7个Python爬虫入门小案例
大家好,随着互联网的快速发展,数据成为了新时代的石油。Python作为一种高效、易学的编程语言,在数据采集领域有着广泛的应用。本文将详细讲解Python爬虫的原理、常用库以及实战案例,帮助读者掌握爬虫技能。
一、爬虫原理
爬虫,又称网络爬虫,是一种自动获取网页内容的程序。它模拟人类浏览网页的行为,发送HTTP请求,获取网页源代码,再通过解析、提取等技术手段,获取所需数据。
1. HTTP请求与响应过程
爬虫首先向目标网站发送HTTP请求,请求可以包含多种参数,如URL、请求方法(GET或POST)、请求头(Headers)等。服务器接收到请求后,返回相应的HTTP响应,包括状态码、响应头和响应体(网页内容)。
2. 常用爬虫技术
请求库:如requests、aiohttp等,用于发送HTTP请求。
解析库:如BeautifulSoup、lxml、PyQuery等,用于解析网页内容。
存储库:如pandas、SQLite等,用于存储爬取到的数据。
异步库:如asyncio、aiohttp等,用于实现异步爬虫,提高爬取效率。
二、Python爬虫常用库
1. 请求库
requests:简洁、强大的HTTP库,支持HTTP连接保持和连接池,支持SSL证书验证、Cookies等。
aiohttp:基于asyncio的异步HTTP网络库,适用于需要高并发的爬虫场景。
2. 解析库
BeautifulSoup:一个HTML和XML的解析库,简单易用,支持多种解析器。
lxml:一个高效的XML和HTML解析库,支持XPath和CSS选择器。
PyQuery:一个Python版的jQuery,语法与jQuery类似,易于上手。
3. 存储库
pandas:一个强大的数据分析库,提供数据结构和数据分析工具,支持多种文件格式。
SQLite:一个轻量级的数据库,支持SQL查询,适用于小型爬虫项目。
三、7个Python爬虫小案例
接下来将分享7个Python爬虫的小案例,帮助大家更好地学习和了解Python爬虫的基础知识。
1. 爬取豆瓣电影Top250
使用BeautifulSoup库爬取豆瓣电影Top250的电影名称、评分和评价人数等信息,并将这些信息保存到CSV文件中。
import requests
from bs4 import BeautifulSoup
import csv# 请求URL
url = '<https://movie.douban.com/top250>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):soup = BeautifulSoup(html, 'lxml')movie_list = soup.find('ol', class_='grid_view').find_all('li')for movie in movie_list:title = movie.find('div', class_='hd').find('span', class_='title').get_text()rating_num = movie.find('div', class_='star').find('span', class_='rating_num').get_text()comment_num = movie.find('div', class_='star').find_all('span')[-1].get_text()writer.writerow([title, rating_num, comment_num])# 保存数据函数
def save_data():f = open('douban_movie_top250.csv', 'a', newline='', encoding='utf-8-sig')global writerwriter = csv.writer(f)writer.writerow(['电影名称', '评分', '评价人数'])for i in range(10):url = '<https://movie.douban.com/top250?start=>' + str(i*25) + '&filter='response = requests.get(url, headers=headers)parse_html(response.text)f.close()if __name__ == '__main__':save_data()2. 爬取猫眼电影Top100
使用正则表达式和requests库爬取猫眼电影Top100的电影名称、主演和上映时间等信息,并将这些信息保存到TXT文件中。
import requests
import re# 请求URL
url = '<https://maoyan.com/board/4>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):pattern = re.compile('<p class="name"><a href=".*?" title="(.*?)" data-act="boarditem-click" data-val="{movieId:\\\\d+}">(.*?)</a></p>.*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', re.S)items = re.findall(pattern, html)for item in items:yield {'电影名称': item[1],'主演': item[2].strip(),'上映时间': item[3]}# 保存数据函数
def save_data():f = open('maoyan_top100.txt', 'w', encoding='utf-8')for i in range(10):url = '<https://maoyan.com/board/4?offset=>' + str(i*10)response = requests.get(url, headers=headers)for item in parse_html(response.text):f.write(str(item) + '\\\\n')f.close()if __name__ == '__main__':save_data()
3. 爬取全国高校名单
使用正则表达式和requests库爬取全国高校名单,并将这些信息保存到TXT文件中。
import requests
import re# 请求URL
url = '<http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):pattern = re.compile('<tr class="alt">.*?<td>(.*?)</td>.*?<td><div align="left">.*?<a href="(.*?)" target="_blank">(.*?)</a></div></td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S)items = re.findall(pattern, html)for item in items:yield {'排名': item[0],'学校名称': item[2],'省市': item[3],'总分': item[4]}# 保存数据函数
def save_data():f = open('university_top100.txt', 'w', encoding='utf-8')response = requests.get(url, headers=headers)for item in parse_html(response.text):f.write(str(item) + '\\\\n')f.close()if __name__ == '__main__':save_data()4. 爬取中国天气网城市天气
使用xpath和requests库爬取中国天气网的城市天气,并将这些信息保存到CSV文件中。
import requests
from lxml import etree
import csv# 请求URL
url = '<http://www.weather.com.cn/weather1d/101010100.shtml>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):selector = etree.HTML(html)city = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/h1/text()')[0]temperature = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/i/text()')[0]weather = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/@title')[0]wind = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/span/text()')[0]return city, temperature, weather, wind# 保存数据函数
def save_data():f = open('beijing_weather.csv', 'w', newline='', encoding='utf-8-sig')writer = csv.writer(f)writer.writerow(['城市', '温度', '天气', '风力'])for i in range(10):response = requests.get(url, headers=headers)city, temperature, weather, wind = parse_html(response.text)writer.writerow([city, temperature, weather, wind])f.close()if __name__ == '__main__':save_data()5. 爬取当当网图书信息
使用xpath和requests库爬取当当网图书信息,并将这些信息保存到CSV文件中。
import requests
from lxml import etree
import csv# 请求URL
url = '<http://search.dangdang.com/?key=Python&act=input>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):selector = etree.HTML(html)book_list = selector.xpath('//*[@id="search_nature_rg"]/ul/li')for book in book_list:title = book.xpath('a/@title')[0]link = book.xpath('a/@href')[0]price = book.xpath('p[@class="price"]/span[@class="search_now_price"]/text()')[0]author = book.xpath('p[@class="search_book_author"]/span[1]/a/@title')[0]publish_date = book.xpath('p[@class="search_book_author"]/span[2]/text()')[0]publisher = book.xpath('p[@class="search_book_author"]/span[3]/a/@title')[0]yield {'书名': title,'链接': link,'价格': price,'作者': author,'出版日期': publish_date,'出版社': publisher}# 保存数据函数
def save_data():f = open('dangdang_books.csv', 'w', newline='', encoding='utf-8-sig')writer = csv.writer(f)writer.writerow(['书名', '链接', '价格', '作者', '出版日期', '出版社'])response = requests.get(url, headers=headers)for item in parse_html(response.text):writer.writerow(item.values())f.close()if __name__ == '__main__':save_data()6. 爬取百科段子
使用xpath和requests库爬取百科的段子,并将这些信息保存到TXT文件中。
import requests
from lxml import etree# 请求URL
url = '<https://www.qiushibaike.com/text/>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):selector = etree.HTML(html)content_list = selector.xpath('//div[@class="content"]/span/text()')for content in content_list:yield content# 保存数据函数
def save_data():f = open('qiushibaike_jokes.txt', 'w', encoding='utf-8')for i in range(3):url = '<https://www.qiushibaike.com/text/page/>' + str(i+1) + '/'response = requests.get(url, headers=headers)for content in parse_html(response.text):f.write(content + '\\\\n')f.close()if __name__ == '__main__':save_data()
7. 爬取新浪微博
使用selenium和requests库爬取新浪微博,并将这些信息保存到TXT文件中。
import time
from selenium import webdriver
import requests# 请求URL
url = '<https://weibo.com/>'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}# 解析页面函数
def parse_html(html):print(html)# 保存数据函数
def save_data():f = open('weibo.txt', 'w', encoding='utf-8')browser = webdriver.Chrome()browser.get(url)time.sleep(10)browser.find_element_by_name('username').send_keys('username')browser.find_element_by_name('password').send_keys('password')browser.find_element_by_class_name('W_btn_a').click()time.sleep(10)response = requests.get(url, headers=headers, cookies=browser.get_cookies())parse_html(response.text)browser.close()f.close()if __name__ == '__main__':save_data()爬虫技能在数据分析、自然语言处理等领域具有广泛的应用,大家可以通过动手实践,不断提高自己的技能水平。同时,请注意合法合规地进行爬虫,遵守相关法律法规。
相关文章:

7个Python爬虫入门小案例
大家好,随着互联网的快速发展,数据成为了新时代的石油。Python作为一种高效、易学的编程语言,在数据采集领域有着广泛的应用。本文将详细讲解Python爬虫的原理、常用库以及实战案例,帮助读者掌握爬虫技能。 一、爬虫原理 爬虫&a…...
 构造数字)
linux 利用 ~$() 构造数字
2024.6.1 题目 <?php //flag in 12.php error_reporting(0); if(isset($_GET[x])){$x $_GET[x];if(!preg_match("/[a-z0-9;|#\"%&\x09\x0a><.,?*\-\\[\]]/i", $x)){system("cat ".$x.".php");} }else{highlight_file(__F…...
七大获取免费https的方式
想要实现https访问最简单有效的的方法就是安装SSL证书。只要证书正常安装上以后,浏览器就不会出现网站不安全提示或者访问被拦截的情况。下面我来教大家怎么去获取免费的SSL证书,又如何安装证书实现https访问。 一、选择免费SSL证书提供商 有多家机构提…...

JVM(Java虚拟机)笔记
面试常见: 请你谈谈你对JVM的理解?java8虚拟机和之前的变化更新?什么是OOM,什么是栈溢出StackOverFlowError? 怎么分析?JVM的常用调优参数有哪些?内存快照如何抓取?怎么分析Dump文件?谈谈JVM中,类加载器你的认识…...

秒杀基本功能开发(显示商品列表和商品详情)
文章目录 1.数据库表设计1.商品表2.秒杀商品表3.修改一下秒杀时间为今天到明天 2.pojo和vo编写1.com/sxs/seckill/pojo/Goods.java2.com/sxs/seckill/pojo/SeckillGoods.java3.com/sxs/seckill/vo/GoodsVo.java 3.Mapper编写1.GoodsMapper.java2.GoodsMapper.xml3.分别编写Seck…...

centos 记录用户登陆ip和执行命令
centos 记录用户登陆ip和执行命令 在/etc/profile 文件末尾添加如下代码: #!/bin/bash USER_IPwho -u am i 2>/dev/null | awk {print $NF} | sed -e s/[()]//g HISTDIR/usr/share/.history if [ -z "$USER_IP" ]; then USER_IPhostname fi…...

JZ2440笔记:DM9000C网卡驱动
在厂家提供的dm9dev9000c.c上修改, 1、注释掉#ifdef MODULE #endif 2、用模块化函数修饰入口出口函数 3、在dm9000c_init入口函数,增加iobase (int)ioremap(0x20000000,1024);irq IRQ_EINT7; 4、一路进入,在dmfe_probe1中注释掉if((db…...
【数据结构】二叉树:简约和复杂的交织之美
专栏引入: 哈喽大家好,我是野生的编程萌新,首先感谢大家的观看。数据结构的学习者大多有这样的想法:数据结构很重要,一定要学好,但数据结构比较抽象,有些算法理解起来很困难,学的很累…...

信号稳定,性能卓越!德思特礁鲨系列MiMo天线正式发布!
作者介绍 礁鲨系列天线,以其独特的外观设计和强大的性能,成为德思特Panorama智能天线家族的最新成员。这款天线不仅稳定提供5G、WIFI和GNSS信号,更能在各类复杂环境中展现出卓越的性能。它的设计灵感来源于海洋中的礁鲨,象征着力量…...

编程学习技巧——实战
目录 学习思路待续、更新中 学习思路 实战大小项目 翻阅官网手册——学习技术,调试问题 待续、更新中 1 顿号、: 先使用ctrl. ,再使用一遍切回 2 下标: 21 2~1~ 3 上标: 2 0 2^{0} 20 $2^{0}$ 4 竖线 | : | ; | 5 空格: &emsp ; 6 换行: &nbs…...

GPU学习(1)
一、为什么要GPU 我们先看一个基本的神经网络计算 YF(x)AxB 这就是一次乘法一次加法 ,也叫FMA,(fused multiply-add) 如果矩阵乘,就是上面的那个式子扩展一下,所以又用了这张老图 比如你要多执行好几个yAxB,可能比较简…...
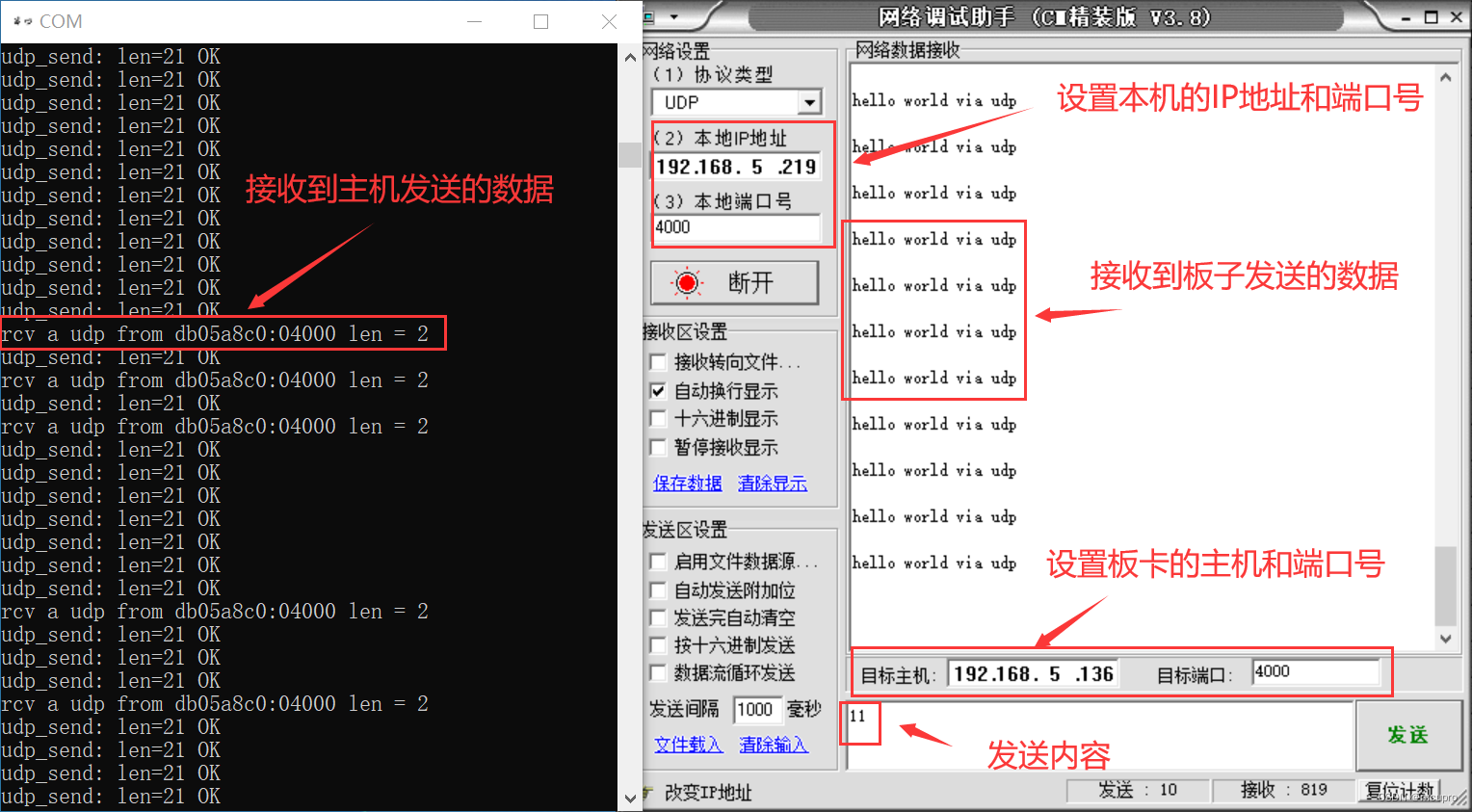
TQSDRPI开发板教程:UDP收发测试
项目资源分享 链接:https://pan.baidu.com/s/1gWNSA9czrGwUYJXdeuOwgQ 提取码:tfo0 LWIP自环教程:https://blog.csdn.net/mcupro/article/details/139350727?spm1001.2014.3001.5501 在lwip自环的基础上修改代码实现UDP的收发测试。新建一…...
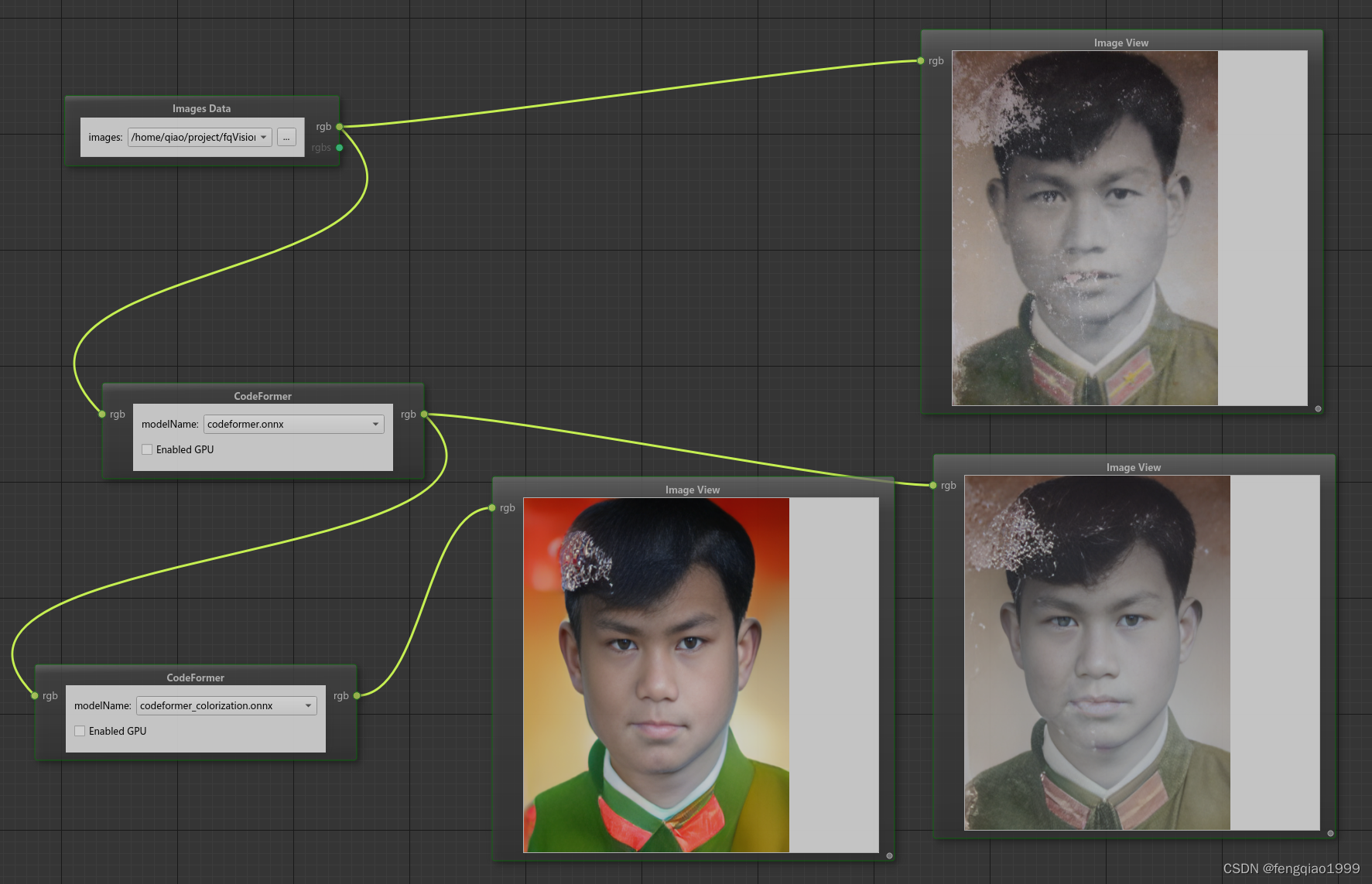
opencv进阶 ——(九)图像处理之人脸修复祛马赛克算法CodeFormer
算法简介 CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.com/sczhou/CodeFormer…...
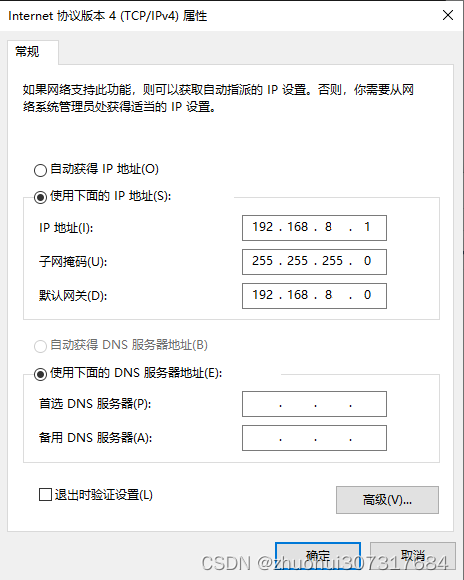
虚拟机改IP地址
使用场景:当你从另一台电脑复制一个VMware虚拟机过来,就是遇到一个问题,虚拟的IP地址不一样(比如,一个是192.168.1.3,另一个是192.168.2.4,由于‘1’和‘2’不同,不是同一网段&#…...
MySQL(二)-基础操作
一、约束 有时候,数据库中数据是有约束的,比如 性别列,你不能填一些奇奇怪怪的数据~ 如果靠人为的来对数据进行检索约束的话,肯定是不行的,人肯定会犯错~因此就需要让计算机对插入的数据进行约束要求! 约…...

vue3学习使用笔记
1.学习参考资料 vue3菜鸟教程:https://www.runoob.com/vue3/vue3-tutorial.html 官方网站:https://cn.vuejs.org/ 中文文档: https://cn.vuejs.org/guide/introduction.html Webpack 入门教程:https://www.runoob.com/w3cnote/webpack-tutor…...

微信小程序怎么进行页面传参
微信小程序页面传参的方式有多种,每种方式都有其特定的使用场景和优势。以下是几种常见的页面传参方式,以及它们的具体使用方法和示例: URL参数传值 原理:通过在跳转链接中附加参数,在目标页面的onLoad函数中获取参数…...

隆道出席河南ClO社区十周年庆典,助推采购和供应链数字化发展
5月26日,“河南ClO社区十周年庆典”活动在郑州举办,北京隆道网络科技有限公司总裁助理姚锐出席本次活动,并发表主题演讲《数字化采购与供应链:隆道的探索与实践》,分享隆道公司在采购和供应链数字化转型方面的研究成果…...
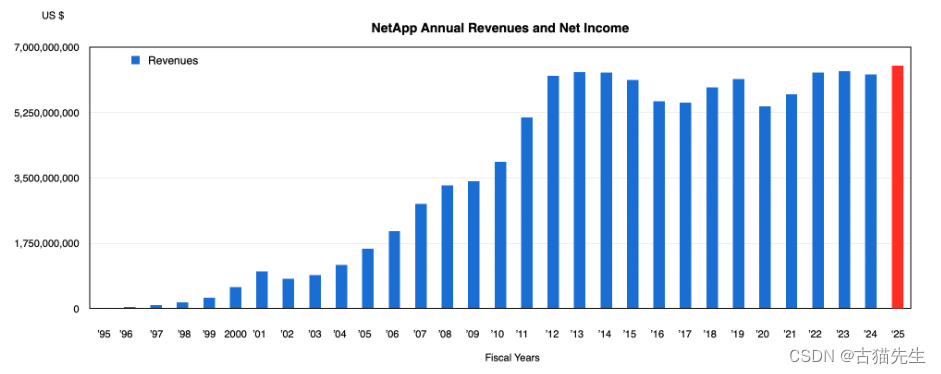
NetApp财季报告亮点:全闪存阵列需求强劲,云计算收入增长放缓但AI领域前景乐观
在最新的财季报告中,NetApp的收入因全闪存阵列的强劲需求而显著增长。截至2024年4月26日的2024财年第四季度,NetApp的收入连续第三个季度上升,达到了16.7亿美元,较前一年同期增长6%,超出公司指导中值。净利润为2.91亿美…...

javascript读取本地目录
在JavaScript中,直接读取本地目录的能力受到浏览器安全限制,因为出于隐私和安全考虑,浏览器的JavaScript环境通常不允许直接访问用户的文件系统。然而,随着Web技术的发展,一些现代浏览器引入了File System API或Web Fi…...

三进制计算机的物理约束与现代复兴路径
1. 三进制计算机的历史逻辑与工程现实当现代工程师在调试一块基于ARM Cortex-M4内核的MCU板卡时,示波器探头轻触GPIO引脚,屏幕上跳动的方波清晰呈现高电平(3.3V)、低电平(0V)两个稳定状态——这是数字电路最…...

TensorFlow-v2.9镜像性能优化:SSH远程操作卡顿解决方案
TensorFlow-v2.9镜像性能优化:SSH远程操作卡顿解决方案 1. 问题现象与初步分析 当你通过SSH连接到TensorFlow-v2.9镜像进行深度学习训练时,是否遇到过以下情况: 命令行响应延迟明显,按键后需要等待才能看到回显训练过程中系统整…...

RPA文件提取效率革命:unrpa工具全场景应用指南
RPA文件提取效率革命:unrpa工具全场景应用指南 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 在视觉小说爱好者和游戏开发者的日常工作中,RPA文件就像一个…...

Nunchaku FLUX.1-dev 构建智能Agent:集成文生图能力的多模态AI助手
Nunchaku FLUX.1-dev 构建智能Agent:集成文生图能力的多模态AI助手 1. 引言:从单一工具到会思考的伙伴 想象一下,你正在和一个AI助手讨论一个创意项目。你说:“我想设计一个未来城市的宣传海报,要有悬浮的交通工具和…...
)
SEO_详解SEO核心关键词研究与布局方法(86 )
SEO核心关键词研究的重要性在当今的互联网时代,搜索引擎优化(SEO)已经成为了网站提升流量和品牌知名度的重要手段之一。其中,核心关键词研究与布局是SEO的核心环节。无论你是一位新手还是资深的SEO专家,理解和掌握SEO核…...

python+Django+Vue.js小说推荐系统 小说可视化 小说爬虫 Django框架 大数据毕业设计
1、项目介绍 Django框架、双推荐算法(基于用户基于物品)、书架、评论收藏、小说阅读、MySQL数据库 、后台管理系统的推荐功能主要通过双推荐算法实现。基于用户的推荐算法根据用户的历史阅读行为和偏好,推荐与其相似的用户喜欢的小说。基于物…...

粒子群算法求解IEEE 33节点最优潮流模型
粒子群算法求解 IEEE 33bus最优潮流模型关键词:粒子群算法 PSO 最优潮流 牛顿迭代 仿真平台:MATLAB 主要内容:这是一个用粒子群来解IEEE 33的最优潮流模型,潮流模型是用牛顿迭代法写的 模型包含了柴油机,储能ÿ…...

Chandra OCR在文档处理中的应用:如何用RTX 3060搭建智能OCR系统
Chandra OCR在文档处理中的应用:如何用RTX 3060搭建智能OCR系统 1. 为什么选择Chandra OCR 在日常办公和数据处理中,我们经常遇到这样的困扰: 扫描的合同或发票需要手动录入关键信息纸质文档转电子版后格式错乱表格数据识别不完整…...

Android性能优化实战:用simpleperf和FlameGraph生成火焰图的全流程指南
Android性能优化实战:用simpleperf和FlameGraph生成火焰图的全流程指南 在移动应用开发中,性能优化始终是开发者面临的核心挑战之一。特别是对于Android平台,随着应用功能日益复杂,性能瓶颈的定位和分析变得尤为关键。火焰图作为一…...

DeepSeek-R1推理模型应用案例:智能客服与学习助手搭建
DeepSeek-R1推理模型应用案例:智能客服与学习助手搭建 1. 引言:AI驱动的智能交互新时代 在数字化转型浪潮中,企业客服与教育领域正面临前所未有的效率挑战。传统客服系统平均响应时间长达数小时,而教育机构则受限于师资力量难以…...