stack和queue(1)
一、stack的简单介绍和使用
1.1 stack的介绍
1.stack是一种容器适配器,专门用在具有先进后出,后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入和弹出操作。
2.stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器尾部(即栈顶)被压入和弹出。
3.stack的底层容器可以是任何标准的容器类模板或者一些其他待定的容器类,这些容器类需要支持以下的一些操作:
- empty :判空操作
- back:获取尾部元素
- push_back:尾部插入元素
- pop_back:尾部删除元素
4.标准容器vector、deque、list等均符合这些需求,默认情况下没有为stack指定特定的底层容器时,默认情况下就使用deque。
1.2 stack的使用
下面是stack的接口函数及其功能介绍:
| 函数说明 | 接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中的元素的个数 |
| top() | 返回栈顶元素的作用 |
| push() | 将元素val压入到stack中 |
| pop() | 将stack中栈顶元素弹出 |
下面我们来看下stack在一些问题中的使用:
我们先来看几道算法设计题:
leetcode155,最小栈
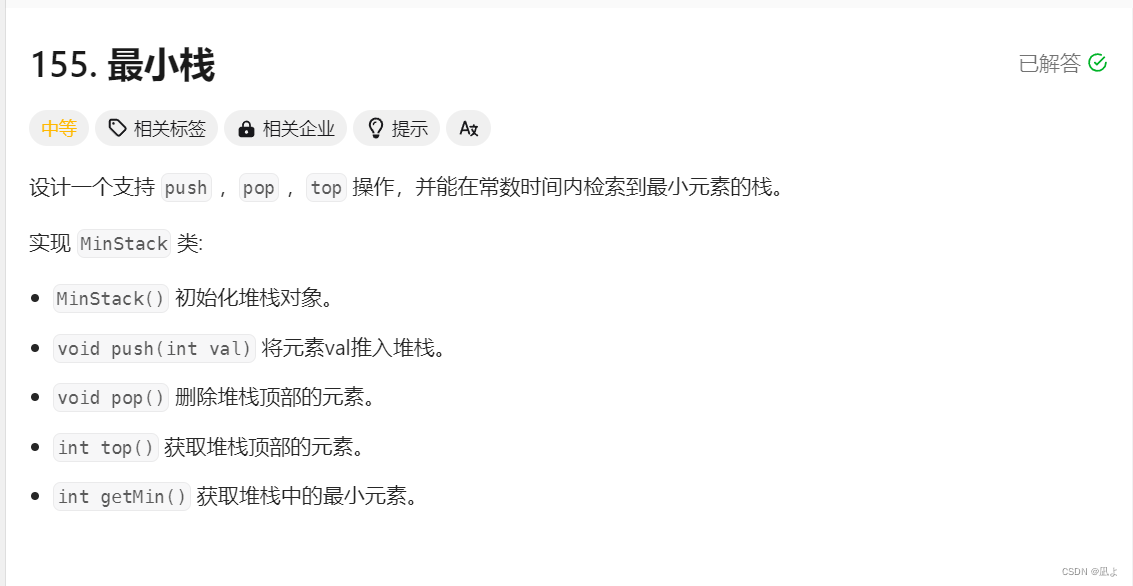
对于这个题目我们可以使用两个stack来实现这个最小栈,首先给一个主体栈s和一个辅助栈min_s
里面存储最小值,当我们的元素入栈时如果辅助栈是空的或者val的值小于min_s的栈顶元素就将val入栈。出栈时如果我们主体栈的栈顶元素和我们的辅助栈的栈顶元素相等的话辅助栈的栈顶元素也出栈。取栈顶元素top()就直接返回s.top()即可,取最小值时就直接返回min_s.top()即可。
下面是参考代码:
class MinStack {
public:MinStack() {}void push(int val) {//将val压入主体栈中s.push(val);//如果最小栈为空或者val小于最小栈的栈顶元素就将val也压入进最小栈中if(min_s.empty() || val <= min_s.top()){min_s.push(val);}}void pop() {//出栈时如果主体栈的栈顶元素和最小栈的栈顶元素相同时最小栈也将栈顶元素弹出if(s.top() == min_s.top()){min_s.pop();}s.pop();}//返回主体栈的top即可int top() {return s.top();}//返回最小栈的栈顶元素即可int getMin() {return min_s.top();}
private://定义一个主体栈和一个存放最小值的栈stack<int> s;stack<int> min_s;
};/*** Your MinStack object will be instantiated and called as such:* MinStack* obj = new MinStack();* obj->push(val);* obj->pop();* int param_3 = obj->top();* int param_4 = obj->getMin();*/牛客网JZ31,栈的压入弹出序列
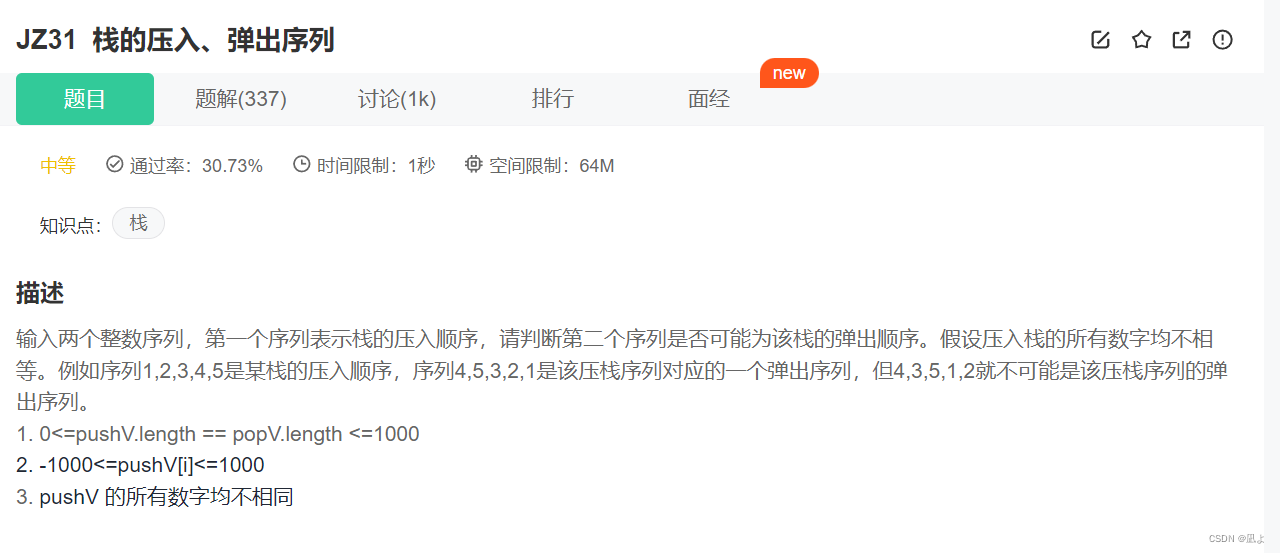
对于这一题就是一个进栈出栈的一个过程模拟,我们先定义出一个栈然后定义一个维护出栈序列的下标,最后我们将进栈序列中的元素进栈,如果栈不为空并且栈顶元素和出栈元素相同就将栈顶元素出栈,然后将指向出栈序列的popi向后走一步。出循环后如果栈为空就是匹配返回true,如果栈不为空就返回false。
下面是参考代码:
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code here//定义一个栈,模拟进栈过程stack<int> s;//定义一个出栈下标,维护出栈序列int popi = 0;//进栈for(auto e : pushV){s.push(e);//如果栈不为空并且出栈队列对应值等于栈顶元素就将栈顶元素弹出,然后将出栈序列向后走一步while(!s.empty() && popV[popi] == s.top()){s.pop();popi++;}}//如果栈为空则匹配否则不匹配return s.empty();}
};通过这两到例题我们应该也就了解了stack的使用,下面我们来看下queue的用法。
二、queue的简单介绍和使用
2.1 queue的介绍
1.queue也就是队列,也是一种容器适配器,专门用于先进先出的上下文操作中,从容器一端进数据,另一端出数据。
2.queue作为容器适配器实现,容器适配器就是将特定的容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素,元素从队尾入队列,从队头出队列。
3.底层容器可以是标准容器类模版之一,也可以是其他专门设计的容器类。queue的底层容器至少需要支持一下操作:
- empty:判断队列是否为空
- size:返回队列中有效元素中的个数
- front:返回队头元素的引用
- back:返回队尾元素的引用
- push_back:在队列尾部入队列
- pop_back:在队列头部出队列
4. 标准容器类deque和list符合这些要求,默认情况下,如果没有为queue实例化指定容器类,则默认使用deque。
2.2 queue的使用
下面是queue的接口函数以及它的接口功能:
| 接口函数 | 接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空,为空就放回true,否则返回false |
| size() | 返回队列中的有效元素个数 |
| front | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 将元素进队列 |
| pop() | 将元素出队列 |
下面我们通过一个题目来了解一下queue的使用:
leetcode102,二叉树的层序遍历
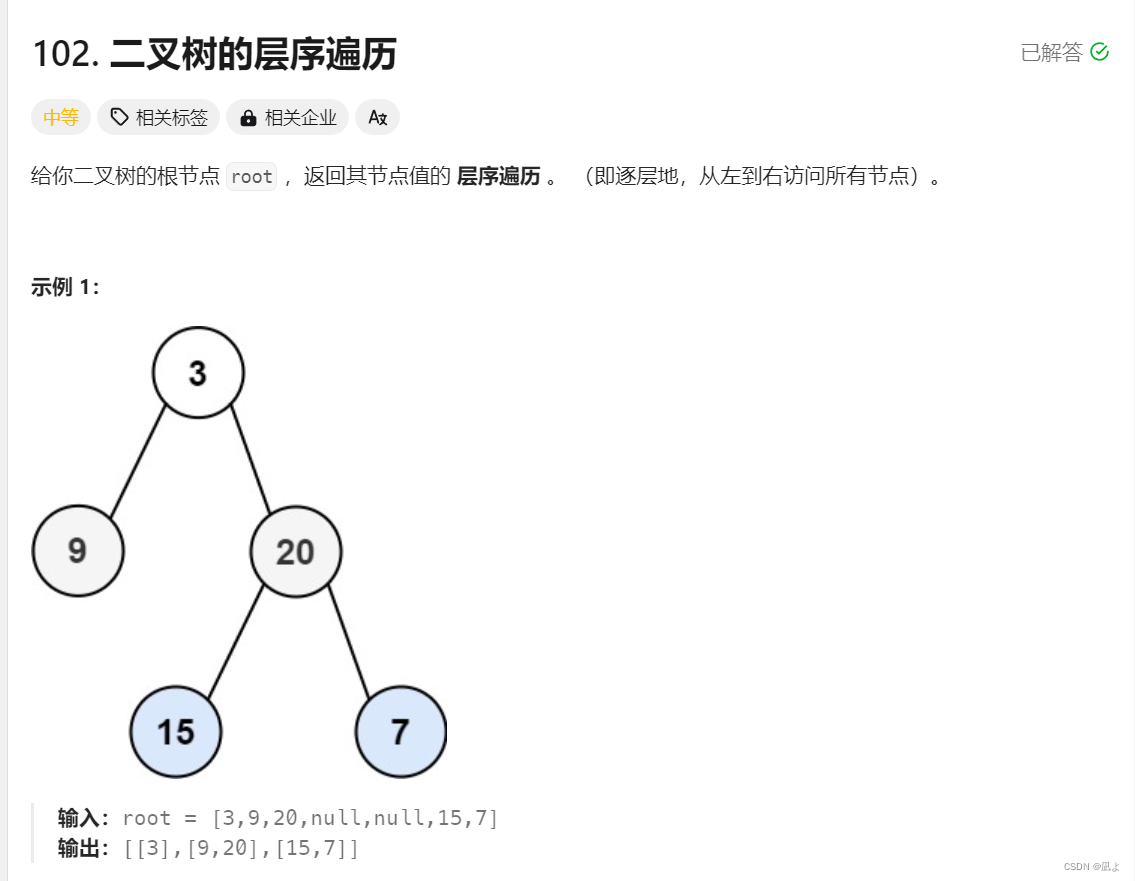
对于这一题我们可以借助队列queue来解决,我们先定义一个二维数组来存放返回值,然后定义一个queue辅助遍历,定义一个level_size来存放没层的节点,然后先将头结点入队,如果队列不为空就进行外层循环,内层循环负责将遍历到的值放进管理这一层节点的数组v中,然后再将下一层的节点带入,出内层循环后更新level_size和ret数组,即将level_size更新为目前队列中的元素个数,将该层的节点数组v,尾插到ret数组中,最后返回ret数组即可。
参考代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left),* right(right) {}* };*/
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {// 定义一个二维数组作为返回数组vector<vector<int>> ret;// 如果二叉树是空树就直接返回空数组if (root == nullptr) {return ret;}// 定义一个辅助队列queue<TreeNode*> q;// 将root入栈q.push(root);// 记录每层的节点数int level_size = 1;//队列不为空就进行循环while (!q.empty()) {//定义一个数组记录每层的节点vector<int> v;//遍历这一层的节点并将下一层的节点带入while (level_size--) {TreeNode* front = q.front();v.push_back(front->val);q.pop();if (front->left) {q.push(front->left);}if (front->right) {q.push(front->right);}}//更新层节点个数level_size = q.size();//将这一层的节点放到返回数组中去ret.push_back(v);}//出循环后返回最终结果return ret;}
};关于stack和queue的使用这篇博客就讲到这里,大家可以自行通过一些算法题去练习一下,也建议能够对博客里的例题能够理解后去自己实现一下。
相关文章:
stack和queue(1)
一、stack的简单介绍和使用 1.1 stack的介绍 1.stack是一种容器适配器,专门用在具有先进后出,后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入和弹出操作。 2.stack是作为容器适配器被实现的,容器适配器即是…...

前端3剑客(第1篇)-初识HTML
100编程书屋_孔夫子旧书网 当今主流的技术中,可以分为前端和后端两个门类。 前端:简单的理解就是和用户打交道 后端:主要用于组织数据 而前端就Web开发方向来说, 分为三门语言, HTML、CSS、JavaScript 语言作用HT…...
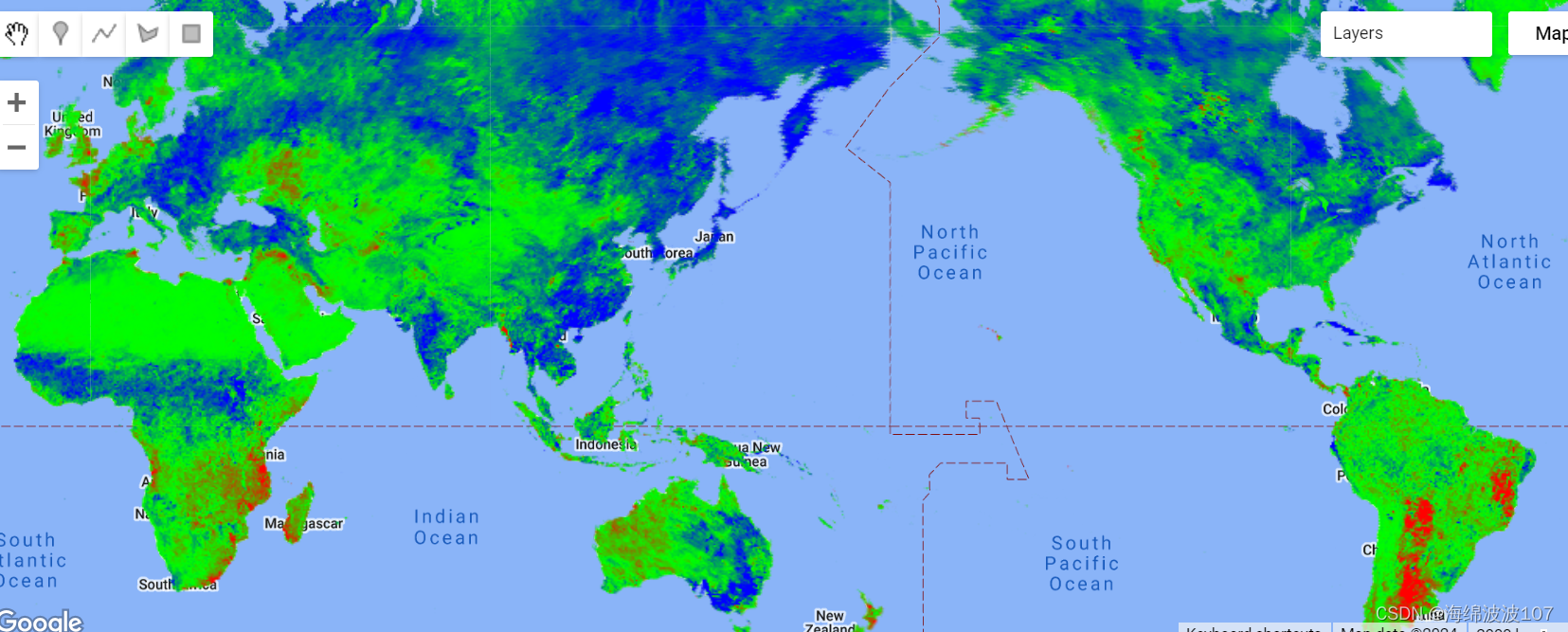
植被变化趋势线性回归以及可视化
目录 植被变化线性回归ee.Reducer.linearFit().reduce()案例:天水市2004-2023年EVI线性回归趋势在该图中,使用了从红色到蓝色的渐变来表示负趋势到正趋势。红色代表在某段时间中,植被覆盖减少,绿色表示持平,蓝色表示植被覆盖增加。 植被变化线性回归 该部分参考Google…...
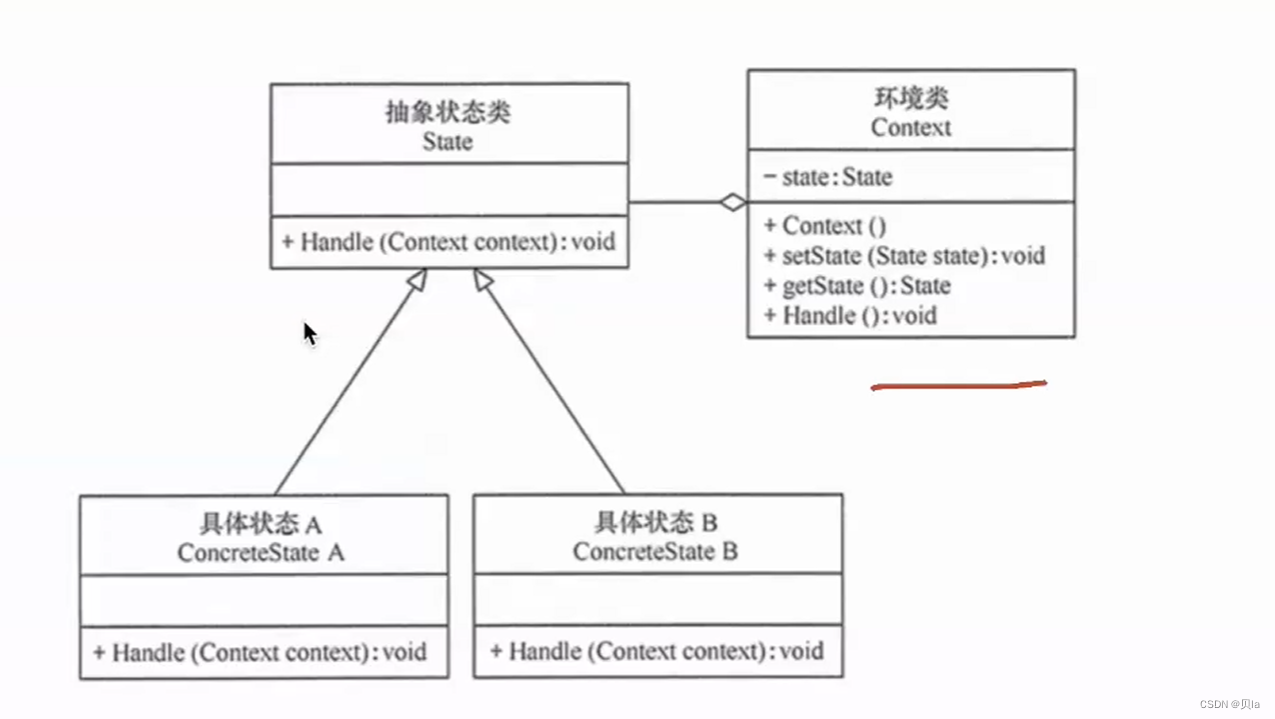
大话设计模式学习笔记
目录 工厂模式策略模式备忘录模式(快照模式)代理模式单例模式迭代器模式访问者模式观察者模式解释器模式命令模式模板方法模式桥接模式适配器模式外观模式享元模式原型模式责任链模式中介者模式装饰模式状态模式 工厂模式 策略模式 核心:封装…...

MiniMax公司介绍
MiniMax是一家专注于通用人工智能技术的科技公司,成立于2021年12月。公司致力于成为通用人工智能时代基础设施建设者和内容应用创造者,积极投身于中国人工智能技术高速发展的时代大潮。MiniMax的团队由多位在人工智能领域有着丰富经验的专家组成…...

lucene 9.10向量检索基本用法
Lucene 9.10 中的 KnnFloatVectorQuery 是用来执行最近邻(k-Nearest Neighbors,kNN)搜索的查询类,它可以在一个字段中搜索与目标向量最相似的k个向量。以下是 KnnFloatVectorQuery 的基本用法和代码示例。 1. 索引向量字段 首先…...

【2023百度之星初赛】跑步,夏日漫步,糖果促销,第五维度,公园,新材料,星际航行,蛋糕划分
目录 题目:跑步 思路: 题目:夏日漫步 思路: 题目:糖果促销 思路: 题目:第五维度 思路: 题目:公园 思路: 新材料 思路: 星际航行 思路…...
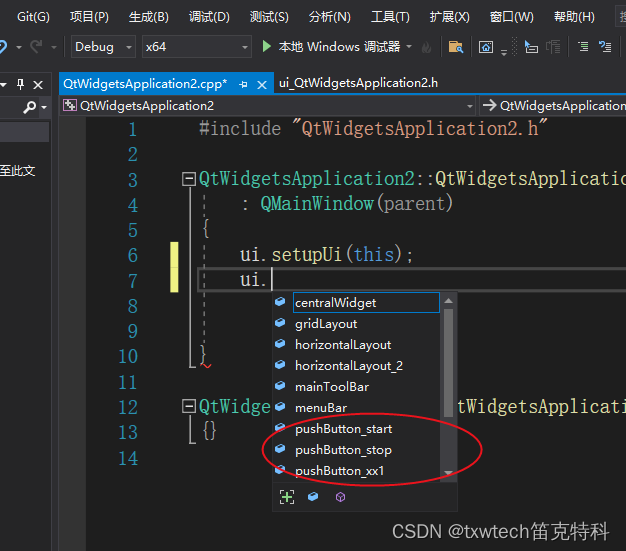
vs2019 QT UI 添加新成员或者控件代码不提示问题解决方法
右键点击头文件,添加ui的头文件 添加现有项 找到uic目录的头文件 打开ui,QtWidgetsApplication2.ui,进行测试 修改一个名字: 重点: 设置一个布局: 点击生成解决方案: 以后每次添加控件后,记得点击保存 这样…...

【面试八股总结】MySQL事务:事务特性、事务并行、事务的隔离级别
参考资料:小林coding 一、事务的特性ACID 原子性(Atomicity) 一个事务是一个不可分割的工作单位,事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。原子性是通过 undo …...

STL用法总结
文章目录 vector构造常用函数遍历适用情形注意事项使用迭代器删除可能会出现的错误 Set & MultiSet(不能用sort,会自动排序)构造常用函数删除,查找遍历 unordered_set(不排序集合),unordered_multiset Map & M…...
他人项目二次开发——慎接
接了一个朋友的项目——开发及运营迭代差不多2年多了,整体样子移动端和PC都能正常使用,但后期的扩展性及新功能添加出现瓶颈。 因此给了一部分钱,让我接手来开发——重构架构。 背景说明 朋友公司的技术人员是我帮忙招聘的,相关技…...

k8s之PV、PVC
文章目录 k8s之PV、PVC一、存储卷1、存储卷定义2、存储卷的作用2.1 数据持久化2.2 数据共享2.3 解耦2.4 灵活性 3、存储卷的分类3.1 emptyDir存储卷3.1.1 定义3.1.2 特点3.1.3 用途3.1.4 示例 3.2 hostPath存储卷3.2.1 定义3.2.2 特点3.2.3 用途3.2.4 示例 3.3 NFS存储卷3.3.1 …...
)
新人学习笔记之(JavaScript作用域)
一、作用域 1.通常来说,一段程序代码中所用的名字并不总是有效和可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域。作用域的使用提高了程序逻辑的局部性,增强了程序的可靠性,减少了名字冲突 二、变量的作用域 1.变…...

图论第一天
在单位摸鱼,地铁上看了个开始,图论开了个头,后面也希望能往这个方向上转,努努力吧。 一周没做题啦,后面坚持继续做题+二刷,接着记录每一天!!!加油࿰…...

革新风暴来袭:报事报修系统小程序如何重塑报事报修体验?
随着数字化、智能化的发展,已经应用在我们日常生活和工作的方方面面。那么,你还在为物业报修而头疼吗?想象一下,家里的水管突然爆裂,你急忙联系物业,时常面临物业电话忙音、接听后才进行登记繁琐的报修单、…...

linux各个日志的含义 以及使用方法
在Linux系统上,系统日志文件通常存储在/var/log/目录下。可以通过查看这些日志文件来了解系统的操作记录、错误信息和其他相关信息。以下是一些常见的系统日志文件以及它们包含的信息: /var/log/messages:这是一个常见的系统日志文件…...

详解 Spark 核心编程之 RDD 持久化
一、问题引出 /** 案例:对同一份数据文件分别做 WordCount 聚合操作和 Word 分组操作 期望:针对数据文件只进行一次分词、转换操作得到 RDD 对象,然后再对该对象分别进行聚合和分组,实现数据重用 */ object TestRDDPersist {def …...
创新融合,5G+工业操作系统引领未来工厂
为加速企业完成生产制造自动化和经营管理自动化,从而走向未来工厂,蓝卓不断探索supOS工业操作系统与前沿技术的的创新融合,而5G技术为工业操作系统提供了更多元化的赋能手段和想象空间。目前,supOS围绕生产、安全、质检、监控等领…...
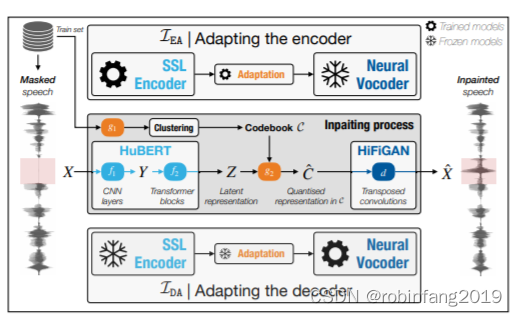
自监督表示学习和神经音频合成实现语音修复
关键词:语音修复、自监督模型、语音合成、语音增强、神经声码器 语音和/或音频修复的目标是增强局部受损的语音和/或音频信号。早期的工作基于信号处理技术,例如线性预测编码、正弦波建模或图模型。最近,语音/音频修复开始使用深度神经网络&a…...
【论文复现|智能算法改进】融合黑寡妇思想的蜣螂优化算法
目录 1.算法原理2.改进点3.结果展示4.参考文献5.代码获取 1.算法原理 【智能算法】蜣螂优化算法(DBO)原理及实现 2.改进点 ICMIC混沌映射 z n 1 sin ( α z n ) , α ∈ ( 0 , ∞ ) (1) z_{n1}\sin(\frac{\alpha}{z_n}),\alpha\in(0,\infty)\ta…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...