数据结构作业
第1章 绪论
单选题
-
数据在计算机的存储器中表示时,逻辑上相邻的两个元素对应的物理地址也是相邻的,这种存储结构称之为________。
- B. 顺序存储结构
-
算法指的是________。
- D. 求解特定问题的指令有限序列
-
下面程序段的时间复杂度为:________。
for(i=1;i<=n;++i) for(j=1;j<=n;++j) s+=a[i][j];- D. O(n²)
-
设数据结构S=(D,R),其中D={1,2,3,4},R={<1,2>,<2,3>,❤️,4>},则数据结构S属于________。
- B. 线性结构
-
设部门的上级领导下级的数据结构S=(D,R),其中D={a,b,c,d,e},R={ a领导b a领导c,b领导d b领导 e },则数据结构S属于________。
- C. 树结构
-
以下数据结构中,________是线性结构。
- A. 字符串
-
在数据结构中,从逻辑上可以把数据结构分为________。
- C. 线性结构和非线性结构
-
某算法的语句执行频度为(n²+nlog₂n+3n+8),其时间复杂度为________。
- C. O(n²)
-
算法的时间复杂度取决于________。
- D. A和B
-
设数据结构S=(DR),其中D={1234},R={<12><23><34><41>},则数据结构S是( )。
- C. 图结构
-
算法分析的两个主要方面是( )。
- B. 时间复杂度和空间复杂度
-
抽象数据类型的三个组成部分分别是( )。
- C. 数据对象、数据关系、基本操作
-
以下程序段中语句“m++;”的语句频度是( )。
int m=0; for(i=1;i<=n;i++) for(j=1;j<=2*i;j++)m++;- A. n(n+1)
-
链式存储的存储结构所占存储空间( )。
- A. 分为两部分,一部分存放结点值,另一部分存放表示结点间关系的指针
填空题
- 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
- 线性结构中元素之间存在一对一关系,树结构中元素之间存在一对多关系,图结构中元素之间存在多对多关系。
- 链式存储结构为了表示结点之间的关系,通常需要给每个结点附加指针字段,用于存放后继元素的地址。
- 抽象数据类型一般指由用户定义的、表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。具体包括3个部分:数据对象、数据关系、基本操作。
- 算法的5个特征是有穷性、确定性、可行性、输入、输出。
- 顺序存储结构中数据元素之间的逻辑关系是由物理地址表示的,链式存储结构中数据元素之间的逻辑关系是由指针表示的。
简答题
-
简述逻辑结构的四种基本关系并画出它们的关系图。
- 逻辑结构的四种基本关系:集合结构、线性结构、树形结构、图形结构。
- 集合结构:元素之间无特定关系
- 线性结构:元素之间存在一对一的关系
- 树形结构:元素之间存在一对多的层次关系
- 图形结构:元素之间存在多对多的关系
- 逻辑结构的四种基本关系:集合结构、线性结构、树形结构、图形结构。
-
存储结构有哪两种基本的存储方法实现?
- 顺序存储
- 链式存储
-
简述算法的定义与特性。
- 算法是解决问题的一系列步骤或程序。特性包括有穷性、确定性、可行性、输入、输出。
第2章 线性表
单选题
-
以下叙述正确的是( )。
- B. 顺序表可以实现随机存取。
-
线性表(a1a2…an)以链式方式存储时,访问第i个位置上的元素的时间复杂度为( )。
- B. O(n)
-
线性表的顺序存储结构是一种( )的存储结构。
- A. 随机存取
-
线性表在( )情况下适用于使用链式结构存储。
- B. 需要不断对线性表进行插入、删除操作。
-
以下属于顺序表的优点的是( )。
- C. 存储密度大。
-
下列叙述错误的是( )。
- D. 线性表的链式存储结构优于顺序存储结构。
填空题
- 顺序表中逻辑上相邻的元素物理位置一定相邻,单链表中逻辑上相邻的元素物理位置不一定相邻。
- 若一个长度为n的顺序表中,在第i个位置(1≤i≤n)插入一个新的元素共需要移动n-i个元素;若一个长度为n的顺序表中,删除第i个元素(1≤i≤n)时需向前移动n-i-1个元素。
- 已知顺序表中第一个元素的存储地址是1000,每个元素的长度为4,则第7个元素的存储地址是1024。
- 向一个有200个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数为100。
- 在一个以L为头指针的单循环链表中,p指针指向链尾的条件是p->next == L。
判断题
-
线性表中每个元素都有一个前驱和一个后继。( )
- 错
-
线性表中所有元素的数据类型必须相同。( )
- 对
-
顺序表结构适宜于进行随机存取,而链表适宜于进行顺序存取。( )
- 对
-
单链表可以实现随机存取。( )
- 错
-
线性表若采用链式存储结构时,其存储结点的地址可以连续,也可以不连续。( )
- 对
-
线性表的顺序存储结构优于链式存储结构。( )
- 错
-
进行插入删除操作时,在链表中比在顺序表中效率高。( )
- 对
-
在顺序表中,逻辑上相邻的元素物理位置上不一定相邻。( )
- 错
-
若频繁地对线性表进行插入和删除操作,该线性表采用链式存储结构更合适。( )
- 对
简答题
-
简述线性结构的特点。
- 线性结构的特点是元素之间存在一对一的线性关系,每个元素只有一个前驱和一个后继。
-
简述顺序表和链表的主要优缺点。
- 顺序表优点:支持随机存取,存储密度大。缺点:插入和删除操作效率低,存储空间不灵活。
- 链表优点:插入和删除操作效率高,存储空间灵活。缺点:不支持随机存取,存储密度低。
综合题
-
请用代码描述如下单链表的插入操作,将s所指结点插入到结点a和b之间。
s->next = a->next; a->next = s; -
请用代码描述如下单链表的删除操作,将结点b删除。
a->next = b->next; delete b;
3.**请用代码描述
b=a->next
x->pre=a
a->next=x
x->next=b
b->pre=x
4. 删除p的所指节点b
b=a->next
c=a->next->next
a->next=c
c->pre=a
delete b
第3章 栈和队列
一、单选题
- 栈在( D,递归+表达式求值+括号匹配 )中有所应用。
- 栈和队列的共同点是( C. 只允许在端点处插入和删除元素 )。
- 最大容量为n的循环队列,队尾指针是rear,队头是front,则判断队空和队满的条件,正确的是( B. 队空:rearfront;队满:(rear+1)%nfront; )。
- 下列说法中符合队列性质的是( D. 只能在一边插入和另一边删除 )。
- 设一个队列的入队序列为d,c,b,a,则队列的输出序列是( B.dcba)。
- 若用一个大小为6的数组实现循环队列,且当前rear和front的值分别为0和3,当从队列中删除一个元素,再插入两个元素后,rear和front的值分别为( C. 2和4 )。
- 为解决计算机主机与打印机间速度不匹配问题,通常设一个打印数据缓冲区。主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是( A. 队列 )。
- 若一个栈以数组V[1…n]存储,初始栈顶指针top设为n+1,则元素x进栈的正确操作是( C top–;V[top]=x; )。
- 若一个栈以数组V[1…n]存储,初始栈顶指针top设为0,则元素x进栈的正确操作是( A. top++; V[top]=x; )。
- 若已知一个栈的入栈序列是1,2,3,…,n,其输出序列为p1,p2,p3,…,pn,若p1=n,则pi为( C. n-i )。
- 设计一个判别表达式中左、右括号是否配对出现的算法,采用( C. 栈 )数据结构最佳。
- 一个栈的入栈序列是a,b,c,d,e, 且在入栈过程中可出栈,则栈的不可能的输出序列是( C. dceab )。
- 队列是限定在( C.队尾)处进行插入操作的线性表。
- 设栈S和队列Q的初始状态为空,元素e1,e2,e3,e4,e5,e6依次进入栈S,一个元素出栈后即进入Q,若6个元素出队的序列是e2,e4,e3,e6,e5,e1,则栈S的容量至少应该是( B3 )。
- 若元素a,b,c,d,e,f依次进栈,允许进栈、出栈操作交替进行,但不允许连续三次进行出栈工作,则不可能得到的出栈序列是( D.afedcb )。
二、判断题
- 队列是一种插入与删除操作分别在表的两端进行的线性表,是一种先进后出的线性结构。( × )
- 循环队列属于队列的链式存储结构。( × ) (是队列的顺序存储结构)
- 若输入序列为1,2,3,4,5,6,则通过一个栈可以输出序列3,1,5,6,4,2。( × )
- 一个递归算法必须包括终止条件和递归部分。( √ )
三、简答题:
栈是一种先进后出(LIFO)的线性数据结构,只允许在表的一端进行插入和删除操作,即栈顶端。栈的特点是后进入的元素先出来,它可以通过顺序存储结构或链式存储结构实现。常见的应用包括递归调用、表达式求值、括号匹配等。
队列是一种先进先出(FIFO)的线性数据结构,插入操作在队尾进行,删除操作在队头进行,只能在表的两端进行操作。队列的特点是先进入的元素先出来,它同样可以通过顺序存储结构或链式存储结构实现。常见的应用包括任务调度、缓冲区管理等。
四、算法分析题:
1、
Status Push(SqStack &S, SElemType e)
{ if (S.top == MAXSIZE - 1) return ERROR; // 判断栈满的条件S.data[++S.top] = e; // 将e入栈,栈顶指针top上移return OK;
}
2、
Status Pop(SqStack &S, SElemType &e)
{ if(S.top == -1) return ERROR; // 判断栈空的条件e = S.data[S.top--]; // 用e返回栈顶元素,栈顶指针top下移return OK;
}
3、
void conversion(int N)
{ InitStack(S);while(N){ Push(S, N % 2); // ①将N % 2入栈N = N / 2;}while(!StackEmpty(S)){ Pop(S, e); // ②从栈中出栈,得到二进制数的每一位cout << e;}
}
4、
Status EnQueue(SqQueue &Q, QElemType e)
{ if((rear+1)%n==front)return ERROR;Q[rear]=e;rear++;Return OK
}
Status DeQueue(SqQueue &Q, QElemType &e)
{ if(rear==front)return ERROR;e=Q[front];front++;Return OK
}
第4章 串、数组和广义表
一、单选题
- 下面说法不正确的是(C. 广义表的表头总是一个广义表)。
- 两个串相等必有串长度相等且(B. 串中各位置字符均对应相等)。
- 设有两个串p和q,求q在p中首次出现的位置的运算称作(B. 模式匹配)。
- 已知串S=“abcaba”的next数组为(C. 011123)。
解析: 1. abcaba -->000121 (就是比较每个字符和首部是否相等)
2.000121 每个加1------> 111232
3.111232 向右移为:011123
4.得到结果011123 - 下面表述正确的是(A. 串是一种特殊的线性表)。
- 对于n阶对称矩阵,如果采用压缩存储,需要(D. n2/2)个存储单元。
- 对特殊矩阵进行压缩存储目的是(C. 节省存储空间)。
- 设一维数组中有n个元素,则读取第i个数组元素的平均时间复杂度为(C. O(1))。
- 数组A[0…7,0…9]的每个元素占3个字节,将其按行列先次序存储在起始地址为1000的内存单元中,则元素A[7,4]的起始地址是(D. 1222)。
- 数组A[0…5,0…6]的每个元素占五个字节,将其按行优先次序存储在起始地址为1000的内存单元中,则元素A[5,5]的地址是(B. 1200)。
- 假设二维数组A[1…60,1…70]以列序为主序顺序存储,其基地址是10000,每个元素占2个存储单元,则元素A[32,58]的存储地址是(B. 16902)。
- 设广义表L=((a,b,c)),则L的长度和深度分别为(C 1和2)。
解析:长度为第一层的所有元素个数(1),深度为一共几层括号(2) - 对广义表L=((a,b),(c,d),(e,f))执行操作GetTail(GetTail(L))的结果是(B.((e,f)))。
二、填空题
- 若矩阵中的所有元素均满足aij=aji,则称此矩阵为 对称矩阵。
- 数组A[0…7,0…8]的每个元素占4个字节,分别将其按行优先、列优先次序存储在起始地址为1000的内存单元中,则元素A[3,6]的地址是1132 和1204。
- 模式串P=“abaabcac”的next函数值序列为 011223012。
- 设字符串S=‘You︺did︺a︺very︺good︺job!’,其长度是24。
- 子串“ture”在主串“datastructure”中的位置 9。
- 设串S=“abcde”,其长度是 5。
- 已知广义表L=((a,b),(c,d)),则head(L)是 (a,b) ,tail(L)是 ((c,d)) ,长度为 2 ,深度为 2。
- 广义表((a,b,c,d))的表头是 (a,b,c,d) ,表尾是 () 。
- 已知广义表C= (a,(b,A),B),则其长度是 3 ,深度是 无穷大 。
- 利用KMP算法进行模式匹配时,模式串t=“abcabaa”的next函数值是 0111232。
三、判断题
- 串是一种数据对象和操作都特殊的线性表。(√)
- KMP算法的特点是在模式匹配时指示主串的指针不会变小。(√)
- 数组可看成线性结构的一种推广,因此与线性表一样,可以对它进行插入,删除等操作。(×)
- 数组和广义表不属于线性结构。(×)
- 二维数组A[-3…5,0…10]中共有80个元素。(×)
- 稀疏矩阵和特殊矩阵压缩存储后均可以实现随机存取。(×)
- 数组元素的下标值越大,存取时间越长。(×)
- 子串在主串中的位置以子串的第一个字符在主串中的位置来表示。(√)
- KMP算法可以在O(m+n)的时间数量级上完成串的模式匹配操作。(√)
- 对n阶矩阵,若矩阵中的元素在i>=j时均满足aij为0或为常数,则称此矩阵为下三角矩阵。(√)
- 一个广义表的表头总是一个广义表。(×)
四、简答题
串的模式匹配是指在一个主串中查找某个子串的过程。常用的两种模式匹配算法是暴力匹配算法(BF算法)和Knuth-Morris-Pratt算法(KMP算法)。
五、算法分析题
1、BF算法:
int Index_BF(SString S, SString T, int pos) {int i = pos;int j = 1;while (i <= S.length && j <= T.length) { // ① 两个串均未比较到串尾if (S.ch[i] == T.ch[j]) { // ② 继续比较后续字符
```cppi++;j++;} else {i = i - j + 2; // ④ 指针回溯重新开始匹配j = 1;}}if (j > T.length) // ⑤ 匹配成功,返回位置序号return i - T.length;elsereturn 0; // ⑥ 匹配失败,返回0
}
2、KMP算法:
int Index_KMP(SString S, SString T, int pos) {int i = pos;int j = 1;while (i <= S.length && j <= T.length) { // ① 两个串均未比较到串尾if (j == 0 || S.ch[i] == T.ch[j]) { // ② 继续比较后续字符i++;j++;} else {j = T.next[j]; // ④ 子串向右滑动至第next[j]个位置}}if (j > T.length) // ⑤ 匹配成功,返回位置序号return i - T.length;elsereturn 0; // ⑥ 匹配失败,返回0
}
一、单选题
- B. 100
解析:哈夫曼树只有度(每个节点孩子数)为2和0的节点,以满二叉树为例,叶子节点有2(n)个,总结点数有2(n+1)-1个
得出总结点= n,叶子结点数有(n+1)/2
叶子结点= n,总结点数有2n-1
2.B. (0,1,00,11)
解析:前缀码是指,画出的图形中不存在节点之间为父子关系 - D. 501
- D. 2^h-1
- B 11
解析:n0=n2+1记住就行 - D5
- B. 只有一个结点的二叉树的度为0
- D. 2i - 1
- A. 11
- B. 10
二、填空题
- 6
- 63
- 16
- DGEBFCA
- 7
- 4, 96
7.FBADCFHGIJK - n+1
- 7 (2^(5-1)=16,第五层本来有16个结点,但是有16-7+1=8没有子节点,所以有7+8/2=11个叶子结点)
- 是
三、判断题
- 是
- 是
- 是
- 错误
- 错误
- 错误
- 错误
- 错误
- 错误
- 错误
- 是
- 错误
四、综合题
- 先序遍历:ABCDEFGHIJKL, 中序遍历:DCEBFAIHGKLJ, 后序遍历:DECFBIHKLJGA
- 先序遍历:ABDHEIJCFLGMN, 中序遍历:HDBIEJAFCLMGN, 后序遍历:HDIJEBLFMNFCA
- 先序遍历:ABCDEFGH, 中序遍历:DCEBAFHG, 后序遍历:ECBGHFA
- 先序遍历:ABCDEF, 中序遍历:CBDAFE, 后序遍历:CDBFEA
- 哈夫曼编码:A: 01, B: 10, C: 000, D: 001, E: 11, WPL = 91
- 数据传输长度最短的编码:C: 000,S:001,E:01,A:10,T:11
STATE:00111101101
SEAT:001011011
ACT:1000011
TEA:110110
CAT:0001011
SET:0010111
A:10
EAT:011011 - 先根遍历:ABDEIJFGKHC, 后根遍历:BIJEFKGHDC
一、单选题
- D. n(n-1)/2
解析:最多,所以是每个结点都和其余n-1个结点相连,有n*(n-1)个边
无向图为n*(n-1) /2 ,因为重复边,要除以2
有向图为n*(n-1) ,没有重复边 - B. n(n-1)
- B. 拓扑排序
- B. 每个顶点的度等于其入度与出度之和
- A. 2
解析:一个边连接两个顶点,,所以是边*2 - B. 1
解析:入度之和=出度之和 - A. 从源点到汇点的最长路径
- B. 任何一个关键活动提前完成,整个工程也将提前完成
- B 12
- A. n-1
解析:树的顶点数= 边数+1,随便画个树就能看出来
11.B. 3,1,2,4,5
解析:每次找入度为0的顶点,输出,然后删除这个顶点和连接这个顶点的边,继续找入度为0的 - D. 对称矩阵
二、填空题
- 6
- 20
三、判断题
- 错误
- 错误
- 错误
- 是
- 是
- 是
- 是
四、综合题
1.
- DFS序列:1364527
- BFS序列:1346527
- [图示 Prim 算法和 Kruskal 算法构造最小生成树的全过程]
- [AOV-网的拓扑排序序列]
- 一种拓扑排序序列:ACEBDFHGI
- 另一种拓扑排序序列:ACEHBDGFI
-
- Ve 和 Vl 表格如下:
| 顶点 | 最早发生时间 Ve | 最晚发生时间 Vl |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 3 | 3 |
| 3 | 4 | 5 |
| 4 | 10 | 10 |
| 5 | 8 | 9 |
| 6 | 14 | 14 |
- 关键路径为:1 ->a1->2->a3->4->a8->6
- 工程完工的最短时间为 14 天
解析:最早发生时间就是从起点到终点找所有连接和中最大的
最晚发生时间就是从终点到起点找结点数-边值(差值)最小的
vl - ve == 0 的活动为关键活动,关键活动跟状态连起来就为关键路径。
第7章 查找
一、单选题
-
对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( )。
- C. (n+1)/2
-
适用于折半查找的表的存储方式及元素排列要求为( )。
- D. 顺序方式存储,元素有序
-
折半查找有序表(4,6,10,12,20,30,50,70,88,100)。若查找表中元素58,则它将依次与表中( )比较大小,查找结果是失败。
- A. 20 70 30 50
-
对22个记录的有序表作折半查找,当查找失败时,至多需要比较( )次关键字。
- C. 5
-
分别以下列序列构造二叉排序树,与用其它三个序列所构造的结果不同的是( )。
- C (100,60,80,90,120,110,130)
解析:二叉排序树则为左边比父类小,右边比父类大,每次从根节点开始找
- C (100,60,80,90,120,110,130)
-
设哈希表长为14,哈希函数是H(key)=key%11,表中已有数据的关键字为15,38,61,84共四个,现要将关键字为49的元素加到表中,用二次探测法解决冲突,则放入的位置是( )。
- D. 9
解析:二次探测法,为二次幂,12,22,32,42,累加
线性探测为1 2 3 4 5 6线性累加
- D. 9
-
衡量查找算法效率的主要标准是( )。
- C. 平均查找长度
二、填空题
- 计算哈希地址时若产生冲突,可以采用开放定址法和链地址法解决冲突。
- 在长度为500的有序表中进行折半查找,查找不成功时和给定值进行比较的关键字个数最多为9。
解析:log以2为底500的对数=9
三、综合题
-
已知如下11个数据元素的有序表(05,13,19,21,37,56,64,75,80,88,92),请画出其“折半查找”到数据“37”的全过程。
- 第一步:中间位置为56,与37比较,37<56,继续在左半部分查找。
- 第二步:中间位置为19,与37比较,37>19,继续在右半部分查找。
- 第三步:中间位置为37,查找成功。
-
已知一组关键字为(47,7,29,11,16,92,22,8,3),散列函数为H(key)=key%11,用线性探测法处理冲突。设表长为11,试构造这组关键字的散列表,并写出查找每个关键字的比较次数,最后计算查找成功时的平均查找长度(四舍五入保留一位小数)。
| 散列地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 11 | 22 | 47 | 92 | 16 | 3 | 7 | 29 | 8 | ||
| 比较次数 | 1 | 2 | 1 | 1 | 1 | 4 | 1 | 2 | 2 |
计算查找成功时的平均查找长度:
15/9=1.7
第8章 排序
一、单选题
1、从未排序序列中依次取出元素与已排序序列中的元素进行比较,将其放入已排序序列的正确位置上的方法,这种排序方法称为( )。
C.插入排序
2、从未排序序列中挑选元素,并将其依次放入已排序序列(初始时为空)的一端的方法,称为( )。
D.选择排序
3、对n个不同的关键字由小到大进行冒泡排序,在下列( )情况下比较的次数最多。
B.从大到小排列好的
4、对n个不同的排序码进行冒泡排序,在元素无序的情况下比较的次数最多为( )。
D.n(n-1)/2
5、下面( )方法是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。
D.基数排序
6、若一组记录的排序码为(46, 79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为( )。
A. 38 40 46 56 79 84
7、下列关键字序列中,( )是堆。
D.16,23,53,31,94,72
8、堆排序是一种( )排序。
B.选择
9、堆的形状是一棵( )。
C.完全二叉树
10、下列排序算法中,( )不属于选择排序。
A.希尔排序
11、下列排序算法中不稳定的是( )。
D.快速排序
二、综合题
设待排序的关键字序列为{12,2,16,30,28,10,16*,20,6,18},试分别写出使用以下排序方法,每趟排序结束后关键字序列的状态。
①直接插入排序
[2 12] 16 30 28 10 16* 20 6 18
[2 12 16] 30 28 10 16* 20 6 18
[2 12 16 30] 28 10 16* 20 6 18
[2 12 16 28 30] 10 16* 20 6 18
[2 10 12 16 28 30] 16* 20 6 18
[2 10 12 16 16* 28 30] 20 6 18
[2 10 12 16 16* 20 28 30] 6 18
[2 6 10 12 16 16* 20 28 30] 18
[2 6 10 12 16 16* 18 20 28 30]
②希尔排序
10 2 16 6 18 12 16* 20 30 28 (增量选取5)
6 2 12 10 18 16 16* 20 30 28 (增量选取3)
2 6 10 12 16 16* 18 20 28 30 (增量选取1)
③简单选择排序
[2],12,16,6,30…
[2,6],12,16,30,29
[2,6,10,]…
[2,6,10,12],…
[2 6 10 12 16 16* 18 20 28 30]
一直取最小/最大 和后面的交换位置
④ 冒泡排序
2 12 16 28 10 16* 20 6 18 [30]
2 12 16 10 16* 20 6 18 [28 30]
2 12 10 16 16* 6 18 [20 28 30]
2 10 12 16 6 16* [18 20 28 30]
2 10 12 6 16 [16* 18 20 28 30]
2 10 6 12 [16 16* 18 20 28 30]
2 6 10 [12 16 16* 18 20 28 30]
2 6 10 12 16 16* 18 20 28 30]
⑤快速排序
12 [6 2 10] 12 [28 30 16* 20 16 18]
6 [2] 6 [10] 12 [28 30 16* 20 16 18 ]
28 2 6 10 12 [18 16 16* 20 ] 28 [30 ]
18 2 6 10 12 [16* 16] 18 [20] 28 30
16* 2 6 10 12 16* [16] 18 20 28 30
相关文章:

数据结构作业
第1章 绪论 单选题 数据在计算机的存储器中表示时,逻辑上相邻的两个元素对应的物理地址也是相邻的,这种存储结构称之为________。 B. 顺序存储结构 算法指的是________。 D. 求解特定问题的指令有限序列 下面程序段的时间复杂度为:_______…...
项目纪实 | 版本升级操作get!GreatDB分布式升级过程详解
某客户项目现场,因其业务系统要用到数据库新版本中的功能特性,因此考虑升级现有数据库版本。在升级之前,万里数据库项目团队帮助客户在本地测试环境构造了相同的基础版本,导入部分生产数据,尽量复刻生产环境进行升级&a…...

富格林:应用正规技巧阻挠被骗
富格林悉知,随着如今入市现货黄金的朋友愈来愈多,不少投资者也慢慢开始重视起提高自身的正规投资技巧,希望能阻挠被骗更高效地在市场上获利。虽然目前黄金市场存在一定的受害风险,但只要投资者严格按照正规的交易规则来做单&#…...
【模型架构】学习RNN、LSTM、TextCNN和Transformer以及PyTorch代码实现
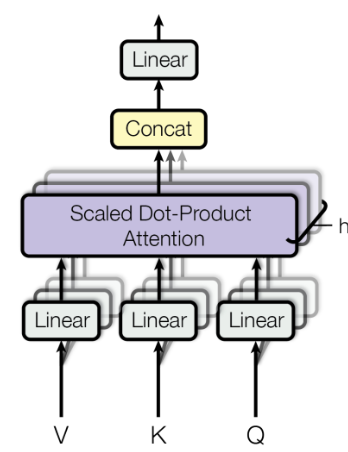
一、前言 在自然语言处理(NLP)领域,模型架构的不断发展极大地推动了技术的进步。从早期的循环神经网络(RNN)到长短期记忆网络(LSTM)、Transformer再到当下火热的Mamba(放在下一节&a…...
【LeetCode】38.外观数列
外观数列 题目描述: 「外观数列」是一个数位字符串序列,由递归公式定义: countAndSay(1) "1"countAndSay(n) 是 countAndSay(n-1) 的行程长度编码。 行程长度编码(RLE)是一种字符串压缩方法,…...
)
如何解决Ubuntu中软件包安装时的404错误(无法安装gdb、cgddb等)
目录 问题描述 解决方法 1. 更新软件包列表 2. 使用--fix-missing选项 3. 更换软件源 4. 清理和修复包管理器 总结 在使用Ubuntu进行软件包安装时,有时可能会遇到404错误。这种错误通常是由于软件源中的某些包已经被移除或迁移到其他位置。本文将介绍几种解决…...
SpringBoot中MyBatisPlus的使用
MyBatis Plus 是 MyBatis 的增强工具,提供了许多强大的功能,简化了 MyBatis 的使用。下面是在 Spring Boot 中使用 MyBatis Plus 的步骤: 添加依赖:在 Maven 或 Gradle 的配置文件中添加 MyBatis Plus 的依赖。 配置数据源&#…...

前后端交互:axios 和 json;springboot 和 vue
vue 准备的 <template><div><button click"sendData">发送数据</button><button click"getData">接收</button><button click"refresh">刷新</button><br><ul v-if"questions&…...
)
前端技术专家岗(虚拟岗)
定位: 团队技术负责人、技术领导者;确保框架、工具的低门槛、高性能、可扩展; 素质要求: 具备架构设计能力;一个或者多个领域的技术专家;较为丰富的基础建设经验;项目管理能力、任务分解、协…...
redis windows环境下的部署安装
2024Redis windows安装、部署与环境变量 一、下载 Redis官网目前暂不支持Windows版本,只能从github中下载。 windows 64位系统下载redis路径:https://github.com/tporadowski/redis/releases,下载zip包。 目前Windows版本只更新到5.0的版本…...
大字体学生出勤记录系统网页HTML源码
源码介绍 上课需要一个个点名记录出勤情况,就借助AI制作了一个网页版学生出勤记录系统, 大字体显示学生姓名和照片,让坐在最后排学生也能看清楚,显示姓名同时会语音播报姓名, 操作很简单,先导入学生姓名…...

筛斗数据提取技术在企业成本预测中的应用
在当今的商业环境中,准确的成本预测对于企业的财务健康和战略规划至关重要。随着大数据和人工智能技术的飞速发展,数据提取技术已经成为企业进行成本预测的强大工具。本文将探讨数据提取技术如何帮助企业进行成本预测,并分析其对企业决策过程…...

enum编程入门:探索枚举类型的奥秘
enum编程入门:探索枚举类型的奥秘 在编程的世界里,enum(枚举)类型是一种特殊的数据类型,它允许我们为变量设置一组预定义的、有限的值。这种类型在很多编程语言中都得到了广泛的应用,为开发者提供了更加清…...
刷机 iPhone 进入恢复模式
文章目录 第 1 步:确保你有一台电脑(Mac 或 PC)第 2 步:将 iPhone 关机第 3 步:将 iPhone 置于恢复模式第 4 步:使用 Mac 或 PC 恢复 iPhone需要更多协助? 本文转载自:如果你忘记了 …...

计算属性和侦听器:为什么在某些情况下使用计算属性比使用methods更好,如何使用侦听器来监听数据的变化。
计算属性和methods的区别和使用场景 计算属性(Computed properties)是 Vue 中非常重要的一个功能,它有以下的优点: 数据缓存:计算属性基于它们的依赖进行缓存。只有在相关依赖发生变化时,才会重新求值。这…...

一文带你搞懂大事务的前因后果
引言 一文带你搞懂Spring事务上篇文章介绍了Spring事务相关内容,本文主要介绍业务开发中遇到的大事务问题。 https://github.com/WeiXiao-Hyy/blog 整理了Java,K8s,极客时间,设计模式等内容,欢迎Star! 什么是大事务 运行时间(调用远程事务或…...
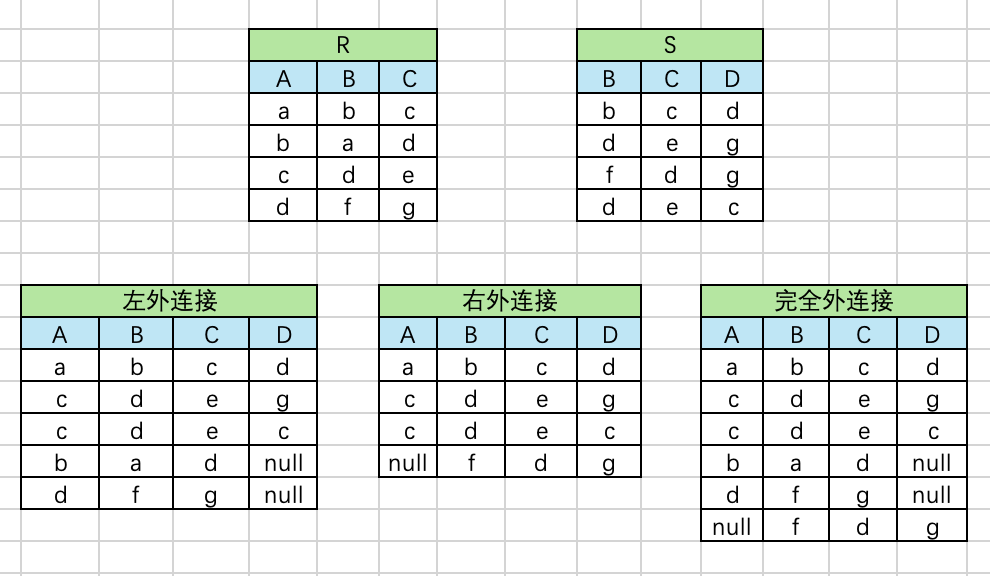
关系数据库:关系运算
文章目录 关系运算并(Union)差(Difference)交(Intersection)笛卡尔积(Extended Cartesian Product)投影(projection)选择(Selection)除…...
微信公众号开发(三):自动回复“你好”
上一篇做了服务器校验,但没有处理用户发来的消息,为了完成自动回复的功能,需要增加一些功能: 1、调整服务器校验函数: def verify_wechat(request):tokentokendatarequest.argssignaturedata.get(signature)timestamp…...

docker基本操作命令(3)
目录 1.Docker服务管理命令: 启动:systemctl start docker 停止:systemctl stop docker 重启:systemctl restart docker 开机自启:systemctl enable docker 查看docker版本: 2.镜像常用管理命令&…...

003 MySQL
文章目录 左外连接、右外连接 的区别where/having的区别执行顺序聚合 聚合函数MySQL约束事务一致性一致性的含义一致性在事务中的作用如何维护一致性 存储引擎 Innodb MyIsam区别事务的ACID属性数据库的隔离级别MySQL中的并发问题1. 锁等待和死锁2. 并发冲突3. 脏读、不可重复读…...
)
Podman镜像加速配置全攻略:阿里云/清华/网易源一键切换(附避坑指南)
Podman镜像加速实战:国内主流源配置与私有仓库部署指南 引言 容器技术已成为现代开发流程中不可或缺的一环,而镜像拉取速度直接影响开发效率。对于国内开发者而言,直接从Docker官方仓库拉取镜像常常面临网络延迟问题。本文将深入探讨Podman环…...

VLC播放RTSP流常见问题及解决方案
1. VLC播放RTSP流的基础操作指南 RTSP(Real Time Streaming Protocol)是一种广泛应用于监控摄像头、视频会议系统等场景的流媒体传输协议。作为一款开源跨平台的播放器,VLC对RTSP协议有着良好的支持。先说说最基本的操作流程,这对…...

SOONet模型Anaconda环境配置详解:创建隔离的Python开发环境
SOONet模型Anaconda环境配置详解:创建隔离的Python开发环境 你是不是也遇到过这种情况:电脑上跑着一个项目的代码好好的,一装另一个项目的依赖,结果两个都崩了。或者好不容易在本地调通了模型,部署到服务器上又是一堆…...

SLANeXt_wireless_safetensors:免费无线安全AI工具?
SLANeXt_wireless_safetensors:免费无线安全AI工具? 【免费下载链接】SLANeXt_wireless_safetensors 项目地址: https://ai.gitcode.com/paddlepaddle/SLANeXt_wireless_safetensors 导语:一款名为SLANeXt_wireless_safetensors的AI工…...

别再只用RSA了!手把手教你用Java SM2国密算法给接口数据加个密
Java开发者必看:从RSA到SM2国密算法的平滑迁移实战 当我们需要在API接口或数据传输中实现非对称加密时,RSA往往是大多数Java开发者的默认选择。但你可能不知道的是,在相同安全强度下,国密SM2算法的计算速度比RSA快得多,…...

FFT幅度谱数值翻倍?从MATLAB案例彻底搞懂频谱校正与帕斯瓦尔定理
FFT幅度谱数值翻倍?从MATLAB案例彻底搞懂频谱校正与帕斯瓦尔定理 信号处理工程师在分析传感器数据时,常常会遇到一个令人困惑的现象:相同的时域信号,在不同FFT点数下显示的幅度谱数值会成比例变化。比如1024点FFT显示峰值1024&…...

丹青识画系统Java八股文实践:设计模式在系统架构中的应用
丹青识画系统Java八股文实践:设计模式在系统架构中的应用 每次面试被问到“说说设计模式”,你是不是也只会背那几句“单例模式确保一个类只有一个实例”?然后心里嘀咕:这玩意儿在实际项目里到底有啥用?今天࿰…...
)
新手必看!Python逻辑运算符的5个易错点及避坑指南(附测试题)
Python逻辑运算符实战:从入门到精通的5个关键陷阱与解决方案 刚接触Python编程时,逻辑运算符看似简单,却暗藏玄机。许多初学者在条件判断、循环控制等场景中频频踩坑而不自知。本文将深入剖析and、or、not三大逻辑运算符的典型误用场景&#…...

终端开发者利器:OpenClaw操控百川2-13B实现CLI智能补全
终端开发者利器:OpenClaw操控百川2-13B实现CLI智能补全 1. 为什么开发者需要AI驱动的终端助手? 作为常年与终端打交道的开发者,我经常陷入这样的困境:面对复杂的Git操作时反复查阅文档,执行Docker命令时记不清参数顺…...

学习DHCP服务器
一、基本定义DHCP(Dynamic Host Configuration Protocol 动态主机配置协议)是用于自动为网络设备分配 IP 及网络参数的标准协议,最初定义于 RFC 1541,现已被 RFC 2131 取代。二、架构与端口采用 C/S 客户端 / 服务器 模型传输层协…...