情感分类学习笔记(1)
文本情感分类(二):深度学习模型 - 科学空间|Scientific Spaces
一、代码理解
cw = lambda x: list(jieba.cut(x)) #定义分词函数
您给出的代码定义了一个使用 jieba 分词库的分词函数。jieba 是一个用于中文分词的 Python 库。该函数 cw 是一个 lambda 函数,它接受一个字符串 x 作为输入,然后使用 jieba.cut(x) 方法对字符串进行分词,并返回一个分词后的列表。
这里是该代码的一个简单解释和如何使用它的例子:
首先,确保您已经安装了 jieba 库。如果没有,您可以使用 pip 来安装它:
bash复制代码
pip install jieba |
然后,您可以使用您定义的 cw 函数来对中文文本进行分词:
python复制代码
import jieba | |
# 定义分词函数 | |
cw = lambda x: list(jieba.cut(x)) | |
# 使用分词函数 | |
text = "我来到北京清华大学" | |
words = cw(text) | |
print(words) # 输出: ['我', '来到', '北京', '清华大学'] |
在上面的例子中,文本 "我来到北京清华大学" 被分词成了 ['我', '来到', '北京', '清华大学']。
lambda 函数在这里是一个简单的函数定义方式,对于简单的函数,使用 lambda 可以使代码更简洁。但是,如果函数变得更加复杂,使用常规的 def 语句来定义函数会更清晰和易于阅读。例如:
python复制代码
def cut_words(x): | |
return list(jieba.cut(x)) | |
# 使用该函数 | |
words = cut_words(text) | |
print(words) # 输出: ['我', '来到', '北京', '清华大学'] |
这两种定义方式(使用 lambda 和使用 def)在功能上是等效的。
2.
pn['words'] = pn[0].apply(cw)后pn的内容

3.
comment = comment[comment['rateContent'].notnull()]
DataFrame 是 Pandas 库中用于处理表格型数据的核心数据结构。以下是一些常用的 DataFrame 操作:
- 创建 DataFrame
使用 pd.DataFrame() 从字典、列表、Series、其他 DataFrame 或其他数据源创建 DataFrame。
python复制代码
import pandas as pd | |
data = {'A': [1, 2, 3], 'B': [4, 5, 6]} | |
df = pd.DataFrame(data) |
- 查看 DataFrame
使用 head(), tail(), info(), describe(), shape 等方法查看 DataFrame 的内容、结构或统计信息。
python复制代码
print(df.head()) # 显示前几行 | |
print(df.info()) # 显示摘要信息,包括列名、数据类型和非空值计数 | |
print(df.describe()) # 显示数值列的统计信息 | |
print(df.shape) # 显示行数和列数 |
- 选择数据
使用列名、行标签、条件表达式、布尔索引等选择数据。
python复制代码
print(df['A']) # 选择列 A | |
print(df.iloc[0]) # 选择第一行(基于整数位置) | |
print(df.loc[0]) # 选择第一行(基于标签) | |
print(df[df['A'] > 1]) # 选择 A 列大于 1 的行 |
- 设置和修改数据
使用列名、行标签或条件表达式设置或修改 DataFrame 中的值。
python复制代码
df['C'] = df['A'] + df['B'] # 添加新列 C,其值为 A 和 B 列的和 | |
df.at[0, 'A'] = 10 # 修改第一行 A 列的值为 10 | |
df.loc[df['A'] > 1, 'B'] = 0 # 将 A 列大于 1 的行对应的 B 列值设置为 0 |
- 排序数据
使用 sort_values() 方法按列值对 DataFrame 进行排序。
python复制代码
df_sorted = df.sort_values(by='A') # 按列 A 的值排序 |
- 数据分组和聚合
使用 groupby() 方法对数据进行分组,并使用聚合函数(如 sum(), mean(), count() 等)对每个组进行计算。
python复制代码
grouped = df.groupby('A').sum() # 按列 A 分组并计算每组的和 |
- 缺失值处理
使用 dropna(), fillna(), interpolate() 等方法处理缺失值。
python复制代码
df_cleaned = df.dropna() # 删除包含缺失值的行 | |
df_filled = df.fillna(0) # 将缺失值替换为 0 |
- 合并和连接
使用 merge(), concat(), join() 等方法合并或连接多个 DataFrame。
python复制代码
df1 = pd.DataFrame({'key': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'B'], 'value': range(8)}) | |
df2 = pd.DataFrame({'key': ['B', 'B', 'A', 'A', 'B', 'A'], 'value2': range(6)}) | |
merged = pd.merge(df1, df2, on='key') # 基于 key 列合并 df1 和 df2 |
- 数据导出
使用 to_csv(), to_excel(), to_sql() 等方法将 DataFrame 导出到 CSV 文件、Excel 文件、数据库等。
python复制代码
df.to_csv('output.csv', index=False) # 将 DataFrame 导出到 CSV 文件,不包含索引列 |
- 其他常用操作
- 重命名列:
df.rename(columns={'old_name': 'new_name'}) - 删除列:
del df['column_name']或df.drop(columns=['column_name']) - 删除行:
df.drop(index=labels_to_drop) - 转换数据类型:
df['column_name'] = df['column_name'].astype(new_type) - 排序索引:
df.sort_index() - 重置索引:
df.reset_index() - 转换日期和时间数据:
pd.to_datetime() - 等等...
这句话的意思就是选取comment 里面rateContent列里面非空的数据重新赋值给comment
4.d2v_train = pd.concat([pn['words'], comment['words']], ignore_index = True)
pd.concat 是 Pandas 库中的一个函数,用于沿一条轴将多个 pandas 对象(如 Series、DataFrame)连接在一起。这个函数在处理多个 DataFrame 或 Series 时非常有用,尤其是当你需要将它们合并成一个更大的数据集时。
基本用法
- 连接 Series
假设你有两个 Series:
python复制代码
import pandas as pd | |
s1 = pd.Series(['A', 'B', 'C']) | |
s2 = pd.Series(['D', 'E', 'F']) | |
result = pd.concat([s1, s2]) |
这将把 s2 连接到 s1 的后面。
- 连接 DataFrame
你可以沿行(axis=0)或列(axis=1)连接 DataFrame。
沿行连接:
python复制代码
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) | |
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]}) | |
result = pd.concat([df1, df2], ignore_index=True) |
沿列连接:
python复制代码
df3 = pd.DataFrame({'C': [9, 10], 'D': [11, 12]}) | |
result = pd.concat([df1, df3], axis=1) |
参数
- objs:要连接的 pandas 对象列表或字典。
- axis:默认为 0,表示沿行连接。如果为 1,则沿列连接。
- join:默认为 'outer',表示连接操作。对于 DataFrame,这可以是 'inner'(交集)或 'outer'(并集)。
- ignore_index:默认为 False。如果为 True,则忽略原始索引并生成一个新的整数索引。
- keys:对于分层索引,可以提供一个列表或数组作为连接键。
- ...:还有其他参数,但上述是最常用的。
注意事项
- 当连接 DataFrame 时,确保列名匹配(除非你使用
join='outer'并希望保留不匹配的列)。 - 如果 DataFrame 的索引不同,但在连接时你想忽略它们并生成一个新的整数索引,请使用
ignore_index=True。 - 你可以使用字典来连接 DataFrame,其中字典的键将用作新的列级索引。例如:
pd.concat({'key1': df1, 'key2': df2}, axis=1)。
5.dict = pd.DataFrame(pd.Series(w).value_counts())
步骤分解:
-
pd.Series(w): 这里假设w是一个可迭代的对象(如列表),您正在将其转换为一个 Pandas Series。如果w已经是一个 Series,则这一步是多余的。 -
.value_counts(): 对 Series 对象调用value_counts()方法会计算每个唯一值出现的次数,并返回一个 Series,其中索引是唯一值,值是它们出现的次数。 -
pd.DataFrame(...): 接下来,您尝试将这个 Series 转换为一个 DataFrame。虽然这是技术上可行的,但通常当您只处理一个 Series(即一列数据)时,没有必要将其转换为 DataFrame。
6.dict['id']=list(range(1,len(dict)+1))
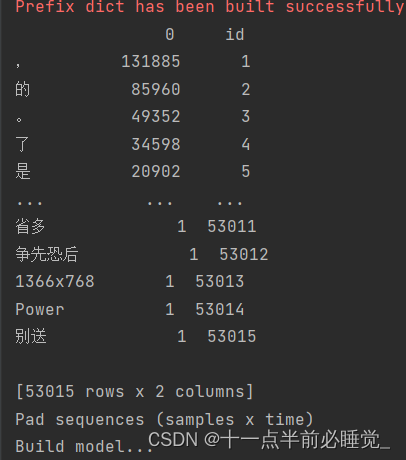
7.
pn['sent'] = pn['words'].apply(get_sent) #速度太慢

8.
x = np.array(list(pn['sent']))[::2] #训练集
在您提供的代码 x = np.array(list(pn['sent']))[::2] 中,您正在对 pn['sent'](假定它是一个Pandas Series、列表或其他可迭代对象)执行几个操作。下面是对这些操作的详细解释:
pn['sent']:这部分代码假定pn是一个Pandas DataFrame,并且'sent'是其中的一个列名。这个列可能包含文本数据、数字或其他任何类型的可迭代数据。list(pn['sent']):这里,您正在将pn['sent']列转换为Python列表。这通常是因为Pandas Series对象虽然可以像列表一样迭代,但有时为了与其他Python库或功能一起使用,您可能需要将其转换为列表。np.array(...):使用NumPy库的array函数将列表转换为一个NumPy数组。NumPy数组是优化过的数据结构,用于存储大量同类型数据,并提供高效的数值计算功能。[::2]:这是一个切片操作,用于从NumPy数组中选取元素。具体来说,[::2]意味着从数组的开始到结束,每隔一个元素取一个。因此,如果原始数组是[a, b, c, d, e],那么切片后的数组将是[a, c, e]。
最终,x 将是一个NumPy数组,其中包含 pn['sent'] 列中每隔一个元素的值。
注意:这里有一个潜在的陷阱。如果 pn['sent'] 列中的元素是字符串(例如文本数据),那么将它们转换为NumPy数组可能不会提供您期望的功能或性能优势,因为NumPy主要用于数值计算,而不是字符串处理。如果您的目标是处理文本数据,那么使用Pandas的字符串方法或Python的内置字符串功能可能更为合适。
总结:
苏大神的思路是用jieba分词,将词汇分出。然后通过词频统计对分过的词进行数字映射。然后这样每一个句子就变成了一个长短不一的向量,再将向量裁切或增加为规定大小的长度。之后将裁切的向量与对于的二分类的标签送入构造的网络中训练。训练后统计准确度。
网络第一层用embedding层来生成语义向量,向量长度为256维。第二层为LSTM层,第三层为Dropout层,第四层为Dense全连接层,第五层为激活层,激活函数为sigmoid二分类激活函数。
思考能否实现多分类细腻情感?喜怒哀乐?
相关文章:
情感分类学习笔记(1)
文本情感分类(二):深度学习模型 - 科学空间|Scientific Spaces 一、代码理解 cw lambda x: list(jieba.cut(x)) #定义分词函数 您给出的代码定义了一个使用 jieba 分词库的分词函数。jieba 是一个用于中文分词的 Python 库。该函数 cw 是…...

EtherCAT运动控制器Delta机械手应用
ZMC406硬件介绍 ZMC406是正运动推出的一款多轴高性能EtherCAT总线运动控制器,具有EtherCAT、EtherNET、RS232、CAN和U盘等通讯接口,ZMC系列运动控制器可应用于各种需要脱机或联机运行的场合。 ZMC406支持6轴运动控制,最多可扩展至32轴&#…...

物联网杀虫灯—新型的环保杀虫设备
型号推荐:云境天合TH-FD2S】物联网杀虫灯是一种新型环保杀虫设备,其中风吸式太阳能杀虫灯作为其一种特殊类型,展现了独特的工作原理和优势。 风吸式太阳能杀虫灯以太阳能电池板为电源,白天储存电源,晚上为杀虫灯提供电…...

加盟零食店的真是大冤种
关注卢松松,会经常给你分享一些我的经验和观点。 我一朋友,在老家县城去年失业没事干,手里有一点钱但不多,就想着自己干点啥 。最后经多方打听考察,加盟了一个零食店,前前后后花去了近五六十万,…...

力扣刷题--数组--第三天
今天再做两道二分查找的题目,关于二分查找的知识可看我前两篇博客。话不多说,直接开干! 题目1:69.x 的平方根 题目详情: 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。由于返回类型是整数&#…...
开源即时通讯IM框架 MobileIMSDK v6.5 发布
一、更新内容简介 本次更新为次要版本更新,进行了bug修复和优化升级(更新历史详见:码云 Release Notes、Github Release Notes)。 MobileIMSDK 可能是市面上唯一同时支持 UDPTCPWebSocket 三种协议的同类开源IM框架。轻量级、高…...

React 第二十七章 Hook useMemo
useMemo 函数可以用于缓存计算结果,以避免不必要的重复计算。 在React的函数组件中,当组件重新渲染时,函数组件内的所有代码都会重新执行。有些计算可能是非常消耗资源的,例如进行复杂的计算或进行网络请求。如果这些计算的结果在…...
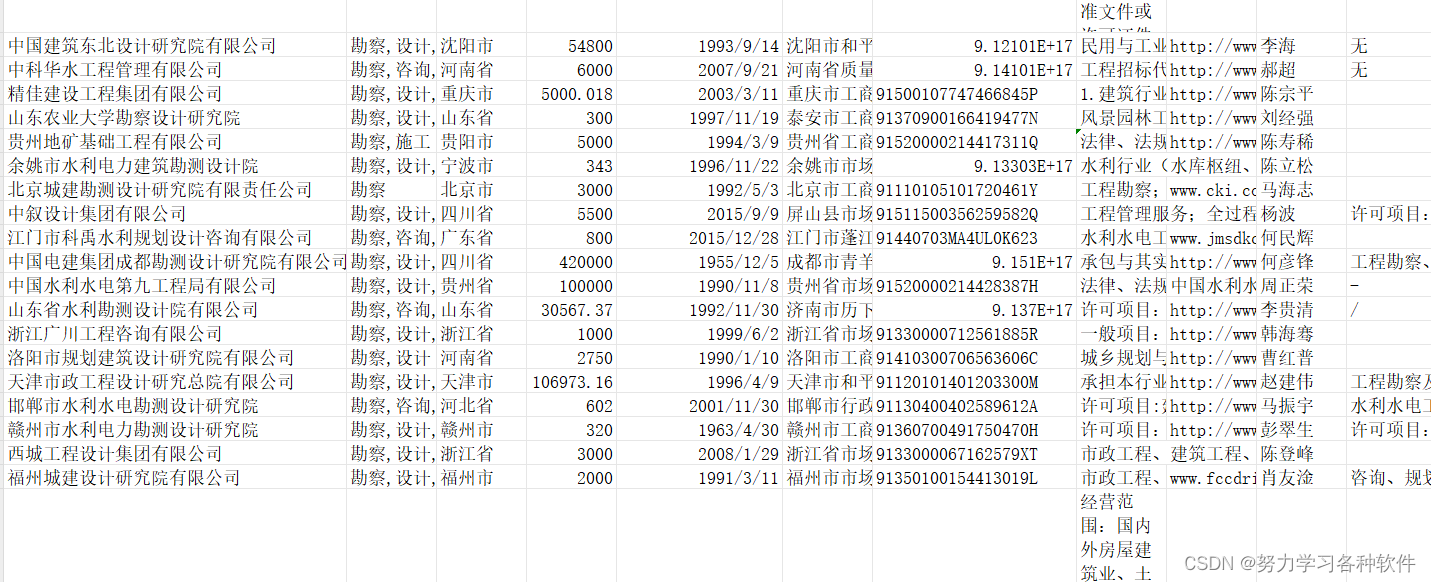
自己写的爬虫小案例
网址:aHR0cDovL2pzc2NqZ3B0Lmp4d3JkLmdvdi5jbi8/dXJsPS92aWV3L3dvcmtpbmdVbml0L3dvcmtpbmdVbml0Lmh0bWw 这串代码能够爬取勘察单位企业的详细信息。 import requests import time import csv f open(勘察单位公司信息.csv,w,encodingutf-8,newline) csv_writer …...

Kafka 环境搭建和使用之单机模式详细教程
上一篇:Kakfa 简介及相关组件介绍 下一篇:Kafka 环境搭建之伪分布式集群详细教程 Kafka 环境搭建 Kafka的环境搭建可以根据不同的需求和场景采取不同的模式,主要包括以下几种: 单机模式(Standalone Mode): 在这种模式下,Kafka、Zookeeper 以及生产者和消费者都在同一…...
Xamarin.Android项目使用ConstraintLayout约束布局
Xamarin.AndroidX.ConstraintLayout Xamarin.Android.Support.Constraint.Layout Xamarin.AndroidX.ConstraintLayout.Solver Xamarin.AndroidX.DataBinding.ViewBinding Xamarin.AndroidX.Legacy.Support.Core.UI Xamarin.AndroidX.Lifecycle.LiveData ![在这里插入图片描述]…...

探索Java 18:未来技术趋势与革新之路
Java,作为一门历史悠久而又历久弥新的编程语言,始终站在技术发展的前沿,引领着软件开发的潮流。随着Java 18的发布,我们再次见证了这门语言的自我迭代与革新。本文将深入探讨Java 18带来的新特性、技术趋势,以及它如何…...

毕业论文怎么写? 推荐4个AI工具
写作这件事一直让我们从小学时期就开始头痛,初高中时期800字的作文让我们焦头烂额,一篇作文里用尽了口水话,拼拼凑凑才勉强完成。 大学时期以为可以轻松顺利毕业,结果毕业前的最后一道坎拦住我们的是毕业论文,这玩意不…...
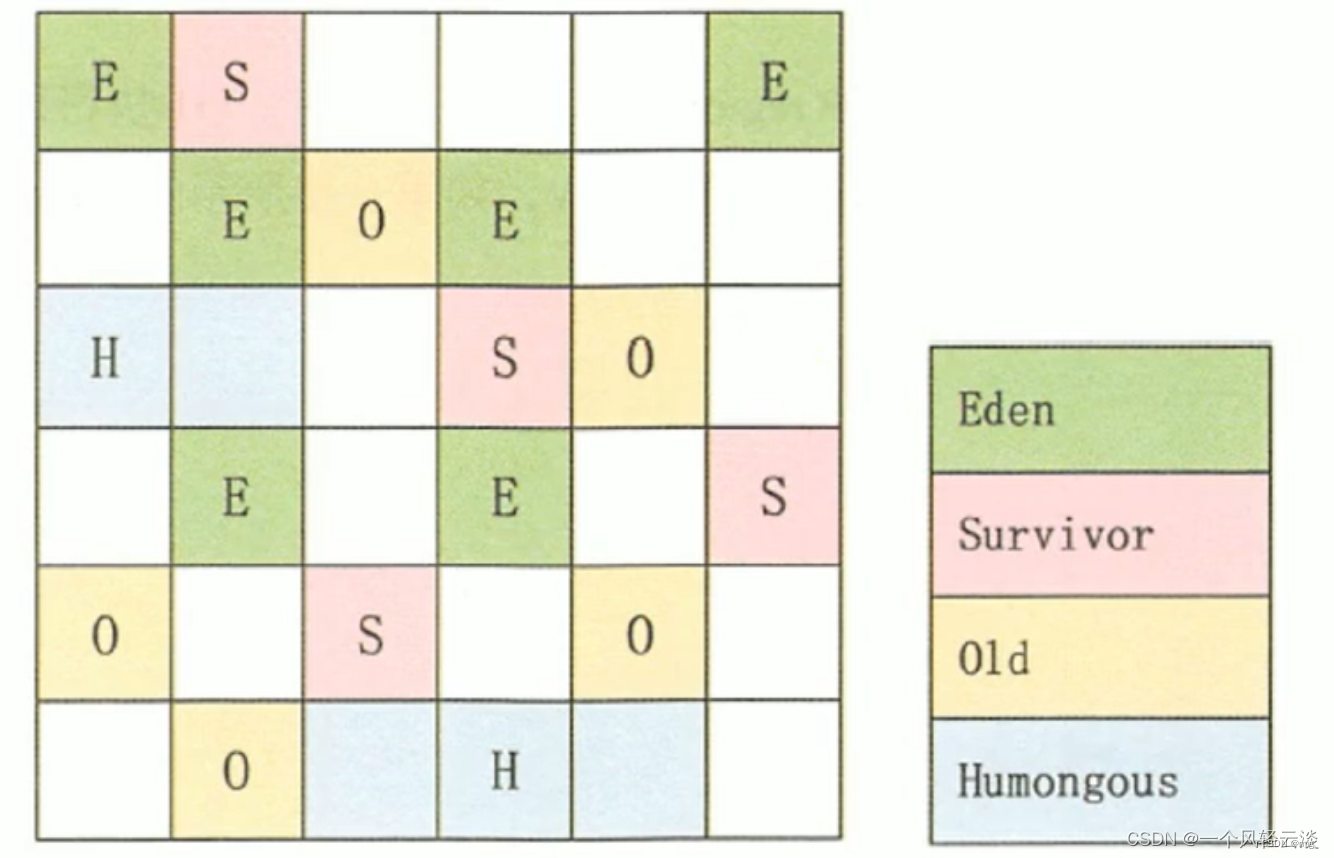
JVM认识之垃圾收集算法
一、标记-清除算法 1、定义 标记-清除算法是最基础的垃圾收集算法。它分为标记和清除两个阶段。先标记出所有需要回收的对象(即垃圾),在标记完成后再统一回收所有垃圾对象。 2、优点和缺点 优点:实现简单缺点: 可能…...

docker-compose部署gitlab
需要提前安装docker和docker-compose环境 参考:部署docker-ce_安装部署docker-ce-CSDN博客 参考:docker-compose部署_docker compose部署本地tar-CSDN博客 创建gitlab的数据存放目录 mkdir /opt/gitlab && cd mkdir /opt/gitlab mkdir {conf…...
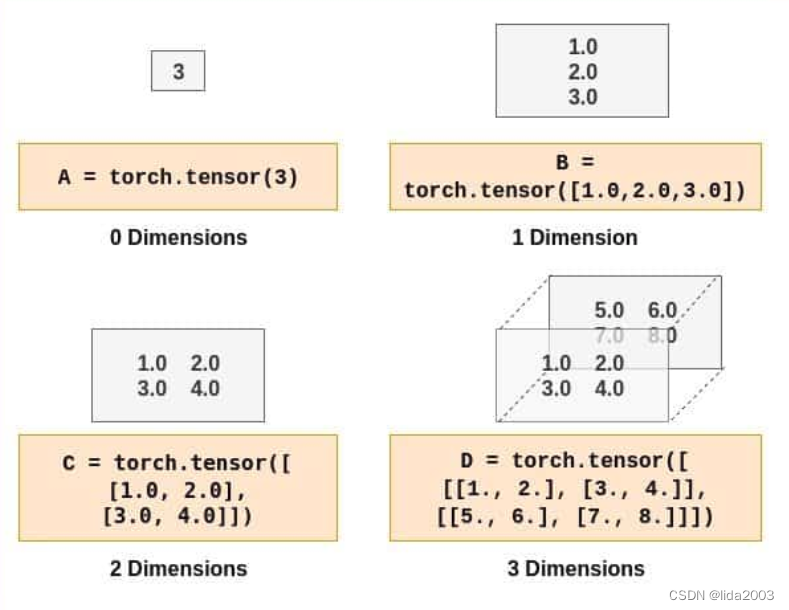
Colab/PyTorch - 001 PyTorch Basics
Colab/PyTorch - 001 PyTorch Basics 1. 源由2. PyTorch库概览3. 处理过程2.1 数据加载与处理2.2 构建神经网络2.3 模型推断2.4 兼容性 3. 张量介绍3.1 构建张量3.2 访问张量元素3.3 张量元素类型3.4 张量转换(NumPy Array)3.5 张量运算3.6 CPU v/s GPU …...

翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习三
合集 ChatGPT 通过图形化的方式来理解 Transformer 架构 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习一翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习二翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深…...

基于Seata实现分布式事务实现
Seata 是一个开源的分布式事务解决方案,它提供了高性能和简单易用的分布式事务服务。Seata 将事务的参与者分为 TC(Transaction Coordinator)、TM(Transaction Manager)和 RM(Resource Manager)…...
adss光缆是什么意思
adss光缆,adss光缆型号,adss光缆用途 什么是adss光缆 ADSS用于高压输电线路并利用电力系统输电塔干,整个光缆为非金属介质,自承悬挂于电力铁塔上的电力强度最小的位置。它运用于已建高压输电线路,具有安全性高&#…...
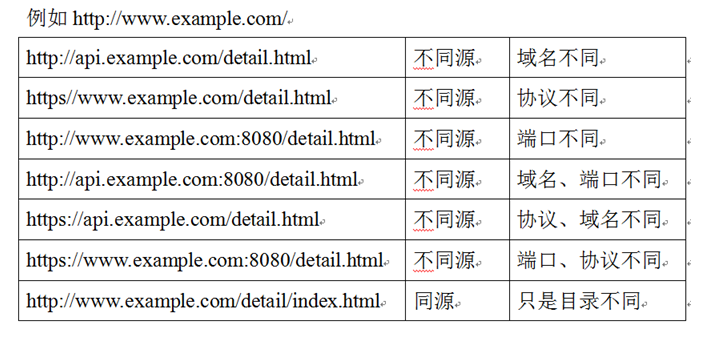
JavaScript异步编程——04-同源和跨域
同源和跨域 同源 同源策略是浏览器的一种安全策略,所谓同源是指,域名,协议,端口完全相同。 跨域问题的解决方案 从我自己的网站访问别人网站的内容,就叫跨域。 出于安全性考虑,浏览器不允许ajax跨域获取…...

出差——蓝桥杯十三届2022国赛大学B组真题
问题分析 该题属于枚举类型,遍历所有情况选出符合条件的即可。因为只需要派两个人,因此采用两层循环遍历每一种情况。 AC_Code #include <bits/stdc.h> using namespace std; string str;//选择的两人 bool ok(){if(str.find("A")!-1…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

ZYNQ中断避坑指南:PL端信号线如何正确‘连线’到PS端处理函数?
ZYNQ中断系统深度解析:从硬件信号到软件响应的全链路实践 在嵌入式系统开发中,中断处理是实时响应的核心机制。对于ZYNQ这种集成了ARM处理器(PS)和可编程逻辑(PL)的异构计算平台,其中断系统既有传统处理器的特性,又具备FPGA灵活定…...