杭州恒生面试,社招,3年经验
你好,我是田哥
一位朋友节前去恒生面试,其实面试问题大部分都是八股文,但由于自己平时工作比较忙,完全没有时间没有精力去看八股文,导致面试结果不太理想,HR说节后通知面试结果(估计是凉了)。
以下是面试遇到的问题:
自我介绍
为什么要离职?
最近在做什么项目?
项目中用到了什么并发技术?
分布式锁实现方式有哪些?
你觉得哪种更好?
你们项目中用到了线程池,那你说说线程池每个参数的含义
线程池中的核心线程能被回收吗?
你们有做线程池监控吗?
如果让你做监控,你会怎么做?
你们的拒绝策略用的是哪个?
你们线程池中线程数量是如何设置的
你还知道哪些并发技术?
那你说说AQS是什么?
synchronized实现原理是什么?
String为什么是不可变的?
说一下你对final关键字的理解
ThreadLocal使用场景知道哪些?
项目中有涉及到分库分表、分布式事务吗?
说说你对分库分表的理解
你知道哪些分布式事务解决方案?
既然你对项目中SQL有做优化,你知道SQL优化有哪些手段?
以上是问题,大家不妨自己先看看自己能回答多少,如果觉得简单,那请你出门右转。
正文
自我介绍
关于自我,我之前有专门分享过一篇文章,这里就不再赘述了,请参考文章:
Java后端面试复习规划表,5万字
为什么要离职?
以下是一些建议:
诚实回答:首先要诚实回答面试官的问题,不要编造不实信息。面试官可能会通过其他渠道核实你的回答,所以保持诚实是很重要的。不过,如果真的没法说,那还是得自己随机应变哈。
积极原因:可以用积极的原因回答为什么离职,比如寻求新的挑战、个人职业发展、寻找更好的工作机会等。强调自己对新机会的追求和进步。
专业发展:强调个人的专业发展目标,说明之前的工作对自己的成长有所帮助,但已经达到一个瓶颈,所以希望找到更好的发展机会。
公司环境:可以提及公司环境、文化或者管理层变化等因素对个人职业发展的影响。但尽量避免批评前公司,保持中立和客观。
综合因素:可以综合以上因素,或者其他个人原因(如家庭变化、搬家等)来解释为什么离职。
避免消极原因:避免提及工资、同事冲突、工作压力等消极原因,保持正面和专业。千万别说领导是傻X,无法融入团队等。
总的来说,回答为什么离职的问题时,要坚持诚实和积极的态度,突出个人的专业发展目标和对新机会的追求,同时要避免提及消极原因,保持中立和专业。这样能够展现出你对工作的认真态度和对未来发展的规划。
最近在做什么项目?
换一种问法:你觉得最有挑战的项目是哪个?
在面试中之前,建议你先梳理一下你的项目,不要等到面试现场再去边说边梳理,在面试中就会出现:
我最近做的项目是xxx,我在这个项目中主要负责xxxxx,然后,这个项目中xxxx业务是核心业务,然后,。。。然后。。。
这是我面试这么多年遇到的介绍做多的模板,各种语气词加起来都已经超过了项目介绍内容。
项目介绍一定要自己用心准备,我们尽可能的给面试官制造一下好奇的话题。
在这个项目中,我负责整体架构设计,我是这个项目负责人,我负责这个项目的核心业务,项目中用到了分布式事务,对项目组朋友的SQL进行优化,其中有一项任务就是负责项目code review,在项目开发过程中遇到了xxx、www、yyyy等问题
项目中用到了什么并发技术?
先搞清楚并发技术有哪些?
在项目中,常常需要处理并发请求,以提高系统的性能和响应速度。以下是一些常见的并发技术,可以用于处理并发请求:
多线程:利用多线程技术可以让程序同时执行多个任务,提高CPU利用率和系统性能。Java中的Thread类和Runnable接口可以用来创建和管理线程。
线程池:通过线程池可以提前创建一定数量的线程并维护这些线程,避免频繁创建和销毁线程带来的开销,提高系统的性能。
并发集合:类似ConcurrentHashMap、ConcurrentLinkedQueue等并发集合可以在多线程环境下安全地进行读写操作,提供高效的并发访问。
锁机制:使用锁机制可以保护共享资源不被多个线程同时访问,常见的锁包括synchronized关键字、ReentrantLock等。
原子操作:原子操作可以保证一系列操作的原子性,不会被中断,如Java中的AtomicInteger、AtomicReference等类。
CAS算法:Compare and Swap(比较并交换)算法是一种实现并发的一种技术,可以通过原子方式进行更新操作。
分布式锁:在分布式系统中,为了保护共享资源或避免重复操作,可以使用分布式锁控制并发访问。
消息队列:消息队列可以作为并发处理的一种方式,将任务异步放入消息队列中,再由多个消费者来处理,降低系统间的耦合度。
缓存:通过缓存技术可以减少对数据库等资源的频繁访问,提高系统的并发能力和性能。
这里举了9个,其实还可以有更多。
在实际面试中,我们要依据自己的项目进行回答,不要随便编造,不然很容易露馅,就算编制也得说出为什么要用这个技术,以及使用后的效果。
对于普通项目而言,最好说的就是线程池、消息队列、缓存,就是这些技术在非分布式微服务项目中也可以被用上。
分布式锁实现方式有哪些?
常见分布式锁实现方式有:数据库、缓存、Zookeeper。
数据库实现:可以在数据库中创建一个表,利用数据库的事务特性和唯一性约束实现分布式锁。通过对这个表的操作来获取和释放锁。
缓存实现:利用分布式缓存存储锁的信息,比如Redis也可以利用其特性实现分布式锁,比如使用SET命令和NX(Not eXists)参数实现互斥锁,也可以使用Redisson实现的锁机制。
ZooKeeper实现:ZooKeeper是一个可靠的分布式协调服务,可以利用其临时节点和顺序节点特性实现分布式锁。可以通过创建临时顺序节点来实现锁竞争。
你觉得哪种更好?
其实,没有谁是最好的,只有相对最适合我们的具体项目业务场景。
数据库因为受到其性能的影响,所以在实际项目中基本上很少使用。项目中大多数都偏向于Redis和Zookeeper,从性能方面来讲Redis更好,从一致性方面来说Zookeeper更好。
我们在实际项目中,不管是考虑技术本身的问题,还要考虑项目技术架构,比如:我们基本上不会因为一个分布式锁而去把Zookeeper加入进来,更多是考虑性价比,如果项目中有redis了,那我们就没有必要再去刻意引入Zookeeper。并且,在实际项目,大部分都是采用Redis来实现分布式锁。
你们项目中用到了线程池,那你说说线程池每个参数的含义
在Java中,线程池通常由ThreadPoolExecutor类实现。ThreadPoolExecutor类的构造方法中包含了一些参数,以下是线程池中常见参数的含义:
corePoolSize:核心线程数。表示线程池中保持存活的线程数量,即使线程处于空闲状态也不会被销毁。当接收到新的任务时,优先使用核心线程来处理任务。
maximumPoolSize:最大线程数。表示线程池中允许存在的最大线程数量。当任务队列已满且核心线程数已经达到上限时,会创建新的线程来处理任务,但不会超过最大线程数。
keepAliveTime:线程空闲时间。表示当线程池中的线程数量大于核心线程数时,多余的空闲线程的存活时间。超过这个时间,多余的空闲线程会被销毁,直到线程数不超过核心线程数。
unit:时间单位。表示keepAliveTime的时间单位,可以是TimeUnit.SECONDS、TimeUnit.MILLISECONDS等。
workQueue:工作队列。表示存放等待执行任务的阻塞队列,当线程池的线程数量达到corePoolSize时,新的任务会被加入到工作队列中等待执行。
threadFactory:线程工厂。用来创建新的线程,可以自定义线程的创建方式,比如指定线程名称、优先级等。
handler:拒绝策略。当线程池中的线程已经达到最大线程数,且工作队列已满,无法继续接收新任务时,会触发拒绝策略来处理这些任务。常见的拒绝策略包括AbortPolicy、DiscardPolicy、DiscardOldestPolicy和CallerRunsPolicy等。
通过合理调整这些参数,可以根据实际情况来优化线程池的性能和资源利用率,提高应用的并发处理能力。
线程池中的线程能被回收吗?
线程池中有两种线程:核心线程和临时线程(最大线程减去核心线程的部分)
临时线程如果处于空闲状态,并到一定时间后会被清理回收。
核心线程数默认是不会被回收的,如果需要回收核心线程数,需要调用下面的方法:allowCoreThreadTimeOut 该值默认为 false。设置为true就会回收核心线程
你们有做线程池监控吗?
没有
很多项目中真的是没有对线程池做监控,不知道你们项目中是否有做监控。
如果让你做监控,你会怎么做?
我们可以用一个 printStats 方法实现了最简陋的监控,每秒输出一次线程池的基本内部信息:
getPoolSize():获取线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁。
getActiveCount():获取活跃的线程数。
getCompletedTaskCount():获取线程池在运行过程中已完成的任务数量。
getQueue().size():获取队列中还有多少积压任务。
也可以参考美团线程池实践 ,对线程池参数动态化管理,增加监控、报警功能。
50000多字,线程池源码详解!建议收藏
你们的拒绝策略用的是哪个?默认是什么?
没注意,好像是用的默认。
线程池中主要有4种拒绝策略:
AbortPolicy:直接丢弃任务,抛出异常,这是默认策略
CallerRunsPolicy:只用调用者所在的线程来处理任务
DiscardOldestPolicy:丢弃等待队列中最旧的任务,并执行当前任务
DiscardPolicy:直接丢弃任务,也不抛出异常
我们也可以根据自己项目实际情况来,自定义拒绝策略。
你们线程池中线程数量是如何设置的
这个没注意具体是怎么设置的,因为是我们领导做的,不过我知道一些理论知识。
在使用线程池时,会考虑线程数如何设置,设置多少,不可能随便胡乱设置。通常会按照任务类型,最线程池中的线程做一个初步的评估;业务类通常分为两总:CPU密集型和IO密集型。
密集型时,任务可以少配置线程数,大概和机器的cpu核数相当,这样可以使得每个线 程都在执行任务。
IO密集型时,大部分线程都阻塞,故需要多配置线程数,
2*cpu核数。
可以先按照理论值进行测试,再通过多次的压测,找到一个相对最优的点。
synchronized实现原理是什么?
synchronized实现原理主要是通过对象头中的标记位(Mark Word)以及Monitor对象来实现的。下面是synchronized实现原理的简要说明:
对象头标记位:每个Java对象在内存中都有一个对象头(Header),对象头中包含了对象的元数据信息,其中就包括一个用于表示锁状态的标记位(Mark Word)。
偏向锁:初始时,对象头中的锁状态为无锁状态(01),当一个线程第一次访问同步代码块时,会尝试获取偏向锁,将对象头中的锁状态改为偏向锁状态(00)。偏向锁会标记获取偏向锁的线程ID,并记录获取锁的线程。
轻量级锁:如果有多个线程竞争同一个对象的锁,即发生锁的竞争,偏向锁会升级为轻量级锁。此时,JVM会尝试使用CAS(Compare and Swap)操作来尝试获取锁,将对象头中的锁标记为轻量级锁状态。如果CAS操作失败,表示有多个线程同时尝试获取锁,JVM会将锁升级为重量级锁。
重量级锁:如果轻量级锁也无法满足多个线程对同一个对象的锁竞争,JVM会将锁升级为重量级锁。此时,会使用基于操作系统的互斥量(Mutex)来实现多个线程之间的互斥访问。
Monitor对象:每个Java对象都会有一个关联的Monitor对象,用于实现重量级锁和进行线程的等待和唤醒操作。
面试中可能会问一些synchronized的使用,修饰普通方法、修饰静态方法以及同步带模块的区别,优缺点,还有就是所得范围要清楚。
说说什么AQS?
AQS是AbstractQueuedSynchronizer 的简称:AQS 是一个用于构建锁和同步器的框架,它提供了一种基于队列的同步器实现方式。通过AQS,可以相对容易地实现各种锁机制,如ReentrantLock和Semaphore等,以及自定义的同步器。
核心原理:
使用一个volatile类型的int成员变量state来表示同步状态,使用CAS(CompareAndSwap)操作来修改state的值。
使用一个双向链表(FIFO队列)来保存等待线程,保证线程获取锁的公平性。
提供了acquire和release等抽象方法,可以通过继承AQS并实现这些方法来构建自定义的同步器。
String为什么是不可变的?
这个可以参考我之前的文章:和面试官吵起来了?
说一下你对final关键字的理解
final关键字有多种用途,主要包括以下方面:
修饰常量:定义常量时通常会使用final关键字,表示该变量的值在初始化后不能被修改。例如:
final int MAX_VALUE = 100;修饰类:使用final修饰的类不能被继承,即为最终类。例如:
final class FinalClass {}修饰方法:使用final修饰的方法不能被子类重写,即为最终方法。例如:
public final void finalMethod() {}修饰变量:使用final修饰的变量表示初始化后不可再赋值,但对象内容可以改变。例如:
final List<Integer> list = new ArrayList<>();
list.add(1); // 合法
list = new ArrayList<>(); // 非法修饰参数:使用final修饰方法参数表示该参数是只读的,不能在方法内部被修改。例如:
public void print(final String str) {System.out.println(str);// str = "new"; // 非法
}使用final关键字的案例:
线程安全常量:在多线程环境下,使用final关键字定义的常量在初始化后不可修改,可以保证线程安全。例如:
public class Constants {public static final int THREAD_COUNT = 5;
}单例模式:使用final关键字确保单例模式中的实例只被初始化一次。例如:
public class Singleton {private static final Singleton instance = new Singleton();private Singleton() {} public static Singleton getInstance() {return instance;}
}性能优化:在编译时,final关键字可用于对代码进行更好的优化,例如对方法进行内联替换,减少方法调用开销。
安全性和可读性:使用final关键字可以提升代码的安全性和可读性,避免不必要的变量修改和类继承。
是不是让你长见识了,大部分人回答都只会说修饰类修饰方法修饰字段的作用就结束了。
ThreadLocal使用场景知道哪些?
下面举几个常见的使用场景:
在spring事务中,保证一个线程下,一个事务的多个操作拿到的是一个Connection。
在hiberate中管理session。
在JDK8之前,为了解决SimpleDateFormat的线程安全问题。
获取当前登录用户上下文。
临时保存权限数据。
使用MDC保存日志信息。
理解其本质,然后再结合业务场景。
项目中有涉及到分库分表、分布式事务吗?
有就有,没有的话,编造需要慎重,否则容易被坑。
说说你对分库分表的理解
分库分表是一种常见的数据库水平拆分方案,通过将数据库数据按照某种规则分散存储在多个数据库实例或表中,以提高数据库性能、扩展性和容量。以下是对分库分表的一些理解:
水平拆分:分库分表是一种水平拆分的数据库设计方式,在水平拆分中,数据根据某种规则(如范围、哈希、取模等)拆分到不同的库或表中,达到分散存储、降低单节点存储压力的效果。
解决瓶颈:分库分表可以有效解决单库单表的数据量过大、QPS过高导致的性能瓶颈问题,将数据分布到多个库、表中,减轻了单一数据库的处理压力。
提高并发:分库分表可以提高系统的并发处理能力,不同用户的数据被分散存储在不同的节点中,避免了热点数据集中在同一节点导致的并发瓶颈。
提高可用性:通过水平拆分,即使某个库或表出现故障,其他库或表仍然可以正常运行,提高了系统的可用性和容错能力。
扩展性:分库分表的设计可以方便系统进行扩展,当系统负载增加时,可以动态增加数据库实例或表,从而实现系统的横向扩展。
注意事项:分库分表虽然提供了一种有效的数据库性能扩展方案,但也带来了一些挑战,比如跨库查询、分布式事务等问题需要额外的处理。
我们也可以使用分布式数据库,比如TiDB。在实际项目中,其实很少回去做真正的分库分表,大部分项目可能会做一些分表,但是分库确实不多。分库分表基本的都是在基于现有sql优化、表结构优化、硬件提升都无法满足的情况下才会考虑的。
你知道哪些分布式事务解决方案?
以下是一些常见的分布式事务解决方案:
两阶段提交(Two-Phase Commit,2PC):是一种最基本的分布式事务协议,通过协调者和参与者之间的两阶段协商来保证事务的一致性。然而2PC存在阻塞、单点故障、性能开销高等问题。
三阶段提交(Three-Phase Commit,3PC):在2PC的基础上引入了准备阶段,解决了2PC的某些问题,但仍然无法完全解决所有问题。
补偿事务(Compensating Transaction):采用补偿事务的方式,在业务处理失败后执行一系列的逆操作(补偿操作)来进行事务回滚,保证数据的一致性。
本地消息表(Local Message Table,LMT):在分布式事务中引入本地消息表,将本地事务和消息发送操作绑定到一起,保证本地事务和消息发送的原子性。
分布式消息队列:借助分布式消息队列中间件来实现分布式事务,将业务逻辑和消息发送放入同一个事务中,实现最终一致性。
TCC(Try-Confirm-Cancel):TCC是一种面向业务逻辑的分布式事务补偿机制,通过Try阶段尝试执行事务操作、Confirm阶段确认执行、Cancel阶段取消操作以实现事务一致性。
Saga模式:将一个大事务拆分成多个小事务,每个小事务有自己的补偿操作,通过一系列连续的小事务来实现分布式事务的一致性。
Seata:阿里巴巴开源的全局事务解决方案,支持分布式事务处理模式,包括AT模式(TCC)、XA模式、SAGA模式等。
以上是一些常见的分布式事务解决方案,每种解决方案都有自己的特点和适用场景,我们需要根据具体业务需求和系统架构选择适合的分布式事务解决方案。
既然你对项目中SQL有做优化,你知道SQL优化有哪些手段?
常见的SQL优化手段在MySQL数据库中的实际应用方法:
创建索引:索引是提高查询性能的重要手段。通过在查询字段上创建索引,可以加快查询速度。在MySQL中,可以使用CREATE INDEX语句创建普通索引、唯一索引或者组合索引来优化查询性能。但不是创建的越多越好,建议不要超过五个,并且尽量全面考察是否需要建联合索引、覆盖索引等。
避免全表扫描:尽量避免对整个表进行扫描,可以通过合适的索引或限制返回结果的数量来提高查询效率。
选择合适的数据类型:在创建表时,选择合适的数据类型有助于提高查询性能。选择适当长度的字符类型、整数类型等会减少数据存储空间和提高查询效率。
合理使用查询语句:避免使用SELECT * 这样的查询语句,只查询需要的字段可以减少数据传输量和加快查询速度。
优化复杂查询:对于复杂查询,可以使用JOIN优化、子查询优化、联合查询优化等方法,尽量简化查询逻辑和减少不必要的计算。
优化表结构:合理设计表结构,避免过度规范化和反规范化,尽量减少 JOIN 操作,减少数据冗余。
使用EXPLAIN分析SQL:使用EXPLAIN命令来分析查询语句的执行计划,通过查看索引使用情况、扫描行数等信息,找到潜在的性能问题并进行优化。
定期优化数据库:定期检查并优化数据库表,包括碎片整理、统计信息更新、索引重建等操作,保持数据库性能稳定。
你觉得难吗?如果你也有面试经历,或者面试中遇到不好回答的问题,请私信我或者在文章下面留言。
相关文件推荐
杭州某科技银行面经和答案
面试:如何设计一个注册中心?
我的知识库:搞定100w
全程面试辅导,快速找到工作!
欢迎加入我的知识星球,可以三天之内无理由退款,三天后找我开通相应账号权限、简历修改、模拟面试。


相关文章:
杭州恒生面试,社招,3年经验
你好,我是田哥 一位朋友节前去恒生面试,其实面试问题大部分都是八股文,但由于自己平时工作比较忙,完全没有时间没有精力去看八股文,导致面试结果不太理想,HR说节后通知面试结果(估计是凉了&…...

python virtualenv 创建虚拟环境指定python版本,pip 从指定地址下载某个包
一、安装 pip install virtualenv是python3 的话 换成 pip3 如果下载过慢可以从国内链接下载 如下从阿里云下载 pip3 install -i https://mirrors.aliyun.com/pypi/simple virtualenv二、创建指定python版本的虚拟环境 virtualenv venv --pythonpython3.12这里的venv 为创…...

open feign支持调用form-data的接口
增加 consumes {MediaType.MULTIPART_FORM_DATA_VALUE}) 示例 PostMapping(value "/ocr", consumes {MediaType.MULTIPART_FORM_DATA_VALUE})DataResponse ocr(RequestPart("file") MultipartFile multipartFile,RequestPart("fileType") Str…...

ESD静电问题 | TypeC接口整改
【转自微信公众号:深圳比创达EMC】...
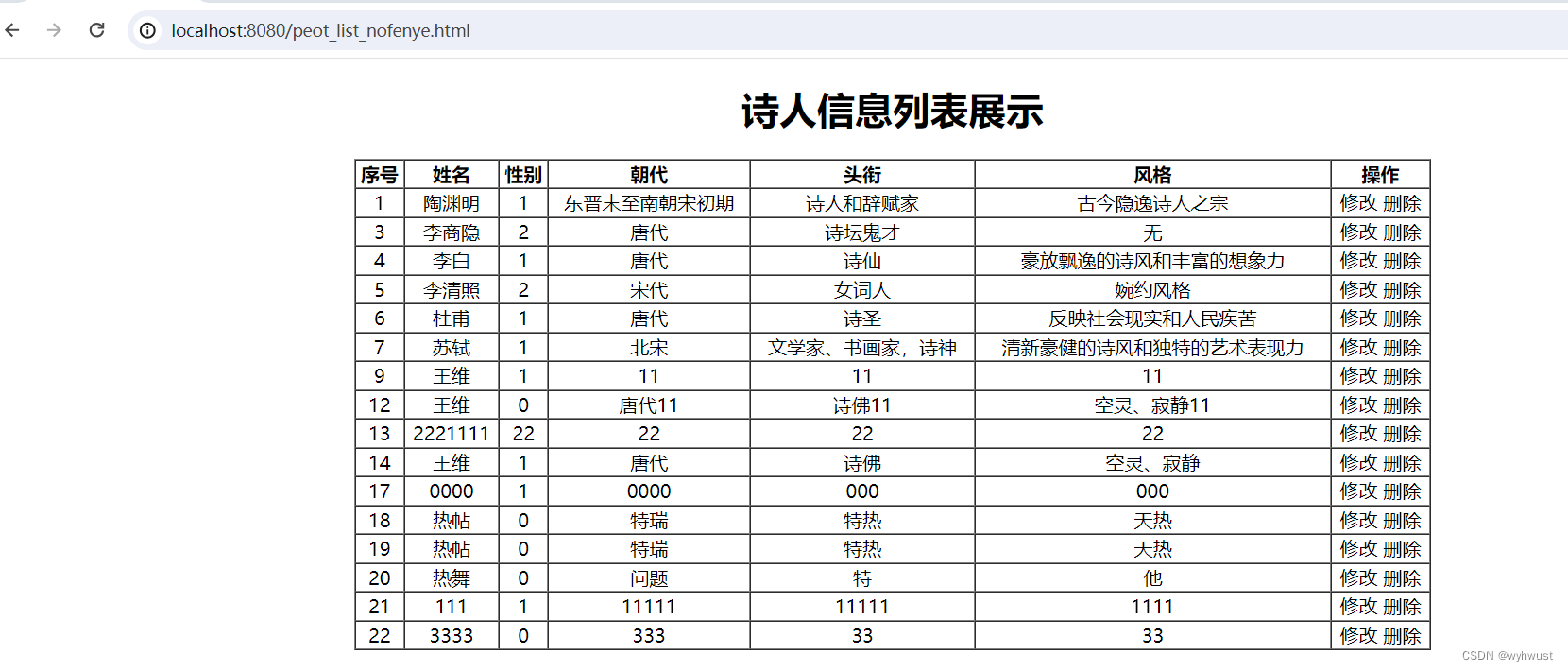
基于springboot+mybatis+vue的项目实战之前端
步骤: 1、项目准备:新建项目,并删除自带demo程序,修改application.properties. 2、使用Apifox准备好json数据的mock地址 3、编写基于vue的静态页面 4、运行 整个的目录结构如下: 0、项目准备 新建项目࿰…...

开源软件托管平台gogs操作注意事项
文章目录 一、基本说明二、gogs私有化部署三、设置仓库git链接自动生成参数四、关闭新用户注册入口 私有化部署gogs托管平台,即把gogs安装在我们自己的电脑或者云服务器上。 一、基本说明 系统环境:ubuntu 20.4docker安装 二、gogs私有化部署 前期准…...

Linux cmake 初窥【3】
1.开发背景 基于上一篇的基础上,已经实现了多个源文件路径调用,但是没有库的实现 2.开发需求 基于 cmake 的动态库和静态库的调用 3.开发环境 ubuntu 20.04 cmake-3.23.1 4.实现步骤 4.1 准备源码文件 基于上个试验的基础上,增加了动态库…...

centos学习- ps命令详解-进程监控的利器
ps命令详解:Linux进程监控的利器 在Linux系统管理中,进程监控是一个至关重要的环节。ps命令是Linux系统中一个功能强大的进程查看工具,通过它可以获取当前系统中所有进程的快照信息,并深入了解各个进程的详细信息。结合其各种选项…...

C++贪心算法
关于string的系统函数! (注:以下函数只可用于string,不适用其他类型的变量) ① a.size(); 这个系统函数是用来获取这个string变量的长度的,我们通常会新建一个变量来保存他,以便之后使用。 …...

访问网络附加存储:nfs
文章目录 访问网络附加存储一、网络附加存储1.1、存储类型1.3、通过NFS挂载NAS1.4、NFS挂载过程服务端客户端 二、实验:搭建NFS服务端及挂载到nfs客户端服务端客户端测试命令合集服务端客户端 访问网络附加存储 一、网络附加存储 1.1、存储类型 DAS:Di…...
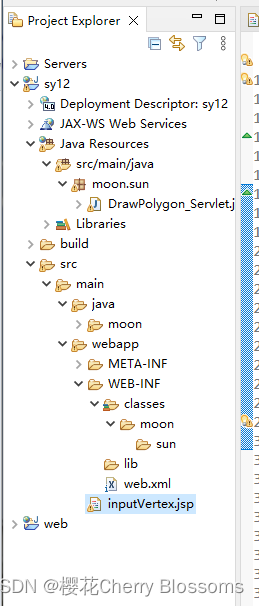
jsp 实验12 servlet
一、实验目的 掌握怎样在JSP中使用javabean 二、实验项目内容(实验题目) 编写代码,掌握servlet的用法。【参考课本 上机实验1 】 三、源代码以及执行结果截图: 源代碼: inputVertex.jsp: <% page lang…...

「 网络安全常用术语解读 」通用配置枚举CCE详解
1. 背景介绍 NIST提供了安全内容自动化协议(Security Content Automation Protocol,SCAP)为漏洞描述和评估提供一种通用语言。SCAP组件包括: 通用漏洞披露(Common Vulnerabilities and Exposures, CVE):提供一个描述…...

一机游领航旅游智慧化浪潮:借助前沿智能设备,革新旅游服务效率,构建高效便捷、生态友好的旅游服务新纪元,开启智慧旅游新时代
目录 一、引言 二、一机游的定义与特点 (一)一机游的定义 (二)一机游的特点 三、智能设备在旅游服务中的应用 (一)旅游前的信息查询与预订支付 (二)旅游中的导航导览与互动体…...
)
设计模式学习笔记 - 项目实战三:设计实现一个支持自定义规则的灰度发布组件(实现)
概述 上两篇文章,我们讲解了灰度组件的需求和设计的思路。不管之前讲的限流、幂等框架,还是现在讲的灰度组件,功能性需求都不复杂,相反,非功能性需求是开发的重点。 本章,按照上篇文章的灰度组件的设计思…...

BJFUOJ-C++程序设计-实验2-类与对象
A 评分程序 答案: #include<iostream> #include<cstring>using namespace std;class Score{ private:string name;//记录学生姓名double s[4];//存储4次成绩,s[0]和s[1]存储2次随堂考试,s[2]存储期中考试,s[3]存储期…...

数据库语法复习
总结: DDL(数据定义语言) CREATE DATABASE:创建一个新的数据库。DROP DATABASE:删除一个数据库。CREATE TABLE:创建一个新的表。DROP TABLE:删除一个表。ALTER TABLE:修改表的结构&a…...

Tomcat、MySQL、Redis最大支持说明
文章目录 一、Tomcat二、MySQL三、Redis1、最大连接数2、TPS、QPS3、key和value最大支持 一、Tomcat 查看SpringBoot内置Tomcat的源码,如下: 主要就是看抽象类AbstractEndpoint,可以看到默认的核心线程数10,最大线程数200 通过…...

MATLAB数值计算工具箱介绍
MATLAB是一个强大的数学计算平台,它提供了广泛的数值计算工具箱,这些工具箱覆盖了从基础的线性代数到复杂的数值分析和优化问题。以下是MATLAB中一些关键工具箱的详细介绍: 1. 线性代数工具箱(Linear Algebra Toolbox)…...
2023 广东省大学生程序设计竞赛(部分题解)
目录 A - Programming Contest B - Base Station Construction C - Trading D - New Houses E - New but Nostalgic Problem I - Path Planning K - Peg Solitaire A - Programming Contest 签到题:直接模拟 直接按照题目意思模拟即可,为了好去…...
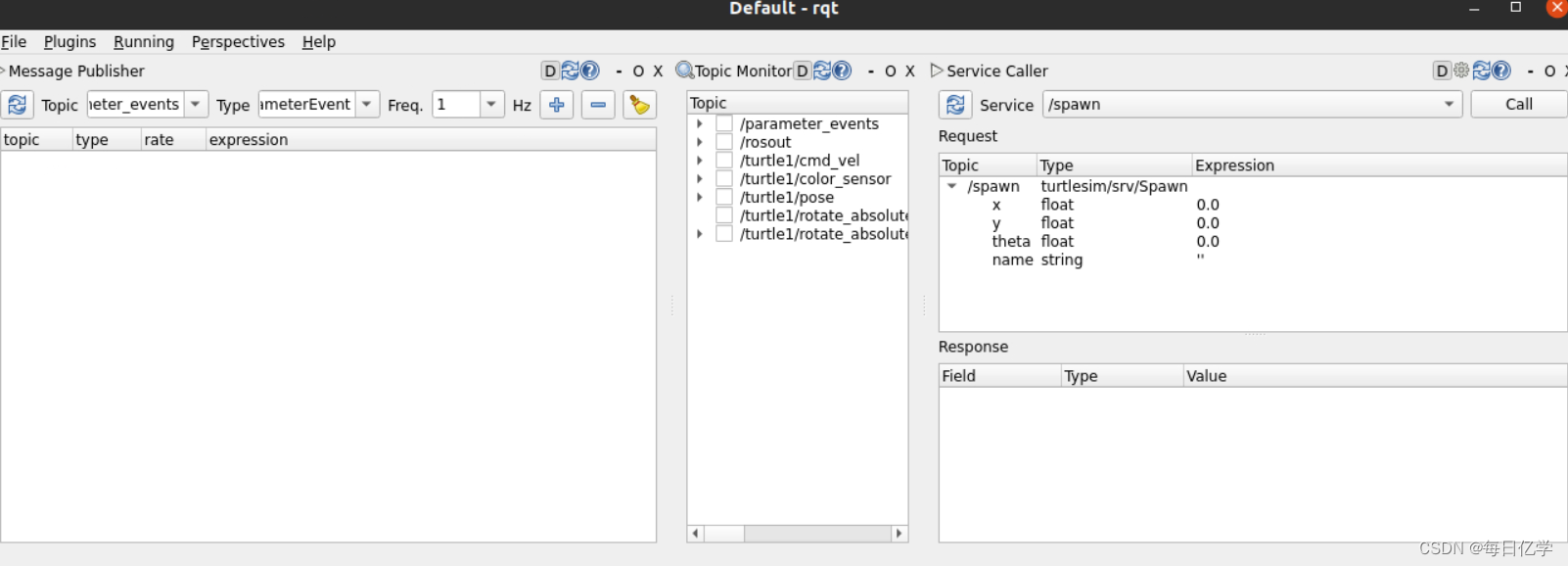
ROS2学习——Docker环境下安装于使用(1)
目录 一、简要 二、ROS2和ROS1区别 三、环境搭建与安装 (2)拉取ubuntu22.04镜像 (2)安装ROS2 1. 基本设置 2.设置源 3.安装ROS2功能包 4.测试 四、相关指令学习 1.小海龟测试 2.ros2 node等指令 3.rqt 一、简要 随着R…...

告别“炼丹”:用ReVeal的GGNN+Triplet Loss实战代码漏洞检测,我踩过的坑你别踩
从理论到实践:ReVeal漏洞检测模型落地中的关键挑战与解决方案 在代码安全领域,深度学习技术的应用正经历着从实验室研究到工业落地的关键转折期。ReVeal作为近年来备受关注的漏洞检测框架,其结合GGNN图神经网络与Triplet Loss的创新设计&…...

从rdt1.0到rdt3.0:可靠数据传输协议的演进与发送接收端FSM解析
1. 可靠数据传输协议的前世今生 第一次接触可靠数据传输协议(Reliable Data Transfer,简称rdt)是在十多年前的一个网络编程项目里。当时为了确保数据能准确无误地传输,我翻遍了各种资料,最终在《计算机网络:…...

从Simulink到实物:单闭环直流调速仿真如何指导真实的Arduino/STM32控制?
从Simulink到Arduino:如何将直流电机控制算法从仿真落地到真实硬件 当你第一次在Simulink中看到那个完美的电机转速响应曲线时,那种成就感是无可替代的。但很快,一个更迫切的问题出现了:这些漂亮的仿真结果,如何变成手…...

Z-Image Turbo实际作品分享:城市风光生成效果
Z-Image Turbo实际作品分享:城市风光生成效果 本文所有内容均为技术效果展示,不涉及任何政治敏感内容,所有案例均为技术演示用途。 1. 效果概览:城市风光的AI艺术呈现 Z-Image Turbo作为基于Gradio和Diffusers构建的高性能AI绘图…...

OmenSuperHub终极指南:简单三步掌控暗影精灵硬件性能
OmenSuperHub终极指南:简单三步掌控暗影精灵硬件性能 【免费下载链接】OmenSuperHub 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿体积和烦人广告?是否希望获得纯净的硬件控制体验…...

余姚加工中心编程培训排行榜单
舜龙模具数控培训执行标准:学习进度一对一、培训一人、合格一人、成就一人;舜龙自有模具工厂,全程实战教学,所学贴合岗位实操,毕业即可对接就业。1998年-2026年,舜龙28年匠心传承。舜龙模具数控培训&#x…...

【论文速递】BubbleRAG:为“黑盒”知识图谱打造高召回、高精度的证据检索引擎
黑盒知识图谱检索中的三个挑战:语义实例化不确定性、结构路径不确定性、证据比较不确定性 01 研究背景 在复杂问答(如多跳推理、专家识别)任务中,基于知识图谱(KG)的检索增强生成(RAG&#x…...

如何用Mi-Create实现小米穿戴设备表盘个性化设计?
如何用Mi-Create实现小米穿戴设备表盘个性化设计? 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create Mi-Create是一款专为2021年及以后发布的小米穿戴…...

像素冒险工坊初体验:维度裂变器真实使用报告,文字创作从未如此有趣
像素冒险工坊初体验:维度裂变器真实使用报告,文字创作从未如此有趣 1. 走进像素冒险工坊 当我第一次打开像素语言维度裂变器时,仿佛穿越回了16-bit游戏黄金年代。这款基于MT5-Zero-Shot-Augment核心引擎构建的文本增强工具,彻底…...

如何3步掌握Home Assistant SSH Web终端:从零到精通的管理指南 ✨
如何3步掌握Home Assistant SSH Web终端:从零到精通的管理指南 ✨ 【免费下载链接】app-ssh Advanced SSH & Web Terminal - Home Assistant Community Apps 项目地址: https://gitcode.com/gh_mirrors/ad/app-ssh 在智能家居系统的日常维护中࿰…...