Boosting三巨头:XGBoost、LightGBM和CatBoost(发展、原理、区别和联系,附代码和案例)

Boosting三巨头:XGBoost、LightGBM和CatBoost(发展、原理、区别和联系,附代码和案例)
机器学习中,提高模型精度是研究的重点之一,而模型融合技术中,Boosting算法是一种常用的方法。在Boosting算法中,XGBoost、LightGBM和CatBoost是三个最为流行的框架。它们在实际使用中有各自的优势和适用场景,下面将会介绍它们的区别与联系。
1. 算法原理
1.1 XGBoost
XGBoost是由陈天奇等人提出的一个优化的Gradient Boosting算法,以其出色的表现和可扩展性而受到广泛关注。XGBoost使用了C++实现,可以运行在多个平台上,并支持多种编程语言,如Python、R、Java等。其原理可以概括为将弱学习器依次加入到一个全局的加权模型中,每一轮迭代都在损失函数的梯度方向上优化模型。它在原有GBDT的基础上,添加了正则化项和缺失值处理,使得模型更加稳定和准确。其原理如下:
首先,假设有n个训练样本(xi,yi)(x_{i}, y_{i})(xi,yi),其中xix_{i}xi为输入特征,yiy_{i}yi为输出值。那么,目标就是找到一个函数f(x),使得f(x)f(x)f(x)可以预测yyy的值。
其次,定义损失函数L(y,f(x))L(y, f(x))L(y,f(x)),用来度量f(x)f(x)f(x)的预测值与实际值之间的误差。
再次,我们使用Boosting算法来不断迭代提高模型精度。假设现在已经有了一个弱分类器fm−1(x)f_{m-1}(x)fm−1(x),那么我们希望找到一个新的弱分类器fm(x)f_{m}(x)fm(x)来减少L(y,f(x))L(y, f(x))L(y,f(x))的值。于是我们在已有的弱分类器fm−1(x)f_{m-1}(x)fm−1(x)基础上,加上一个新的弱分类器fm(x)f_{m}(x)fm(x),最终得到新的分类器fm(x)=fm−1(x)+γhm(x)f_{m}(x)=f_{m-1}(x)+\gamma h_{m}(x)fm(x)=fm−1(x)+γhm(x),其中γ\gammaγ为学习率,hm(x)h_{m}(x)hm(x)为新的弱分类器。
最后,由于XGBoost使用了正则化项来控制模型的复杂度,并采用了特殊的梯度下降方法进行训练,使得其在处理高维稀疏数据时,具有较好的效果。
1.2 LightGBM
LightGBM是由微软提出的一种基于Histogram算法的Gradient Boosting框架。它通过对样本特征值进行离散化,将连续特征离散化为有限个整数,从而将高维稀疏数据转化为低维稠密数据,从而加速了训练速度。相比XGBoost,LightGBM的最大优势在于其快速的训练速度和较小的内存占用,这主要得益于其采用了基于直方图的决策树算法和局部优化等技术。LightGBM的核心思想是在构造决策树时,将连续特征离散化为若干个桶,然后将每个桶作为一个离散特征对待,从而加速树的构建和训练过程。其原理如下:
首先,对于每个特征,我们需要将其离散化为一些桶,每个桶中包含一些连续的特征值。在训练时,我们只需要计算每个桶中的样本的统计信息(如平均值和方差),而不需要计算每个样本的特征值,从而减少了计算量。
其次,对于每个样本,我们根据离散化后的特征值,将其归入对应的桶中,然后计算桶中样本的统计信息。接着,我们通过梯度单边采样(GOSS)算法,选择一部分样本进行训练,这些样本中包含了大部分的梯度信息,从而保证了训练的准确性和效率。
最后,LightGBM还使用了基于直方图的决策树算法,使得在处理高维稀疏数据时,具有较好的效果。
1.3 CatBoost
CatBoost是由Yandex提出的一种基于梯度提升算法的开源机器学习框架。它在处理分类问题时,可以自动处理类别特征,无需手动进行特征编码。CatBoost的原理与XGBoost和LightGBM类似,同样是通过将多个弱学习器组合成一个强学习器。不同之处在于,CatBoost使用了一种新的损失函数,即加权交叉熵损失函数,可以有效地处理类别不平衡问题。其原理如下:
首先,CatBoost使用了一种称为Ordered Boosting的算法来提高模型精度。Ordered Boosting可以看做是一种特殊的特征选择方法,它将训练样本按照特征值大小排序,然后使用分段线性模型拟合每一段特征值的梯度,从而提高了模型的拟合能力。
其次,CatBoost在处理分类问题时,可以自动处理类别特征。它使用了一种称为Target Encoding的方法,将类别特征转化为一组实数值,从而避免了手动进行特征编码的麻烦。
最后,CatBoost还使用了基于对称树的决策树算法,使得在处理高维稀疏数据时,具有较好的效果。
2. 发展前景和应用场景
XGBoost、LightGBM和CatBoost作为目前最先进的梯度提升算法,在许多数据科学竞赛和实际应用中都取得了很好的效果。随着大数据时代的到来,这三种算法的应用场景也越来越广泛。
其中,XGBoost在传统机器学习领域仍然是最常用的算法之一,特别是在结构化数据的分类、回归和排序任务中表现突出。LightGBM在大规模数据集和高维度数据上表现更佳,适用于处理文本分类、图像分类、推荐系统等领域的数据。CatBoost在处理类别特征和缺失值方面表现出色,适用于电商推荐、医疗预测、金融风控等领域的数据。
总的来说,XGBoost、LightGBM和CatBoost作为梯度提升算法的代表,都具有自身的优势和适用场景,随着数据和计算能力的不断提升,它们的应用前景也会越来越广阔。
3. 使用案例
3.1 XGBoost
XGBoost可以应用于多种场景,如回归、分类、排序等。下面以Kaggle竞赛中的房价预测问题为例,展示如何使用XGBoost进行模型训练和预测。
首先,我们使用Pandas读取数据集,并将其划分为训练集和测试集。
import pandas as pd
from sklearn.model_selection import train_test_splitdf = pd.read_csv('train.csv')
X = df.drop('SalePrice', axis=1)
y = df['SalePrice']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接着,我们使用XGBoost的Python接口进行模型训练和预测。
import xgboost as xgb
from sklearn.metrics import mean_squared_errordtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)params = {'max_depth': 3, 'learning_rate': 0.1, 'objective': 'reg:squarederror'}
num_rounds = 100model = xgb.train(params, dtrain, num_rounds)
y_pred = model.predict(dtest)mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
上述代码中,我们首先使用xgb.DMatrix将训练数据转化为DMatrix格式。接着,我们定义了模型参数,并设置了迭代次数为100。然后,我们使用xgb.train函数进行模型训练,并使用model.predict函数进行模型预测。最后,我们使用sklearn.metrics.mean_squared_error函数计算了模型的均方误差。
3.2 LightGBM
LightGBM可以应用于多种场景,如回归、分类、排序等。下面以Kaggle竞赛中的鸢尾花分类问题为例,展示如何使用LightGBM进行模型训练和预测。
首先,我们使用Pandas读取数据集,并将其划分为训练集和测试集。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitdata = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.targetX = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接着,我们使用LightGBM的Python接口进行模型训练和预测。
import lightgbm as lgb
from sklearn.metrics import accuracy_scoredtrain = lgb.Dataset(X_train, label=y_train)
dtest = lgb.Dataset(X_test, label=y_test)params = {'objective': 'multiclass', 'num_class': 3, 'metric': 'multi_logloss'}
num_rounds = 100model = lgb.train(params, dtrain, num_rounds)
y_pred = model.predict(X_test)y_pred = [list(x).index(max(x)) for x in y_pred]
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
上述代码中,我们首先使用lgb.Dataset将训练数据转化为Dataset格式。接着,我们定义了模型参数,并设置了迭代次数为100。然后,我们使用lgb.train函数进行模型训练,并使用model.predict函数进行模型预测。最后,我们使用sklearn.metrics.accuracy_score函数计算了模型的准确率。
3.3 CatBoost
import catboost as cb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreiris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)train_data = cb.Pool(X_train, label=y_train)
test_data = cb.Pool(X_test, label=y_test)params = {'loss_function': 'MultiClass', 'num_class': 3, 'eval_metric': 'Accuracy'}num_rounds = 20
bst = cb.train(params, train_data, num_rounds)preds = bst.predict(X_test)
y_pred = [np.argmax(pred) for pred in preds]acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)
综合展示
为了更好地展示XGBoost、LightGBM和CatBoost的应用场景和效果,我们以波士顿房价预测数据集为例进行实验。
首先,我们使用sklearn库中的load_boston函数加载数据集,并对数据进行划分,80%用于训练,20%用于测试。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_splitdata = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
然后,我们依次使用XGBoost、LightGBM和CatBoost训练模型,并对模型进行评估。
import xgboost as xgb
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error# XGBoost
xgb_model = xgb.XGBRegressor(n_estimators=100, max_depth=5, learning_rate=0.1, random_state=42)
xgb_model.fit(X_train, y_train)
xgb_pred = xgb_model.predict(X_test)
xgb_rmse = mean_squared_error(y_test, xgb_pred, squared=False)# LightGBM
lgb_model = LGBMRegressor(n_estimators=100, max_depth=5, learning_rate=0.1, random_state=42)
lgb_model.fit(X_train, y_train)
lgb_pred = lgb_model.predict(X_test)
lgb_rmse = mean_squared_error(y_test, lgb_pred, squared=False)# CatBoost
cat_model = CatBoostRegressor(n_estimators=100, max_depth=5, learning_rate=0.1, random_seed=42, silent=True)
cat_model.fit(X_train, y_train)
cat_pred = cat_model.predict(X_test)
cat_rmse = mean_squared_error(y_test, cat_pred, squared=False)print("XGBoost RMSE: {:.2f}".format(xgb_rmse))
print("LightGBM RMSE: {:.2f}".format(lgb_rmse))
print("CatBoost RMSE: {:.2f}".format(cat_rmse))
参考文献
[1] Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[2] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., … & Liu,
G. (2017). Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems (pp. 3146-3154).
[3] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: unbiased boosting with categorical features. In Advances in neural information processing systems (pp. 6638-6648).
[4] XGBoost官方文档:https://xgboost.readthedocs.io/en/latest/
[5] LightGBM官方文档:https://lightgbm.readthedocs.io/en/latest/
[6] CatBoost官方文档:https://catboost.ai/docs/
[7] 《Python机器学习基础教程》(吴斌):介绍了XGBoost、LightGBM和CatBoost的使用方法和实例。
[8] 《Applied Machine Learning》(Kelleher, John D.):介绍了各种机器学习算法,其中也包括了梯度提升算法和其变种。
[9] 《Hands-On Gradient Boosting with XGBoost and scikit-learn》(Villalba, Benjamin):详细介绍了XGBoost和scikit-learn库的梯度提升实现。
[10] 《Gradient Boosting》(Friedman, Jerome H.):介绍了梯度提升算法的基本思想和实现原理。
相关文章:
Boosting三巨头:XGBoost、LightGBM和CatBoost(发展、原理、区别和联系,附代码和案例)
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
-10)
设计模式~模板方法模式(Template method)-10
目录 (1)优点: (2)缺点: (3)使用场景: (4)注意事项: (5)应用实例: (6)Servlet Api & Spring 中的应用 代码 (钩子函数)在模板模式(Template Pattern)中,一个抽象类公开定…...

【WebSocket】在SSM项目中配置websocket
在SSM项目中配置websocket 最近在ssm项目中配置了websocket,踩了很多坑,来分享一下 本文暂不提供发送消息等内容的代码逻辑(后续也许会补充),如果你直接复制这类可能会对配置造成更大的麻烦(博主就是复制…...

node-red中创建自定义节点 JavaScript 文件API编写详解
前言 在node-red中如果你没有找到自己需要的节点时,那么你可以自定义一个节点来满足自己的需求。之前的文章中,我有简单介绍过如何创建一个节点,并以转换大小写来举例。例子虽然简单,但可以让大家了解创建自定义节点的步骤以及一个节点的组成部分。那么本篇将会聚焦在自定…...
【独家】)
华为OD机试 - 寻找路径 or 数组二叉树(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:寻找路径…...

YOLOv7、YOLOv5改进之打印热力图可视化:适用于自定义模型,丰富实验数据
💡该教程为改进YOLO高阶指南,属于《芒果书》📚系列,包含大量的原创改进方式🚀 💡更多改进内容📚可以点击查看:YOLOv5改进、YOLOv7改进、YOLOv8改进、YOLOX改进原创目录 | 唐宇迪老师联袂推荐🏆 💡🚀🚀🚀内含改进源代码 按步骤操作运行改进后的代码即可�…...

【Java代码与架构之完美优化】篇1:代码质量优化通用准则
工欲善其事,必先利其器 1. 避免使用空块 常见空块一般有以下几种情况: 多余的分号:if(xxx);多余的大括号:if(xxx){这里没有内容}空finall语句:try{...}catch(...){...}finally{这里没有内容} 空块的存在࿰…...

Linux进程间通信详解(最全)
进程间的五种通信方式介绍 进程间通信(IPC,InterProcess Communication)是指在不同进程之间传播或交换信息。IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享内存、Socket(套接字&a…...

ROS 摄像头的使用
参考: youtubeArticulated Robotics 作者Josh Newans博客 建议: 这个只是我的看法,强烈建议看原视频或博客 png:无损压缩 jpeg:有损压缩 Driver Node 负责连接硬件设备,读取摄像头数据"ima…...

VR全景云展厅,实现7*24小时的线上宣传能力!
数字化时代,虚拟现实技术的应用越来越广泛,其中VR全景云展厅是一种新兴的展示方式,具有独特的展示优势。随着VR技术的不断发展,越来越多的企业、机构和个人开始使用VR全景云展厅来展示他们的产品和服务。一、展厅营销痛点1、实地到…...
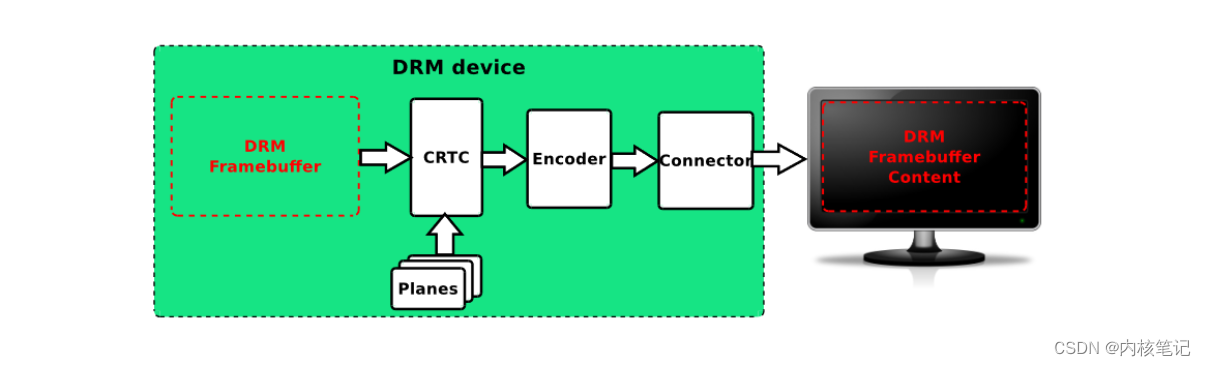
RK3568平台开发系列讲解(显示篇) DRM显示系统组成分析
🚀返回专栏总目录 文章目录 一、DRM Framebuffer二、CRTC三、Planes四、Encoder五、Connector沉淀、分享、成长,让自己和他人都能有所收获!😄 📢让我们分析一下绿框中的五个部件,以及他们的联动。 一、DRM Framebuffer 与 framebuffer一样,是一片存放图像的内存区域,…...
WPF DataGrid控件的使用 使用列模板来进行数据格式的美化
<Grid><Grid.RowDefinitions><RowDefinition Height"0.1*" /><RowDefinition /></Grid.RowDefinitions><Button Content"刷新"FontSize"25"Command"{Binding ExecuteRefreshCommand}" /><Dat…...
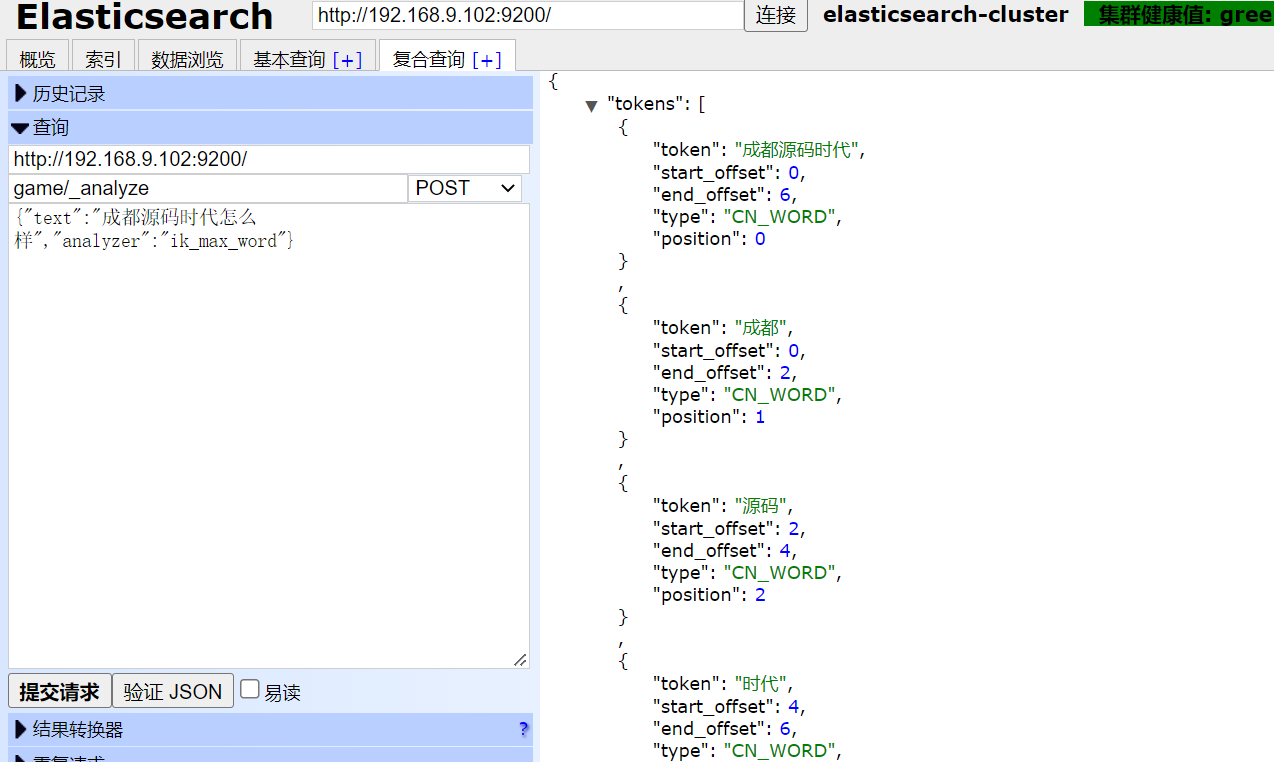
elasticsearch自定义企业词典
我们中文分词用的是ik,但是ik只是对基本的中文词进行了分词,而对于企业或者人名没有进行分词。比如,我搜索中国平安,那么ik只能分成中国、平安如果这样,这肯定是不行滴!接下来,俺就教你…...

【AcWing】学了一坤时才明白的一道题
🎆音乐分享 (点击链接可以听哦) The Right Path - Thomas Greenberg 这道题小吉花了一坤时才弄明白,虽然花的时间有点长 但是至少是明白了 😎😎😎😎😎😎 …...

ES6的export和import
ES6中的模块加载ES6 模块是编译时加载,编译时就能确定模块的依赖关系,以及输入和输出的变量,相比于CommonJS 和 AMD 模块都只能在运行时确定输入输出变量的加载效率要高。严格模式ES6 的模块自动采用严格模式,不管你有没有在模块头…...
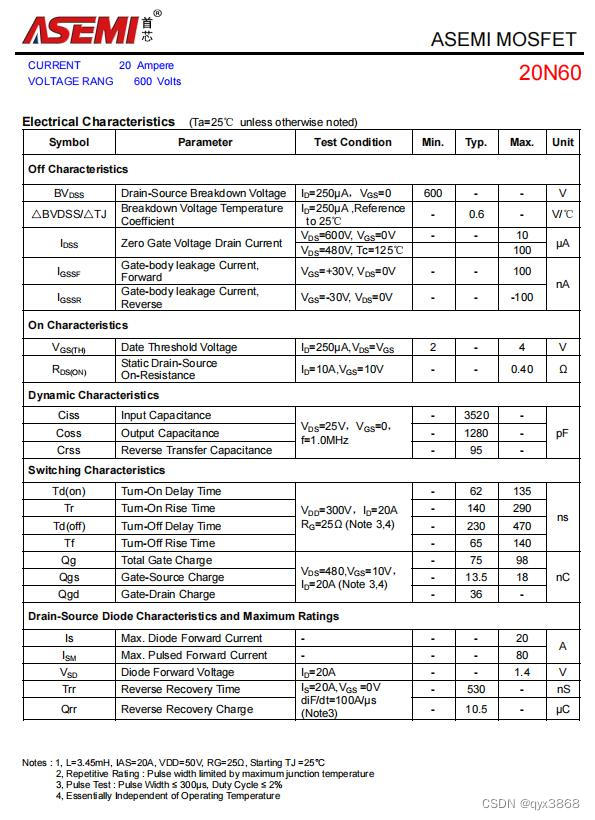
ASEMI高压MOS管20N60参数,20N60尺寸,20N60体积
编辑-Z ASEMI高压MOS管20N60参数: 型号:20N60 漏极-源极电压(VDS):600V 栅源电压(VGS):30V 漏极电流(ID):20A 功耗(PDÿ…...
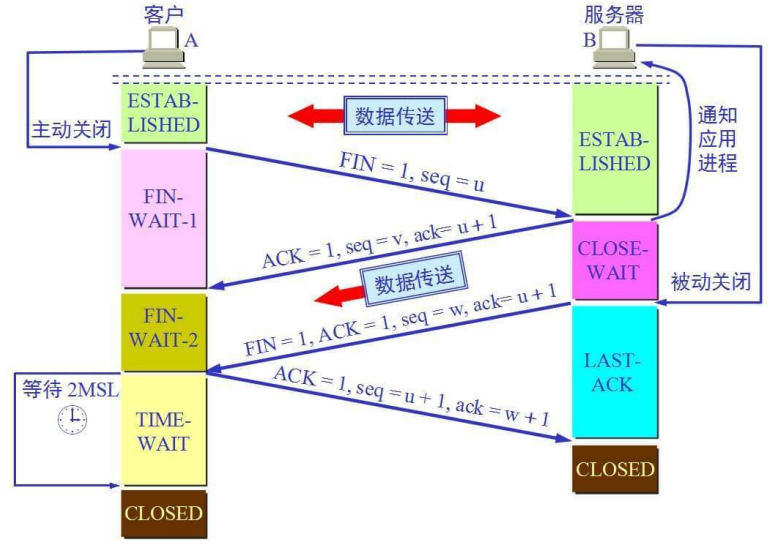
【备战面试】TCP的三次握手与四次挥手
本篇总结的是计算机网络知识相关的面试题,后续也会更新其他相关内容 文章目录1、TCP头部结构2、三次握手3、四次挥手4、为什么TCP连接的时候是三次?两次是否可以?5、为什么TCP连接的时候是三次,关闭的时候却是四次?6、…...
【模板进阶】
目录 1. 非类型模板参数 2. 模板的特化 2.1 概念 2.2 函数模板特化 2.3 类模板特化 2.3.1 全特化 3 模板分离编译 3.1 什么是分离编译 3.2 模板的分离编译 4. 模板总结 有需要的老哥可以先看看模板的介绍:http://t.csdn.cn/2TkUYhttp://t.csdn.cn/2TkUY 1. …...

Tech Talk | 电致变色技术带来的智能AR体验
2023年2月27日,小米在2023MWC世界移动通信大会上,正式发布了小米无线AR眼镜探索版。这款产品搭载了创新的数控电致变色镜片,能适应不同光环境,遮光模式可以在观影时更沉浸,通透模式又能让AR虚实结合的体验更生动。“ 本…...
ACWING蓝桥杯每日一题python(持续更新
ACWing蓝桥杯每日一题 一直没时间去总结算法,终于有空可以总结一下刷的acwing了,因为没时间所以最近只刷了ACWING的蓝桥杯每日一题。。。真是该死 1.截断数组 首先我们要知道,如果sum(a)不能被3整除或者len(a) < 3 ,那么他肯…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...