Lesson 8.3 ID3、C4.5 决策树的建模流程 Lesson 8.4 CART 回归树的建模流程与 sklearn 参数详解
文章目录
- 一、ID3 决策树的基本建模流程
- 二、C4.5 决策树的基本建模流程
- 1. 信息值(information value)
- 2. C4.5 的连续变量处理方法
- 三、CART 回归树的基本建模流程
- 1. 数据准备
- 2. 生成备选规则
- 3. 挑选规则
- 4. 进行多轮迭代
- 5. 回归树的预测过程
- 四、CART 回归树的 Scikit-Learn 实现方法
- 1. CART 回归树的 sklearn 快速实现
- 2. CART 回归树评估器的参数解释
- 2.1 criterion='mse' 情况
- 2.2 criterion='mae' 情况
- 2.3 criterion='friedman_mse' 情况
- ID3 和 C4.5 作为的经典决策树算法,尽管无法通过 sklearn 来进行建模,但其基本原理仍然值得讨论与学习。接下来我们详细介绍关于 ID3 和 C4.5 这两种决策树模型的建模基本思路和原理。
- ID3 和 C4.5 的基本建模流程和 CART 树是类似的,也是根据纯度评估指标选取最佳的数据集划分方式,只是不过 ID3 和 C4.5 是以信息熵为评估指标。
- 而数据集的离散特征划分方式也是一次展开一列,而不是寻找切点进行切分。我们先从 ID3 的基本原理开始介绍,随后讨论 C4.5 在 ID3 基础上的改善措施。
import numpy as np
from ML_basic_function import *
一、ID3 决策树的基本建模流程
- ID3 是一个只能围绕离散型变量进行分类问题建模的决策树模型,即 ID3 无法处理连续型特征、也无法处理回归问题,如果带入训练数据有连续型变量,则首先需要对其进行离散化处理,也就是连续变量分箱。
- 例如如下个人消费数据,各特征都是离散型变量,能够看出,其中 age 和 income 两列就是连续型变量分箱之后的结果,例如 age 列就是以 30、40 为界进行连续变量分箱。
- 当然,除了如下表示外,我们还可以将分箱之后的结果直接赋予一个离散的值,如 1、2、3 等。

- ID3 的生长过程其实和 CART 树基本一致,其目标都是尽可能降低数据集的不纯度,其生长的过程也就是数据集不断划分的过程。
- 只不过 ID3 的数据集划分过程(规律提取过程)和 CART 树有所不同,CART 树是在所有特征中寻找切分点、然后再从中挑选出能够最大程度降低数据集不纯度的节分方式,换而言之就是 CART 树是按照某切分点来展开,而 ID3 则是按照列来展开,即根据某列的不同取值来对数据集进行划分。
- 例如根据上述数据集中的 age 列的不同取值来对原始数据集进行划分,则划分结果如下:
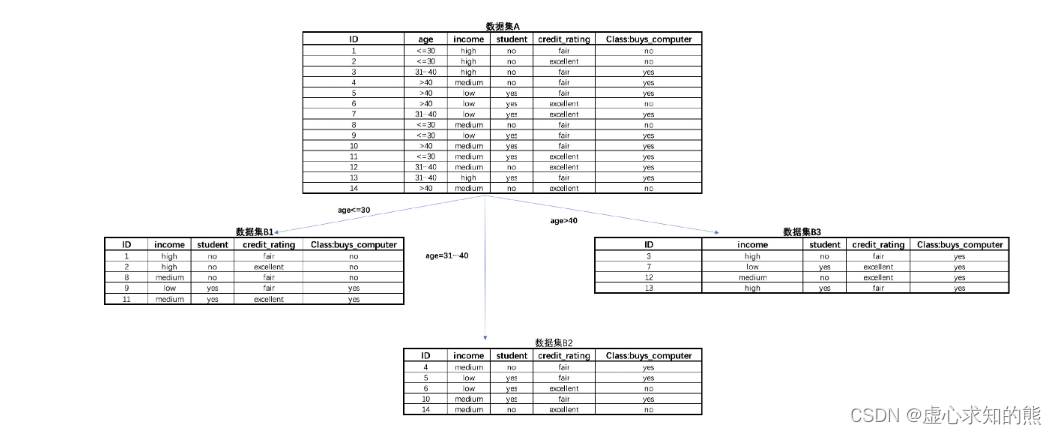
- 同样,我们可以计算在以 age 的不同取值为划分规则、对数据集进行划分后数据集整体不纯度下降结果,ID3 中采用信息熵作为评估指标,具体计算过程如下:
- 首先计算父节点的信息熵。
# 父节点A的信息熵
ent_A = -5/14 * np.log2(5/14) - 9/14 * np.log2(9/14)
ent_A
#0.9402859586706311
- 然后计算每个子节点的信息熵。
# 子节点B的信息熵
ent_B1 = entropy(2/5)
ent_B2 = entropy(2/5)
ent_B3 = 0
ent_B1, ent_B2, ent_B3
#(0.9709505944546686, 0.9709505944546686, 0)
- 同样,子节点整体信息熵就是每个子节点的信息熵加权求和计算得出,其权重就是各子节点数据集数量占父节点总数据量的比例:
ent_B = ent_B1 * 5/14 + ent_B2 * 5/14 + ent_B3 * 4/14
ent_B
#0.6935361388961919
- 然后即可算出按照如此规则进行数据集划分,最终能够减少的不纯度数值:
# 不纯度下降结果
ent_A - ent_B
#0.24674981977443922
- 而该结果也被称为根据 age 列进行数据集划分后的信息增益(information gain),上述结果可写成Gain(age) = 0.247。
- 当然,至此我们只计算了按照 age 列的不同取值来进行数据集划分后数据集不纯度下降结果,而按照 age 列进行展开只能算是树的第一步生长中的一个备选划分规则。
- 此外我们还需要测试按照 income、student 或者 credit_rating 列展开后数据集不纯度下降情况,具体计算过程和 age 列展开后的计算过程类似,此处直接给出结果,Gain(income)=0.026、Gain(student)=0.151、Gain(credit_rating)=0.048。
- 很明显,按照 age 列展开能够更有效的降低数据集的不纯度,因此树的第一层生长就是按照 age 列的不同取值对数据集进行划分。
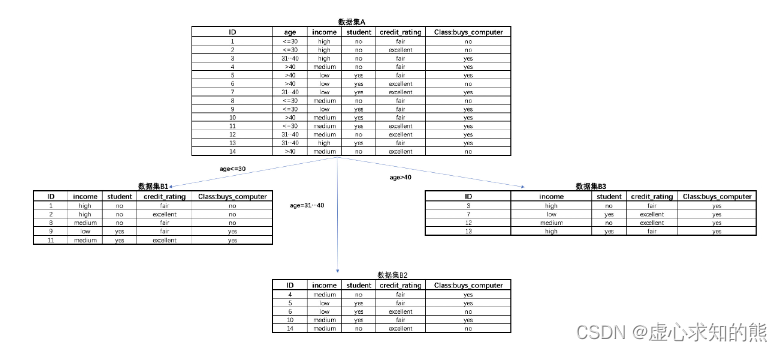
- 接下来需要继续进行迭代,通过观察我们不难发现,对于数据集 B1 来说来说,按照 student 这一列来进行展开,能够让子节点的信息熵归零,而数据集 B2 按照如果按照 credit_rating 来展开,也同样可以将子节点的标签纯度提高至 100%。因此该模型最终树的生长形态如下:
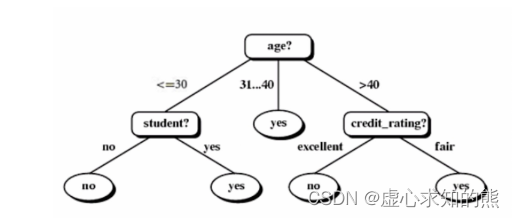
- 至此,我们就完成了 ID3 决策树的建模全流程,具体模型结果解读和 CART 树完全一样,此处不做赘述。
- 接下来简单对比 ID3 和 CART 树之间的差异:首先,由于 ID3 是按照列来提取规则、每次展开一列,因此每一步生长会有几个分支,其实完全由当前列有几个分类水平决定,而 CART 树只能进行二叉树的生长。
- 其次,由于 ID3 每次展开一列,因此建模过程中对列的消耗非常快,数据集中特征个数就决定了树的最大深度,相比之下 CART 树的备选规则就要多的多,这也使得 CART 树能够进行更加精细的规则提取。
- 当然,尽管 CART 树和 ID3 存在着基本理论层面的差异,但有的时候也能通过 CART 树的方法来挖掘出和 ID3 决策树相同的规律,例如 ID3 中按照 age 列一层展开所提取出的三个分类规则,也可以在 CART 树中通过两层树来实现,例如第一层按照是否是 <=30 来进行划分、第二层围绕不满足第一层条件的数据集进一步根据是否 > 40来进行划分。
- 此外,需要注意的是,正因为 ID3 是按照列来进行展开,因此只能处理特征都是离散变量的数据集。另外,根据 ID3 的建模规则我们不难发现,ID3 树在实际生长过程中会更倾向于挑选取值较多的分类变量展开。
- 但如此一来便更加容易造成模型过拟合,而遗憾的是 ID3 并没有任何防止过拟合的措施。而这些 ID3 的缺陷,则正是 C4.5 算法的改进方向。
- 当然,对于 ID3 来说,规则是和分类变量的取值一一绑定的,
二、C4.5 决策树的基本建模流程
- 作为 ID3 的改进版算法,C4.5 在 ID3 的基础上进行了三个方面的优化,首先在衡量不纯度降低的数值计算过程中引入信息值(information value,也被称为划分信息度、分支度等)概念来修正信息熵的计算结果,以抑制 ID3 更倾向于寻找分类水平较多的列来展开的情况,从而间接抑制模型过拟合倾向。
- 其二则是新增了连续变量的处理方法,也就是 CART 树中寻找相邻取值的中间值作为切分点的方法。
- 其三是加入了决策树的剪枝流程,使得模型泛化能力能够得到进一步提升。但需要注意的是,尽管有如此改进,但 C4.5 仍然只能解决分类问题,其本质仍然还是一种分类树。接下来我们详细讨论 C4.5 的具体改进策略。
1. 信息值(information value)
- C4.5 中信息值(以下简称IV值)是一个用于衡量数据集在划分时分支个数的指标,如果划分时分支越多,IV值就越高。具体IV值的计算公式如下:InformationValue=−∑i=1KP(vi)log2P(vi)Information\ Value = -\sum^K_{i=1}P(v_i)log_2P(v_i)Information Value=−i=1∑KP(vi)log2P(vi)
- IV 值计算公式和信息熵的计算公式基本一致,只是具体计算的比例不再是各类样本所占比例,而是各划分后子节点的数据所占比例,或者说信息熵是计算标签不同取值的混乱程度,而 IV 值就是计算特征不同取值的混乱程度。
- 其中 K 表示某次划分是总共分支个数, viv_ivi 表示划分后的某样本,P(vi)P(v_i)P(vi) 表示该样本数量占父节点数据量的比例。对于如下三种数据集划分情况,简单计算 IV 值:
# 父节点按照50%-50%进行划分
- (1/2 * np.log2(1/2) + 1/2 * np.log2(1/2))
#1.0# 父节点按照1/4-1/2-1/4进行划分
- (1/4 * np.log2(1/4) + 1/2 * np.log2(1/2)+ 1/4 * np.log2(1/4))
#1.5# 父节点按照1/4-1/4-1/4-1/4进行划分
- (1/4 * np.log2(1/4) + 1/4 * np.log2(1/4) + 1/4 * np.log2(1/4) + 1/4 * np.log2(1/4))
#2.0
- 而在实际建模过程中,ID3 是通过信息增益的计算结果挑选划分规则,而 C4.5 采用 IV 值对信息增益计算结果进行修正,构建新的数据集划分评估指标:增益比例(Gain Ratio,被称为获利比例或增益率),来指导具体的划分规则的挑选。GR 的计算公式如下:GainRatio=InformationGainInformationValueGain\ Ratio = \frac{Information\ Gain}{Information\ Value}Gain Ratio=Information ValueInformation Gain
- 也就是说,在 C4.5 的建模过程中,需要先计算 GR,然后选择 GR 计算结果较大的列来执行这一次展开。例如对于上述例子来看,以 age 列展开后 Information Gain 结果为:
IG = ent_A - ent_B
IG
0.24674981977443922
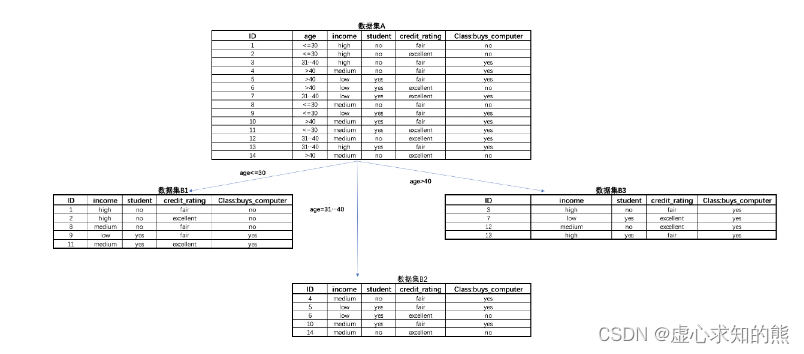
- 而 IV 值为:
IV = - (5/14 * np.log2(5/14) + 5/14 * np.log2(5/14)+ 4/14 * np.log2(4/14))
IV
#1.5774062828523454
- 因此计算得到 GR 值为:
GR = IG / IV
GR
#0.1564275624211752
- 然后据此进一步计算其他各列展开后的 GR 值,并选择 GR 较大者进行数据集划分。
2. C4.5 的连续变量处理方法
- C4.5 允许带入连续变量进行建模,并且围绕连续变量的规则提取方式和此前介绍的 CART 树一致。即在连续变量中寻找相邻的取值的中间点作为备选切分点,通过计算切分后的 GR 值来挑选最终数据集划分方式。
- 当然,基于连续变量的备选切分方式也要和离散变量的切分方式进行横向比较,到底是一次展开一个离散列还是按照连续变量的某个切点展开,要根据最终 GR 的计算结果来决定。
- 例如,如果将上述数据集的 age 列换成连续变量,则我们需要计算的 GR 情况就变成了 GR(income)、GR(student)、GR(credit_rating)、GR(age<=26.5)、GR(age<=27.5)…
- 当然,由于 C4.5 的离散变量和连续变量提取规则方式不同,离散变量是一次消耗一列来进行展开(有可能多分叉),而连续变量则一次消耗一个切分点,因此和 CART 树一样、同一个连续变量可以多次指导数据集进行划分。
三、CART 回归树的基本建模流程
- 接下来,我们继续讨论关于 CART 回归树的相关内容。
- 根据此前介绍,CART 树能同时解决分类问题和回归问题,但由于两类问题的性质还是存在一定的差异,因此 CART 树在处理不同类型问题时相应建模流程也略有不同,当然对应的 sklearn 中的评估器也是不同的。
- 并且值得一提的是,尽管回归树单独来看是解决回归类问题的模型,但实际上回归树其实是构建梯度提升树(GBDT,一种集成算法)的基础分类器,并且无论是解决回归类问题还是分类问题,CART 回归树都是唯一的基础分类器,因此哪怕单独利用回归树解决问题的场景并不多见,但对于 CART 回归树的相关方法仍然需要重点掌握,从而为后续集成算法的学习奠定基础。
- 本节我们将在 CART 分类树的基础之上详细讨论 CART 树在处理回归问题时的基本流程,并详细介绍关于 CART 回归树在 sklearn 中评估器的的相关参数与使用方法。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
# Scikit-Learn相关模块
# 评估器类
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
# 实用函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据准备
from sklearn.datasets import load_iris
- 同样,我们先从一个极简的例子来了解 CART 回归树的基本建模流程,然后再介绍通过数学语言描述得更加严谨的建模流程。
1. 数据准备
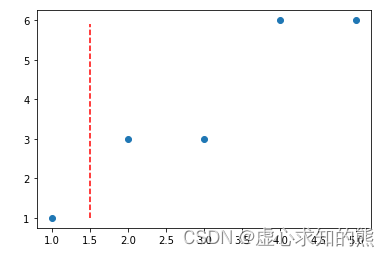
- 首先我们创建一个简单的回归数据集如下,该数据集只包含一个特征和一个连续型标签:
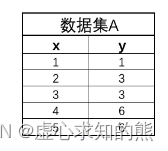
data = np.array([[1, 1], [2, 3], [3, 3], [4, 6], [5, 6]])
plt.scatter(data[:, 0], data[:, 1])
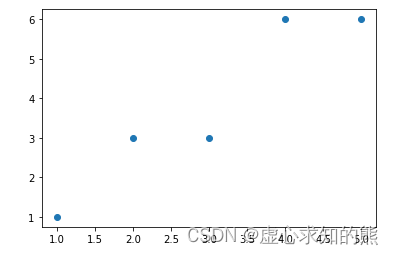
- 其中横坐标代表数据集特征,纵坐标代表数据集标签。
2. 生成备选规则
- CART 回归树和分类树流程类似,从具体操作步骤来看,首先都是寻找切分点对数据集进行切分,或者说需要确定备选划分规则。
- 回归树中寻找切分点的方式和分类树的方式相同,都是逐特征寻找不同取值的中间点作为切分点。对于上述数据集来说,由于只有一个特征,并且总共有 5 个不同的取值,因此切分点有 4 个。
- 而根据此前介绍,有几个切分点就有几种数据集划分方式、即有同等数量的备选划分规则、或有同等数量的树的生长方式。初始数据集的 4 个不同的划分方式,可以通过如下方式进行呈现:
y_range = np.arange(1, 6, 0.1)plt.subplot(221)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.subplot(222)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 2.5), y_range, 'r--')
plt.subplot(223)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.subplot(224)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 4.5), y_range, 'r--')
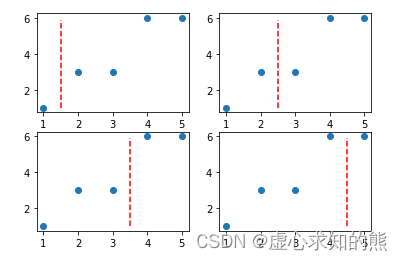
3. 挑选规则
- 在确定了备选划分规则之后,接下来需要根据某种评估标准来寻找最佳划分方式。、回归树的该步骤和分类树差异较大,分类树中我们是采用基尼系数或者信息熵来衡量划分后数据集标签不纯度下降情况来挑选最佳划分方式,而在回归树中,则是根据划分之后子数据集 MSE 下降情况来进行最佳划分方式的挑选。
- 在该过程中,子数据集整体的 MSE 计算方法也和 CART 分类树类似,都是先计算每个子集单独的 MSE,然后再通过加权求和的方法来进行计算两个子集整体的 MSE。
- 此处 MSE 的计算虽然不复杂,但我们知道,但凡需要计算 MSE,就必须给出一个预测值,然后我们才能根据预测值和真实值计算 MSE。
- 而 CART 回归树在进行子数据集的划分之后,会针对每个子数据集给出一个预测值(注意是针对一个子数据集中所有数据给出一个预测值,而不是针对每一个数给出一个预测值),而该预测值会依照让对应子数据集 MSE 最小的目标进行计算得出。
- 让 MSE 取值最小这一目标其实等价于让 SSE 取值最小,而用一个数对一组数进行预测并且要求 SSE 最小,其实就相当于 K-Means 快速聚类过程中所要求的寻找组内误差平方和最小的点作为中心点,我们曾在 Lesson 7 中进行过相关数学推导,此时选取这组数的质心能够让组内误差平方和计算结果最小。
- 而此时情况也是类似,只不过我们针对一组一维的数据去寻找一个能够使得组内误差平方和的最小的点,这个点仍然是这组数据的质心,而一维数据的质心,其实就是这组数据的均值。那么也就是说,在围绕让每一个子数据集 MSE 取值最小这一目标下,每个子数据集的最佳预测值就是这个子数据集真实标签的均值。
- 具体计算过程如下,例如对上述第一种划分数据集的情况来说,每个子数据集的预测值和 MSE 计算结果如下:
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
- 对应划分情况也可以通过如下形式进行表示:
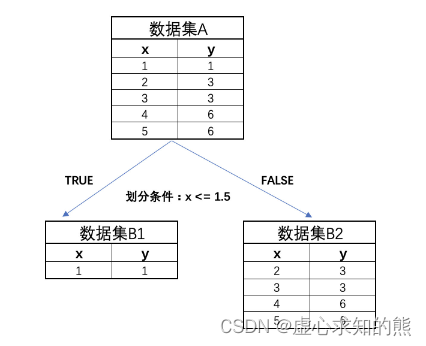
- 此时可计算子数据集 B1 和 B2 的 MSE,首先是两个数据集的预测值,也就是两个数据集的均值:
data[0, 1]
#1# B1数据集的预测值
y_1 = np.mean(data[0, 0])
y_1
#1.0data[1: , 1]
#array([3, 3, 6, 6])# B2数据集的预测值
y_2 = np.mean(data[1: , 1])
y_2
#4.5# 模型预测结果
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.plot(np.arange(0, 1.5, 0.1), np.full_like(np.arange(0, 1.5, 0.1), y_1), 'r-')
plt.plot(np.arange(1.7, 5.1, 0.1), np.full_like(np.arange(1.7, 5.1, 0.1), y_2), 'r-')
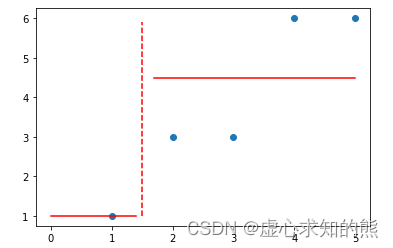
- 然后计算两个子集的 MSE:
# B1的MSE
mse_b1 = 0# B2的MSE
mse_b2 = np.power(data[1: , 1] - 4.5, 2).sum() / 4
mse_b2
#2.25
- 然后和 CART 分类树一样,以各子集所占全集的样本比例为权重,通过加权求和的方式计算两个子集整体的 MSE:
mse_b = 1/5 * mse_b1 + 4/5 * mse_b2
mse_b
#1.8
- 而父节点的 MSE 为:
data[: , 1].mean()
#3.8mse_a = np.power(data[: , 1] - data[: , 1].mean(), 2).sum() / data[: , 1].size
mse_a
#3.7599999999999993
- 因此,本次划分所降低的 MSE 为:
mse_a - mse_b
#1.9599999999999993
- 即为该种划分方式的最终评分。当然,我们要以相似的流程计算其他几种划分方式的评分,然后从中挑选能够最大程度降低 MSE 的划分方式,基本流程如下:
impurity_decrease = []
for i in range(4):# 寻找切分点splitting_point = data[i: i+2 , 0].mean()# 进行数据集切分data_b1 = data[data[:, 0] <= splitting_point]data_b2 = data[data[:, 0] > splitting_point]# 分别计算两个子数据集的MSEmse_b1 = np.power(data_b1[: , 1] - data_b1[: , 1].mean(), 2).sum() / data_b1[: , 1].sizemse_b2 = np.power(data_b2[: , 1] - data_b2[: , 1].mean(), 2).sum() / data_b2[: , 1].size# 计算两个子数据集整体的MSEmse_b = data_b1[: , 1].size/data[: , 1].size * mse_b1 + data_b2[: , 1].size/data[: , 1].size * mse_b2#mse_b = mse_b1 + mse_b2# 计算当前划分情况下MSE下降结果impurity_decrease.append(mse_a - mse_b)impurity_decrease
#[1.9599999999999993, 2.1599999999999993, 3.226666666666666, 1.209999999999999]plt.subplot(221)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.subplot(222)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 2.5), y_range, 'r--')
plt.subplot(223)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.subplot(224)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 4.5), y_range, 'r--')
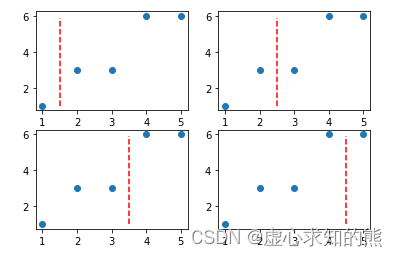
- 根据最终结果能够看出,第三种划分情况能够最大程度降低 MSE,即此时树模型的第一次生长情况如下:
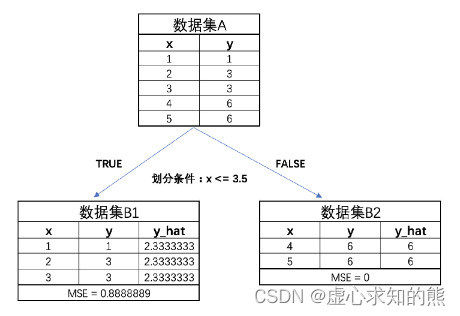
4. 进行多轮迭代
- 当然,和 CART 分类树一样,接下来,我们就能够进一步围绕 B1 和 B2 进行进一步划分。此时 B2 的 MSE 已经为 0,因此无需再进行划分,而 B1 的 MSE 为 0.88,还可以进一步进行划分。
- 当然 B1 的划分过程也和 A 数据集的划分过程一致,寻找能够令子集 MSE 下降最多的方式进行切分。不过由于 B1 数据集本身较为简单,通过观察不难发现,我们可以以 x<= 1.5 作为划分条件对其进行切分,进一步切分出来的子集的 MSE 都将取值为 0。

- 此外,我们也可以观察当回归树生长了两层之后,相关规则对原始数据集的划分情况:
# 数据分布
plt.scatter(data[:, 0], data[:, 1])
# 两次划分
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
# 预测结果
plt.plot(np.arange(1, 1.5, 0.1), np.full_like(np.arange(1, 1.5, 0.1), 1), 'r-')
plt.plot(np.arange(1.5, 3.5, 0.1), np.full_like(np.arange(1.5, 3.5, 0.1), 3), 'r-')
plt.plot(np.arange(3.5, 5, 0.1), np.full_like(np.arange(3.5, 5, 0.1), 6), 'r-')
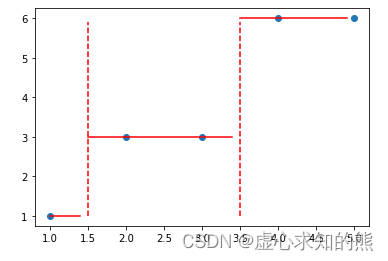
- 不难发现,回归树的对标签的预测,实际上是一种分区定值的预测,建模过程的实际表现是对样本进行划分、然后每个区间给定一个预测值,并且树的深度越深、对样本空间的划分次数就越多、样本空间就会被分割成更多的子空间。
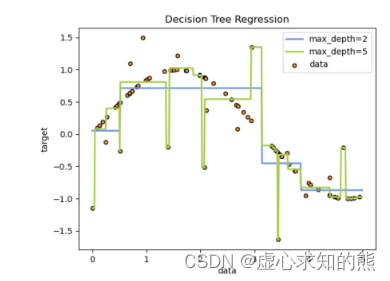
- 在 sklearn 的说明文档中也有相关例子:
5. 回归树的预测过程
- 而一旦当模型已经构建完成后,回归树的预测过程其实和分类树非常类似,新数据只要根据划分规则分配到所属样本空间,则该空间模型的预测结果就是该数据的预测结果。
- 至此,我们就在一个极简的数据集上完成了 CART 回归树的构建。不难发现,回归树和分类树的构建过程大致相同、迭代过程也基本一致,我们可以将其视作同一种建模思想的两种不同实现形式。
四、CART 回归树的 Scikit-Learn 实现方法
1. CART 回归树的 sklearn 快速实现
- 接下来,我们尝试在 sklearn 中调用回归树评估器围绕上述数据集进行建模,并对上述过程进行简单验证。回归树也是在 tree 模块下,我们可以通过如下方式进行导入:
from sklearn.tree import DecisionTreeRegressor
- 然后进行模型训练:
clf = DecisionTreeRegressor().fit(data[:, 0].reshape(-1, 1), data[:, 1])
# 同样可以借助tree.plot_tree进行结果的可视化呈现plt.figure(figsize=(6, 2), dpi=150)
tree.plot_tree(clf)
#[Text(418.5, 188.75, 'X[0] <= 3.5\nmse = 3.76\nsamples = 5\nvalue = 3.8'),
# Text(279.0, 113.25, 'X[0] <= 1.5\nmse = 0.889\nsamples = 3\nvalue = 2.333'),
# Text(139.5, 37.75, 'mse = 0.0\nsamples = 1\nvalue = 1.0'),
# Text(418.5, 37.75, 'mse = 0.0\nsamples = 2\nvalue = 3.0'),
# Text(558.0, 113.25, 'mse = 0.0\nsamples = 2\nvalue = 6.0')]
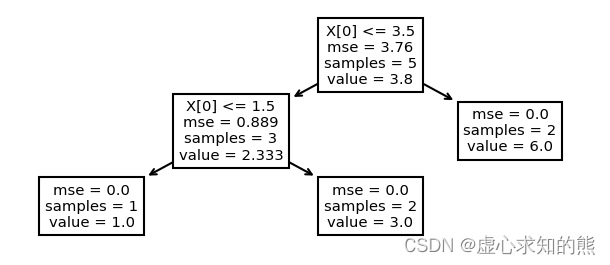
- 发现和我们手动实现过程一致。
2. CART 回归树评估器的参数解释
- 接下来,详细讨论关于 CART 回归树评估器中的相关参数。尽管 CART 回归树和分类树是由不同评估器实现相关过程,但由于两种模型基本理论一致,因此两种不同评估器的参数也大都一致。
DecisionTreeRegressor?
- 不难发现,其中大多数参数我们在 Lesson 8.2 中都进行了详细的讲解,此处重点讲解 criterion 参数取值。criterion 是备选划分规则的选取指标,对于 CART 分类树来说默认基尼系数、可选信息熵。
- 而对于 CART 回归树来说默认 mse,同时可选 mae 和 friedman_mse,同时在新版 sklearn 中,还加入了 poisson 作为可选参数取值。接下来我们就这几个参数不同取值进行介绍:
2.1 criterion=‘mse’ 情况
- 当 criterion 取值为 mse 时当然是计算误差平方和再除以样本总数,其基本计算流程与上述手动实现过程层类似。但有一点可能会对阅读源码的同学造成困扰,那就是在源码中子节点整体的 MSE 计算公式描述如下:

- 尽管上述公式看起来像是子节点的整体 MSE 就等于左右两个节点的方差只和,但实际上是经过加权之后的方差只和。我们可以通过在手动实现过程中灵活调整 min_impurity_decrease 参数来进行验证。
- 需要注意的是,CART 回归树的子节点整体 MSE 的计算方式是加权求和还是简单求和,不同的材料中有不同的描述,例如由 Aurélien Géron 等人所著《机器学习实战,基于 Scikit-Learn、Keras 和 TensorFlow 》一书中表示是通过加权求和方式算得,而在《统计学习方法》一书中则表示是根据子节点的 MSE 直接求和得到。
2.2 criterion=‘mae’ 情况
- 和 MSE 不同,MAE 实际上计算的是预测值和真实值的差值的绝对值再除以样本总数,即可以通过如下公式计算得出:MAE=1m∑i=1m∣(yi−y^i)∣MAE = \frac{1}{m}\sum^m_{i=1}|(y_i-\hat y _i)|MAE=m1i=1∑m∣(yi−y^i)∣
- 也就是说,MSE 是基于预测值和真实值之间的欧式距离进行的计算,而 MAE 则是基于二者的街道距离进行的计算,很多时候,MSE 也被称为 L2 损失,而 MAE 则被称为 L1 损失。
- 需要注意的是,当 criterion 取值为 mae 时,为了让每一次划分时子集内的 MAE 值最小,此时每个子集的模型预测值就不再是均值,而是中位数。
- 再次强调,CART 回归树的 criterion 不仅是划分方式挑选时的评估标准,同时也是划分子数据集后选取预测值的决定因素。
- 也就是说,对于回归树来说,criterion 的取值其实决定了两个方面,其一是决定了损失值的计算方式、其二是决定了每一个数据集的预测值的计算方式——数据集的预测值要求 criterion 取值最小,如果 criterion=mse,则数据集的预测值要求在当前数据情况下 mse 取值最小,此时应该以数据集的标签的均值作为预测值;而如果 criterion=mse,则数据集的预测值要求在当前数据情况下 mae 取值最小,此时应该以数据集标签的座位数作为预测值。
- 并且一般来说,如果希望模型对极端值(非常大或者非常小的值,也被称为离群值)的忍耐程度比较高,整体建模过程不受极端值影响,可以考虑使用 mae 参数(就类似于中位数会更少的受到极端值的影响),此时模型一般不会为极端值单独设置规则。
- 而如果希望模型具备较好的识别极端值的能力,则可以考虑使用 mse 参数,此时模型会更大程度受到极端值影响(就类似于均值更容易受到极端值影响),更大概率会围绕极端值单独设置规则,从而帮助建模者对极端值进行识别。
2.3 criterion=‘friedman_mse’ 情况
- friedman_mse 是一种基于 mse 的改进型指标,是由 GBDT(梯度提升树,一种集成算法)的提出者 friedman 所设计的一种残差计算方法,是 sklearn 中树梯度提树默认的 criterion 取值,对于单独的树决策树模型一般不推荐使用。
- 关于 friedman_mse 的计算方法我们将在集成算法中进行详细介绍。
相关文章:
Lesson 8.3 ID3、C4.5 决策树的建模流程 Lesson 8.4 CART 回归树的建模流程与 sklearn 参数详解
文章目录一、ID3 决策树的基本建模流程二、C4.5 决策树的基本建模流程1. 信息值(information value)2. C4.5 的连续变量处理方法三、CART 回归树的基本建模流程1. 数据准备2. 生成备选规则3. 挑选规则4. 进行多轮迭代5. 回归树的预测过程四、CART 回归树…...

阿里云手机短信登录
阿里云短信服务介绍阿里云短信服务(Short Message Service)是广大企业客户快速触达手机用户所优选使用的通信能力。调用API或用群发助手,即可发送验证码、通知类和营销类短信;国内验证短信秒级触达,到达率最高可达99%&…...
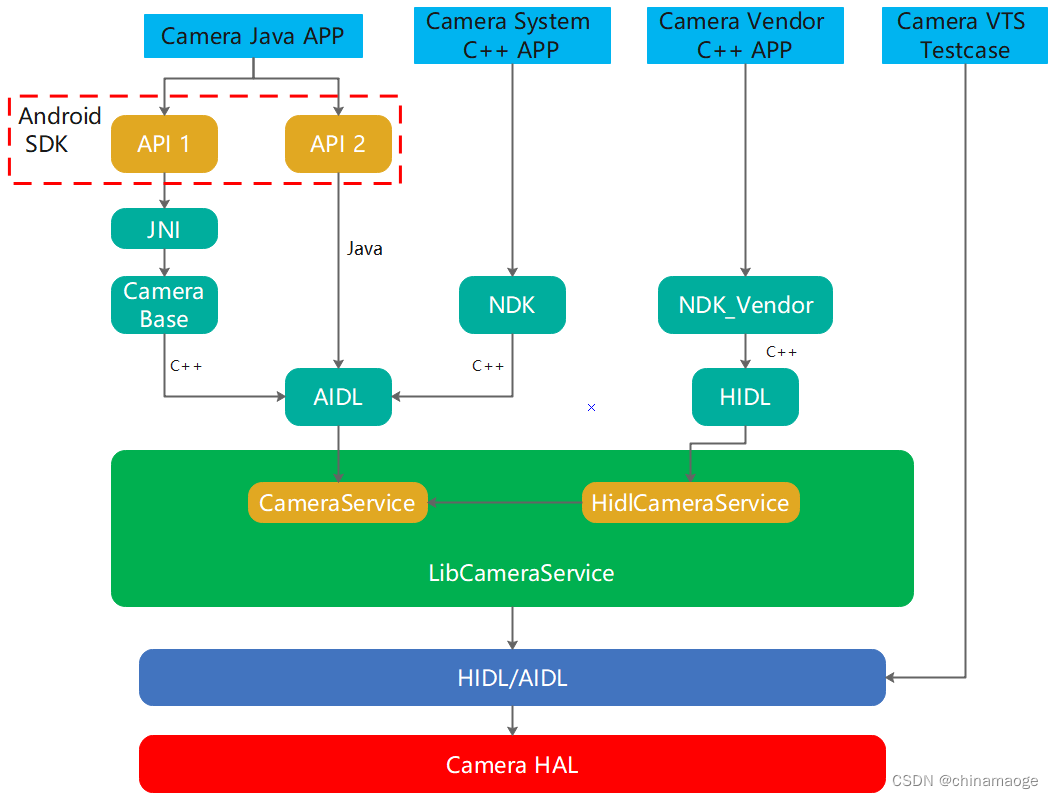
Android Camera SDK NDK NDK_vendor介绍
Android Camera JNI NDK NDK_vendor介绍前言主要有哪几种interface?Android SDKCamera API 1Camera API 2小结Android NDKNDK InterfaceNDK Vendor Interface小结Camera VTS Testcase总结Reference前言 本篇博客是想介绍Android camera从application layer到camera…...

SQL基础语句小结
🍎道阻且长,行则将至。🍓 目录 一、SQL概述 1.简介 2.格式语法 3.SQL分类 二、DDL操作数据库 1.创建数据库 2.查询与使用 3.删除数据库 三、DDL:操作表 (1)数据类型 (2)创建表 (3)查询当前数据库的表 (4)删除表 (5)修改表 四、DML…...

管理类书籍推荐
管理类书籍对于每一位想要获得管理能力提升或者实现职业生涯更上一层楼的企业管理者或领导者而言,都是不可或缺的一项重要学习工具。作为管理工作从事者的职场必需品,一本出色的管理类书籍可以为我们提供大量宝贵的经验与专业建议,从而让管理…...
win10 mingw 调用python
ubuntu调用pythonhttps://blog.csdn.net/qq_39942341/article/details/129333969 我这里mingw是用msys2的 opencv也是msys2装的 安装msys2和opencv可以参考这个https://blog.csdn.net/qq_39942341/article/details/129380197?spm1001.2014.3001.5502 环境变量里加入python路…...

教你使用三种方式写一个最基本的spark程序
当需要处理大规模数据并且需要进行复杂的数据处理时,通常会使用Hadoop生态系统中的Hive和Spark来完成任务。在下面的例子中,我将说明如何使用Spark编写一个程序来处理Hive中的数据,以满足某个特定需求。假设我们有一个Hive表,其中…...

软件设计师错题集
软件设计师错题集一、计算机组成与体系结构1.1 浮点数1.2 Flynn分类法1.3 指令流水线1.4 层次化存储体系1.4.1 程序的局限性1.5 Cache1.6 输入输出技术1.7 总线系统1.8 CRC循环冗余校验码二、数据结构与算法基础2.1 队列与栈2.2 树与二叉树的特殊性2.3 最优二叉树(哈…...
【华为机试真题详解 Python实现】静态扫描最优成本【2023 Q1 | 100分】
文章目录前言题目描述输入描述输出描述示例 1输入:输出:示例 2输入:输出:题目解析参考代码前言 《华为机试真题详解》专栏含牛客网华为专栏、华为面经试题、华为OD机试真题。 如果您在准备华为的面试,期间有想了解的…...
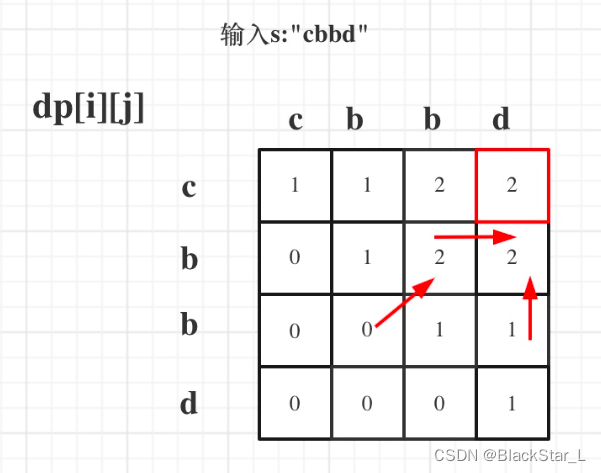
算法刷题总结 (四) 动态规划
算法总结4 动态规划一、动态规划1.1、基础问题11.1.1、509. 斐波那契数列1.1.2、70. 爬楼梯1.1.3、746. 使用最小花费爬楼梯1.2、基础问题21.2.1、62. 不同路径1.2.2、63. 不同路径Ⅱ1.2.3、343. 整数拆分1.2.4、96. 不同的二叉搜索树1.3、背包问题1.3.1、01背包1.3.1.1、单次选…...

Grafana 转换数据的工具介绍
转换数据 Grafana 可以在数据显示到面板前对数据进行处理 1、点击Transform选项卡 2、选择要使用的转换类型,不同的转换类型配置不同 3、要新增转换类型,点击Add transformation 4、使用右上角调式按钮可以调式转换 支持的转换类型: Add f…...

Linux 学习笔记
一、 概述 1. 操作系统 ① 计算机由硬件和软件组成 ② 操作系统属于软件范畴,主要作用是协助用户调度硬件工作,充当用户和计算机硬件之间的桥梁 ③ 常见的操作系统 🤠 PC端:Windows、Linux、MacOS🤠 移动端&#…...

HTML注入专精整理
目录 HTML注入介绍 抽象解释 HTML注入的影响 HTML注入与XSS的区别 HTML元素流程图...
看完这篇我不信你不会二叉树的层序遍历【C语言】
目录 实现思路 代码实现 之前介绍了二叉树的前、中、后序三种遍历,采用的是递归的方式。今天我们来学习另外一种遍历方式——层序遍历。层序遍历不容小觑,虽然实现方法并不难,但是它所采取的思路是很值得学习的,与前三者不同&am…...
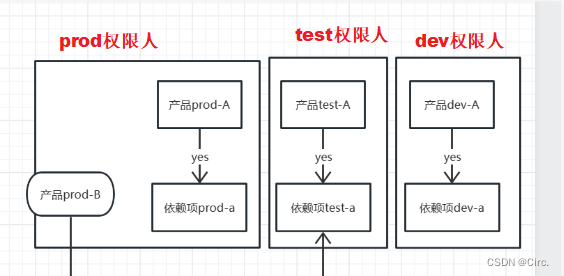
案例17-环境混用带来的影响
目录一、背景介绍背景事故二、思路&方案三、过程四、总结nginx做转发fastdfs(文件上传下载)五、升华一、背景介绍 本篇博客主要介绍开发中项目使用依赖项环境闭一只带来的恶劣影响,在错误中成长进步。 背景 本公司另外一个产品开发God…...

知识蒸馏论文阅读:DKD算法笔记
标题:Decoupled Knowledge Distillation 会议:CVPR2022 论文地址:https://ieeexplore.ieee.org/document/9879819/ 官方代码:https://github.com/megvii-research/mdistiller 作者单位:旷视科技、早稻田大学、清华大学…...
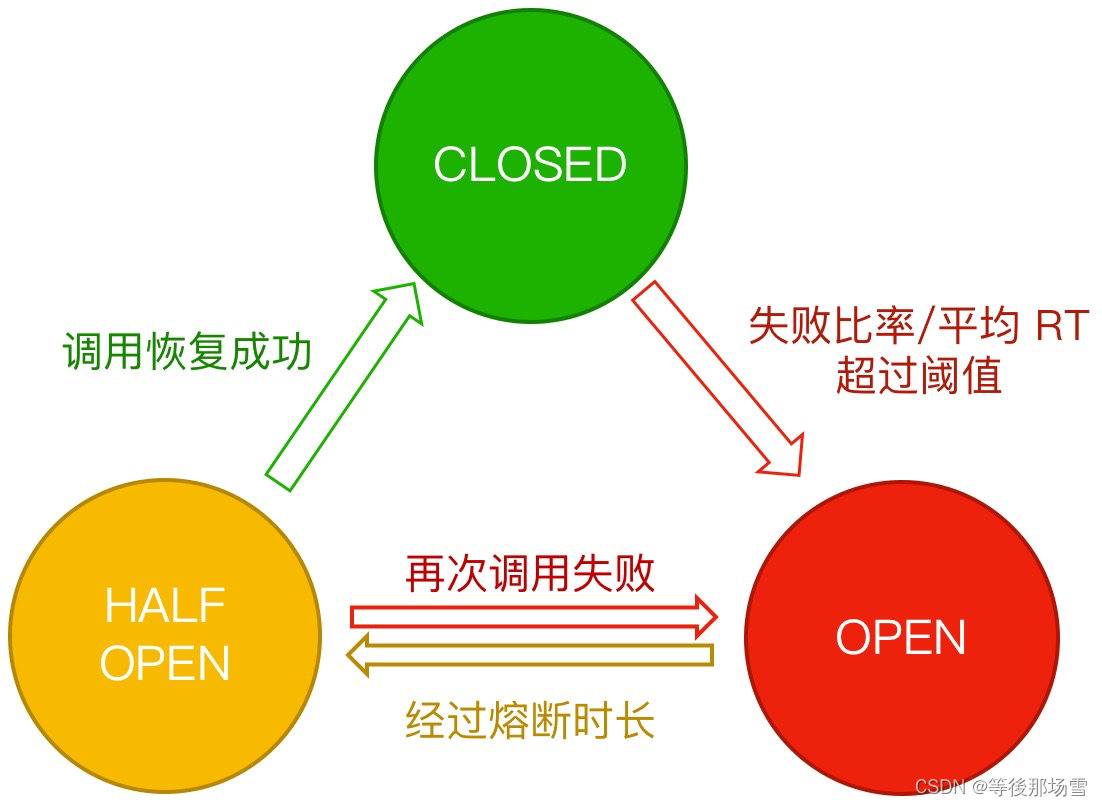
Sentinel架构篇 - 熔断降级
熔断降级 概念 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用其它模块,可能是一个远程服务、数据库、或者第三方 API 等。然而,被依赖的服务的稳定性是不能保证的。如果依赖的服…...

shell脚本的一些记录 与jenkins的介绍
shell 脚本的执行 sh ***.sh shell脚本里面的命令 其实就是终端执行一些命令 shell 连接服务器 可以直接ssh连接 但是这样最好是无密码的 不然后面的命令就不好写了 换而言之有密码得 不好写脚本 需要下载一些expect的插件之类的才可以 判断语句 的示例 需要注意的是…...

JVM的了解与学习
一:jvm是什么 jvm是java虚拟机java Virtual Machine的缩写 jdk包含jre和java DevelopmentTools 二:什么是java虚拟机 虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。java虚拟机有自己完善的硬体结构,如处理器、堆栈、寄存器等,还有…...

提升数字品牌的5个技巧
“品牌”或“品牌推广”的概念通常用于营销。因为建立您的企业品牌对于产品来说极其重要,品牌代表了您与客户互动的身份和声音。今天,让我们来看看在数字领域提升品牌的一些有用的技巧。如何在数字领域提升您的品牌?在了解这些技巧之前&#…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...