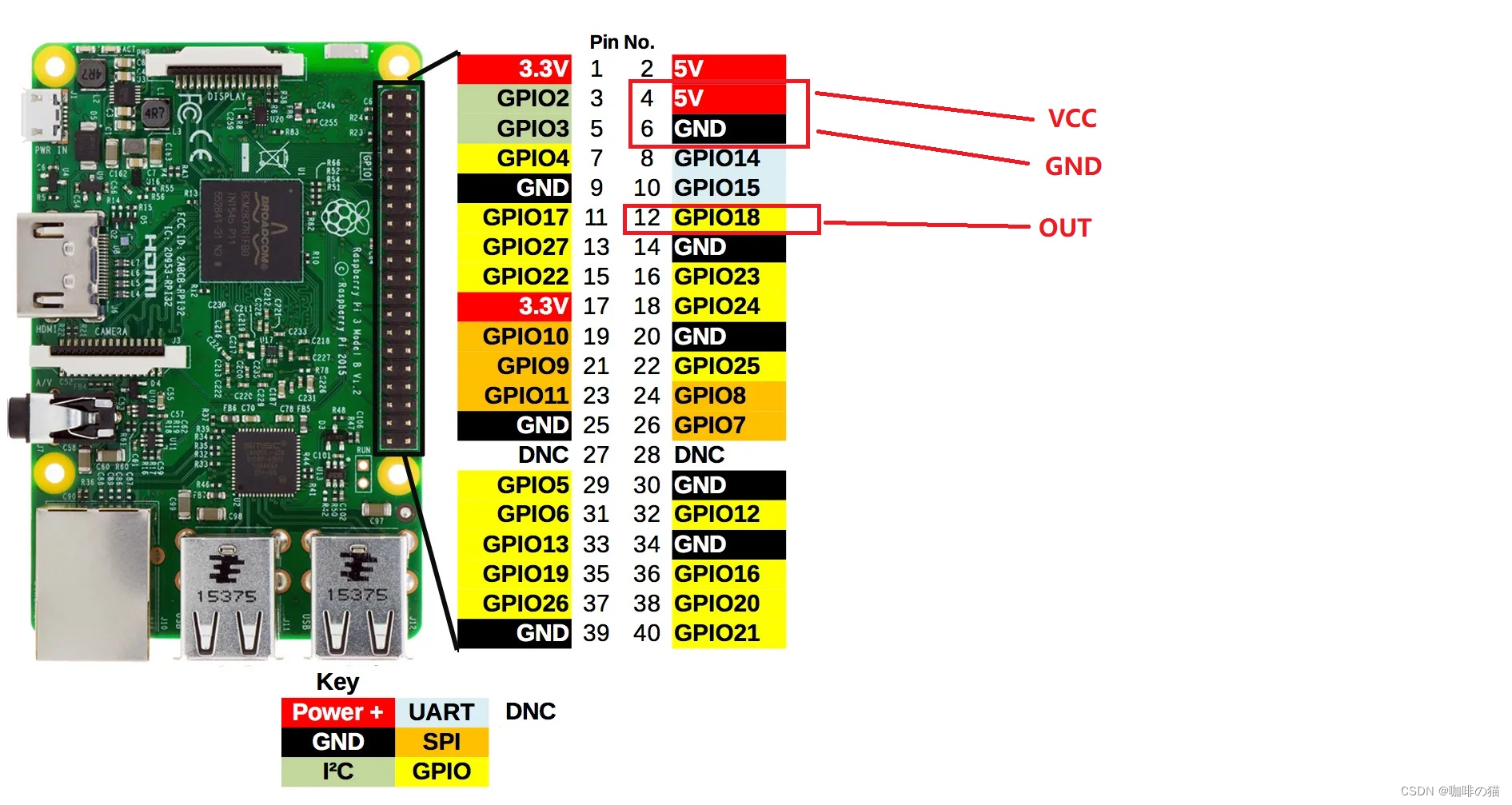
树莓派4b红外检测
1.红外检测连接图 2.红外检测工作原理 红外传感器的工作原理类似于物体检测传感器。该传感器包括一个红外LED和一个红外光电二极管,因此通过将这两者结合起来,可以形成一个光耦合器。 红外LED是一种发射红外辐射的发射器。该LED看起来与标准LED相似&a…...

大模型的不足与解决方案
文章目录 ⭐ 不具备记忆能力 上下文窗口受限⭐ 实时信息更新慢 新旧知识难区分⭐ 内部操作很灵活 外部系统难操作⭐ 无法为专业问题 提供靠谱的答案⭐ 解决方案的结果 各有不同的侧重 在前面三个章节呢,为大家从技术的角度介绍了大模型的历程与发展,也为…...

Java中使用FlatBuffers实现序列化
Java 中的 FlatBuffers有助于高速数据序列化/反序列化,消除解析开销。它由 Google 开发,为跨平台数据交换提供无模式、内存高效的解决方案。 Java 开发人员可以利用其直接内存访问来实现最佳性能和最小内存占用,从而提高应用程序速度、可扩展…...
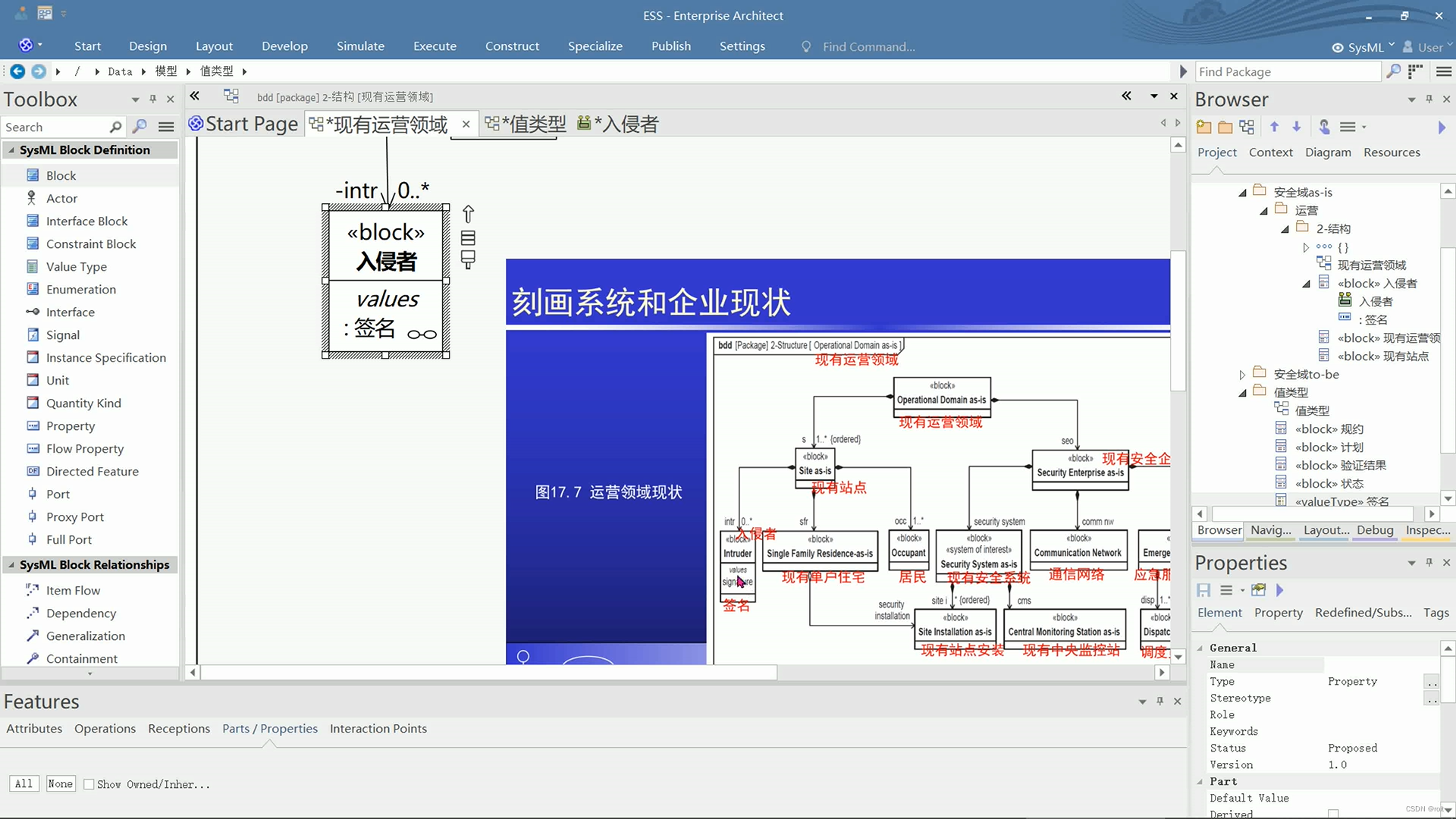
[图解]SysML和EA建模住宅安全系统-02
1 00:00:00,900 --> 00:00:02,690 这个就是一个块定义图了 2 00:00:03,790 --> 00:00:04,780 简称BDD 3 00:00:05,610 --> 00:00:08,070 实际上就是UML里面的类图 4 00:00:08,080 --> 00:00:09,950 和组件图的一个结合体 5 00:00:13,150 --> 00:00:14,690 我…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...