使用Tensorflow完成一个简单的手写数字识别
Tensorflow中文手册
介绍TensorFlow_w3cschool
模型结构图:
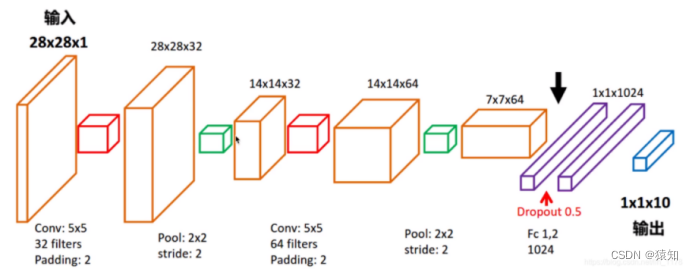
首先明确模型的输入及输出(先不考虑batch)
输入:一张手写数字图(28x28x1像素矩阵) 1是通道数
输出:预测的数字(1x10的one-hot向量)
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程,比如
输出[0,0,0,0,0,0,0,0,1,0]代表数字“8”
各层的维度说明(先不考虑batch)
输入层(28 x28 x1)
卷积层1的输出(28x28x32)(32 filters)
pooling层1的输出(14x14x32)
卷积层2的输出(14x14x64)(64 filters)
pooling层2的输出(7x7x64)
全连接层1的输出(1x1024)
全连接层2 含softmax的输出(1x10)
注意,训练时采用batch,只是加了一个维度而已,比如(28x28x1)→(100x28x28x1) batch=100
详细代码讲解
下载mnist手写数字图片数据集:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
若报错可自行前往
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
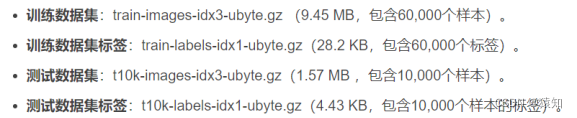
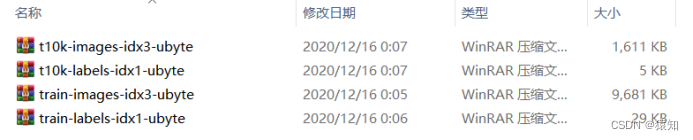
下载(或者其他地址),只要将四个压缩文件都放进MNIST_data文件夹即可,包含了四个部分:
Tensorflow读取的mnist的数据形式(Datasets)
原训练集分出了5000作为验证集(实验中未使用)
训练集(train\0)的数量:55000
验证集(validation\1)的数量:5000
测试集(test\2)的数量:10000


补充:可视化train数据集图片
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
train_img = mnist.train.images
train_label = mnist.train.labels
for i in range(5):
img = np.reshape(train_img[i, :], (28, 28))
label = np.argmax(train_label[i, :])
plt.matshow(img, cmap = plt.get_cmap('gray'))
plt.title('第%d张图片 标签为%d' %(i+1,label))
plt.show()

卷积层1代码:
## conv1 layer 含pool ##
W_conv1 = weight_variable([5, 5, 1, 32])
# 初始化W_conv1为[5,5,1,32]的张量tensor,表示卷积核大小为5*5,1表示图像通道数(输入),32表示卷积核个数即输出32个特征图(即下一层的输入通道数)
# 张量说明:
# 3 这个 0 阶张量就是标量,shape=[]
# [1., 2., 3.] 这个 1 阶张量就是向量,shape=[3]
# [[1., 2., 3.], [4., 5., 6.]] 这个 2 阶张量就是二维数组,shape=[2, 3]
# [[[1., 2., 3.]], [[7., 8., 9.]]] 这个 3 阶张量就是三维数组,shape=[2, 1, 3]
# 即有几层中括号
b_conv1 = bias_variable([32])
# 偏置项,参与conv2d中的加法,维度会自动扩展到28x28x32(广播)
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# output size 28x28x32
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32 卷积操作使用padding保持维度不变,只靠pool降维
其中:
xs = tf.placeholder(tf.float32, [None, 784], name='x_input')
ys = tf.placeholder(tf.float32, [None, 10], name='y_input')
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# 创建两个占位符,xs为输入网络的图像,ys为输入网络的图像标签
# 输入xs(二维张量,shape为[batch, 784])变成4d的x_image,x_image的shape应该是[batch,28,28,1],第四维是通道数1
# -1表示自动推测这个维度的size
# reshape成了conv2d需要的输入形式;若是直接进入全连接层,则没必要reshape
——————————————以上使用到的函数的定义——————————————
注意:tensorflow的变量必须定义为tf.Variable类型
def weight_variable(shape):
# tf.truncated_normal从截断的正态分布中输出随机值.
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 卷积核移动步长为1,填充padding类型为SAME,可以不丢弃任何像素点, VALID丢弃边缘像素点
# 计算给定的4-D input和filter张量的2-D卷积
# input shape [batch, in_height, in_width, in_channels]
# filter shape [filter_height, filter_width, in_channels, out_channels]
# stride对应在这四维上的步长,默认[1,x,y,1]
def max_pool_2x2(x):
# 采用最大池化,也就是取窗口中的最大值作为结果
# x 是一个4维张量,shape为[batch,height,width,channels]
# ksize表示pool窗口大小为2x2,也就是高2,宽2
# strides,表示在height和width维度上的步长都为2
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
———————————————————————————————————————
卷积层2代码:
## conv2 layer 含pool##
W_conv2 = weight_variable([5, 5, 32, 64]) # 同conv1,不过卷积核数增为64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2)
# output size 7x7x64
全连接层1代码:
## fc1 layer ##
# 含1024个神经元,初始化(3136,1024)的tensor
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
# 将conv2的输出reshape成[batch, 7*7*16]的张量,方便全连接层处理
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
其中:
xs = tf.placeholder(tf.float32, [None, 784], name='x_input')
ys = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1])
keep_prob_rate = 0.5
# 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
# 在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
# 神经元按1-keep_prob概率置0,否则以1/keep_prob的比例缩放该元(并非保持不变)
# 这是为了保证神经元输出激活值的期望值与不使用dropout时一致,结合概率论的知识来具体看一下:假设一个神经元的输出激活值为a,在不使用dropout的情况下,其输出期望值为a,如果使用了dropout,神经元就可能有保留和关闭两种状态,把它看作一个离散型随机变量,符合概率论中的0-1分布,其输出激活值的期望变为 p*a+(1-p)*0=pa,为了保持测试集与训练集神经元输出的分布一致,可以在训练时除以此系数或者测试时乘以此系数,或者在测试时乘以该系数
全连接层2代码:
## fc2 layer 含softmax层##
# 含10个神经元,初始化(1024,10)的tensor
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 交叉熵函数
![]()
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
补充tf.reduce_mean

计算张量的(各个维度上)元素的平均值,例如
x = tf.constant([[1., 1.], [2., 2.]])
tf.reduce_mean(x) # 1.5
tf.reduce_mean(x, 0) # [1.5, 1.5]
tf.reduce_mean(x, 1) # [1., 2.]T
0代表输出是个行向量,那么就是各行每个维度取mean
# 使用ADAM优化器来做梯度下降,学习率learning_rate=0.0001
learning_rate = 1e-4
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
# 模型训练后,计算测试集准确率
def compute_accuracy(v_xs, v_ys):
global prediction
# y_pre将v_xs(test)输入模型后得到的预测值 (10000,10)
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
# argmax(axis) axis = 1 返回结果为:数组中每一行最大值所在“列”索引值
# tf.equal返回布尔值,correct_prediction (10000,1)
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
# tf.cast将bool转成float32, tf.reduce_mean求均值,作为accuracy值(0到1)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
TensorFlow 程序通常被组织成一个构建阶段(graph)和一个执行阶段.
上述阶段就是构建阶段,现在进入执行阶段,反复执行图中的训练操作,首先需要创建一个Session对象,如
sess = tf.Session() ****** sess.close()
Session对象在使用完后需要关闭以释放资源. 除了显式调用 close 外, 也可以使用 "with" 代码块 来自动完成关闭动作,如下
with tf.Session() as sess:
# 初始化图中所有Variables
init = tf.global_variables_initializer()
sess.run(init)
# 总迭代次数(batch)为max_epoch=1000,每次取100张图做batch梯度下降
for i in range(max_epoch):
# mnist.train.next_batch 默认shuffle=True,随机读取,batch大小为100
batch_xs, batch_ys = mnist.train.next_batch(100)
# 此batch是个2维tuple,batch[0]是(100,784)的样本数据数组,batch[1]是(100,10)的样本标签数组,分别赋值给batch_xs, batch_ys
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob})
# 暂时不进行赋值的元素叫占位符(如xs、ys),run需要它们时得赋值,feed_dict就是用来赋值的,格式为字典型
if (i+1) % 50 == 0:
print("step %d, test accuracy %g" % (i+1, compute_accuracy(
mnist.test.images, mnist.test.labels)))
利用自带的tensorboard可视化模型(深入理解图的概念)
tensorboard支持8种可视化,也就是上图中的8个选项卡,它们分别是:

tensorboard通过运行一个本地服务器,监听6006端口,在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的数据曲线、图像。
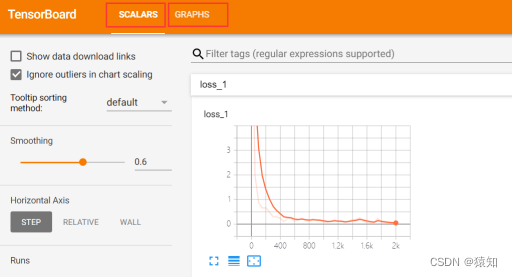

以可视化loss(scalars)、graphs为例:
为了在graphs中展示节点名称,在设计网络时可用with tf.name_scope()限定命名空间
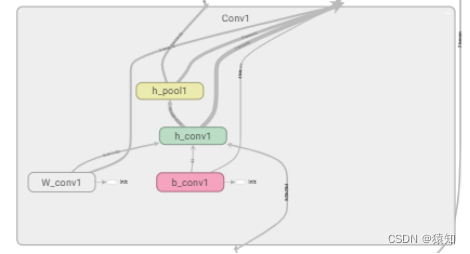
以第一个卷积层为例:
with tf.name_scope('Conv1'):
with tf.name_scope('W_conv1'):
W_conv1 = weight_variable([5, 5, 1, 32])
with tf.name_scope('b_conv1'):
b_conv1 = bias_variable([32])
with tf.name_scope('h_conv1'):
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
with tf.name_scope('h_pool1'):
h_pool1 = max_pool_2x2(h_conv1)
同样地,对所有节点进行命名
如下,Conv1中的名称即命名结果
with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
在with tf.Session() as sess中添加
losssum = tf.summary.scalar('loss', cross_entropy)
# loss计入summary中,可以被统计
writer = tf.summary.FileWriter("", graph=sess.graph)
# tf.summary.FileWriter指定一个文件用来保存图
在if i % 50 == 0中添加
summery= sess.run(losssum, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob_rate})
writer.add_summary(summery, i)
# add_summary()方法将训练过程数据保存在filewriter指定的文件中
在Terminal中输入
tensorboard --logdir=E:\cnn_mnist
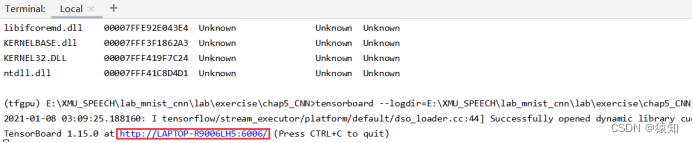
将网址中的LAPTOP-R9006LH5改为localhost,复制在浏览器中打开即可
附录(完整代码1):
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def weight_variable(shape):
# tf.truncated_normal从截断的正态分布中输出随机值.
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 偏置初始化
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 使用tf.nn.conv2d定义2维卷积
def conv2d(x, W):
# 卷积核移动步长为1,填充padding类型为SAME,简单地理解为以0填充边缘, VALID采用不填充的方式,多余地进行丢弃
# 计算给定的4-D input和filter张量的2-D卷积
# input shape [batch, in_height, in_width, in_channels]
# filter shape [filter_height, filter_width, in_channels, out_channels]
# stride 长度为4的1-D张量,input的每个维度的滑动窗口的步幅
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# 采用最大池化,也就是取窗口中的最大值作为结果
# x 是一个4维张量,shape为[batch,height,width,channels]
# ksize表示pool窗口大小为2x2,也就是高2,宽2
# strides,表示在height和width维度上的步长都为2
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 计算test set的accuracy,v_xs (10000,784), y_ys (10000,10)
def compute_accuracy(v_xs, v_ys):
global prediction
# y_pre将v_xs输入模型后得到的预测值 (10000,10)
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
# argmax(axis) axis = 1 返回结果为:数组中每一行最大值所在“列”索引值
# tf.equal返回布尔值,correct_prediction (10000,1)
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
# tf.cast将bool转成float32, tf.reduce_mean求均值,作为accuracy值(0到1)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
xs = tf.placeholder(tf.float32, [None, 784], name='x_input')
ys = tf.placeholder(tf.float32, [None, 10], name='y_input')
max_epoch = 2000
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1])
keep_prob_rate = 0
# 卷积层1
# input size 28x28x1 (以一个样本为例)batch=100 则100x28x28x1
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# output size 28x28x32
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32 卷积操作使用padding保持维度不变,只靠pool降维
# 卷积层2
W_conv2 = weight_variable([5, 5, 32, 64]) # 同conv1,不过卷积核数增为64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2)
# output size 7x7x64
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
# 全连接层1
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# 将conv2的输出reshape成[batch, 7*7*16]的张量,方便全连接层处理
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 全连接层2
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
learning_rate = 1e-4
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
with tf.Session() as sess:
# 初始化图中所有Variables
init = tf.global_variables_initializer()
sess.run(init)
# 总迭代次数(batch)为max_epoch=1000,每次取100张图做batch梯度下降
print("step 0, test accuracy %g" % (compute_accuracy(
mnist.test.images, mnist.test.labels)))
for i in range(max_epoch):
# mnist.train.next_batch 默认shuffle=True,随机读取,batch大小为100
batch_xs, batch_ys = mnist.train.next_batch(100)
# 此batch是个2维tuple,batch[0]是(100,784)的样本数据数组,batch[1]是(100,10)的样本标签数组,分别赋值给batch_xs, batch_ys
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob_rate})
# 暂时不进行赋值的元素叫占位符(如xs、ys),run需要它们时得赋值,feed_dict就是用来赋值的,格式为字典型
if (i + 1) % 50 == 0:
print("step %d, test accuracy %g" % (i + 1, compute_accuracy(
mnist.test.images, mnist.test.labels)))
附录(完整代码2 带tensorboad可视化):
import tensorflow.compat.v1 as tf
# import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
# 导入input_data用于自动下载和安装MNIST数据集
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
learning_rate = 1e-4
keep_prob_rate = 0.7 # drop out比例(补偿系数)
# 为了保证神经元输出激活值的期望值与不使用dropout时一致,我们结合概率论的知识来具体看一下:假设一个神经元的输出激活值为a,
# 在不使用dropout的情况下,其输出期望值为a,如果使用了dropout,神经元就可能有保留和关闭两种状态,把它看作一个离散型随机变量,
# 它就符合概率论中的0-1分布,其输出激活值的期望变为 p*a+(1-p)*0=pa,为了保持测试集与训练集神经元输出的分布一致,可以训练时除以此系数或者测试时乘以此系数
# 即输出节点按照keep_prob概率置0,否则以1/keep_prob的比例缩放该节点(而并非保持不变)
max_epoch = 2000
# 权重矩阵初始化
def weight_variable(shape):
# tf.truncated_normal从截断的正态分布中输出随机值.
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 偏置初始化
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 使用tf.nn.conv2d定义2维卷积
def conv2d(x, W):
# 卷积核移动步长为1,填充padding类型为SAME,简单地理解为以0填充边缘, VALID采用不填充的方式,多余地进行丢弃
# 计算给定的4-D input和filter张量的2-D卷积
# input shape [batch, in_height, in_width, in_channels]
# filter shape [filter_height, filter_width, in_channels, out_channels]
# stride 长度为4的1-D张量,input的每个维度的滑动窗口的步幅
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# 采用最大池化,也就是取窗口中的最大值作为结果
# x 是一个4维张量,shape为[batch,height,width,channels]
# ksize表示pool窗口大小为2x2,也就是高2,宽2
# strides,表示在height和width维度上的步长都为2
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 计算test set的accuracy,v_xs (10000,784), y_ys (10000,10)
def compute_accuracy(v_xs, v_ys):
global prediction
# y_pre将v_xs输入模型后得到的预测值 (10000,10)
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
# argmax(axis) axis = 1 返回结果为:数组中每一行最大值所在“列”索引值
# tf.equal返回布尔值,correct_prediction (10000,1)
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
# tf.cast将bool转成float32, tf.reduce_mean求均值,作为accuracy值(0到1)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
with tf.name_scope('input'):
xs = tf.placeholder(tf.float32, [None, 784], name='x_input')
ys = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# 输入转化为4D数据,便于conv操作
# 把输入x(二维张量,shape为[batch, 784])变成4d的x_image,x_image的shape应该是[batch,28,28,1],第四维是通道数1
# -1表示自动推测这个维度的size
## conv1 layer ##
with tf.name_scope('Conv1'):
with tf.name_scope('W_conv1'):
W_conv1 = weight_variable([5, 5, 1, 32])
# 初始化W_conv1为[5,5,1,32]的张量tensor,表示卷积核大小为5*5,1表示图像通道数,6表示卷积核个数即输出6个特征图
# 3 这个 0 阶张量就是标量,shape=[]
# [1., 2., 3.] 这个 1 阶张量就是向量,shape=[3]
# [[1., 2., 3.], [4., 5., 6.]] 这个 2 阶张量就是二维数组,shape=[2, 3]
# [[[1., 2., 3.]], [[7., 8., 9.]]] 这个 3 阶张量就是三维数组,shape=[2, 1, 3]
# 即有几层中括号
with tf.name_scope('b_conv1'):
b_conv1 = bias_variable([32])
with tf.name_scope('h_conv1'):
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32 5x5x1的卷积核作用在28x28x1的二维图上
with tf.name_scope('h_pool1'):
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32 卷积操作使用padding保持维度不变,只靠pool降维
## conv2 layer ##
with tf.name_scope('Conv2'):
with tf.name_scope('W_conv2'):
W_conv2 = weight_variable([5, 5, 32, 64]) # patch 5x5, in size 32, out size 64
with tf.name_scope('b_conv2'):
b_conv2 = bias_variable([64])
with tf.name_scope('h_conv2'):
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
with tf.name_scope('h_pool2'):
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
# 全连接层 1
## fc1 layer ##
# 1024个神经元的全连接层
with tf.name_scope('Fc1'):
with tf.name_scope('W_fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
with tf.name_scope('b_fc1'):
b_fc1 = bias_variable([1024])
with tf.name_scope('h_pool2_flat'):
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
with tf.name_scope('h_fc1'):
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
with tf.name_scope('h_fc1_drop'):
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 全连接层 2
## fc2 layer ##
with tf.name_scope('Fc2'):
with tf.name_scope('W_fc2'):
W_fc2 = weight_variable([1024, 10])
with tf.name_scope('b_fc2'):
b_fc2 = bias_variable([10])
with tf.name_scope('prediction'):
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 交叉熵函数
with tf.name_scope('loss'):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
# 使用ADAM优化器来做梯度下降,学习率为learning_rate0.0001
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
with tf.Session() as sess:
# 初始化图中所有Variables
init = tf.global_variables_initializer()
sess.run(init)
losssum = tf.summary.scalar('loss', cross_entropy) # 若placeholde报错,则rerun
# merged = tf.summary.merge_all() # 只有loss值需要统计,故不需要merge
writer = tf.summary.FileWriter("", graph=sess.graph)
# tf.summary.FileWriter指定一个文件用来保存图
# writer.close()
# writer = tf.summary.FileWriter("", sess.graph) # 重新保存图时,要在console里rerun,否则graph会累计 cmd进入tfgpu环境 tensorboard --logdir=路径,将网址中的laptop替换为localhost
for i in range(max_epoch + 1):
# mnist.train.next_batch 默认shuffle=True,随机读取
batch_xs, batch_ys = mnist.train.next_batch(100)
# 此batch是个2维tuple,batch[0]是(100,784)的样本数据数组,batch[1]是(100,10)的样本标签数组
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob_rate})
if i % 50 == 0:
summery= sess.run(losssum, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob_rate})
# summary = sess.run(merged, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: keep_prob_rate})
writer.add_summary(summery, i)
# add_summary()方法将训练过程数据保存在filewriter指定的文件中
print("step %d, test accuracy %g" % (i, compute_accuracy(
mnist.test.images, mnist.test.labels)))
相关文章:
使用Tensorflow完成一个简单的手写数字识别
Tensorflow中文手册 介绍TensorFlow_w3cschool 模型结构图: 首先明确模型的输入及输出(先不考虑batch) 输入:一张手写数字图(28x28x1像素矩阵) 1是通道数 输出:预测的数字(1x10的one…...

OpenGL三种向着色器传递数据的方法 attributes,uniform,texture以及中间产物
(1)属性,使在顶点着色器中使用的变量,用于描述顶点的属性,如位置、颜色、法向量等,attributes通常用于描述每个顶点的属性,因此在顶点缓冲对象中存储,渲染的时候,openGL会…...

详解package.json和package-lock
详解package.json和package-lockpackage.json和package-lock.json作用首先要明确一点,package.json不会自动生成,需要我们使用 npm init 创建。package-lock.json是自动生成的,我们使用 npm install 安装包后就会自动生成。在我们执行 npm in…...

02-CSS
一、emmet语法1、简介Emmet语法的前身是Zen coding,它使用缩写,来提高html/css的编写速度, Vscode内部已经集成该语法。快速生成HTML结构语法快速生成CSS样式语法2、快速生成HTML结构语法生成标签 直接输入标签名 按tab键即可 比如 div 然后tab 键, 就可以生成 <…...

JavaScript 中的类型转换机制以及==和===的区别
目录一、概述二、显示转换Number()parseInt()String()Boolean()三、隐式转换自动转换成字符串自动转换成数值四、 和 区别1、等于操作符2、全等操作符3、区别小结一、概述 我们知道,JS中有六种简单数据类型:undefined、null、boolean、string、number、…...
RocketMQ基础篇(一)
目录一、发送消息类型1、同步消息2、异步消息3、单向消息4、顺序消费5、延迟消费二、消费模式1、集群模式2、广播模式3、消费模式扩展4、如何配置三、其他用法1、事务消息2、过滤消息1)Tag过滤2)SQL方式过滤源码放到了GitHub仓库上,地址 http…...

Android前沿技术—gradle中的build script详解
build.gradle是gradle中非常重要的一个文件,因为它描述了gradle中可以运行的任务,今天本文将会带大家体验一下如何创建一个build.gradle文件和如何编写其中的内容。 project和task gradle是一个构建工具,所谓构建工具就是通过既定的各种规则…...

深入浅出PaddlePaddle函数——paddle.zeros_like
分类目录:《深入浅出PaddlePaddle函数》总目录 相关文章: 深入浅出PaddlePaddle函数——paddle.Tensor 深入浅出PaddlePaddle函数——paddle.ones 深入浅出PaddlePaddle函数——paddle.zeros 深入浅出PaddlePaddle函数——paddle.full 深入浅出Padd…...

物料-零部件分类属性
离散制造业的研发、生产跟产品零部件紧密联系在一起,从企业业务流程来说零部件涉及研发、采购、仓储、生产、质量、售后和配件等多个部门,为了更好地管理零部件,下面我们一起来看看零部件概念及分类。 1、按行业属性分类 (1&…...

TypeError: cannot pickle ‘module‘ object
创建python对象时报错: TypeError: cannot pickle module object 原因: 很大可能是类成员错误的使用了第三方包(别名)等,具体排查方法可参考: import redisimport pickle from pprint import pformat as …...
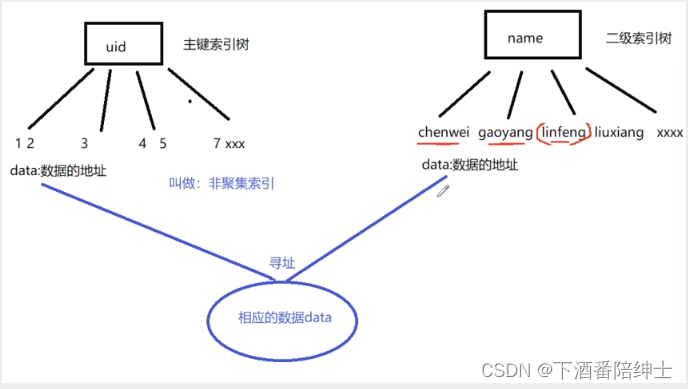
[MySQL索引]3.索引的底层原理(二)
索引的底层原理(二)InnoDB的主键和二级/辅助索引树(涉及回表)MyISAM存储引擎的主键和二级索引树InnoDB的主键和二级/辅助索引树(涉及回表) 看下面这张student数据库表: 场景一:uid…...

JavaScript混淆——逆向思维的艺术
在本文中我们将介绍三种常见的JavaScript混淆技术。 1.混合名称 通过将函数名称和变量名混合使用,我们可以使代码更难读。下面是一个使用名称混合的JavaScript函数。 function c(a){var b[2,4,8,a],db[0]b[1]b[2]b[3],ed""a;return e}混合名称技术通过…...
数据库管理-第六十期 监听(20230309)
数据库管理 2023-03-09第六十期期 监听1 无法访问2 监听配置3 问题复现与解决4 静态监听5 记不住配置咋整总结第六十期期 监听 不知不觉又来到了一个整10期数,我承认上一期有很大的划水的。。。嫌疑吧,本期内容是从帮群友解决ADG前置配置时候的一个问题…...

概率论与数理统计相关知识
本博客为《概率论与数理统计--茆诗松(第二版)》阅读笔记,目的是查漏补缺前置知识数学符号连乘符号:;总和符号:;“任意”符号:∀;“存在”符号&…...

SOC计算方法:卡尔曼滤波算法
卡尔曼滤波算法是一种经典的状态估计算法,它广泛应用于控制领域和信号处理领域。在电动汽车领域中,卡尔曼滤波算法也被广泛应用于电池管理系统中的电池状态估计。其中,电池的状态包括电池的剩余容量(SOC)、内阻、温度等…...

【C语言】自定义类型、枚举类型与宏定义
目录一、自定义类型二、宏定义三、枚举类型一、自定义类型 自定义类型关键字:typedef,用新的类型名称代替原有的类型名。 例如: typedef char u8; u8 x;表示指定u8为新的类型名,代替char,作用与char相同,…...

Java进阶(下篇2)
Java进阶(下篇2)一、IO流01.File类的使用1.1、File类的实例化1.2、File类的常用方法11.3、File类的常用方法21.4、课后练习02、IO流原理及流的分类2.1、IO流原理2.2、流的分类2.3、IO 流体系03、节点流(或文件流)3.1、FileReader读入数据的基本操作3.2、…...

03单链表
、# 单链表 单链表是一种链式存储的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。单链表中的每个结点包含一个数据域和一个指针域,数据域存放数据元素,指针域存放下一个结点的地址。单链表的第一个结点称为头结点,…...
ESLint、Prettier插件的安装与使用
在统一代码风格这一块,通常大家都会用到ESLint。虽然 ESLint 本身具备自动格式化代码的功能,但ESLint 的主要优势在于代码的风格检查并给出提示,而在代码格式化这一块 Prettier 做的更加专业,因此在实际项目开发中我们经常将 ESLi…...

matlab在管理学中的应用简matlab基础【三】
规划论及MATLAB计算 1、线性规划 问题的提出 例1. 某工厂在计划期内要安排甲、乙两种产品的生产,已知生产单位产品所需的资源A、B、C的消耗以及资源的计划期供给量,如下表: 问题:工厂应分别生产多少单位甲、乙产品才能使工厂获…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...