代码随想录算法训练营第二十天:二叉树成长
代码随想录算法训练营第二十天:二叉树成长
110.平衡二叉树
力扣题目链接(opens new window)
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]

返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]

返回 false 。
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** :后序遍历求高度,高度判断是否平衡 | LeetCode:110.平衡二叉树 ****(opens new window)**** ,相信结合视频在看本篇题解,更有助于大家对本题的理解。
#题外话
咋眼一看这道题目和104.二叉树的最大深度 **(opens new window)** 很像,其实有很大区别。
这里强调一波概念:
- 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。
- 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
但leetcode中强调的深度和高度很明显是按照节点来计算的,如图:
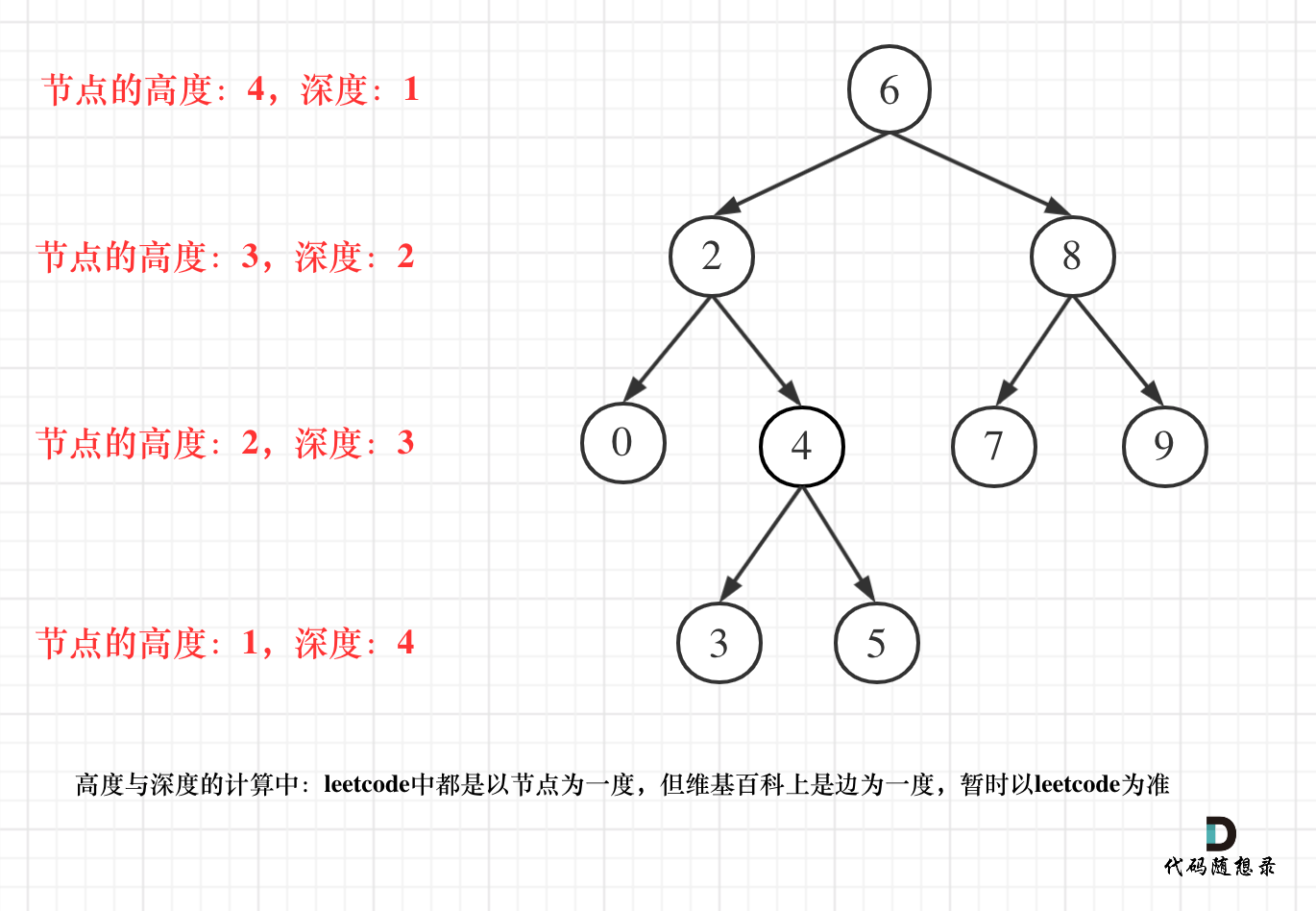
关于根节点的深度究竟是1 还是 0,不同的地方有不一样的标准,leetcode的题目中都是以节点为一度,即根节点深度是1。但维基百科上定义用边为一度,即根节点的深度是0,我们暂时以leetcode为准(毕竟要在这上面刷题)。
因为求深度可以从上到下去查 所以需要前序遍历(中左右),而高度只能从下到上去查,所以只能后序遍历(左右中)
有的同学一定疑惑,为什么104.二叉树的最大深度 **(opens new window)** 中求的是二叉树的最大深度,也用的是后序遍历。
那是因为代码的逻辑其实是求的根节点的高度,而根节点的高度就是这棵树的最大深度,所以才可以使用后序遍历。
在104.二叉树的最大深度 **(opens new window)** 中,如果真正求取二叉树的最大深度,代码应该写成如下:(前序遍历)
class Solution {
public:int result;void getDepth(TreeNode* node, int depth) {result = depth > result ? depth : result; // 中if (node->left == NULL && node->right == NULL) return ;if (node->left) { // 左depth++; // 深度+1getDepth(node->left, depth);depth--; // 回溯,深度-1}if (node->right) { // 右depth++; // 深度+1getDepth(node->right, depth);depth--; // 回溯,深度-1}return ;}int maxDepth(TreeNode* root) {result = 0;if (root == NULL) return result;getDepth(root, 1);return result;}
};这段代码是计算给定二叉树的最大深度。为了理解为什么在depth++之后又进行了depth--,需要先明白递归过程中栈(调用栈)的使用以及回溯(Backtracking)的概念。 ### 递归过程 在递归过程中,每次调用getDepth时,当前函数的局部变量(比如本例中的depth)都会保存在调用栈上。当递归调用返回时,会弹出栈顶元素,恢复到调用之前的状态,保证每一层递归的上下文环境是独立的。 ### 为什么需要depth-- 这里的depth++和随后的depth--是为了在递归调用过程中正确管理深度计数。 1. depth++ : 当你进入一个子节点时,深度增加1,表示当前从根到这个子节点的路径长度增加了1。 2. 继续递归调用: 递归调用子节点的getDepth,此时传递的depth值是增加后的值,反映了当前的正确深度。 3. depth-- : 当你完成了当前子节点的递归处理后,即将回到其父节点,此时需要将深度减1(回溯)。这是因为你即将离开当前节点返回到上一层,深度自然要减少1,以确保深度计数正确无误代表从根节点到当前处理节点的距离。 ### 回溯的作用 回溯(depth--)保证了每当递归返回上一层时,深度depth都能准确表示当前的树层级。这样,无论是往左子树深入,还是从左子树回溯后向右子树深入,depth都能准确地代表从根到当前节点的路径长度。 简而言之,depth++和随后的depth--是为了确保在递归过程中对树的每个节点进行遍历时,深度变量depth都能正确地反映当前节点的层级,这对于计算二叉树的最大深度是关键所在。
可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!
简化代码如下:
class Solution {
public:int result;void getDepth(TreeNode* node, int depth) {result = depth > result ? depth : result; // 中if (node->left == NULL && node->right == NULL) return ;if (node->left) { // 左getDepth(node->left, depth + 1);}if (node->right) { // 右getDepth(node->right, depth + 1);}return ;}int maxDepth(TreeNode* root) {result = 0;if (root == 0) return result;getDepth(root, 1);return result;}
};
在这个优化后的递归版本中,你去掉了手动的depth--操作,使用depth + 1来直接传递给递归调用。这一变化有效地简化了代码,同时保留了原始逻辑的精髓。 ### 为什么不需要depth--了 在这个版本的代码中,每次递归调用 getDepth 时,你不是直接修改 depth 变量,而是传递一个增加了的值 depth + 1。这样做有几个好处: 1. 不改变当前depth值: 你不再需要在递归调用后将depth减一,因为在递归调用时depth的值本身并没有改变。你传递的是depth + 1的新值,而当前作用域中的depth保持不变。 2. 简化代码: 这种方式简化了逻辑,使其更容易阅读和理解。没有必要增加然后再减同一个变量,只要在需要增加深度时传递增加后的值即可。 3. 保持不变性: 这种策略保持了函数参数depth的不变性,即在整个getDepth函数调用过程中,传入的深度值depth在函数体内不会被修改,只会以新的值传递给递归调用。这样做有利于避免副作用,使得每次递归调用都基于明确的、明智的状态。 ### 技术解释 当你调用getDepth(node->left, depth + 1),实际上你是在以node->left为根的子树上递归调用getDepth,同时将其深度视作depth + 1。同理,调用getDepth(node->right, depth + 1)时,也是进行相同的操作。由于每次递归都是创建新的调用栈帧,而且传给递归函数的是值参数(即深拷贝的值,而非引用或指针),这意味着每层递归使用的depth值都是独立的,不存在需要恢复(即递减)到原先状态的必要。 总的来说,这种方式通过向子递归传递更新后的值来避免了depth的手动增减操作,使代码更加清晰和高效。
本题思路
#递归
此时大家应该明白了既然要求比较高度,必然是要后序遍历。
递归三步曲分析:
- 明确递归函数的参数和返回值
参数:当前传入节点。 返回值:以当前传入节点为根节点的树的高度。
那么如何标记左右子树是否差值大于1呢?
如果当前传入节点为根节点的二叉树已经不是二叉平衡树了,还返回高度的话就没有意义了。
所以如果已经不是二叉平衡树了,可以返回-1 来标记已经不符合平衡树的规则了。
代码如下:
// -1 表示已经不是平衡二叉树了,否则返回值是以该节点为根节点树的高度
int getHeight(TreeNode* node)
- 明确终止条件
递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的树高度为0
代码如下:
if (node == NULL) {return 0;
}
- 明确单层递归的逻辑
如何判断以当前传入节点为根节点的二叉树是否是平衡二叉树呢?当然是其左子树高度和其右子树高度的差值。
分别求出其左右子树的高度,然后如果差值小于等于1,则返回当前二叉树的高度,否则返回-1,表示已经不是二叉平衡树了。
代码如下:
int leftHeight = getHeight(node->left); // 左
if (leftHeight == -1) return -1;
int rightHeight = getHeight(node->right); // 右
if (rightHeight == -1) return -1;int result;
if (abs(leftHeight - rightHeight) > 1) { // 中result = -1;
} else {result = 1 + max(leftHeight, rightHeight); // 以当前节点为根节点的树的最大高度
}return result;
代码精简之后如下:
int leftHeight = getHeight(node->left);
if (leftHeight == -1) return -1;
int rightHeight = getHeight(node->right);
if (rightHeight == -1) return -1;
return abs(leftHeight - rightHeight) > 1 ? -1 : 1 + max(leftHeight, rightHeight);
此时递归的函数就已经写出来了,这个递归的函数传入节点指针,返回以该节点为根节点的二叉树的高度,如果不是二叉平衡树,则返回-1。
getHeight整体代码如下:
int getHeight(TreeNode* node) {if (node == NULL) {return 0;}int leftHeight = getHeight(node->left);if (leftHeight == -1) return -1;int rightHeight = getHeight(node->right);if (rightHeight == -1) return -1;return abs(leftHeight - rightHeight) > 1 ? -1 : 1 + max(leftHeight, rightHeight);
}
最后本题整体递归代码如下:
class Solution {
public:// 返回以该节点为根节点的二叉树的高度,如果不是平衡二叉树了则返回-1int getHeight(TreeNode* node) {if (node == NULL) {return 0;}int leftHeight = getHeight(node->left);if (leftHeight == -1) return -1;int rightHeight = getHeight(node->right);if (rightHeight == -1) return -1;return abs(leftHeight - rightHeight) > 1 ? -1 : 1 + max(leftHeight, rightHeight);}bool isBalanced(TreeNode* root) {return getHeight(root) == -1 ? false : true;}
};
迭代
在104.二叉树的最大深度 **(opens new window)** 中我们可以使用层序遍历来求深度,但是就不能直接用层序遍历来求高度了,这就体现出求高度和求深度的不同。
本题的迭代方式可以先定义一个函数,专门用来求高度。
这个函数通过栈模拟的后序遍历找每一个节点的高度(其实是通过求传入节点为根节点的最大深度来求的高度)
代码如下:
// cur节点的最大深度,就是cur的高度
int getDepth(TreeNode* cur) {stack<TreeNode*> st;if (cur != NULL) st.push(cur);int depth = 0; // 记录深度int result = 0;while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop();st.push(node); // 中st.push(NULL);depth++;if (node->right) st.push(node->right); // 右if (node->left) st.push(node->left); // 左} else {st.pop();node = st.top();st.pop();depth--;}result = result > depth ? result : depth;}return result;
}
然后再用栈来模拟后序遍历,遍历每一个节点的时候,再去判断左右孩子的高度是否符合,代码如下:
bool isBalanced(TreeNode* root) {stack<TreeNode*> st;if (root == NULL) return true;st.push(root);while (!st.empty()) {TreeNode* node = st.top(); // 中st.pop();if (abs(getDepth(node->left) - getDepth(node->right)) > 1) { // 判断左右孩子高度是否符合return false;}if (node->right) st.push(node->right); // 右(空节点不入栈)if (node->left) st.push(node->left); // 左(空节点不入栈)}return true;
}
整体代码如下:
class Solution {
private:int getDepth(TreeNode* cur) {stack<TreeNode*> st;if (cur != NULL) st.push(cur);int depth = 0; // 记录深度int result = 0;while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop();st.push(node); // 中st.push(NULL);depth++;if (node->right) st.push(node->right); // 右if (node->left) st.push(node->left); // 左} else {st.pop();node = st.top();st.pop();depth--;}result = result > depth ? result : depth;}return result;}public:bool isBalanced(TreeNode* root) {stack<TreeNode*> st;if (root == NULL) return true;st.push(root);while (!st.empty()) {TreeNode* node = st.top(); // 中st.pop();if (abs(getDepth(node->left) - getDepth(node->right)) > 1) {return false;}if (node->right) st.push(node->right); // 右(空节点不入栈)if (node->left) st.push(node->left); // 左(空节点不入栈)}return true;}
};
当然此题用迭代法,其实效率很低,因为没有很好的模拟回溯的过程,所以迭代法有很多重复的计算。
虽然理论上所有的递归都可以用迭代来实现,但是有的场景难度可能比较大。
例如:都知道回溯法其实就是递归,但是很少人用迭代的方式去实现回溯算法!
因为对于回溯算法已经是非常复杂的递归了,如果再用迭代的话,就是自己给自己找麻烦,效率也并不一定高。
#总结
通过本题可以了解求二叉树深度 和 二叉树高度的差异,求深度适合用前序遍历,而求高度适合用后序遍历。
本题迭代法其实有点复杂,大家可以有一个思路,也不一定说非要写出来。
但是递归方式是一定要掌握的!
257. 二叉树的所有路径
力扣题目链接(opens new window)
给定一个二叉树,返回所有从根节点到叶子节点的路径。
说明: 叶子节点是指没有子节点的节点。
示例: 
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** ::递归中带着回溯,你感受到了没?| LeetCode:257. 二叉树的所有路径 ****(opens new window)**** ,相信结合视频在看本篇题解,更有助于大家对本题的理解。
#思路
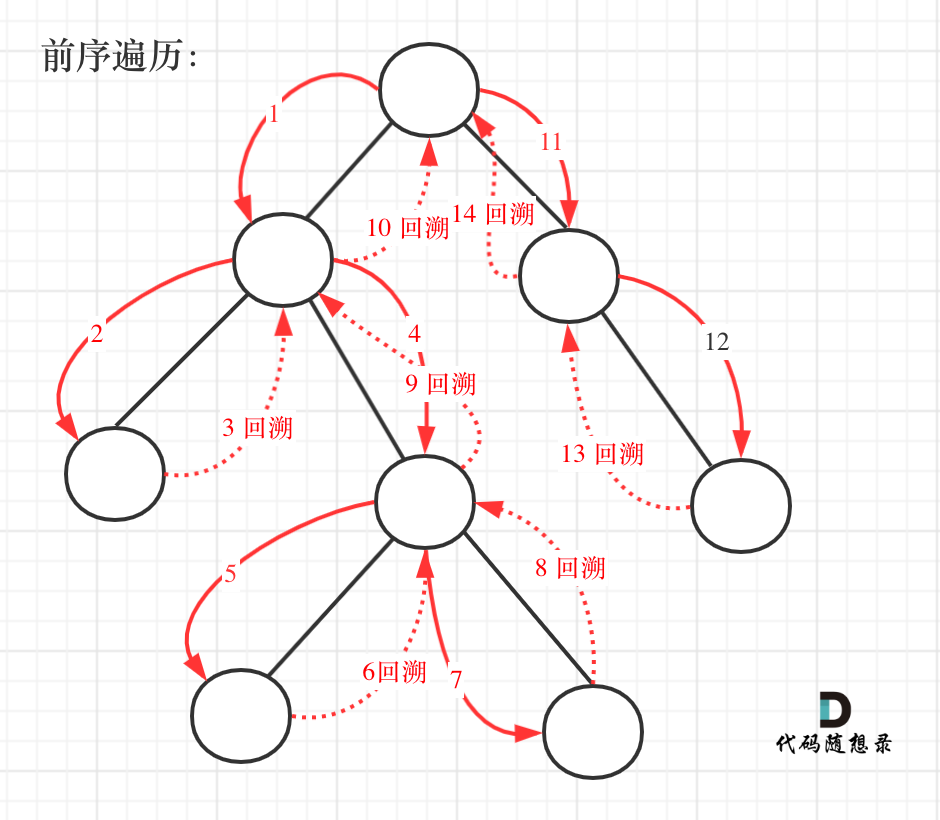
这道题目要求从根节点到叶子的路径,所以需要前序遍历,这样才方便让父节点指向孩子节点,找到对应的路径。
在这道题目中将第一次涉及到回溯,因为我们要把路径记录下来,需要回溯来回退一个路径再进入另一个路径。
前序遍历以及回溯的过程如图:
递归
- 递归函数参数以及返回值
要传入根节点,记录每一条路径的path,和存放结果集的result,这里递归不需要返回值,代码如下:
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result)
- 确定递归终止条件
在写递归的时候都习惯了这么写:
if (cur == NULL) {终止处理逻辑
}
但是本题的终止条件这样写会很麻烦,因为本题要找到叶子节点,就开始结束的处理逻辑了(把路径放进result里)。
那么什么时候算是找到了叶子节点? 是当 cur不为空,其左右孩子都为空的时候,就找到叶子节点。
所以本题的终止条件是:
if (cur->left == NULL && cur->right == NULL) {终止处理逻辑
}
为什么没有判断cur是否为空呢,因为下面的逻辑可以控制空节点不入循环。
再来看一下终止处理的逻辑。
这里使用vector 结构path来记录路径,所以要把vector 结构的path转为string格式,再把这个string 放进 result里。
那么为什么使用了vector 结构来记录路径呢? 因为在下面处理单层递归逻辑的时候,要做回溯,使用vector方便来做回溯。
可能有的同学问了,我看有些人的代码也没有回溯啊。
其实是有回溯的,只不过隐藏在函数调用时的参数赋值里,下文我还会提到。
这里我们先使用vector结构的path容器来记录路径,那么终止处理逻辑如下:
if (cur->left == NULL && cur->right == NULL) { // 遇到叶子节点string sPath;for (int i = 0; i < path.size() - 1; i++) { // 将path里记录的路径转为string格式sPath += to_string(path[i]);sPath += "->";}sPath += to_string(path[path.size() - 1]); // 记录最后一个节点(叶子节点)result.push_back(sPath); // 收集一个路径return;
}
- 确定单层递归逻辑
因为是前序遍历,需要先处理中间节点,中间节点就是我们要记录路径上的节点,先放进path中。
path.push_back(cur->val);
然后是递归和回溯的过程,上面说过没有判断cur是否为空,那么在这里递归的时候,如果为空就不进行下一层递归了。
所以递归前要加上判断语句,下面要递归的节点是否为空,如下
if (cur->left) {traversal(cur->left, path, result);
}
if (cur->right) {traversal(cur->right, path, result);
}
此时还没完,递归完,要做回溯啊,因为path 不能一直加入节点,它还要删节点,然后才能加入新的节点。
那么回溯要怎么回溯呢,一些同学会这么写,如下:
if (cur->left) {traversal(cur->left, path, result);
}
if (cur->right) {traversal(cur->right, path, result);
}
path.pop_back();
这个回溯就有很大的问题,我们知道,回溯和递归是一一对应的,有一个递归,就要有一个回溯,这么写的话相当于把递归和回溯拆开了, 一个在花括号里,一个在花括号外。
所以回溯要和递归永远在一起,世界上最遥远的距离是你在花括号里,而我在花括号外!
那么代码应该这么写:
if (cur->left) {traversal(cur->left, path, result);path.pop_back(); // 回溯
}
if (cur->right) {traversal(cur->right, path, result);path.pop_back(); // 回溯
}
那么本题整体代码如下:
// 版本一
class Solution {
private:void traversal(TreeNode* cur, vector<int>& path, vector<string>& result) {path.push_back(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中 // 这才到了叶子节点if (cur->left == NULL && cur->right == NULL) {string sPath;for (int i = 0; i < path.size() - 1; i++) {sPath += to_string(path[i]);sPath += "->";}sPath += to_string(path[path.size() - 1]);result.push_back(sPath);return;}if (cur->left) { // 左 traversal(cur->left, path, result);path.pop_back(); // 回溯}if (cur->right) { // 右traversal(cur->right, path, result);path.pop_back(); // 回溯}}public:vector<string> binaryTreePaths(TreeNode* root) {vector<string> result;vector<int> path;if (root == NULL) return result;traversal(root, path, result);return result;}
};
如上的C++代码充分体现了回溯。
那么如上代码可以精简成如下代码:
class Solution {
private:void traversal(TreeNode* cur, string path, vector<string>& result) {path += to_string(cur->val); // 中if (cur->left == NULL && cur->right == NULL) {result.push_back(path);return;}if (cur->left) traversal(cur->left, path + "->", result); // 左if (cur->right) traversal(cur->right, path + "->", result); // 右}public:vector<string> binaryTreePaths(TreeNode* root) {vector<string> result;string path;if (root == NULL) return result;traversal(root, path, result);return result;}
};
如上代码精简了不少,也隐藏了不少东西。
注意在函数定义的时候void traversal(TreeNode* cur, string path, vector<string>& result) ,定义的是string path,每次都是复制赋值,不用使用引用,否则就无法做到回溯的效果。(这里涉及到C++语法知识)
那么在如上代码中,貌似没有看到回溯的逻辑,其实不然,回溯就隐藏在traversal(cur->left, path + "->", result); 中的 path + "->" 。 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
为了把这份精简代码的回溯过程展现出来,大家可以试一试把:
if (cur->left) traversal(cur->left, path + "->", result); // 左 回溯就隐藏在这里
改成如下代码:
path += "->";
traversal(cur->left, path, result); // 左
即:
if (cur->left) {path += "->";traversal(cur->left, path, result); // 左
}
if (cur->right) {path += "->";traversal(cur->right, path, result); // 右
}
此时就没有回溯了,这个代码就是通过不了的了。
如果想把回溯加上,就要 在上面代码的基础上,加上回溯,就可以AC了。
if (cur->left) {path += "->";traversal(cur->left, path, result); // 左path.pop_back(); // 回溯 '>'path.pop_back(); // 回溯 '-'
}
if (cur->right) {path += "->";traversal(cur->right, path, result); // 右path.pop_back(); // 回溯 '>' path.pop_back(); // 回溯 '-'
}
整体代码如下:
//版本二
class Solution {
private:void traversal(TreeNode* cur, string path, vector<string>& result) {path += to_string(cur->val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中if (cur->left == NULL && cur->right == NULL) {result.push_back(path);return;}if (cur->left) {path += "->";traversal(cur->left, path, result); // 左path.pop_back(); // 回溯 '>'path.pop_back(); // 回溯 '-'}if (cur->right) {path += "->";traversal(cur->right, path, result); // 右path.pop_back(); // 回溯'>'path.pop_back(); // 回溯 '-'}}public:vector<string> binaryTreePaths(TreeNode* root) {vector<string> result;string path;if (root == NULL) return result;traversal(root, path, result);return result;}
};大家应该可以感受出来,如果把 path + "->" 作为函数参数就是可以的,因为并没有改变path的数值,执行完递归函数之后,path依然是之前的数值(相当于回溯了)
综合以上,第二种递归的代码虽然精简但把很多重要的点隐藏在了代码细节里,第一种递归写法虽然代码多一些,但是把每一个逻辑处理都完整的展现出来了。
#拓展
这里讲解本题解的写法逻辑以及一些更具体的细节,下面的讲解中,涉及到C++语法特性,如果不是C++的录友,就可以不看了,避免越看越晕。
如果是C++的录友,建议本题独立刷过两遍,再看下面的讲解,同样避免越看越晕,造成不必要的负担。
在第二版本的代码中,其实仅仅是回溯了 -> 部分(调用两次pop_back,一个pop> 一次pop-),大家应该疑惑那么 path += to_string(cur->val); 这一步为什么没有回溯呢? 一条路径能持续加节点 不做回溯吗?
其实关键还在于 参数,使用的是 string path,这里并没有加上引用& ,即本层递归中,path + 该节点数值,但该层递归结束,上一层path的数值并不会受到任何影响。 如图所示:
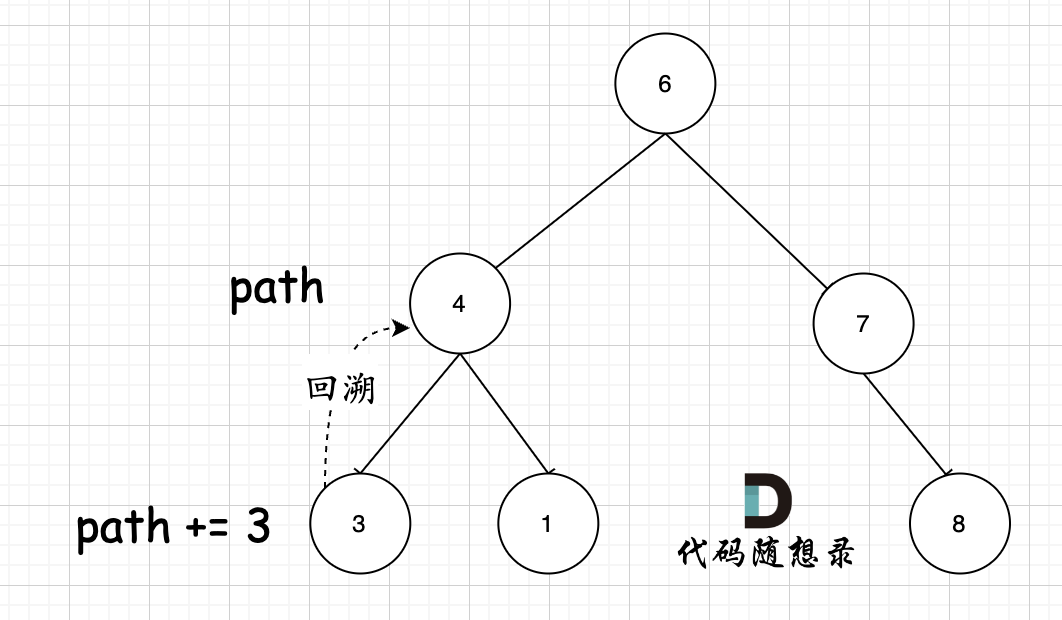
节点4 的path,在遍历到节点3,path+3,遍历节点3的递归结束之后,返回节点4(回溯的过程),path并不会把3加上。
所以这是参数中,不带引用,不做地址拷贝,只做内容拷贝的效果。(这里涉及到C++引用方面的知识)
在第一个版本中,函数参数我就使用了引用,即 vector<int>& path ,这是会拷贝地址的,所以 本层递归逻辑如果有path.push_back(cur->val); 就一定要有对应的 path.pop_back()
那有同学可能想,为什么不去定义一个 string& path 这样的函数参数呢,然后也可能在递归函数中展现回溯的过程,但关键在于,path += to_string(cur->val); 每次是加上一个数字,这个数字如果是个位数,那好说,就调用一次path.pop_back(),但如果是 十位数,百位数,千位数呢? 百位数就要调用三次path.pop_back(),才能实现对应的回溯操作,这样代码实现就太冗余了。
所以,第一个代码版本中,我才使用 vector 类型的path,这样方便给大家演示代码中回溯的操作。 vector类型的path,不管 每次 路径收集的数字是几位数,总之一定是int,所以就一次 pop_back就可以。
#迭代法
至于非递归的方式,我们可以依然可以使用前序遍历的迭代方式来模拟遍历路径的过程,对该迭代方式不了解的同学,可以看文章二叉树:听说递归能做的,栈也能做! **(opens new window)** 和二叉树:前中后序迭代方式统一写法 **(opens new window)** 。
这里除了模拟递归需要一个栈,同时还需要一个栈来存放对应的遍历路径。
C++代码如下:
class Solution {
public:vector<string> binaryTreePaths(TreeNode* root) {stack<TreeNode*> treeSt;// 保存树的遍历节点stack<string> pathSt; // 保存遍历路径的节点vector<string> result; // 保存最终路径集合if (root == NULL) return result;treeSt.push(root);pathSt.push(to_string(root->val));while (!treeSt.empty()) {TreeNode* node = treeSt.top(); treeSt.pop(); // 取出节点 中string path = pathSt.top();pathSt.pop(); // 取出该节点对应的路径if (node->left == NULL && node->right == NULL) { // 遇到叶子节点result.push_back(path);}if (node->right) { // 右treeSt.push(node->right);pathSt.push(path + "->" + to_string(node->right->val));}if (node->left) { // 左treeSt.push(node->left);pathSt.push(path + "->" + to_string(node->left->val));}}return result;}
};
当然,使用java的同学,可以直接定义一个成员变量为object的栈Stack<Object> stack = new Stack<>();,这样就不用定义两个栈了,都放到一个栈里就可以了。
#总结
本文我们开始初步涉及到了回溯,很多同学过了这道题目,可能都不知道自己其实使用了回溯,回溯和递归都是相伴相生的。
我在第一版递归代码中,把递归与回溯的细节都充分的展现了出来,大家可以自己感受一下。
第二版递归代码对于初学者其实非常不友好,代码看上去简单,但是隐藏细节于无形。
最后我依然给出了迭代法。
对于本题充分了解递归与回溯的过程之后,有精力的同学可以再去实现迭代法。
周一
本周刚开始我们讲解了判断二叉树是否对称的写法, 二叉树:我对称么? **(opens new window)** 。
这道题目的本质是要比较两个树(这两个树是根节点的左右子树),遍历两棵树而且要比较内侧和外侧节点,所以准确的来说是一个树的遍历顺序是左右中,一个树的遍历顺序是右左中。
而本题的迭代法中我们使用了队列,需要注意的是这不是层序遍历,而且仅仅通过一个容器来成对的存放我们要比较的元素,认识到这一点之后就发现:用队列,用栈,甚至用数组,都是可以的。
那么做完本题之后,再看如下两个题目。
- 100.相同的树(opens new window)
- 572.另一个树的子树(opens new window)
二叉树:我对称么? ****(opens new window)****中的递归法和迭代法只需要稍作修改其中一个树的遍历顺序,便可刷了100.相同的树。
100.相同的树的递归代码如下:
class Solution {
public:bool compare(TreeNode* left, TreeNode* right) {// 首先排除空节点的情况if (left == NULL && right != NULL) return false;else if (left != NULL && right == NULL) return false;else if (left == NULL && right == NULL) return true;// 排除了空节点,再排除数值不相同的情况else if (left->val != right->val) return false;// 此时就是:左右节点都不为空,且数值相同的情况// 此时才做递归,做下一层的判断bool outside = compare(left->left, right->left); // 左子树:左、 右子树:左 (相对于求对称二叉树,只需改一下这里的顺序)bool inside = compare(left->right, right->right); // 左子树:右、 右子树:右bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)return isSame;}bool isSymmetric(TreeNode* p, TreeNode* q) {return compare(p, q);}
};
100.相同的树,精简之后代码如下:
class Solution {
public:bool compare(TreeNode* left, TreeNode* right) {if (left == NULL && right != NULL) return false;else if (left != NULL && right == NULL) return false;else if (left == NULL && right == NULL) return true;else if (left->val != right->val) return false;else return compare(left->left, right->left) && compare(left->right, right->right);}bool isSameTree(TreeNode* p, TreeNode* q) {return compare(p, q);}
};
100.相同的树,迭代法代码如下:
class Solution {
public:bool isSameTree(TreeNode* p, TreeNode* q) {if (p == NULL && q == NULL) return true;if (p == NULL || q == NULL) return false;queue<TreeNode*> que;que.push(p);que.push(q);while (!que.empty()) {TreeNode* leftNode = que.front(); que.pop();TreeNode* rightNode = que.front(); que.pop();if (!leftNode && !rightNode) {continue;}if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {return false;}// 相对于求对称二叉树,这里两个树都要保持一样的遍历顺序que.push(leftNode->left);que.push(rightNode->left);que.push(leftNode->right);que.push(rightNode->right);}return true;}
};而572.另一个树的子树,则和 100.相同的树几乎一样的了,大家可以直接AC了。
#周二
在二叉树:看看这些树的最大深度 **(opens new window)** 中,我们讲解了如何求二叉树的最大深度。
本题可以使用前序,也可以使用后序遍历(左右中),使用前序求的就是深度,使用后序呢求的是高度。
而根节点的高度就是二叉树的最大深度,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度,所以二叉树:看看这些树的最大深度 **(opens new window)** 中使用的是后序遍历。
本题当然也可以使用前序,代码如下:(充分表现出求深度回溯的过程)
class Solution {
public:int result;void getDepth(TreeNode* node, int depth) {result = depth > result ? depth : result; // 中if (node->left == NULL && node->right == NULL) return ;if (node->left) { // 左depth++; // 深度+1getDepth(node->left, depth);depth--; // 回溯,深度-1}if (node->right) { // 右depth++; // 深度+1getDepth(node->right, depth);depth--; // 回溯,深度-1}return ;}int maxDepth(TreeNode* root) {result = 0;if (root == 0) return result;getDepth(root, 1);return result;}
};
可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!
注意以上代码是为了把细节体现出来,简化一下代码如下:
class Solution {
public:int result;void getDepth(TreeNode* node, int depth) {result = depth > result ? depth : result; // 中if (node->left == NULL && node->right == NULL) return ;if (node->left) { // 左getDepth(node->left, depth + 1);}if (node->right) { // 右getDepth(node->right, depth + 1);}return ;}int maxDepth(TreeNode* root) {result = 0;if (root == 0) return result;getDepth(root, 1);return result;}
};
#周三
在二叉树:看看这些树的最小深度 **(opens new window)** 中,我们讲解如何求二叉树的最小深度, 这道题目要是稍不留心很容易犯错。
注意这里最小深度是从根节点到最近叶子节点的最短路径上的节点数量。注意是叶子节点。
什么是叶子节点,左右孩子都为空的节点才是叶子节点!
求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。
注意到这一点之后 递归法和迭代法 都可以参照二叉树:看看这些树的最大深度 **(opens new window)** 写出来。
#周四
我们在二叉树:我有多少个节点? **(opens new window)** 中,讲解了如何求二叉树的节点数量。
这一天是十一长假的第一天,又是双节,所以简单一些,只要把之前两篇二叉树:看看这些树的最大深度 **(opens new window)** , 二叉树:看看这些树的最小深度 **(opens new window)** 都认真看了的话,这道题目可以分分钟刷掉了。
估计此时大家对这一类求二叉树节点数量以及求深度应该非常熟练了。
#周五
在二叉树:我平衡么? **(opens new window)** 中讲解了如何判断二叉树是否是平衡二叉树
今天讲解一道判断平衡二叉树的题目,其实 方法上我们之前讲解深度的时候都讲过了,但是这次我们通过这道题目彻底搞清楚二叉树高度与深度的问题,以及对应的遍历方式。
二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
但leetcode中强调的深度和高度很明显是按照节点来计算的。
关于根节点的深度究竟是1 还是 0,不同的地方有不一样的标准,leetcode的题目中都是以节点为一度,即根节点深度是1。但维基百科上定义用边为一度,即根节点的深度是0,我们暂时以leetcode为准(毕竟要在这上面刷题)。
当然此题用迭代法,其实效率很低,因为没有很好的模拟回溯的过程,所以迭代法有很多重复的计算。
虽然理论上所有的递归都可以用迭代来实现,但是有的场景难度可能比较大。
例如:都知道回溯法其实就是递归,但是很少人用迭代的方式去实现回溯算法!
讲了这么多二叉树题目的迭代法,有的同学会疑惑,迭代法中究竟什么时候用队列,什么时候用栈?
如果是模拟前中后序遍历就用栈,如果是适合层序遍历就用队列,当然还是其他情况,那么就是 先用队列试试行不行,不行就用栈。
#周六
在二叉树:找我的所有路径? **(opens new window)** 中正式涉及到了回溯,很多同学过了这道题目,可能都不知道自己使用了回溯,其实回溯和递归都是相伴相生的。最后我依然给出了迭代法的版本。
我在题解中第一个版本的代码会把回溯的过程充分体现出来,如果大家直接看简洁的代码版本,很可能就会忽略的回溯的存在。
我在文中也强调了这一点。
有的同学还不理解 ,文中精简之后的递归代码,回溯究竟隐藏在哪里了。
文中我明确的说了:回溯就隐藏在traversal(cur->left, path + "->", result);中的 path + "->"。 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
如果还不理解的话,可以把
traversal(cur->left, path + "->", result);
改成
string tmp = path + "->";
traversal(cur->left, tmp, result);
看看还行不行了,答案是这么写就不行了,因为没有回溯了。
#总结
二叉树的题目,我都是使用了递归三部曲一步一步的把整个过程分析出来,而不是上来就给出简洁的代码。
一些同学可能上来就能写出代码,大体上也知道是为啥,可以自圆其说,但往细节一扣,就不知道了。
所以刚接触二叉树的同学,建议按照文章分析的步骤一步一步来,不要上来就照着精简的代码写(那样写完了也很容易忘的,知其然不知其所以然)。
简短的代码看不出遍历的顺序,也看不出分析的逻辑,还会把必要的回溯的逻辑隐藏了,所以尽量按照原理分析一步一步来,写出来之后,再去优化代码。
大家加个油!!
相信很多小伙伴刷题的时候面对力扣上近两千道题目,感觉无从下手,我花费半年时间整理了Github项目:「力扣刷题攻略」https://github.com/youngyangyang04/leetcode-master ****(opens new window)**** 。 里面有100多道经典算法题目刷题顺序、配有40w字的详细图解,常用算法模板总结,以及难点视频讲解,按照list一道一道刷就可以了!star支持一波吧!
- 公众号:代码随想录(opens new window)
- B站:代码随想录(opens new window)
- Github:leetcode-master(opens new window)
- 知乎:代码随想录(opens new window)
404.左叶子之和
力扣题目链接(opens new window)
计算给定二叉树的所有左叶子之和。
示例:

#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** ::二叉树的题目中,总有一些规则让你找不到北 | LeetCode:404.左叶子之和 ****(opens new window)**** ,相信结合视频在看本篇题解,更有助于大家对本题的理解。
#思路
首先要注意是判断左叶子,不是二叉树左侧节点,所以不要上来想着层序遍历。
因为题目中其实没有说清楚左叶子究竟是什么节点,那么我来给出左叶子的明确定义:节点A的左孩子不为空,且左孩子的左右孩子都为空(说明是叶子节点),那么A节点的左孩子为左叶子节点
大家思考一下如下图中二叉树,左叶子之和究竟是多少?
其实是0,因为这棵树根本没有左叶子!
但看这个图的左叶子之和是多少?
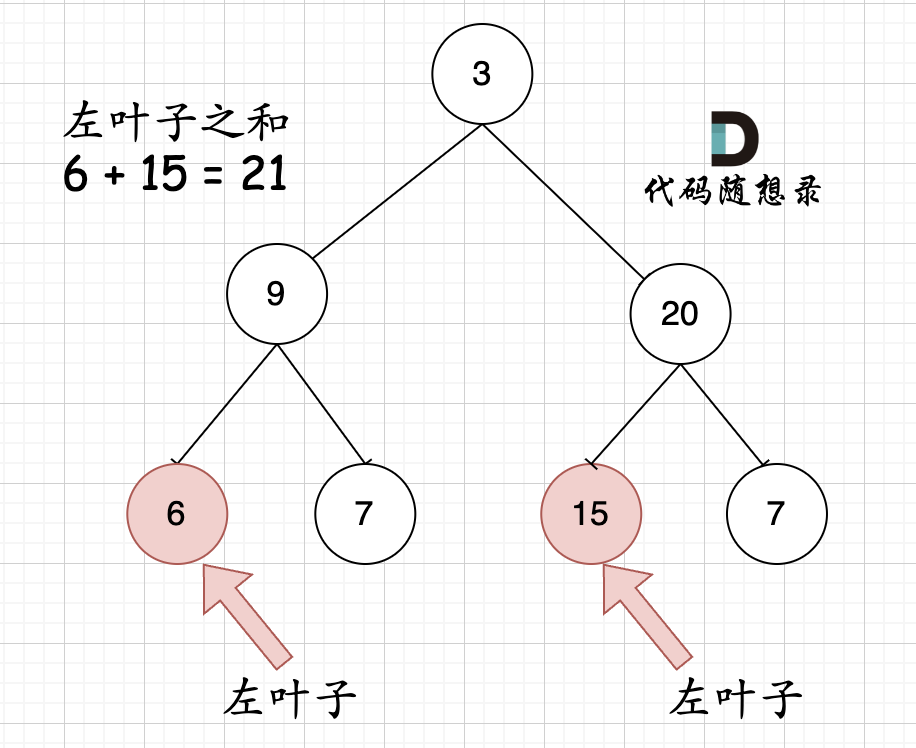
相信通过这两个图,大家对最左叶子的定义有明确理解了。
那么判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。
如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子,判断代码如下:
if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {左叶子节点处理逻辑
}
#递归法
递归的遍历顺序为后序遍历(左右中),是因为要通过递归函数的返回值来累加求取左叶子数值之和。
递归三部曲:
- 确定递归函数的参数和返回值
判断一个树的左叶子节点之和,那么一定要传入树的根节点,递归函数的返回值为数值之和,所以为int
使用题目中给出的函数就可以了。
- 确定终止条件
如果遍历到空节点,那么左叶子值一定是0
if (root == NULL) return 0;
注意,只有当前遍历的节点是父节点,才能判断其子节点是不是左叶子。 所以如果当前遍历的节点是叶子节点,那其左叶子也必定是0,那么终止条件为:
if (root == NULL) return 0;
if (root->left == NULL && root->right== NULL) return 0; //其实这个也可以不写,如果不写不影响结果,但就会让递归多进行了一层。
- 确定单层递归的逻辑
当遇到左叶子节点的时候,记录数值,然后通过递归求取左子树左叶子之和,和 右子树左叶子之和,相加便是整个树的左叶子之和。
代码如下:
int leftValue = sumOfLeftLeaves(root->left); // 左
if (root->left && !root->left->left && !root->left->right) {leftValue = root->left->val;
}
int rightValue = sumOfLeftLeaves(root->right); // 右int sum = leftValue + rightValue; // 中
return sum;
整体递归代码如下:
class Solution {
public:int sumOfLeftLeaves(TreeNode* root) {if (root == NULL) return 0;if (root->left == NULL && root->right== NULL) return 0;int leftValue = sumOfLeftLeaves(root->left); // 左if (root->left && !root->left->left && !root->left->right) { // 左子树就是一个左叶子的情况leftValue = root->left->val;}int rightValue = sumOfLeftLeaves(root->right); // 右int sum = leftValue + rightValue; // 中return sum;}
};
以上代码精简之后如下:
class Solution {
public:int sumOfLeftLeaves(TreeNode* root) {if (root == NULL) return 0;int leftValue = 0;if (root->left != NULL && root->left->left == NULL && root->left->right == NULL) {leftValue = root->left->val;}return leftValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right);}
};
精简之后的代码其实看不出来用的是什么遍历方式了,对于算法初学者以上根据第一个版本来学习。
#迭代法
本题迭代法使用前中后序都是可以的,只要把左叶子节点统计出来,就可以了,那么参考文章 二叉树:听说递归能做的,栈也能做! **(opens new window)** 和二叉树:迭代法统一写法 **(opens new window)** 中的写法,可以写出一个前序遍历的迭代法。
判断条件都是一样的,代码如下:
class Solution {
public:int sumOfLeftLeaves(TreeNode* root) {stack<TreeNode*> st;if (root == NULL) return 0;st.push(root);int result = 0;while (!st.empty()) {TreeNode* node = st.top();st.pop();if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {result += node->left->val;}if (node->right) st.push(node->right);if (node->left) st.push(node->left);}return result;}
};
#总结
这道题目要求左叶子之和,其实是比较绕的,因为不能判断本节点是不是左叶子节点。
此时就要通过节点的父节点来判断其左孩子是不是左叶子了。
平时我们解二叉树的题目时,已经习惯了通过节点的左右孩子判断本节点的属性,而本题我们要通过节点的父节点判断本节点的属性。
希望通过这道题目,可以扩展大家对二叉树的解题思路。
相关文章:
代码随想录算法训练营第二十天:二叉树成长
代码随想录算法训练营第二十天:二叉树成长 110.平衡二叉树 力扣题目链接(opens new window) 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝…...

Opensbi初始化分析:设备初始化-warmboot
Opensbi初始化分析:设备初始化-warmboot 设备初始化sbi_init函数init_warmboot函数coolboot & warmbootwait_for_coldboot函数domain && scratch(coldboot所特有)console初始化及print相关工作(coldboot所特有)系统调用的相关初始化(coldboot所特有)综上设备…...
)
软考 系统架构设计师系列知识点之软件可靠性基础知识(13)
接前一篇文章:软考 系统架构设计师系列知识点之软件可靠性基础知识(12) 所属章节: 第9章. 软件可靠性基础知识 第3节 软件可靠性管理 为了进一步提高软件可靠性,人们又提出了软件可靠性管理的概念,把软件可…...
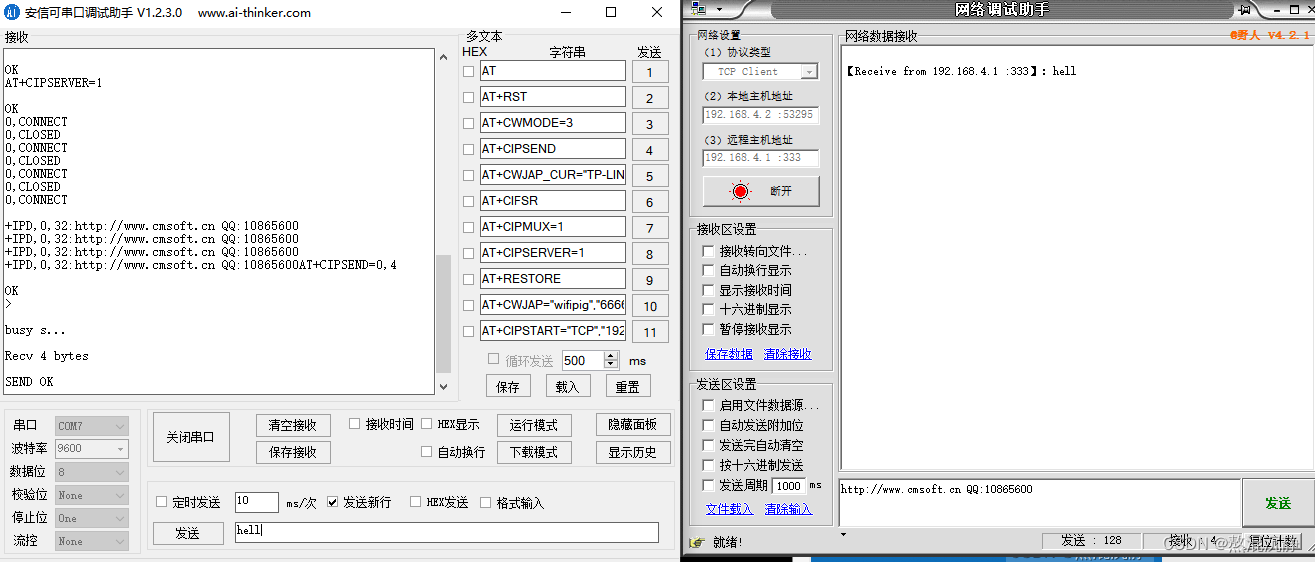
将ESP工作为AP路由模式并当成服务器
将ESP8266模块通过usb转串口接入电脑 ATCWMODE3 //1.配置成双模ATCIPMUX1 //2.使能多链接ATCIPSERVER1 //3.建立TCPServerATCIPSEND0,4 //4.发送4个字节在链接0通道上 >ATCIPCLOSE0 //5.断开连接通过wifi找到安信可的wifi信号并连接 连接后查看自己的ip地址变为192.168.4.…...
Python深度学习基于Tensorflow(6)神经网络基础
文章目录 使用Tensorflow解决XOR问题激活函数正向传播和反向传播解决过拟合权重正则化Dropout正则化批量正则化 BatchNormal权重初始化残差连接 选择优化算法传统梯度更新算法动量算法NAG算法AdaGrad算法RMSProp算法Adam算法如何选择优化算法 使用tf.keras构建神经网络使用Sequ…...

力扣HOT100 - 35. 搜索插入位置
解题思路: 二分法模板 class Solution {public int searchInsert(int[] nums, int target) {int left 0;int right nums.length - 1;while (left < right) {int mid left ((right - left) >> 1);if (nums[mid] target)return mid;else if (nums[mid…...
MinimogWP WordPress 主题下载——优雅至上,功能无限
无论你是个人博客写手、创意工作者还是企业站点的管理员,MinimogWP 都将成为你在 WordPress 平台上的理想之选。以其优雅、灵活和功能丰富而闻名,MinimogWP 不仅提供了令人惊叹的外观,还为你的网站带来了无限的创作和定制可能性。 无与伦比的…...
kube-prometheus部署到 k8s 集群
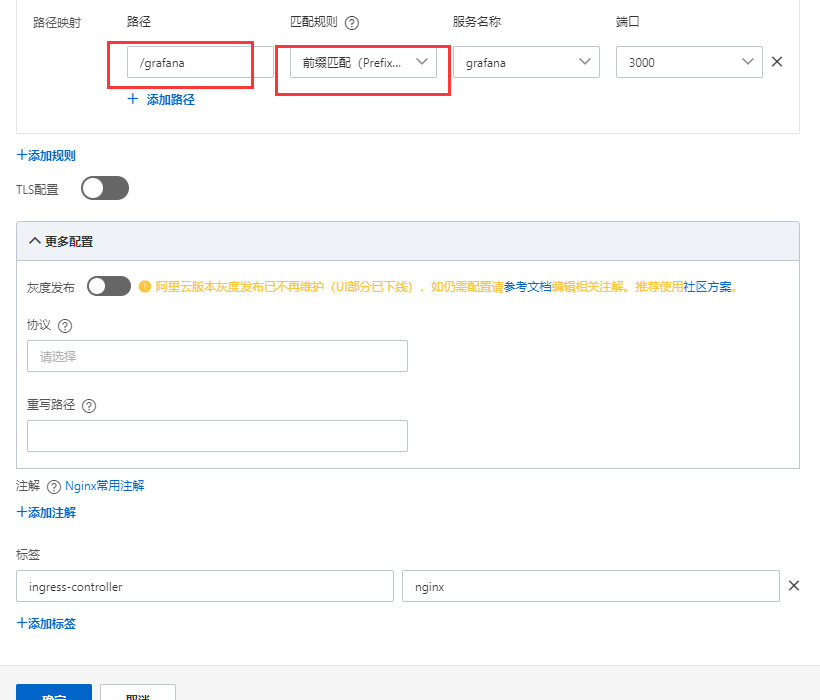
文章目录 **修改镜像地址****访问配置****修改 Prometheus 的 service****修改 Grafana 的 service****修改 Alertmanager 的 service****安装****Prometheus验证****Alertmanager验证****Grafana验证****卸载****Grafana显示时间问题** 或者配置ingress添加ingress访问grafana…...

从0开始学习python(六)
目录 前言 1、循环结构 1.1 遍历循环结构for 1.2 无限循环结构while 总结 前言 上一篇文章我们讲到了python的顺序结构和分支结构。这一章继续往下讲。 1、循环结构 在python中,循环结构分为两类,一类是遍历循环结构for,一类是无限循环结…...
OpenGL 入门(三)—— OpenGL 与 OpenCV 共同打造大眼滤镜
从本篇开始,会在上一篇搭建的滤镜框架的基础上,介绍具体的滤镜效果该如何制作。本篇会先介绍大眼滤镜,先来看一下效果,原图如下: 使用手机后置摄像头对眼部放大后的效果: 制作大眼滤镜所需的主要知识点&…...

Linux服务器安全基础 - 查看入侵痕迹
1. 常见系统日志 /var/log/cron 记录了系统定时任务相关的日志 /var/log/dmesg 记录了系统在开机时内核自检的信息,也可以使用dmesg命令直接查看内核自检信息 /var/log/secure:记录登录系统存取数据的文件;例如:pop3,ssh,telnet,ftp等都会记录在此. /var/log/btmp:记…...

Java反射机制的实战应用:探索其魅力与局限
引言 Java作为一种面向对象的编程语言,其灵活性和强大的功能使其成为众多开发者的首选。而Java反射机制作为Java语言中的一项重要特性,为程序员提供了一种在运行时检查和操作类、方法、属性等信息的能力。本文旨在深入探讨Java反射机制的实战应用&#…...

vue3项目 文件组成
从头捋顺一遍vue3项目文件目录 前置知识JS模块化什么是依赖?安装依赖webpack能做什么?vue基本使用 不借助vue-cli,从0开始搭建vue项目。index.html、main.js、App.vue引入npm引入webpack引入babel引入vue-loaderwebpack配置webpack配置 前置知…...

C语言关键字 typedef 的功能是什么?
一、问题 语⾔有 32 个关键字,其中 int 的功能是声明整型变量,struct 的功能是声明结构体变量,那么 typedef 的功能是什么呢? 二、解答 1. typedef 的功能 在 C 语⾔中除了可以使⽤标准类型名(如 int、 char、float …...

【YoloDeployCsharp】基于.NET Framework的YOLO深度学习模型部署测试平台-源码下载与项目配置
基于.NET Framework 4.8 开发的深度学习模型部署测试平台,提供了YOLO框架的主流系列模型,包括YOLOv8~v9,以及其系列下的Det、Seg、Pose、Obb、Cls等应用场景,同时支持图像与视频检测。模型部署引擎使用的是OpenVINO™、TensorRT、ONNX runtime以及OpenCV DNN,支持CPU、IGP…...

如何在 Ubuntu 12.04 VPS 上使用 MongoDB 创建分片集群
简介 MongoDB 是一个 NoSQL 文档数据库系统,可以在水平方向上很好地扩展,并通过键值系统实现数据存储。作为 Web 应用程序和网站的热门选择,MongoDB 易于实现并可以通过编程方式访问。 MongoDB 通过一种称为“分片”的技术实现扩展。分片是将…...
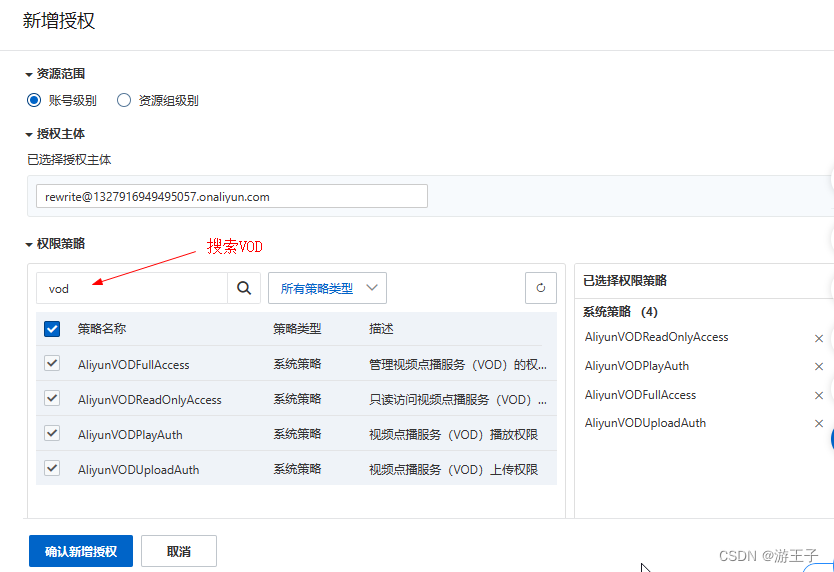
阿里云VOD视频点播流程(1)
一、开通阿里云VOD 视频点播(ApsaraVideo VoD,简称VOD)是集视频采集、编辑、上传、媒体资源管理、自动化转码处理、视频审核分析、分发加速于一体的一站式音视频点播解决方案。登录阿里云,在产品找到视频点播VOD ,点击…...
Python爬虫获取豆瓣电影Top100
大家好,我是秋意零。 今天分析一篇,Python爬虫获取豆瓣电影Top100。 在此之前,我没有学习过爬虫,只有一丢丢的Python基础。下面效果的实现源码几乎没经过我,而是AI百老师。我主要负责了对应的调试以及根据我想要的功…...

动态规划专训8——背包问题
动态规划题目中,常出现背包的相关问题,这里单独挑出来训练 A.01背包 1.01背包模板题 【模板】01背包_牛客题霸_牛客网 (nowcoder.com) 你有一个背包,最多能容纳的体积是V。 现在有n个物品,第i个物品的体积为𝑣&am…...

软件杯 深度学习花卉识别 - python 机器视觉 opencv
文章目录 0 前言1 项目背景2 花卉识别的基本原理3 算法实现3.1 预处理3.2 特征提取和选择3.3 分类器设计和决策3.4 卷积神经网络基本原理 4 算法实现4.1 花卉图像数据4.2 模块组成 5 项目执行结果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &a…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...
针对药品仓库的效期管理问题,如何利用WMS系统“破局”
案例: 某医药分销企业,主要经营各类药品的批发与零售。由于药品的特殊性,效期管理至关重要,但该企业一直面临效期问题的困扰。在未使用WMS系统之前,其药品入库、存储、出库等环节的效期管理主要依赖人工记录与检查。库…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...