Hadoop生态系统的核心组件探索
理解大数据和Hadoop的基本概念
当我们谈论“大数据”时,我们指的是那些因其体积、速度或多样性而难以使用传统数据处理软件有效管理的数据集。大数据可以来自多种来源,如社交媒体、传感器、视频监控、交易记录等,通常包含了TB(太字节)甚至PB(拍字节)级别的数据。
大数据的特征
大数据通常被描述为具有以下四个“V”特征:
- 体积(Volume):数据的规模非常大,传统数据库难以存储和处理。
- 速度(Velocity):数据以极快的速度生成,需要快速处理和分析。
- 多样性(Variety):数据来自多种来源,格式多样,包括结构化数据、非结构化数据和半结构化数据。
- 价值(Value):虽然大数据的价值密度较低,但通过适当的分析可以提取出有价值的信息。
Hadoop的基本概念
Hadoop是一个开源框架,由Apache Software Foundation开发,用于存储和处理大数据。它设计用来从单台服务器扩展到数千台机器,每台机器都提供本地计算和存储。Hadoop框架的核心有两部分:
- Hadoop分布式文件系统(HDFS):一种分布式文件系统,能在多个物理服务器上存储极大量的数据,提供高吞吐量的数据访问,非常适合大规模数据集的应用。
- MapReduce:一种编程模型,用于大规模数据集的并行运算。它将应用分为两个阶段:Map阶段和Reduce阶段。Map阶段处理输入的数据,生成一系列中间键值对,Reduce阶段则对这些键值对进行排序和汇总,产生最终结果。
Hadoop的作用
Hadoop使得企业能够以可扩展的方式存储、处理和分析大数据。其优势包括:
- 可扩展性:Hadoop支持从单个服务器到成千上万台服务器的无缝扩展。
- 成本效益:使用廉价的商用硬件即可部署,降低存储成本。
- 灵活性:能处理各种形式的结构化和非结构化数据。
- 容错性:通过自动保存数据的多个副本来处理硬件故障。
通过使用Hadoop及其生态系统中的其他工具(如Apache Hive、Apache HBase、Apache Spark等),组织可以有效地解决大数据带来的挑战,从而挖掘数据的潜在价值。这种能力使得Hadoop成为当前大数据技术中非常重要的一环。
安装和配置Hadoop
在本地或云环境中安装Hadoop,熟悉Hadoop的基础架构,包括HDFS(Hadoop分布式文件系统)和YARN(资源管理器)
安装和配置Hadoop是进入大数据领域的重要一步。Hadoop可以在单机(伪分布式)模式、完全分布式模式或者云环境中安装。以下是基于单机模式的安装步骤,适合初学者进行学习和实验。
系统要求
- 操作系统:Linux和Unix环境是最推荐的,Windows也可以通过Cygwin或者Windows Subsystem for Linux来使用。
- 内存:至少需要2GB内存,更多内存会更好。
- 硬盘空间:至少需要10GB的空闲硬盘空间。
安装步骤
-
安装Java:Hadoop是用Java编写的,因此需要安装Java Development Kit (JDK)。可以通过访问Oracle的网站或使用开源版本如OpenJDK。
sudo apt update sudo apt install openjdk-11-jdk安装完成后,你可以通过运行
java -version来检查Java是否安装成功。 -
下载和解压Hadoop:从Apache Hadoop的官方网站下载适合你系统的Hadoop发行版。
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz tar -xzvf hadoop-3.3.1.tar.gz mv hadoop-3.3.1 /usr/local/hadoop -
配置Hadoop环境变量:编辑你的shell配置文件(如
.bashrc或.bash_profile),添加Hadoop和Java的环境变量。export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin保存并执行
source ~/.bashrc以应用更改。 -
配置Hadoop文件:编辑Hadoop配置文件,设置Hadoop的运行环境。
hadoop-env.sh:设置Java环境变量。export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64core-site.xml:配置HDFS的默认文件系统URI。<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property> </configuration>hdfs-site.xml:设置HDFS的副本数。<configuration><property><name>dfs.replication</name><value>1</value></property> </configuration>mapred-site.xml:设置MapReduce的运行框架。<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property> </configuration>yarn-site.xml:配置YARN的资源管理器。<configuration><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property> </configuration>
-
格式化HDFS:在启动Hadoop之前,需要格式化HDFS文件系统。
hdfs namenode -format -
启动Hadoop:启动HDFS和YARN。
start-dfs.sh start-yarn.sh -
验证安装:检查Hadoop是否成功运行。
jps应该会看到如
Namenode、Datanode、ResourceManager、NodeManager等进程。
总结
以上步骤将帮助你在单机环境中安装和运行Hadoop,适合进行基本的学习和开发。对于生产环境或大规模数据处理,建议使用完全分布式模式或云平台服务。
学习HDFS的架构,理解NameNode和DataNode的功能,练习基本的文件操作命令
在Hadoop生态系统中,Hadoop分布式文件系统(HDFS)是一个关键组件,专门设计用于存储大规模数据。理解HDFS的架构以及其核心组件,如NameNode和DataNode,是有效使用Hadoop的基础。
HDFS架构简介
HDFS是一个主从(Master/Slave)架构,其设计目的是在廉价硬件上可靠地存储大量数据,并确保高吞吐量的数据访问。HDFS架构主要由以下两种类型的节点组成:
-
NameNode(主节点):
- NameNode是HDFS的心脏,负责文件系统的元数据管理。它不存储实际数据,而是维护整个文件系统的目录树以及所有文件和目录的元数据信息,例如文件的权限、大小和文件块的位置信息等。
- NameNode还负责客户端对文件的打开、关闭、重命名等请求,并确定文件数据块的映射。
-
DataNode(从节点):
- DataNode负责管理存储在其上的数据。每个DataNode在文件系统中存储数据块(通常大小为128MB),并负责处理这些块的创建、删除和复制。
- 在NameNode的控制下,DataNodes会定期向NameNode发送心跳和块报告,以表明它们正常工作,并提供它们所持有的所有数据块的列表。
文件操作命令
HDFS提供了一系列类似于传统Unix文件系统的命令行工具,可以用来操作存储在HDFS中的数据。在进行文件操作前,确保Hadoop服务正在运行。以下是一些基本的文件操作命令:
-
列出目录(ls):
hdfs dfs -ls /path/to/directory -
创建目录(mkdir):
hdfs dfs -mkdir /path/to/new/directory -
上传文件到HDFS(copyFromLocal):
hdfs dfs -copyFromLocal /local/path/to/file /path/in/hdfs -
从HDFS下载文件(copyToLocal):
hdfs dfs -copyToLocal /path/in/hdfs /local/path/to/file -
删除文件或目录(rm):
hdfs dfs -rm /path/in/hdfs使用
-r选项可以递归删除目录。 -
查看文件内容(cat):
hdfs dfs -cat /path/to/file -
移动或重命名文件(mv):
hdfs dfs -mv /path/source /path/destination
通过熟练使用这些命令,你可以有效地管理存储在HDFS中的数据。这些基本操作是掌握Hadoop的基础,并对进行更高级的数据处理和分析活动至关重要。
深入学习MapReduce编程模型,编写简单的MapReduce程序,了解其在数据处理中的应用
MapReduce 是一个编程模型和一个用于处理和生成大数据集的相关实现。通过MapReduce,开发者可以编写应用程序来并行处理大量的数据。MapReduce 模型主要包含两个步骤:Map(映射)阶段和 Reduce(归约)阶段。
MapReduce 编程模型概述
-
Map 阶段:
- 输入:输入数据通常是键值对的形式。
- 处理:Map函数处理输入数据,并为每个元素生成中间键值对。
- 目的:通常用于过滤、排序、分类等数据预处理任务。
-
Reduce 阶段:
- 输入:来自Map阶段的中间键值对。
- 处理:Reduce函数对每个键对应的值列表进行归约,输出结果集。
- 目的:通常用于汇总、计算总和、平均或其他统计数据。
示例:编写一个简单的MapReduce程序
假设我们有一个文本文件,我们想要计算文件中每个单词的出现次数。以下是使用Java和Hadoop MapReduce框架来实现的基本步骤:
环境准备
确保你已经设置好了Java开发环境和Hadoop。你需要编写Java代码,并将其打包为JAR文件在Hadoop上运行。
1. 编写 Map 函数
Map函数读取文本输入(通常是TextInputFormat),将每行文本转换成单词,并输出每个单词与数字1作为键值对。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] words = value.toString().split("\\s+");for (String str : words) {word.set(str);context.write(word, one);}}
}
2. 编写 Reduce 函数
Reduce函数接收来自Map函数的输出,并对相同的键(单词)的值(出现的次数)进行求和。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}
}
3. 配置和运行
你需要设置一个驱动程序,它将配置MapReduce作业,包括输入输出格式、键值类型等。
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static void main(String[] args) throws Exception {if (args.length != 2) {System.err.println("Usage: WordCount <input path> <output path>");System.exit(-1);}Job job = Job.getInstance();job.setJarByClass(WordCount.class);job.setJobName("Word Count");FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
这个程序需要编译成JAR文件,并在Hadoop集群上运行。运行时,你需要指定输入文件的路径和输出目录的路径。
小结
通过这个简单的例子,你可以看到MapReduce模型如何用于处理分布式数据。MapReduce不仅限于文字处理,还可以扩展到各种复杂的数据处理场景,如图数据处理、大规模机器学习等。
了解YARN的工作机制和架构,学习如何在YARN上运行应用程序
YARN(Yet Another Resource Negotiator)是Hadoop 2.x引入的资源管理平台,它将作业调度和资源管理的功能从Hadoop的旧MapReduce系统中分离出来,以提供更广泛的数据处理。YARN允许多种数据处理引擎如MapReduce、Spark等在同一平台上有效并行运行,优化了资源利用率。
YARN的核心组件
-
ResourceManager (RM):ResourceManager是YARN架构的核心,负责整个系统的资源管理和分配。它包括两个主要组件:
- 调度器(Scheduler):调度器负责分配资源给各个正在运行的应用程序,但它不负责监控或跟踪应用程序的状态,也不重新启动失败的任务。
- 应用程序管理器(ApplicationManager):处理来自客户端的应用程序提交请求,负责为每个应用程序实例启动一个ApplicationMaster,并监控其状态,重新启动失败的ApplicationMaster。
-
NodeManager (NM):每个集群节点上都运行一个NodeManager,它负责该节点的资源(如CPU、内存等)的管理和监控,并处理来自ResourceManager的任务。
-
ApplicationMaster (AM):每个应用程序都有一个ApplicationMaster,它负责协调应用程序中所有的任务,向Scheduler请求资源,并监控任务执行,处理任务失败和资源调整。
YARN的工作流程
-
提交应用程序:
- 开发者或最终用户将应用程序代码及其配置(如jar包、相关文件等)提交给ResourceManager。
-
启动ApplicationMaster:
- ResourceManager为新应用程序启动一个ApplicationMaster实例。ApplicationMaster在获得资源(如CPU、内存等)后在某个NodeManager上启动。
-
资源请求和任务调度:
- ApplicationMaster向ResourceManager的Scheduler请求所需的资源来运行应用程序的任务。
- 一旦资源被授予,ApplicationMaster将与相应的NodeManager通信,后者将启动和监控任务。
-
任务执行:
- NodeManager负责监控其上运行的任务的执行,并向ApplicationMaster报告任务的进度和状态。
-
完成执行:
- 应用程序完成后,ApplicationMaster将状态报告给ResourceManager,释放所有资源,并关闭自身。
如何在YARN上运行应用程序
以运行一个简单的MapReduce作业为例,过程如下:
-
准备作业配置:确保你的MapReduce作业(如jar文件和相关配置)已准备好。
-
提交作业:
- 使用Hadoop命令行工具提交MapReduce作业:hadoop jar example-job.jar MainClass -input input-path -output output-path
- 这条命令会通知ResourceManager,随后ResourceManager启动一个ApplicationMaster,ApplicationMaster负责作业的具体执行过程。
-
监控作业:
- 可以通过YARN的Web界面(ResourceManager的Web UI通常可通过
http://<ResourceManager-Host>:8088访问)来监控作业的执行状态和进度。
- 可以通过YARN的Web界面(ResourceManager的Web UI通常可通过
YARN极大地提高了Hadoop生态系统的灵活性和资源利用率,允许更多种类的计算任务在同一个集群上高效运行。通过以上步骤,你可以在YARN上成功地部署和运行各种大数据应用程序。
探索Hadoop生态系统
Hive:学习Hive的SQL-like查询语言,理解如何在Hadoop上进行数据仓库操作。
Apache Hive 是建立在Hadoop上的一个数据仓库工具,它可以让开发者使用类似于SQL的查询语言(HiveQL)来读写存储在分布式文件系统中的数据。Hive 使得数据汇总、查询和分析变得更容易,特别是对于那些熟悉SQL的用户。
Hive 的基本概念
-
HiveQL:
- HiveQL 是 Hive 使用的查询语言,其语法非常类似于 SQL。它允许用户执行数据查询、数据插入以及多种统计工作,而无需了解底层的Java API。
- HiveQL 也支持MapReduce的自定义脚本,以便进行复杂的数据分析。
-
元数据:
- Hive 将结构信息(如表定义)存储在元数据中。默认情况下,这些信息存储在关系数据库中,如MySQL或PostgreSQL。
- 元数据包括关于表、列以及它们的数据类型等信息。
-
表和分区:
- Hive允许用户在其上定义表。这些表映射到HDFS上的数据。用户可以查询这些表而感觉就像在操作传统数据库一样。
- 分区是一种将表数据分成多个部分以优化查询的方法。例如,按日期分区可以让用户更快地查询特定日期的数据。
-
存储格式:
- Hive支持多种存储格式,包括文本文件、Parquet、ORC等。每种格式都有其优点和使用场景。
Hive 的使用场景
- 数据仓库应用:Hive 适用于管理数据仓库的任务,特别是涉及大量数据且不需要实时查询的场景。
- 日志处理:Hive 经常用于处理和分析大型数据集,如Web服务器日志。
- 数据挖掘:Hive 支持SQL-like查询,可以用来执行复杂的数据分析和数据挖掘任务。
如何在Hive上进行操作
假设你已经安装并配置好了Hive环境,以下是一些基本的Hive操作:
-
启动Hive:
hive -
创建表:
CREATE TABLE employees (id INT,name STRING,age INT,department STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; -
加载数据:
- 假设你的数据存储在
/user/hive/warehouse/employees.txt:
LOAD DATA INPATH '/user/hive/warehouse/employees.txt' INTO TABLE employees; - 假设你的数据存储在
-
查询数据:
SELECT name, age FROM employees WHERE department = 'Sales'; -
聚合查询:
SELECT department, COUNT(*) FROM employees GROUP BY department;
小结
Hive 提供了一个高级的抽象,允许用户使用类似SQL的语法来处理存储在Hadoop生态系统中的大数据。通过使用Hive,组织能够对其数据进行复杂的分析和报告,而无需详细了解底层的MapReduce编程模式。这使得数据分析变得更加容易,特别是对于那些已经熟悉SQL的用户。
Pig:学习Pig的脚本语言,探索其在数据分析中的用途。
Apache Pig 是一个高级平台,用于创建MapReduce程序用于运行在Hadoop集群上。Pig 的核心是一种名为Pig Latin的脚本语言,这种语言为数据分析提供了一种简化的方法,特别是对于非结构化或半结构化的大数据集。Pig Latin 能够处理数据连接、过滤、聚合等操作,并自动转换成底层的MapReduce任务。
Pig Latin 语言概述
Pig Latin 是一种过程性语言,其设计理念是让数据流和转换过程写起来更直观。Pig Latin 代码通常包括一系列的数据转换操作,每一个操作都处理数据,并生成一个新的数据集,供后续操作使用。这些操作被称为转换(transformation)和动作(action)。
基本特性和操作
-
加载和存储数据:
- LOAD:用于读取存储在HDFS或其他数据存储中的数据。
- STORE:用于将结果写回存储系统。
A = LOAD '/path/to/data' USING PigStorage(',') AS (field1: type1, field2: type2, ...); STORE A INTO '/output/path' USING PigStorage(','); -
数据转换:
- FILTER:根据条件过滤数据行。
- FOREACH/GENERATE:生成新的数据集合,可能会添加或转换列。
- GROUP:根据一个或多个字段对数据集合进行分组。
- JOIN:根据一个或多个键将两个数据集合连接起来。
B = FILTER A BY field1 > 100; C = FOREACH A GENERATE field1, field2*2; D = GROUP A BY field1; E = JOIN A BY field1, B BY field1; -
聚合操作:
- 使用聚合函数如
SUM(),COUNT(),MIN(),MAX()等在GROUP操作后进行数据汇总。
F = GROUP A BY field1; G = FOREACH F GENERATE group AS field1, SUM(A.field2) AS sum_field2; - 使用聚合函数如
Pig 的应用场景
- 数据管道:Pig 很适合用来开发数据处理管道(即数据的连续处理和转换序列),特别是当数据模型和数据处理需求经常变化时。
- 原型开发和快速迭代:在数据分析中,初期经常需要对数据进行探索和实验,Pig 的灵活性让这个过程更快、更高效。
- 复杂的数据处理:Pig 的设计使得它非常适合进行复杂的数据转换和多步骤的数据分析,例如复杂的联接和迭代数据过滤。
小结
Pig 提供了一种高效的方式来处理大数据,特别是对于数据准备和初步分析阶段。通过使用Pig Latin,开发者可以更容易地描述数据的处理流程,而不用深入到MapReduce编程的复杂性中。Pig 的这些特性使其在数据分析师和工程师之间非常受欢迎,尤其是在需要处理大规模数据集的场景中。
HBase:了解HBase的非关系型数据库特性,学习如何在HBase上进行实时读写操作。
Apache HBase 是一个开源的非关系型分布式数据库(NoSQL),基于Google的BigTable模型构建,并运行在Hadoop的文件系统(HDFS)之上。HBase设计用于提供快速的随机访问大量结构化数据,使其成为处理大规模数据集的理想选择,尤其是在需要实时查询和更新的场景中。
HBase的非关系型数据库特性
-
列存储:与传统的关系数据库不同,HBase是基于列的存储系统。数据是按列族(column family)组织存储的,这意味着来自同一列族的数据存储在一起,优化了读写性能。
-
可扩展性:HBase通过分布式架构实现水平扩展。它使用HDFS作为其底层存储,支持使用Zookeeper进行集群协调。
-
高可用性和容错性:HBase支持数据的自动分区和故障恢复。它将表自动分割为多个区域(regions),这些区域可以分布在集群的不同服务器上。
-
强一致性:对于单个行的操作,HBase提供强一致性,确保每次读取都能返回最新写入的数据。
如何在HBase上进行实时读写操作
在HBase中进行数据操作通常涉及使用HBase的Shell或通过编程方式使用HBase API。这里我们首先介绍如何使用HBase Shell来执行基本的CRUD(创建、读取、更新、删除)操作:
启动HBase Shell
hbase shell创建表
在HBase中,你需要定义至少一个列族(column family)来创建表:
create 'test', 'data'这里创建了一个名为test的表,包含一个名为data的列族。
写入数据
使用put命令向表中插入数据。你需要指定表名、行键、列族和列限定符,以及值:
put 'test', 'row1', 'data:name', 'John Doe'
put 'test', 'row1', 'data:age', '30'
这些命令在test表的row1行键下的data列族中写入了两个列:name和age。
读取数据
使用get命令读取数据。你需要指定表名和行键:
get 'test', 'row1'这将显示row1中所有列的数据。
更新数据
更新数据只需再次对相同的行键和列执行put命令。例如,更新上述年龄:
put 'test', 'row1', 'data:age', '31'
删除数据
使用delete命令删除特定列的数据,或使用deleteall删除整行数据:
delete 'test', 'row1', 'data:age'
deleteall 'test', 'row1'
扫描表
使用scan命令查看表中的数据:
scan 'test'
使用HBase API进行编程操作
对于需要在应用程序中集成HBase的场景,你可以使用HBase提供的API来编程实现上述操作。这通常涉及到设置一个Configuration对象,使用Connection创建一个到HBase的连接,然后通过这个连接创建Table对象来进行操作。
以下是一个简单的Java代码示例,演示如何连接HBase并插入数据:
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "localhost");
try (Connection connection = ConnectionFactory.createConnection(config);Table table = connection.getTable(TableName.valueOf("test"))) {Put put = new Put(Bytes.toBytes("row1"));put.addColumn(Bytes.toBytes("data"), Bytes.toBytes("name"), Bytes.toBytes("John Doe"));table.put(put);
}
在这个示例中,我们创建了一个连接到HBase的Connection对象,接着获取test表的句柄,并向其中插入一行数据。
总结
HBase提供了一个高效、可扩展的非关系型数据库平台,特别适合于处理大量的实时读写请求。通过HBase Shell或API,用户可以方便地在Hadoop环境中进行复杂的数据操作和分析。
进阶应用与优化
性能优化:学习如何优化Hadoop作业的执行时间和资源使用
优化Hadoop作业是提高大数据处理效率、减少资源消耗和缩短处理时间的重要步骤。在Hadoop中,性能优化通常涉及到对作业配置、资源分配和代码调优的综合考虑。下面是一些关键的优化策略:
1. 理解数据和工作负载
- 数据倾斜:数据倾斜是Hadoop作业中常见的问题,可能导致某些Reducer处理的数据远多于其他Reducer。使用Hadoop的计数器来检查Map和Reduce阶段的输出记录数,如果发现极大的不平衡,考虑重新设计键的分配方式。
- 输入数据格式:选择合适的输入格式对性能有重要影响。例如,使用列式存储格式(如Parquet或ORC)可以提高扫描效率,减少IO操作。
2. 优化MapReduce算法
- 合理使用Map和Reduce阶段:不是所有的处理都需要Reduce阶段,有些情况下仅使用Map阶段即可完成任务,这可以显著减少网络传输和数据排序的开销。
- 减少数据传输:在Map到Reduce阶段尽可能减少数据传输。例如,可以在Map阶段进行聚合或过滤,减少发送到Reducer的数据量。
- 合并小文件:Hadoop处理大量小文件时效率较低,因为每个文件的读取都需要单独的输入分割和Map任务。可以在作业运行前使用工具如
SequenceFile或Parquet来合并这些小文件。
3. 配置调整
- 内存和CPU的适当配置:合理配置Map和Reduce任务的内存可以防止OOM(Out of Memory)错误并提高性能。同样,为Map和Reduce任务分配适当的CPU核心数量也很重要。
<property><name>mapreduce.map.memory.mb</name><value>2048</value> </property> <property><name>mapreduce.reduce.memory.mb</name><value>4096</value> </property> - 调整并行度:适当增加Map和Reduce任务的并行度可以加速处理过程,但过多的并行度可能会增加管理开销并降低吞吐量。并行度通常通过设置
mapreduce.job.maps和mapreduce.job.reduces进行调整。
4. 使用压缩
- 启用压缩:在MapReduce中启用数据压缩可以减少磁盘IO和网络传输的数据量。可以为Map输出和最终输出启用压缩。支持的压缩格式包括Gzip, Bzip2, Snappy等。
<property><name>mapreduce.map.output.compress</name><value>true</value> </property> <property><name>mapreduce.output.fileoutputformat.compress</name><value>true</value> </property>
5. 利用YARN资源管理
- 调整YARN容器大小:YARN容器的大小应根据任务的需求来配置,以避免资源浪费。对于内存和CPU资源需求较高的应用,增加容器资源配置可以提高性能。
- 调整队列管理:在YARN中,使用队列来管理不同优先级或者部门的资源分配。合理配置队列可以确保重要的作业获得足够的资源,提高作业执行的优先级。
通过上述策略,你可以有效地优化Hadoop作业,改进执行时间和资源使用效率。每个策略的实施需要根据具体情况和作业特性来调整,通常需要在实际环境中多次测试和调整。
数据安全与管理:探索如何在Hadoop生态系统中实现数据安全,例如使用Kerberos
在Hadoop生态系统中实现数据安全是非常重要的,因为这些系统通常处理大量敏感数据。保护这些数据免受未经授权的访问和其他安全威胁是至关重要的。一个完善的Hadoop数据安全策略包括认证、授权、审计和数据保护等多个方面。
认证 - Kerberos
Kerberos 是一个基于票据的认证协议,它允许节点在不安全网络中相互验证身份。在Hadoop中,Kerberos是实现强认证的标准方式。启用Kerberos后,Hadoop集群中的每个服务和用户都必须拥有有效的Kerberos凭证才能进行交互。
设置Kerberos认证
- 安装Kerberos服务器:首先,你需要在你的网络环境中设置一个Kerberos KDC(Key Distribution Center)服务器。
- 为Hadoop服务配置Principal:在Kerberos中,每个服务和用户都需要一个Principal。例如,HDFS、YARN和其他组件都需要各自的Principal。
- 配置Hadoop集群:在Hadoop的配置文件中设置Kerberos认证,如
core-site.xml和hdfs-site.xml:<property><name>hadoop.security.authentication</name><value>kerberos</value> </property> <property><name>dfs.namenode.kerberos.principal</name><value>nn/_HOST@YOUR-REALM.COM</value> </property> - 分发和管理票据:使用Kerberos的票据(ticket)管理工具如kinit来管理用户和服务的票据。
授权 - Apache Ranger 和 Apache Sentry
一旦认证机制到位,下一步是控制对数据的访问。Apache Ranger 和 Apache Sentry 都是管理细粒度访问控制的工具。
- Apache Ranger:提供了一个中心化的平台来定义、管理和监控数据访问策略,支持HDFS、Hive、HBase等。Ranger可以集成Kerberos认证,并提供用户界面来配置策略。
- Apache Sentry:是一个基于角色的授权模型,专门用于Hive和Impala。Sentry通过定义角色和权限来管理用户和组对数据的访问。
审计
审计是数据安全的一个重要方面,因为它记录了谁访问了什么数据以及何时访问。这对于遵守法规和检测潜在的安全问题至关重要。
- Apache Ranger 提供了审计功能,可以记录所有数据访问的详细信息,并将审计日志发送到外部系统如Solr或HDFS。
数据保护 - 加密
在Hadoop生态系统中,数据在传输和静态时都应该被加密,以保护数据不被未授权访问。
- HDFS透明加密:Hadoop提供了HDFS透明加密(Transparent Data Encryption, TDE),它允许管理员在HDFS级别对数据进行加密,同时保持操作的透明性。
通过实施这些策略,你可以有效地增强Hadoop生态系统的数据安全。每个组织可能需要根据自己的具体需求和安全政策来定制这些策略。
使用Spark
虽然Spark不是Hadoop的一部分,但它是处理大数据的另一个重要工具。学习Spark的基础,如RDDs和DataFrames。
Apache Spark 是一个强大的开源处理框架,支持快速的大数据分析。它设计用来进行高性能的数据处理和分析,尤其是对于复杂的数据转换和机器学习任务。虽然Spark可以独立运行,但它通常与Hadoop生态系统一起使用,利用HDFS作为存储层。
Spark的核心概念
-
弹性分布式数据集(RDD):
- RDD是Spark的基本数据结构,代表一个不可变、分布式的数据集合。一个RDD可以跨多个计算节点分布存储,以实现高效的并行处理。
- RDD支持两种类型的操作:转换(transformations)和行动(actions)。转换操作如
map和filter会创建一个新的RDD,而行动操作如count和collect则会计算结果并返回给驱动程序。
-
数据帧(DataFrame):
- DataFrame是Spark的另一核心概念,建立在RDD之上,提供了一个高级抽象。它允许开发者使用类似SQL的接口来操作数据。
- DataFrame带有一个模式(schema),意味着每一列的数据类型都是已知的,这使得Spark可以使用更多的优化技术来提高查询的执行速度。
Spark的架构
- Driver程序:运行你的主程序并创建SparkContext,负责向集群提交各种并行操作。
- 集群管理器:负责管理集群资源(包括Standalone,Mesos,YARN或Kubernetes)。
- Executor进程:在集群的节点上运行,负责执行任务,存储数据,并与Driver程序交互。
使用RDD
from pyspark import SparkContext
sc = SparkContext("local", "First App")# 创建RDD
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)# 执行转换和行动操作
distData = distData.map(lambda x: x * x) # 平方
print(distData.collect()) # [1, 4, 9, 16, 25]
使用DataFrame
from pyspark.sql import SparkSession# 初始化SparkSession
spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()# 创建DataFrame
data = [("James", 34), ("Anna", 20), ("Julia", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data).toDF(*columns)# DataFrame操作
df.show()
df.filter(df.Age > 25).show() # 选择年龄大于25的行
小结
Spark为大规模数据处理提供了极高的灵活性和性能,特别是在需要复杂数据处理或实时处理的场景中。通过RDD和DataFrame,开发者可以高效地处理大数据,同时享受到Spark提供的丰富的库和API支持,如Spark SQL, MLlib(机器学习)和GraphX(图处理)。
项目实践:选择一个实际问题,使用Hadoop生态系统的工具来解决。这可以是数据清洗、转换、分析或者是建立数据仓库
我们将使用Hadoop工具来建立一个数据仓库,该数据仓库用于分析社交媒体上的用户行为数据。
项目概述:社交媒体数据分析
目标:分析社交媒体数据,以洞察用户行为和网络互动模式。数据将包括用户帖子、回复、点赞数和分享数等。
工具:使用Hadoop、Hive和Pig。
步骤:
1. 数据收集
- 数据来源:假设你已经有了一个包含社交媒体活动的原始数据集,可能是从APIs抓取的JSON文件。
2. 数据预处理
- 使用Hadoop:首先,将原始数据上传到HDFS。
hdfs dfs -put local_path/social_media_data /data/social_media - 使用Pig:编写Pig脚本来清洗数据,如过滤无效或不完整的记录,抽取必要字段等。
raw_data = LOAD '/data/social_media' USING JsonLoader('user_id:int, post_id:int, message:chararray, likes:int, shares:int, replies:int'); filtered_data = FILTER raw_data BY user_id IS NOT NULL AND post_id IS NOT NULL; STORE filtered_data INTO '/data/processed_social_media' USING PigStorage(',');
3. 数据仓库构建
- 使用Hive:创建Hive表来存储和查询数据。
CREATE TABLE social_media (user_id INT,post_id INT,message STRING,likes INT,shares INT,replies INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;LOAD DATA INPATH '/data/processed_social_media' INTO TABLE social_media;
4. 数据分析
- 查询分析:使用Hive进行SQL查询,分析数据,如计算平均点赞数,最活跃的用户等。
SELECT user_id, AVG(likes) AS avg_likes FROM social_media GROUP BY user_id ORDER BY avg_likes DESC; SELECT message, COUNT(*) AS total_shares FROM social_media GROUP BY message ORDER BY total_shares DESC;
5. 可视化和报告
- 结果应用:将查询结果导出到Excel或使用BI工具进行可视化。
小结
通过这个项目,你可以实际操作Hadoop生态系统中的多种工具,解决实际问题。从数据清洗、存储到分析和报告的全流程,这个综合项目不仅增强了对各工具的理解,还提供了如何将这些工具组合使用以解决复杂问题的实战经验。这种经验对于想要在大数据和数据科学领域进一步发展的专业人士非常宝贵。
相关文章:

Hadoop生态系统的核心组件探索
理解大数据和Hadoop的基本概念 当我们谈论“大数据”时,我们指的是那些因其体积、速度或多样性而难以使用传统数据处理软件有效管理的数据集。大数据可以来自多种来源,如社交媒体、传感器、视频监控、交易记录等,通常包含了TB(太…...
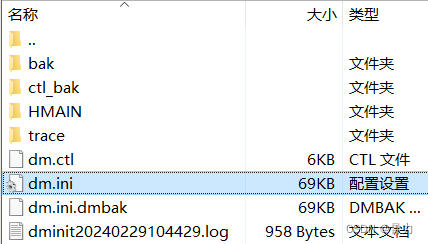
命令行方式将mysql数据库迁移到达梦数据库(全步骤)
因项目需求,需要将mysql数据库转换为国产达梦数据库,但由于安全问题,正式环境只能用命令行方式连接,下列是操作全步骤 目录 一、操作逻辑二、操作步骤1、本地安装达梦相关工具2、将服务器mysql导出到本地a) 服务器命令行导出mysql…...

旅游系列之:庐山美景
旅游系列之:庐山美景 一、路线二、住宿二、庐山美景 一、路线 庐山北门乘坐大巴上山,住在上山的酒店东线大巴游览三叠泉,不需要乘坐缆车,步行上下三叠泉即可,线路很短 二、住宿 长江宾馆庐山分部 二、庐山美景...

杭州恒生面试,社招,3年经验
你好,我是田哥 一位朋友节前去恒生面试,其实面试问题大部分都是八股文,但由于自己平时工作比较忙,完全没有时间没有精力去看八股文,导致面试结果不太理想,HR说节后通知面试结果(估计是凉了&…...

python virtualenv 创建虚拟环境指定python版本,pip 从指定地址下载某个包
一、安装 pip install virtualenv是python3 的话 换成 pip3 如果下载过慢可以从国内链接下载 如下从阿里云下载 pip3 install -i https://mirrors.aliyun.com/pypi/simple virtualenv二、创建指定python版本的虚拟环境 virtualenv venv --pythonpython3.12这里的venv 为创…...

open feign支持调用form-data的接口
增加 consumes {MediaType.MULTIPART_FORM_DATA_VALUE}) 示例 PostMapping(value "/ocr", consumes {MediaType.MULTIPART_FORM_DATA_VALUE})DataResponse ocr(RequestPart("file") MultipartFile multipartFile,RequestPart("fileType") Str…...

ESD静电问题 | TypeC接口整改
【转自微信公众号:深圳比创达EMC】...
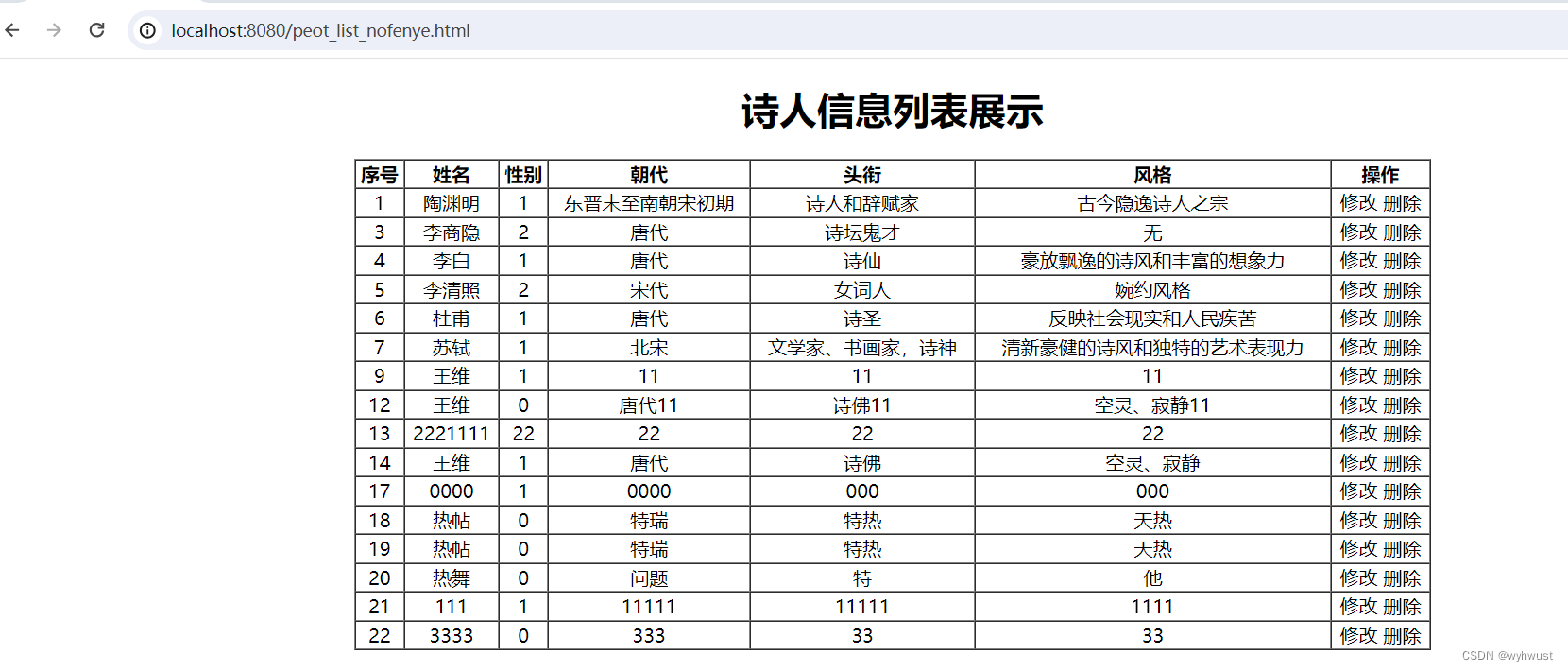
基于springboot+mybatis+vue的项目实战之前端
步骤: 1、项目准备:新建项目,并删除自带demo程序,修改application.properties. 2、使用Apifox准备好json数据的mock地址 3、编写基于vue的静态页面 4、运行 整个的目录结构如下: 0、项目准备 新建项目࿰…...

开源软件托管平台gogs操作注意事项
文章目录 一、基本说明二、gogs私有化部署三、设置仓库git链接自动生成参数四、关闭新用户注册入口 私有化部署gogs托管平台,即把gogs安装在我们自己的电脑或者云服务器上。 一、基本说明 系统环境:ubuntu 20.4docker安装 二、gogs私有化部署 前期准…...

Linux cmake 初窥【3】
1.开发背景 基于上一篇的基础上,已经实现了多个源文件路径调用,但是没有库的实现 2.开发需求 基于 cmake 的动态库和静态库的调用 3.开发环境 ubuntu 20.04 cmake-3.23.1 4.实现步骤 4.1 准备源码文件 基于上个试验的基础上,增加了动态库…...

centos学习- ps命令详解-进程监控的利器
ps命令详解:Linux进程监控的利器 在Linux系统管理中,进程监控是一个至关重要的环节。ps命令是Linux系统中一个功能强大的进程查看工具,通过它可以获取当前系统中所有进程的快照信息,并深入了解各个进程的详细信息。结合其各种选项…...

C++贪心算法
关于string的系统函数! (注:以下函数只可用于string,不适用其他类型的变量) ① a.size(); 这个系统函数是用来获取这个string变量的长度的,我们通常会新建一个变量来保存他,以便之后使用。 …...

访问网络附加存储:nfs
文章目录 访问网络附加存储一、网络附加存储1.1、存储类型1.3、通过NFS挂载NAS1.4、NFS挂载过程服务端客户端 二、实验:搭建NFS服务端及挂载到nfs客户端服务端客户端测试命令合集服务端客户端 访问网络附加存储 一、网络附加存储 1.1、存储类型 DAS:Di…...
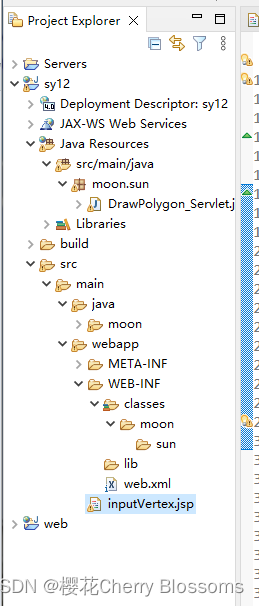
jsp 实验12 servlet
一、实验目的 掌握怎样在JSP中使用javabean 二、实验项目内容(实验题目) 编写代码,掌握servlet的用法。【参考课本 上机实验1 】 三、源代码以及执行结果截图: 源代碼: inputVertex.jsp: <% page lang…...

「 网络安全常用术语解读 」通用配置枚举CCE详解
1. 背景介绍 NIST提供了安全内容自动化协议(Security Content Automation Protocol,SCAP)为漏洞描述和评估提供一种通用语言。SCAP组件包括: 通用漏洞披露(Common Vulnerabilities and Exposures, CVE):提供一个描述…...

一机游领航旅游智慧化浪潮:借助前沿智能设备,革新旅游服务效率,构建高效便捷、生态友好的旅游服务新纪元,开启智慧旅游新时代
目录 一、引言 二、一机游的定义与特点 (一)一机游的定义 (二)一机游的特点 三、智能设备在旅游服务中的应用 (一)旅游前的信息查询与预订支付 (二)旅游中的导航导览与互动体…...
)
设计模式学习笔记 - 项目实战三:设计实现一个支持自定义规则的灰度发布组件(实现)
概述 上两篇文章,我们讲解了灰度组件的需求和设计的思路。不管之前讲的限流、幂等框架,还是现在讲的灰度组件,功能性需求都不复杂,相反,非功能性需求是开发的重点。 本章,按照上篇文章的灰度组件的设计思…...

BJFUOJ-C++程序设计-实验2-类与对象
A 评分程序 答案: #include<iostream> #include<cstring>using namespace std;class Score{ private:string name;//记录学生姓名double s[4];//存储4次成绩,s[0]和s[1]存储2次随堂考试,s[2]存储期中考试,s[3]存储期…...

数据库语法复习
总结: DDL(数据定义语言) CREATE DATABASE:创建一个新的数据库。DROP DATABASE:删除一个数据库。CREATE TABLE:创建一个新的表。DROP TABLE:删除一个表。ALTER TABLE:修改表的结构&a…...

Tomcat、MySQL、Redis最大支持说明
文章目录 一、Tomcat二、MySQL三、Redis1、最大连接数2、TPS、QPS3、key和value最大支持 一、Tomcat 查看SpringBoot内置Tomcat的源码,如下: 主要就是看抽象类AbstractEndpoint,可以看到默认的核心线程数10,最大线程数200 通过…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...