2017年MathorCup数学建模A题流程工业的智能制造解题全过程文档及程序
2017年第七届MathorCup高校数学建模挑战赛
A题 流程工业的智能制造
原题再现:
“中国制造 2025”是我国制造业升级的国家大战略。其技术核心是智能制造,智能化程度相当于“德国工业 4.0”水平。“中国制造 2025”的重点领域既包含重大装备的制造业,也包含新能源、新材料制造的流程工业。
在流程工业中,钢铁冶金,石油化工等行业是代表性的国民经济支柱性产业。其生产过程的系统优化与智能控制的目标函数包括节能,优质,低耗,绿色环保等多目标要求。为了实现这样的优化目标,生产过程智能控制的关键技术就要从原来的反馈控制进一步升级为预测控制。即通过生产工艺大数据的信息物理系统(Cyber Physical System)建模,通过大数据挖掘,确定生产过程的最佳途径与最佳参数控制范围,预测性地动态调整生产过程控制,获得最佳生产效果。
以高炉冶炼优质铁水为例,高炉炼铁过程是按加料顺序由高炉顶部加入矿石和焦炭等原燃料,由高炉下部连续鼓入热风、喷入煤粉进行炉温调整的冶炼过程。从原燃料炉顶加入,到冶炼成炉渣和铁水,其冶炼周期 6-8 小时。而高炉每经过2 小时就出渣、出铁一次。并且化验得到此次出铁的铁水与炉渣的化学成分。因此,前后两炉铁水含硅量,即炉温之间是具有相关性的。炼铁过程是一个离散加入,连续冶炼,离散输出的复杂生产过程。
炼铁过程的机理既包含由热平衡/物料平衡约束的化学反应过程,也包括由三相流体动力学混合的物理运动过程。因此完整的冶炼过程机理模型是一个由代数方程组和偏微分方程组构成的复杂数学模型,模型方程如下:
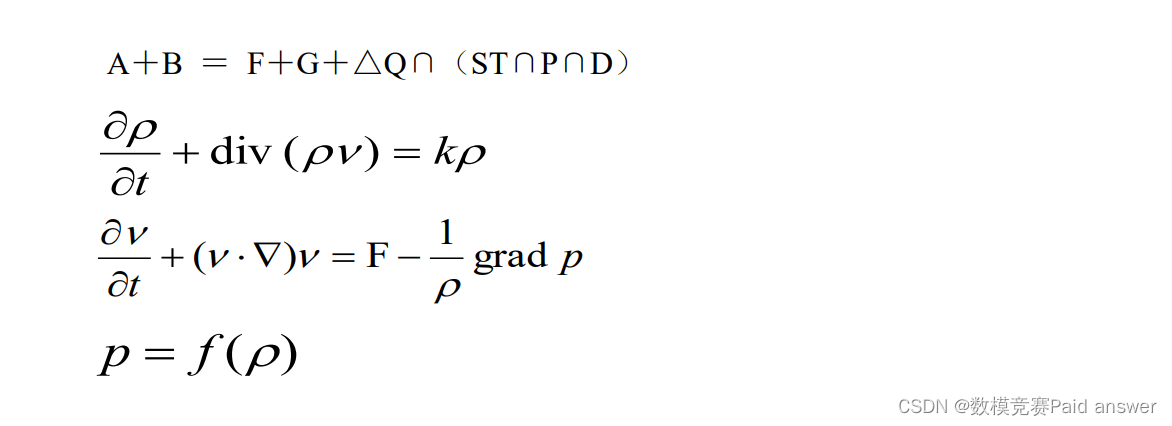
从机理上求解上述混合动力学方程组的最优解是尚未解决的数学难题。因此,通过大数据的数据挖掘技术对其进行过程优化是一条可行的求解途径。
炼铁过程依时间顺序采集的工艺参数是一个高维的大数据时间序列。影响因素数以百计。其终极生产指标产量、能耗、铁水质量等指标都与冶炼过程的一项控制性中间指标——炉温,即铁水含硅量[Si](铁水含硅质量百分数)密切相关。对 2 小时后或 4 小时后高炉炉温上升或下降的预测,即[Si]时间序列的预测关系着当前高炉各项操作参数的调控方向。因此,[Si]的准确预测控制建模成为冶炼过程优化与预测控制的关键技术。
为了简化问题,本项目仅提供由铁水含硅量[Si]、含硫量[S]、喷煤量 PML和鼓风量 FL 组成的数据库作为数学建模分析和数据挖掘的基础。序号 N 既是数据序列的序号,其实也是高炉出铁时间的顺序序号。
本课题数学建模的要求是:
(1)从给定数据表中[Si]-[S]-FL-PML 依序号排列的 1000 炉生产大数据中,自主选取学习样本和算法,建立[Si]预测动态数学模型,包括一步预测模型和二步预测模型。全面论述你的数学建模思路。
(2)自主选取验证样本,验证你所建立的数学模型的预测成功率。包括数值预测成功率和炉温升降方向预测成功率。并且讨论其动态预测控制的可行性。
(3)以质量指标铁水含硫量[S]为例,含硫量低,铁水质量好,可以生产优质钢,制造优质装备。试建立质量指标[S]的优化数学模型,并且讨论按照优化模型计算结果进行[Si]预测控制的预期效果。
(4)讨论你所建立的复杂流程工业智能控制大数据建模的心得体会。

整体求解过程概述(摘要)
在我国制造业升级“中国制造 2025”的国家战略下,为了预测控制高炉炼铁过程,本文建立了神经网络预测模型、混沌时间序列预测模型,并基于遗传算法(GA)改进了神经网络模型,使用粒子群算法(PSO)优化了含硫量[S]。
针对问题一,首先,本文对附件所给数据进行了数据预处理,剔除了异常值并归一化,得到 932 组有效数据。然后,建立 BP 神经网络预测模型预测了含硅量[Si],并分析了含硅量[Si]、含硫量[S]、鼓风量 FL 和喷煤量 PML 之间的相关性。其次,建立了小波神经网络预测模型和遗传算法(GA)优化的 BP 神经网络预测模型,并比较了三者优劣。接着,选取训练样本数据 922 组,验证样本数据 10 组,发现遗传算法优化的 BP 神经网络预测模型和小波神经网络预测模型预测效果较好,BP 神经网络预测模型较差。最后,本文建立了混沌时间序列预测模型,并对含硅量[Si]进行了混沌局部线性一步预测和二步预测。
针对问题二,首先,本文选取了 922 组数据作为训练样本,10 组数据作为验证样本,将传统的 BP 神经网络预测模型、小波神经网络模型预测模型、基于遗传算法优化 BP 神经网络预测模型和混沌时间序列预测模型,分别预测后 10炉次含硅量[Si]的结果与实际值进行对比,计算得到:BP 预测成功率为 20%,小波预测为 70%,GA+BP 预测为 60%,混沌预测为 80%。其次,通过不同的模型分别预测了后 10 炉次含硅量[Si]的结果,预测了炉温升降方向,计算得到:BP预测成功率为 40%,小波预测为 100%,GA+BP 预测为 100%,混沌预测为 100%。最后,通过讨论神经网络训练函数的选取、神经网络性能参数的设定与混沌时间
序列预测邻域半径的选取,分析了动态预测控制的可行性。
针对问题三,首先,本文根据遗传算法(GA)优化 BP 神经网络的预测模型,预测了含硫量[S],并找出了含硫量[S]与含硅量[Si]、鼓风量 FL 和喷煤量 PML之间的关系。然后,本文使用粒子群算法(PSO)优化了含硫量[S],得出当鼓风量归一化后 FL=0.7012 和喷煤量 PML=0.0809 时,含硫量[S]有最小值。最后,本文分析了在含硫量[S]最优条件下,预测控制含硅量[Si]的预期效果,在含硫量[S]取最小值时,预测到此时含硅量[Si]较小,为 0.5712。
针对问题四,我们结合建模背景、求解模型所得结果与分析结果所得结论,根据复杂流程工业智能控制的意义,浅谈了建模的心得体会。通过大数据挖掘,我们可以确定生产过程的最佳途径与最佳参数范围,获得最佳生产效果。
模型假设:
(1)假设在混沌局部线性预测中,邻域ε的选取客观准确,主观性较小。
(2)假设在混沌局部线性预测中,局部特性可以准确代表整体特性。
(3)假设在神经网络预测中,输入变量作为网络的第一层合理有效。
(4)假设附件中提供的数据及所使用的数据都真实准确。
(5)假设铁水含硅量[Si]、含硫量[S]、喷煤量 PML 和鼓风量 FL 组成的数据能代表高炉炼铁过程,体现高炉炼铁特性。
问题分析:
问题一的分析:在问题一中,题目要求我们从给定数据表中[Si]-[S]-FL-PML依序号排列的 1000 炉生产大数据中,自主选取学习样本和算法,建立[Si]预测动态数学模型,包括一步预测模型和二步预测模型。其中的一步预测模型和二步预测模型指的是预测步长分别取 1 和 2,前后两炉铁水含硅量,即炉温之间是具有相关性的。这里的学习样本不能是全部的 1000 炉生产大数据,因为问题二中需要我们验证所建立的数学模型的预测成功率,所以不能选择全部数据来训练,只能选择一部分数据来学习训练。至于建模的算法,需要结合问题本身来选择。
问题二的分析:在问题二中,题目要求我们自主选取验证样本,验证我们所建立的数学模型的预测成功率,包括数值预测成功率和炉温升降方向预测成功率。并且讨论其动态预测控制的可行性。我们需要从 1000 炉生产大数据中剩下未学习训练的数据中,选取验证样本,验证包括[Si]含量和炉温升降方向的成功率。难点在于讨论其动态预测控制的可行性,以及如何提高算法的预测成功率。
问题三的分析:在问题三中,题目要求我们以质量指标铁水含硫量[S]为例,含硫量低,铁水质量好,可以生产优质钢,制造优质装备。试建立质量指标[S]的优化数学模型,并且讨论按照优化模型计算结果进行[Si]预测控制的预期效果。通过大数据挖掘,确定生产过程的最佳途径与最佳参数控制范围,预测性地动态调整生产过程控制,获得最佳生产效果,建立优化模型,讨论对[Si]的预测控制。
问题四的分析:在问题四中,题目要求我们讨论我们所建立的复杂流程工业智能控制大数据建模的心得体会,这需要结合我们模型的结果和背景来讨论。
模型的建立与求解整体论文缩略图



全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
The actual procedure is shown in the screenshot
1 def BP(sampleinnorm, sampleoutnorm,hiddenunitnum=3): 2 # 超参数3 maxepochs = 60000 # 最大迭代次数4 learnrate = 0.030 # 学习率5 errorfinal = 0.65*10**(-3) # 最终迭代误差6 indim = 3 # 输入特征维度37 outdim = 2 # 输出特征唯独28 # 隐藏层默认为3个节点,1层9 n,m = shape(sampleinnorm)
10 w1 = 0.5*np.random.rand(hiddenunitnum,indim)-0.1 #8*3维
11 b1 = 0.5*np.random.rand(hiddenunitnum,1)-0.1 #8*1维
12 w2 = 0.5*np.random.rand(outdim,hiddenunitnum)-0.1 #2*8维
13 b2 = 0.5*np.random.rand(outdim,1)-0.1 #2*1维
14
15 errhistory = []
16
17 for i in range(maxepochs):
18 # 激活隐藏输出层
19 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose()
20 # 计算输出层输出
21 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose()
22 # 计算误差
23 err = sampleoutnorm - networkout
24 # 计算代价函数(cost function)sum对数组里面的所有数据求和,变为一个实数
25 sse = sum(sum(err**2))/m
26 errhistory.append(sse)
27 if sse < errorfinal: #迭代误差
28 break
29 # 计算delta
30 delta2 = err
31 delta1 = np.dot(w2.transpose(),delta2)*hiddenout*(1-hiddenout)
32 # 计算偏置
33 dw2 = np.dot(delta2,hiddenout.transpose())
34 db2 = 1 / 20 * np.sum(delta2, axis=1, keepdims=True)
35
36 dw1 = np.dot(delta1,sampleinnorm.transpose())
37 db1 = 1/20*np.sum(delta1,axis=1,keepdims=True)
38
39 # 更新权值
40 w2 += learnrate*dw2
41 b2 += learnrate*db2
42 w1 += learnrate*dw1
43 b1 += learnrate*db1
44
45 return errhistory,b1,b2,w1,w2,maxepochs
import numpy as np
#定义激活函数
def sigmoid(x,deriv=False):if deriv == True:return x*(1-x)return 1/(1+np.exp(-x))
x = np.array([[0,0,0],[0,1,1],[1,0,1],[0,0,1],[0,0,1]])
print(x.shape)
#指定label值
y = np.array([[0],[1],[1],[0],[0]])
print(y.shape)
#指定随机化种子,使得每次随机值一样
np.random.seed(1)
#定义三层的神经网络
w0 = 2*np.random.random((3,4)) - 1
w1 = 2*np.random.random((4,1)) - 1
print(w0)
print(w1)
for j in range(6000):l0 = xl1 = sigmoid(np.dot(l0,w0))l2 = sigmoid(np.dot(l1,w1))#真实值-预测值l2_error = y - l2if j%1000 == 0 :print("error"+str(np.mean(np.abs(l2_error))))l2_delta = l2_error*sigmoid(l2,deriv=True)l1_error = l2_delta.dot(w1.T)l1_delta = l1_error*sigmoid(l1,deriv=True)#更新w0 w1w1 += l1.T.dot(l2_delta)w0 += l0.T.dot(l1_delta)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2017年MathorCup数学建模A题流程工业的智能制造解题全过程文档及程序
2017年第七届MathorCup高校数学建模挑战赛 A题 流程工业的智能制造 原题再现: “中国制造 2025”是我国制造业升级的国家大战略。其技术核心是智能制造,智能化程度相当于“德国工业 4.0”水平。“中国制造 2025”的重点领域既包含重大装备的制造业&…...

HNU-电子测试平台与工具2-数模转换
数模转换实验 计科XXXX wolf 工程文件我也一并上传了 D级任务 一.实验任务 对74194进行仿真验证,掌握Quartus仿真的基本原则和常规步骤,记录移位寄存器的数据读写,并描述仿真波形,分析结果。 二.实验过程 1.电路连接 2.功能…...

CentOS7安装Telnet客户端和服务端和使用方式
在执行telnet时会提示命令不存在。Telnet服务的配置步骤如下:一、检测是否安装telnet软件包(通常要两个)1、telnet-client (或 telnet),这个软件包提供的是 telnet 客户端程序;2、telnet-server 软件包,这个才是真正的…...

脂肪毒性的新兴调节剂——肠道微生物组
谷禾健康 肠道微生物组与脂质代谢:超越关联 脂质在细胞信号转导中起着至关重要的作用,有助于细胞膜的结构完整性,并调节能量代谢。 肠道微生物组通过从头生物合成和对宿主和膳食底物的修饰产生了大量的小分子。 最近的研究表明,由…...

【JavaSE系列】 第九节 —— 多态那些事儿
文章目录 前言 一、多态的概念 二、向上转型和向下转型 2.1 向上转型 2.2 什么是向上转型 2.3 三种常见的向上转型 2.3.1 直接赋值 2.3.2 作为方法的参数 2.3.3 作为方法的返回值 2.4 向下转型(这个了解即可) 三、方法重写 3.1 方法重写的…...

ego微商小程序项目-测试步骤
文章目录 1. 需求分析和评审2. 编写测试计划和测试方案2.1 ego小程序测试计划2.1.1 项目简介2.1.2 项目任务2.1.3 项目风险2.1.4 测试方案2.1.5 测试实施2.1.6 测试管理2.1.7 附录资料3. 编写测试用例和评审3.1 功能测试用例设计3.1.1 总-整体把控3.1.2 分- 拆分细化3.2 测试用…...

华为OD机试用Python实现 -【报数游戏】2023Q1 A卷
华为OD机试题 本篇题目:报数游戏题目输入输出示例 1输入输出示例 2输入输出Code代码编写思路最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解...
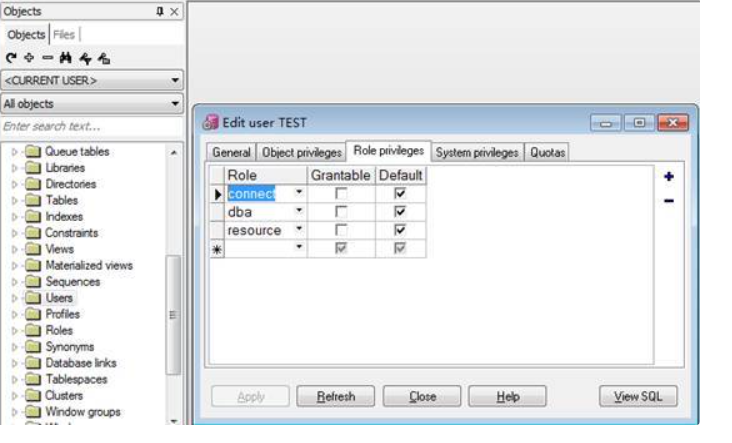
Plsql使用
登录登录system用户,初始有两个用户sys和system,密码是自己安装oracle数据库时写的,数据库选择orcl创建用户点击user,右键新增填写权限关于3个基本去权限介绍: connect : 基本操作表的权限,比如增删改查、视图创建等 r…...

小丑改造计划之四线程控制
1.线程有哪些优点,缺点? 1.优点: 创建线程的代价比较小 线程切换比进程的切换,操作系统要做的事少 线程比进程占用的资源要少 缺点: 子线程可能会影响主线程,健壮性不如进程 编写多线程比单线程难ÿ…...

Spring注册Bean的几种方式
通过XML配置注册Bean spring-config.xml <!--方式一:声明自定义的bean,没有设置id,id默认为全类型#编号--><bean id"cat" class"com.rzg.entity.Cat"/><bean class"com.rzg.entity.Cat"/>public class SpringApp…...

Egg:使用joi进行参数校验以及注册接口小demo
目录 前言: 准备工作: 前端代码: 后端目录截图: 1.获取参数 2.校验参数 3.查询数据库中是否已经存在该用户 4.用户入库 5.测试一哈 添加用户成功 同样的用户名再注册一遍 编辑总结: 前言: 在阅…...
)
天梯赛训练L1-016(查验身份证)
目录 1、L1-016 查验身份证 2、如果帮助到大家了,希望大家一键三连!!! 1、L1-016 查验身份证 分数 15 题目通道 一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下: 首…...

技术方案评审
目录 参考一、流程&规范二、评审维度组件选型性能可伸缩性灵活性可扩展性可靠性安全性兼容性弹性处理事务性可测试性可运维性监控三、方案模板背景目标整体架构业务流程接口定义数据库表功能实现测试计划人力排期Check List整体评估<...

Python机器学习库scikit-learn在Anaconda中的配置
本文介绍在Anaconda环境中,安装Python语言scikit-learn模块的方法。 scikit-learn库(简称sklearn)是一个基于Python语言的机器学习库,提供了各种机器学习算法和相关工具,包括分类、回归、聚类、降维、模型选择和预处理…...

yarn init 没有 ts 类型声明
yarn 版本为 3. 的初始化项目里,我们下载的包会发现没有 ts 类型提示。那么跟着我做这几个命令,就可以轻松搞定,具体原因我就不贴了,如果有兴趣可以评论问这里只写 vscode 没有提示的修复方式yarn add typescript -Dyarn dlx yarn…...

孩子喜欢打人父母要怎么引导?听听专家的小建议
随着人们生活水平的提高。有些孩子被父母宠坏了,不仅脾气暴躁,还喜欢打人。面对这种情况,许多家长会选择暴制暴,导致孩子更崇尚暴力。被打后,孩子不仅没有悔改,而且变得更糟。即使孩子被说服了,…...

Hive中order by,sort by,distribute by,Cluster by
order by 对数据进行全局排序, 只有一个reducer Task, 效率低 mysql中strict模式下, order by必须要有limit, 不然会拒绝执行. 对于分区表, 必须显示指定分区字段查询。 sort by 可以有多个reduce Task(以distribute by后的字段个数为准) 每个reduce Task内部数据有序, 但…...

PyTorch的自动微分(autograd)
PyTorch的自动微分(autograd) 计算图 计算图是用来描述运算的有向无环图 计算图有两个主要元素:结点(Node)和边(Edge) 结点表示数据,如向量、矩阵、张量 边表示运算,如加减乘除卷积等 用计算…...

sum-check protocol
sumcheck是一个交互式证明协议,给定域F上的多元多项式g(x1,...,xv)g(x_1,...,x_v)g(x1,...,xv),证明者Prover可以向验证者Verifier证明该多项式ggg的遍历求和值等于公开值HHH,即 H∑b1,b2,...,bv∈{0,1}vg(b1,b2,...,bv)H \sum_{b_1,b_2,…...
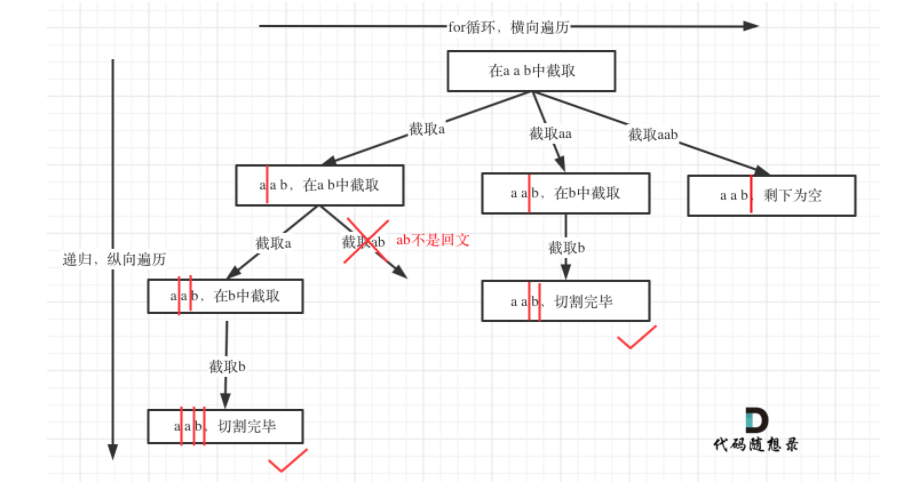
数据结构刷题(二十一):131分割回文串、78子集
1.分割回文串题目链接思路:回溯算法的组合方法(分割问题类似组合问题)。流程图:红色竖杠就是startIndex。 for循环是横向走,递归是纵向走。回溯三部曲:递归函数参数:字符串s和startIndex&#…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...

Python爬虫实战:研究Restkit库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的有价值数据。如何高效地采集这些数据并将其应用于实际业务中,成为了许多企业和开发者关注的焦点。网络爬虫技术作为一种自动化的数据采集工具,可以帮助我们从网页中提取所需的信息。而 RESTful API …...

mcts蒙特卡洛模拟树思想
您这个观察非常敏锐,而且在很大程度上是正确的!您已经洞察到了MCTS算法在不同阶段的两种不同行为模式。我们来把这个关系理得更清楚一些,您的理解其实离真相只有一步之遥。 您说的“select是在二次选择的时候起作用”,这个观察非…...

Q1起重机指挥理论备考要点分析
Q1起重机指挥理论备考要点分析 一、考试重点内容概述 Q1起重机指挥理论考试主要包含三大核心模块:安全技术知识(占40%)、指挥信号规范(占30%)和法规标准(占30%)。考试采用百分制,8…...

Spring Boot SQL数据库功能详解
Spring Boot自动配置与数据源管理 数据源自动配置机制 当在Spring Boot项目中添加数据库驱动依赖(如org.postgresql:postgresql)后,应用启动时自动配置系统会尝试创建DataSource实现。开发者只需提供基础连接信息: 数据库URL格…...