c++字符串相关接口
c++字符串相关接口
- 1.str2wstr(str转换wstr)
- 2.wstr2str(str转换wstr)
- 3.Utf8ToAsi(Utf8转换ANSI)
- 4.AsiToUtf8(ANSI转换Utf8)
- 5.stringformatA/stringformatW(按照指定的格式格式化字符串)
- 6.GetStringBetween(获取cStart cEnd之间的字符串)
- 7.Char2Int(char转int)
- 8.Str2Bin(字符串转换为二进制)
- 9.BinToStr(二进制转字符串)
- 10.Trim(压缩string两边的空格)
- 11.GetBase64Value(获取Base64的值)
- 12.Base64Dec(Base64还原(解码))
- 13.Base64Dec(Base64加密)
- 14.ConvertJsonToString(Json转换string)
- 15.EasyEnc/EasyDec 异或+7,异或-7
- 16.TimeToStr/StrToTime(时间和字符串相互转换)
- 17.Split(字符串分割然后赋值给容器)
- 18.GetJsonValue(从json中读取value值)
- 19.HexStr2Bin
- 20.UrlDecode(url解码)
- 21.Base64Trim
- 22.DecodeQuoted
- 23.ToLower(字符串大写换小写)
- 24.ToUpper(字符串小写换大写)
- 25.stringreplace(字符串替换)
- 26.StrWildcard(* ?的通配符比较)
- 27.NetTools_IpString2Ip(将点分格式的字符串IP地址转换为整数)
- 28.NetTools_Ip2IpString(将整数IP地址转换为点分格式的字符串IP地址)
- 29.RandomString(根据类型生成随机字符串)
- 30.Utf8SubString
1.str2wstr(str转换wstr)
#if WS_PLATFORM == WS_PLATFORM_WIN32
std::wstring str2wstr( const std::string &strSrc, UINT CodePage/*=CP_ACP CP_UTF8*/ )
{if(strSrc.length() == 0)return L"";int buflen=MultiByteToWideChar( CodePage, 0, strSrc.c_str(), -1, NULL, 0 ) +1 ;if(buflen == 0)return L"";wchar_t * buf = new wchar_t[buflen];std::wstring retn = L"";if (buf){memset(buf, 0, buflen * sizeof(wchar_t));::MultiByteToWideChar( CodePage, 0, strSrc.c_str(), -1, buf, buflen );retn = buf;delete []buf;}return retn;
}#elif WS_PLATFORM == WS_PLATFORM_LINUX
std::wstring str2wstr( const std::string &strSrc, UINT CodePage)
{UNUSED(CodePage);if(strSrc.length() == 0)return L"";std::string strLocale = setlocale(LC_ALL, "");int buflen=mbstowcs(NULL, strSrc.c_str(), 0) + 1;if(buflen == 0)return L"";wchar_t * buf = new wchar_t[buflen];std::wstring retn = L"";if (buf){memset(buf,0, buflen * sizeof(wchar_t));mbstowcs(buf, strSrc.c_str(), strSrc.length());retn = buf;delete []buf;}setlocale(LC_ALL, strLocale.c_str());return retn;
}#endif
2.wstr2str(str转换wstr)
#if WS_PLATFORM == WS_PLATFORM_WIN32
std::string wstr2str( const std::wstring &wstrSrc, UINT CodePage/*=CP_ACP CP_UTF8*/)
{if(wstrSrc.length() == 0)return "";//得到转化后需要Buf的长度std::string retn = "";try{int buflen = ::WideCharToMultiByte( CodePage, 0, wstrSrc.c_str(), -1, NULL, 0, NULL, NULL ) + 1;if(buflen == 0)return "";char * buf = new char[buflen];if(buf != NULL){memset(buf,0, buflen );::WideCharToMultiByte( CodePage, 0, wstrSrc.c_str(), -1, buf, buflen, NULL, NULL );retn = buf;delete []buf;}}catch (...){}return retn;
}#elif WS_PLATFORM == WS_PLATFORM_LINUX
std::string wstr2str( const std::wstring &wstrSrc, UINT CodePage)
{UNUSED(CodePage);if(wstrSrc.length() == 0)return "";//得到转化后需要Buf的长度std::string retn = "";try{std::string strLocale = setlocale(LC_ALL, "");int buflen = wcstombs(NULL, wstrSrc.c_str(), 0) + 1;if(buflen == 0)return "";char * buf = new char[buflen];if(buf != NULL){memset(buf,0, buflen );wcstombs(buf, wstrSrc.c_str(), buflen);retn = buf;delete []buf;}setlocale(LC_ALL, strLocale.c_str());}catch (...){}return retn;
}
#endif
3.Utf8ToAsi(Utf8转换ANSI)
std::string Utf8ToAsi(std::string strUtf8)
{
#if WS_PLATFORM == WS_PLATFORM_WIN32CWSByteArray baData;baData.Append(strUtf8.c_str());DWORD UniCodeLen = ::MultiByteToWideChar(CP_UTF8, 0, strUtf8.c_str(), -1, NULL, 0);std::vector <wchar_t> vWCH(UniCodeLen);::MultiByteToWideChar(CP_UTF8, 0, strUtf8.c_str(), -1, &vWCH[0], UniCodeLen);DWORD dwASCIILen = ::WideCharToMultiByte(CP_ACP, 0, &vWCH[0], UniCodeLen, NULL, NULL, NULL, NULL);if(!dwASCIILen)return "";char* pASCIIBuf = new char[dwASCIILen + 1];if(NULL == pASCIIBuf){return "";}memset(pASCIIBuf, 0, dwASCIILen + 1);::WideCharToMultiByte(CP_ACP, 0, &vWCH[0], UniCodeLen, pASCIIBuf, dwASCIILen, NULL, NULL);std::string szRetAsiic = pASCIIBuf;delete[] pASCIIBuf;return szRetAsiic;
#endifreturn strUtf8;
}
4.AsiToUtf8(ANSI转换Utf8)
string AsiToUtf8(string strAsi)
{
#if WS_PLATFORM == WS_PLATFORM_WIN32DWORD UniCodeLen = ::MultiByteToWideChar(CP_ACP, 0, strAsi.c_str(), -1, NULL, 0);std::vector <wchar_t> vWCH(UniCodeLen);::MultiByteToWideChar(CP_ACP, 0, strAsi.c_str(), -1, &vWCH[0], UniCodeLen);DWORD dwUTF8Len = ::WideCharToMultiByte(CP_UTF8, 0, &vWCH[0], UniCodeLen, NULL, NULL, NULL, NULL);if(!dwUTF8Len)return "";char* pUTF8Buf = new char[dwUTF8Len + 1];if(NULL == pUTF8Buf){return "";}memset(pUTF8Buf, 0, dwUTF8Len + 1);::WideCharToMultiByte(CP_UTF8, 0, &vWCH[0], UniCodeLen, pUTF8Buf, dwUTF8Len, NULL, NULL);std::string szRetUTF8 = pUTF8Buf;delete[] pUTF8Buf;return szRetUTF8;
#endifreturn strAsi;
}
5.stringformatA/stringformatW(按照指定的格式格式化字符串)
std::string stringformatA(const char* fmt, ...)
{ std::string s="";try{va_list argptr;
#ifdef _WIN32
#pragma warning( push )
#pragma warning( disable : 4996 )
#endifva_start(argptr, fmt);int bufsize = _vsnprintf(NULL, 0, fmt, argptr) + 1;va_end(argptr);char* buf=new char[bufsize];memset(buf, 0, bufsize);va_start(argptr, fmt);_vsnprintf(buf, bufsize, fmt, argptr);va_end(argptr);
#ifdef _WIN32
#pragma warning( pop )
#endifs=buf;delete[] buf;}catch(...){s="TryError!";}return s;
}std::wstring stringformatW(const wchar_t* fmt, ...)
{std::wstring s = L"";try{va_list argptr;
#ifdef _WIN32
#pragma warning( push )
#pragma warning( disable : 4996 )
#endifva_start(argptr, fmt);int bufsize = _vsnwprintf(NULL, 0, fmt, argptr) + 2;va_end(argptr);wchar_t* buf = new wchar_t[bufsize];memset(buf, 0, bufsize);va_start(argptr, fmt);_vsnwprintf(buf, bufsize,fmt, argptr);va_end(argptr);
#ifdef _WIN32
#pragma warning( pop )
#endifs = buf;delete[] buf;}catch (...){s = L"TryError!";}return s;
}
6.GetStringBetween(获取cStart cEnd之间的字符串)
std::string GetStringBetween(const char* cContent, const char* cStart, const char* cEnd)
{std::string strRe = "";char* cStartNow = strstr((char*)cContent,cStart);if (NULL != cStartNow){cStartNow += strlen(cStart);strRe = cStartNow;char* iEnd = strstr(cStartNow,cEnd);if (NULL != iEnd){strRe.erase(iEnd-cStartNow);}}return strRe;
}//获取cStart cEnd之间的字符串,限定范围是:cContent+cStartNow iEnd之间
std::string GetStringBetweenEx(const char* cContent, char* cStart, char* cEnd,int cStartNowPos,int iEndPos)
{std::string strRe = "";char* cStartNow = strstr((char*)(cContent+cStartNowPos),cStart);int cStartNowNow = 0;if ((NULL != cStartNow)&&((cContent+iEndPos)>cStartNow)){cStartNowNow = (int)(cStartNow - cContent);strRe.append(cStartNow,iEndPos-cStartNowNow);///<只写入部分数据char* iEnd = strstr(cStartNow,cEnd);if (NULL != iEnd){strRe.erase(iEnd-cStartNow);}strRe.erase(0,strlen(cStart));}return strRe;
}
7.Char2Int(char转int)
char Char2Int(char ch){if(ch>='0' && ch<='9')return (char)(ch-'0');if(ch>='a' && ch<='f')return (char)(ch-'a'+10);if(ch>='A' && ch<='F')return (char)(ch-'A'+10);return -1;}
8.Str2Bin(字符串转换为二进制)
char Str2Bin(char *str)
{char tempWord[2];char chn;tempWord[0] = Char2Int(str[0]);///<make the B to 11 -- 00001011tempWord[1] = Char2Int(str[1]); ///<make the 0 to 0 -- 00000000chn = (tempWord[0] << 4) | tempWord[1];///<to change the BO to 10110000return chn;
}size_t StrToBin(const string &strStr, CWSByteArray &arrBin)
{size_t iLen = 0;unsigned int nSingle = 0;BYTE bSingle = 0;char cSingle[4];arrBin.RemoveAll();for(iLen = 0; iLen<(size_t)strStr.length(); iLen+=2){memset(cSingle, 0, sizeof(cSingle));strncpy_s(cSingle, sizeof(cSingle),strStr.c_str() + iLen, 2);sscanf_s(cSingle, "%02X", &nSingle);bSingle = (BYTE)nSingle;arrBin.Add(bSingle);}return arrBin.GetCount();
}
9.BinToStr(二进制转字符串)
size_t BinToStr(CWSByteArray &arrBin, string &strStr)
{return BinToStr(arrBin.GetData(), arrBin.GetCount(), strStr);
}size_t BinToStr(const BYTE* pBuffer, size_t nSize, string &strStr)
{size_t iLen = 0;BYTE bSingle = 0;char cSingle[3];strStr = "";for(iLen = 0; iLen<nSize; iLen++){bSingle = *(pBuffer+iLen);memset(cSingle, 0, sizeof(cSingle));sprintf_s(cSingle,sizeof(cSingle), "%02X", bSingle);strStr += cSingle;}return strStr.length();
}
10.Trim(压缩string两边的空格)
std::string trimLeft(const std::string& str)
{std::string strRet = str;for (std::string::iterator iter = strRet.begin(); iter != strRet.end(); ++iter){if (!isspace(*iter)){strRet.erase(strRet.begin(), iter);break;}}return strRet;
}std::string trimRight(const std::string& str)
{if (str.begin() == str.end()){return str;}std::string strRet = str;for (std::string::iterator iter = strRet.end() - 1; iter != strRet.begin(); --iter){if (!isspace(*iter)){strRet.erase(iter + 1, strRet.end());break;}}return strRet;
}//string 的trim 函数 ,干掉头尾空格
std::string Trim(const std::string& str){if(str.empty())return "";std::string strRet = str;std::string::iterator iter;for (iter = strRet.begin(); iter != strRet.end(); ++iter){if (!isspace(*iter)){strRet.erase(strRet.begin(), iter);break;}}if (iter == strRet.end()){return strRet;}for (iter = strRet.end() - 1; iter != strRet.begin(); ++iter){if (!isspace(*iter)) {strRet.erase(iter + 1, strRet.end());break;}}return strRet;
}
11.GetBase64Value(获取Base64的值)
char GetBase64Value(char ch)
{if ((ch >= 'A') && (ch <= 'Z')) return ch - 'A'; if ((ch >= 'a') && (ch <= 'z')) return ch - 'a' + 26; if ((ch >= '0') && (ch <= '9')) return ch - '0' + 52; switch (ch) { case '+': return 62; case '/': return 63; case '=': /* base64 padding */ return 0; default: return 0; }
}
12.Base64Dec(Base64还原(解码))
int Base64Dec(char *buf,char*text,int size)
{if(size%4) return 0;unsigned char chunk[4];int parsenum=0;while(size>0){chunk[0] = GetBase64Value(text[0]); chunk[1] = GetBase64Value(text[1]); chunk[2] = GetBase64Value(text[2]); chunk[3] = GetBase64Value(text[3]); *buf++ = (chunk[0] << 2) | (chunk[1] >> 4); *buf++ = (chunk[1] << 4) | (chunk[2] >> 2); *buf++ = (chunk[2] << 6) | (chunk[3]);text+=4;size-=4;parsenum+=3;}return parsenum;
}
int Base64Decode(const std::string& strB64, char* pOutput,int iBufferSize)
{int iB64Len=(int)strB64.size();//检查是否是4的整数倍if(iB64Len == 0 || iB64Len%4) return 0;//检查输出缓冲区是不是正确int iBINLen=iB64Len*3/4;if (strB64[strB64.size()-1]=='='){iBINLen--;}if (strB64[strB64.size()-2]=='='){iBINLen--;}if (iBufferSize<iBINLen) return iBINLen;if(NULL==pOutput) return 0;unsigned char chunk[4];int parsenum=0;int iNowPos=0;while(iNowPos<iB64Len){chunk[0] = GetBase64Value(strB64[iNowPos]); chunk[1] = GetBase64Value(strB64[iNowPos+1]); chunk[2] = GetBase64Value(strB64[iNowPos+2]); chunk[3] = GetBase64Value(strB64[iNowPos+3]); *pOutput++ = (chunk[0] << 2) | (chunk[1] >> 4); *pOutput++ = (chunk[1] << 4) | (chunk[2] >> 2); *pOutput++ = (chunk[2] << 6) | (chunk[3]);iNowPos+=4;parsenum+=3;}if (iNowPos>0 && strB64[iNowPos-4+3]=='='){parsenum--;}if (iNowPos>1 && strB64[iNowPos-4+2]=='='){parsenum--;}return parsenum;
}
13.Base64Dec(Base64加密)
int Base64Enc(char *pOutBuf, char *pInput, int iSize)
{ const char *cBase64_Encoding = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";int iBuflen = 0; int c1 =0,c2 =0,c3 =0;while(iSize>0){if(iSize>2){c1 = pInput[0] & 0xFF;c2 = pInput[1] & 0xFF;c3 = pInput[2] & 0xFF;*pOutBuf++ = cBase64_Encoding[(c1 & 0xFC) >> 2];*pOutBuf++ = cBase64_Encoding[((c1 & 0x03) << 4) | ((c2 & 0xF0) >> 4)];*pOutBuf++ = cBase64_Encoding[((c2 & 0x0F) << 2) | ((c3 & 0xC0) >> 6)];*pOutBuf++ = cBase64_Encoding[c3 & 0x3F];}else{switch(iSize){case 1:c1 = pInput[0] & 0xFF;*pOutBuf++ = cBase64_Encoding[ (c1 & 0xFC) >> 2];*pOutBuf++ = cBase64_Encoding[((c1 & 0x03) << 4)];*pOutBuf++ = '=';*pOutBuf++ = '=';break;case 2: c1 = pInput[0] & 0xFF;c2 = pInput[1] & 0xFF;*pOutBuf++ = cBase64_Encoding[(c1 & 0xFC) >> 2];*pOutBuf++ = cBase64_Encoding[((c1 & 0x03) << 4) | ((c2 & 0xF0) >> 4)]; *pOutBuf++ = cBase64_Encoding[((c2 & 0x0F) << 2)]; *pOutBuf++ = '='; break; } } pInput +=3; iSize -=3; iBuflen +=4; } *pOutBuf = 0; return iBuflen;
} int Base64Encode(char* pInput,int iSize,std::string& strB64)
{const char *cBase64_Encoding = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";int iBuflen = 0; int c1 =0,c2 =0,c3 =0;if(NULL==pInput) return 0;if(0==iSize) return 0;while(iSize>0){if(iSize>2){c1 = pInput[0] & 0xFF;c2 = pInput[1] & 0xFF;c3 = pInput[2] & 0xFF;strB64 += cBase64_Encoding[(c1 & 0xFC) >> 2];strB64 += cBase64_Encoding[((c1 & 0x03) << 4) | ((c2 & 0xF0) >> 4)];strB64 += cBase64_Encoding[((c2 & 0x0F) << 2) | ((c3 & 0xC0) >> 6)];strB64 += cBase64_Encoding[c3 & 0x3F];}else{switch(iSize){case 1:c1 = pInput[0] & 0xFF;strB64 += cBase64_Encoding[ (c1 & 0xFC) >> 2];strB64 += cBase64_Encoding[((c1 & 0x03) << 4)];strB64 += '=';strB64 += '=';break;case 2: c1 = pInput[0] & 0xFF;c2 = pInput[1] & 0xFF;strB64 += cBase64_Encoding[(c1 & 0xFC) >> 2];strB64 += cBase64_Encoding[((c1 & 0x03) << 4) | ((c2 & 0xF0) >> 4)]; strB64 += cBase64_Encoding[((c2 & 0x0F) << 2)]; strB64 += '='; break; } } pInput +=3; iSize -=3; iBuflen +=4; } //*pOutBuf = 0; return iBuflen;
}
14.ConvertJsonToString(Json转换string)
void ConvertJsonToString(Value *pValue, string &strJson)
{//将doc对象的值写入字符串StringBuffer buffer; Writer<StringBuffer> writer(buffer);pValue->Accept(writer);strJson = buffer.GetString();
}std::string ConvertJsonToString(Value &pValue)
{StringBuffer buffer;Writer<StringBuffer> writer(buffer);pValue.Accept(writer);return string(buffer.GetString());
}
15.EasyEnc/EasyDec 异或+7,异或-7
//异或+7
string EasyEnc(string strKey, string strIn)
{string strOut = "";char cSingle[3] = {0};unsigned char bSingle = '0';size_t nKeyLen = strKey.length();for (size_t nIndex=0; nIndex<strIn.length(); nIndex++){//加密,异或+7bSingle = (strIn.at(nIndex)^strKey.at(nIndex%nKeyLen))+7;//bin转strmemset(cSingle, 0, sizeof(cSingle));snprintf(cSingle, 3, "%02X", bSingle);strOut += cSingle;}return strOut;
}//异或-7
string EasyDec(string strKey, string strIn)
{string strOut = "";unsigned int nSingle = 0;unsigned char bSingle = '0';char cSingle[3] = {0};size_t nKeyLen = strKey.length();for (size_t nIndex=0; nIndex<strIn.length(); nIndex += 2){//str转binmemset(cSingle,0,sizeof(cSingle));strncpy_s(cSingle, sizeof(cSingle), strIn.c_str()+nIndex, 2);sscanf_s(cSingle, "%02X", &nSingle);//解密,异或-7bSingle = (unsigned char)(nSingle-7)^strKey.at((nIndex/2)%nKeyLen);strOut += bSingle;}return strOut;
}
16.TimeToStr/StrToTime(时间和字符串相互转换)
std::string TimeToStr(time_t t)
{std::string strRe = "2000-01-01 00:00:00";if (0 == t) return strRe;struct tm newtime;memset(&newtime, 0, sizeof(newtime));localtime_s(&newtime, &t);if (newtime.tm_year > 0){strRe = stringformatA("%04d-%02d-%02d %02d:%02d:%02d",newtime.tm_year + 1900, newtime.tm_mon + 1, newtime.tm_mday,newtime.tm_hour, newtime.tm_min, newtime.tm_sec);}return strRe;
}time_t StrToTime(const char *strString)
{time_t timeRe = 0;char *pPos = strstr((char*)strString, "-");if (pPos == NULL){return timeRe;}int iYear = std::atoi(strString);int iMonth = std::atoi(pPos + 1);pPos = strstr(pPos + 1, "-");if (pPos == NULL){return timeRe;}int iDay = atoi(pPos + 1);int iHour = 0;int iMin = 0;int iSec = 0;pPos = strstr(pPos + 1, " ");//为了兼容有些没精确到时分秒的if (pPos != NULL){iHour = atoi(pPos + 1);pPos = strstr(pPos + 1, ":");if (pPos != NULL){iMin = atoi(pPos + 1);pPos = strstr(pPos + 1, ":");if (pPos != NULL){iSec = atoi(pPos + 1);}}}struct tm sourcedate;memset((void*)&sourcedate, 0, sizeof(sourcedate));sourcedate.tm_sec = iSec;sourcedate.tm_min = iMin;sourcedate.tm_hour = iHour;sourcedate.tm_mday = iDay;sourcedate.tm_mon = iMonth - 1;sourcedate.tm_year = iYear - 1900;timeRe = _mktime64(&sourcedate);return timeRe;
}
17.Split(字符串分割然后赋值给容器)
/// @fn void Split(const std::string& strInput, const std::string& strSep, std::vector<std::string> &vecSeg);
/// @brief 字符串分割然后赋值给容器
/// @param const std::string& strInput 传入赋值给容器的字符
/// @param const std::string& strSep 传入给容器字符内容的下标数
/// @param std::vector<std::string> &vecSeg 所要赋值的容器
/// @return 得到数值
/// @retval 返回需要的字符串
/// @note
void Split(const std::string& strInput, const std::string& strSep, std::vector<std::string> &vecSeg)
{std::string strTemp = "";if(strInput.empty() || strSep.empty())return;vecSeg.clear();vecSeg.reserve(strInput.size()/2);size_t nStart = 0;size_t nPos = std::string::npos;do{nPos = strInput.find(strSep,nStart);strTemp = strInput.substr(nStart,nPos-nStart);if (strTemp.length() > 0){vecSeg.push_back(strTemp);}nStart = nPos + strSep.size();}while(nPos!=std::string::npos);
}/// @fn void Split(const std::wstring &strInput, const std::wstring &strSep, vector<std::wstring> &vecSeg);
/// @brief 字符串分割然后赋值给容器
/// @param const std::wstring& strInput 传入赋值给容器的字符
/// @param const std::wstring& strSep 传入给容器字符内容的下标数
/// @param std::vector<std::wstring> &vecSeg 所要赋值的容器
/// @retval 返回需要的字符串
void Split(const std::wstring &strInput, const std::wstring &strSep, std::vector<std::wstring> &vecSeg)
{wstring strTemp = L"";if(strInput.empty() || strSep.empty())return;vecSeg.clear();vecSeg.reserve(strInput.size()/2);size_t nStart = 0;size_t nPos = string::npos;do{nPos = strInput.find(strSep, nStart);strTemp = strInput.substr(nStart, nPos-nStart);if (strTemp.length() > 0){vecSeg.push_back(strTemp);}nStart = nPos + strSep.size();}while(nPos != string::npos);
}
18.GetJsonValue(从json中读取value值)
std::string GetJsonValue(const std::string& str, const std::string& strKey)
{string strRet = "";Document doc;doc.Parse(str.c_str());if(doc.HasParseError()){return strRet;}if(!doc.HasMember(strKey.c_str())){TRACKERROR("str = %s NO Field(%s)!", str.c_str(), strKey.c_str());return strRet;}ConvertJsonToString(&doc[strKey.c_str()],strRet);if(strRet.find_first_of("\"") == 0){strRet.erase(strRet.begin());strRet.erase(strRet.end() - 1);}return strRet;
}
19.HexStr2Bin
/// @fn int HexStr2Bin(unsigned char *pBinStr, int nMaxOutLen, const char *pszHexStr, int nHexLen);
/// @brief Base6416进制存储bin文件
/// @param unsigned char *pBinStr 接收文件
/// @param int nMaxOutLen 最大值数
/// @param const char *pszHexStr 被复制的
/// @param int nHexLen 循环次数
/// @return 得到数值
int HexStr2Bin(unsigned char *pBinStr, int nMaxOutLen, const char *pszHexStr, int nHexLen)
{if (NULL == pBinStr || NULL == pszHexStr){return -1;}if (nMaxOutLen <= 0 || nHexLen <= 0 || nHexLen % 2 || nMaxOutLen < nHexLen / 2){return -1;}unsigned int dwSingle = 0;char cSingle[3];int nOutLen = 0;for (int i = 0; i < nHexLen; i += 2){memset(cSingle, 0, sizeof(cSingle));strncpy_s(cSingle, sizeof(cSingle), (char *)pszHexStr + i, 2);sscanf_s(cSingle, "%02X", &dwSingle);pBinStr[nOutLen++] = dwSingle;}return nOutLen;
}
20.UrlDecode(url解码)
std::string UrlDecode(std::string strForDec)
{//1. base64解码//2.utf8 1/2/3解码//3. Unicode解码std::string output="";DWORD dwCodeType =CODETYPE_UNKNOWN;//#pragma region 1. base64解码const static int iCount = 8;const string strAryTemp[iCount]={ "=?utf-8?B?", "=?UTF-8?B?","=?gb2312?B?", "=?GB2312?B?","=?gbk?B?","=?GBK?B?","=?UTF8?B?","=?utf8?B?"};size_t offset;int iIndex = 0;bool bNeedBase64Dec = false;for(; !bNeedBase64Dec && iIndex < iCount; iIndex++){offset = strForDec.find(strAryTemp[iIndex]);if ( string::npos != offset){bNeedBase64Dec = true;break;}}bool bUsedBase64Dec = false;for ( ; bNeedBase64Dec;){string strTemp = GetStringBetween(strForDec.c_str(),(char *)strAryTemp[iIndex].c_str(),"?=");int iLength = (int)strTemp.length();assert(iLength > 0);char *pOutBuffer = new char[iLength];if ( pOutBuffer == NULL ){return "";}memset(pOutBuffer, 0, iLength);if (Base64Decode(strTemp,pOutBuffer, iLength )>0){strForDec.erase( offset, strAryTemp[iIndex].length() + iLength + 2);strForDec.insert( offset, pOutBuffer);bUsedBase64Dec = true;delete []pOutBuffer;}else{delete []pOutBuffer;return "";}offset = strForDec.find(strAryTemp[iIndex]);bNeedBase64Dec = string::npos != offset;}
//#pragma endregion 1. base64解码if ( bUsedBase64Dec ){output = strForDec;if ( lstrcmpiA(strAryTemp[iIndex].c_str(), "=?utf-8?B?")==0 ){dwCodeType = CODETYPE_UTF8_OK;}}//2.utf8 1/2/3解码else{dwCodeType =CODETYPE_UTF8_UNKNOWN;size_t nlen =strForDec.length();size_t nIndex = 0;char tmp[2];char ctmp;int iUtf8Type = 2;int iUtf8Count = 0;while(nIndex<nlen){if(strForDec[nIndex]=='%' && nIndex <(nlen-2)){tmp[0]=strForDec[nIndex+1];tmp[1]=strForDec[nIndex+2];ctmp = Str2Bin(tmp);output+=ctmp;nIndex=nIndex+3;
//#pragma region 只是对字节数判断if (0 == iUtf8Count){//3字节if ((ctmp&0xF0)==0xE0){iUtf8Type = 3;if (dwCodeType == CODETYPE_UTF8_UNKNOWN){dwCodeType = CODETYPE_UTF8_OK;}}//2字节else if ( ((ctmp&0xF0)==0xC0) || ((ctmp&0xF0)==0xD0)){iUtf8Type = 2;if (dwCodeType == CODETYPE_UTF8_UNKNOWN){dwCodeType = CODETYPE_UTF8_OK;}}else if( !(ctmp & 0x80) ) //1字节 0xxxxxxx{iUtf8Type = 1; // add by ybx 2012-11-03if (dwCodeType == CODETYPE_UTF8_UNKNOWN){dwCodeType = CODETYPE_UTF8_OK;}}else{dwCodeType = CODETYPE_UTF8_ERROR;}}iUtf8Count++;if (iUtf8Count == iUtf8Type) iUtf8Count = 0;
//#pragma endregion 只是对字节数判断}else if(strForDec[nIndex]=='+'){output+=' ';iUtf8Count = 0;nIndex++;}else{output+=strForDec[nIndex];iUtf8Count = 0;nIndex++;}}}//3. Unicode解码if (CODETYPE_UTF8_OK == dwCodeType){wstring woutput = L"";size_t nlen = output.length();size_t i = 0;wchar_t tTemp[2];while(i<nlen){if (((output[i]&0xF0)==0xE0)&&((i+2)<nlen)){///UTF8->UnicodeBYTE b1 = ((output[i+0] & 0x0f) <<4) + ((output[i+1] & 0x3c) >>2);BYTE b2 = ((output[i+1] & 0x03) <<6) + (output[i+2] & 0x3f);tTemp[0]=b1*0x100+b2;tTemp[1]=L'\0';woutput += tTemp;i+=3;}else if ((((output[i]&0xF0)==0xC0)||((output[i]&0xF0)==0xD0))&&((i+1)<nlen)){///UTF8->UnicodeBYTE b1 = (UCHAR)((output[i]) & 0x1f) >> 2;BYTE b2 = ((UCHAR)((output[i]) & 0x1f) << 6) | (output[i+1] & 0x3f);tTemp[0]=b1*0x100+b2;tTemp[1]=L'\0';woutput += tTemp;i+=2;}else{tTemp[0]=output[i];tTemp[1]=L'\0';woutput += tTemp;i++;}}output = wstr2str(woutput.c_str(), CP_UTF8);}return output;
}int Base64Decode(const std::string& strB64, char* pOutput,int iBufferSize)
{int iB64Len=(int)strB64.size();//检查是否是4的整数倍if(iB64Len == 0 || iB64Len%4) return 0;//检查输出缓冲区是不是正确int iBINLen=iB64Len*3/4;if (strB64[strB64.size()-1]=='='){iBINLen--;}if (strB64[strB64.size()-2]=='='){iBINLen--;}if (iBufferSize<iBINLen) return iBINLen;if(NULL==pOutput) return 0;unsigned char chunk[4];int parsenum=0;int iNowPos=0;while(iNowPos<iB64Len){chunk[0] = GetBase64Value(strB64[iNowPos]); chunk[1] = GetBase64Value(strB64[iNowPos+1]); chunk[2] = GetBase64Value(strB64[iNowPos+2]); chunk[3] = GetBase64Value(strB64[iNowPos+3]); *pOutput++ = (chunk[0] << 2) | (chunk[1] >> 4); *pOutput++ = (chunk[1] << 4) | (chunk[2] >> 2); *pOutput++ = (chunk[2] << 6) | (chunk[3]);iNowPos+=4;parsenum+=3;}if (iNowPos>0 && strB64[iNowPos-4+3]=='='){parsenum--;}if (iNowPos>1 && strB64[iNowPos-4+2]=='='){parsenum--;}return parsenum;
}
21.Base64Trim
/// @fn void Base64Trim(std::string& str);
/// @brief 去除Base64编码字符串开头和结尾两端的空格
/// @param std::string& str
/// @return 得到数值
void Base64Trim(string &str)
{size_t iposfront = 0;size_t iposback = 0;std::string str64Char = base64Char;str64Char += "=";for( ;iposback < str.size(); ++iposback){if ( std::string::npos == str64Char.find((char)str.at(iposback))){continue;}str.replace(iposfront, 1, 1, str.at(iposback));++iposfront;}str.erase(iposfront, str.size() - iposfront);
}
22.DecodeQuoted
string DecodeQuoted(const string &strSrc)
{INT_PTR iSrcSize = strSrc.size();const char *pByteSrc = (char*)strSrc.data();char * pDes = new char[iSrcSize];memset(pDes,0, iSrcSize);char * pTemp = pDes;INT_PTR i = 0;int iSize = 0;while(i < iSrcSize){if (strncmp(pByteSrc, "=\r\n", 3) == 0) // 软回车,跳过{pByteSrc += 3;i += 3;}else{if (*pByteSrc == '=') // 是编码字节{sscanf_s(pByteSrc, "=%02X", reinterpret_cast<unsigned int *>(pTemp));pTemp++;pByteSrc += 3;i += 3;}else // 非编码字节{*pTemp++ = (unsigned char)*pByteSrc++;i++;}++iSize;}}std::string result(pDes, iSize);delete []pDes;pDes = NULL;return result;
}
23.ToLower(字符串大写换小写)
std::string ToLower(const std::string& strIn)
{std::string strTmp = strIn;for(size_t i=0; i<strTmp.size(); ++i){char& c = strTmp[i];if(c >= 'A' && c <= 'Z')c |= 32;}return strTmp;
}std::wstring ToLower(const std::wstring& strIn)
{std::wstring strTmp = strIn;for(size_t i=0; i<strTmp.size(); ++i){wchar_t& c = strTmp[i];if(c >= L'A' && c <= L'Z')c|=32;}return strTmp;
}
24.ToUpper(字符串小写换大写)
std::string ToUpper(const std::string& strIn)
{std::string strTmp = strIn;for(size_t i=0; i<strTmp.size(); ++i){char& c = strTmp[i];if(c >= 'a' && c <= 'z')c &= 0xdf;}return strTmp;
}std::wstring ToUpper(const std::wstring& strIn)
{std::wstring strTmp = strIn;for(size_t i=0; i<strTmp.size(); ++i){wchar_t& c = strTmp[i];if(c >= L'A' && c <= L'Z')c &= 0xdf;}return strTmp;
}
25.stringreplace(字符串替换)
int stringreplace(std::string& strString, const char* src, const char* target)
{size_t nLen = 0;int iPos = 0;int iCount = 0;while (nLen < strString.length()){iPos = (int)strString.find(src, nLen);if (iPos >= 0){//找到了iCount++;strString.replace(iPos, strlen(src), target);nLen = iPos + strlen(target);}else{break;}}return iCount;
}
26.StrWildcard(* ?的通配符比较)
BOOL StrWildcard(const char *pat, const char *str)
{while(*str && *pat){if(*pat == '?'){if(StrWildcard(pat+1, str)) return TRUE;str++;pat++;}else if(*pat == '*'){while(*pat == '*' || *pat == '?') pat++;if(!*pat) return TRUE;while(*str){if(StrWildcard(pat, str)) return TRUE;str++;}return FALSE;}else{if(*pat!=*str) return FALSE;str++;pat++;}}if(*str!=0) return FALSE;while(*pat == '*' || *pat == '?') pat++;return !*pat;
}
27.NetTools_IpString2Ip(将点分格式的字符串IP地址转换为整数)
LONGLONG NetTools_IpString2Ip(const std::string& strRe, BOOL ipv6)
{LONGLONG ullIp = 0;int bIP[8];if (0 == strRe.length()){return 0;}if (ipv6){//ipV6sscanf_s(strRe.c_str(), "%d.%d.%d.%d.%d.%d", &bIP[5], &bIP[4], &bIP[3], &bIP[2], &bIP[1], &bIP[0]);ullIp = ((LONGLONG)bIP[5] << 40) | ((LONGLONG)bIP[4] << 32) | ((LONGLONG)bIP[3] << 24) | ((LONGLONG)bIP[2] << 16) | ((LONGLONG)bIP[1] << 8) | (LONGLONG)bIP[0];}else{//ipV4sscanf_s(strRe.c_str(), "%d.%d.%d.%d", &bIP[3], &bIP[2], &bIP[1], &bIP[0]);ullIp = ((LONGLONG)bIP[3] << 24) | ((LONGLONG)bIP[2] << 16) | ((LONGLONG)bIP[1] << 8) | (LONGLONG)bIP[0];}return ullIp;
}
28.NetTools_Ip2IpString(将整数IP地址转换为点分格式的字符串IP地址)
std::string NetTools_Ip2IpString(LONGLONG llIp, BOOL ipv6)
{BYTE bIP[6];std::string strRe;bIP[0] = (BYTE)((llIp >> (8 * 0)) & (BYTE)0xff);bIP[1] = (BYTE)((llIp >> (8 * 1)) & (BYTE)0xff);bIP[2] = (BYTE)((llIp >> (8 * 2)) & (BYTE)0xff);bIP[3] = (BYTE)((llIp >> (8 * 3)) & (BYTE)0xff);if (ipv6){//ipV6bIP[4] = (BYTE)((llIp >> (8 * 4)) & (BYTE)0xff);bIP[5] = (BYTE)((llIp >> (8 * 5)) & (BYTE)0xff);strRe = stringformatA("%d.%d.%d.%d.%d.%d", bIP[5], bIP[4], bIP[3], bIP[2], bIP[1], bIP[0]);}else{//ipV4strRe = stringformatA("%d.%d.%d.%d", bIP[3], bIP[2], bIP[1], bIP[0]);}return strRe;
}
29.RandomString(根据类型生成随机字符串)
std::string RandomString(DWORD dwStrLen, DWORD dwType, DWORD dwSrand)
{std::string strRand = "";char cRand;DWORD dwLen = 0;srand((unsigned)time(NULL) + dwSrand);while (dwLen < dwStrLen){cRand = rand() % 128;if (_UPPER&dwType){//<大写字母if (isupper(cRand)) { strRand += cRand; dwLen++; continue; }}if (_LOWER&dwType){//<小写字母if (islower(cRand)) { strRand += cRand; dwLen++; continue; }}if (_DIGIT&dwType){//<数字if (isdigit(cRand)) { strRand += cRand; dwLen++; continue; }}if (_PUNCT&dwType){//<特殊字符if (ispunct(cRand)) { strRand += cRand; dwLen++; continue; }}}return strRand;
}
30.Utf8SubString
//返回str中的一个UTF-8编码的子字符串,从位置nStart开始,长度为nLength。
std::string Utf8SubString(const std::string &str, size_t nStart, size_t nLength)
{if (nLength == 0 || nStart > str.size()){return std::string();}if (nLength == std::string::npos){return str.substr(nStart, std::string::npos);}size_t i = 0, j = 0;size_t nMin = std::string::npos;size_t nMax = std::string::npos;for (i = 0, j = 0; i < str.size(); i++, j++){if (j == nStart){nMin = i;}if (i <= nStart + nLength ){nMax = i;}else{break;}unsigned char byte = str[i];if (byte < 128){i += 0;}else if ((byte & 0xE0) == 0xC0){i += 1;}else if ((byte & 0xF0) == 0xE0){i += 2;}else if ((byte & 0xF8) == 0xF0){i += 3;}else{return std::string();}}if (j <= nStart + nLength){nMax = i;}return str.substr(nMin, nMax);
}
相关文章:

c++字符串相关接口
c字符串相关接口 1.str2wstr(str转换wstr)2.wstr2str(str转换wstr)3.Utf8ToAsi(Utf8转换ANSI)4.AsiToUtf8(ANSI转换Utf8)5.stringformatA/stringformatW(按照指定的格式格式化字符串)6.GetStringBetween(获取cStart cEnd之间的字符串)7.Char2Int(char转int)8.Str2Bin(字符串转换…...
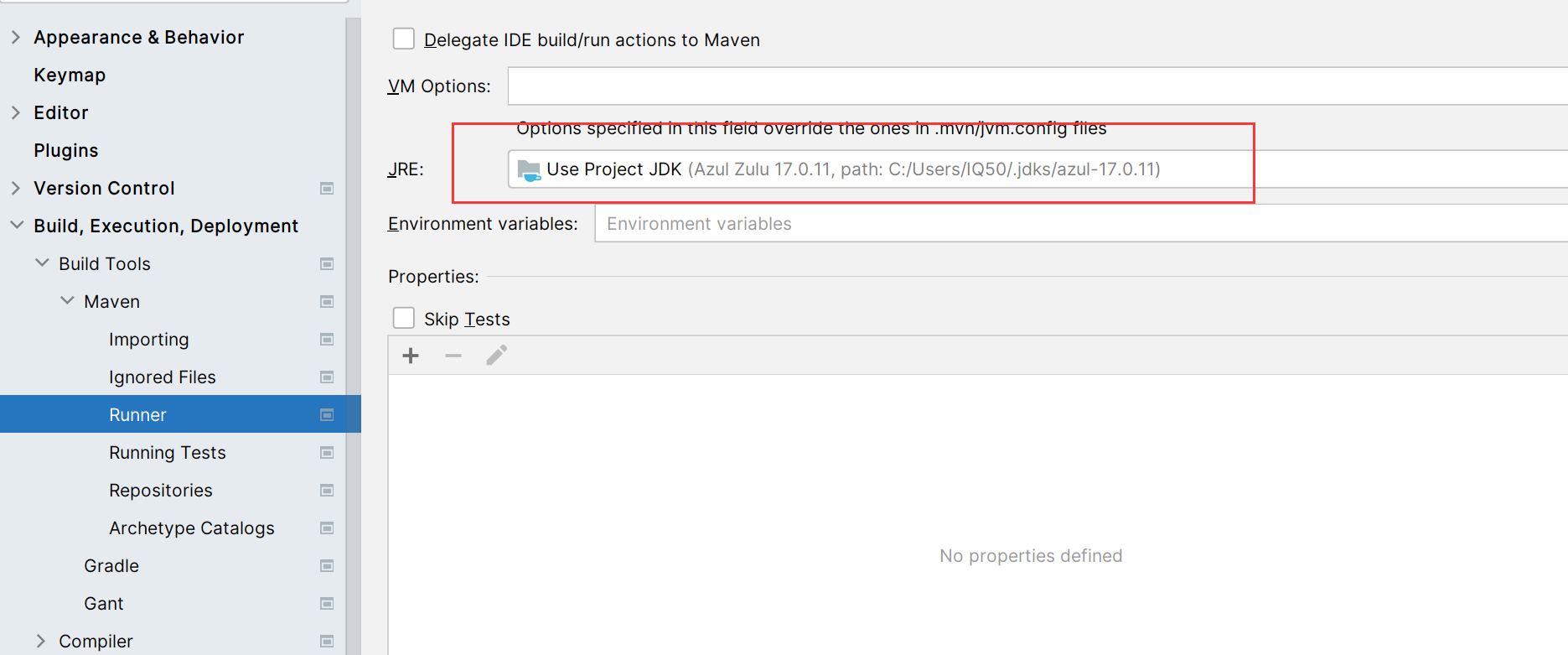
Maven打包错误:无效的源发行版:17
1. 报错问题 在用maven进行打包时(clean & install),报如下错误: 一开始让我很摸不着头脑,我确定我的pom.xml,还有IDEA中的Project Settings是正确的。 2. 排查 尽管确定,但还是一个个排…...

【环境栏Composer】Composer常见问题(持续更新)
1、执行composer install提示当前目录中没有 composer.lock 文件时 No composer.lock file present. Updating dependencies to latest instead of installing from lock file. See https://getcomposer.org/install for more information. Composer 在执行 install 命令时会…...

塑造更智慧的AI:策略与路径探索
提升数据质量: 数据清洗:去除数据中的异常值、缺失值、噪声等干扰因素,确保数据的准确性和一致性。数据标注:为数据集提供准确的标签,以便进行有监督学习。标注的质量直接影响模型的性能。数据增强:通过图像…...

软设之快速排序
快速排序是冒泡排序的改进算法 它采用的是分治法,基本思想是把原问题分解为若干规模更小但结构与原问题相似的子问题,通过递归解决这些子问题,然后将这些子问题的解组合成原问题的解。 它的步骤是 1.在待排序的n个记录中任取一个记录&…...

从零学算法2965
2965. 找出缺失和重复的数字 给你一个下标从 0 开始的二维整数矩阵 grid,大小为 n * n ,其中的值在 [1, n2] 范围内。除了 a 出现 两次,b 缺失 之外,每个整数都 恰好出现一次 。 任务是找出重复的数字a 和缺失的数字 b 。 返回一个…...
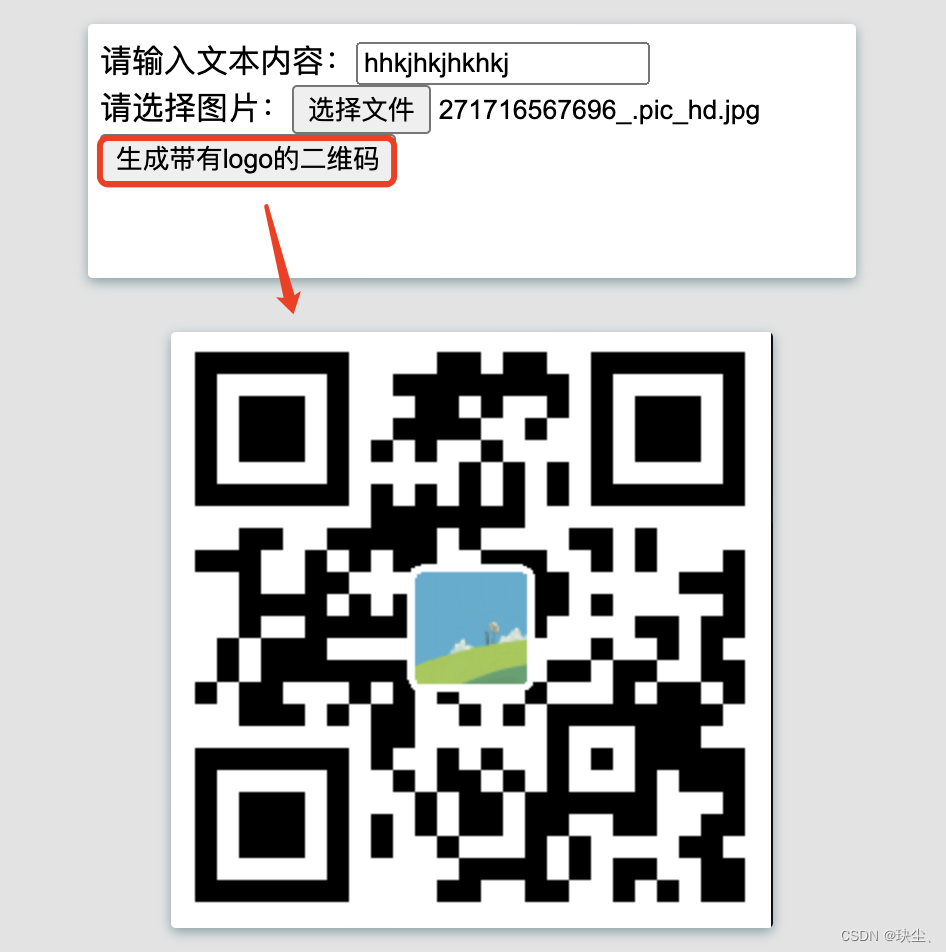
【Mac版】Java生成二维码
软件版本 IntelliJ IDEA:2023.2 JDK:17 Tomcat:10.1.11 Maven:3.9.3 技术栈 servlet谷歌的:zxing 生成普通的黑白二维码在二维码中间添加一个小图标 github开源项目:qrcode qrcode开源项目的内部是基于z…...

ROS2自定义服务接口
ROS2自定义服务接口 在src/village_interface 下构建srv文件夹 src/village_interface/srv 下新建一个BorrowMoney.srv 遵循大小写编程规范 # 客户端请求 string name uint32 money # 中间这三个横杠很重要 不能删掉 --- # 服务端响应 bool success uint32 money接口编译 修改…...
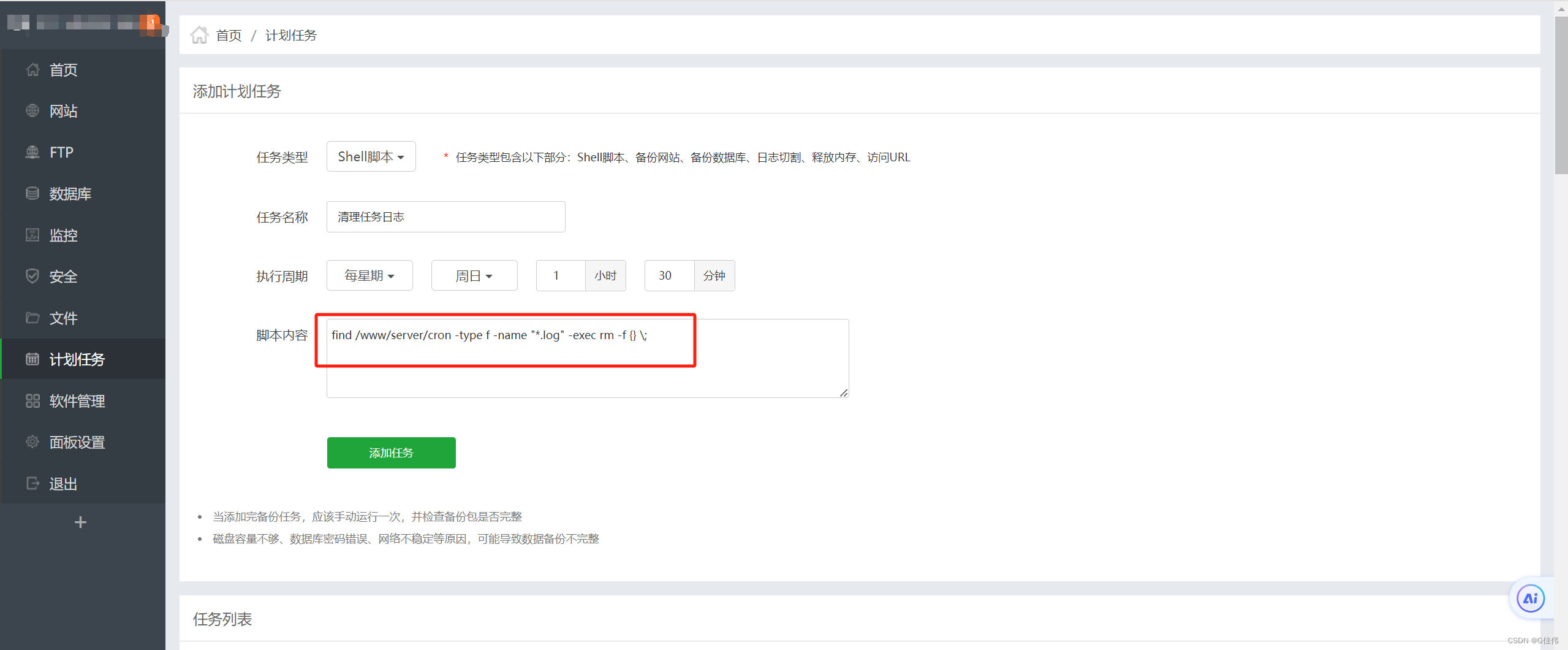
linux /www/server/cron内log文件占用空间过大,/www/server/cron是什么内容,/www/server/cron是否可以删除
linux服务器长期使用宝塔自带计划任务,计划任务执行记录占用服务器空间过大,导致服务器根目录爆满,需要长期排查并删除 /www/server/cron 占用空间过大问题处理 /www/server/cron是什么内容?/www/server/cron是否可以删除…...

C++青少年简明教程:break语句、continue语句
C青少年简明教程:break语句、continue语句 break语句 只能用在switch语句和循环语句(for循环、while循环和do-while循环)中。作用:跳出switch语句或提前终止循环。 break语句的基本语法如下: break; break语句的示例…...
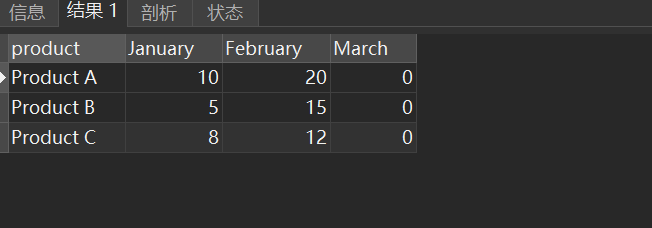
MySQL实战行转列(或称为PIVOT)实战sales的表记录了不同产品在不同月份的销售情况,进行输出
有一个sales的表,它记录了不同产品在不同月份的销售情况: productJanuaryFebruaryMarchProduct AJanuary10Product AFebruary20Product BJanuary5Product BFebruary15Product CJanuary8Product CFebruary12 客户需求展示为如下的样子: pro…...

牛客NC164 最长上升子序列(二)【困难 贪心+二分 Java/Go/PHP/C++】
题目 题目链接: https://www.nowcoder.com/practice/4af96fa010c44638a7e112abf65f7237 思路 贪心二分 所谓贪心,就是往死里贪,所以对于最大上升子序列,结尾元素越小,越有利于后面接上其他的数,也就可能变…...

电子烟开发【恒压、恒有效算法】
恒压算法 pwm是通过软件模拟的 pwm满值运行是250全占空比 #define D_TARGET_AVERAGE_VOLTAGE 3500 //R_ADC1_Vout :发热丝两端AD值 //R_ADC_FVR :电池电压AD值 //FVR_VOLTAGE :电池AD参考电压 满电值AD //R_Smk1Duty :最后…...

基于Open3D的点云处理22-非阻塞可视化/动态可视化
官网测试用例:examples/python/visualization/non_blocking_visualization.py 非阻塞可视化,即实时更新点云数据; 如下,动态可视化ICP的匹配过程: import open3d as o3d import numpy as npif __name__ == "__main__":o3d.utility.set_verbosity_level(o3d.ut…...

C++面试题其一
C和C的区别 C和C都是广泛使用的编程语言,但它们有显著的区别: 语言范式: C:是一种过程化编程语言,强调过程和函数的使用。C:是一种多范式编程语言,支持面向对象编程、泛型编程和过程化编程。 …...
CentOS7某天的samba服务搭建操作记录(还没成功)
#CentOS7 yum软件仓库阿里云 samba服务器配置失败 sensors成功了 (花了200元组装H61测试机,75元的主板只有一块能用,垃圾板但又不完全能用) 2024.5月的某天记录如下: https://blog.csdn.net/dszgf5717/article/details/53732182 …...
Qt Demo:基于TCP协议的视频传输Demo
目录 1.设计思路 2.Pro文件配置 3.头文件引入 4.界面设计 5.初始化设备函数 6.发起视频链接函数 7.初始化定时器模块函数 8.TCP链接模块函数 9.处理接收的数据线程函数 10.实现功能展示 设计思路 基于TCP协议的视频传输Demo,设计要实现的功能主要是TCP传输还有视频&…...

内存管理【C++】
内存分布 C中的内存区域主要有以下5种 栈(堆栈):存放非静态局部变量/函数参数/函数返回值等等,栈是向下增长的【地址越高越先被使用】。栈区内存的开辟和销毁由系统自动执行 堆:用于程序运行时动态内存分配ÿ…...

D3D 顶点格式学习
之前D3D画三角形的代码中有这一句, device.VertexFormat CustomVertex.TransformedColored.Format; 这是设置顶点格式; 画出的三角形如下, 顶点格式是描述一个三维模型的顶点信息的格式;可以包含以下内容, 位置…...
gmssl vs2010编译
1、虚拟机win10 x64,离线安装vs2010和2010sp1补丁; 2、安装ActivePerl_v5.28.1.0000和nasm-2.16.03-installer-x64均是默认完整安装; nasm官网下载: Index of /pub/nasm/releasebuilds/2.16.03/win64https://www.nasm.us/pub/nas…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...
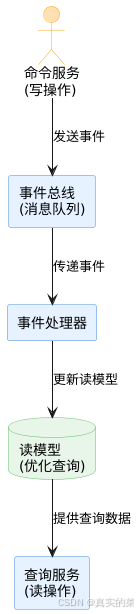
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...