MySQL中JOIN连接的实现算法
目录
嵌套循环算法(NLJ)
简单嵌套循环(SNLJ)
索引嵌套循环(INLJ)
块嵌套循环(BNLJ)
三种算法比较
哈希连接算法(Hash Join)
注意事项:
工作原理:
优点:
缺点:
排序合并链接(SORT MERGE JOIN)
工作流程:
优点:
缺点:
总结
我们都知道SQL的join关联表的使用方式,但是这次聊的是实现join的算法,join有三种算法,分别是Nested Loop Join,Hash join,Sort Merge Join。
嵌套循环算法(NLJ)
嵌套循环算法(Nested-Loop Join,NLJ)是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法:嵌套循环算法又可以分为简单嵌套循环、索引嵌套循环、块嵌套循环。
简单嵌套循环(SNLJ)
// 伪代码for (r in R) {for (s in S) {if (r satisfy condition s) {output <r, s>;}}}
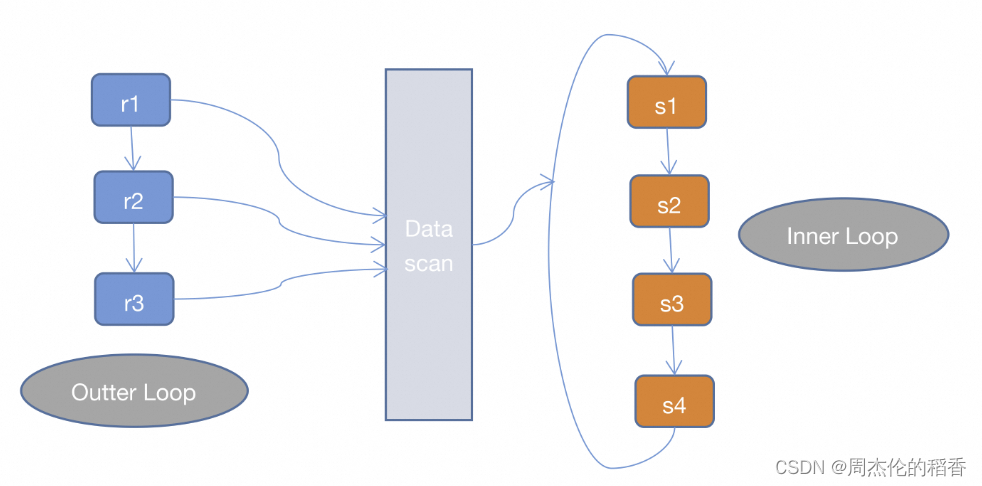
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时。
索引嵌套循环(INLJ)
// 伪代码for (r in R) {for (si in SIndex) {if (r satisfy condition si) {output <r, s>;}}}
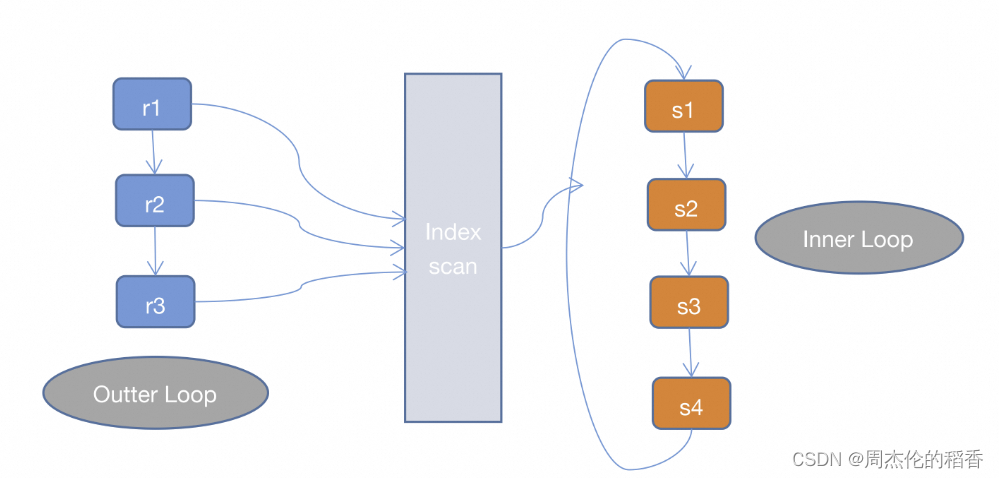
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
块嵌套循环(BNLJ)
// 伪代码for (r in R) {for (sbu in SBuffer) {if (r satisfy condition sbu) {output <r, s>;}}}

扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后在内存中比较匹配条件是否满足。但内存里可能并不能完全存放的下表中所有的记录。为了减少访问被驱动表的次数,我们可以首先将驱动表的数据批量加载到 Join Buffer(连接缓冲),然后当加载被驱动表的记录到内存时,就可以一次性和多条驱动表中的记录做匹配,这样可大大减少被驱动表的扫描次数,这就是 BNLJ 算法的思想。
三种算法比较
算法比较(外表大小R,内表大小S):
| \algorithm comparison\ | Simple Nested Loop Join | Block Nested Loop Join | ||||
|---|---|---|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 | |||
| 内表扫描次数 | R | 0 |  | |||
| 读取记录次数 |
|
|
| |||
| 比较次数 |
| R * IndexHeight |
| |||
| 回表次数 | 0 |
| 0 |

整体效率比较:INLJ > BNLJ > SNLJ
哈希连接算法(Hash Join)
MySQL 8.0.18支持在optimizer_switch中设置hash_join标志,以及优化器提示HASH_JOIN和NO_HASH_JOIN。在MySQL 8.0.19和更高版本中,这些都不再有任何效果。
从MySQL 8.0.20开始,对块嵌套循环的支持被删除,并且服务器在以前使用块嵌套循环的地方使用哈希连接。

hash join的实现分为build table也就是被用来建立hash map的小表和probe table,首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash map中的一个元組,数据缓存在内存中,如果内存放不下需要dump到外存。依次扫描探测表拿到每一行数据根据join condition生成hash key映射hash map中对应的元組,元組对应的行和探测表的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的投影列。
// 伪代码 // 算法复杂度:O(M + N) // 假设用户表有M条记录, 订单表有N条记录 func HashJoin(users []TradeUser, orders []TradeOrder) []*UserOrderView {var userOrderViews []*UserOrderView = make([]*UserOrderView, 0)// 将用户表以用户ID为Key,用户为Value转换为Hash表// 算法复杂度:O(M)userTable := make(map[int]TradeUser)for _, user := range users {userTable[user.Id] = user}// 遍历订单表,查找用户// 算法复杂度:O(N)for _, order := range orders {// 复杂度,接近:O(1)if user, exists := userTable[order.UserId]; exists {// 添加视图结果userOrderViews = append(userOrderViews, &UserOrderView{UserId: user.Id,UserName: user.Name,OrderId: order.Id,OrderAmount: order.Amount,})}}return userOrderViews }

注意事项:
- hash join本身的实现不要去判断哪个是小表,优化器生成执行计划时就已经确定了表的连接顺序,以左表为小表建立hash table,那对应的代价模型就会以左表作为小表来得出代价,这样根据代价生成的路径就是符合实现要求的。
- hash table的大小、需要分配多少个桶这个是需要在一开始就做好的,那分配多少是一个问题,分配太大会造成内存浪费,分配太小会导致桶数过小开链过长性能变差,一旦超过这里的内存限制,会考虑dump到外存,不同数据库有它们自身的实现方式。
- 如何对数据hash,不同数据库有着自己的方式,不同的哈希方法也会对性能造成一定的影响。
工作原理:
构建阶段(Build Phase)
- 选择构建表(Build Table):算法通常会选择数据量较小的表作为构建表,以减少哈希表的构建时间和所需内存。但这不是绝对的,实际选择会根据统计信息和成本估算来决定。
- 创建哈希表:对构建表中的每一行记录,取其连接列(即用于JOIN的列)的值,应用哈希函数计算出一个哈希码(hash code)。然后,根据这个哈希码将记录存储在一个哈希桶(hash bucket)中。如果有多个记录的连接列值经过哈希后得到相同的哈希码,这些记录会被组织成链表或其他数据结构存储在同一哈希桶内。
探测阶段(Probe Phase)
- 扫描探测表(Probe Table):对另一个较大的表(探测表)进行扫描。
- 哈希计算与匹配:对于探测表中的每一行,同样对其连接列值应用相同的哈希函数计算哈希码,然后在这个预先构建好的哈希表中查找对应的哈希桶。
- 匹配与输出:如果找到匹配的哈希桶,就进一步检查桶内的链表或数据结构,进行精确的等值比较,以确保连接列的值确实相等。一旦找到匹配项,就结合两个表的相关字段生成结果集的行并输出。
优点:
- 性能优势:在数据量大时,哈希连接可以显著减少磁盘I/O和CPU时间,因为它避免了嵌套循环的多次扫描和排序-合并连接中的排序开销。
- 并行处理友好:哈希连接天然适合并行化处理,因为哈希表可以在不同的处理器或节点上并行构建和查询。
- 内存依赖:哈希连接的效率高度依赖于可用内存,因为需要在内存中存储整个哈希表。如果内存不足,部分或全部哈希表可能需要溢写到磁盘,这会大大降低效率。
缺点:
- 内存消耗:如前所述,构建哈希表需要足够的内存空间,特别是当构建表较大时。
- 非等值连接不适用:哈希连接主要用于等值连接,对于非等值连接(如大于、小于等条件)不适用。
- 预读取与优化:为了效率,数据库系统需要有效管理内存使用,并可能实施预读取策略来优化性能。
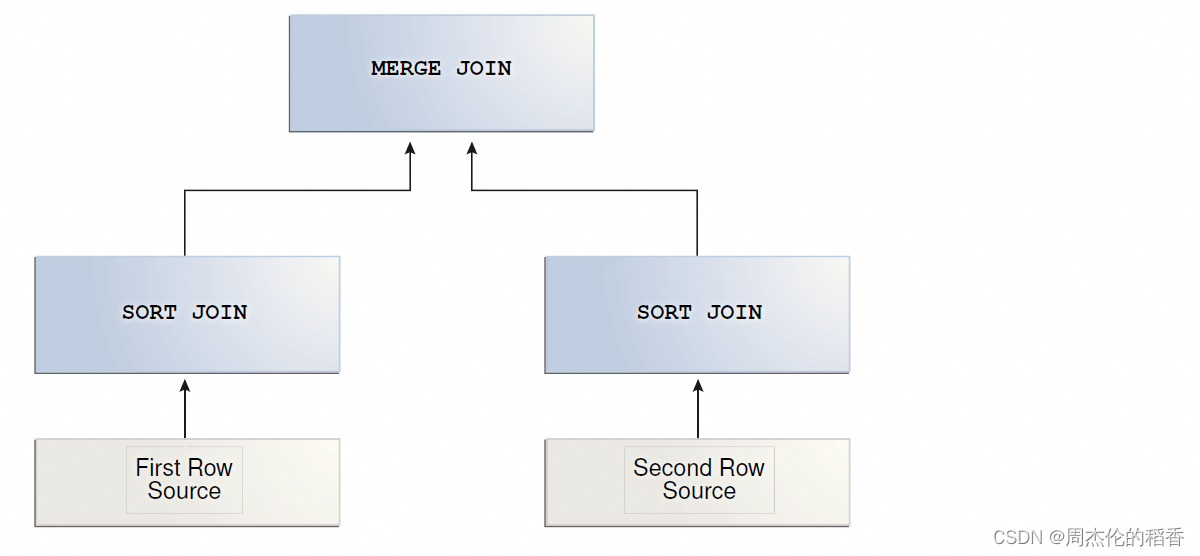
排序合并链接(SORT MERGE JOIN)
排序合并连接是嵌套循环连接的变种。如果两个数据集还没有排序,那么数据库会先对它们进行排序,这就是所谓的sort join操作。对于数据集里的每一行,数据库会从上一次匹配到数据的位置开始探查第二个数据集,这一步就是Merge join操作。
// 伪代码 // 算法复杂度:O(M log M + N log N) // 假设用户表有M条记录, 订单表有N条记录 func SortJoin(users []TradeUser, orders []TradeOrder) []*UserOrderView {var userOrderViews []*UserOrderView = make([]*UserOrderView, 0)// 排序user表// 算法复杂度:O(M log M)sort.Slice(users, func(i, j int) bool {return users[i].Id < users[j].Id})// 排序order表// 算法复杂度:O(N log N)sort.Slice(orders, func(i, j int) bool {return orders[i].Id < orders[j].Id})// 遍历订单表,查找用户// 算法复杂度:O(M)userIdx := 0for _, order := range orders {// 在user.id为主键的情况下,这里还可以执行二分查找for idx < len(users) && users[userIdx].Id < order.UserId {userIdx++}// 如果找到用户,添加到结果集合if userIdx < len(users) && users[userIdx].id == order.UserId {// Join条件满足添加视图结果userOrderViews = append(userOrderViews, &UserOrderView{UserId: user.Id,UserName: user.Name,OrderId: order.Id,OrderAmount: order.Amount,})}}return userOrderViews }
工作流程:
-
排序阶段:
- 数据排序:首先,算法会对参与连接的两个表根据连接键进行排序。这一步骤是关键,因为只有排序后的数据才能有效地进行归并操作。如果表已经按照连接键排序,这一步可以省略。
- 索引利用:如果表上有适合的索引(如聚集索引或覆盖索引),数据库引擎可能会直接利用这些索引来避免全表排序。
-
合并阶段:
- 双指针扫描:一旦两个表的数据都按连接键排序好了,算法会使用两个指针(或游标)分别指向两个表的开始。每个指针逐步向后移动,比较两个指针所指记录的连接键值。
- 匹配与输出:当两个指针指向的记录的连接键相等时,说明这两个记录应该被连接起来,此时就会输出(或累积到结果集中)这对匹配的记录。如果一个表的指针达到末尾,而另一个表还有剩余记录,则剩余的记录被视为不匹配,如果有外连接的情况,则可能作为NULL扩展输出。
- 推进指针:匹配后,指针会根据排序顺序向后移动,继续寻找下一个匹配的记录。
优点:
- 效率:对于大表连接,特别是当连接键分布均匀,且数据已经排序或可以低成本排序时,SMJ比Nested-Loop Join更高效,因为它减少了不必要的比较次数。
- 稳定性:由于是基于排序的,Sort Merge Join保证了输出结果的稳定性,即具有相同键值的记录保持原有的相对顺序。
- 可预测性能:时间复杂度主要取决于排序操作,通常是O(n log n),对于大规模数据集来说,性能较为可预测。
缺点:
- 内存和I/O开销:排序操作可能需要额外的内存空间,并且如果数据不能完全放入内存,还需要磁盘I/O操作,这可能会成为性能瓶颈。
- 预处理时间:排序是预处理步骤,可能增加整体处理时间,尤其是在数据已经接近有序或只需要执行一次连接操作的情况下。
总结
| 算法名称 | 时间复杂度 | 描述 |
| Nested Loop Join | O(M*N) | 适合小数据集,大数据集很慢 |
| Sort Merge Join | O(M log M + N log N + M + N) | 适合于当内存不足以存放整个数据集,需要小的分区上进行排序和合并 |
| Hash Join | O(M+N) | 适用于大数据集 |
相关文章:
MySQL中JOIN连接的实现算法
目录 嵌套循环算法(NLJ) 简单嵌套循环(SNLJ) 索引嵌套循环(INLJ) 块嵌套循环(BNLJ) 三种算法比较 哈希连接算法(Hash Join) 注意事项: 工…...

[力扣题解] 216. 组合总和 III
题目:216. 组合总和 III 思路 回溯法 代码 class Solution { private:vector<vector<int>> result;vector<int> path;public:void function(int k, int n, int startindex, int sum){int i;// 剪枝// 超过了, 不用找了;if(sum > n){return…...

Spring Security Oauth2 JWT 添加额外信息
目录 一、问题描述 二、实现步骤 1、自定义TokenEnhancer 2、配置授权服务器 3、自定义UserDetails的User类 三、参考文档 一、问题描述 Oauth2里默认生成的JWT信息并没有用户信息,在认证授权后一般会返回这一部分信息,我对此进行了改造。 Oauth…...
蜜蜂收卡系统 加油卡充值卡礼品卡自定义回收系统源码 前后端开源uniapp可打包app
本文来自:蜜蜂收卡系统 加油卡充值卡礼品卡自定义回收系统源码 前后端开源uniapp可打包app - 源码1688 卡券绿色循环计划—— 一项旨在构建卡券价值再利用生态的社会责任感项目。在当前数字化消费日益普及的背景下,大量礼品卡、优惠券因各种原因未能有效…...
三星硬盘好还是西数硬盘好?硬盘数据丢失怎么找回
在数字化时代,硬盘作为数据存储的核心组件,其品质与性能直接关系到用户的数据安全与使用体验。在众多硬盘品牌中,三星与西数无疑是两个备受关注的名字。那么,究竟是三星硬盘更胜一筹,还是西数硬盘更受用户青睐…...

企业微信hook接口协议,ipad协议http,设置是否自动同意
设置是否自动同意 参数名必选类型说明uuid是String每个实例的唯一标识,根据uuid操作具体企业微信 请求示例 {"uuid":"bc4800492083fdec4c1a7e5c94","state":1 //1 是需要验证同意(需要手动点击同意) 0关闭验证…...
自动化测试的成本高效果差,那么自动化测试的意义在哪呢?
有人问:自动化测试的成本高效果差,那么自动化测试的意义在哪呢? 我觉得这个问题带有很强的误导性,是典型的逻辑陷阱之一。“自动化测试的成本高效果差”是真的吗?当然不是。而且我始终相信,回答问题的最…...

h5页面用js判断机型是安卓还是ios,判断有app安装没app跳转应用商店app stroe或者安卓应用商店
用vue3写的wep页面。亲测好使。 疑惑: 微信跳转和浏览器跳转不一样,需要控制定时器的时间,android在没下载的情况下点击没反应,ios在没下载的情况下会跳404,就是定时器2000,不知道有没有别的办法࿰…...
:从“课程学习”到“逐步暴露心理疗法”)
算法人生(17):从“课程学习”到“逐步暴露心理疗法”
课程学习(Curriculum Learning)是一种机器学习里常用的策略,它的灵感来源于人类学习方式:学习从简单的概念开始,逐步过渡到更复杂的问题。它通过模仿教育领域中课程安排的思想,设计了一系列有序的任务或数据…...

C++仿函数周边及包装器
我最近开了几个专栏,诚信互三! > |||《算法专栏》::刷题教程来自网站《代码随想录》。||| > |||《C专栏》::记录我学习C的经历,看完你一定会有收获。||| > |||《Linux专栏》࿱…...
改进灰狼算法优化随机森林回归预测
灰狼算法(Grey Wolf Optimization,GWO)是一种基于自然界灰狼行为的启发式优化算法,在2014年被提出。该算法模仿了灰狼群体中不同等级的灰狼间的优势竞争和合作行为,通过不断搜索最优解来解决复杂的优化问题。 灰狼算法…...

Hadoop生态系统的核心组件探索
理解大数据和Hadoop的基本概念 当我们谈论“大数据”时,我们指的是那些因其体积、速度或多样性而难以使用传统数据处理软件有效管理的数据集。大数据可以来自多种来源,如社交媒体、传感器、视频监控、交易记录等,通常包含了TB(太…...
命令行方式将mysql数据库迁移到达梦数据库(全步骤)
因项目需求,需要将mysql数据库转换为国产达梦数据库,但由于安全问题,正式环境只能用命令行方式连接,下列是操作全步骤 目录 一、操作逻辑二、操作步骤1、本地安装达梦相关工具2、将服务器mysql导出到本地a) 服务器命令行导出mysql…...

旅游系列之:庐山美景
旅游系列之:庐山美景 一、路线二、住宿二、庐山美景 一、路线 庐山北门乘坐大巴上山,住在上山的酒店东线大巴游览三叠泉,不需要乘坐缆车,步行上下三叠泉即可,线路很短 二、住宿 长江宾馆庐山分部 二、庐山美景...

杭州恒生面试,社招,3年经验
你好,我是田哥 一位朋友节前去恒生面试,其实面试问题大部分都是八股文,但由于自己平时工作比较忙,完全没有时间没有精力去看八股文,导致面试结果不太理想,HR说节后通知面试结果(估计是凉了&…...

python virtualenv 创建虚拟环境指定python版本,pip 从指定地址下载某个包
一、安装 pip install virtualenv是python3 的话 换成 pip3 如果下载过慢可以从国内链接下载 如下从阿里云下载 pip3 install -i https://mirrors.aliyun.com/pypi/simple virtualenv二、创建指定python版本的虚拟环境 virtualenv venv --pythonpython3.12这里的venv 为创…...

open feign支持调用form-data的接口
增加 consumes {MediaType.MULTIPART_FORM_DATA_VALUE}) 示例 PostMapping(value "/ocr", consumes {MediaType.MULTIPART_FORM_DATA_VALUE})DataResponse ocr(RequestPart("file") MultipartFile multipartFile,RequestPart("fileType") Str…...

ESD静电问题 | TypeC接口整改
【转自微信公众号:深圳比创达EMC】...
基于springboot+mybatis+vue的项目实战之前端
步骤: 1、项目准备:新建项目,并删除自带demo程序,修改application.properties. 2、使用Apifox准备好json数据的mock地址 3、编写基于vue的静态页面 4、运行 整个的目录结构如下: 0、项目准备 新建项目࿰…...

开源软件托管平台gogs操作注意事项
文章目录 一、基本说明二、gogs私有化部署三、设置仓库git链接自动生成参数四、关闭新用户注册入口 私有化部署gogs托管平台,即把gogs安装在我们自己的电脑或者云服务器上。 一、基本说明 系统环境:ubuntu 20.4docker安装 二、gogs私有化部署 前期准…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...