数据挖掘(二)数据预处理
前言
基于国防科技大学 丁兆云老师的《数据挖掘》
数据挖掘
数据挖掘(一)数据类型与统计
2、数据预处理

2.1数据清理
缺失值处理:
from sklearn.impute import SimpleImputer# 创建一个SimpleImputer对象,指定缺失值的处理策略(如均值、中位数、众数等)
imputer = SimpleImputer(strategy='mean') # 可以替换为'median'、'most_frequent'或'constant'# 假设X是包含缺失值的特征矩阵
X = [[1, 2], [np.nan, 3], [7, 6]]# 使用fit_transform方法对特征矩阵进行缺失值处理
X_imputed = imputer.fit_transform(X)# 输出处理后的特征矩阵
print(X_imputed)
离群值处理:
一般使用基于统计方法的离群值处理:(配合箱线图)
- 标准差方法(Standard Deviation Method):通过计算数据的均值和标准差,将超过一定标准差阈值的值识别为离群值,并进行处理。
- 百分位数方法(Percentile Method):基于数据的百分位数,将超过一定百分位数阈值的值识别为离群值,并进行处理。
其它方法还有基于聚类方法的离群值处理,基于监督学习方法的离群值处理等等
2.2 数据集成:
数据集成(Data Integration)是将来自不同来源的数据合并到一个一致的数据集中的过程。在数据集成中,目标是将具有不同结构和格式的数据源整合成一个统一的视图,以便更好地进行数据分析和建模。
在数据集成过程中,可以采用以下方法:
- 数据合并(Data Concatenation):将相同结构的数据源按行或列进行合并。例如,使用Pandas库可以使用
concat函数或merge函数来合并DataFrame对象。 - 数据追加(Data Appending):将不同结构的数据源按行追加到一个数据集中。这通常用于添加新的记录。同样,Pandas库提供了
append函数来实现数据追加。 - 数据连接(Data Joining):根据特定的键(Key)将不同数据源中的记录连接起来。这类似于数据库中的表连接操作。Pandas库中的
merge函数提供了灵活的数据连接功能。 - 数据匹配(Data Matching):通过相似性匹配的方法将数据源中的记录进行关联。这可以使用文本匹配、字符串匹配或其他相似性度量来实现。
- 实体解析(Entity Resolution):通过识别和解决不同数据源中的相同实体(例如人名、公司名等)来进行数据集成。这可以使用姓名解析、实体链接等方法来实现。
容易出现的问题:数据冗余
解决方案:相关性分析和协方差分析
相关性分析(离散型):

连续型:


协方差只能测量线性关系,不能完全描述两个变量之间的非线性关系。此外,协方差的数值大小受到变量单位的影响,因此通常使用标准化的相关系数(如皮尔逊相关系数)来更准确地衡量变量之间的相关性。
2.3 数据规约:
数据规约(Data Reduction)是数据挖掘和分析中的一个重要步骤,旨在减少数据集的维度或数量,同时保留关键信息,以提高计算效率和模型性能。
2.3.1降维:
在数据分析和机器学习任务中,降维(Dimensionality Reduction)是一种常用的数据规约技术,它通过减少特征的维度来处理高维数据。

主成分分析(Principal Component Analysis,PCA)是一种常用的降维方法和统计技术,用于将高维数据集转换为低维表示,同时保留数据中的主要信息。PCA的目标是通过线性变换将原始特征空间映射到新的特征空间,使得新的特征具有最大的方差。
以下是PCA的基本步骤:
- 标准化数据:首先,对原始数据进行标准化处理,使得每个特征具有零均值和单位方差。这是为了确保不同特征的尺度不会对PCA的结果产生不合理的影响。
- 计算协方差矩阵:通过计算标准化后的数据的协方差矩阵,来衡量不同特征之间的相关性。协方差矩阵的元素表示了不同特征之间的协方差。
- 计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示了新特征空间中的方差,特征向量表示了原始特征空间到新特征空间的映射关系。
- 选择主成分:按照特征值的大小降序排列,选择最大的k个特征值对应的特征向量作为主成分,其中k是希望保留的维度。
- 构建投影矩阵:将选择的主成分作为列向量,构建投影矩阵。通过将原始数据与投影矩阵相乘,可以将数据映射到新的低维特征空间。
from sklearn.decomposition import PCA
import numpy as np# 创建一个示例数据集
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])# 创建PCA对象,并指定降维后的维度为2
pca = PCA(n_components=2)# 对数据集进行PCA降维
X_reduced = pca.fit_transform(X)
# 获取每个主成分的贡献率
variance_ratio = pca.explained_variance_ratio_# 计算累积贡献率
cumulative_variance_ratio = np.cumsum(variance_ratio)# 输出每个主成分的贡献率和累积贡献率
for i, ratio in enumerate(variance_ratio):print(f"Component {i+1}: {ratio:.4f}")print("Cumulative Contribution Rate:")
print(cumulative_variance_ratio)
# 输出降维后的数据
print(X_reduced)
一般取累积贡献比达到85%到95%
2.3.2 降数据(降采样):
下面介绍两种常见的降采样方法:
- 随机抽样(Random Sampling):从原始数据集中随机选择一部分样本作为降采样后的数据集。这种方法简单快速,但可能会导致抽样后的数据集不够代表性。
import numpy as np# 创建一个示例数据集
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])# 随机抽样,降采样至2个样本
num_samples = 2
random_indices = np.random.choice(X.shape[0], size=num_samples, replace=False)
X_reduced = X[random_indices]# 输出降采样后的数据
print(X_reduced)
- 分层抽样(Stratified Sampling):保持原始数据集中不同类别样本的比例,从每个类别中抽取一定数量的样本作为降采样后的数据集。这种方法可以保持类别分布的均衡性。
from sklearn.model_selection import train_test_split# 创建一个示例数据集和标签
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
y = np.array([0, 1, 0, 1])# 分层抽样,保持类别比例,降采样至2个样本
num_samples = 2
X_reduced, _, y_reduced, _ = train_test_split(X, y, train_size=num_samples, stratify=y, random_state=42)# 输出降采样后的数据和标签
print(X_reduced)
print(y_reduced)
2.3.3 数据压缩
2.4 数据转换与离散化:
2.4.1 规范化
最小-最大规范化(Min-Max Normalization):
最小-最大规范化将数据线性地映射到一个指定的范围(通常是[0, 1]或[-1, 1])。公式如下:
X_norm = (X - X_min) / (X_max - X_min)
其中,X为原始数据,X_min和X_max分别为原始数据的最小值和最大值。
import numpy as np# 创建一个示例数据集
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 最小-最大规范化
X_min = np.min(X, axis=0)
X_max = np.max(X, axis=0)
X_norm = (X - X_min) / (X_max - X_min)# 输出规范化后的数据
print(X_norm)
Z-Score规范化(Standardization):
Z-Score规范化将数据转换为均值为0、标准差为1的分布。公式如下:
X_norm = (X - mean) / std
其中,X为原始数据,mean为原始数据的均值,std为原始数据的标准差。
import numpy as np# 创建一个示例数据集
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# Z-Score规范化
mean = np.mean(X, axis=0)
std = np.std(X, axis=0)
X_norm = (X - mean) / std# 输出规范化后的数据
print(X_norm)
2.4.2 离散化

等宽离散化(Equal Width Discretization):
等宽离散化将数据的值范围分成相等宽度的区间。具体步骤如下:
- 确定要划分的区间个数(例如,n个区间)。
- 计算数据的最小值(min_value)和最大值(max_value)。
- 计算每个区间的宽度(width):width = (max_value - min_value) / n。
- 将数据根据区间宽度映射到相应的区间。
import numpy as np# 创建一个示例数据集
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])# 等宽离散化
n_bins = 3
width = (np.max(X) - np.min(X)) / n_bins
bins = np.arange(np.min(X), np.max(X) + width, width)
X_discretized = np.digitize(X, bins)# 输出离散化后的数据
print(X_discretized)
等频离散化(Equal Frequency Discretization):
等频离散化将数据划分为相同数量的区间,每个区间包含相同数量的数据。具体步骤如下:
- 确定要划分的区间个数(例如,n个区间)。
- 计算每个区间的数据数量(每个区间应包含总数据数量除以区间个数的数据)。
- 将数据按照值的大小排序。
- 按照区间的数据数量依次划分数据。
import numpy as np# 创建一个示例数据集
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])# 等频离散化
n_bins = 3
bin_size = len(X) // n_bins
sorted_X = np.sort(X)
bins = [sorted_X[i * bin_size] for i in range(1, n_bins)]
X_discretized = np.digitize(X, bins)# 输出离散化后的数据
print(X_discretized)
聚类离散化(Cluster Discretization):
聚类离散化使用聚类算法将数据划分为不同的簇,每个簇作为一个离散化的值。常用的聚类算法包括K-Means、DBSCAN等。该方法需要根据数据的分布和特点进行参数调整和簇数的选择。
相关文章:
数据挖掘(二)数据预处理
前言 基于国防科技大学 丁兆云老师的《数据挖掘》 数据挖掘 数据挖掘(一)数据类型与统计 2、数据预处理 2.1数据清理 缺失值处理: from sklearn.impute import SimpleImputer# 创建一个SimpleImputer对象,指定缺失值的处理策略…...
docker学习-docker常用其他命令整理
随便写写,后面有空再更新 镜像命令,容器命令已在之前略有更新,这次不写, 一、后台启动命令 # 命令 docker run -d 容器名 # 例子 docker run -d centos # 启动centos,使用后台方式启动 # 问题: 使用doc…...

【matlab基础知识代码】(十六)代数方程的图解法多项式型方程的准解析解方法
>> ezplot(exp(-3*t)*sin(4*t2)4*exp(-0.5*t)*cos(2*t)-0.5,[0 5]), line([0 5],[0 0]) 验证 >> t0.6738; >> exp(-3*t)*sin(4*t2)4*exp(-0.5*t)*cos(2*t)-0.5 ans -2.9852e-04 >> ezplot(x^2*exp(-x*y^2/2)exp(-x/2)*sin(x*y)) >> hold on; …...

智能奶柜:健康生活新风尚
智能奶柜:健康生活新风尚 在快节奏的都市生活中,健康与便利成为了现代人的双重追求。而在这两者交汇之处,智能奶柜应运而生,它不仅是科技与生活的完美融合,更是日常营养补给的智慧之选。 清晨的第一缕温暖 —— 新鲜…...

SpringBoot 集成 FFmpeg 解析音视频
文章目录 1 摘要2 核心 Maven 依赖3 核心代码3.1 FFmpeg 解析音视频工具类3.2 音视频文件信息参数3.3 音视频文件上传Controller3.4 application 配置文件 4 测试数据4.1 视频文件解析4.2 音频文件解析 5 注意事项5.1 文件必须在本地 6 推荐参考文档7 Github 源码 1 摘要 FFmp…...
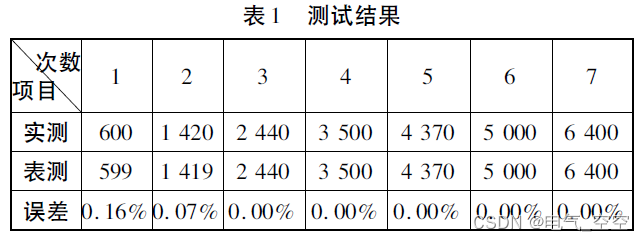
基于单片机的直流电机测速装置研究与设计
摘要: 基于单片机的直流电机测速装置采用了对直流电机的中枢供电回路串联取样电阻的方式实现对电机转速的精确实时测量。系统由滤波电路、信号放大电路、单片机控制电路以及稳压电源等功能模块电路构成。工作过程中高频磁环作为载体,利用电磁感应的基本原理对直流电…...

【快捷部署】022_ZooKeeper(3.5.8)
📣【快捷部署系列】022期信息 编号选型版本操作系统部署形式部署模式复检时间022ZooKeeper3.5.8Ubuntu 20.04tar包单机2024-05-07 一、快捷部署 #!/bin/bash ################################################################################# # 作者ÿ…...

引领AI数据标注新纪元:景联文科技为智能未来筑基
在人工智能蓬勃发展的今天,数据如同燃料,驱动着每一次技术飞跃。在这场智能革命的浪潮中,景联文科技凭借其深厚的专业实力与前瞻性的战略眼光,正站在行业前沿,为全球的人工智能企业提供坚实的数据支撑。 全国布局&…...

多模态大语言模型和 Apple 的 MM1
原文地址:multimodal-large-language-models-apples-mm1 2024 年 4 月 13 日 抽象是计算机科学中最关键的概念之一,具有一些最强大的影响。从简单的角度来看,抽象就是将某一事物应用于多种不同情况的能力。例如,如果你创造了一种…...
算法day04
第一题 : 209. 长度最小的子数组 有上题可知,我们会采用双指针和单调性的思路来解决 我们本题采用左右双指针从数组的0位置同向前进,所以将此类模型称为滑块; 步骤思路如下: 步骤一: 定义所有双指针都指向…...
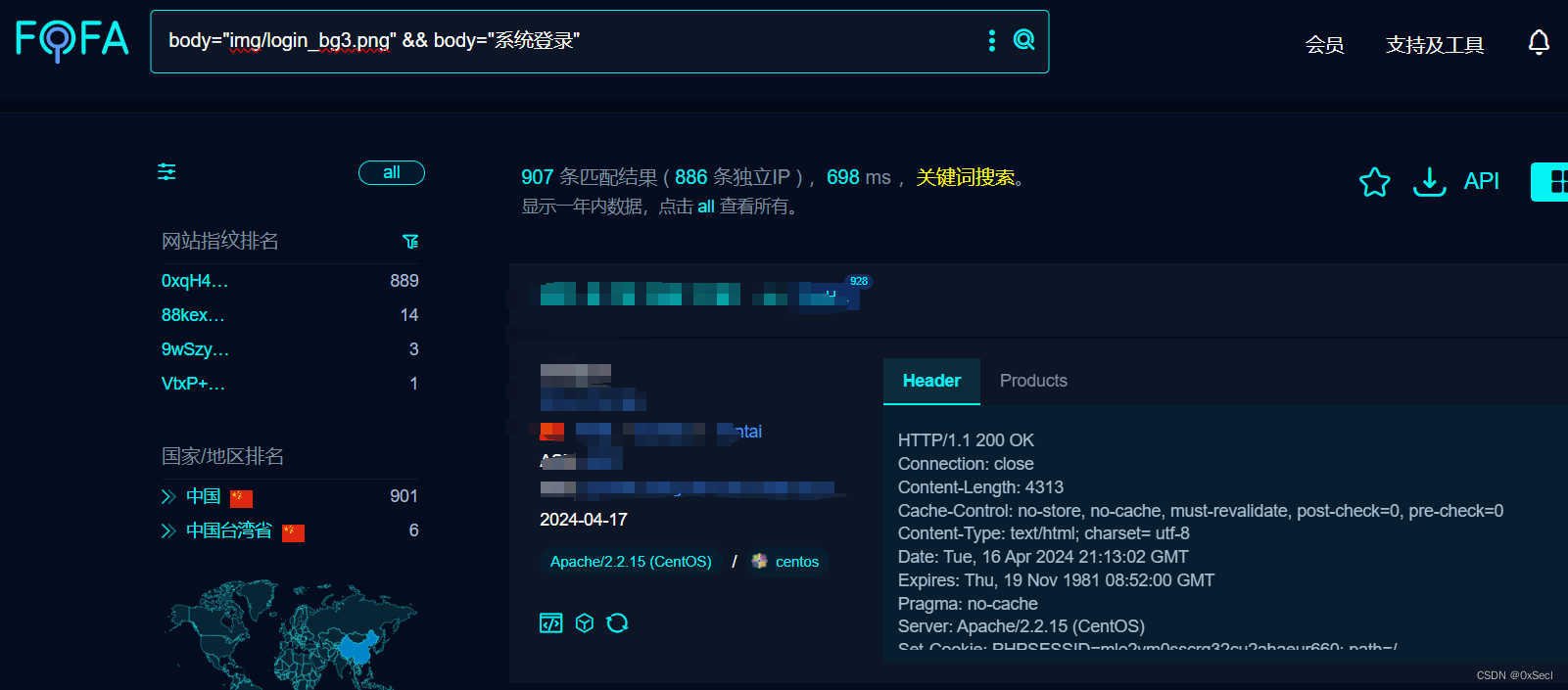
电信网关配置管理系统 rewrite.php 文件上传致RCE漏洞复现
0x01 产品简介 中国电信集团有限公司(英文名称“China Telecom”、简称“中国电信”)成立于2000年9月,是中国特大型国有通信企业、上海世博会全球合作伙伴。电信网关配置管理系统是一个用于管理和配置电信网络中网关设备的软件系统。它可以帮助网络管理员实现对网关设备的远…...

从零学算法14
14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: 输入:strs [“d…...
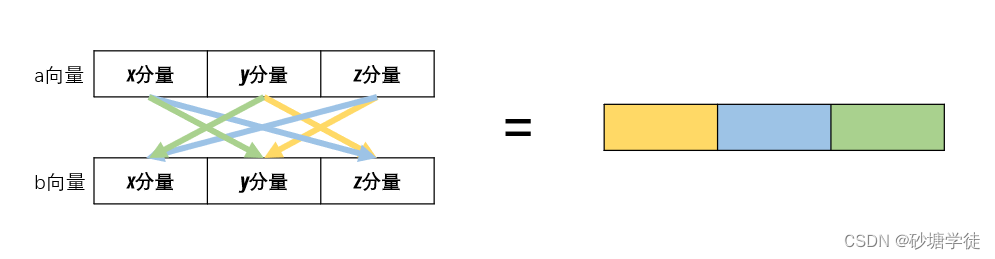
[入门] Unity Shader前置知识(5) —— 向量的运算
在Unity中,向量无处不在,我想很多人都使用过向量类的内置方法 normalized() 吧,我们都知道该方法是将其向量归一化从而作为一个方向与速度相乘,以达到角色朝任一方向移动时速度都相等的效果,但内部具体是如何将该向量进…...

html的i标签 “\e905“ font-family 字体没有效果
一、html的i标签 “\e905” 没有效果 在HTML和CSS中,\e905 这样的字符通常与字体图标(Font Icons)或自定义字体(Custom Fonts)中的Unicode字符相关。具体来说,\e905 是一个Unicode转义序列,但它…...
 的用法及示例)
Golang reflect.MakeFunc() 的用法及示例
Golang 作为一门强类型语言,在某些场景下,我们需要动态地创建函数或者修改函数,这个时候就可以使用反射的方法去实现。在反射中,我们可以使用 reflect.MakeFunc() 方法来创建一个新的函数,本文我将介绍使用反射及其 Ma…...

深入学习和理解Django视图层:处理请求与响应
title: 深入学习和理解Django视图层:处理请求与响应 date: 2024/5/4 17:47:55 updated: 2024/5/4 17:47:55 categories: 后端开发 tags: Django请求处理响应生成模板渲染表单处理中间件异常处理 第一章:Django框架概述 1.1 什么是Django?…...
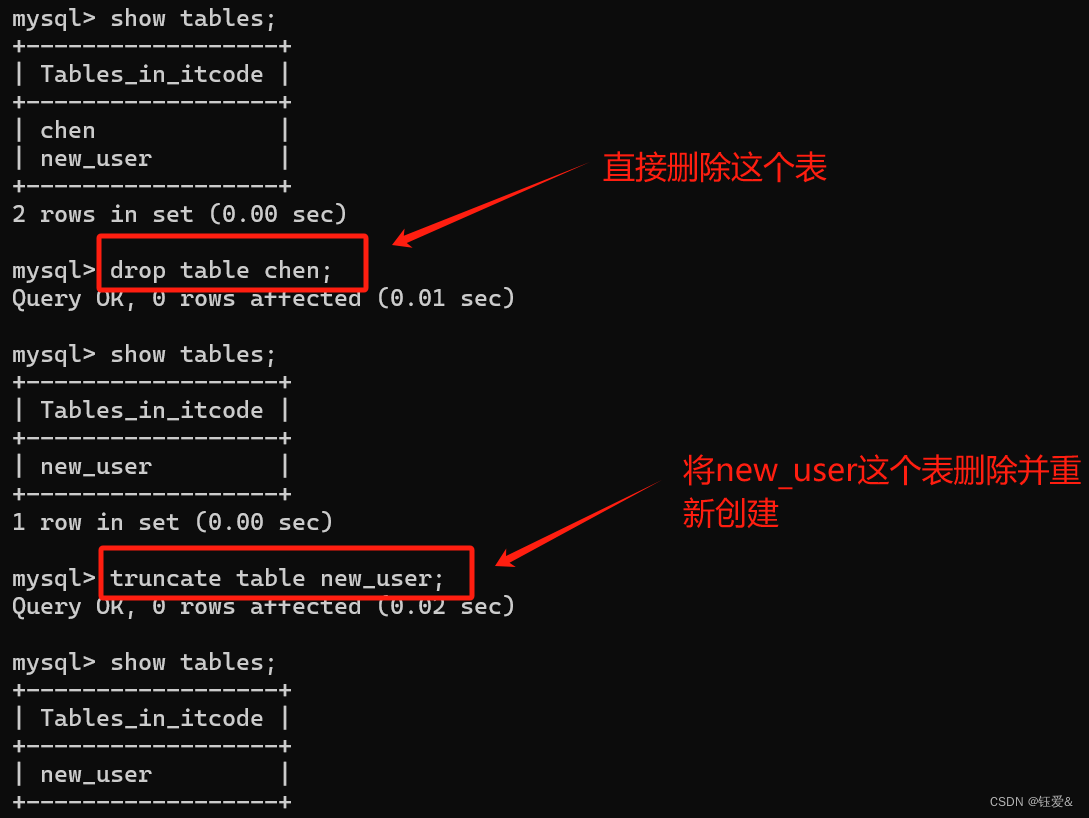
【MySQL】SQL基本知识点DDL(1)
目录 1.SQL分类: 2.DDL-数据库操作 3.DDL-表操作-创建 4.DDL-表操作-查询 5.DDL-表操作-数据类型 6.DDL-表操作-修改 1.SQL分类: 2.DDL-数据库操作 3.DDL-表操作-创建 注意:里面的符号全部要切换为英文状态 4.DDL-表操作-查询 5.DDL…...

短剧奔向小程序,流量生意如何开启?
随着移动互联网的飞速发展,小程序作为一种轻量级、易传播的应用形态,逐渐在各个领域展现出其独特的商业价值。而最近爆火的短剧小视频作为一种受众广泛的娱乐形式,与小程序结合后,不仅为观众提供了更为便捷的观看体验,…...
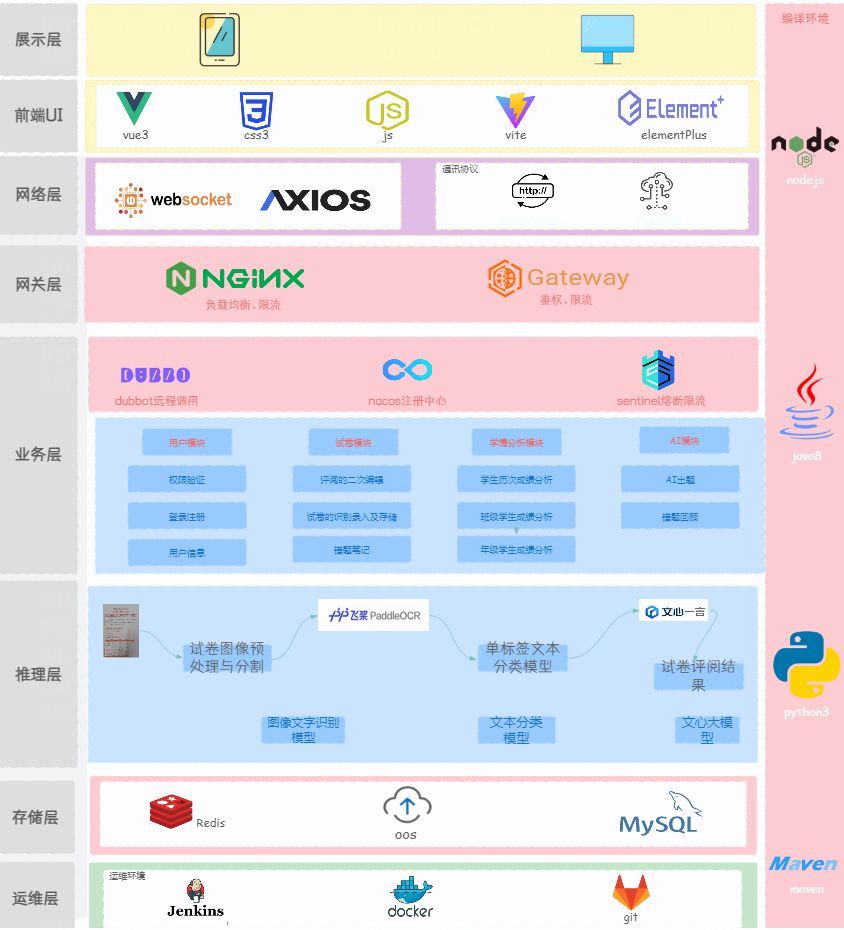
微服务下的技术栈架构解析
微服务是一种架构风格,它将一个复杂的应用拆分成多个独立自治的服务,每个服务负责应用程序中的一小部分功能。这些服务通过定义良好的API进行通信,通常是HTTP RESTful API或事件流。微服务架构的主要特点包括单一职责、自治性、可独立部署和扩…...
)
Mesa3D图形库与NIR(New Intermediate Representation)
Mesa 是一个开源图形库,为 Unix 和 Linux 系统提供了 OpenGL 和 Vulkan API 的实现。它也支持其他图形 API,如OpenCL、OpenGL ES 和 Vulkan。Mesa 项目的目标是为开源社区提供高性能的图形库,使得开源操作系统能够充分利用现代图形硬件。 Me…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...