【深耕 Python】Data Science with Python 数据科学(19)书402页练习题:模型准确率对比研究、KMeans算法的一点探讨
写在前面
关于数据科学环境的建立,可以参考我的博客:
【深耕 Python】Data Science with Python 数据科学(1)环境搭建
往期数据科学博文一览:
【深耕 Python】Data Science with Python 数据科学(2)jupyter-lab和numpy数组
【深耕 Python】Data Science with Python 数据科学(3)Numpy 常量、函数和线性空间
【深耕 Python】Data Science with Python 数据科学(4)(书337页)练习题及解答
【深耕 Python】Data Science with Python 数据科学(5)Matplotlib可视化(1)
【深耕 Python】Data Science with Python 数据科学(6)Matplotlib可视化(2)
【深耕 Python】Data Science with Python 数据科学(7)书352页练习题
【深耕 Python】Data Science with Python 数据科学(8)pandas数据结构:Series和DataFrame
【深耕 Python】Data Science with Python 数据科学(9)书361页练习题
【深耕 Python】Data Science with Python 数据科学(10)pandas 数据处理(一)
【深耕 Python】Data Science with Python 数据科学(11)pandas 数据处理(二)
【深耕 Python】Data Science with Python 数据科学(12)pandas 数据处理(三)
【深耕 Python】Data Science with Python 数据科学(13)pandas 数据处理(四):书377页练习题
【深耕 Python】Data Science with Python 数据科学(14)pandas 数据处理(五):泰坦尼克号亡魂 Perished Souls on “RMS Titanic”
【深耕 Python】Data Science with Python 数据科学(15)pandas 数据处理(六):书385页练习题
【深耕 Python】Data Science with Python 数据科学(16)Scikit-learn机器学习(一)
【深耕 Python】Data Science with Python 数据科学(17)Scikit-learn机器学习(二)
【深耕 Python】Data Science with Python 数据科学(18)Scikit-learn机器学习(三)
代码说明: 由于实机运行的原因,可能省略了某些导入(import)语句。
11.7.4 Exercises
1. The RandomForestClassifier( ) function takes a keyword argument called n_estimators that represents the “number of trees in the forest”. According to the documentation, what is the default value for n_estimators? Use random_state=1.
Answer in Python:
# ex 1
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(random_state=1)
print(random_forest.n_estimators) # default value of number of trees
random_forest_2 = RandomForestClassifier(random_state=1, n_estimators=10)
print(random_forest_2.n_estimators) # set the value of number of trees
程序输出:
100 # 默认树棵数
10 # 设置值
2. By varying n_estimators in the call to RandomForestClassifier( ), determine the approximate value where the Random Forest classifier is less accurate than Decision Tree. Use random_state=1.
Answer in Python:
首先取n_estimators=50:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltURL = "https://learnenough.s3.amazonaws.com/titanic.csv"
titanic = pd.read_csv(URL)from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifierdropped_columns = ["PassengerId", "Name", "Cabin", "Embarked", "SibSp", "Parch", "Ticket", "Fare"]
for column in dropped_columns:titanic = titanic.drop(column, axis=1)for column in ["Age", "Sex", "Pclass"]:titanic = titanic[titanic[column].notna()]sexes = {"male": 0, "female": 1}
titanic["Sex"] = titanic["Sex"].map(sexes)X = titanic.drop("Survived", axis=1)
Y = titanic["Survived"]from sklearn.model_selection import train_test_split(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, random_state=1)decision_tree = DecisionTreeClassifier(random_state=1)
decision_tree.fit(X_train, Y_train)
accuracy_decision_tree = decision_tree.score(X_test, Y_test)random_forest = RandomForestClassifier(random_state=1, n_estimators=50)
random_forest.fit(X_train, Y_train)
accuracy_random_forest = random_forest.score(X_test, Y_test)results = pd.DataFrame({"Model": ["Decision Tree", "Random Forest"],"Score": [accuracy_decision_tree, accuracy_random_forest]
})result_df = results.sort_values(by="Score", ascending=False)
result_df = result_df.set_index("Score")
print(result_df)
模型准确率排序输出:
# 准确率 模型
Score Model
0.854749 Decision Tree
0.854749 Random Forest
此时,使用50棵树的随机森林模型和决策树模型的识别准确率恰好相等(保留至小数点后第6位)。经过多次尝试,当取n_estimators=18时两种模型的识别准确率相等:
random_forest = RandomForestClassifier(random_state=1, n_estimators=18)
random_forest.fit(X_train, Y_train)
accuracy_random_forest = random_forest.score(X_test, Y_test)
# 准确率 模型
Score Model
0.854749 Decision Tree
0.854749 Random Forest
取n_estimators=17时,随机森林模型的识别准确率首次变为低于决策树模型。
random_forest = RandomForestClassifier(random_state=1, n_estimators=17)
random_forest.fit(X_train, Y_train)
accuracy_random_forest = random_forest.score(X_test, Y_test)
# 准确率 模型
Score Model
0.854749 Decision Tree
0.843575 Random Forest
综上,要寻找的阈值大约为17.
3. By rerunning the steps in Section 11.7.2 using a few different values of random_state, verify that the ordering is not always the same as shown in Listing 11.25. Hint: Try values like 0, 2, 3, and 4.
Answer:
在划分数据集过程中和部分模型中,修改random_state参数的值。
random_state=0:
from sklearn.model_selection import train_test_split(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, random_state=0)
(模型参数省略)
模型识别准确率输出:
# 准确率 模型
Score Model
0.821229 Logistic Regression # 逻辑斯蒂回归
0.793296 Decision Tree # 决策树
0.782123 Naive Bayes # 朴素贝叶斯
0.776536 Random Forest # 随机森林
0.681564 Perceptron # 感知机
random_state=2:
from sklearn.model_selection import train_test_split(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, random_state=2)
(模型参数省略)
模型识别准确率输出:
# 准确率 模型
Score Model
0.837989 Decision Tree # 决策树
0.826816 Logistic Regression # 逻辑斯蒂回归
0.821229 Random Forest # 随机森林
0.787709 Perceptron # 感知机
0.782123 Naive Bayes # 朴素贝叶斯
random_state=3:
from sklearn.model_selection import train_test_split(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, random_state=3)
(模型参数省略)
模型识别准确率输出:
# 准确率 模型
Score Model
0.810056 Decision Tree # 决策树
0.810056 Random Forest # 随机森林
0.782123 Logistic Regression # 逻辑斯蒂回归
0.765363 Naive Bayes # 朴素贝叶斯
0.402235 Perceptron # 感知机
和random_state=1时的准确率排序相同,但整体上存在大幅度下降趋势。
random_state=4:
from sklearn.model_selection import train_test_split(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, random_state=4)
(模型参数省略)
模型识别准确率输出:
# 准确率 模型
Score Model
0.837989 Random Forest # 随机森林
0.798883 Logistic Regression # 逻辑斯蒂回归
0.782123 Decision Tree # 决策树
0.765363 Naive Bayes # 朴素贝叶斯
0.603352 Perceptron # 感知机
日后可以深究一下random_state参数对不同模型识别准确率的影响,本文在此不作赘述。不过显而易见的是,简单感知机的识别准确率性能确实基本上是垫底的。
4. Repeat the clustering steps in Section 11.7.3 using two clusters and eight clusters. Does the algorithm still work well in both cases?
Answer in Python:
首先取KMeans算法中的n_clusters=2,输出聚类结果(聚类中心点坐标):
from sklearn.datasets import make_blobs
import matplotlib.pyplot as pltX, _ = make_blobs(n_samples=300, centers=4, random_state=42)from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=2)
kmeans.fit(X)
centers = kmeans.cluster_centers_
print(centers)
程序输出:
[[-6.83235205 -6.83045748] # 中心点1[-2.26099839 6.07059051]] # 中心点2
聚类结果可视化:
fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1])
ax.scatter(centers[:, 0], centers[:, 1], s=200, alpha=0.9, color="orange")
plt.title("Cluster Result Illustration")
plt.xlabel("X")
plt.ylabel("Y")
plt.grid()
plt.show()
输出的图像:

可见,上方3个簇被模型划分为1个类。
再取KMeans算法中的n_clusters=8,输出聚类结果(聚类中心点坐标):
kmeans = KMeans(n_clusters=8) # 修改的代码行
聚类结果图示:
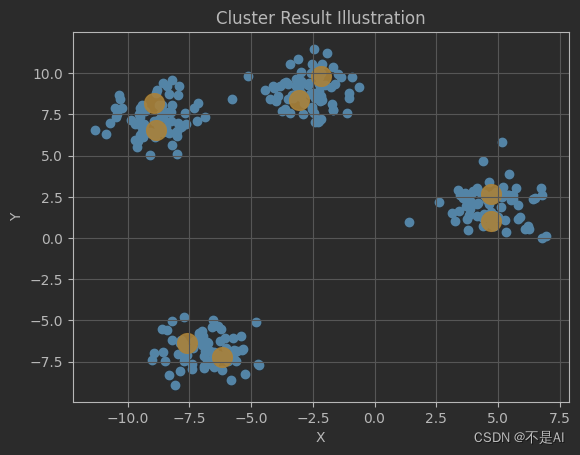
结果比较好理解,8 = 4 * 2,模型对每一个数据簇赋了2个聚类中心。
但是当n_clusters=16时,出人意料的是,模型并没有简单地按照4 * 4的方式进行“分配”,而是3 + 5 + 4 + 4:
kmeans = KMeans(n_clusters=16)
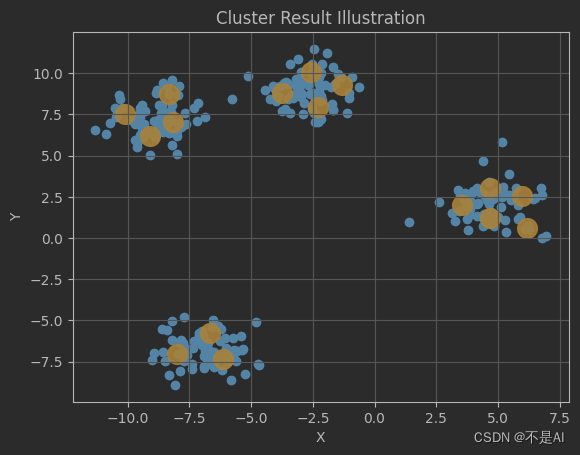
直观上,认为导致这种现象的原因可能是样本点的数量。
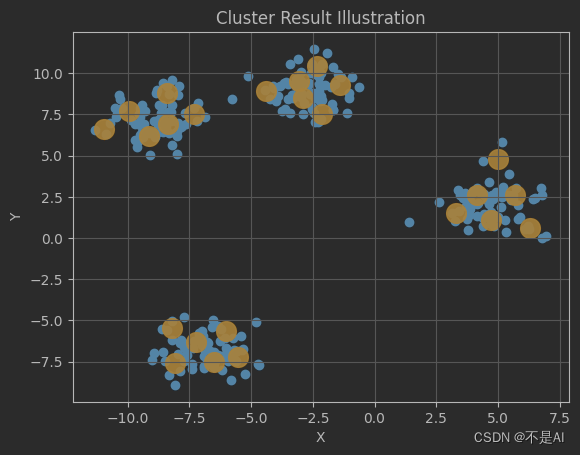
再分别观察n_clusters=24 和 n_clusters=32时的情形:
平均分配,6 + 6 + 6 + 6
8 + 8 + 7 + 9,“平均率”被打破。
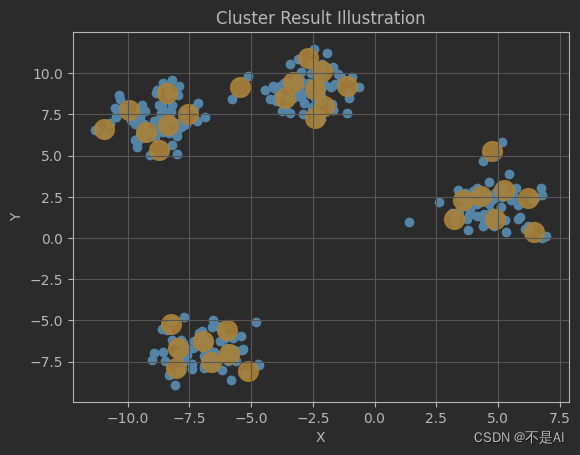
看来模型对于聚类中心的“分配”是随机的,但位置基本落在各个数据簇的边缘内,这个结果是可以令人满意的。
参考文献 Reference
《Learn Enough Python to be Dangerous——Software Development, Flask Web Apps, and Beginning Data Science with Python》, Michael Hartl, Boston, Pearson, 2023.
相关文章:
【深耕 Python】Data Science with Python 数据科学(19)书402页练习题:模型准确率对比研究、KMeans算法的一点探讨
写在前面 关于数据科学环境的建立,可以参考我的博客: 【深耕 Python】Data Science with Python 数据科学(1)环境搭建 往期数据科学博文一览: 【深耕 Python】Data Science with Python 数据科学(2&…...

汽车品牌区域营销方案
领克汽车粤海区域营销方案-36P 活动策划信息: 方案页码:36页 文件格式:PPT 方案简介: 车市反弹形势明显,领克销量呈现稳健上涨趋势 品牌 未来市场可观,应 持续扩大品牌声量,保持市场占有优…...

matlab 中在3维坐标系中绘制一个点的X,Y,Z坐标,除了mesh还有什么函数?使用格式与mesh都有什么区别?
在MATLAB中,除了mesh函数之外,还有其他一些函数可以用来在三维坐标系中绘制点或曲面。以下是一些常用的函数及其与mesh函数的区别: 函数名描述与mesh的区别plot3在三维坐标系中绘制线或点仅限于线或点的绘制,不生成网格scatter3在…...
如何在六个月内学会任何一门外语(ted转述)
/仅作学习和参考,勿作他用/ a question : how can you speed up learning? 学得快,减少在学校时间 结果去研究心理学惹 spend less time at school. if you learn really fast , you donot need to go to school at all. school got in the way of …...
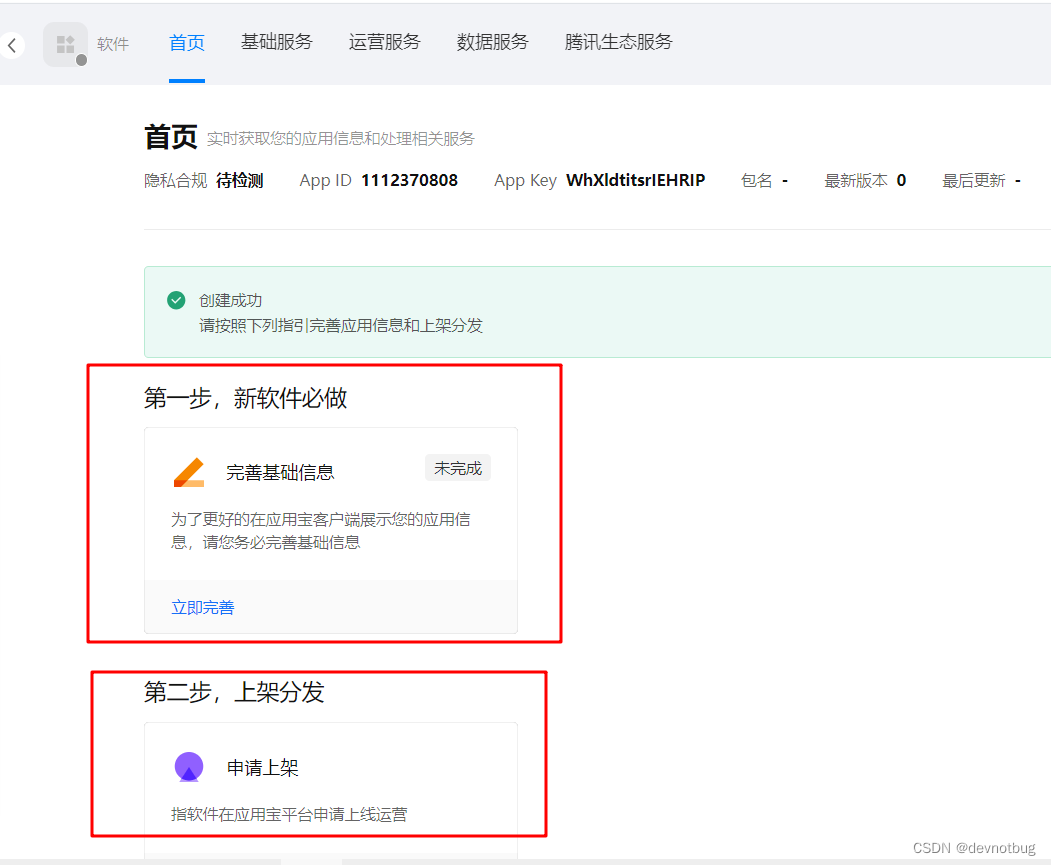
前端 Android App 上架详细流程 (Android App)
1、准备上架所需要的材料 先在需要上架的官方网站注册账号。提前把手机号,名字,身份证等等材料准备好,完成开发者实名认证;软著是必要的,提前准备好,软著申请时间比较长大概需要1-2周时间才能下来…...
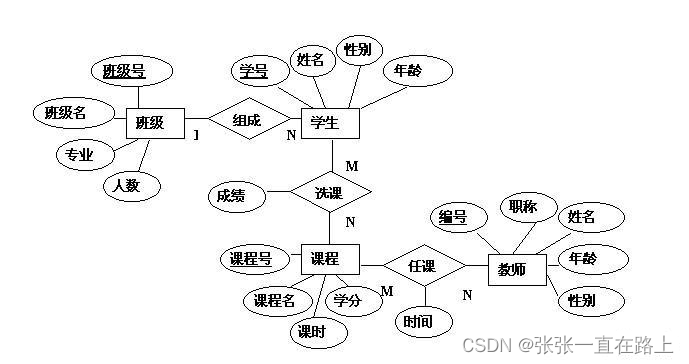
MySQL学习笔记11——数据备份 范式 ER模型
数据备份 & 范式 & ER模型 一、数据备份1、如何进行数据备份(1)备份数据库中的表(2)备份数据库(3)备份整个数据库服务器 2、如何进行数据恢复3、如何导出和导入表里的数据(1)…...
软件测试基础理论复习
什么是软件? 软件是计算机系统中与硬件相互依存的另一部分, 软件包括程序文档 什么是软件测试? (1)软件测试是在现有软件(程序文档)中寻找缺陷的过程; (2࿰…...

【UnityRPG游戏制作】Unity_RPG项目_玩家逻辑相关
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:就业…...

QT_BEGIN_NAMESPACE
最近碰到了QT_BEGIN_NAMESPACE这个宏,这个宏就是一个命名空间,意思是如果不用这个宏,可能我qwidget定义的一个变量a会和标准C定义的变量a冲突对不,Qt通过这个命名空间,将所有类和函数封装在一个作用域里,防…...

Swift 集合类型
集合类型 一、集合的可变性二、数组(Arrays)1、数组的简单语法2、创建一个空数组3、创建一个带有默认值的数组4、通过两个数组相加创建一个数组5、用数组字面量构造数组6、访问和修改数组7、数组的遍历 三、集合(Sets)1、集合类型…...

string容器
目录 string函数的构造 string赋值操作 string字符串拼接 string字符串查找和替换 string字符串比较 string字符存取 string插入与删除 string字串 string函数的构造 #include<iostream> #include<cstring> using namespace std; void test01() {string s…...
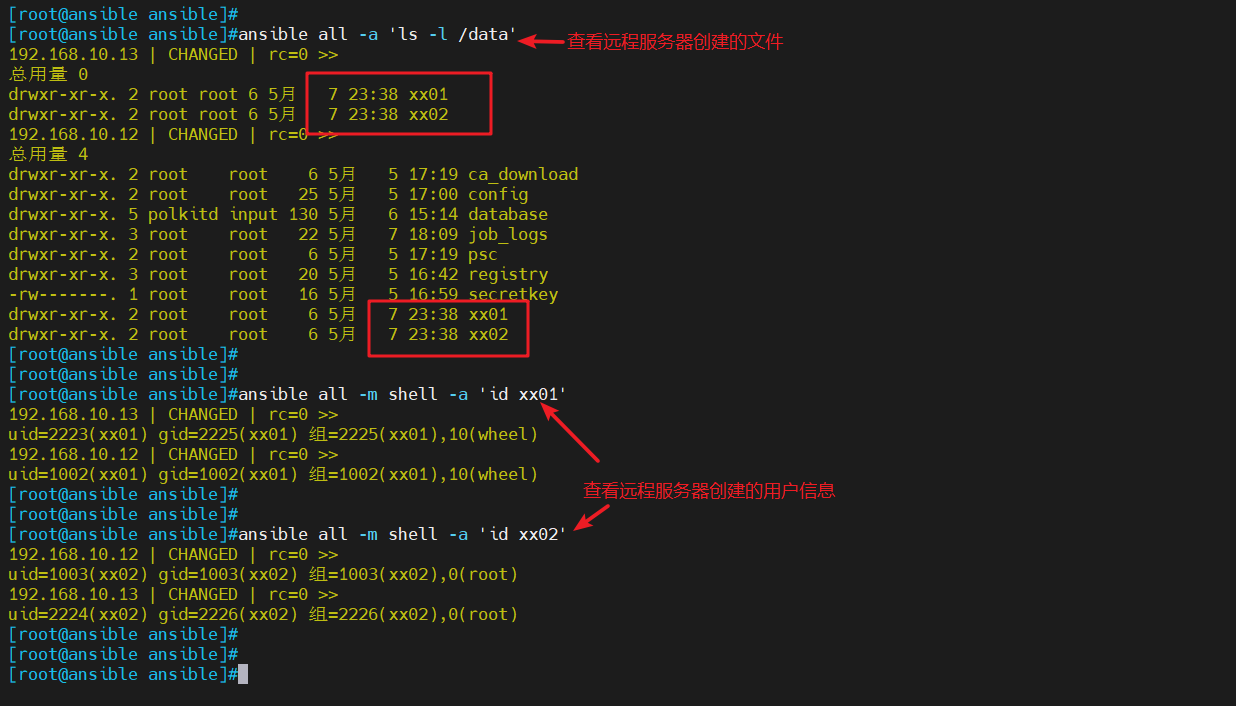
Ansible-inventory和playbook
文章目录 一、inventory 主机清单1、列表表示2、inventory 中的变量3、变量3.1 主机变量3.2 组变量3.3 组嵌套 二、playbook剧本1、playbook的组成2、编写剧本2.1 剧本制作2.2 准备nginx.conf2.3 运行剧本2.4 查看webservers服务器2.5 补充参数 3、剧本定义、引用变量3.1 剧本制…...

HI3516CV610
一、总体介绍 HI3516CV610是一颗应用在安防市场的IPC SoC,在开放操作系统、新一代视频编解码标准网络安全和隐私保护、人工智能方面引领行业发展,主要面向室内外场景下的枪机、球机、半球机、海螺机、枪球一体机、双目长短焦机等产品形态,打…...

ansible内置主机变量及魔法变量
目录 概述实践代码执行效果 概述 简单实用版本 实践 代码 --- - name: Get IP Addresshosts: allgather_facts: notasks:- name: Get IP Addressansible.builtin.setup:register: host_ip- name: Print IP Addressansible.builtin.debug:msg: "The IP Address of {{ a…...

设计模式一
单例模式(Singleton Pattern)是一种常用的软件设计模式,旨在确保一个类只有一个实例,并提供一个全局访问点。单例模式常用于控制资源密集型对象的创建,如数据库连接池、线程池等,以避免资源浪费。 单例模式…...
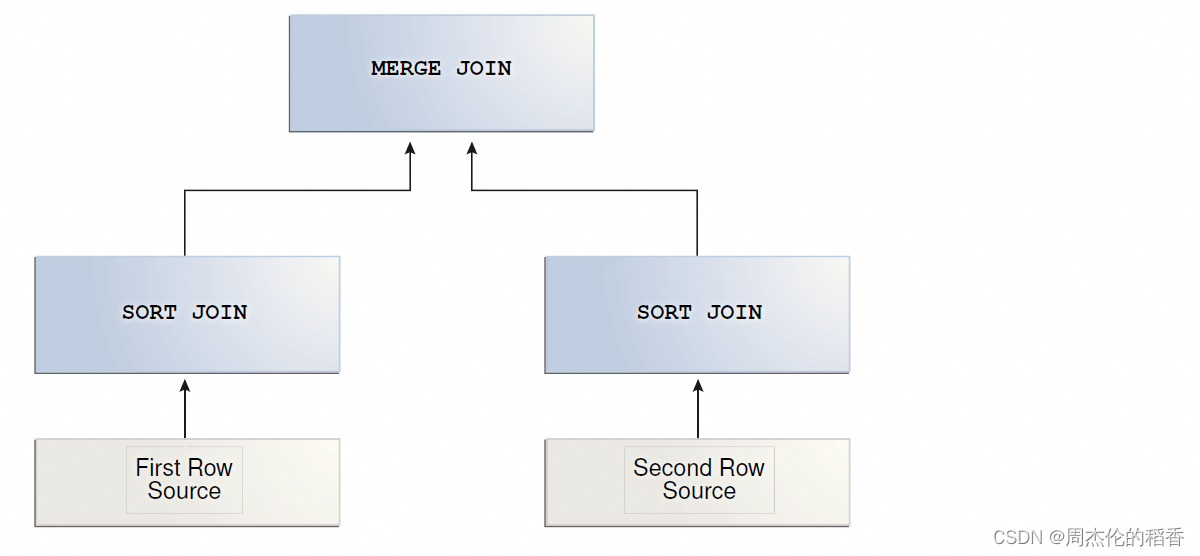
MySQL中JOIN连接的实现算法
目录 嵌套循环算法(NLJ) 简单嵌套循环(SNLJ) 索引嵌套循环(INLJ) 块嵌套循环(BNLJ) 三种算法比较 哈希连接算法(Hash Join) 注意事项: 工…...

[力扣题解] 216. 组合总和 III
题目:216. 组合总和 III 思路 回溯法 代码 class Solution { private:vector<vector<int>> result;vector<int> path;public:void function(int k, int n, int startindex, int sum){int i;// 剪枝// 超过了, 不用找了;if(sum > n){return…...

Spring Security Oauth2 JWT 添加额外信息
目录 一、问题描述 二、实现步骤 1、自定义TokenEnhancer 2、配置授权服务器 3、自定义UserDetails的User类 三、参考文档 一、问题描述 Oauth2里默认生成的JWT信息并没有用户信息,在认证授权后一般会返回这一部分信息,我对此进行了改造。 Oauth…...
蜜蜂收卡系统 加油卡充值卡礼品卡自定义回收系统源码 前后端开源uniapp可打包app
本文来自:蜜蜂收卡系统 加油卡充值卡礼品卡自定义回收系统源码 前后端开源uniapp可打包app - 源码1688 卡券绿色循环计划—— 一项旨在构建卡券价值再利用生态的社会责任感项目。在当前数字化消费日益普及的背景下,大量礼品卡、优惠券因各种原因未能有效…...
三星硬盘好还是西数硬盘好?硬盘数据丢失怎么找回
在数字化时代,硬盘作为数据存储的核心组件,其品质与性能直接关系到用户的数据安全与使用体验。在众多硬盘品牌中,三星与西数无疑是两个备受关注的名字。那么,究竟是三星硬盘更胜一筹,还是西数硬盘更受用户青睐…...

Llama-3.2V-11B-cot新手指南:Streamlit界面快捷键与批量操作技巧
Llama-3.2V-11B-cot新手指南:Streamlit界面快捷键与批量操作技巧 1. 工具简介 Llama-3.2V-11B-cot是一款基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具。它针对双卡4090环境进行了深度优化,特别适合想要体验多模态大模型能力的新手…...

炼精化气:黄庭协议硬件升级的第一关,也是最关键的一关
炼精化气:黄庭协议硬件升级的第一关,也是最关键的一关 项目地址: github.com/XianDAO-Labs/huangting-protocol 官方网站: huangting.ai 作者: 孟元景(Mark Meng)| 协议版本: v7.8 一…...

G-Helper神器:解决华硕ROG笔记本色彩配置丢失完全指南
G-Helper神器:解决华硕ROG笔记本色彩配置丢失完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址…...

nli-distilroberta-base效果展示:长文本截断策略对NLI准确率影响实测
nli-distilroberta-base效果展示:长文本截断策略对NLI准确率影响实测 1. 项目概述 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务,专门用于判断两个句子之间的逻辑关系。这个轻量级模型保留了R…...

告别硬编码!泛微OA流程表单的智能字段控制:一个下拉框搞定明细表规则
泛微OA流程表单的智能字段控制:用动态规则提升表单复用性 在企业的日常运营中,采购申请流程是最常见也最复杂的业务流程之一。传统的OA系统表单设计往往采用"一刀切"的方式,为每种采购类型创建独立的表单模板。这不仅增加了系统维护…...

ggwave声波通信库:嵌入式轻量级音频数据传输方案
1. ggwave:嵌入式系统中的轻量级声波数据通信库1.1 技术定位与工程价值ggwave 是一个专为资源受限嵌入式平台设计的超轻量级声波数据通信库,其核心目标是在无射频模块、无网络基础设施的物理邻近场景下,实现设备间短消息的可靠音频信道传输。…...
用C++实现信奥题 P6202 [USACO07CHN] Summing Sums G)
打卡信奥刷题(3004)用C++实现信奥题 P6202 [USACO07CHN] Summing Sums G
P6202 [USACO07CHN] Summing Sums G 题目描述 NNN 头奶牛(1≤N≤51041 \leq N \leq 5 \times 10^41≤N≤5104)刚刚学习了不少密码学知识,终于,她们创造出了属于奶牛的加密方法,由于她们经验不足,她们的加密…...

核心常量T表生成(前16轮T_j = 0x79cc4519,后48轮T_j = 0x7a879...
算法部署设计,Sm3国密算法的硬件ip设计,纯v手写代码,图一为ip接口,图二为资源消耗,图三四为封装为axilite接口并在开发版下板测试,图五为开发版实测结果 直接联系内容包括:sm3的软件python实现代码…...

Token:解决 Cookie+Session 痛点的新一代「身份凭证」
一、为什么会出现 Token?1. Cookie Session 的天生痛点服务器压力大Session 存在服务器内存 / Redis,用户越多占用越大。分布式集群麻烦必须做 Session 共享(Redis 同步、IP 绑定等)。跨域 / 跨端不友好Cookie 受同源策略限制&am…...
)
告别ST-Link!用你手边的CMSIS-DAP给STM32烧录固件(附CoFlash保姆级配置)
低成本高效烧录:用CMSIS-DAP调试器玩转STM32固件更新 在嵌入式开发的世界里,ST-Link调试器几乎成了STM32开发者的标配工具。但当你手头只有一块廉价的开发板,或者临时需要调试设备却发现ST-Link不在身边时,是否只能望"芯&qu…...