乐高小人分类项目
数据来源
LEGO Minifigures | Kaggle
建立文件目录
BASE_DIR = 'lego/star-wars-images/'
names = ['YODA', 'LUKE SKYWALKER', 'R2-D2', 'MACE WINDU', 'GENERAL GRIEVOUS'
]
tf.random.set_seed(1)# Read information about dataset
if not os.path.isdir(BASE_DIR + 'train/'):for name in names:os.makedirs(BASE_DIR + 'train/' + name)os.makedirs(BASE_DIR + 'test/' + name)os.makedirs(BASE_DIR + 'val/' + name) 
划分数据集
# Total number of classes in the dataset
orig_folders = ['0001/', '0002/', '0003/', '0004/', '0005/']
for folder_idx, folder in enumerate(orig_folders):files = os.listdir(BASE_DIR + folder)number_of_images = len([name for name in files])n_train = int((number_of_images * 0.6) + 0.5)n_valid = int((number_of_images * 0.25) + 0.5)n_test = number_of_images - n_train - n_validprint(number_of_images, n_train, n_valid, n_test)for idx, file in enumerate(files):file_name = BASE_DIR + folder + fileif idx < n_train:shutil.move(file_name, BASE_DIR + 'train/' + names[folder_idx])elif idx < n_train + n_valid:shutil.move(file_name, BASE_DIR + 'val/' + names[folder_idx])else:shutil.move(file_name, BASE_DIR + 'test/' + names[folder_idx])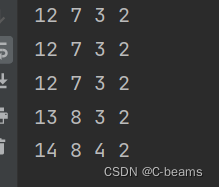
训练数据生成
train_gen = ImageDataGenerator(rescale=1./255)
val_gen = ImageDataGenerator(rescale=1./255)
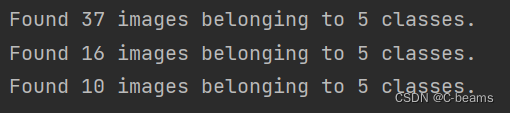
test_gen = ImageDataGenerator(rescale=1./255)train_batches = train_gen.flow_from_directory('lego/star-wars-images/train',target_size=(256, 256),class_mode='sparse',batch_size=4,shuffle=True,color_mode='rgb',classes=names,
)
查看其中一批次的样本
train_batch = train_batches[0]
test_batch = train_batches[0]
print(train_batch[0].shape)
print(train_batch[1])
print(test_batch[0].shape)
print(test_batch[1])def show(batch, pre_labels=None):plt.figure(figsize=(10, 10))for i in range(4):plt.subplot(2, 2, i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(batch[0][i], cmap=plt.cm.binary)# extra indexlbl = names[int(batch[1][i])]if pre_labels is not None:lbl += '/Pred:' + names[int(pre_labels[i])]plt.xlabel(lbl)plt.show()show(test_batch)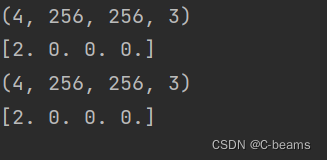

模型建立
model = keras.Sequential([layers.Conv2D(32, (3, 3), strides=(1, 1), padding='valid', activation='relu', input_shape=(256, 256, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, 3, activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(5),
])
# print(model.summary())model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer=keras.optimizers.Adam(0.001),metrics=['accuracy']
)model.fit(train_batches, validation_data=val_batches, epochs=30, verbose=2)
model.save('lego_model.h5')
绘制 loss 和 acc
# plot loss and acc
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='valid loss')
plt.grid()
plt.legend(fontsize=15)plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='train acc')
plt.plot(history.history['val_accuracy'], label='valid acc')
plt.grid()
plt.legend(fontsize=15);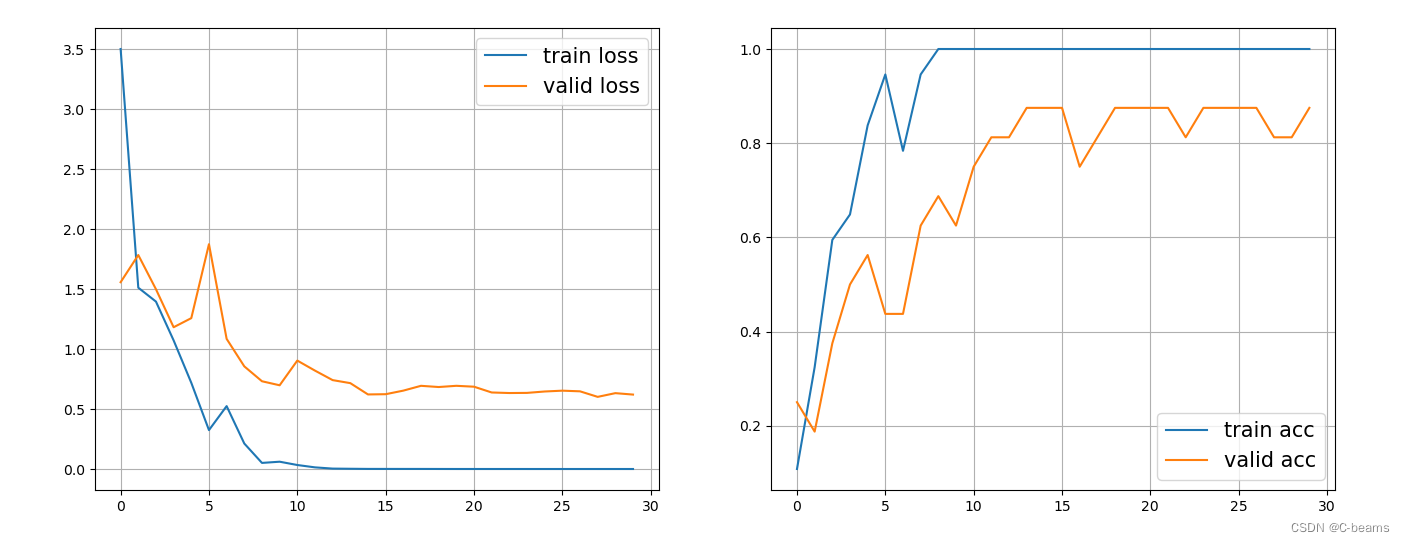
模型评估和预测
model.evaluate(test_batches, verbose=2)predictions = model.predict(test_batches)
predictions = tf.nn.softmax(predictions)
labels = np.argmax(predictions, axis=1)
print(test_batches[0][1])
print(labels[0:4])show(test_batches[0], labels[0:4])

相关文章:
乐高小人分类项目
数据来源 LEGO Minifigures | Kaggle 建立文件目录 BASE_DIR lego/star-wars-images/ names [YODA, LUKE SKYWALKER, R2-D2, MACE WINDU, GENERAL GRIEVOUS ] tf.random.set_seed(1)# Read information about dataset if not os.path.isdir(BASE_DIR train/):for name in …...

个人关于ChatGPT的用法及建议
概述 这里只是个人常用的几个软件,做一下汇总,希望对各位有用。 如果有更高认知的朋友,请留下你的工具名称,提醒我一下,谢谢~ 常用的chatgpt模型工具: 以下是一些知名的例子: 文…...

神经网络的工程基础(二)——随机梯度下降法|文末送书
相关说明 这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。 本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/stochastic_gradient_descent.ipynb 本文将讨论利用…...

常见的几种编码方式
常见的编码方式及其特点: 编码方式的设计是为了适应不同的字符集和应用需求,因此它们在表示字符时使用的位数和字节数各不相同 常见编码方式及其位数和字节数 ASCII(American Standard Code for Information Interchange)&#x…...
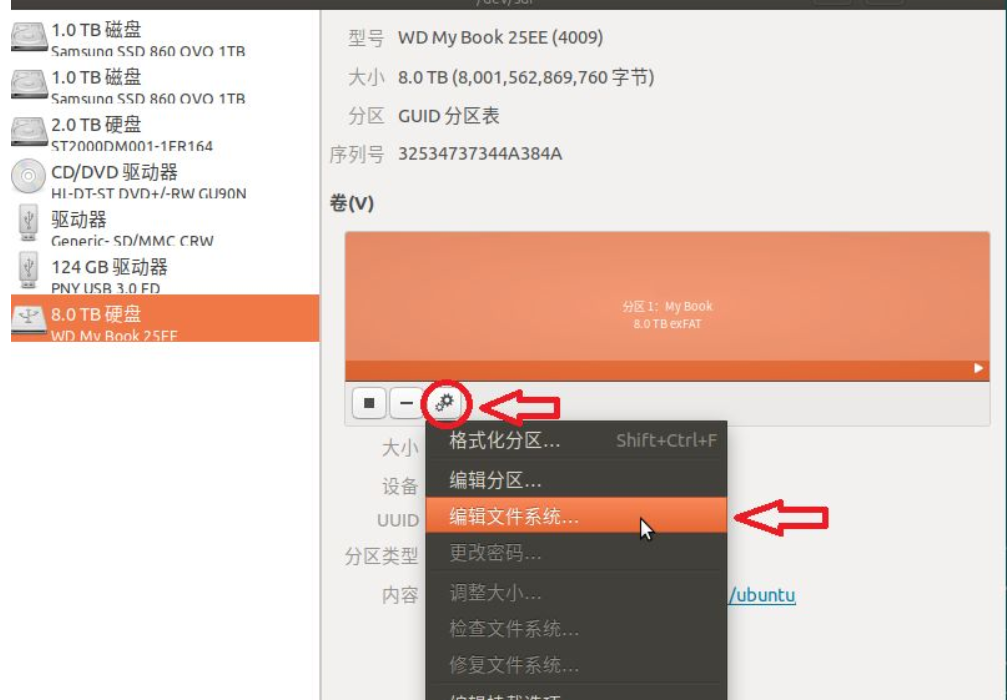
ubuntu移动硬盘重命名
因为在ubuntu上移动硬盘的名字是中文的,所以想要改成英文的。 我的方法: 将移动硬盘插到windows上,直接右键重命名。再插到ubuntu上名字就改变了。 别人的方法: ubuntu下如何修改U盘名字-腾讯云开发者社区-腾讯云 在自带的软件…...

VUE框架前置知识总结
一、前言 在学习vue框架中,总是有些知识不是很熟悉,又不想系统的学习JS,因为学习成本太大了,所以用到什么知识就学习什么知识。此文档就用于记录零散的知识点。主要是还是针对与ES6规范的JS知识点。 以下实验环境都是在windows环…...

张宇1000题80%不会?别急,这个方法肯定有用!
这太正常了,1000题的难度本来就高,不要慌 我考研的时候跟的也是张宇老师,但是1000题我根本就没做几道题就给换成880题660题了,而且只是强化阶段用880题,基础阶段我用的都是汤家凤的1800题。 不要担心做的不是张宇老师…...

【python】爬虫记录每小时金价
数据来源: https://www.cngold.org/img_date/ 因为这个网站是数据随时变动的,用requests、BeautifulSoup的方式解析html的话,数据的位置显示的是“--”,并不能取到数据。 所以采用webdriver访问网站,然后从界面上获取…...
一行命令将已克隆的本地Git仓库推送到内网服务器
一、需求背景 我们公司用gitea搭建了一个git服务器,其中支持win7的最高版本是v1.20.6。 我们公司的电脑在任何时候都不能连接外网,但是希望将一些开源的仓库移植到内网的服务器来。一是有相关代码使用的需求,二是可以建设一个内网能够查阅的…...

Linux文本处理三剑客(详解)
一、文本三剑客是什么? 1. 对于接触过Linux操作系统的人来说,应该都听过说Linux中的文本三剑客吧,即awk、grep、sed,也是必须要掌握的Linux命令之一,三者都是用来处理文本的,但侧重点各不相同,a…...
AI在线UI代码生成,不需要敲一行代码,聊聊天,上传图片,就能生成前端页面的开发神器
ioDraw的在线UI代码生成器是一款开发神器,它可以让您在无需编写一行代码的情况下创建前端页面。 主要优势: 1、极简操作:只需聊天或上传图片,即可生成响应式的Tailwind CSS代码。 2、节省时间:自动生成代码可以节省大…...

go-zero整合单机版ClickHouse并实现增删改查
go-zero整合单机版ClickHouse并实现增删改查 本教程基于go-zero微服务入门教程,项目工程结构同上一个教程。 本教程主要实现go-zero框架整合单机版ClickHouse,并暴露接口实现对ClickHouse数据的增删改查。 go-zero微服务入门教程:https://b…...
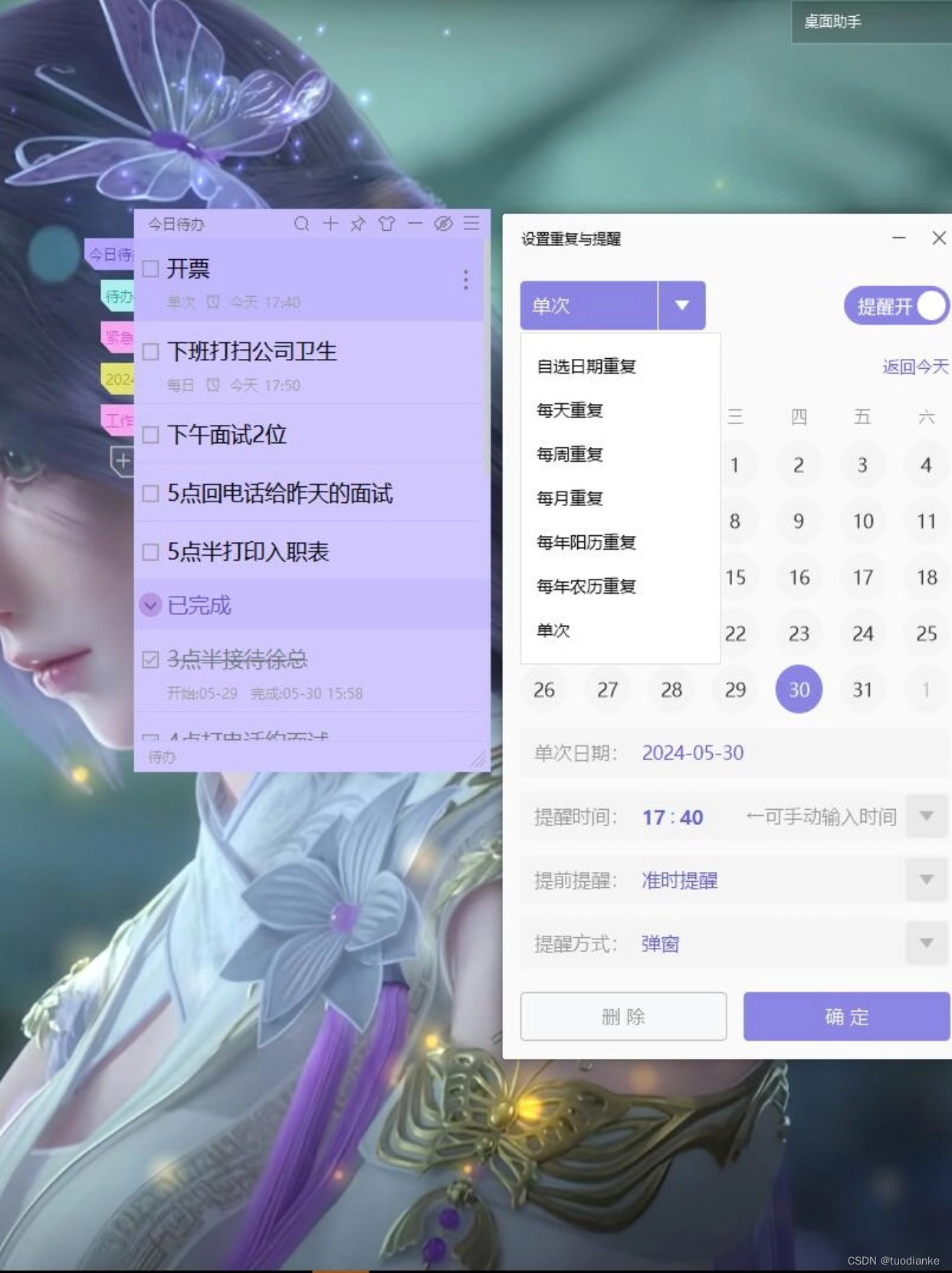
行政工作如何提高效率?桌面备忘录便签软件哪个好
在行政管理工作中,效率的提高无疑是每个行政人员都追求的目标。而随着科技的发展,各种便捷的工具也应运而生,其中桌面备忘录便签软件便是其中的佼佼者。那么,这类软件又如何帮助我们提高工作效率呢? 首先,…...

利用向日葵和微信/腾讯会议实现LabVIEW远程开发
利用向日葵远程控制软件结合微信或腾讯会议的视频通话功能,可以实现LabVIEW的远程开发和调试。通过向日葵进行远程桌面访问,配合视频通话工具进行实时沟通与问题解决,不仅提高了开发效率,还减少了地域限制带来的不便。介绍这种远程…...
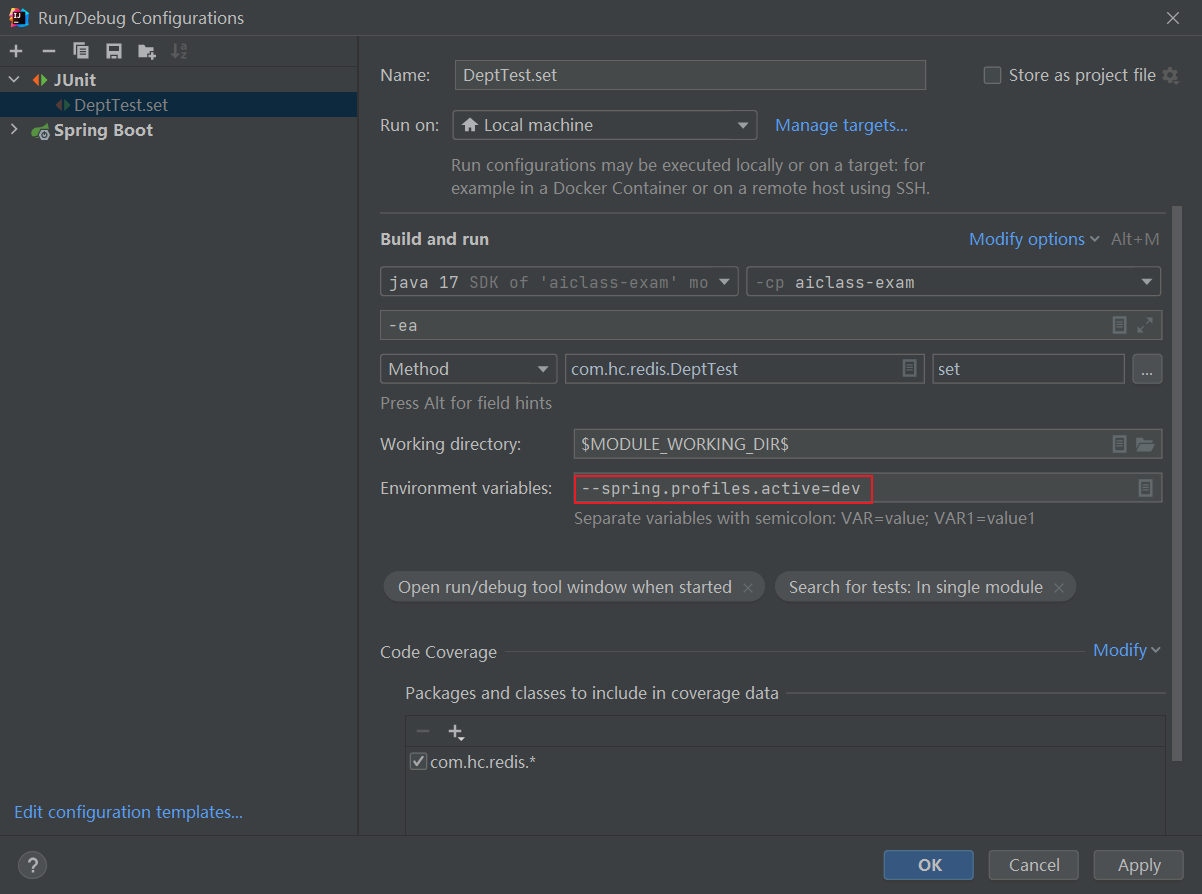
SpringBoot 单元测试 指定 环境
如上图所示,在配置窗口中添加--spring.profiles.activedev,就可以了。...

Flutter 中的 SliverOpacity 小部件:全面指南
Flutter 中的 SliverOpacity 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,由 Google 开发,允许开发者使用 Dart 语言来构建高性能、美观的跨平台应用。在 Flutter 的滚动组件体系中,SliverOpacity 是一个用来为其子 Slive…...

源码分析の前言
源码分析路线图: 初级部分:ArrayList->LinkedList->Vector->HashMap(红黑树数据结构,如何翻转,变色,手写红黑树)->ConcurrentHashMap 中级部分:Spring->Spring MVC->Spring Boot->M…...
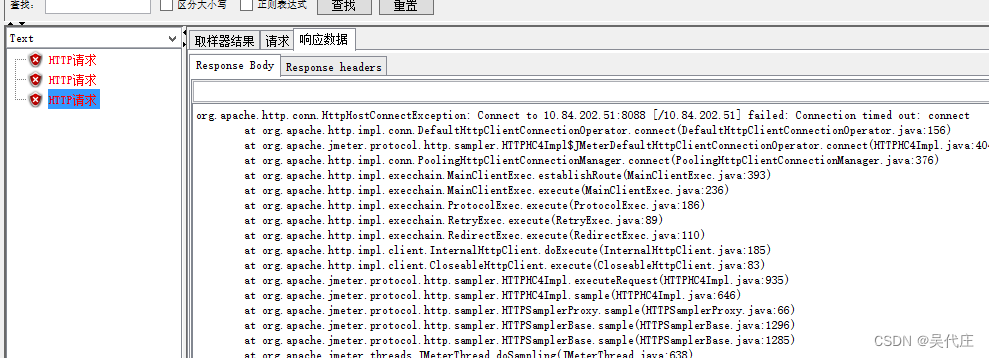
接口性能测试复盘:解决JMeter超时问题的实践
在优化接口并重新投入市场后,我们面临着一项关键任务:确保其在高压环境下稳定运行。于是,我们启动了一轮针对该接口的性能压力测试,利用JMeter工具模拟高负载场景。然而,在测试进行约一分钟之后,频繁出现了…...

[数据集][目标检测]猕猴桃检测数据集VOC+YOLO格式1838张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1838 标注数量(xml文件个数):1838 标注数量(txt文件个数):1838 标注…...
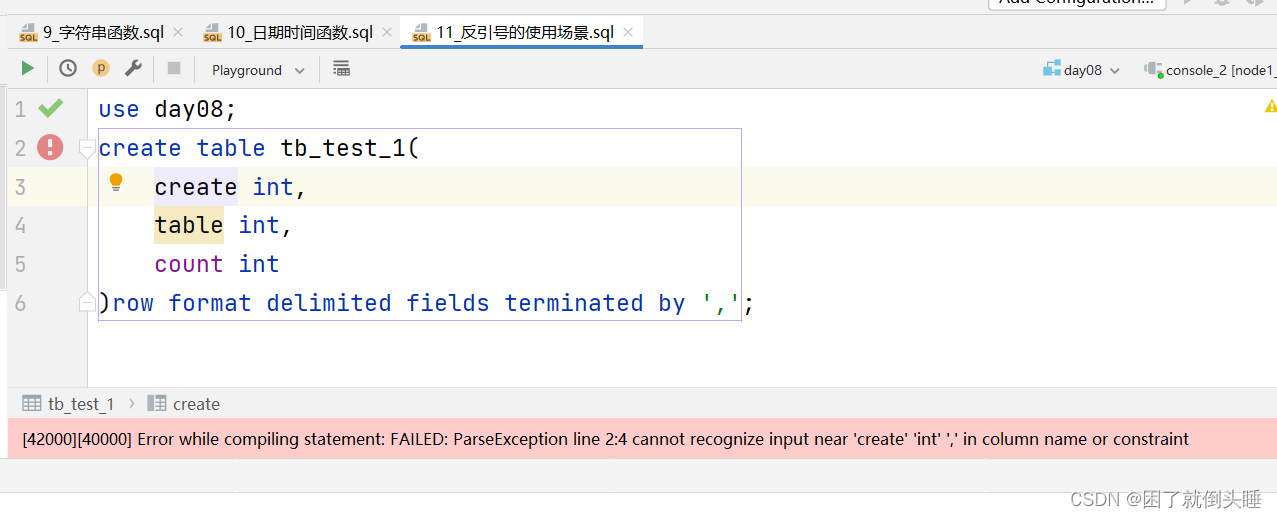
摸鱼大数据——Hive函数7-9
7、日期时间函数 Hive函数链接:LanguageManual UDF - Apache Hive - Apache Software Foundation SimpleDateFormat (Java Platform SE 8 ) current_timestamp: 获取时间原点到现在的秒/毫秒,底层自动转换方便查看的日期格式 常用 to_date: 字符串格式时间…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...