《SQL基础》17. InnoDB引擎
InnoDB引擎
- InnoDB引擎
- 逻辑存储结构
- 架构
- 内存结构
- 磁盘结构
- 后台线程
- 事务原理
- 事务基础
- redo log
- undo log
- MVCC
- 基本概念
- 隐式字段
- undo log版本链
- readView
- 原理分析
InnoDB引擎
逻辑存储结构
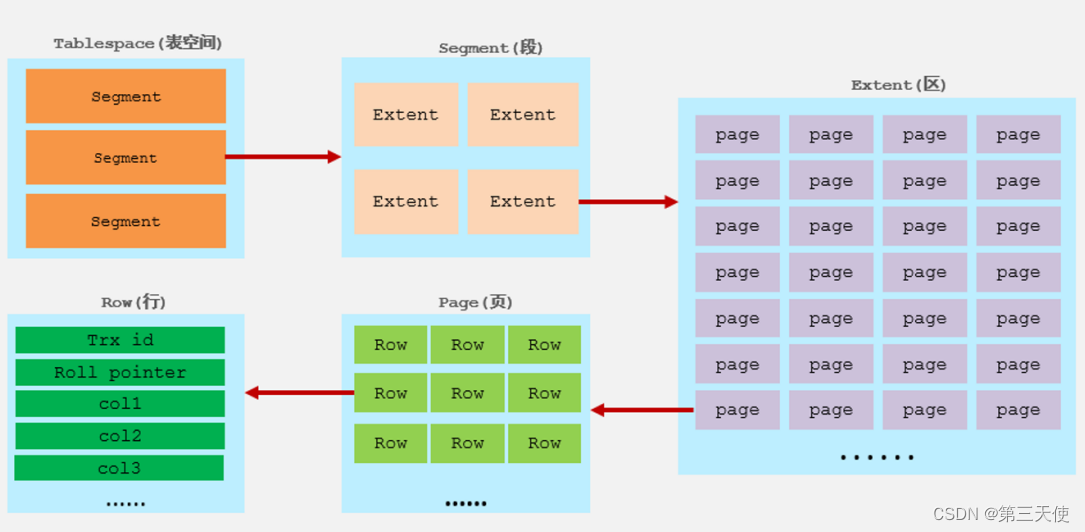
InnoDB的逻辑存储结构如下图所示:
-
表空间
表空间是InnoDB存储引擎逻辑结构的最高层,如果用户启用了参数 innodb_file_per_table(在8.0版本中默认开启),则每张表都会有一个表空间(xxx.ibd),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。 -
段
段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段即为B+树的非叶子节点。段用来管理多个Extent(区)。 -
区
区,表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页。 -
页
页,是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请 4-5 个区。 -
行
行,InnoDB存储引擎数据是按行进行存放的。在行中,默认有两个隐藏字段:- Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。
- Roll_pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
架构
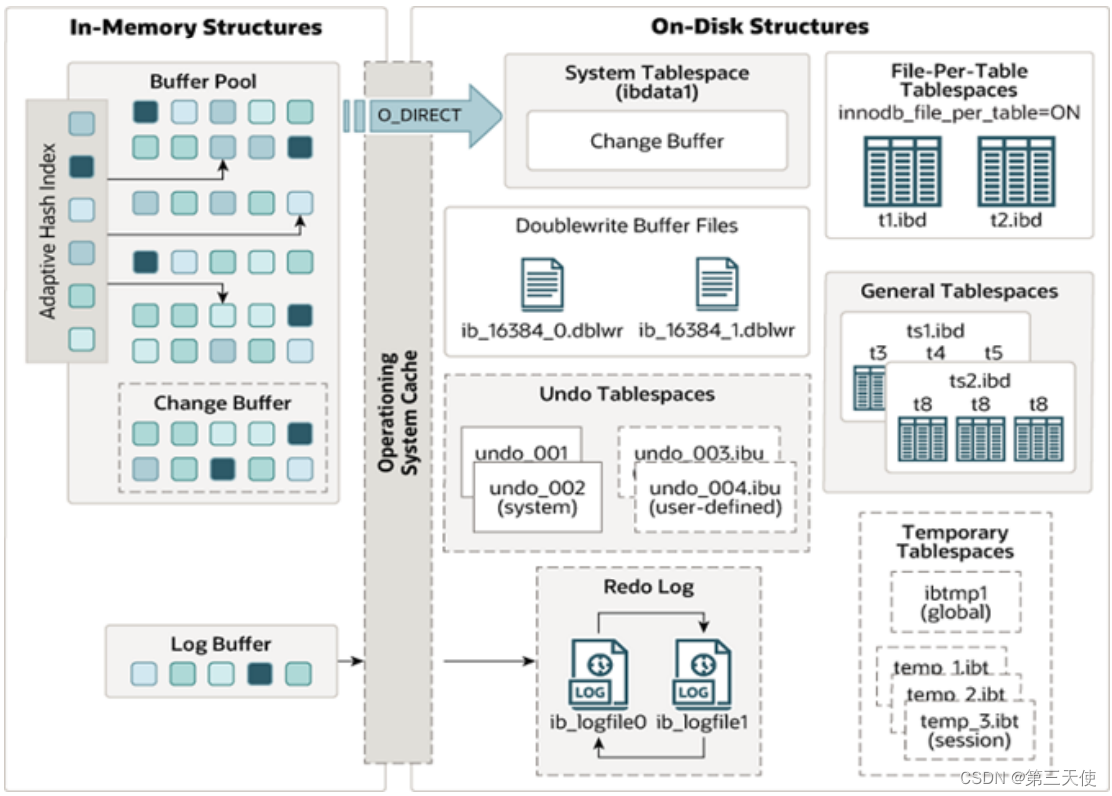
MySQL5.5版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。下面是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
内存结构
在左侧的内存结构中,主要分为四大块:
- Buffer Pool(缓冲池)
- Change Buffer(更改缓冲区)
- Adaptive Hash Index(自适应hash索引)
- Log Buffer(日志缓冲区)

Buffer Pool
Buffer Pool(缓冲池),是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page(页)为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
- free page:空闲页,未被使用。
- clean page:被使用页,且数据没有被修改过。
- dirty page:脏页,被使用页,且数据被修改过,页中数据与磁盘的数据不一致。
在专用服务器上,通常将多达80%的物理内存分配给缓冲池。
缓冲池大小查询:
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
Change Buffer
Change Buffer(更改缓冲区),针对于非唯一二级索引页,在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在Change Buffer中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,将合并后的数据刷新到磁盘中。
Change Buffer的意义
与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,可以在缓冲池中进行合并处理,减少磁盘IO。
Adaptive Hash Index
Adaptive Hash Index(自适应hash索引),用于优化对Buffer Pool数据的查询。MySQL的innoDB引擎中虽然没有直接支持hash索引,但是提供了自适应hash索引。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到在特定的条件下hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成的。
参数:adaptive_hash_index
Log Buffer
Log Buffer(日志缓冲区),用来保存要写入到磁盘中的log日志数据(redo log 、undo log),默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
参数:
innodb_log_buffer_size:缓冲区大小。
innodb_flush_log_at_trx_commit:日志刷新到磁盘时机。取值主要包含以下三个:
- 1:日志在每次事务提交时写入并刷新到磁盘,默认值。
- 0:每秒将日志写入并刷新到磁盘一次。
- 2:日志在每次事务提交后写入,并每秒刷新到磁盘一次。
磁盘结构
InnoDB体系结构的右边部分,也就是磁盘结构:
- System Tablespace(系统表空间)
- File-Per-Table Tablespaces(独立表空间)
- General Tablespaces(通用表空间)
- Undo Tablespaces(撤销表空间)
- Temporary Tablespaces(临时表空间)
- Doublewrite Buffer Files(双写缓冲区)
- Redo Log(重做日志)
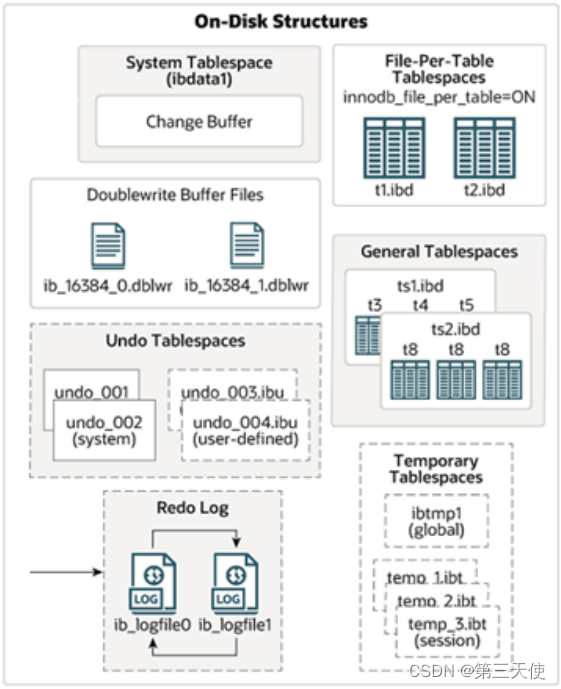
System Tablespace
系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)
参数:innodb_data_file_path
系统表空间,默认的文件名叫 ibdata1。
File-Per-Table Tablespaces
如果开启了 innodb_file_per_table 开关,则每个表的文件表空间包含单个InnoDB表的数据和索引 ,并存储在文件系统上的单个数据文件中。也就是说,每创建一个表,都会产生一个表空间文件。
开关参数:innodb_file_per_table,该参数默认开启。
General Tablespaces
通用表空间,需要通过 CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空间。
创建表空间:
CREATE TABLESPACE 表空间名 ADD DATAFILE '关联的表空间文件' ENGINE = 存储引擎名;
表空间文件即(xxx.ibd)
创建表时指定表空间:
CREATE TABLE 表名(创建字段列表) TABLESPACE 表空间名;
Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
Temporary Tablespaces
InnoDB使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
Doublewrite Buffer Files
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log
重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息存到该日志中,用于在刷新脏页到磁盘发生错误时,进行数据恢复使用。
重做日志文件以循环方式写入,涉及两个文件。
后台线程
内存中所更新的数据,存到磁盘中,涉及到后台线程。
在InnoDB的后台线程中,分为4类
- Master Thread
- IO Thread
- Purge Thread
- Page Cleaner Thread
Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read thread | 4 | 负责读操作 |
| Write thread | 4 | 负责写操作 |
| Log thread | 1 | 负责将日志缓冲区刷新到磁盘 |
| Insert buffer thread | 1 | 负责将写缓冲区内容刷新到磁盘 |
查看InnoDB状态信息:
SHOW ENGINE INNODB STATUS \G;
Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
事务原理
事务基础
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务特性:
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
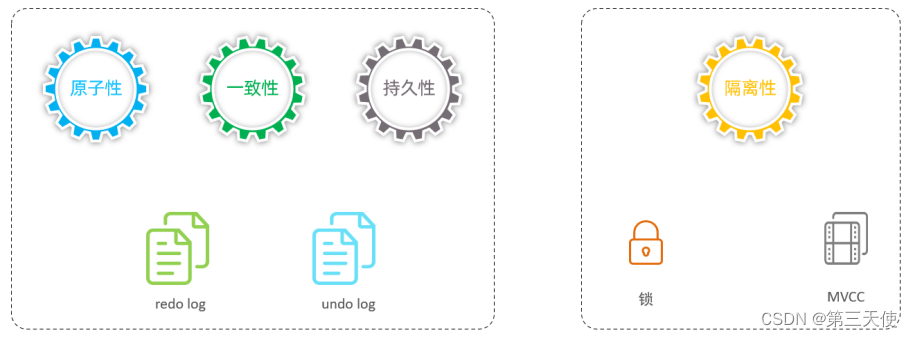
其中的原子性、一致性、持久性,实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而持久性是通过数据库的锁,加上MVCC来保证的。
redo log
redo log(重做日志),记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息存到该日志中,用于在刷新脏页到磁盘发生错误时,进行数据恢复使用。
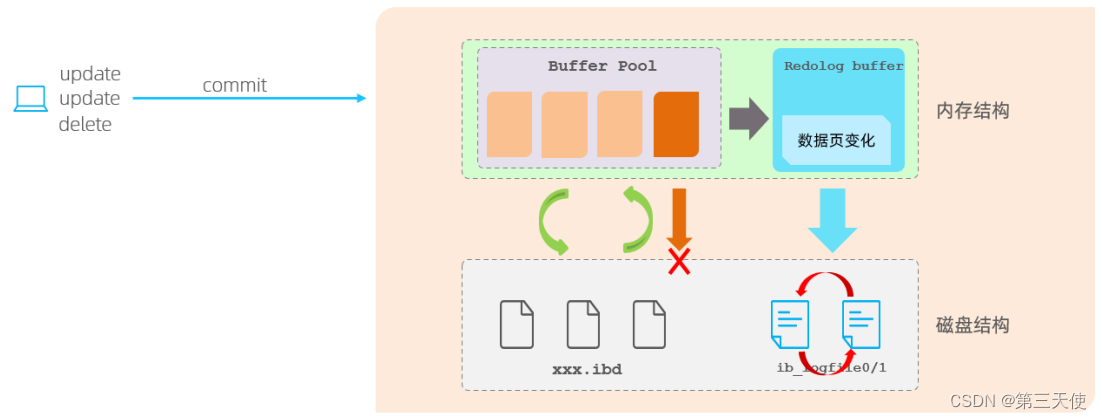
当对缓冲区的数据进行增删改之后,会首先将操作的数据页的变化记录在redo log buffer中。在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中。过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助redo log进行数据恢复,这样就保证了事务的持久性。 而如果脏页成功刷新到磁盘 或 涉及到的数据已经落盘,此时redo log就没有作用了,可以删除,所以存在的两个redolog文件是循环写的。
为什么每一次提交事务,要刷新 redo log 到磁盘中,而不是直接将 buffer pool 中的脏页刷新到磁盘?
因为在业务操作中,操作数据一般都是随机读写磁盘,而不是顺序读写磁盘。而redo log在往磁盘文件中写入数据时,由于是日志文件,所以是顺序写的。顺序写的效率,要远大于随机写。这种先写日志的方式,称之为Write-Ahead Logging(WAL)。
undo log
undo log(回滚日志),用于记录数据被修改前的信息,作用包含两个:提供回滚(保证事务的原子性)和MVCC(多版本并发控制)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然。当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
- Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
- Undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment(回滚段)中,内部包含1024个undo log segment。
MVCC
基本概念
-
当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于日常的操作,如:select … lock in share mode(共享锁),select … for update、update、insert、delete(排他锁)都是一种当前读。 -
快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。- Read Committed:每次select,都生成一个快照读。
- Repeatable Read:开启事务后第一个select语句才是快照读的地方。
- Serializable:快照读会退化为当前读。
-
MVCC
全称 Multi-Version Concurrency Control(多版本并发控制)。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView。
隐式字段
当创建表时,查看表结构可以显式地看到字段。实际上除了显式字段以外,InnoDB还会自动的添加三个隐藏字段。
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
上述前两个字段是肯定会添加的,是否添加最后一个字段 DB_ROW_ID,得看当前表有没有主键,如果有主键,则不会添加该隐藏字段。
查看表结构及其中的字段信息(Linux命令行):
ibd2sdi 表名.ibd
undo log版本链
undo log
回滚日志,在 insert、update、delete 的时候产生的便于数据回滚的日志。
当 insert 的时候,产生的 undo log 日志只在回滚时需要,在事务提交后,可被立即删除。
而 update、delete 的时候,产生的 undo log 日志不仅在回滚时需要,在快照读时也需要,不会被立即删除。
undo log版本链
不同事务或相同事务对同一条记录进行修改,会导致该记录的 undo log 生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
readView
ReadView(读视图)是快照读 SQL 执行时 MVCC 提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
ReadView中包含了四个核心字段:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
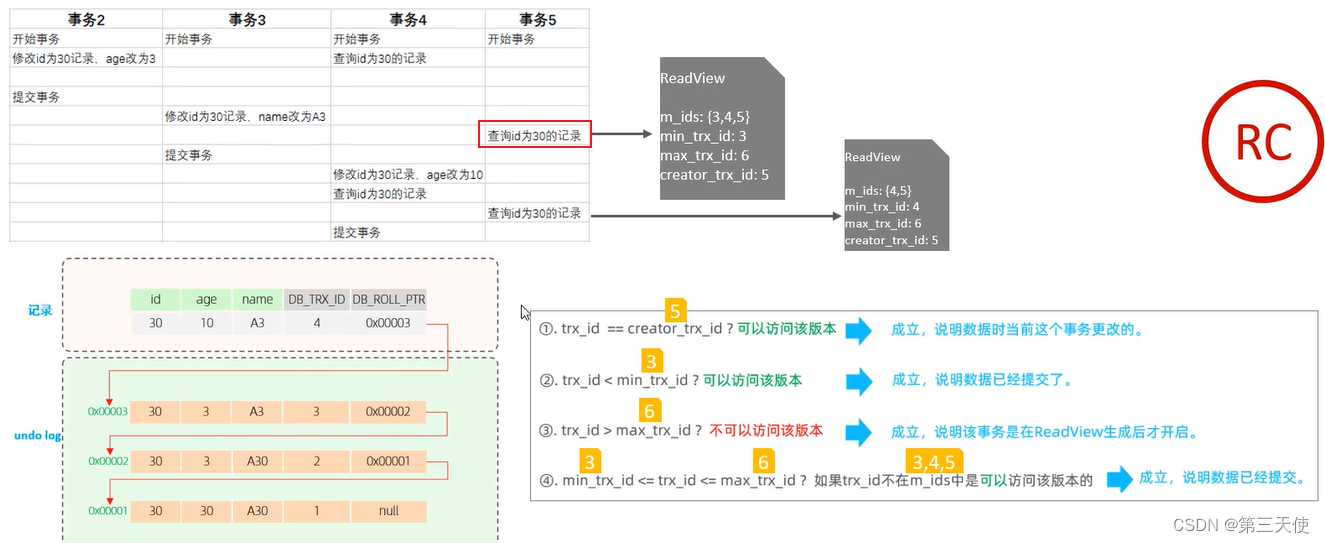
而在 readview 中就规定了版本链数据的访问规则(trx_id 代表当前undolog版本链对应事务ID):
| 条件 | 是否可以访问 | 说明 |
|---|---|---|
| trx_id = creator_trx_id | 可以访问该版本 | 成立,说明数据是当前这个事务更改的 |
| trx_id < min_trx_id | 可以访问该版本 | 成立,说明数据已经提交了 |
| trx_id > max_trx_id | 不可以访问该版本 | 成立,说明该事务是在ReadView生成后才开启 |
| min_trx_id <= trx_id <= max_trx_id | 如果 trx_id 不在 m_ids 中,可以访问该版本 | 成立,说明数据已经提交 |
不同的隔离级别,生成ReadView的时机不同:
- READ COMMITTED:在事务中每一次执行快照读时生成ReadView。
- REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
原理分析
RC隔离级别
RC隔离级别下,在事务中每一次执行快照读时生成 ReadView。
分析事务5中,两次快照读读取数据,是如何获取数据的。
第一次快照读具体的读取过程:
第二次快照读具体的读取过程:
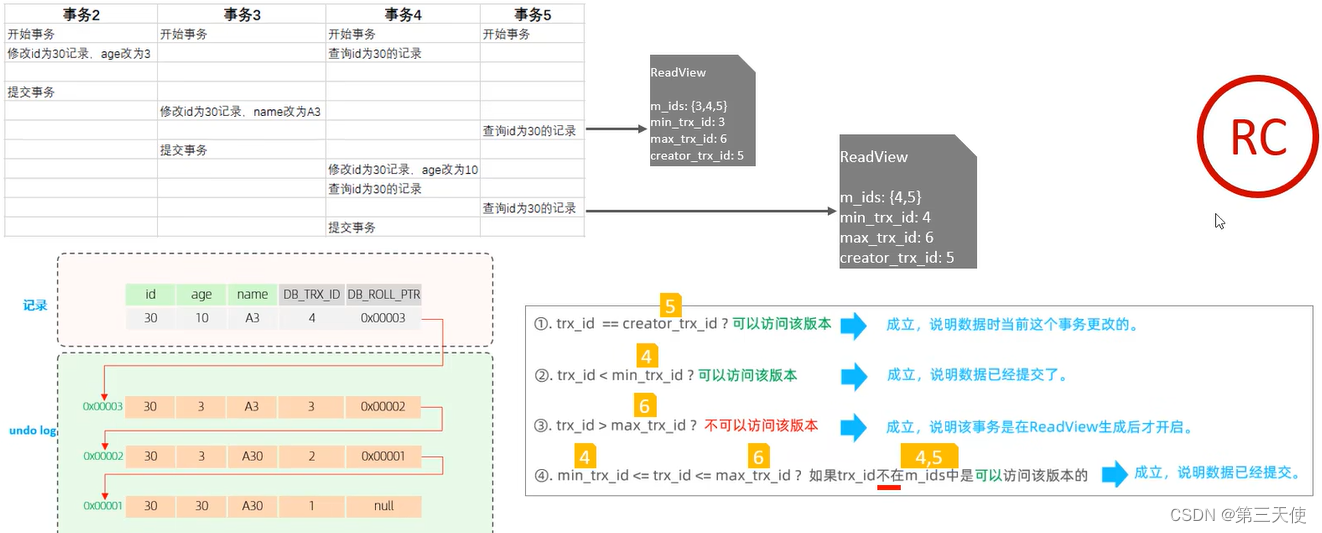
RR隔离级别
RR隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
而 RR 是可重复读,在一个事务中,执行两次相同的select语句,查询到的结果是一样的。
相关文章:
《SQL基础》17. InnoDB引擎
InnoDB引擎InnoDB引擎逻辑存储结构架构内存结构磁盘结构后台线程事务原理事务基础redo logundo logMVCC基本概念隐式字段undo log版本链readView原理分析InnoDB引擎 逻辑存储结构 InnoDB的逻辑存储结构如下图所示: 表空间 表空间是InnoDB存储引擎逻辑结构的最高层…...
api接口详解大全
api接口详解大全?优秀的设计是产品变得卓越的原因设计API意味着提供有效的接口,可以帮助API使用者更好地了解、使用和集成,同时帮助人们有效地维护它每个产品都需要使用手册,API也不例外在API领域,可以将设计视为服务器和客户端之…...

为什么要用VR全景?5个答案告诉你
看中了刚上市的一款新车,再也不用等车展、去4s店才能仔细观赏,点开手机就能“置身”车内近距离观看每一处细节,点击关灯开灯、关门关门,除了摸不到,和在现场几乎没有区别; 准备买房的时候,没人愿…...

常用的深度学习优化方式
全连接层 PyTorch中的全连接层(Fully Connected Layer)也被称为线性层(Linear Layer),是神经网络中最常用的一种层。全连接层将输入数据的每个元素与该层中的每个神经元相连接,输出结果是输入数据与该层的…...

全面吃透Java Stream流操作,让代码更加的优雅
文章目录1 认识Stream流1.1 什么是流1.2 流与集合1.2.1 流只能遍历一次1.2.2 外部迭代和内部迭代1.3 流操作1.3.1 中间操作1.3.2 终端操作1.3.3 使用流2 学会使用Stream流2.1 筛选和切片2.1.1 用谓词筛选2.1.2 筛选各异的元素2.1.3 截短流2.1.4 跳过元素2.2 映射2.2.1 map方法2…...
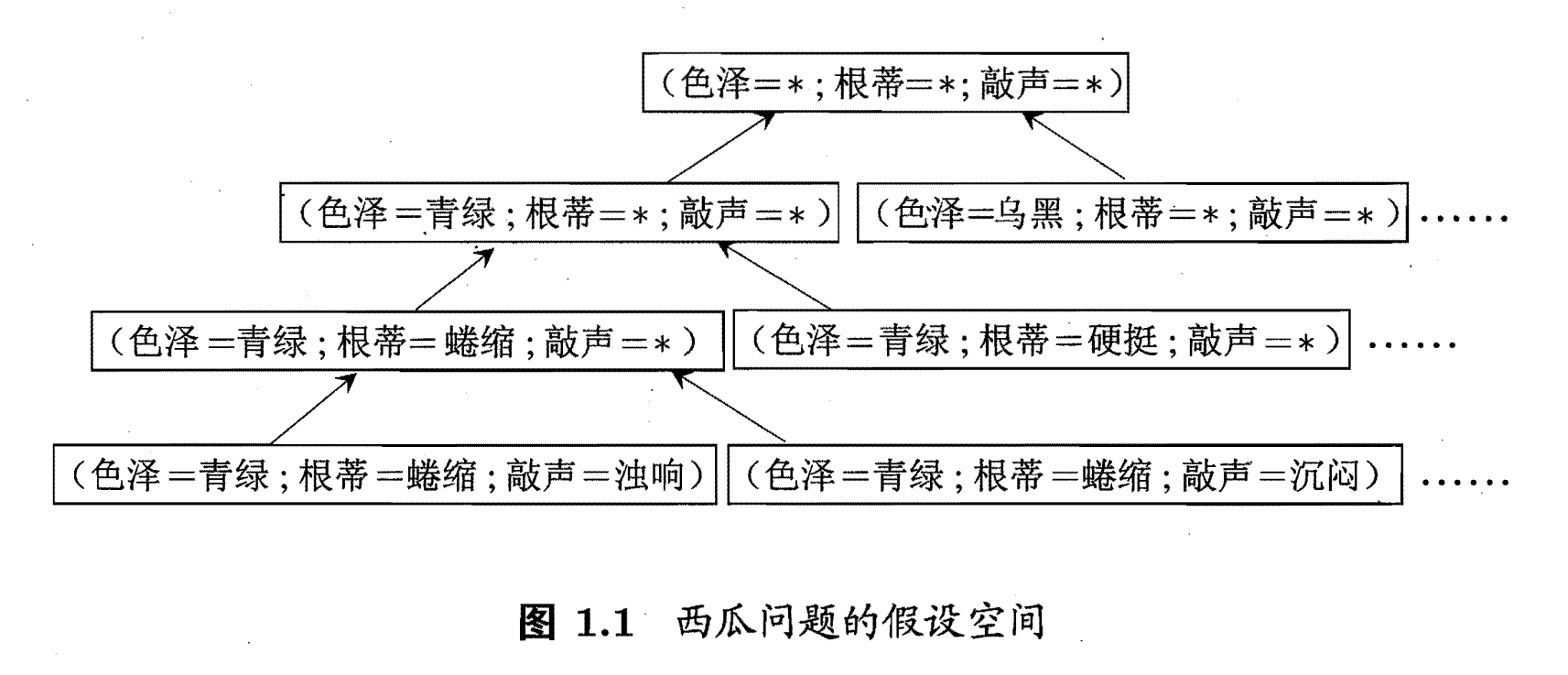
机器学习学习记录1:假设空间
我们可以把学习过程看作一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集"匹配" 的假设,即能够将训练集中的瓜判断正确的假设.假设的表示一旦确定,假设空间及其规模大小就确定了.对于西瓜问题,这里我们…...
开源工具系列5:DependencyCheck
Dependency-Check 是 OWASP(Open Web Application Security Project)的一个实用开源程序,用于识别项目依赖项并检查是否存在任何已知的,公开披露的漏洞。 DependencyCheck 是什么 Dependency-Check 是 OWASP(Open Web …...
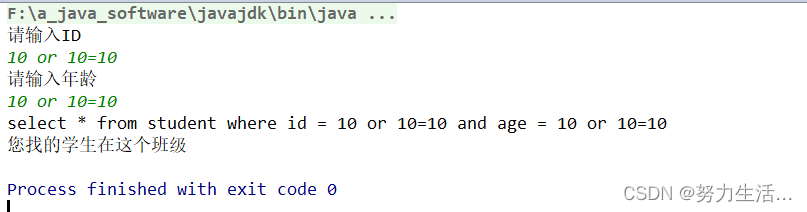
JDBC知识点全面总结2:JDBC实战编写CRUD
二.JDBC知识点全面总结1:JDBC实战编写CRUD 1.JDBC重要接口? 2.Driver和DriverMangement的关系? 3.JAVA与数据库连接 4.JAVA中使用statement来执行sql语句时,拼接字符串的sql注入问题? 5.使用preparedstatement进行…...
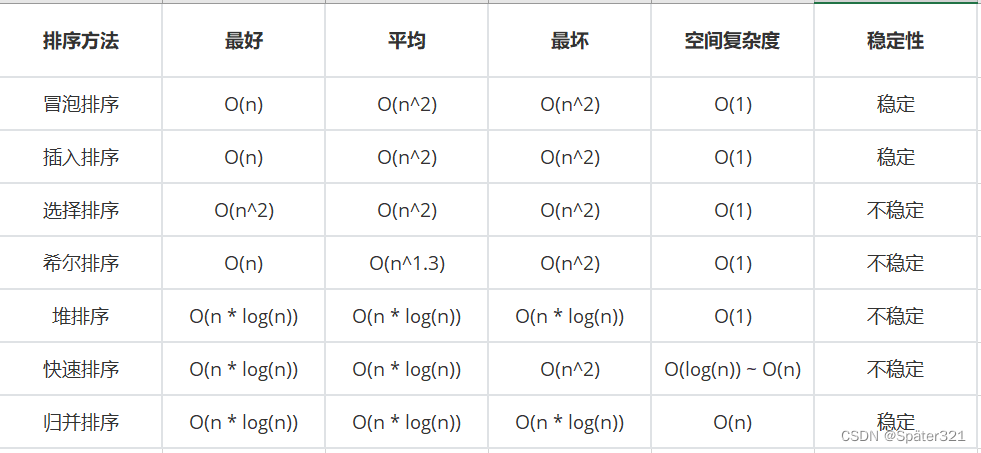
java - 数据结构,算法,排序
一、概念 1.1、排序 排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 平时的上下文中,如果提到排序,通常指的是排升序(非降序)。 通常意义上的排序&#…...

二叉树经典14题——初学二叉树必会的简单题
此篇皆为leetcode、牛客中的简单题型和二叉树基础操作,无需做过多讲解,仅付最优解。有需要的小伙伴直接私信我~ 目录 1.二叉树的节点个数 2.二叉树叶子节点个数 3.二叉树第K层节点个数 4.查找值为X的节点 5.leetcode——二叉树的最大深度 6.leetc…...

基于NMOSFET的电平转换电路设计
一、概述: 在单片机系统中,5V、3.3V是芯片常用的电平。而在传输协议中(如IIC、SPI等协议),存在芯片与芯片的高电平和低电平定义的范围不一样,所以需要存在一个电平转换电路,来使芯片与芯片之间顺利的传输。 二、前置…...

mongoDB搭建集群
(学习自黑马)下载对应linux版本MongoDB源码下载地址:https://www.mongodb.com/download-center#community目前在一台服务器开三个端口模拟三个mongodb, 配置一个主节点27017,一个从节点27018,一个仲裁者27019配置主节点,副节点,仲裁节点(下面的创建文件一共有三份,通…...
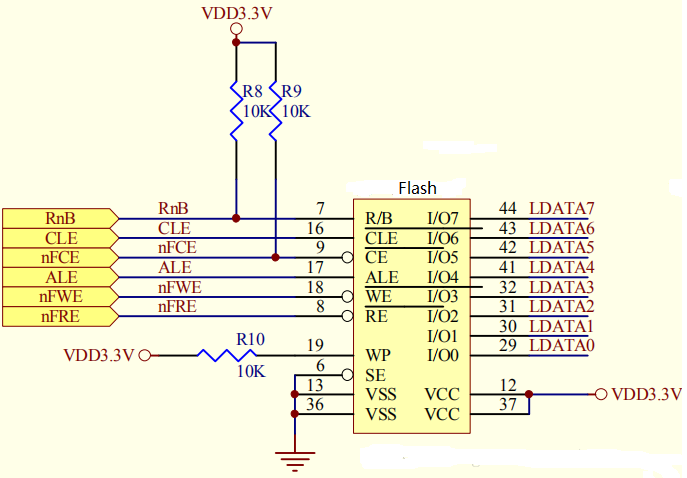
[深入理解SSD系列 闪存2.1.5] NAND FLASH基本读操作及原理_NAND FLASH Read Operation源码实现
前言 上面是我使用的NAND FLASH的硬件原理图,面对这些引脚,很难明白他们是什么含义, 下面先来个热身: 问1. 原理图上NAND FLASH只有数据线,怎么传输地址? 答1.在DATA0~DATA7上既传输数据,又传输地址 当ALE为高电平时传输的是地址, 问2. 从NAND FLASH芯片手册可知,要…...

最新 JVM 面试经典问题
文章目录 说说JVM的内存布局?知道new一个对象的过程吗?知道双亲委派模型吗?说说有哪些垃圾回收算法?标记-清除复制算法标记-整理那么什么是GC ROOT?有哪些GC ROOT?垃圾回收器了解吗?年轻代和老年代都有哪些垃圾回收器?G1的原理了解吗?什么时候会触发YGC和FGC?对象什么…...
HTML5 和 CSS3 的新特性
目标能够说出 3~5 个 HTML5 新增布局和表单标签能够说出 CSS3 的新增特性有哪些HTML5新特性概述HTML5 的新增特性主要是针对于以前的不足,增加了一些新的标签、新的表单和新的表单属性等。 这些新特性都有兼容性问题,基本是 IE9 以上版本的浏览器才支持&…...

Vulnhub系列:FristLeaks
一、配置靶机环境以往的靶机,本人是在virtual box中,去配置,和vm上的kali进行联动,但是这个靶机需要DHCP,以往的方式可能不太行了,或者可以在virtual box中桥接成统一网卡。下面介绍下本人最有用的方法&…...

XWiki Annotation Displayer 存在任意代码执行漏洞(CVE-2023-26475)
漏洞描述 XWiki 是一个开源的企业级 Wiki 平台,Annotation Displayer 是 XWiki 中的一个插件,用于在 XWiki 页面上显示注释和其他相关内容。 该项目受影响版本存在任意代码执行漏洞,由于Annotation Displayer 对 Groovy 宏的使用没有限制&a…...

数字孪生GIS智慧风场Web3D可视化运维系统
随着国家双碳目标的实施,新能源发电方式逐渐代替了污染大气层的火力发电,其中风力发电相比于光伏发电具有能量密度高、发电小时数长、生命周期达20-25年之久等独特的优势。风能取之不尽、用之不竭,在新型能源互联网下,风力发电有可…...
- 网络请求和响应处理)
Retrofit核心源码分析(二)- 网络请求和响应处理
在上一篇文章中,我们详细分析了 Retrofit 中的注解解析和动态代理实现,本篇文章将继续深入研究 Retrofit 的核心源码,重点分析 Retrofit 如何进行网络请求和响应处理。 网络请求 在使用 Retrofit 发起网络请求时,我们可以通过定…...

STM32启动模式讲解与ICP下载电路
一、官方提供的启动模式说明硬件BOOT引脚接法表格从表格可以看出有三种启动模式,然后对应这不同的存储器启动,那我们现在疑问为啥有三种不能只有一种就好,还有存储器启动区域怎么区分,有些乱,带着这些疑问,…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...