【模型架构】学习RNN、LSTM、TextCNN和Transformer以及PyTorch代码实现
一、前言
在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、Transformer再到当下火热的Mamba(放在下一节),每一种架构都带来了不同的突破和应用。本文将详细介绍这些经典的模型架构及其在PyTorch中的实现,由于我只是门外汉(想扩展一下知识面),如果有理解不到位的地方欢迎评论指正~。
个人感觉NLP的任务本质上是一个序列到序列的过程,给定输入序列 ,要通过一个函数实现映射,得到输出序列
,这里的x1、x2、x3可以理解为一个个单词,NLP的具体应用有:
-
机器翻译:将源语言的句子(序列)翻译成目标语言的句子(序列)。
-
文本生成:根据输入序列生成相关的输出文本,如文章生成、对话生成等。
-
语音识别:将语音信号(序列)转换为文本(序列)。
-
文本分类:尽管最终输出是一个类别标签,但在一些高级应用中,也可以将其看作是将文本序列映射到某个特定的输出序列(如标签序列)。
二、RNN和LSTM
2.1 RNN
循环神经网络(RNN)是一种适合处理序列数据的神经网络架构。与传统的前馈神经网络(线性层)不同,RNN具有循环连接,能够在序列数据的处理过程中保留和利用之前的状态信息。网络结构如下所示:
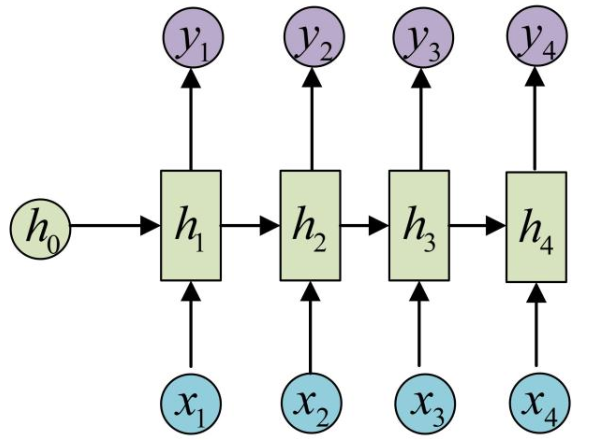
RNN的网络结构
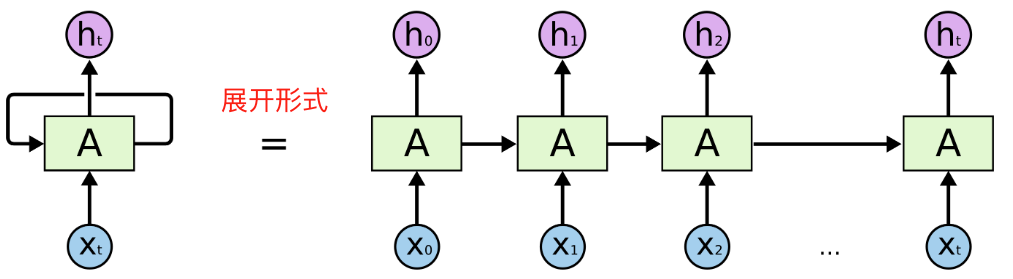
x和隐藏状态h的计算过程
RNN通过在网络中引入循环连接,将前一个时间步的输出作为当前时间步的输入之一,使得网络能够记住以前的状态。具体来说,RNN的每个时间步都会接收当前输入和前一个时间步的隐藏状态,并输出新的隐藏状态。其核心公式为:
-
𝑥𝑡 是当前时间步的输入。
-
ℎ𝑡 是当前时间步的隐藏状态。
-
ℎ𝑡−1 是前一个时间步的隐藏状态(如果是第一个输入,这项是0)。
-
𝑦𝑡 是当前时间步的输出。
-
𝑊ℎ𝑥𝑊ℎℎ𝑊ℎ𝑦 都是权重矩阵,是可以共享参数的。
-
𝑏ℎ 𝑏𝑦 是偏置。
-
𝜎𝜙 是激活函数。
2.1.1 RNN的优点
-
处理序列数据:RNN可以处理任意长度的序列数据,并能够记住序列中的上下文信息。
-
参数共享:RNN在不同时间步之间共享参数,使得模型在处理不同长度的序列时更加高效。
2.1.2 RNN的缺点
-
梯度消失和爆炸:在训练过程中,RNN会遇到梯度消失和梯度爆炸的问题,导致模型难以训练或收敛缓慢。
-
长距离依赖问题:RNN在处理长序列数据时,容易遗忘较早的上下文信息,难以捕捉长距离依赖关系。
-
不能并行训练:每个时间步的计算需要依赖于前一个时间步的结果,这导致RNN的计算不能完全并行化,必须按顺序进行。这种顺序性限制了RNN的训练速度,但是推理不受影响(尽管推理过程同样受到顺序性依赖的限制,但相比训练过程,推理的计算量相对较小,因为推理时不需要进行反向传播和梯度计算。推理过程主要集中在前向传播,即根据输入数据通过模型得到输出。因此,推理过程中的计算相对较快,尽管不能并行化,但在许多实际应用中仍然可以达到实时或接近实时的性能)。
关于长距离依赖问题的理解:
在RNN中,每个时间步的信息会被传递到下一个时间步。然而,随着序列长度的增加,早期时间步的信息需要通过许多次的传递才能影响到后续时间步。每次传递过程中,信息可能会逐渐衰减。这种逐步衰减导致RNN在处理长序列数据时,早期时间步的信息可能被遗忘或淹没在新信息中。
同时,在训练RNN时,通过时间反向传播算法(Backpropagation Through Time, BPTT)来更新参数。这一过程中,梯度会从输出层反向传播到输入层。然而,长序列中的梯度在多次反向传播时,容易出现梯度消失(梯度逐渐变小,趋近于零)或梯度爆炸(梯度过大,导致数值不稳定)的现象。梯度消失会导致模型难以学习和记住长距离依赖的信息,梯度爆炸则会导致模型参数更新不稳定。
2.1.3 代码实现
以下的实现都是基于文本分类任务进行的:
import torch
import torch.nn as nnclass TextRNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)self.fc = nn.Linear(hidden_dim, num_classes)self.dropout = nn.Dropout(dropout)def forward(self, x):x = self.embedding(x)rnn_out, hidden = self.rnn(x)x = self.dropout(rnn_out[:, -1, :])x = self.fc(x)return x如果不用torch自带RNN的api的话,下面是自搭版本:
import torch
import torch.nn as nnclass CustomRNNLayer(nn.Module):def __init__(self, input_dim, hidden_dim):super(CustomRNNLayer, self).__init__()self.hidden_dim = hidden_dimself.i2h = nn.Linear(input_dim + hidden_dim, hidden_dim)self.h2o = nn.Linear(hidden_dim, hidden_dim)self.tanh = nn.Tanh()def forward(self, input, hidden):combined = torch.cat((input, hidden), 1)hidden = self.tanh(self.i2h(combined))output = self.h2o(hidden)return output, hiddenclass TextRNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.hidden_dim = hidden_dimself.num_layers = num_layersself.rnn1 = CustomRNNLayer(embedding_dim, hidden_dim)self.rnn2 = CustomRNNLayer(hidden_dim, hidden_dim)self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)batch_size, seq_len, _ = x.shapehidden1 = torch.zeros(batch_size, self.hidden_dim).to(x.device)hidden2 = torch.zeros(batch_size, self.hidden_dim).to(x.device)for t in range(seq_len):input_t = x[:, t, :]hidden1, _ = self.rnn1(input_t, hidden1)hidden2, _ = self.rnn2(hidden1, hidden2)x = self.dropout(hidden2)x = self.fc(x)return x初始化 hidden1 和 hidden2 为零张量,表示第一个和第二个RNN层的初始隐藏状态,遍历序列长度 seq_len 的每个时间步,将当前时间步的输入向量 input_t 输入到第一个RNN层,更新 hidden1;再将 hidden1 输入到第二个RNN层,更新 hidden2。
特别解释一下,input_t = x[:, t, :] 是提取当前时间步 t 的输入向量,原本的x是(batch_size, seq_len, embedding_dim),处理后是(batch_size, embedding_dim)。
2.2 LSTM
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN)架构,旨在解决传统RNN在处理长序列数据时的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元(cell state)和门控机制(gate mechanism),能够更好地捕捉和保留长距离依赖关系。
LSTM的基本结构包括一个记忆单元和三个门:输入门、遗忘门和输出门。这些门用于控制信息在LSTM单元中的流动。LSTM的工作原理可以用以下步骤描述:
-
遗忘门(Forget Gate):决定记忆单元中的哪些信息需要被遗忘。
-
输入门(Input Gate):决定哪些新信息需要被存储到记忆单元中。
-
输出门(Output Gate):决定记忆单元中的哪些信息需要输出。
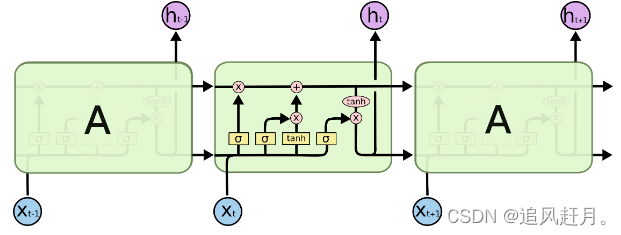
LSTM的网络结构,可以看到和RNN相似,但是用到门控和记忆机制
LSTM在每个时间步的计算可以分为以下4个阶段,也对应了上图出现的顺序:
遗忘门的计算:
遗忘门 ft决定了前一个时间步的记忆单元状态C t-1 中哪些信息需要被遗忘。 σ是 sigmoid 激活函数(输出限制在 [0, 1] 之间,0就代表了遗忘,不许任何量通过,1就指允许任意量通过,从而使得网络就能了解哪些数据是需要遗忘,哪些数据是需要保存), wf是遗忘门的权重矩阵,bf是偏置。 这是一个concat连接操作。
输入门的计算:
输入门 it决定了当前输入xt中哪些信息需要被添加到记忆单元中, Ct是新的候选记忆, Wi和Wc 分别是输入门和候选记忆的权重矩阵,bi和bc 是偏置。
tanh激活函数的范围是-1~1,它对新信息进行变换,使得新信息能够取正值和负值。这样可以更灵活地调整记忆单元状态,从而保留和更新信息
更新记忆单元状态:
记忆单元状态Ct通过遗忘门和输入门的输出进行更新,融合了前一个时间步的记忆和当前时间步的新信息。
输出门的计算:
输出门 ot 决定了记忆单元中哪些信息需要输出,最终的隐藏状态 ht 通过记忆单元状态 Ct 以及输出门的控制生成。
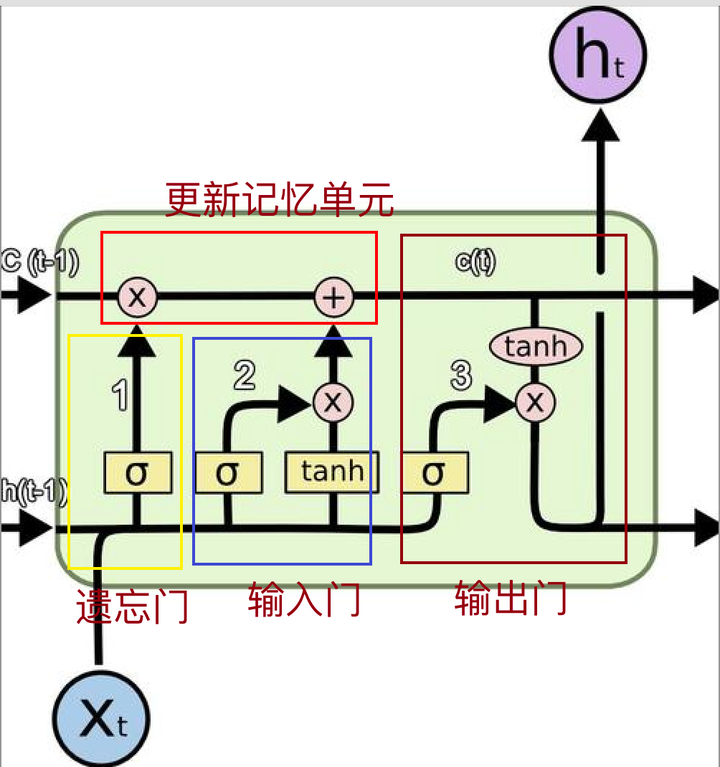
单个计算模块的细节
2.2.1 LSTM的优点
-
解决长距离依赖问题:LSTM通过引入记忆单元(cell state)和门控机制(遗忘门、输入门和输出门),有效地解决了传统RNN的长距离依赖问题。它能够记住长时间跨度内的重要信息,避免了信息在多次传递逐渐衰减。
-
缓解梯度消失和梯度爆炸问题:在传统RNN中,梯度消失和梯度爆炸是常见的问题,特别是在处理长序列时。LSTM通过其门控机制,能够更稳定地传递梯度,减少了梯度消失和爆炸的发生,从而提高了训练效果。
-
灵活的记忆更新:LSTM的记忆单元和门控机制使得网络能够有选择性地记住和遗忘信息。这种灵活性使得LSTM在处理复杂的时间序列数据时表现出色,能够捕捉到数据中的重要模式和特征。
2.2.2 LSTM的缺点
-
计算复杂度高:相较于简单的RNN,LSTM的结构更复杂,包含更多的参数(如多个门和记忆单元)。这种复杂性增加了计算成本,导致训练和推理速度较慢。
-
难以并行化:LSTM的顺序计算特性限制了其并行化的能力。在处理长序列时,每个时间步的计算依赖于前一个时间步的结果,这使得计算不能完全并行化,从而影响训练和推理的效率。
-
对长序列仍有局限:尽管LSTM在处理长距离依赖问题上比传统RNN有显著改善,但在极长序列的情况下,仍可能遇到信息遗忘和梯度衰减的问题。
2.2.3 代码实现
import torch
import torch.nn as nnclass TextLSTM(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextLSTM, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first=True, dropout=dropout)self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)batch_size, seq_len, _ = x.shapeh_0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size).to(x.device)c_0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size).to(x.device)x, (h_n, c_n) = self.lstm(x, (h_0, c_0))x = self.dropout(h_n[-1])x = self.fc(x)return x自搭版本:
import torch
import torch.nn as nnclass CustomLSTMLayer(nn.Module):def __init__(self, input_dim, hidden_dim):super(CustomLSTMLayer, self).__init__()self.hidden_dim = hidden_dimself.i2f = nn.Linear(input_dim + hidden_dim, hidden_dim)self.i2i = nn.Linear(input_dim + hidden_dim, hidden_dim)self.i2c = nn.Linear(input_dim + hidden_dim, hidden_dim)self.i2o = nn.Linear(input_dim + hidden_dim, hidden_dim)self.tanh = nn.Tanh()self.sigmoid = nn.Sigmoid()def forward(self, input, hidden, cell):combined = torch.cat((input, hidden), 1)f_t = self.sigmoid(self.i2f(combined))i_t = self.sigmoid(self.i2i(combined))c_tilde_t = self.tanh(self.i2c(combined))c_t = f_t * cell + i_t * c_tilde_to_t = self.sigmoid(self.i2o(combined))h_t = o_t * self.tanh(c_t)return h_t, c_tclass TextLSTM(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout, num_classes):super(TextLSTM, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.hidden_dim = hidden_dimself.num_layers = num_layersself.lstm1 = CustomLSTMLayer(embedding_dim, hidden_dim)self.lstm2 = CustomLSTMLayer(hidden_dim, hidden_dim)self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):x = self.embedding(x)batch_size, seq_len, _ = x.shapehidden1 = torch.zeros(batch_size, self.hidden_dim).to(x.device)cell1 = torch.zeros(batch_size, self.hidden_dim).to(x.device)hidden2 = torch.zeros(batch_size, self.hidden_dim).to(x.device)cell2 = torch.zeros(batch_size, self.hidden_dim).to(x.device)for t in range(seq_len):input_t = x[:, t, :]hidden1, cell1 = self.lstm1(input_t, hidden1, cell1)hidden2, cell2 = self.lstm2(hidden1, hidden2, cell2)x = self.dropout(hidden2)x = self.fc(x)return x三、TextCNN
TextCNN(文本卷积神经网络)是一种应用于自然语言处理(NLP)任务的卷积神经网络(CNN)模型。
TextCNN的基本结构包括以下几个部分:
-
嵌入层(Embedding Layer):将输入的文本序列转换为稠密的词向量表示。这些词向量可以是预训练的词向量(如Word2Vec、GloVe)或在训练过程中学习到的嵌入。
-
卷积层(Convolutional Layer):对嵌入后的词向量序列应用卷积操作,提取不同大小的n-gram特征。卷积核的大小可以设定为不同的窗口大小(如2, 3, 4等),以捕捉不同范围的局部特征。
-
池化层(Pooling Layer):对卷积后的特征图应用最大池化操作,将每个卷积核的输出缩减为一个固定大小的特征向量。这一步有助于提取最重要的特征,并减少特征的维度。
-
全连接层(Fully Connected Layer):将池化后的特征向量连接成一个长的特征向量,输入到全连接层中进行分类。最后一层通常是一个Softmax层,用于输出分类结果。
具体流程如下:
-
输入文本:输入一个文本序列,假设长度为n,每个词通过词汇表索引转换为词向量表示,形成一个形状为(n,d)的矩阵,其中 d 是词向量的维度。
-
卷积操作:使用不同大小的卷积核(如2, 3, 4)对嵌入矩阵进行卷积操作,提取不同n-gram的局部特征。卷积后的特征图形状为(n-k+1, m),其中 k 是卷积核的大小,m 是卷积核的数量。
-
最大池化:对每个卷积核的输出特征图进行最大池化操作,提取重要的特征。池化后的特征向量形状为 (m, )。
-
特征拼接:将不同卷积核和池化操作得到的特征向量拼接成一个长的特征向量,输入到全连接层。
-
分类输出:最后通过全连接层和Softmax层进行分类,输出各类别的概率。

TextCNN的网络结构
3.1 TextCNN的优点
-
高效提取局部特征:卷积操作能够有效提取不同n-gram范围内的局部特征,对于捕捉文本的局部模式非常有效。
-
并行计算:卷积操作和池化操作可以并行计算,相对于RNN等顺序模型,训练和推理速度更快。
3.2 TextCNN的缺点
-
缺乏长距离依赖:由于卷积操作的感受野有限,TextCNN在捕捉长距离依赖方面不如LSTM等序列模型表现好。
-
固定大小的卷积核:虽然可以通过多种卷积核来捕捉不同的n-gram特征,但仍然受限于卷积核的大小,对于变长依赖的建模能力有限。
3.3 权值共享
权值共享是指在卷积神经网络的卷积操作中,同一卷积核(filter)的参数在整个输入图像或特征图上被重复使用。这意味着,对于一个卷积层中的每一个卷积核,其参数在整个输入图像的不同位置上是相同的。
-
降低参数:在传统的全连接层中,每个神经元都有自己的权重参数,输入维度较大时会导致参数数量庞大。而在卷积层中,由于使用了权值共享,一个卷积核的参数数量固定,独立于输入图像的大小。这大大减少了模型的参数数量。
-
提升训练效率:由于参数数量减少,权值共享使得模型训练变得更加高效。需要学习的参数变少了,相应的训练时间也减少了。
-
空间不变性(Translation Invariance):权值共享意味着卷积核在输入图像的不同位置都使用相同的参数,这使得卷积神经网络可以识别图像中的特征,不管这些特征出现在图像的哪个位置。这样,模型可以更好地处理位移和变形,提高对输入图像的泛化能力。
3.4 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self, vocab_size, embedding_dim, num_filters, kernel_sizes, dropout, num_classes):super(TextCNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.conv1 = nn.Conv2d(1, num_filters, (kernel_sizes[0], embedding_dim))self.conv2 = nn.Conv2d(1, num_filters, (kernel_sizes[1], embedding_dim))self.conv3 = nn.Conv2d(1, num_filters, (kernel_sizes[2], embedding_dim))self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(num_filters * len(kernel_sizes), num_classes)def forward(self, x):x = self.embedding(x)x = x.unsqueeze(1) # 增加通道维度方便卷积处理conv1_out = F.relu(self.conv1(x)).squeeze(3)pooled1 = F.max_pool1d(conv1_out, conv1_out.size(2)).squeeze(2)conv2_out = F.relu(self.conv2(x)).squeeze(3)pooled2 = F.max_pool1d(conv2_out, conv2_out.size(2)).squeeze(2)conv3_out = F.relu(self.conv3(x)).squeeze(3)pooled3 = F.max_pool1d(conv3_out, conv3_out.size(2)).squeeze(2)x = torch.cat((pooled1, pooled2, pooled3), 1)x = self.dropout(x)x = self.fc(x)return x四、Transformer
Transformer是老熟人了,是目前主流的网络架构,当然它最早还是起源于NLP领域。
Transformer模型主要由两个部分组成:编码器(Encoder)和解码器(Decoder)。编码器和解码器各自由多个相同的层(layer)堆叠而成,每一层包含两个主要子层(sublayer):
-
编码器(Encoder):由多个相同的编码器层堆叠组成,每个编码器层包含一个自注意力子层和一个前馈神经网络子层。
-
解码器(Decoder):由多个相同的解码器层堆叠组成,每个解码器层包含一个自注意力子层、一个编码器-解码器注意力子层和一个前馈神经网络子层。
4.1 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心组件,用于计算输入序列中每个位置的表示。具体来说,自注意力机制通过计算输入序列中每个位置与其他所有位置的相似度来捕捉全局依赖关系。计算公式如下:
其中:
-
Q(Query)是查询矩阵。
-
K(Key)是键矩阵。
-
V(Value)是值矩阵。
-
dk 是键向量的维度。
-
其实,QKV都是来自一个x经过不同的权重矩阵计算得到的。
4.2 多头注意力机制(Multi-Head Attention)
为了进一步提升模型的表达能力,Transformer采用了多头注意力机制。多头注意力通过对输入进行多个独立的自注意力计算(称为头),并将结果拼接在一起,通过线性变换生成最终的输出。公式如下:
其中每个头的计算为:
4.3 前馈神经网络(Feed-Forward Neural Network)
每个编码器和解码器层还包含一个前馈神经网络子层。这个子层包含两个线性变换和一个激活函数(通常是ReLU):
4.4 整体流程
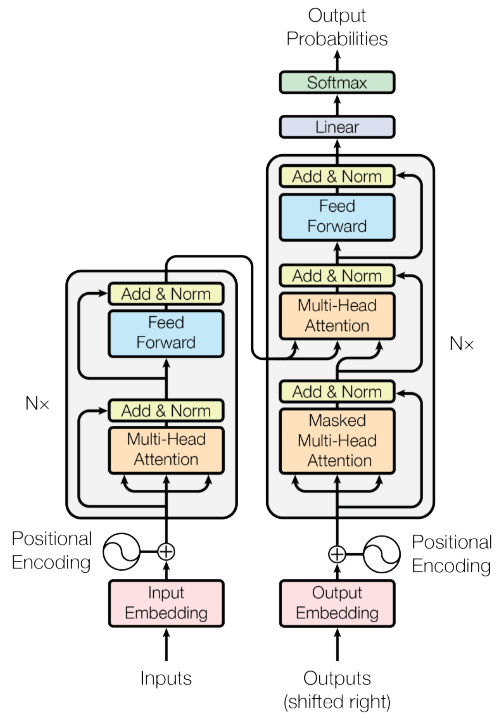
Transformer网络框架
Transformer模型通过嵌入层和位置编码将输入序列转化为稠密向量表示,然后经过编码器和解码器的多层处理,捕捉序列中的全局依赖关系。
编码器通过多头自注意力机制和前馈神经网络提取输入序列的特征,解码器通过掩码多头自注意力机制(遮住了遮盖掉未来的时间步,防止解码器在生成当前时间步的输出时看到未来的单词,确保自回归性质。)、编码器-解码器注意力机制和前馈神经网络生成输出序列。最后通过线性层和Softmax层生成输出单词的概率分布。加法和归一化(Add & Norm,其实就是残差和LayerNorm)操作在每个子层后确保梯度稳定,帮助训练更深的网络。
在Transformer模型的解码器部分,"outputs (shifted right)" 指的是在解码过程中,模型使用已经生成的输出单词作为当前时间步的输入,同时将这些输出单词整体向右偏移一个位置,以确保模型生成下一个单词时只能依赖之前生成的单词,而不是未来的单词。
假设要生成一个法语句子 "Je suis étudiant"。具体步骤如下:
编码器处理
-
编码器接收英语句子 "I am a student"。
-
编码器生成全局上下文表示,提供给解码器。
解码器生成
-
解码器首先接收起始标记 <sos> 作为输入(这里就体现了右移,因为第一个单词变成了一个特定的符号),生成第一个单词 "Je"。
-
在生成 "Je" 后,将 "Je" 作为下一个时间步的输入。解码器现在的输入是 <sos> Je,它只能看到 "Je" 之前的内容。
-
解码器生成第二个单词 "suis"。接下来,解码器的输入是 <sos> Je suis。
-
这一过程不断重复,解码器在每个时间步只能看到之前生成的单词,而不能看到未来的单词。
多头注意力机制
将查询(Q)、键(K)和值(V)通过多个线性变换,拆分成多个组(头),每个头独立计算注意力分数和加权求和值。最后,所有头的输出拼接在一起,通过一个线性变换恢复到原来的维度。这种设计允许模型在不同的子空间中关注不同部分的信息,从而提高模型的表达能力和捕捉复杂模式的能力。
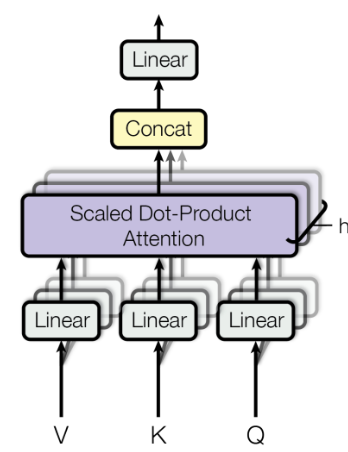
多头注意力机制示意图
4.5 Transformer的优点
-
并行化计算:由于不依赖于前一个时间步的计算结果,Transformer可以并行处理整个序列,这显著提高了训练和推理的速度。
-
捕捉全局依赖:自注意力机制能够捕捉序列中任意两个位置之间的依赖关系(具体体现在是矩阵运算),特别适合长序列的处理。
-
扩展性强:Transformer架构具有很强的扩展性,可以通过增加层数和头数来提高模型的表达能力。
4.6 Transformer的缺点
-
计算资源消耗大:自注意力机制的计算复杂度为 𝑂(𝑛2⋅𝑑),其中n是序列长度,d是模型的维度。这使得Transformer在处理非常长的序列时计算资源消耗较大。
-
需要大量数据:Transformer模型通常需要大量的数据来进行训练,以充分发挥其性能优势。这在数据稀缺的任务中可能成为一个限制因素。主要是在ViT那篇论文中提到了,Transformer结构缺少一些CNN本身设计的归纳偏置(其实就是卷积结构带来的先验经验),比如平移不变性和包含局部关系,因此在规模不足的数据集上表现没有那么好。所以,卷积结构其实是一种trick,而transformer结构是没有这种trick的,就需要更多的数据来让它学习这种结构。
4.7 Pytorch代码实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Transformer(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers,dim_feedforward, dropout=0.1):super(Transformer, self).__init__()self.d_model = d_model# 定义源语言和目标语言的嵌入层self.src_embedding = nn.Embedding(src_vocab_size, d_model)self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)# 位置编码层self.pos_encoder = PositionalEncoding(d_model, dropout)# Transformer模型self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward,dropout)# 输出层self.fc_out = nn.Linear(d_model, tgt_vocab_size)def forward(self, src, tgt, src_mask, tgt_mask, src_padding_mask, tgt_padding_mask, memory_key_padding_mask):# 对源输入进行嵌入和位置编码src = self.src_embedding(src) * torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))src = self.pos_encoder(src)# 对目标输入进行嵌入和位置编码tgt = self.tgt_embedding(tgt) * torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))tgt = self.pos_encoder(tgt)# 编码器memory = self.transformer.encoder(src, mask=src_mask, src_key_padding_mask=src_padding_mask)# 解码器output = self.transformer.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=None,tgt_key_padding_mask=tgt_padding_mask,memory_key_padding_mask=memory_key_padding_mask)# 输出层output = self.fc_out(output)return outputclass PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)# 初始化位置编码矩阵pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:x.size(0), :]return self.dropout(x)def generate_square_subsequent_mask(sz):# 生成一个上三角矩阵,防止解码器看到未来的tokenmask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))return maskdef create_padding_mask(seq):# 创建填充mask,忽略填充部分seq = seq == 0return seq# 使用示例
src_vocab_size = 10000
tgt_vocab_size = 10000
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
dropout = 0.1model = Transformer(src_vocab_size, tgt_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers,dim_feedforward, dropout)src = torch.randint(0, src_vocab_size, (10, 32)) # (源序列长度, 批次大小)
tgt = torch.randint(0, tgt_vocab_size, (20, 32)) # (目标序列长度, 批次大小)
src_mask = generate_square_subsequent_mask(src.size(0))
tgt_mask = generate_square_subsequent_mask(tgt.size(0)) # 生成shifted mask,防止解码器看到未来的token
src_padding_mask = create_padding_mask(src).transpose(0, 1) # 调整mask形状为 (批次大小, 源序列长度)
tgt_padding_mask = create_padding_mask(tgt).transpose(0, 1) # 调整mask形状为 (批次大小, 目标序列长度)
memory_key_padding_mask = src_padding_maskoutput = model(src, tgt, src_mask, tgt_mask, src_padding_mask, tgt_padding_mask, memory_key_padding_mask)
print(output.shape) # 应该是 (目标序列长度, 批次大小, 目标词汇表大小)generate_square_subsequent_mask 函数
-
torch.ones(sz, sz):生成一个全是1的矩阵,形状为 (sz, sz)。
-
torch.triu():将矩阵的下三角部分置为0,上三角部分保持为1。torch.triu(torch.ones(sz, sz)) 生成一个上三角矩阵。
-
transpose(0, 1):对矩阵进行转置,使其符合注意力机制的输入格式。
-
mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0)):将上三角矩阵中0的位置填充为负无穷,1的位置填充为0。
create_padding_mask 函数
用于生成一个填充mask,标记序列中的填充部分。具体来说,这个mask会告诉模型哪些位置是填充值(通常是0),模型在计算注意力时会忽略这些填充值,从而只关注有效的输入。
在自然语言处理任务中,输入序列通常具有不同的长度。为了使所有输入序列具有相同的长度,通常会在较短的序列末尾添加填充值(通常为0)。但是,这些填充值在计算注意力时是不应该被考虑的,因为它们不包含实际信息。因此,需要一个mask来标记这些填充值的位置,使模型在计算注意力时忽略它们。
Input:
序列1: [5, 7, 2, 0, 0] 序列2: [1, 3, 0, 0, 0]
Output:
tensor([[False, False, False, True, True], [False, False, True, True, True]])相关文章:
【模型架构】学习RNN、LSTM、TextCNN和Transformer以及PyTorch代码实现
一、前言 在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、Transformer再到当下火热的Mamba(放在下一节&a…...
【LeetCode】38.外观数列
外观数列 题目描述: 「外观数列」是一个数位字符串序列,由递归公式定义: countAndSay(1) "1"countAndSay(n) 是 countAndSay(n-1) 的行程长度编码。 行程长度编码(RLE)是一种字符串压缩方法,…...
)
如何解决Ubuntu中软件包安装时的404错误(无法安装gdb、cgddb等)
目录 问题描述 解决方法 1. 更新软件包列表 2. 使用--fix-missing选项 3. 更换软件源 4. 清理和修复包管理器 总结 在使用Ubuntu进行软件包安装时,有时可能会遇到404错误。这种错误通常是由于软件源中的某些包已经被移除或迁移到其他位置。本文将介绍几种解决…...
SpringBoot中MyBatisPlus的使用
MyBatis Plus 是 MyBatis 的增强工具,提供了许多强大的功能,简化了 MyBatis 的使用。下面是在 Spring Boot 中使用 MyBatis Plus 的步骤: 添加依赖:在 Maven 或 Gradle 的配置文件中添加 MyBatis Plus 的依赖。 配置数据源&#…...

前后端交互:axios 和 json;springboot 和 vue
vue 准备的 <template><div><button click"sendData">发送数据</button><button click"getData">接收</button><button click"refresh">刷新</button><br><ul v-if"questions&…...
)
前端技术专家岗(虚拟岗)
定位: 团队技术负责人、技术领导者;确保框架、工具的低门槛、高性能、可扩展; 素质要求: 具备架构设计能力;一个或者多个领域的技术专家;较为丰富的基础建设经验;项目管理能力、任务分解、协…...
redis windows环境下的部署安装
2024Redis windows安装、部署与环境变量 一、下载 Redis官网目前暂不支持Windows版本,只能从github中下载。 windows 64位系统下载redis路径:https://github.com/tporadowski/redis/releases,下载zip包。 目前Windows版本只更新到5.0的版本…...
大字体学生出勤记录系统网页HTML源码
源码介绍 上课需要一个个点名记录出勤情况,就借助AI制作了一个网页版学生出勤记录系统, 大字体显示学生姓名和照片,让坐在最后排学生也能看清楚,显示姓名同时会语音播报姓名, 操作很简单,先导入学生姓名…...

筛斗数据提取技术在企业成本预测中的应用
在当今的商业环境中,准确的成本预测对于企业的财务健康和战略规划至关重要。随着大数据和人工智能技术的飞速发展,数据提取技术已经成为企业进行成本预测的强大工具。本文将探讨数据提取技术如何帮助企业进行成本预测,并分析其对企业决策过程…...

enum编程入门:探索枚举类型的奥秘
enum编程入门:探索枚举类型的奥秘 在编程的世界里,enum(枚举)类型是一种特殊的数据类型,它允许我们为变量设置一组预定义的、有限的值。这种类型在很多编程语言中都得到了广泛的应用,为开发者提供了更加清…...
刷机 iPhone 进入恢复模式
文章目录 第 1 步:确保你有一台电脑(Mac 或 PC)第 2 步:将 iPhone 关机第 3 步:将 iPhone 置于恢复模式第 4 步:使用 Mac 或 PC 恢复 iPhone需要更多协助? 本文转载自:如果你忘记了 …...

计算属性和侦听器:为什么在某些情况下使用计算属性比使用methods更好,如何使用侦听器来监听数据的变化。
计算属性和methods的区别和使用场景 计算属性(Computed properties)是 Vue 中非常重要的一个功能,它有以下的优点: 数据缓存:计算属性基于它们的依赖进行缓存。只有在相关依赖发生变化时,才会重新求值。这…...

一文带你搞懂大事务的前因后果
引言 一文带你搞懂Spring事务上篇文章介绍了Spring事务相关内容,本文主要介绍业务开发中遇到的大事务问题。 https://github.com/WeiXiao-Hyy/blog 整理了Java,K8s,极客时间,设计模式等内容,欢迎Star! 什么是大事务 运行时间(调用远程事务或…...
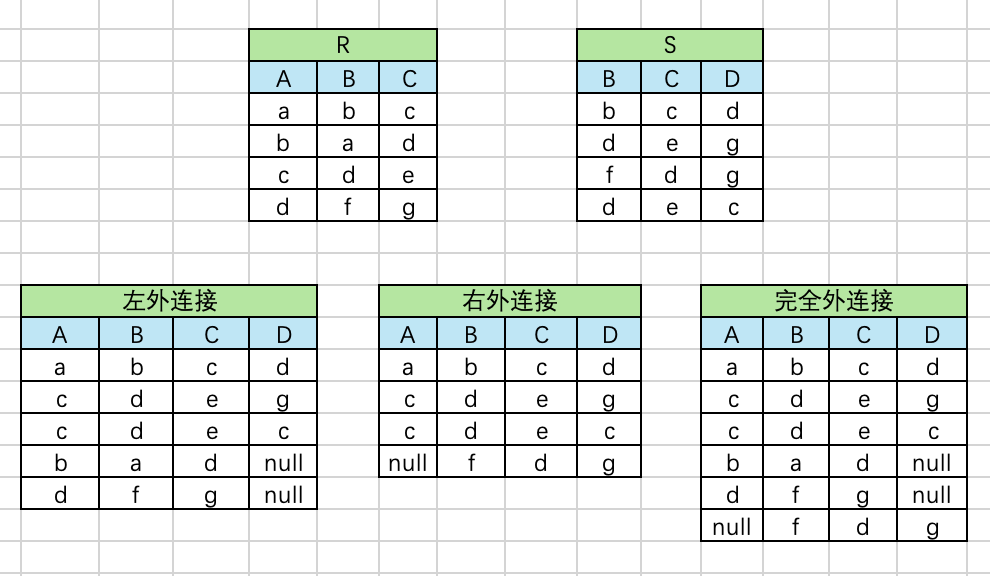
关系数据库:关系运算
文章目录 关系运算并(Union)差(Difference)交(Intersection)笛卡尔积(Extended Cartesian Product)投影(projection)选择(Selection)除…...
微信公众号开发(三):自动回复“你好”
上一篇做了服务器校验,但没有处理用户发来的消息,为了完成自动回复的功能,需要增加一些功能: 1、调整服务器校验函数: def verify_wechat(request):tokentokendatarequest.argssignaturedata.get(signature)timestamp…...

docker基本操作命令(3)
目录 1.Docker服务管理命令: 启动:systemctl start docker 停止:systemctl stop docker 重启:systemctl restart docker 开机自启:systemctl enable docker 查看docker版本: 2.镜像常用管理命令&…...

003 MySQL
文章目录 左外连接、右外连接 的区别where/having的区别执行顺序聚合 聚合函数MySQL约束事务一致性一致性的含义一致性在事务中的作用如何维护一致性 存储引擎 Innodb MyIsam区别事务的ACID属性数据库的隔离级别MySQL中的并发问题1. 锁等待和死锁2. 并发冲突3. 脏读、不可重复读…...
)
数据分析------统计学知识点(一)
1.在统计学中,均值分类有哪些? 算术均值:平均值,所有数值加总后除以数值的个数 几何均值:所有数值相乘后,再取其n次方根,n是数值的个数 调和均值:是数值倒数的算术均值的倒数 加…...
)
Apache Doris 基础 -- 数据表设计(分区分桶)
Versions: 2.1 本文档主要介绍了Doris的表创建和数据分区,以及表创建过程中可能遇到的问题和解决方案。 1、基本概念 在Doris中,数据以表的形式被逻辑地描述。 1.1 Row & Column 表由行和列组成: 行:表示用户数据的单行;列:用于描述一行数据中的…...

题目:求0—7所能组成的奇数个数。
题目:求0—7所能组成的奇数个数。 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheated should…...

霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度
霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度 不知道你有没有遇到过这种情况:想让AI画一个穿汉服的女孩,结果出来的图,发型和衣服总是一起“跑偏”。比如,你想生成一个“唐代齐胸襦裙”的造型&…...

Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例
Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例 1. 惊艳效果预览 Kandinsky-5.0-I2V-Lite-5s带来的建筑漫游视频生成效果令人印象深刻。想象一下,你有一张静态的建筑设计图纸,通过这个模型,只需简单描述…...

CMake + VTK 编译
CMake VTK 编译 1下载 1 CMake下载 https://cmake.org/download/#older2 VTK 下载 https://gitlab.kitware.com/vtk/vtk/-/tags2 安装和解压缩 3 配置CMake 这一部分忘了截图 ,可以查看这里的步骤,基本一致 https://blog.csdn.net/weixin_42964413/arti…...

DanKoe 视频笔记:每日60分钟改变生活:引言与概述
在本教程中,我们将学习如何通过每天投入60分钟来系统地改变生活。我们将探讨常规的重要性,并介绍三个核心习惯,帮助你重新掌控精力、提升财务状况、改善健康以及获得内心的清晰。 每日60分钟改变生活:2:常规的必要性 …...

vLLM-v0.17.1保姆级教程:vLLM + Weights Biases 实验跟踪实践
vLLM-v0.17.1保姆级教程:vLLM Weights & Biases 实验跟踪实践 1. vLLM框架简介 vLLM是一个专注于大语言模型推理和服务的开源库,以其出色的性能和易用性在开发者社区中广受欢迎。这个项目最初由加州大学伯克利分校的天空计算实验室发起࿰…...

手把手教你用Python实现熵权PCA:从数据清洗到可视化,一个案例全讲透
用Python实战熵权PCA:电商商品竞争力分析全流程解析 在电商平台的海量商品中,如何快速识别出真正具有竞争力的产品?传统的人工筛选方式不仅效率低下,还容易受到主观偏见的影响。本文将带你用Python实现一个完整的熵权PCA分析流程&…...

乙巳马年春联生成终端参数详解:长文本生成稳定性保障机制
乙巳马年春联生成终端参数详解:长文本生成稳定性保障机制 1. 引言:当传统春联遇见现代AI 每到新年,家家户户贴春联是传承千年的习俗。一副好春联,不仅要对仗工整、平仄协调,更要蕴含美好的寓意。但创作一副原创的、有…...

XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统
XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一个专为Unity游戏设计的自动翻译插件,…...

BinCmdParser:嵌入式二进制命令动态解析器
1. BinCmdParser:面向嵌入式通信的动态二进制命令解析器 在工业控制、传感器网络与跨平台设备互联场景中,串口/UART/SPI/I2C等低带宽物理通道常承载结构化二进制指令。传统固定帧格式(如Modbus RTU、自定义8字节头4字节长度2字节CRCÿ…...

5分钟快速部署!终极开源邮件营销平台BillionMail完全指南 [特殊字符]
5分钟快速部署!终极开源邮件营销平台BillionMail完全指南 🚀 【免费下载链接】BillionMail Billion Mail is a future open-source email marketing platform designed to help businesses and individuals manage their email campaigns with ease 项…...