Whisper-AT:抗噪语音识别模型(Whisper)实现通用音频事件标记(Audio Tagger)
本文介绍一个统一音频标记(Audio Tagger)和语音识别(ASR)的模型:Whisper-AT,通过冻结Whisper的主干,并在其之上训练一个轻量级的音频标记模型。Whisper-AT在额外计算成本不到1%的情况下,可以在单次前向传递中识别音频事件以及口语文本。这个模型的提出是建立一个有趣的发现基础上:Whisper对真实世界背景声音非常鲁棒,其音频表示实际上并不是噪声不变的,而是与非语音声音高度相关,这表明Whisper是在噪声类型的基础上识别语音的。
1.概述:
Whisper-AT 是建立在 Whisper 自动语音识别(ASR)模型基础上的一个模型。Whisper 模型使用了一个包含 68 万小时标注语音的大规模语料库进行训练,这些语料是在各种不同条件下录制的。Whisper 模型以其在现实背景噪音(如音乐)下的鲁棒性著称。尽管如此,其音频表示并非噪音不变,而是与非语音声音高度相关。这意味着 Whisper 在识别语音时会依据背景噪音类型进行调整。
主要发现:
-
噪音变化的表示:
- Whisper 的音频表示编码了丰富的非语音背景声音信息,这与通常追求噪音不变表示的 ASR 模型目标不同。
- 这一特性使得 Whisper 能够在各种噪音条件下通过识别和适应噪音来保持其鲁棒性。
-
ASR 和音频标签的统一模型:
- 通过冻结 Whisper 模型的骨干网络,并在其上训练一个轻量级的音频标签模型,Whisper-AT 可以在一次前向传递中同时识别音频事件和语音文本,额外的计算成本不足 1%。
- Whisper-AT 在音频事件检测方面表现出色,同时保持了 Whisper 的 ASR 功能。
技术细节:
-
Whisper ASR 模型:
- Whisper 使用基于 Transformer 的编码器-解码器架构。
- 其训练集包括从互联网上收集的 68 万小时音频-文本对,涵盖了广泛的环境、录音设置、说话人和语言。
-
抗噪机制:
- Whisper 的鲁棒性并非通过噪音不变性实现,而是通过在其表示中编码噪音类型。
- 这一机制使得 Whisper 能够根据背景噪音类型来转录文本,从而在嘈杂条件下表现优越。
-
构建 Whisper-AT:
- Whisper-AT 是通过在 Whisper 模型上添加新的音频标签层而构建的,未修改其原始权重。
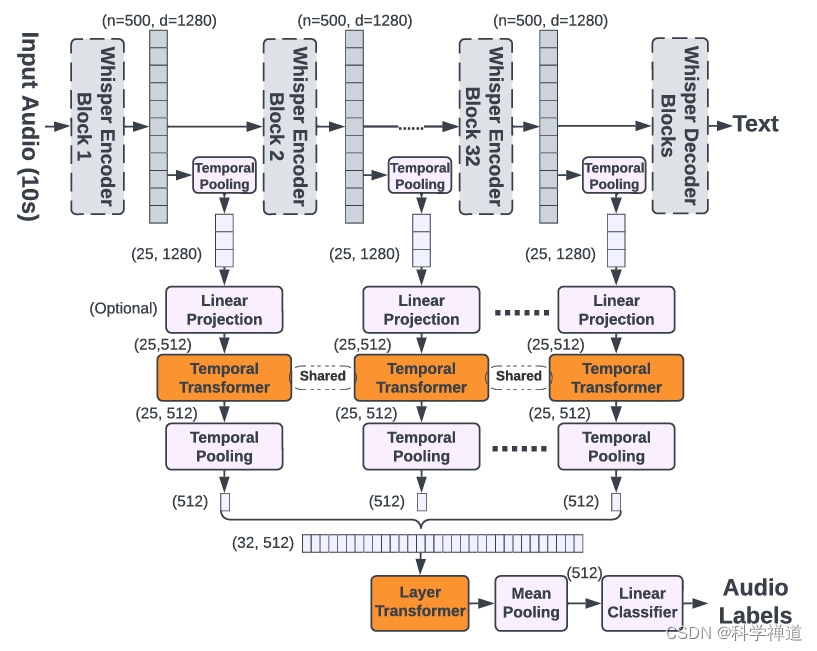
- 探索了不同的音频标签层集成方法,包括:
- Last-MLP:对 Whisper 的最后一层表示进行时间均值池化,然后应用线性层。
- WA-MLP:对所有层的表示进行加权平均,然后应用线性层。
- WA-Tr:用时间 Transformer 层替换线性层。
- TL-Tr:使用时间和层次 Transformer 处理所有层的表示。
- Whisper-AT 是通过在 Whisper 模型上添加新的音频标签层而构建的,未修改其原始权重。
-
效率考量:
- 为保持计算效率,采用了各种策略,例如减少表示的序列长度,并在应用音频标签 Transformer 之前可选地降低维度。
性能:
- Whisper-AT 在 AudioSet 上达到了 41.5 的 mAP,略低于独立的音频标签模型,但处理速度显著更快,超过 40 倍。
意义:
- 能够同时执行 ASR 和音频标签任务,使得 Whisper-AT 非常适合于视频转录、语音助手和助听器系统等应用场景,在这些场景中需要同时进行语音文本和声学场景分析。
2.代码:
欲了解详细的实现和实验结果,请访问 GitHub: github.com/yuangongnd/whisper-at.下面是对 Whisper-AT 代码的详细解释。我们将逐步解析其主要组件和功能,帮助理解其工作原理。
安装和准备
首先,确保你已经安装了 Whisper 和相关的依赖项:
pip install git+https://github.com/openai/whisper.git
pip install torch torchaudio
pip install transformers datasets
代码结构
简要 Whisper-AT 的代码结构如下所示:
Whisper-AT/
│
├── whisper_at.py
├── train.py
├── dataset.py
├── utils.py
└── README.md
whisper_at.py - Whisper-AT 模型
import torch
import torch.nn as nn
import whisperclass WhisperAT(nn.Module):def __init__(self, model_name="base"):super(WhisperAT, self).__init__()self.whisper = whisper.load_model(model_name)self.audio_tagging_head = nn.Linear(self.whisper.dims, 527) # 527 是 AudioSet 的标签数def forward(self, audio):# 获取 Whisper 的中间表示with torch.no_grad():features = self.whisper.encode(audio)# 通过音频标签头audio_tagging_output = self.audio_tagging_head(features.mean(dim=1))return audio_tagging_output
train.py - 训练脚本
import torch
from torch.utils.data import DataLoader
from dataset import AudioSetDataset
from whisper_at import WhisperAT
import torch.optim as optim
import torch.nn.functional as Fdef train():# 加载数据集train_dataset = AudioSetDataset("path/to/training/data")train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)# 初始化模型model = WhisperAT()model.train()# 定义优化器optimizer = optim.Adam(model.parameters(), lr=1e-4)for epoch in range(10): # 假设训练10个epochfor audio, labels in train_loader:optimizer.zero_grad()# 前向传播outputs = model(audio)# 计算损失loss = F.binary_cross_entropy_with_logits(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()print(f"Epoch {epoch}, Loss: {loss.item()}")if __name__ == "__main__":train()
dataset.py - 数据集处理
import torch
from torch.utils.data import Dataset
import torchaudioclass AudioSetDataset(Dataset):def __init__(self, data_path):self.data_path = data_pathself.audio_files = [...] # 这里假设你有一个包含所有音频文件路径的列表self.labels = [...] # 这里假设你有一个包含所有对应标签的列表def __len__(self):return len(self.audio_files)def __getitem__(self, idx):# 加载音频audio, sample_rate = torchaudio.load(self.audio_files[idx])# 获取对应标签labels = torch.tensor(self.labels[idx])return audio, labels
utils.py - 辅助功能
import torchdef save_model(model, path):torch.save(model.state_dict(), path)def load_model(model, path):model.load_state_dict(torch.load(path))model.eval()
详细解释
-
Whisper-AT 模型 (
whisper_at.py):WhisperAT类继承自nn.Module,初始化时加载 Whisper 模型,并在其上添加一个线性层用于音频标签任务。forward方法首先调用 Whisper 模型的encode方法获取音频特征,然后将这些特征传递给音频标签头(线性层)以生成标签输出。
-
训练脚本 (
train.py):train函数中,数据集被加载并传递给 DataLoader。- 模型实例化并设置为训练模式。
- 定义了 Adam 优化器和二进制交叉熵损失函数。
- 在训练循环中,音频输入通过模型生成输出,计算损失并执行反向传播和优化。
-
数据集处理 (
dataset.py):AudioSetDataset类继承自Dataset,实现了音频数据和标签的加载。__getitem__方法加载音频文件并返回音频张量和对应标签。
-
辅助功能 (
utils.py):- 包含保存和加载模型状态的函数,方便模型的持久化和恢复。
通过以上代码结构和解释,可以帮助理解 Whisper-AT 的实现和训练流程。可以根据需要扩展这些代码来适应具体的应用场景和数据集。
附录:
A. 通用音频事件标记(Audio Tagger)
通用音频事件标记 (Audio Tagger) 是一种用于识别和分类音频信号中不同事件的技术。它在音频处理领域具有广泛的应用,包括环境声音识别、音乐信息检索、语音识别、和多媒体内容分析等。
核心概念
-
音频事件(Audio Event): 音频事件指的是音频信号中的特定声音,如鸟鸣、犬吠、警笛声、音乐片段或人声。这些事件可以是短暂的瞬时声音或持续一段时间的信号。
-
标签(Tagging): 标签是对音频信号中的事件进行分类或标注的过程。每个标签对应一个音频事件类别,目的是识别音频信号中包含哪些类型的声音。
技术实现
1. 特征提取
特征提取是音频事件标记的第一步,它将原始音频信号转换为适合分类的特征向量。常用的特征提取方法包括:
- 梅尔频率倒谱系数(MFCC):捕捉音频信号的短时频谱特征。
- 谱质心(Spectral Centroid):描述音频信号的亮度。
- 零交叉率(Zero-Crossing Rate):音频信号通过零点的次数。
- 色度特征(Chromagram):表示音频信号的音调内容。
2. 特征表示和建模
一旦提取了音频特征,需要将其输入到机器学习模型中进行训练和预测。常用的模型包括:
- 传统机器学习模型:如高斯混合模型 (GMM)、支持向量机 (SVM) 和隐马尔可夫模型 (HMM)。
- 深度学习模型:卷积神经网络 (CNN) 和递归神经网络 (RNN) 在音频事件标记中表现出色,尤其是能够处理复杂的时间和频率模式。
3. 标签分配和分类
在训练模型之后,对新的音频信号进行标签分配。模型根据输入的特征向量预测音频信号所属的事件类别。
应用实例
- 环境声音识别:识别并分类自然环境中的声音,如鸟叫、雨声、车流声等。
- 音乐信息检索:分析和分类音乐片段,识别音乐类型、乐器声或特定的音乐模式。
- 语音识别:识别和分类语音中的特定事件,如关键词检测、语音活动检测等。
前沿研究
-
多任务学习: 多任务学习方法通过在多个相关任务上共享表示来提高模型性能。例如,PSLA(Pretraining, Sampling, Labeling, and Aggregation)方法在音频标签任务中取得了显著进展 。
-
自监督学习: 自监督学习方法通过利用大量未标记数据进行预训练,显著提高了模型在音频事件标记任务上的表现。
-
基于Transformer的模型: 例如,Audio Spectrogram Transformer (AST) 利用Transformer架构的优势,在多个音频分类任务上表现优异,超越了传统的卷积神经网络(CNN)方法 。
总结
通用音频事件标记在现代音频处理领域发挥着重要作用。通过结合特征提取、先进的机器学习模型和深度学习技术,音频事件标记能够实现高效、准确的音频信号分类和识别。在未来,随着多任务学习、自监督学习和更先进的深度学习模型的引入,音频事件标记技术将继续发展和完善。
B. Whisper模型
Whisper 是由 OpenAI 开发的一个先进的自动语音识别(ASR)模型。它采用了Transformer架构,特别擅长捕捉音频信号中的全局特征和时间动态。这使得 Whisper 能够在多语言和多任务的语音识别任务中表现优异。
Whisper 模型简介
1. 模型架构
Whisper模型的核心是Transformer架构,包括编码器(Encoder)和解码器(Decoder)。该架构利用多头自注意力机制(Multi-Head Self-Attention)和位置编码(Positional Encoding)来处理音频信号,捕捉其时间动态和全局特征。
- 编码器(Encoder):负责接收和处理输入音频信号,将其转换为高维度的中间表示。编码器由多层自注意力和前馈神经网络组成。
- 解码器(Decoder):利用编码器生成的中间表示,结合上下文信息,生成目标输出(如转录文本)。解码器结构类似于编码器,同样由多层自注意力和前馈神经网络组成。
2. 自注意力机制
自注意力机制允许模型在处理音频信号时,动态地关注不同部分的信息,从而捕捉长程依赖关系。这种机制特别适用于音频信号处理,因为语音信息通常分布在整个序列中,需要全局视角进行建模。
3. 位置编码
由于音频信号是连续的时间序列数据,位置编码在Whisper模型中起着关键作用。位置编码通过为每个时间步添加唯一的位置信息,使得模型能够识别音频信号中的顺序和时间动态。
Whisper 模型的特性和优势
- 多语言支持:Whisper 支持多种语言的语音识别任务,能够处理不同语言的音频信号。
- 高准确性:得益于Transformer架构和自注意力机制,Whisper在多任务语音识别任务中表现出色,准确率高。
- 长程依赖建模:通过自注意力机制,Whisper能够捕捉音频信号中的长程依赖关系,处理长时间的语音数据更加有效。
- 灵活性和扩展性:Whisper可以通过预训练和微调,适应不同的语音识别任务和数据集。
Whisper 模型的应用
Whisper 可应用于多种语音识别和处理任务,包括:
- 实时语音转录:将实时语音输入转录为文本,用于字幕生成、会议记录等场景。
- 多语言翻译:实时翻译不同语言的语音输入,促进跨语言交流。
- 语音指令识别:用于智能设备和语音助手的语音指令识别,提高交互体验。
相关文章:
Whisper-AT:抗噪语音识别模型(Whisper)实现通用音频事件标记(Audio Tagger)
本文介绍一个统一音频标记(Audio Tagger)和语音识别(ASR)的模型:Whisper-AT,通过冻结Whisper的主干,并在其之上训练一个轻量级的音频标记模型。Whisper-AT在额外计算成本不到1%的情况下…...

K8s:Pod初识
Pod Pod是k8s处理的最基本单元。容器本身不会直接分配到主机上,封装为Pod对象,是由一个或多个关系紧密的容器构成。她们共享 IPC、Network、和UTS namespace pod的特征 包含多个共享IPC、Network和UTC namespace的容器,可直接通过loaclhos…...

HCIP-Datacom-ARST自选题库__MAC【14道题】
一、单选题 1.缺省情况下,以下哪种安全MAC地址类型在设备重启后表项会丢失? 黑洞MAC地址 Sticky MAC地址 安全动态MAC地址 安全静态MAC地址 2.华为交换机MAC地址表中的动态sticky MAC地址的默认老化时间是多少秒? 300 不会老化 400 500 3.华为交换机MA…...
)
Go基础编程 - 03 - init函数、main函数、_(下划线)
目录 1. init 函数2. main 函数3. init 函数与 main 函数异同4. _ (下划线)示例 1. init 函数 Go语言中,init 函数用于包(package)的初始化。具有以下特征: 1. init 函数用于程序执行前包的初始化,如初始化变量等。2…...

【TensorFlow深度学习】LeNet-5卷积神经网络实战分析
LeNet-5卷积神经网络实战分析 LeNet-5卷积神经网络实战分析:从经典模型到现代实践LeNet-5的历史背景LeNet-5网络架构实战代码解析实战分析结论 LeNet-5卷积神经网络实战分析:从经典模型到现代实践 在深度学习的历程中,LeNet-5无疑是一座里程…...

错误发生在尝试创建一个基于有限元方法的功能空间时
问题: index cell.index(#直接使用从0开始的索引if0<1ndex<10: #正集流体 subdomains_x[cell,index(] 1 fem1 /usr/bin/python3.8 /home/wy/PycharmProjects/pythonProject2/fem1.pyUnknown ufl object type FiniteElementTraceback (aost recent call last)…...

【八股】Hibernate和JPA:理解它们的关系
在Java开发中,持久化框架是至关重要的工具,它们帮助开发者将Java对象与关系数据库中的数据进行映射和管理。Hibernate和JPA(Java Persistence API)是两个广泛使用的持久化框架。那么,Hibernate和JPA之间到底是什么关系…...

C++类型参数技术以及常见的类型擦除容器
文章目录 一、类型擦除的作用二、常见的类型擦除容器1.std::any2.std::function3.std::shared_ptr\<void\>和 std::unique_ptr\<void\>4.总结 三、实现一个any参考 类型擦除(Type Erasure)是一种编程技术,通过它可以在运行时存储…...

SpringBoot如何缓存方法返回值?
Why? 为什么要对方法的返回值进行缓存呢? 简单来说是为了提升后端程序的性能和提高前端程序的访问速度。减小对db和后端应用程序的压力。 一般而言,缓存的内容都是不经常变化的,或者轻微变化对于前端应用程序是可以容忍的。 否…...

C#的web项目ASP.NET
添加实体类和控制器类 using System; using System.Collections.Generic; using System.Linq; using System.Web;namespace WebApplication1.Models {public class Company{public string companyCode { get; set; }public string companyName { get; set; }public string com…...

Spring MVC 源码分析之 DispatcherServlet#getHandlerAdapter 方法
前言: 前面我们分析了 Spring MVC 的工作流程源码,其核心是 DispatcherServlet#doDispatch 方法,我们前面分析了获取 Handler 的方法 DispatcherServlet#getHandler 方法,本篇我们重点分析一下获取当前请求的适配器 HandlerAdapt…...

假设检验学习笔记
1. 假设检验的基本概念 1.1. 原假设(零假设) 对总体的分布所作的假设用表示,并称为原假设或零假设 在总体分布类型已知的情况下,仅仅涉及总体分布中未知参数的统计假设,称为参数假设 在总体分布类型未知的情况下&#…...

vue3 watch学习
watch的侦听数据源类型 watch的第一个参数为侦听数据源,有4种"数据源": ref(包括计算属性) reactive(响应式对象) getter函数 多个数据源组成的数组。 //ref const xref(0)//单个ref watch(x,(newX)>{console.…...

推荐的Pytest插件
推荐的Pytest插件 Pytest的插件生态系统非常丰富,以下是一些特别推荐的Pytest插件: pytest-sugar 这个插件改进了Pytest的默认输出,添加了进度条,并立即显示失败的测试。它不需要额外配置,只需安装即可享受更漂亮、更…...
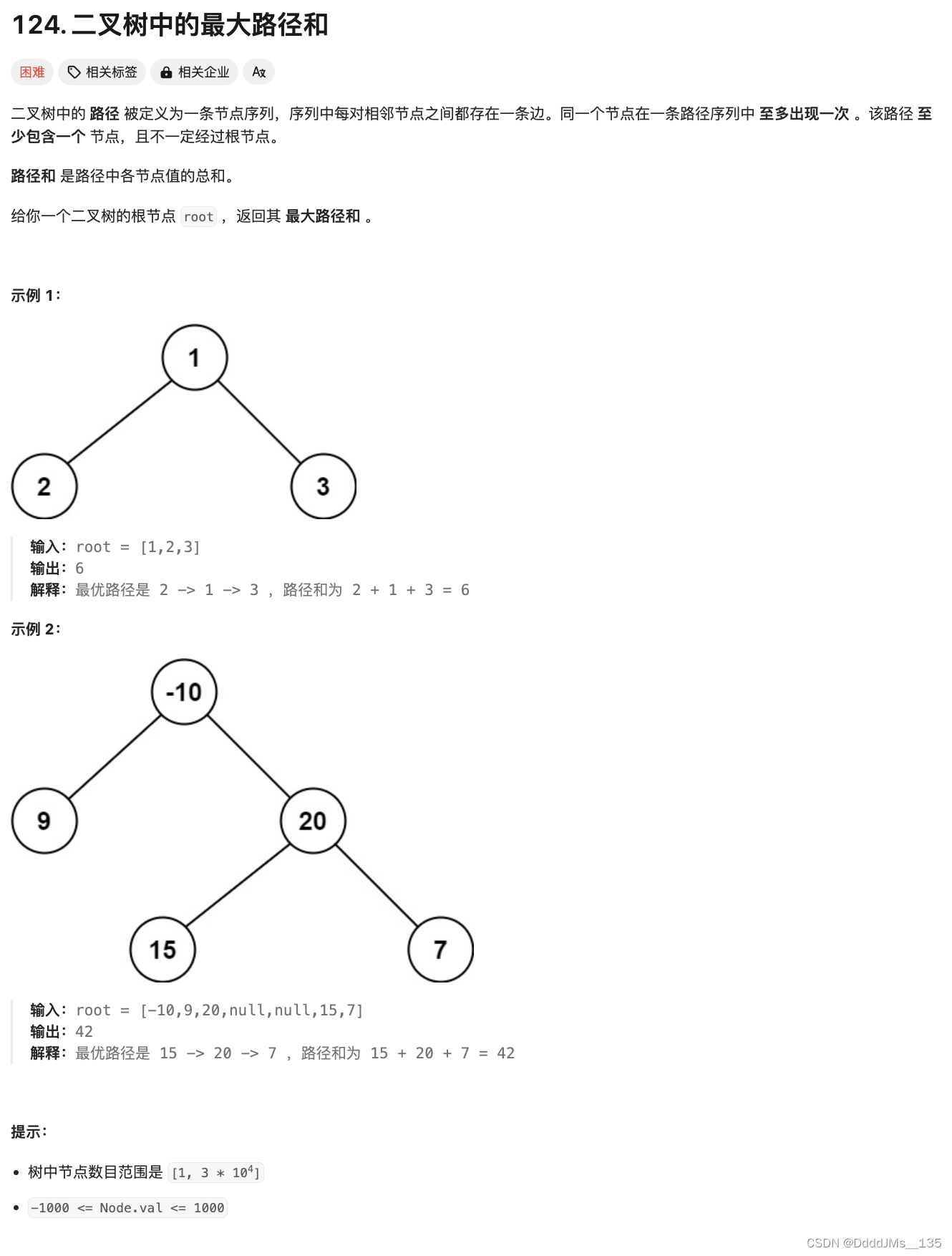
C语言 | Leetcode C语言题解之第124题二叉树中的最大路径和
题目: 题解: /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ int max; int dfs(struct TreeNode* root){if(!root) return 0;int left dfs(root->left…...

Linux综合实践(Ubuntu)
目录 一、配置任务 1.1 配置该服务器的软件源为中科大软件源 1.2 安装相关软件openssh-server和vim 1.3 设置双网卡,网卡1为NAT模式,网卡2为桥接模式(桥接模式下,使用静态ip,该网卡数据跟实验室主机网络设置相似,除…...

C++面试题其二
19. STL中unordered_map和map的区别 unordered_map 和 map 都是C标准库中的关联容器,但它们在实现和性能方面有显著区别: 底层实现:map 是基于红黑树实现的有序关联容器,而 unordered_map 是基于哈希表实现的无序关联容器。元素…...
系统架构设计师【第9章】: 软件可靠性基础知识 (核心总结)
文章目录 9.1 软件可靠性基本概念9.1.1 软件可靠性定义9.1.2 软件可靠性的定量描述9.1.3 可靠性目标9.1.4 可靠性测试的意义9.1.5 广义的可靠性测试与狭义的可靠性测试 9.2 软件可靠性建模9.2.1 影响软件可靠性的因素9.2.2 软件可靠性的建模方法9.2.3 软件的可靠性模…...

x264 参考帧管理原理:i_poc_type 变量
x264 参考帧管理 x264 是一个开源的 H.264 视频编码软件,它提供了许多高级特性,包括对参考帧的高效管理。参考帧管理是视频编码中的一个重要部分,它涉及到如何存储、更新和使用已经编码的帧以提高编码效率。 x264 参考帧管理的一些关键点总结如下: 参考帧的初始化和重排序:…...

高级Web Lab2
高级Web Lab2 12 1 按照“Lab 2 基础学习文档”文档完成实验步骤 实验截图: 2 添加了Web3D场景选择按钮,可以选择目标课程或者学习房间。...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...

从实验室到产业:IndexTTS 在六大核心场景的落地实践
一、内容创作:重构数字内容生产范式 在短视频创作领域,IndexTTS 的语音克隆技术彻底改变了配音流程。B 站 UP 主通过 5 秒参考音频即可克隆出郭老师音色,生成的 “各位吴彦祖们大家好” 语音相似度达 97%,单条视频播放量突破百万…...