OceanBase 4.3.0 列存引擎解读:OLAP场景的入门券
近期,OceanBase 发布了4.3.0版本,该版本成功实现了行存与列存存储的一体化,并同时推出了基于列存的全新向量化引擎和代价评估模型。通过强化这些能力,OceanBase V4.3.0 显著提高了处理宽表的效率,增强了在AP(分析处理)场景下的查询性能,并依旧保持着对TP业务的良好支持。
这篇文章是基于列存功能进行的一次简单测试,并结合测试结果给出了一些面向用户的使用建议。
背景
首先需要给大家简单介绍一个背景知识点,就是OceanBase 存储层架构图中的 “基线数据” 和 “增量数据” 分别指什么?
存储层架构图如下:
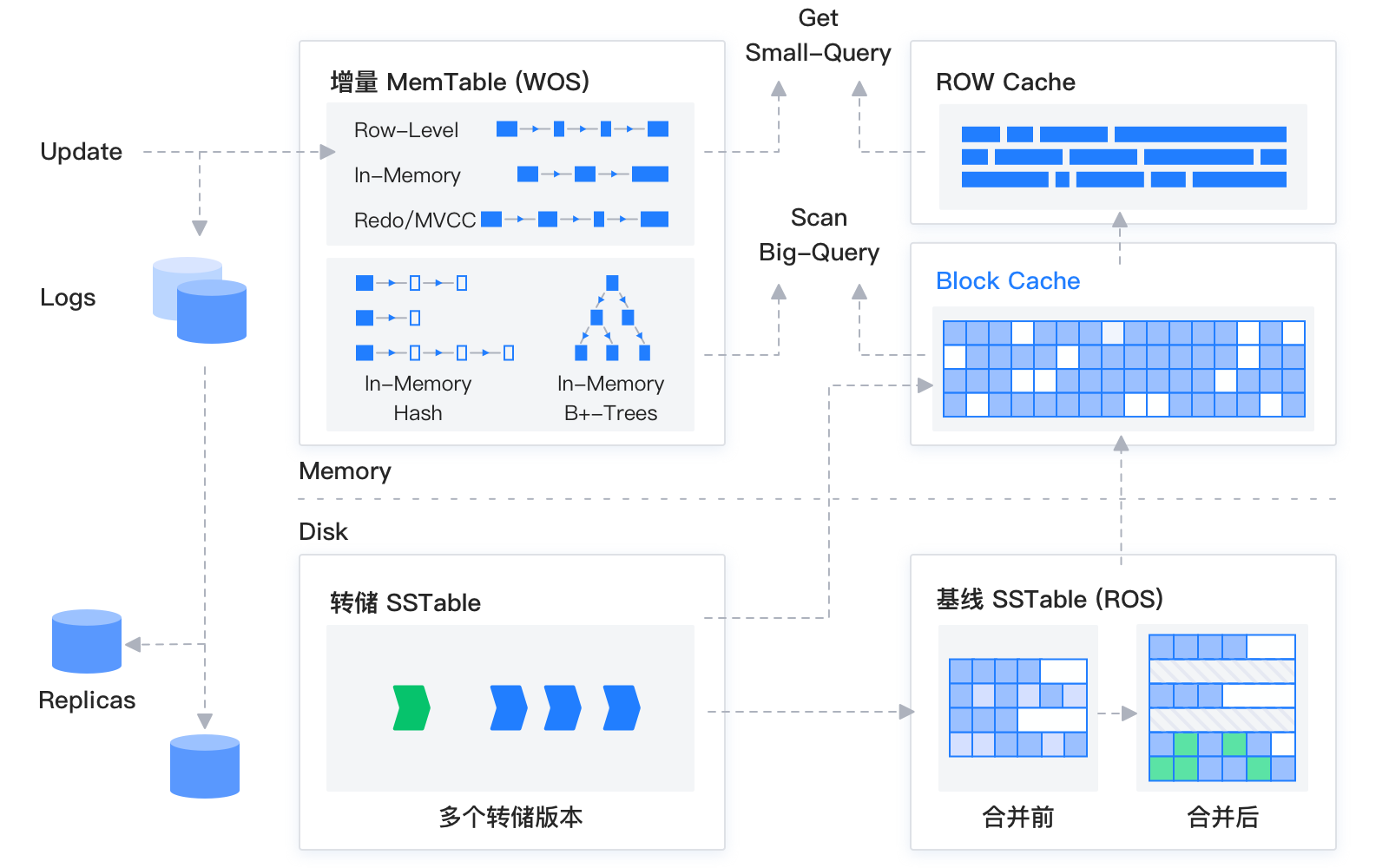
OceanBase 数据库的存储引擎基于 LSM-Tree 架构,将数据分为静态的基线数据和动态的增量数据两部分。
数据库 DML 操作插入、更新、删除时,首先写入内存中的 MemTable,等内存中的 MemTable 达到一定大小时,转储到磁盘成为 SSTable,内存中的 MemTable 和转储之后的 SSTable 被统称为增量数据。当增量的数据达到一定规模的时候,会触发增量数据和老版本基线数据的合并,合并成新版本的基线数据,也就是新版本的基线 SSTable。同时每天晚上的空闲时刻,系统也会自动每日合并。
在进行查询时,需要分别对增量数据和基线数据进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。OceanBase 也数据读取过程中实现了 Block Cache 和 Row Cache 两层缓存,来避免对基线数据的随机读。
列存整体架构
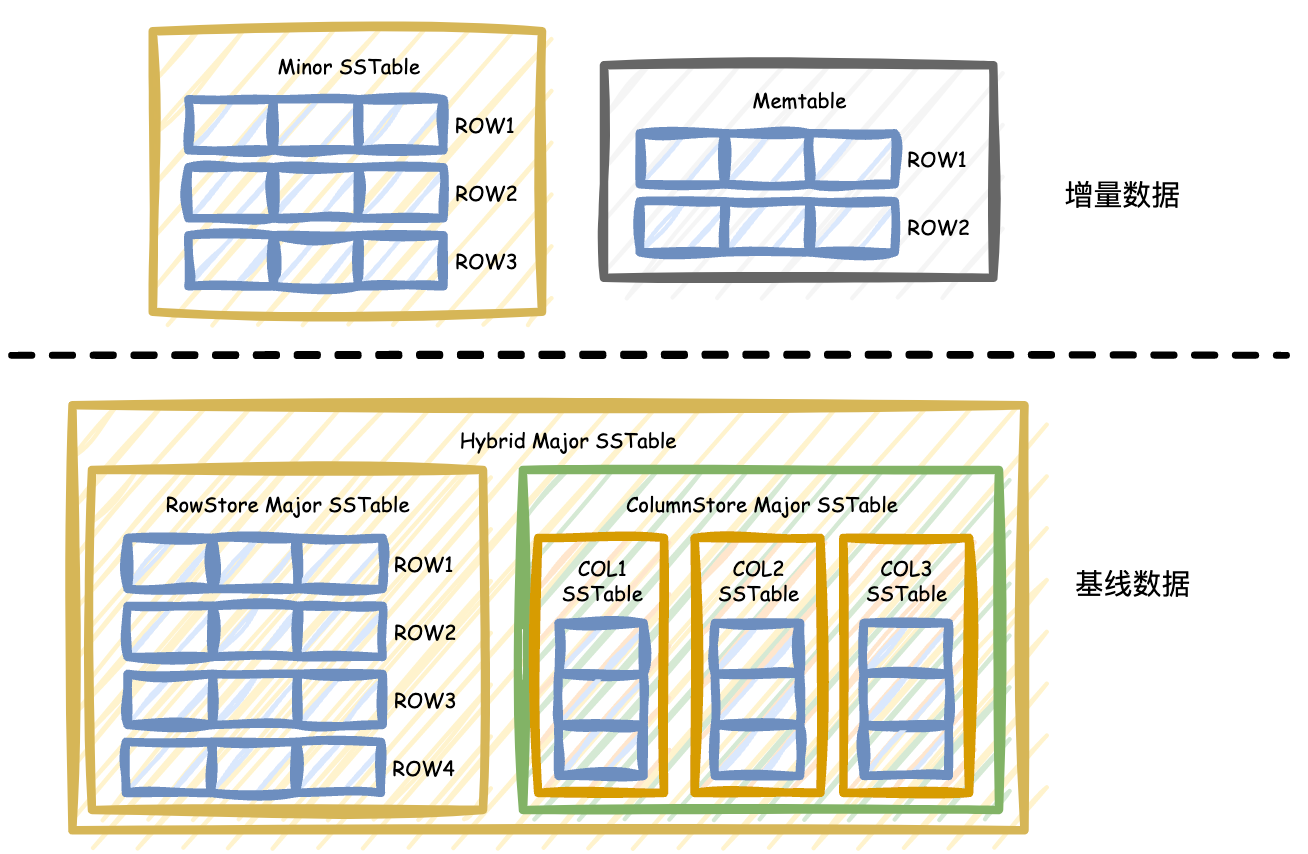
对于 AP 分析类查询,列存可以极大地提升查询性能,也是 OceanBase 做好 HTAP 的一项不可缺少的功能。用于进行 AP 分析的数据通常都是静态的,很少被原地更新,而 OceanBase 的 LSM Tree 架构中基线数据也是静态的,天然就适合列存的实现。增量数据是动态的,即使在列存表中,存储层的增量数据仍然是行存,同步的日志也都是行存模式,对于事务处理、日志同步、备份恢复都不会造成影响。这样就可以在一定程度上兼顾 TP 类和 AP 类查询的性能。
在 OceanBase 4.3 版本中创建表时,可以选择把表创建成行存表、列存表、行列冗余存储的表。无论是什么模式的表,表的增量数据均保持行存格式,因此列存表的 DML、事务、上下游数据同步都不会受到影响。
列存表和行存表在存储层的区别主要体现在基线数据的格式上,根据用户在建表时的设置,基线数据可以有行存,列存,行存列存冗余三种模式。
行存模式下,基线数据也是行存,如下图所示:

列存模式下,每列数据在基线数据中存储为一个独立的基线 SSTable,和行存有所不同,如下图所示:

行存列存冗余的模式下,在基线数据中会同时存储行存 SSTable 和列存 SSTable,如下图所示:
在这种行存列存冗余的模式下,优化器会根据访问行存和访问列存的代价高低,自动选择扫描列存 SSTable 还是行存 SSTable。
例如我们创建一个行列冗余存储的表 t_column_row。建表语句中的 with column group (all columns, each column) 表示这张表是行列冗余存储,其中的 each column 表示列存,all columns 表示再增加一份儿行存。
create table tt_column_row(c1 int primary key, c2 int , c3 int) with column group (all columns, each column);如果我们不加过滤条件,查询表中的一个列的全量数据,就会生成下面的执行计划,计划中的 COLUMN TABLE FULL SCAN 算子表示优化器根据代价模型,选择扫描列存的基线数据。因为相比选择扫描行存数据,扫描列存数据会在存储层减少 c2 和 c3 列数据的额外 I/O 开销。
explain select c1 from t_column_row;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| ============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|t_column_row|1 |3 | |
| ============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t_column_row.c1]), filter(nil), rowset=16 |
| access([t_column_row.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t_column_row.c1]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------+如果我们不指定过滤条件进行全表扫,就会生成下面的执行计划,计划中的 TABLE FULL SCAN 算子表示优化器选择扫描行存的基线数据。因为行存的增量数据和基线数据的格式都是行存,所以增量和基线归并起来速度会更快,这时候优化器会选择生产走行存的计划。
explain select * from t_column_row;
+-----------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------+
| ======================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------- |
| |0 |TABLE FULL SCAN|t_column_row|1 |3 | |
| ======================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t_column_row.c1], [t_column_row.c2], [t_column_row.c3]), filter(nil), rowset=16 |
| access([t_column_row.c1], [t_column_row.c2], [t_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t_column_row.c1]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------------------------------------+列存的基础性能测试
我这里使用 TPCH 100G 的测试集,对大家普遍比较关心的列存性能,进行了一个简单的测试,包括列存和行存的存储压缩率对比,以及列存的查询性能测试。版本是社区版的 OceanBase_CE-v4.3.0.1。
存储压缩率测试
首先对 OceanBase 4.3.0 版本的列存表压缩率做一个测试,对比行存表。
分别把 TPCH 100G 的数据导入一批纯行存表和一批纯列存表中,选择最大的一张表 lineitem 计算存储开销,导入的 lineitem.tbl 大小大约是 76 GB,在行存表中占用了 22.5 GB 的存储空间,在列存表里占用了 15 GB 的存储空间。
-- 列存表 lineitem 定义
CREATE TABLE lineitem (l_orderkey BIGINT NOT NULL,l_partkey BIGINT NOT NULL,l_suppkey INTEGER NOT NULL,l_linenumber INTEGER NOT NULL,l_quantity DECIMAL(15,2) NOT NULL,l_extendedprice DECIMAL(15,2) NOT NULL,l_discount DECIMAL(15,2) NOT NULL,l_tax DECIMAL(15,2) NOT NULL,l_returnflag char(1) DEFAULT NULL,l_linestatus char(1) DEFAULT NULL,l_shipdate date NOT NULL,l_commitdate date DEFAULT NULL,l_receiptdate date DEFAULT NULL,l_shipinstruct char(25) DEFAULT NULL,l_shipmode char(10) DEFAULT NULL,l_comment varchar(44) DEFAULT NULL,PRIMARY KEY(l_orderkey, l_linenumber))row_format = condensedpartition by key (l_orderkey) partitions 4with column group(each column);对于 lineitem 这张表的表结构来说,列存表的存储空间大约是行存表的 2/3 左右。这一点大家也容易理解,相比行存表,列存表中同一列中的数据属于同一类型,如果能够集中存储同一类型的数据,就可以选择效率更高的方式进行压缩。

为什么列存的压缩效果对比行存,看上去并没有想象中的这么强?因为 OceanBase 的行存表,压缩能力已经非常好了。不过即使我们在行存表的存储压缩上做过诸多优化,列存的压缩效果也会比行存表稍好一些,并且表中的列越多,数据量越大,列存的压缩效果就会越明显。
查询性能测试
找了三台 6C 35G 的机器做测试(后续所有功能都在这几台机器上做的测试),简单对比行存表和列存表的一些查询性能。

我们创建了两张表,一张是纯行存表 lineitem_row,一张是纯列存表 lineitem_column,都导入了 TPCH 100G 的数据集。
走主键点查
先通过两条 SQL 测下列存表和行存表走主键时的点查性能:
-- 列存
select * from lineitem_column where l_orderkey = 7 and l_linenumber = 1;
1 row in set (0.035 sec)select * from lineitem_column where l_orderkey = 7;
7 rows in set (0.036 sec)-- 行存
select * from lineitem_row where l_orderkey = 7 and l_linenumber = 1;
1 row in set (0.044 sec)select * from lineitem_row where l_orderkey = 7;
7 rows in set (0.044 sec)行存和列存走主键的点查性能都在 0.04 秒左右,基本是一致的(为避免篇幅过长,图中只展示 SQL 的执行时间,不再展示查询的结果数据)。
无索引全表扫
我们不走主键和索引,分别在列存表和行存表中执行以下 SQL:
-- 列存
select * from lineitem_column where l_extendedprice = 13059.24;
102 rows in set (0.467 sec)-- 行存
select * from lineitem_row where l_extendedprice = 13059.24;
102 rows in set (2.306 sec)返回的行数是 102 行,行存表执行时间在 2.31 秒左右,列存表的执行时间在 0.47 秒左右。对于 lineitem 这种有十几个列的小宽表,列存表的性能是行存表的五倍。
过滤条件不走宽表的主键和索引时,虽然列存需要拼各个列的结果,这一步会比行存表更耗时。但列存相比行存,可以省下大量的 I / O 开销,行存表在这里是做了一次真正的 “全表扫描”。
在过滤条件中只有单列,并且没能走主键和索引的前提下,表越宽(列数越多),相比行存表,列存表的查询性能就会越好。在这个例子中,行存表如果想通过省下 I / O 开销来提高性能,需要在 l_extendedprice 列上创建索引。所以在一些场景下,列存表相对于行存表,可以节省一些创建和维护索引的额外开销。
在不走主键和索引的前提下,我们把过滤条件变的更复杂一些,让过滤条件中包含多个列的计算:
-- 列存
select * from lineitem_column where l_partkey + l_suppkey = 20999999;
7 rows in set (5.091 sec)-- 行存
select * from lineitem_row where l_partkey + l_suppkey = 20999999;
7 rows in set (6.254 sec)这次列存性能还是强于行存,但是只是略强,优势没有上面这个测试好几倍的性能差距了。
我们继续让过滤条件中包含更多个列的计算:
-- 列存
select * from lineitem_column where l_partkey + l_suppkey +l_extendedprice + l_discount + l_tax = 19173494.34;
1 row in set (15.675 sec)-- 行存
select * from lineitem_row where l_partkey + l_suppkey +l_extendedprice + l_discount + l_tax = 19173494.34;
1 row in set (15.837 sec)我们可以发现一个规律,当过滤条件的表达式中涉及的列数持续增加时,行存表的性能会逐渐逼近列存表。
简单来说,在列存表中,需要先根据主键值,把不同列的对应行拼在一起,然后才能做列与列之间的运算,拼列并在不同列间做计算的操作会为列存表带来额外的开销,当这个开销逐渐逼近在行存表中额外列的 I/O 开销时,行存表的性能就会逐渐逼近列存表。
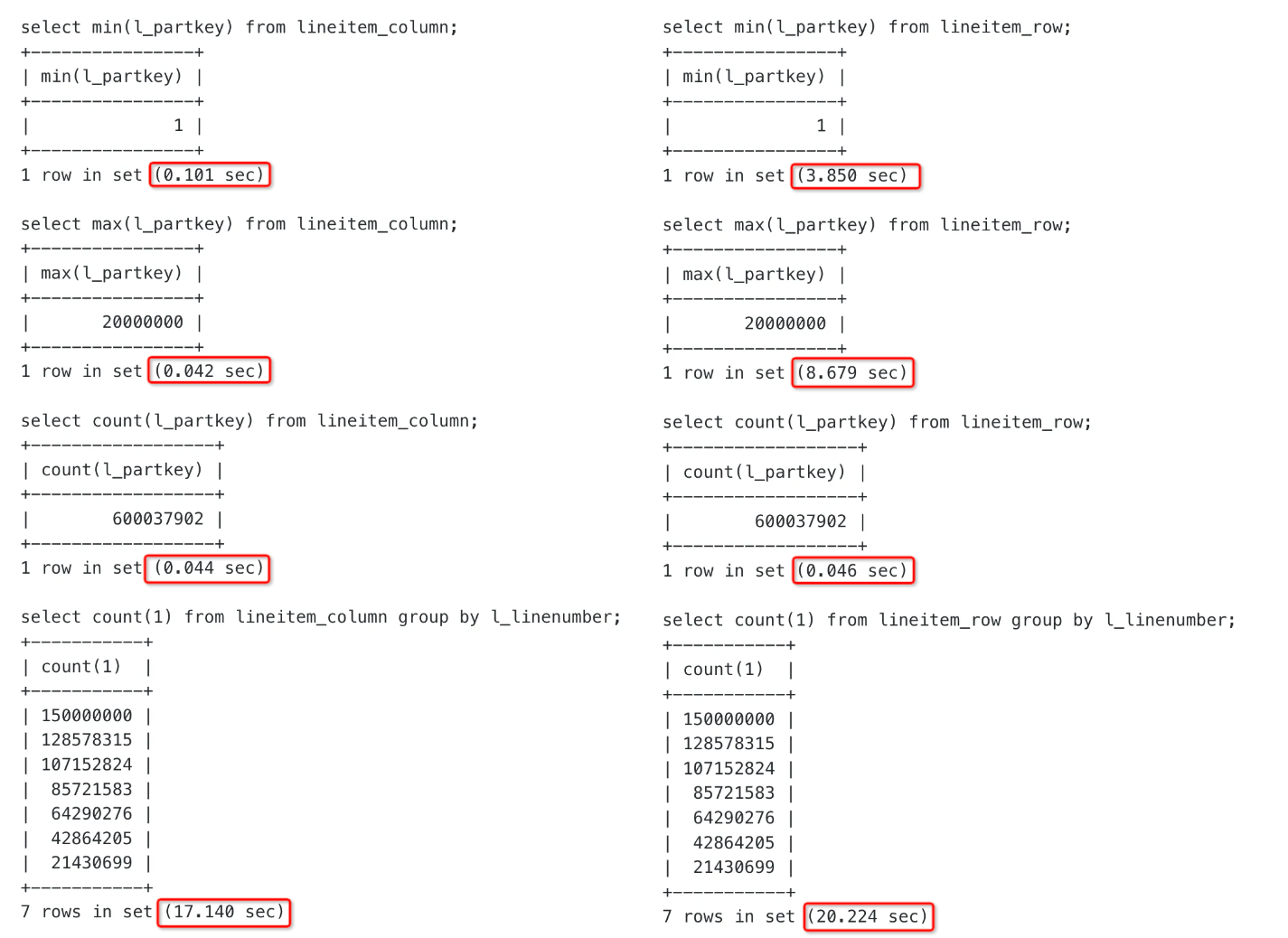
聚合计算
对于简单聚合,列存表的性能比行存表更好一些。下图左边的 lineitem_column 为列存表,右边的 lineitem_row 为行存表。
对于复杂一些的聚合计算,例如 max(l_partkey + l_suppkey),列存和行存的性能如下:
-- 列存表
select max(l_partkey + l_suppkey) from lineitem_column;
+----------------------------+
| max(l_partkey + l_suppkey) |
+----------------------------+
| 20999999 |
+----------------------------+
1 row in set (19.302 sec)-- 行存表
select max(l_partkey + l_suppkey) from lineitem_row;
+----------------------------+
| max(l_partkey + l_suppkey) |
+----------------------------+
| 20999999 |
+----------------------------+
1 row in set (4.833 sec)在有表达式的聚合计算测试中,列存表的性能明显是不如行存表的。一个原因是刚刚提到过的,在列存表中,需要先把 l_partkey 和 l_suppkey 两列的对应行拼在一起,然后才能做加法运算,拼列并在不同列间做计算的操作会为列存表带来额外的开销。另一个原因就是当前的 4.3.0.1 版本,在列存的表达式过滤这里做了比较深入的向量化执行优化,而列存的表达式聚合优化则被排期在了后续的版本中。
我们可以得出一个结论:聚合函数中包含多列表达式运算的场景,不是当前列存版本的优势场景。不过 lineitem 这张表的表结构中列数并不多,如果测试的表是大宽表,例如有几百或者上千个列,在同样的场景下,因为列存表相比行存表节省的 I/O 开销会比 lineitem 表更多,上述测试结果可能会有所变化。
更新不同百分比的列存数据,对查询性能的影响
因为列存表的基线数据和增量数据格式不同,所以如果增量数据较多的场景下,在查询时进行增量数据和基线数据归并的过程中,需要对行、列数据的格式进行转换和整合,这里必然会比行存表增加一些额外的开销。
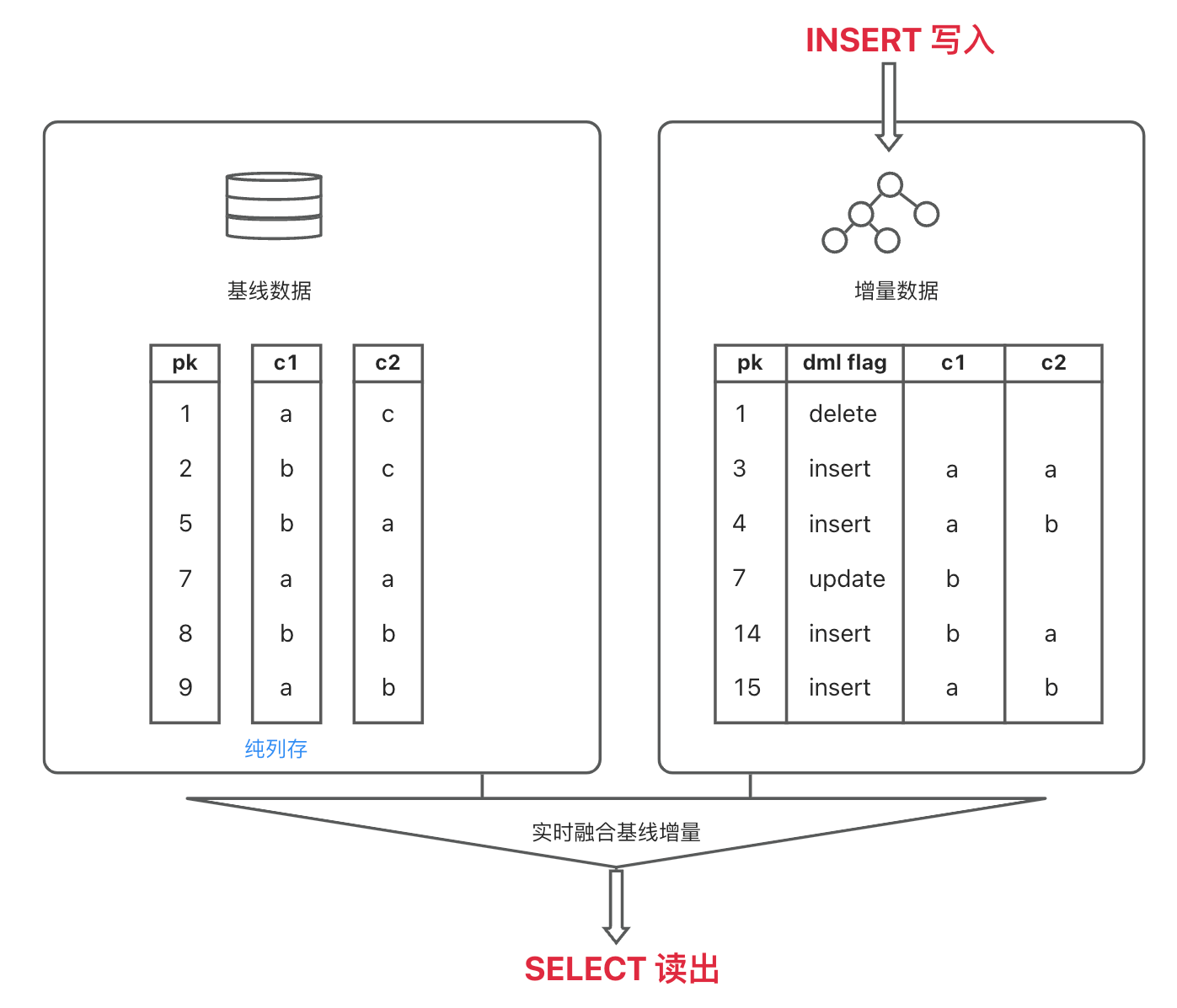
我们通过更新不同百分比的连续列存数据来进行一个测试,因为 l_orderkey 列是均匀分布的,所以我们通过 l_orderkey 的不同范围来改不同比例的数据,例如:
-- l_orderkey 在 1 到 600000000 之间均匀分布
-- 通过 where l_orderkey <= 6000000 更新百分之一的数据
-- 因为 l_orderkey 是主键列,所以更改的数据也可以保证是连续的
update lineitem_column set l_partkey = l_partkey + 1,l_suppkey = l_suppkey - 1,l_quantity = l_quantity + 1,l_extendedprice = l_extendedprice + 1,l_discount = l_discount + 0.01,l_tax = l_tax + 0.01,l_returnflag = lower(l_returnflag), l_linestatus = lower(l_linestatus),l_shipdate = date_add(l_shipdate, interval 1 day),l_commitdate = date_add(l_commitdate, interval 1 day),l_receiptdate = date_add(l_receiptdate, interval 1 day),l_shipinstruct = lower(l_shipinstruct),l_shipmode = lower(l_shipmode),l_comment = upper(l_comment)where l_orderkey <= 6000000;
Query OK, 6001215 rows affected (4 min 2.397 sec)
Rows matched: 6001215 Changed: 6001215 Warnings: 0-- 多次执行走主键查询
select * from lineitem_column where l_orderkey = 7;
select * from lineitem_column where l_orderkey = 600000000;
(0.036 sec)-- 多次执行不走主键查询
select * from lineitem_column where l_suppkey = 825656;
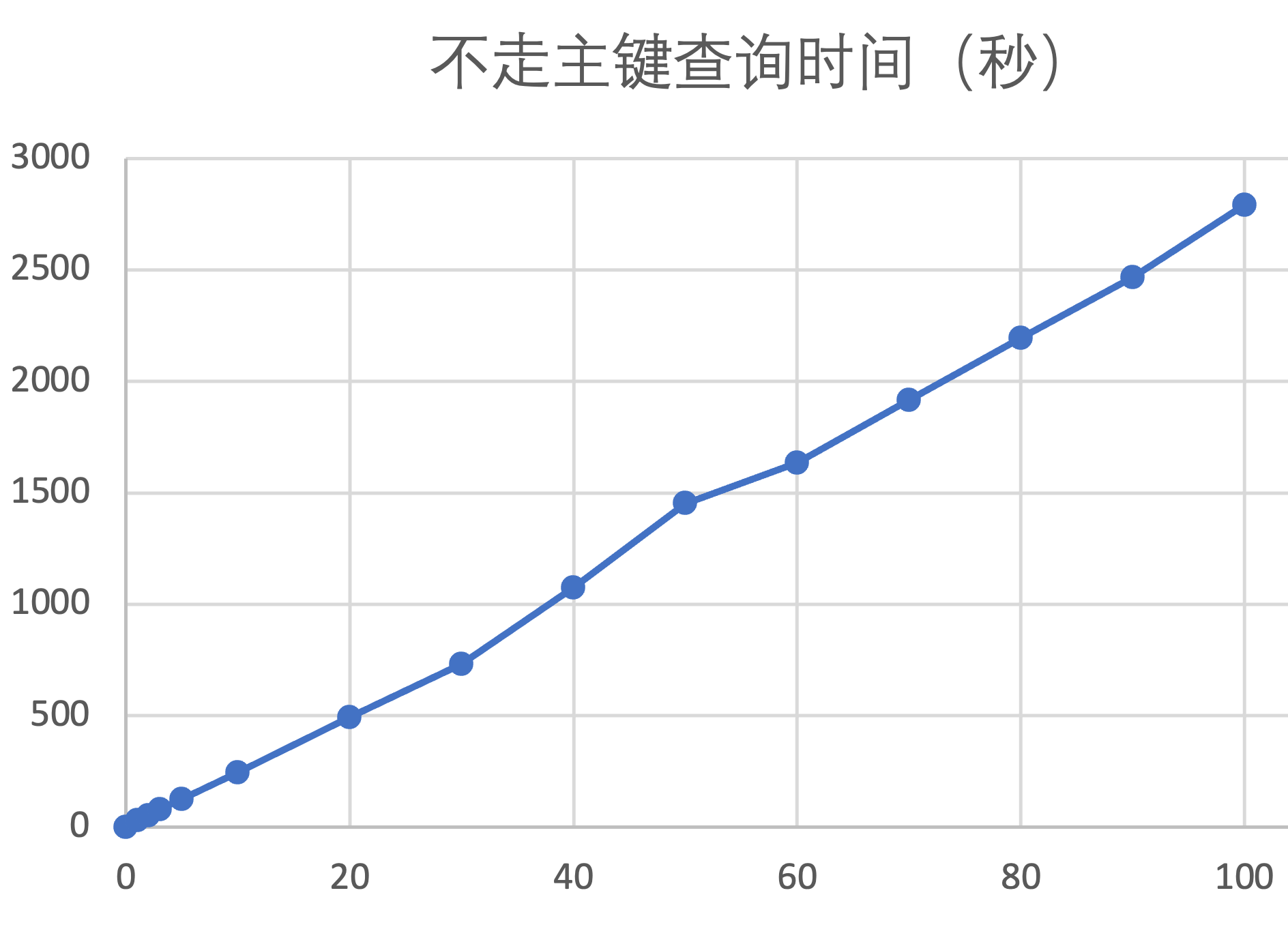
(31.722 sec)以下是更改列存表不同数据百分比后,走主键查询时间,以及不走主键查询时间:
| 列存表更新数据百分比(%) | 走主键查询时间(秒) | 不走主键查询时间(秒) |
| 0 | 0.03 | 0.5 |
| 1 | 0.03 | 32 |
| 2 | 0.03 | 54 |
| 3 | 0.03 | 80 |
| 5 | 0.03 | 126 |
| 10 | 0.03 | 245 |
| 20 | 0.03 | 495 |
| 30 | 0.03 | 733 |
| 40 | 0.03 | 1075 |
| 50 | 0.04 | 1453 |
| 60 | 0.04 | 1636 |
| 70 | 0.04 | 1916 |
| 80 | 0.04 | 2195 |
| 90 | 0.04 | 2468 |
| 100 | 0.04 | 2793 |
由上面的表格可以整理出下面这张曲线图,横轴是增量数据占全表数据的百分比,纵轴是不走主键(和索引)的查询时间。列存场景,在增量数据中更新不同百分比的数据(测试过程中一直不进行合并),对查询性能的影响曲线几乎是一条纯线性的直线。
这里需要注意的是:上述测试均是更新表中连续的数据。
如果是随机更新一定比例的非连续数据,性能会比更新连续数据更差。因为在 OceanBase 查询时,数据文件读 IO 的最小单位是 16KB 左右的变长数据块,我们称之为微块(Micro Block),如果修改的数据不连续,可能在修改表中少量的数据时,也能够改动到大量微块中的数据。所以即使我们只修改了 10% 的表数据,可能就已经修改了这张表所涉及到的 100% 的微块数据,这时候的查询性能和修改 100% 的表数据可能就不会有太大差别了。
完成这个测试之后,我们可以得到一个结论:对于列存表来说,如果存在大量更新操作,并且没有及时合并,查询性能是不优的。推荐批量导入数据后发起一次合并,这样可以获得最优的查询性能。
列存适用场景
根据上面的测试结果,咱们可以简单总结出 OceanBase 列存表的两个适用场景:
- 宽表场景。
- 当查询只需要扫描宽表的单列或者少数列时,列存表可以省下大量的磁盘 I / O 开销。行存宽表为了解决这个问题,需要再特定列上创建索引,让扫描主表的动作变为扫描列数更少的索引。所以列存表相比行存表,可以省下在特定列上创建索引的存储开销和索引的维护开销。
- 读多写少的 AP 数仓场景。
- 在数仓场景下,经常需要执行复杂的分析查询,但这些查询往往只关注表的某些特定列。列存表由于其数据按列存储,能够高效地支持这类 AP 查询,可以减少大量不必要的数据 I / O 开销。
- OceanBase 为了支持列存表频繁的小事务写入,避免列存表在数据更新操作上性能收到较大影响,让列存表的增量数据保持了行存的格式。因为列存表的基线数据和增量数据格式不同,如果增量数据较多的场景下,在查询时进行增量数据和基线数据归并的过程中,需要对行、列数据的格式进行转换和整合。这一步会比行存表增加额外的开销,并且对列数据的扫描耗时会随着增量数据的增长而线性增长,所以列存表更适合读多写少的场景。
列存基础语法
列存相关的语法在 OceanBase 官网上写的已经很清楚了,这里再 “冗余” 地介绍一遍。
租户级配置项
对于 OLAP 业务,我们推荐默认创建列存表,通过下面的配置项即可实现让租户创建出来的表默认就是列存表:
-- 修改配置项,对当前租户生效
alter system set default_table_store_format = "column"; // 默认创建列存表
alter system set default_table_store_format = "row"; // 默认创建行存表
alter system set default_table_store_format = "compound"; // 默认创建行列冗余存储的表-- 查看配置项的值(默认是 row)
show parameters like 'default_table_store_format';创建列存表
创建纯列存表的新语法是 with column group,当用户建表时最后指定 with column group(each column) 即代表创建纯列存表:
-- 创建纯列存表
create table t1 (c1 int, c2 int) with column group (each column);-- 创建纯列存分区表
create table t2(pk int,c1 int,c2 int,primary key (pk)
) partition by hash(pk) partitions 4
with column group (each column);对于部分场景,用户可以忍受一定程度的数据冗余,希望带来 AP / TP 业务场景的兼顾,此时可以增加行存数据的冗余,通过 with column group 语法增加 all columns 关键字即可:
-- 创建行列冗余存储表
create table t2 (c1 int, c2 int) with column group(all columns, each column);上述语法中的 with column group 后不同选项表示的含义如下:
-
-
- all columns:把所有列聚合在一起成组,看成一个宽列,其实就是:按行进行存储。
- each column:表中的每一列分别使用列格式来存储。
- all columns, each column 一起出现,意味着默认创建列存表后同时冗余行存, 每个副本存储两份基线数据。
-
创建列存索引
和创建列存表类似,也是通过 with column group 指定索引属性。注意这里不要和 “对列存建索引” 混淆,列存索引的含义是:索引表的存储结构是列存格式,相比行存索引,也可以减少存储层的 I / O 开销。
-- 在 t1 表的的 c1, c2 列上创建纯列存的索引
create index idx1 on t1(c1, c2) with column group(each column);-- 在 t1 表的的 c1 列上创建行列冗余存储的索引
create index idx2 on t1(c1) with column group(all columns, each column);-- 在 t1 表的的 c2 列上创建纯列存的索引,额外地存储非索引列 c1 列数据到索引中
alter table t1 add index idx3 (c2) storing(c1) with column group(each column);上述例子中,通过 storing(c1) 在索引中存储额外列的目的是:优化特定查询的性能,既能让查询避免回主表查询 c1 列的值,也可以减少为 c1 列进行索引排序的代价(idx3 中的 c1 列只是冗余存储在索引中,并不是索引列,索引只需要对 c2 列排序。如果 c1 列为索引列,则需要对 c2、c1 进行排序)。
explain select c1 from t1 order by c2;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|t1(idx3)|1 |5 | |
| ========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c2], [t1.__pk_increment]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+例如上面这条 SQL 的计划,利用 idx3 索引,可以消除对 c2 列的排序(计划中不需要分配 sort 算子),而且因为索引中冗余存储了一个非索引列 c1,所以不需要进行索引回表(is_index_back=false)。
行存表和列存表的相互转化
这几个存储格式相互转化的语法,着实有点儿绕。
行存转列存:
create table t1(c1 int, c2 int);-- 这个语法有点儿奇怪,add 这个关键字给人一种是行存表转行列冗余存储表的错觉……
alter table t1 add column group(each column);列存转行存:
alter table t1 drop column group(each column);行存转冗存(为了表达方便,“行列冗余存储” 在下面均被简称为“冗存”):
create table t1(c1 int, c2 int);alter table t1 add column group(all columns, each column);冗存转行存:
alter table t1 drop column group(all columns, each column);
说明:这里的 drop column group(all columns, each column); 执行后,不用担心没有任何 group 来承载数据,所有列会被放到一个叫做 DEFAUTL COLUMN GROUP 的默认 group 中。DEFAUTL COLUMN GROUP 中的存储格式,由租户级配置项 default_table_store_format 的取值决定,当没有修改过默认值(row)时,执行完成后 t1 就会变成纯行存表。
列存转冗存:
create table t1(c1 int, c2 int) with column group(each column);alter table t1 add column group(all columns);冗存转列存:
alter table t1 drop column group(all columns);列存相关 Hint
对于列存行存冗余表,优化器会根据代价选择走行存或者列存扫描。如果用户还是希望手动调优,走列存扫描,可以通过指定 USE_COLUMN_TABLE 这个 Hint 来强制走列存扫描。类似地,通过 NO_USE_COLUMN_TABLE 可以强制表走行存扫描:
explain select /*+ USE_COLUMN_TABLE(tt_column_row) */ * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| =============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_row|1 |7 | |
| =============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+explain select /*+ NO_USE_COLUMN_TABLE(tt_column_row) */ c2 from tt_column_row;
+------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c2]), filter(nil), rowset=16 |
| access([tt_column_row.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+------------------------------------------------------------------+如何通过计划判断是否走了列存?如上面的计划所示,扫描走行存时,explain 中显示的是 TABLE FULL SCAN,走到列存时,显示的是 COLUMN TABLE FULL SCAN。
列存使用建议
我们对列存进行了一些测试,并了解了列存的基础语法,最后简单总结下对 OceanBase 列存功能的使用建议。
- 对于新创建的 OceanBase 4.3.0 及以上版本的集群,并且应用场景是 OLAP 数据仓库。建议通过修改组户级配置项 default_table_store_format,让创建表时的默认存储格式为列存,该配置项的默认值是 row。
- 对于从低版本升级到 OceanBase 4.3.0 及以上版本的集群,并且希望利用新版本提供的列存能力来优化旧的行存表,OceanBase 提供两种方式:
- 创建列存索引。
- 优:在部分列上创建列存索引,适用于宽表场景。并且建列存索引是 Online DDL,不影响业务。
- 劣:增量数据需要在原表和索引表中写两份,写入增量数据时会占用更多内存和磁盘空间。
- 通过 alter table 修改原表的存储格式。
- 优:对写友好,增量数据只用在原表中写一份(增量数据都是行存格式)。
- 劣:属于 Offline DDL,执行 DDL 期间会锁表,无法更新数据。
- 创建列存索引。
- 行列冗余模式仅适用于 HTAP 场景,优化器会根据代价估算,自动选择对列数据的访问使用行存还是列存。纯 AP 场景,建议使用纯列存。
- 对于列存表来说,如果存在大量更新操作,并且没有及时合并,那么查询性能是不优的。推荐批量导入数据后发起一次合并,以获得最优的查询性能(列存表合并速度会比行存表慢一些)。合并操作需要在租户内执行 alter system major freeze; 然后在系统租户执行 select STATUS from CDB_OB_MAJOR_COMPACTION where TENANT_ID = 租户ID; 判断合并是否完成,当 STATUS 变为 IDLE 即表示合并完成。当然,也可以通过 OCP 白屏化工具完成合并操作。
- 合并后,推荐做一次统计信息收集。收集统计信息方法如下:
- 在业务租户一键对所有表收集统计信息,启动16个线程并发收集
CALL DBMS_STATS.GATHER_SCHEMA_STATS ('db', granularity=>'auto', degree=>16);
-
- 观测统计信息进度可以通过视图 GV$OB_OPT_STAT_GATHER_MONITOR。
6. 可以通过旁路导入来进行批量数据的导入,使用这种方式导入数据的表无需做合并,就能达到最优列存扫描性能。支持全量旁路导入的工具包括 obloader、原生 load data 命令。
7. 对于数据量较大的表,Cold Run 的性能一般会弱于 Hot Run。
8. 对于非大宽表场景,不使用列存也可能达到和列存相当的性能。这得益于 OceanBase 行存版本中微块级别的行列混合存储架构。
9. 还有哪些可以进一步提升列存表 AP 性能的方法?在实践中的经验分享:
-
- 如果用户或者业务可以接受的话,建表时候字符集不要使用 utf8mb4,而是使用 binary,可以提升性能。例如:
create table t1(c1 int, c2 int) CHARSET=binary with column group (each column);-
- 当 charset 需要是 utf8mb4 时,如果用户或者业务可以接受的话,在创建 mysql 租户时可以把 collation 指定为 utf8mb4_bin,如:locality = 'F@z1', collate = utf8mb4_bin。或者在建表时指定 utf8mb4_bin 字符集,建表时带上:CHARSET = utf8mb4 collate=utf8mb4_bin。
- 列存 PoC 推荐配置:
-- 设置 collation 为 utf8mb4_bin
set global collation_connection = utf8mb4_bin;
set global collation_server = utf8mb4_bin;set global ob_query_timeout=10000000000;
set global ob_trx_timeout=100000000000;
alter system set_tp tp_no = 2100, error_code = 4001, frequency = 1;
alter system set _trace_control_info=''
alter system set _rowsets_enabled=true;
alter system set _bloom_filter_enabled=1;
alter system set _px_message_compression=1;
set global _nlj_batching_enabled=true;
set global ob_sql_work_area_percentage=70;
set global max_allowed_packet=67108864;
set global parallel_servers_target=1000; -- 建议是 cpu 的 10 倍
set global parallel_degree_policy = auto;
set global parallel_min_scan_time_threshold = 10;
set global parallel_degree_limit = 0; alter system set _pushdown_storage_level = 4;
alter system set _enable_skip_index=true;
alter system set _enable_column_store=true;
alter system set compaction_low_thread_score = cpu_count;
alter system set compaction_mid_thread_score = cpu_count;未来展望
在 V4.3.x 后续版本,还会支持列存副本的形态,以减少 TP、AP 混合负载情况下,行存列存冗余带来的存储开销。
如下图:只读列存副本可以部署在独立的 Zone 里,不仅可以做到 TP 业务和 AP 业务的物理资源隔离,列存合并和行存合并也可以做到互不影响,适合读写并发都高的 HTAP 混合负载场景。
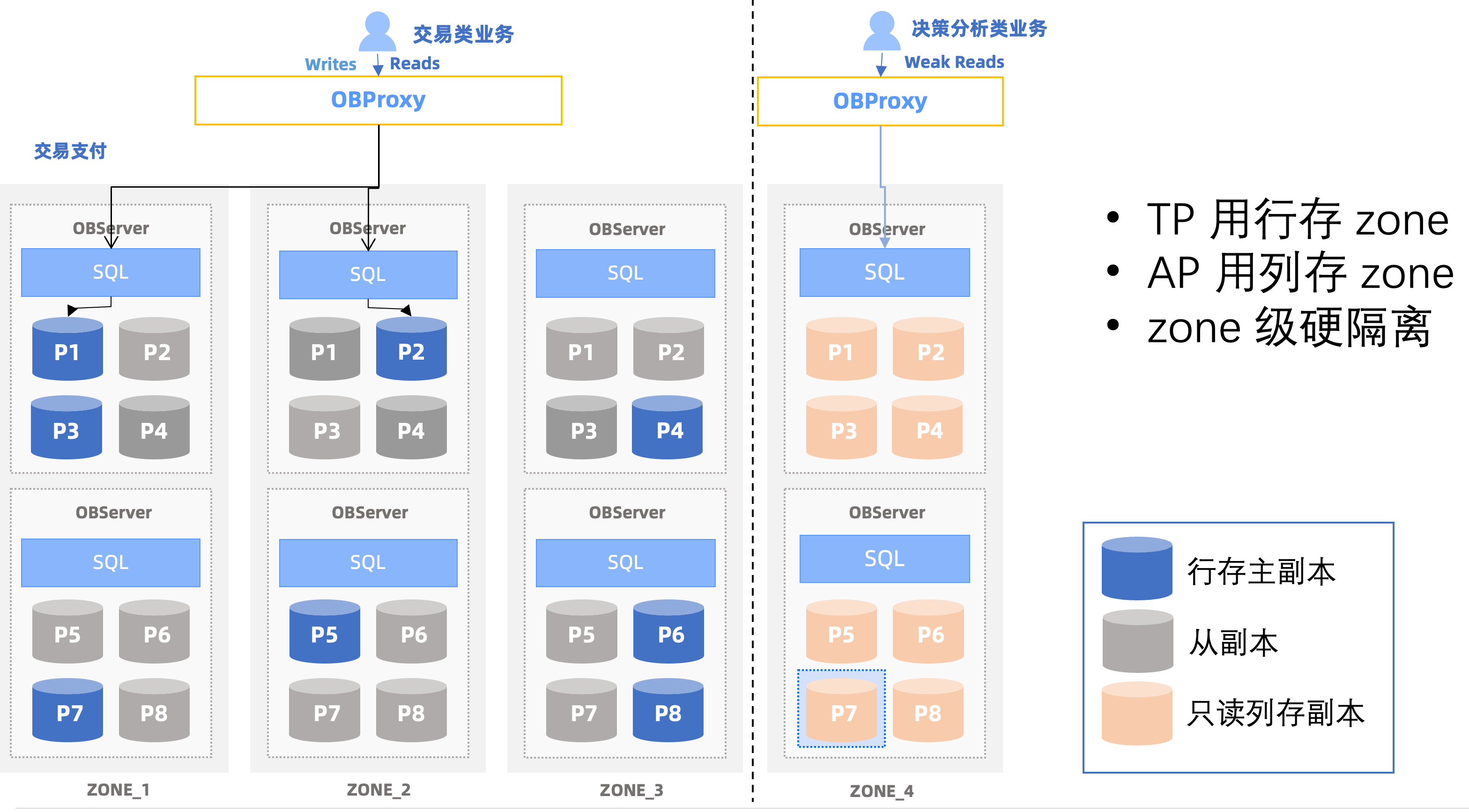
这篇博客到此为止,都是偏用户向的内容,对于大多数 OceanBase 列存版本的使用者来说,了解完这些内容,可以有很多参考了。
参考
- OceanBase 官网文档《列存》
- OceanBase 官网文档《创建索引》
- OceanBase 官网文档《更改表》
- 列存研发同学寒晖的博客《OceanBase v4.3 特性解读:查询性能提升之利器列存储引擎》
相关文章:
OceanBase 4.3.0 列存引擎解读:OLAP场景的入门券
近期,OceanBase 发布了4.3.0版本,该版本成功实现了行存与列存存储的一体化,并同时推出了基于列存的全新向量化引擎和代价评估模型。通过强化这些能力,OceanBase V4.3.0 显著提高了处理宽表的效率,增强了在AP࿰…...
算法每日一题(python,2024.05.25) day.7
题目来源(力扣. - 力扣(LeetCode),简单) 解题思路: 难点:加一时可能出现9使得位数进一,而当特殊情况,即全部为9时,数组所在长度会变长一。 从末尾开始判断&…...

【正在线上召开】2024机器智能与数字化应用国际会议(MIDA2024),免费参会
【ACM出版】2024机器智能与数字化应用国际会议(MIDA2024) 2024 International Conference on Machine Intelligence and Digital Applications 【支持单位】 宁波财经学院 法国上阿尔萨斯大学 【大会主席】 Ljiljana Trajkovic 加拿大西蒙菲莎大…...

景源畅信:抖音的爆款视频怎么选?
在短视频风起云涌的今天,抖音作为其中的佼佼者,每天都有无数视频在这里诞生。但如何在内容海洋中脱颖而出,成为人们茶余饭后谈论的焦点,是许多创作者和品牌思考的问题。选择爆款视频,不仅需要对平台规则有深刻理解&…...

开源大模型源代码
开源大模型的源代码可以在多个平台上找到,以下是一些知名的开源大模型及其源代码的获取方式: 1. **艾伦人工智能研究所的开放大语言模型(Open Language Model,OLMo)**: - 提供了完整的模型权重、训练代…...
算法思想总结:哈希表
一、哈希表剖析 1、哈希表底层:通过对C的学习,我们知道STL中哈希表底层是用的链地址法封装的开散列。 2、哈希表作用:存储数据的容器,插入、删除、搜索的时间复杂度都是O(1),无序。 3、什么时…...
基于Docker搭建属于你的CC++集成编译环境
常常,我会幻想着拥有一个随时可以携带、随时可以使用的开发环境,那该是多么美好的事情。 在工作中,编译环境的复杂性常常让我头疼不已。稍有不慎,删除了一些关键文件,整个编译链就会瞬间崩溃。更糟糕的是,…...
如何限制上网行为?上网行为管控软件有什么功能?
上网行为的管理与限制对于保障企业安全、提高员工工作效率以及保护孩子健康成长都显得尤为重要。 上网行为管控软件作为一种专业的工具,在这方面发挥着不可替代的作用。 本文将探讨如何限制上网行为,并介绍上网行为管控软件的主要功能。 一、如何限制上…...

重庆耶非凡科技有限公司的选品师项目靠谱吗?
在跨境电商和零售市场日益繁荣的今天,选品师的角色愈发凸显出其重要性。重庆耶非凡科技有限公司作为一家致力于多元化服务的科技公司,其选品师项目备受关注。那么,重庆耶非凡科技有限公司的选品师项目靠谱吗?接下来,我们将从多个…...
基于Cloudflare/CloudDNS/GitHub使用免费域名部署NewBing的AI服务
部署前准备: Cloudflare 账号 https://dash.cloudflare.com/login CloudDNS 账号 https://www.cloudns.net/ GitHub 账号 https://github.com/Harry-zklcdc/go-proxy-bingai Cloudflare 部署 Worker CloudDNS 获取免费二级域名 GitHub New Bing Ai 项目 https://git…...
redux状态管理用法详解
在React中使用redux,官方要求安装俩个其他插件 - Redux Toolkit 和 react-redux 1.ReduxToolkit (RTK) 官方推荐编写 Redux 逻辑的方式,是一套工具的集合集,简化书写方式 简化 store 的配置方式; 内置 immer 支持…...
函数的实现过程)
细说ARM MCU中的MX_GPIO_Init()函数的实现过程
目录 1、建立.ioc工程 2、 MX_GPIO_Init()函数 (1)MX_GPIO_Init()函数的类型 (2)MX_GPIO_Init()函数中用到的结构体变量 (3)MX_GPIO_Init()函数使能时钟 (4)MX_GPIO_Init()函数…...

【wordpress】网站提示Error establishing a database connection错误代码
Error establishing a database connection错误代码处理方法: 检查数据库连接情况检查数据库账号密码是否正确检查数据库是否开启 总之较大可能是数据库出现了问题...
图书管理系统——Java实现
文章目录 Java实现图书管理系统问题分析框架搭建业务实现项目测试代码演示BookioperationUserMain(默认包) Java实现图书管理系统 学习了前六篇的SE语法,我们现在要用它们实现一个简单的图书管理系统项目,深入了解各个知识点的应…...
Capto 标准版【简体中文+Mac 】
Capto 是一套易于使用的屏幕捕捉、视频录制和视频编辑 Capto-capto安装包-安装包https://souurl.cn/DPhBmP 屏幕录制和教程视频制作 记录整个屏幕或选择的任何特定区域。在创建内容丰富的教程视频时选择显示或隐藏光标。无论您做什么,都可以确保获得高质量的视频。…...
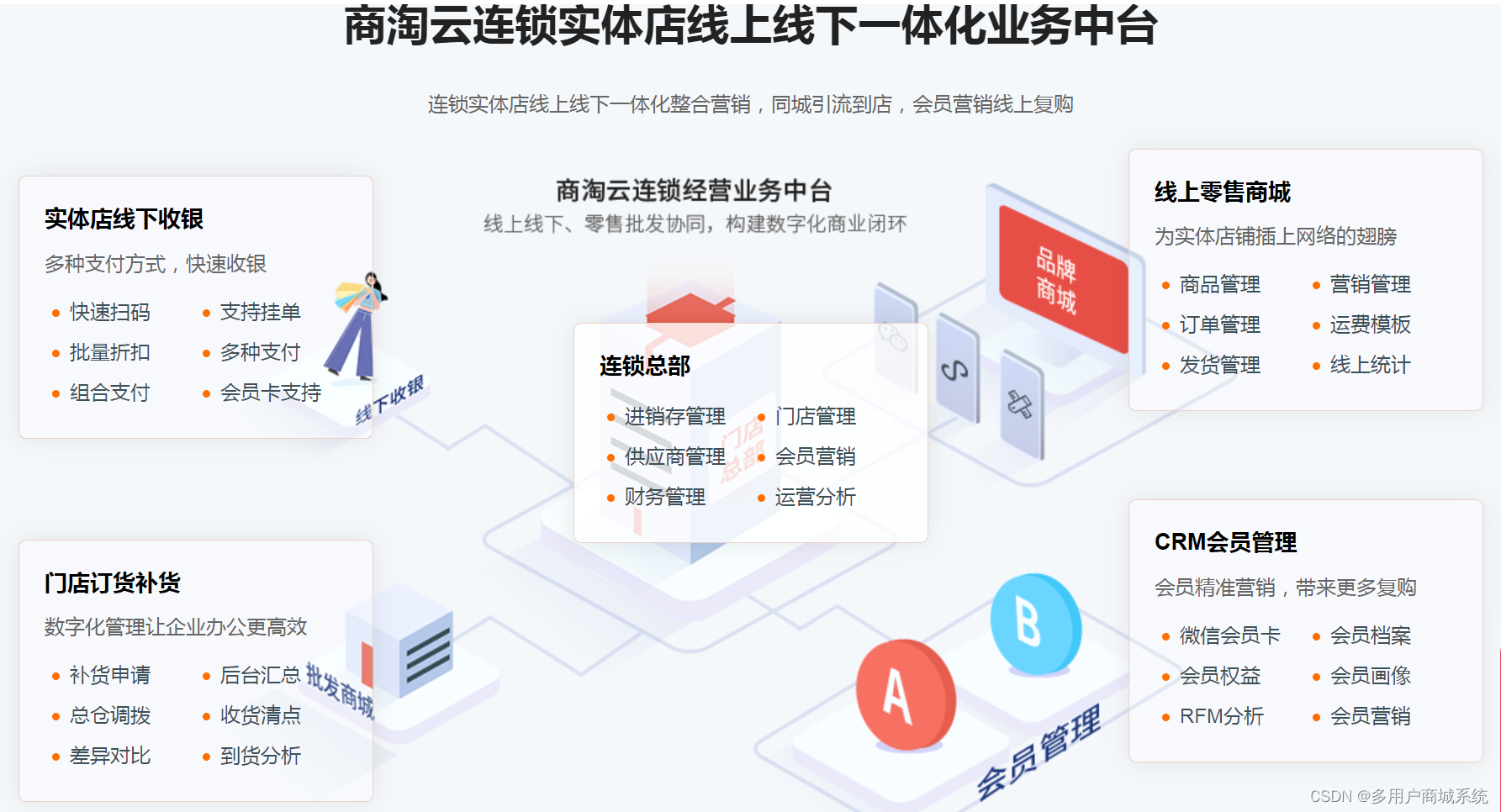
连锁收银系统的五大功能 会员营销是核心
连锁企业的收银系统是其经营管理的关键工具之一,具备多种功能可以帮助企业提高效率、优化服务并实现会员营销。以下是连锁收银系统的五大功能,其中会员营销作为核心功能将在最后详细讨论。 首先,收银系统应具备高效的销售管理功能。这包括商品…...

射频功率限幅器简略
在功率输入保护方面,限幅器是最好用的器件之一,可以保护后级电路不受超限功率的损害,限幅器其实像TVS功能一样,让超过阈值的功率释放到接地上,来达到限制幅度的目的,目前限幅器的限幅幅度大多都大于15dBm,很…...

[备忘] Reboot Linux in python
1.可行的Reboot方法 1.1 修改/etc/sudoers 假定当前用户是mimi,增补这一行: mimi ALL(ALL) NOPASSWD: ALL 这是为了免输指令。 sudoers文件尽量在覆盖前把它的权限改回去: 原始权限 mimidebian-vm:~/test_app$ ls -l /tmp/sudoers -r--r-…...

windows打开工程文件是顺序读写吗
在 Windows 操作系统中,打开和读写工程文件的过程可以是顺序读写,也可以是随机读写,具体取决于使用的软件和文件的性质。以下是一些详细解释: 顺序读写 顺序读写(sequential access)是指按文件中数据的顺…...

【Python】解决Python报错:AttributeError: ‘generator‘ object has no attribute ‘xxx‘
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...