PyTorch的自动微分(autograd)
PyTorch的自动微分(autograd)
计算图
计算图是用来描述运算的有向无环图
计算图有两个主要元素:结点(Node)和边(Edge)
结点表示数据,如向量、矩阵、张量
边表示运算,如加减乘除卷积等
用计算图表示:y = (x + w) * (w + 1)
令 a = x + w,b = w + 1
则 y = a * b

使用计算图可以更方便的求导

在计算图中,y对w求导,就是找到所有y到w的边,然后分别进行求导。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
tensor([5.])叶子节点:用户创建的结点成为叶子结点,如X与W
is_leaf:指示张量是否为叶子结点
叶子结点的作用:节省内存,非叶子结点的梯度会被释放
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
is_leaf:
True True False False Falseprint("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
gradient:tensor([5.]) tensor([2.]) None None None
如果想要保存非叶子结点的梯度,需要在反向传播前前,使用a.retain_grad()(以张量a为例)
grad_fn:记录创建该张量时所用的方法(函数)
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
grad_fn:None None <AddBackward0 object at 0x00000254C1C6C7B8> <AddBackward0 object at 0x00000254C334DDD8> <MulBackward0 object at 0x00000254C334D828>
这里w和x是用户创建的,所以grad_fn为None,a、b、y都是有grad_fn的,其grad_fn的作用主要是在求导时,可以知道其是使用哪种计算方式得到的,以便确认求导法则。
动态图 VS 静态图
根据计算图搭建方式,可将计算图分为动态图和静态图
动态图:运算和搭建同时进行,特点:灵活,易调解,以pytorch为代表
静态图:先搭建图,后运算,特点:高效,但不灵活,以tensorflow为代表
autograd–自动求导系统
torch.autograd.backward方法介绍
torch.autograd.backward:自动求取梯度,参数
- inputs:用于求导的张量,如loss
- retain_graph:保存计算图
- create_graph:创建导数计算图,用于高阶求导
- gradient:多梯度权重
tensor.backward()调用的就是torch.autograd.backward()
在梯度求导之后,计算图会被释放,无法执行两次backward(),要想执行两次backward(),就需要将retain_graph设置为True。
一般中间结点会遇到需要多次backward的情况
下面代码解释多梯度权重
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a ,b)
y1 = torch.add(a, b) # dy1/dw = 2
loss = torch.cat([y, y1], dim=0)grad_tensors = torch.tensor([1, 1])
loss.backward(gradient=grad_tensors)
print(w.grad)
tensor([7.])
这里同时求了dy/dw和dy1/dw,w.grad=(1 x dy/dw) + (1 x dy1/dw) = 5+2
grad_tensors = torch.tensor([1, 2])
loss.backward(gradient=grad_tensors)
print(w.grad)
tensor([7.])
w.grad = (1 x dy/dw) + (2 x dy1/dw) = 5 + 2x2 = 9
torch.autograd.grad()方法介绍
torch.autograd.grad():求取梯度
- outputs:用于求导的张量,如loss
- inputs:需要梯度的张量
- create_graph:创建导数计算图,用于高阶求导
- retain_graph:保存计算图
- grad_outputs:多梯度权重
# x需要设置requires_grad=True才可以后续求导
x = torch.tensor([3.], requires_grad=True)
y = torch.pow(x, 2)
# 创建导数计算图,用于高阶求导,即后续可以求二阶导数
grad_1 = torch.autograd.grad(y, x, create_graph=True)
print(grad_1)
(tensor([6.], grad_fn=<MulBackward0>),)
# 求2阶导数
grad_2 = torch.autograd.grad(grad_1[0], x)
print(grad_2)
(tensor([2.]),)
autograd小贴士:
- 梯度不会自动清零(比如w会一直叠加),手动清零:
w.grad.zero_(); - 依赖于叶子结点的结点(比如a, b, y),其requires_grad=True;
- 叶子结点不可以执行in-place操作(原地操作,在原始内存地址中改变数据)。
自动求导系统实现
torch.Tensor 是包的核心类。如果将其属性 .requires_grad 设置为 True,则会开始跟踪针对 tensor 的所有操作。完成计算后,您可以调用 .backward() 来自动计算所有梯度。该张量的梯度将累积到 .grad 属性中。
如果你想计算导数,你可以调用 Tensor.backward()。如果 Tensor 是标量(即它包含一个元素数据),则不需要指定任何参数backward(),但是如果它有更多元素,则需要指定一个gradient 参数 来指定张量的形状。
这两段话非常重要,我们借助下面这个例子来帮助理解
import torchx = torch.ones(2, 2, requires_grad=True)
print(x)tensor([[1., 1.],[1., 1.]], requires_grad=True)y = x + 2
print(y)tensor([[3., 3.],[3., 3.]], grad_fn=<AddBackward0>)print(x.grad_fn) # None
print(y.grad_fn) # y 作为操作的结果被创建,所以它有 grad_fn None
<AddBackward0 object at 0x000001F7739B1BB0>
每个张量都有一个 .grad_fn属性保存着创建了张量的 Function 的引用,(如果用户自己创建张量,则grad_fn 是 None )。
针对y做更多的操作
z = y*y*3
out = z.mean()
print(z)
print(out)
print(out.backward()) # 这里是没有返回值的
print(x.grad) # 需要先backward,才能得到x的gradtensor([[27., 27.],[27., 27.]], grad_fn=<MulBackward0>)
tensor(27., grad_fn=<MeanBackward0>)
None
tensor([[4.5000, 4.5000],[4.5000, 4.5000]])
这里的重点是x.grad的计算

通过这个例子,理解上面的两段话就是,这里x的requires_grad 属性为True,后续跟踪针对x的所有操作,之后调用backward自动计算所有梯度,x的梯度累积到.grad属性中。
接下来我们再看一个pytorch自动微分的例子,如果对于张量手动计算梯度的话,代码是这样的:
import torchdtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # 取消注释以在GPU上运行# N是批量大小,D_in是输入维度,H是隐藏层维度,D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10# 创建随机输入和输出数据
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)# 随机初始化权重
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)learning_rate = 1e-6
for t in range(500):# 前向传递:计算预测yh = x.mm(w1) # mm表示tensor相乘# 将输入input张量的每个元素夹紧到区间[min, max]h_relu = h.clamp(min=0)y_pred = h_relu.mm(w2)# 计算和打印损失loss = (y_pred - y).pow(2).sum().item() # 求平方和print(t, loss)# Backprop计算w1和w2相对于损耗的梯度grad_y_pred = 2.0 * (y_pred - y)grad_w2 = h_relu.t().mm(grad_y_pred)grad_h_relu = grad_y_pred.mm(w2.t())grad_h = grad_h_relu.clone()grad_h[h < 0] = 0grad_w1 = x.t().mm(grad_h)# 使用梯度下降更新权重w1 -= learning_rate * grad_w1w2 -= learning_rate * grad_w2这段代码最核心的点在于Backprop部分,首先根据
loss=(y_pred-y)^2
容易到loss对于y_pred的偏导数,即grad_y_pred
而loss对于w2的偏导数,即grad_w2就稍复杂一些,涉及到矩阵求导、雅可比矩阵和链式法则。
根据在网上查阅资料得到,查到一个矩阵求导相关的文章:
https://blog.sina.com.cn/s/blog_51c4baac0100xuww.html
说实话没怎么看懂,以前没有学过矩阵求导。
关于雅可比矩阵和链式法则:

上面的内容简而言之,雅可比矩阵是一阶偏导数以一定方式排列成的矩阵,根据求导的链式法则,(y对x的偏导)x(l对y的偏导) = (l对x的偏导)。
现在可以想到
grad_w2 = y_pred对w2的偏导 x loss对y_pred的偏导y_pred对w2的偏导 = h_relu的转置即 grad_w2 = h_relu.t().mm(grad_y_pred)
这里两个矩阵的前后顺序我不知道有没有什么规则,但是根据其size可以pytorch官方文档给出前后顺序是合理的
h_relue.t()的size是(100, 64)
grad_y_pred的size是(64, 10)grad_h_relu = loss对y_pred的偏导 x y_pred对h_relu的偏导
y_pred对h_relue的偏导 = w2的转置
即grad_h_relue = grad_y_pred.mm(w2.t())
而且你看,这里相乘的两个矩阵顺序调整了,调整的原因是因为
grad_y_pred的size是(64, 10)
w2.t()的size是(10, 100)
只有按照给出的位置才能得到相乘,而且正好得到(64, 100)的grad_h_relu同理对于loss对于w1的偏导
grad_w1 = h_relu对于w1的偏导 x y_pred对h_relu的偏导 x loss对y_pred的偏导
后两项的乘积就是grad_h_relu
h_relue对w1的偏导 = x.t()
而x.t()的size为(1000, 64)
所以grad_w1 = x.t().mm(grad_h)现在我们已经理解了上述求导和反向传播的过程,如果使用pytorch的自动求导,则可以利用下述方式来实现。
import torchdtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # 取消注释以在GPU上运行# N是批量大小,D_in是输入维度,H是隐藏层维度,D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10# 创建随机输入和输出数据
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)# 随机初始化权重
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)learning_rate = 1e-6
for t in range(500):# 前向传播:使用tensors上的操作计算预测值y;# 由于w1和w2有requires_grad=True,涉及这些张量的操作将让PyTorch构建计算图,# 从而允许自动计算梯度。由于我们不再手工实现反向传播,所以不需要保留中间值的引用。y_pred = x.mm(w1).clamp(min=0).mm(w2)# 使用Tensors上的操作计算和打印丢失。# loss是一个形状为(1,)的张量# loss.item() 得到这个张量对应的python数值loss = (y_pred - y).pow(2).sum()print(t, loss.item())# 使用autograd计算反向传播。这个调用将计算loss对所有requires_grad=True的tensor的梯度。# 这次调用后,w1.grad和w2.grad将分别是loss对w1和w2的梯度张量。loss.backward()# 使用梯度下降更新权重。对于这一步,我们只想对w1和w2的值进行原地改变;不想为更新阶段构建计算图,# 所以我们使用torch.no_grad()上下文管理器防止PyTorch为更新构建计算图with torch.no_grad():w1 -= learning_rate * w1.gradw2 -= learning_rate * w2.grad# 反向传播后手动将梯度设置为零w1.grad.zero_()w2.grad.zero_()相关文章:
PyTorch的自动微分(autograd)
PyTorch的自动微分(autograd) 计算图 计算图是用来描述运算的有向无环图 计算图有两个主要元素:结点(Node)和边(Edge) 结点表示数据,如向量、矩阵、张量 边表示运算,如加减乘除卷积等 用计算…...

sum-check protocol
sumcheck是一个交互式证明协议,给定域F上的多元多项式g(x1,...,xv)g(x_1,...,x_v)g(x1,...,xv),证明者Prover可以向验证者Verifier证明该多项式ggg的遍历求和值等于公开值HHH,即 H∑b1,b2,...,bv∈{0,1}vg(b1,b2,...,bv)H \sum_{b_1,b_2,…...
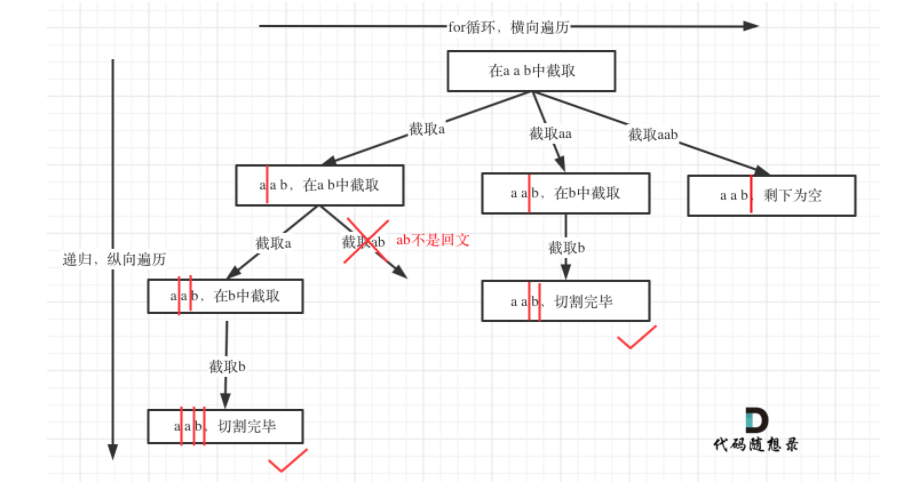
数据结构刷题(二十一):131分割回文串、78子集
1.分割回文串题目链接思路:回溯算法的组合方法(分割问题类似组合问题)。流程图:红色竖杠就是startIndex。 for循环是横向走,递归是纵向走。回溯三部曲:递归函数参数:字符串s和startIndex&#…...

Spring Aop 详解
主要内容: 了解Spring AOP的概念及其术语熟悉Spring AOP的JDK动态代理熟悉Spring AOP的CGLib动态代理掌握基于XML的AOP实现掌握基于注解的AOP实现AOP用官方话来说: AOP即面向切面编程。和OOP(面向对象编程)不同,AOP主…...

【数据库死锁】线上问题之数据库死锁
原本平静的一天,惊现生产项目瘫痪问题,马上打开日志,发现后台日志提示了多个“com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction” 大概去了解一下这个异常&#x…...

好友管理系统--课后程序(Python程序开发案例教程-黑马程序员编著-第4章-课后作业)
实例3:好友管理系统 如今的社交软件层出不穷,虽然功能千变万化,但都具有好友管理系统的基本功能,包括添加好友、删除好友、备注好友、展示好友等。下面是一个简单的好友管理系统的功能菜单,如图1所示。 图1 好友管理系…...

Redis 集群 Redis Cluster搭建
Redis集群需要至少三个master节点,我们这里搭建三个master节点192.168.20.130,192.168.20.131,192.168.20.132,并且给每个master再搭建一个slave节点(一个节点一主一从,通过端口号区分)…...
博客系统(前后端分离版)
博客系统的具体实现 文章目录博客系统的具体实现软件开发的基本流程具体实现的八大功能数据库设计创建数据库操作数据库引入依赖封装DataSource创建实体类将JDBC增删改查封装起来实现博客列表页web.xml的配置文件实现博客系统的展示功能登录功能强制要求用户登录显示用户信息退…...
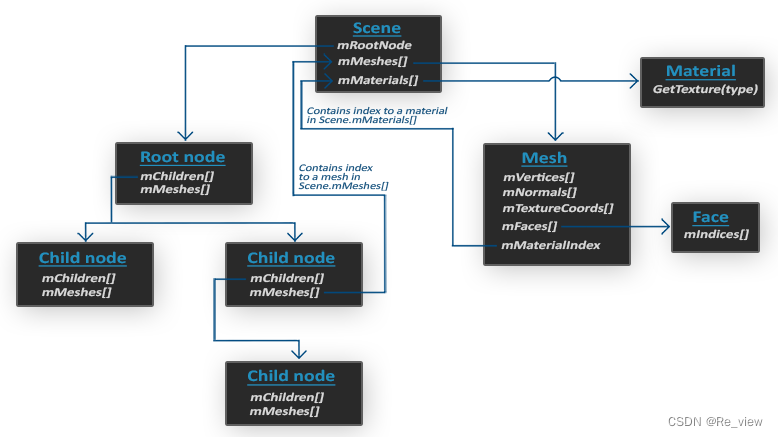
第十二章 opengl之模型加载(Assimp)
OpenGLAssimp模型加载库构建Assimp网格网格渲染Assimp 我们不太能够对像是房子、汽车或者人形角色这样的复杂形状手工定义所有的顶点、法线和纹理坐标。我们要的是将这些模型(Model)导入(Import)到程序当中。模型通常都由3D艺术家在Blender、3DS Max或者Maya这样的工具中精心制…...

Stable Matching-稳定匹配问题【G-S算法,c++】
Stable Matching-稳定匹配问题【G-S算法,c】题目描述:(Gale-Shapley算法)解题思路一:G-S算法(Gale-Shapley算法)题目描述:(Gale-Shapley算法) Teenagers from the local high school have asked you to help them with the organ…...
TypeScript(四)接口
目录 前言 定义 用法 基本用法 约定规则 属性控制 任意属性 可选属性 只读属性 定义函数 冒号定义 箭头定义 接口类型 函数接口 索引接口 继承接口 类接口 总结 前言 在介绍TS对象类型中,为了让数组每一项更具体,我们使用 string [ ]…...

Python-基础知识
目录 Python 简介 Python 发展历史 Python 特点 Python 标识符 Python 保留字符 行和缩进 多行语句 Python 引号 Python注释 Python 简介 Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可读性,相比…...
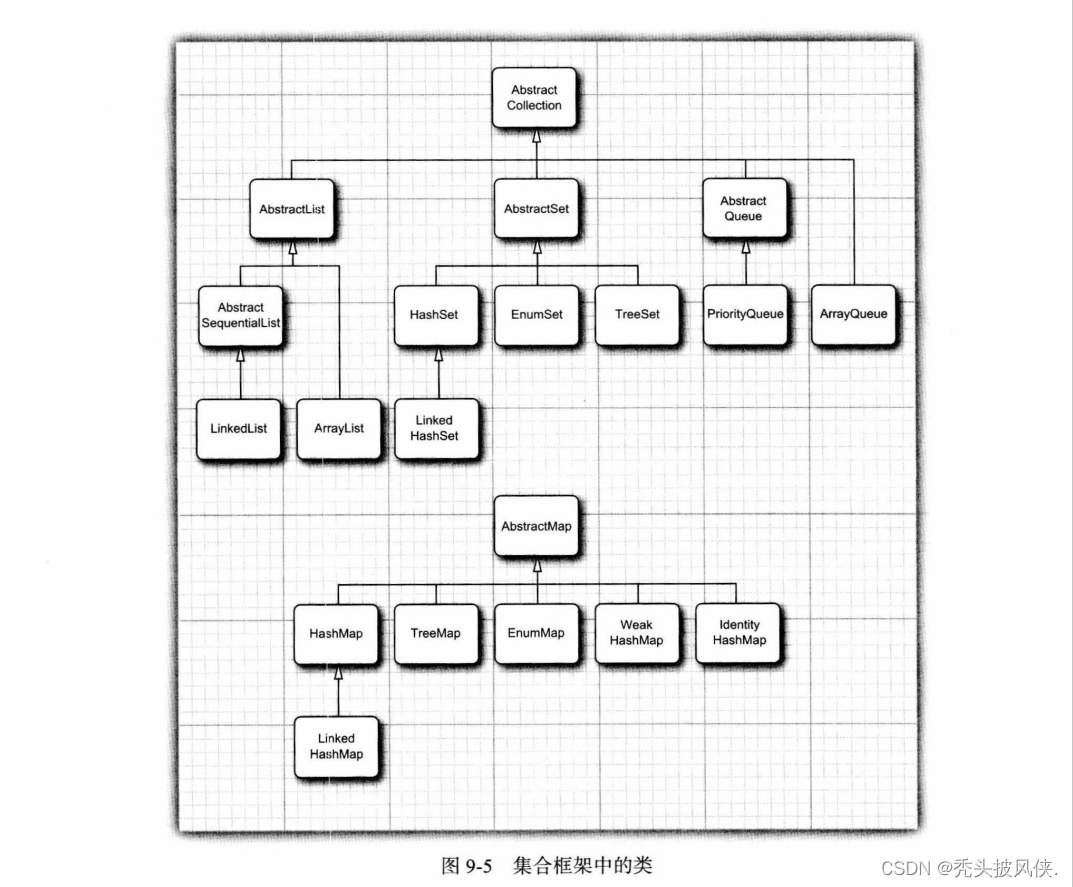
【java基础】集合基础说明
文章目录基本介绍Collection接口Iterator和Iterable接口Map接口关于Iterator接口的一些说明框架中的接口具体集合总结基本介绍 集合就是存储用来存储一系列数据的一种数据结构。在这篇文章中会介绍集合的一些基本概念。 Collection接口 集合的基本接口是Collection接口&…...
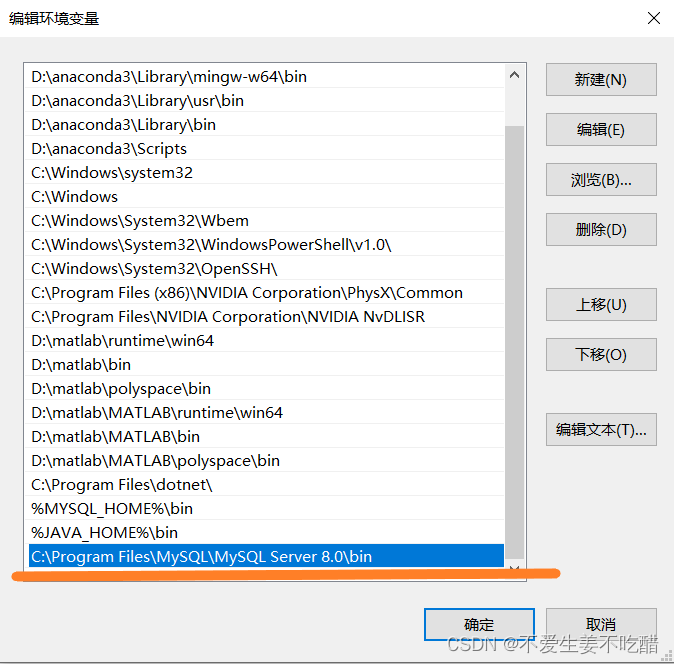
MySQL的下载及安装详细教程
提示:本文仅为MySQL初学者的安装MySQL过程提供参考,创作不易,请多点赞支持! MySQL的下载及安装前言一、MySQL的下载及安装1.MySQL的下载2.MySQL的安装3.配置环境变量4.连接MySQL4.1 方式一4.2 方式二前言 本文内容主要是帮助初学…...

SSL/TLS协议工作原理
SSL/TLS协议工作原理 SLL/TLS协议工作在应用层和传输层之间,应用层数据需要经过SSL/TLS层的加密之后才会发送到传输层。SSL/TLS协议有两个重要协议:握手协议、记录协议。 1. 握手协议 TCP三次握手完成后,才能进行SSL/TLS的握手。 因为&#…...

大数据项目实战之数据仓库:用户行为采集平台——第4章 用户行为数据采集模块
第4章 用户行为数据采集模块 4.1 数据通道 4.2 环境准备 4.2.1 集群所有进程查看脚本 1)在/home/atguigu/bin目录下创建脚本xcall [atguiguhadoop102 bin]$ vim xcall2)在脚本中编写如下内容 #! /bin/bashfor i in hadoop102 hadoop103 hadoop104 d…...
《统计学习方法》(李航)——学习笔记
第一章 概论统计学习,又称统计机器学习(机器学习),现在提到的 机器学习 往往指的就是 统计机器学习。统计学习研究的对象是数据,其对数据的基本假设是同类数据存在一定的统计规律性,因此可以用概率统计方法…...
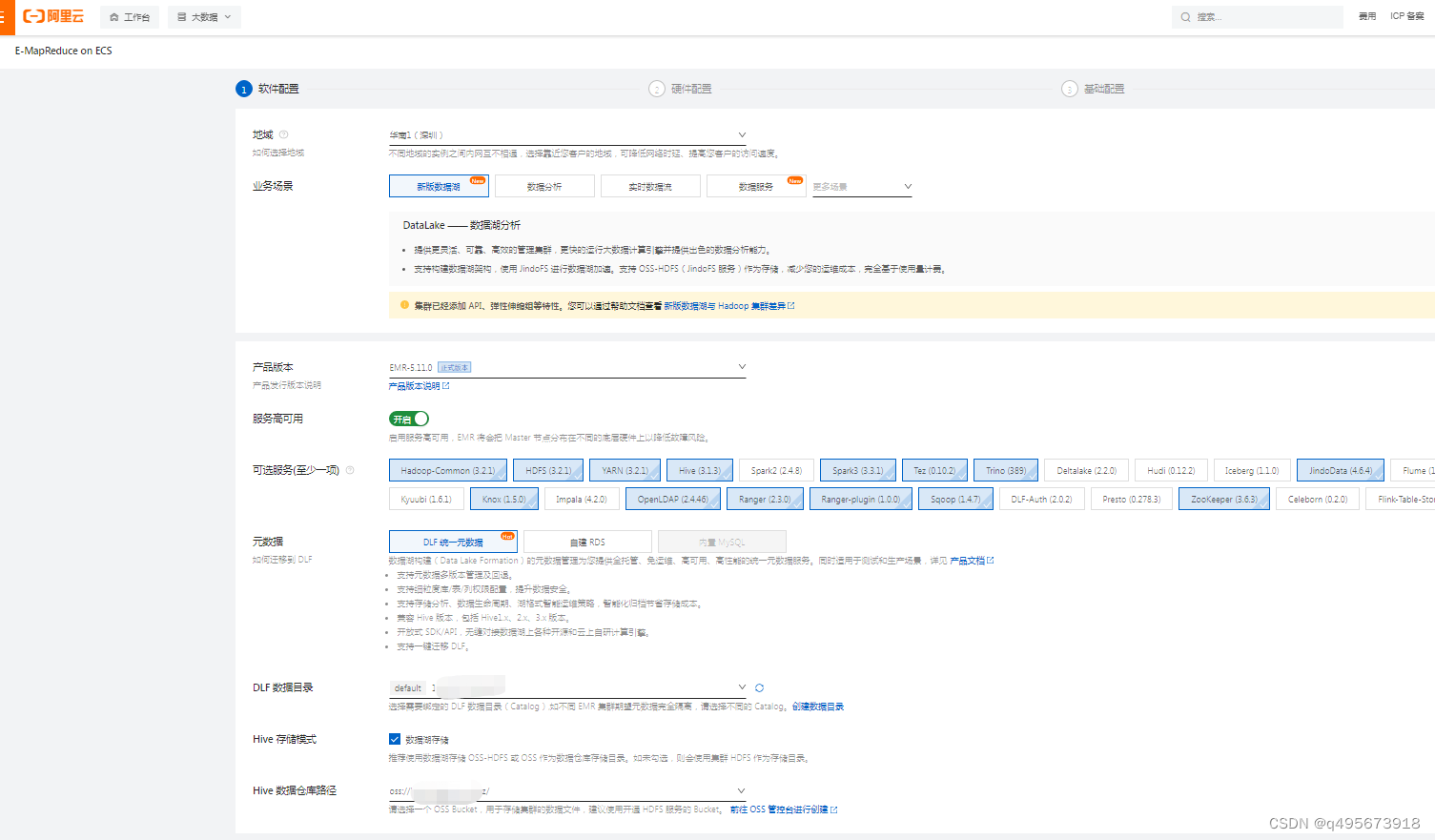
阿里云EMR集群搭建及使用
目录 1.简介 1.什么是EMR 2.组成 3.与自建hadoop集群对比 4.产品架构 2.使用 1.创建EMR集群 1.登录EMR on ECS控制台 2.软件设置 3.硬件设置 3.基础配置 2.配置 1.组件配置 2.用户管理 3.安全组 4.Gateway 3.组件UI 1.简介 1.什么是EMR EMR是运行在阿里云平台…...

学习streamlit-4
st.slider 今天学习st.slider滑块组件的使用。 st.slider滑块组件通常被用来作为应用的输入,支持整数、浮点数、日期、时间和日期时间。 下面的示例程序包含以下简单功能,以演示st.slider滑块组件: 用户通过调整滑块选择值应用打印出所选…...

高级Oracle DBA面试题及答案
作为高级 Oracle DBA,您将负责 Oracle 数据库基础架构的设计、安装、配置、监控和维护。您还将负责制定和实施备份和恢复计划,并确保数据的安全性和完整性。要成功担任此职位,您需要对 Oracle 数据库架构有深入的了解,并能够有效地…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...