vector你得知道的知识
vector的基本使用和模拟实现

一、std::vector基本介绍
1.1 常用接口说明
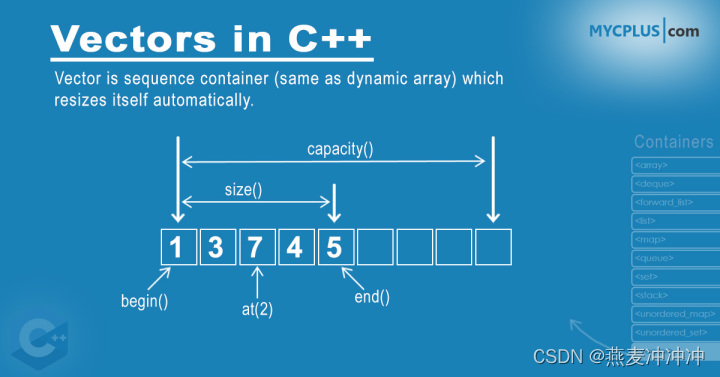
std::vector是STL中的一个动态数组容器,它可以自动调整大小,支持在数组末尾快速添加和删除元素,还支持随机访问元素。
以下是std::vector常用的接口及其说明:
push_back(): 在容器末尾添加元素
std::vector<int> vec{1, 2, 3};
vec.push_back(4);
pop_back(): 删除容器末尾的元素
std::vector<int> vec{1, 2, 3};
vec.pop_back();
size(): 返回容器中元素的个数
std::vector<int> vec{1, 2, 3};
std::cout << vec.size() << std::endl; //输出3
-
empty(): 判断容器是否为空 -
reserve(): 分配容器的内部存储空间,但不改变元素个数
std::vector<int> vec{1, 2, 3};
vec.reserve(10); // 分配10个int大小的空间
其中的reserve接口,你说是分配容器空间,这是在堆上还是栈上开辟空间?那如果重新分配的空间比现有空间小,会发生什么?以及重新分配的空间大于现有空间,是在现有的基础上直接扩容,还是舍弃现有空间,将现有数据拷贝到新的空间上?
新分配的内存空间位于堆上。如果重新分配的空间比现有空间小,std::vector 会舍弃多余的元素。如果新分配的空间比现有空间大,std::vector 会重新分配内存,并将原有数据复制到新的内存空间中。
需要注意的是,重新分配内存并将原有数据复制到新的内存空间中,可能会导致性能问题。因此,如果您能够预估存储的数据量,建议在创建 std::vector 时就预分配足够的内存空间,以避免频繁地重新分配内存。
resize(): 改变容器的元素个数
std::vector<int> vec{1, 2, 3};
vec.resize(5);
-
clear(): 删除容器中的所有元素 -
at(): 返回指定位置的元素
std::vector<int> vec{1, 2, 3};
std::cout << vec.at(1) << std::endl; //输出2
-
front(): 返回容器中第一个元素 -
back(): 返回容器中最后一个元素 -
begin(): 返回指向容器中第一个元素的迭代器,end(): 返回指向容器中最后一个元素之后位置的迭代器
std::vector<int> vec{1, 2, 3};
for (auto it = vec.begin(); it != vec.end(); ++it) {std::cout << *it << " ";
}
reverse():反转vector
std::vector::reverse 不是重新分配容器空间的接口,它是用于反转容器中元素的顺序。也就是将容器中第一个元素和最后一个元素交换,第二个元素和倒数第二个元素交换,以此类推。
1.2 代码示例

1.2.1 遍历vector的几种方式
以下示例中分别提到了:下标+[], 迭代器, 范围for, 反向迭代器
void test_vector1()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);for (size_t i = 0; i < v.size(); i++) //1、下标+[]{cout << v[i] << " ";}vector<int>::iterator it = v.begin(); //2、迭代器while (it != v.end()){cout << *it << " ";it++;}for (auto e : v) //3、范围for{cout << e << " ";}vector<int>::reverse_iterator rit = v.rbegin(); // 4、反向迭代器while (rit != v.rend()){cout << *rit << " ";rit++;}// 5 4 3 2 1
}
不难发现,用范围for访问的元素可以直接输出,而通过for循环,从v.begin()开始的迭代器it,却需要解引用。这是因为,在范围for循环中,迭代器是被自动解引用的。
在范围for循环中,循环变量的类型是根据容器元素的类型自动推导出来的,而不是容器的迭代器类型。对于std::vector<int>容器,其元素类型是int,因此在范围for循环中,循环变量的类型是int,而不是std::vector<int>::iterator。
1.2.2 使用迭代器区间构造对象
vector<int> v2(++v.begin(), --v.end()); //利用迭代器区间构造对象————区间左闭右开
// 2 3 4
string s("hello world");
vector<char> v3(s.begin(), s.end()); //其它容器的迭代器只要类型匹配同样适用vector<int> v4;
v4.assign(s.begin(), s.end()); //assign接口类似————中文意思为分配
以上示例中,提到了利用迭代器区间构建对象这种方式是左闭右开的,例如:(v.begin() + 1, v.begin() + 4),这代表下标为[2, 5)的元素。
只要迭代器的类型与vector所存储的元素类型相同,就可以使用迭代器区间构建新的vector对象。例如上面提到的char类型的vector和char类型的string是可以匹配的。

1.2.3 vector的初始化
void test_vector2()
{vector<int> v;v.reserve(10);//开空间改变容量,但不初始化//错误访问——————下标引用操作符会检查插入位置是否合法,即小于_size//for (size_t i = 0; i < 10; i++)//{// v[i] = i;//}//正确访问for (size_t i = 0; i < 10; i++){v.push_back(i);}v.resize(20);//开空间+初始化
}
上述示例中,提到了我在OJ题中经常弄糊涂的内容,使用reserve进行初始化是最好的,因为不会像resize那样,擅自向vector中填入值,但使用后记得不要使用下标引用操作符去访问,而是使用push_back
1.2.4 insert\查找\排序
void test_vector3()
{int a[] = { 1,2,3,4,5 };vector<int> v(a, a + 5);//头插v.insert(v.begin(), 0); //第一个参数传入的是迭代器//在2前面插入vector<int>::iterator pos = find(v.begin(), v.end(), 2); //find函数位于算法库中algorithmif (pos != v.end()) //查找失败会返回end位置的迭代器{v.insert(pos, 20);}// 0 1 20 2 3 4 5 //sort排序sort(v.begin(), v.end()); // 0 1 2 3 4 5 20 sort(v.begin(), v.end(), greater<int>()); //greater<int>是一个仿函数类,需要调用库函数是functional// 20 5 4 3 2 1 0
}
上述例子注释写得很清楚,印象最深的是二叉树后序遍历可以巧用头插获取返回结果。下面主要讲解sort的第三个参数:
sort函数的第三个参数是可选的比较函数,用于指定排序时的元素比较规则。当不指定比较函数时,默认使用小于号进行比较,即升序。
在sort(v.begin(), v.end(), greater<int>())中,greater<int>()是一个函数对象,用于指定降序排序的比较规则。greater<int>()是一个模板类,它重载了函数调用运算符operator(),实现了比较规则。对于两个元素x和y,如果greater<int>()(x, y)返回true,则x会被排在y之前。
因此,sort(v.begin(), v.end(), greater<int>())实现了对容器v进行降序排序的操作,greater<int>()是用于指定比较规则的函数对象,它实现了元素的比较运算。
下面是一个简单的实现:
template<typename T>
struct greater
{bool operator()(const T& x, const T& y) const{return x > y;}
};
这个定义了一个模板类greater,它有一个函数调用运算符operator()。operator()接受两个参数x和y,表示要比较的两个元素,它的返回值是一个bool类型,表示x是否应该排在y之前。在这个实现中,operator()的比较规则是x大于y,即从大到小排序。
1.2.5 erase删除
void test_vector4()
{int a[] = { 1,2,3,4,5 };vector<int> v(a, a + 5);//头删v.erase(v.begin()); //参数传入下标位置的迭代器,或迭代器区间//删除2vector<int>::iterator pos = find(v.begin(), v.end(), 2);if (pos != v.end()){v.erase(pos);}
}
上述例子中主要写了erase的使用方式,参数是一个vector的迭代器。
二、vector模拟实现
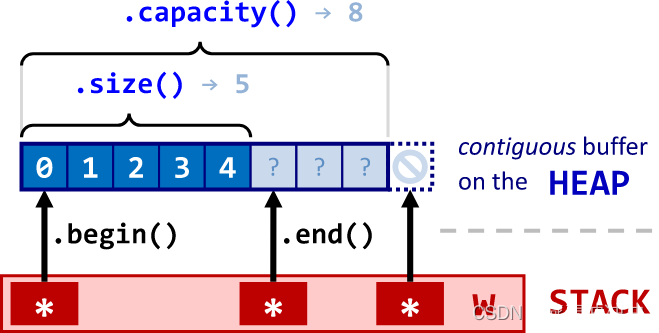
这个 vector 类中包含了:构造函数、拷贝构造、使用迭代器区间初始化的构造函数、析构。
实现了普通迭代器和只读迭代器,及其对应的begin()和end()函数。
这个类中的成员变量为私有类型的普通迭代器类型的。记录了vector开始位置、最后一个数据的下一个位置、最大容量的下一个位置。
size()和capacity()能返回容器的元素个数和已开辟空间大小。
reserve()用于为容器重新分配空间,如果分配的空间小于现有空间容量,则不处理。否则,会重新分配空间,拷贝现有数据到新空间,并修改成员变量。
insert()用于向容器中插入元素,插入时需要将所在位置及其以后的元素全部向后移动,移动时是从后往前。
erase()用于删除某个元素,参数为要删除元素的迭代器。删除后还需要从前往后开始,逐一将元素向前移动。
resize()用于调整空间大小,并将未初始化的位置赋予指定的值。当调整的空间小于现有元素个数,会舍弃掉多出的元素。当调整的大小介于元素个数和有效空间之间时,会初始化这些多出来的部分。当调整的大小大于有效空间时,会重新开辟空间,并将现有数据拷贝过去,然后初始化多余部分。
其他接口比较简单,就不再单独描述。
template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;vector():_start(nullptr),_finish(nullptr),_endofstorage(nullptr){}vector(const vector<T>& v):_start(nullptr), _finish(nullptr), _endofstorage(nullptr){reserve(v.capacity());for (const auto e : v) {push_back(e);}}template <class InputIterator>vector(InputIterator first, InputIterator last):_start(nullptr), _finish(nullptr), _endofstorage(nullptr){while (first != last) {push_back(*first);first++;}}~vector() {delete[] _start;_start = _finish = _endofstorage = nullptr;}iterator begin() {return _start;}iterator end() {return _finish;}const_iterator begin()const {return _start;}const_iterator end()const {return _finish;}size_t capacity() const{return _endofstorage - _start;}size_t size() const{return _finish - _start;}void reserve(size_t num) {if (num > capacity()) {size_t sz = size();T* tmp = new T[num];memcpy(tmp, _start, sz * sizeof(T));_start = tmp;_finish = _start + sz;_endofstorage = _start + num;}}iterator insert(iterator pos, const T& num){assert(pos >= begin() && pos <= end());if (_finish == _endofstorage) {size_t len = pos - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);pos = _start + len;}iterator end = _finish - 1;while (end >= pos) {*(end + 1) = *end;end--;}*pos = num;_finish++;return pos;}iterator erase(iterator pos) {assert(pos >= begin() && pos < end());//删除指定下标的数据,并把其后的数据依次向前挪动iterator it = pos + 1;while (it != end()){*(it - 1) = *it;it++;}--_finish;return pos;}void push_back(const T& num){insert(end(), num);}T& operator[](size_t i) {assert(i < size());return *(_start + i);}void swap(vector<T>& v) {std::swap(v._start, _start);std::swap(v._finish, _finish);std::swap(v._endofstorage, _endofstorage);}vector<T>& operator=(vector<T> v) {swap(v);return *this;}void resize(size_t n, const T& val = T()) {//开的空间小于size(把超出范围的舍弃)介于size和capacity(初始化_finish以后的空间)//大于capacity(要重新开空间,并且初始化_finish以后的空间)if (n <= size()){_finish = _start + n;}else{if (n > capacity()){reserve(n);}while (_finish < _start + n) {*_finish = val;_finish++;}}}private:iterator _start;iterator _finish;iterator _endofstorage;};

三、reverse浅拷贝Bug
不难发现,在上述模拟实现的vector::reverse()中,如果模版类型T为std::string,那string中含有一些指针成员变量,通过memcpy将其浅拷贝到新空间后,又进行了一次delete,在生命周期结束时,也会进行delete,就会造成崩溃。
3.1 解决方案
既然要销毁原有空间,那为何不通过std::move将左值转换为右值,然后拷贝到新空间去。
下面通过伪代码进行举例:
template <typename T>
void MyVector<T>::reserve(size_t newCapacity)
{if (newCapacity <= m_capacity)return;T* newData = new T[newCapacity];for (size_t i = 0; i < m_size; i++){newData[i] = std::move(m_data[i]); // 深复制}delete[] m_data;m_data = newData;m_capacity = newCapacity;
}
上述代码没有考虑使用迭代器成员变量,容量和有效数据数量均为size_t类型,数据类型为T*
在这个实现中,我们使用了 std::move 函数将 m_data[i] 的内容移动到 newData[i] 中,从而进行深复制,避免了多个 std::string 对象共享同一块内存空间的问题。同时,在析构函数中也只需要简单地使用 delete[] 删除 m_data 指向的内存即可。
3.2 move函数
std::move 是一个 C++11 中引入的函数,它能够将一个对象的值转移到另一个对象中,同时将原对象置于一种“移动状态”,从而避免不必要的对象复制和销毁。
std::move 本质上是将一个左值引用转换成右值引用。在 C++ 中,左值引用是指向左值的引用,右值引用是指向右值的引用。左值是可以取地址的、有持久性的、具名的、具有明确定义的生命周期的值,而右值则是无法取地址的、临时的、没有名称的、生命周期不确定的值。在 C++11 中,我们可以通过使用 && 运算符来声明右值引用。
具体来说,当我们调用 std::move 函数时,它将接受一个左值引用,并返回一个右值引用,表示该对象的值可以被移动。通常情况下,我们会将返回的右值引用绑定到另一个对象上,从而将原对象的值移动到新对象中。例如:
std::vector<int> v1{1, 2, 3};
std::vector<int> v2 = std::move(v1); // 将 v1 的值移动到 v2 中
需要注意的是,在使用 std::move 移动对象时,只会移动对象的值,也就是说会将对象的成员变量的值复制到新的内存位置,但不会复制对象的状态,比如对象的引用计数、对象的资源句柄等等。移动完成后,原对象的值会被置为“移后”的状态,这个状态下对象的行为是未定义的,我们不能再对其进行读取或修改。在移动一个对象之后,如果我们需要继续使用该对象,就必须重新对其进行赋值或初始化。
相关文章:
vector你得知道的知识
vector的基本使用和模拟实现 一、std::vector基本介绍 1.1 常用接口说明 std::vector是STL中的一个动态数组容器,它可以自动调整大小,支持在数组末尾快速添加和删除元素,还支持随机访问元素。 以下是std::vector常用的接口及其说明…...
【C++进阶】四、AVL树(二)
目录 前言 一、AVL树的概念 二、AVL树节点的定义 三、AVL树的插入 四、AVL树的旋转 4.1 左单旋 4.2 右单旋 4.3 左右双旋 4.4 右左双旋 五、AVL树的验证 六、AVL树的性能 七、完整代码 前言 前面对 map/multimap/set/multiset 进行了简单的介绍,在其文…...
React 服务端渲染
React 服务器端渲染概念回顾什么是客户端渲染CSR(Client Side Rendering)服务器端只返回json数据,Data和Html的拼接在客户端进行(渲染)。什么是服务器端渲染SSR(Server Side Rendering)服务器端返回数据拼接过后的HTML,Data和Html…...
)
【算法设计-搜索】回溯法应用举例(1)
文章目录0. 回溯模板1. 走楼梯2. 机器走格子,但限定方向3. 中国象棋,马走日字4. 走迷宫5. 积木覆盖0. 回溯模板 搜索算法中的回溯策略,也是深度优先搜索的一种策略,比较接近早期的人工智能。毕竟,搜索是人工智能技术中…...

C++基础了解-23-C++ 多态
C 多态 一、C 多态 多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。 C 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。 下面的实例中,基类 Shape 被…...
【GNN/深度学习】常用的图数据集(资源包)
【GNN/深度学习】常用的图数据集(图结构) 文章目录【GNN/深度学习】常用的图数据集(图结构)1. 介绍2. 图数据集2.1 Cora2.2 Citeseer2.3 Pubmed2.4 DBLP2.5 ACM2.6 AMAP & AMAC2.7 WIKI2.8 COCS2.9 BAT2.10 EAT2.11 UAT2.12 C…...
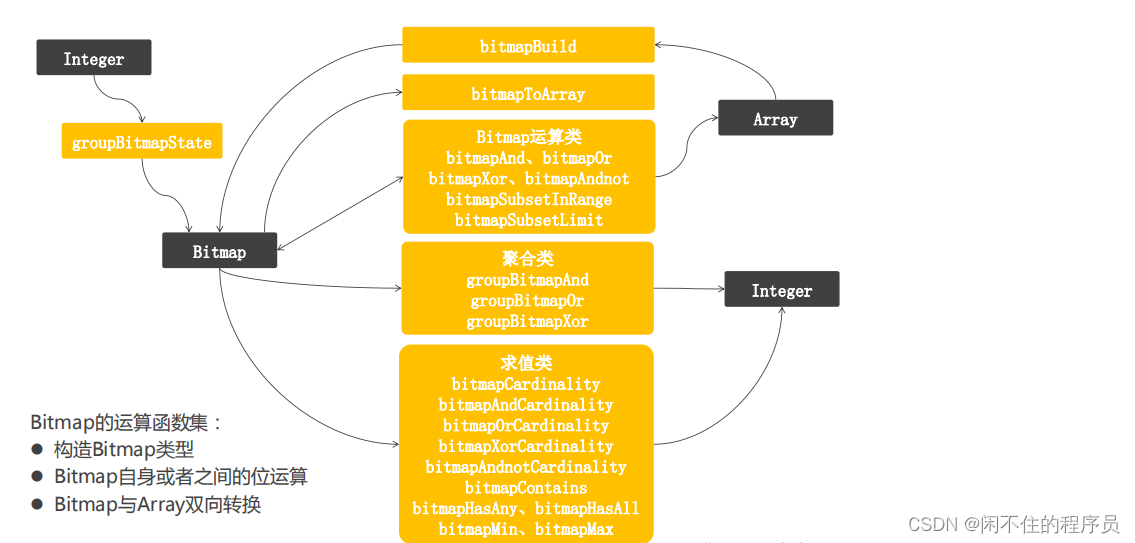
Clickhouse中bitmap介绍以及计算留存Demo
前言 参考了腾迅的大数据分析-计算留存,能够根据用户自定义属性,以及玩家行为进行留存的计算。最初计算留存的方法使用的是clickhosue自带的rentention函数,使用这个函数不用关注太多细节,只需要把留存条件放入函数即可。但是这个如果需要关联用户属性,就比较麻烦了。因此…...

大数据是什么?学习后能找高薪工作么
大数据是什么,比较官方的定义是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 简单来说,大数据就是结构化的…...

如何提取视频中的音频转文字?分享提效减负视频转文字方法
最近我在学做短视频,就看了很多博主怎么做视频,像他们的拍摄方法、剪辑角度还有怎么写文案。我一开始只看了一两个博主,写文案时就是边看视频边打字,这视频量少还好,视频多了就觉得这种方法好费时间,感觉一…...

脑机接口科普0018——前额叶切除手术
本文禁止转载!!! 首先说明一下,前额叶切除手术,现在已经不允许做了。 其次,前额叶切除手术,发明这个手术的人居然还获得了诺贝尔奖。太过于讽刺。1949年的那次诺贝尔医学奖(就是我…...

FPGA工程师面试——基础知识
1. 简述FPGA等可编程逻辑器件设计流程 答:系统设计电路构思,设计说明与设计划分, 电路设计与输入(HDL代码、原理图), 功能仿真与测试, 逻辑综合, 门级综合, 逻辑验证与测…...

全国青少年软件编程(Scratch)等级考试一级真题——2019.12
青少年软件编程(Scratch)等级考试试卷(一级)分数:100 题数:37一、单选题(共25题,每题2分,共50分)1.下列关于舞台的描述,不正确的是?( )…...

【Integrated Electronics系列——数字电子技术基础】
目录 序言...

【微信小程序】-- 页面处理总结(三十一)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

Spring Batch使用详细例子
Spring Batch 是一个开源的批处理框架,它提供了一种简单的方式来处理大规模的数据处理任务。它基于 Spring 框架,可以与 Spring 的其他组件无缝集成,如 Spring Boot、Spring Data 等。本文将介绍如何使用 Spring Batch 进行批处理任务。 1. 准…...

漏洞预警|Apache Dubbo 存在反序列化漏洞
棱镜七彩安全预警 近日网上有关于开源项目Apache Dubbo 存在反序列化漏洞,棱镜七彩威胁情报团队第一时间探测到,经分析研判,向全社会发起开源漏洞预警公告,提醒相关安全团队及时响应。 项目介绍 Apache Dubbo 是一款 RPC 服务开…...

Tomcat源码分析-spring boot集成tomcat
SPI 在分析源码前,我们先来了解下 spring 的 SPI 机制。我们知道,jdk 为了方便应用程序进行扩展,提供了默认的 SPI 实现(ServiceLoader),dubbo 也有自己的 SPI。spring 也是如此,他为我们提供了…...
一个古老的html后台的模板代码
效果图下: css部分代码:/* CSS Document / body{font-family:“宋体”, Arial,Verdana, sans-serif, Helvetica;font-size:12px;margin:0;background:#f4f5eb;color:#000;} dl,ul,li{list-style:none;} a img{border:0;} a{color:#000;} a:link,a:visit…...
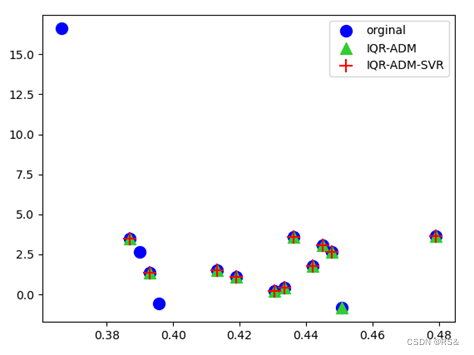
支持向量回归删除异常值Python
1、支持向量回归(SVR)原理 支持向量回归(Support Vector Regression,SVR)不仅可以用于预测,还可以用于异常值检测。其基本思路是训练一个回归模型,通过对每个数据点进行预测,并计算…...
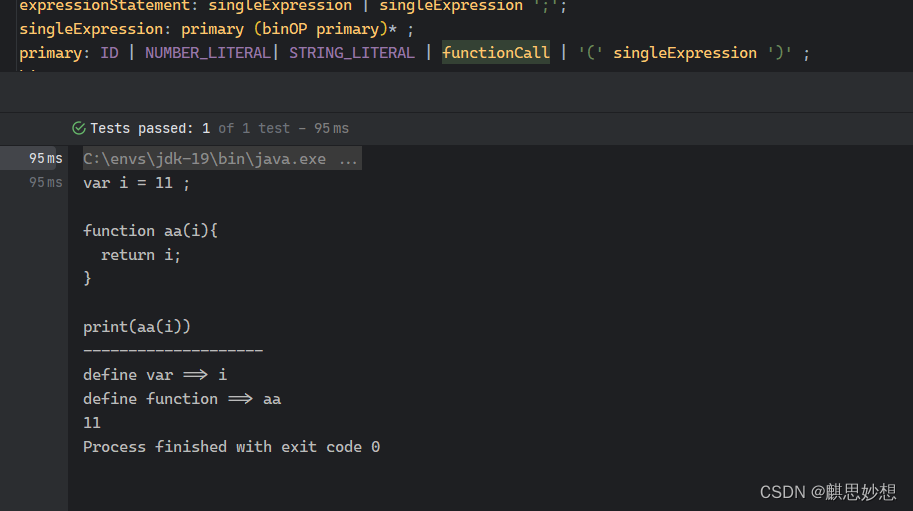
手把手开发一门程序语言JimLang (2)
根据爱因斯坦的相对论,物体的质量越大,时间过得越快,所以托更对于我的煎熬,远远比你们想象的还要痛苦…今天给大家来盘硬菜,也是前些时日预告过的JimLang的开发过程… Let’s go !!! 语法及解析 JimLang.g4 这里我们…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...