SIGIR22:User-controllable Recommendation Against Filter Bubbles
User-controllable Recommendation Against Filter Bubbles
摘要
推荐系统经常面临过滤气泡的问题:过度推荐基于用户特征以及历史交互的同质化项目。过滤气泡将会随着反馈循环增长,缩小了用户兴趣。现有的工作通常通过纳入诸如多样性和公平性等准确性之外的目标来减少过滤气泡。然而,这种方式会牺牲精确性,损害模型的保真度以及用户体验。甚至用户需要被动地接受推荐策略以及用一种很低效高延迟性的方式来影响系统。
本文提出了一种新的推荐原型,叫做“用户可控推荐系统”(User Controllable Recommender System, UCRS),该系统使得用户可以主动地控制对过滤气泡的减弱。UCRS的目标有以下几点:
- UCRS可以提醒那些深陷过滤气泡的用户,
- UCRS可以支持四种控制命令来帮助用户从不同的粒度上来减弱气泡效应,
- UCRS可以对控制进行响应,并且自由地调整推荐。
调整的关键在于阻塞推荐中过时用户响应的效应,包括与控制命令不一致的历史信息。例如,作者发展了一种因果增强的用户可控推理(User-Controllable Inference, UCI)狂降,可以快速地修正在推理阶段基于用户控制的推荐,使用反事实推理来减弱过时用户表示的效应。在三个数据集上的实验证明了UCI框架可以基于用户控制有效地推荐更多需要的项目,在精确性和多样性上展示出了卓越的效果。
1 简介
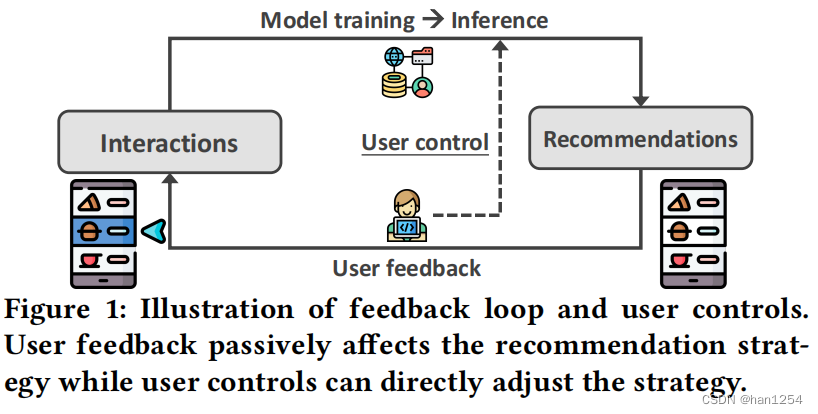
由于仅仅是拟合数据,推荐系统常常面临过滤气泡问题:持续推荐很多同质性的项目,将用户和多样化的内容隔离开。例如,如果用户点击了很多短视频,来学习制作咖啡,系统可能会持续向其推荐不同视频上传者投稿的相似短视频,占据了其他诸如热点新闻等信息丰富的视频。更糟糕的是,因为如图一的反馈循环,过滤气泡可能会逐渐地变得严重。从长远来看,过滤气泡将会减少用户的积极性以及项目的创造性,会损伤整个生态环境。因此,消除过滤气泡是很重要的。
为了实现这一目标,现有的研究提出纳入额外目标的历史交互数据拟合。例如(1)多样性[6]、[58],强制推荐列表覆盖尽可能多的项目类别;(2)公平性[3]、[30],追求在项目类别上的公平曝光机会;(3)标准化[39]、[48],保证了推荐列表在不同项目类别上的显示与用户的交互历史具有相同的分布。然而这些方法只是在不同目标间的权衡,牺牲了精确性甚至是用户体验。此外,在反馈循环中,用户只能通过用户反馈来被动地调整推荐,由于用户需要持续地提供反馈知道系统识别到用户需求,这种方式是低效并且不充分的。
作者认为,用户需要拥有权力来决定是否消除过滤气泡,并且选择减弱哪种气泡。最终,作者基于三个设想提出了UCRS:(1)系统有责任来提醒用户他们是否陷入了过滤气泡中;(2)系统应该提供多样的命令来充分支持用户的控制倾向;(3)系统应该快速地对控制进行响应。
过滤气泡警告
作者定义了一些标准来衡量过滤气泡的强度。这些标准,表现为系统提示,旨在让用户理解过滤气泡的状态,并且决定是否消除气泡。
控制命令
作者建议在用户特征以及项目特征两个层次上进行用户控制。在细粒度层次上,UCRS支持增加特定用户或者项目特征上的项目,例如“更多的被年轻人喜欢的项目”、“更多的某一类别的项目”。注意到用户可能并不会区分目标组别,UCRS也会支持粗粒度级别上的命令,例如“当涉及到我的年龄时,不要存在气泡”、“在项目类别上,不要存在气泡”。
对用户控制的响应
一旦接收到控制命令,UCRS通过将命令结合到推荐系统的推理中来调整推荐。但是这是有一定难度的,因为从历史交互中习得的一些过时用户表示已经将可能导致过滤气泡的偏好信息进行了编码。因此一些用户表示可能导致同质性推荐。
为了克服这些挑战,作者提出了一种因果强化的用户可控推理框架,从因果视角来审视推荐的产生过程,消除过时用户表示的影响。UCI框架设想出一个反事实世界,在这里的过时用户表示被去除,并且将过时表示的效应估计为真实世界以及反事实世界之间的差别。在减除该效应之后,UCI将控制指令结合进推荐系统的推理中。至于用户特征的控制,UCI使用指令中确定的用户特征(例如,将年龄从中年改成青少年)来在细粒度和粗粒度两个层面上产生最终的推理。而项目特征控制,考虑到项目分类,UCI采用了用户可控的排序策略来控制推荐。
2 前期准备
首先对过滤气泡进行直觉上的理解。
实验设置
作者在三个公开数据集(DIGIX-Video、Amazon-Book以及ML-1M)上训练了一个具有代表性的推荐模型FM[35],然后对每个用户选取top-10的推荐项目。然后为了研究过滤气泡的问题,作者根据用户特征以及用户交互这两个因子来将用户分成两个组别。可以通过例如性别和年龄来对用户进行分组。此外,用户经常对不同的项目类别(如:浪漫爱情电影)感兴趣,因此可以根据用户在项目类别上的交互来对用户进行分组。对于每个项目类别,选择那些交互比例比阈值高的用户。然后比较用户的历史交互以及以及FM生成的推荐。
分析
对于DIGIX-Video数据集上的男性和女性用户,作者可视化了他们在top-3项目类别的历史分布,总结在图二(a)中。从图中,可以观察到,男性和女性用户再项目类别上表现出不同的兴趣。例如,与女性相比,男性用户更加偏好动作电影而不是浪漫爱情电影。因此,推荐模型继承了这一偏差分布。如图二(b)和(c)所示,对于男性和女性用户的推荐分布很接近历史分布,表现出用户将会接收到同质化的推荐。更糟糕的是,模型倾向于放大偏差并且曝光出更多的历史多数类别,如图二(b)、(c)所示,这将造成男性和女性用户推荐之间的严重割裂。
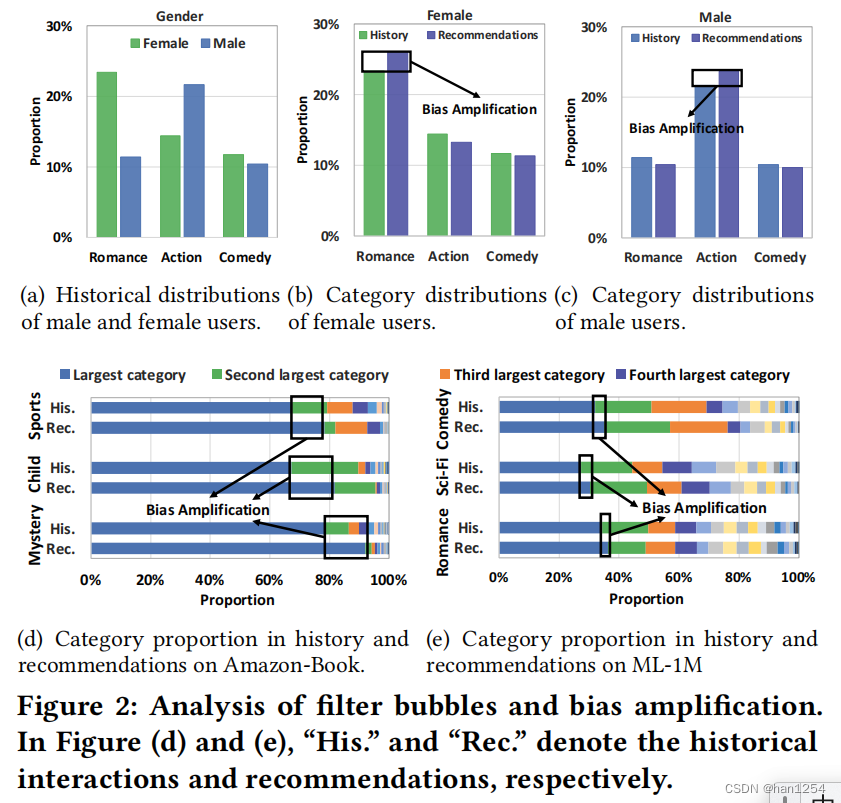
对于被用户交互区分的组别,图二(d)和(e)中作者分别展示了在Amazon-Book和ML-1M上的结果。从图中有以下发现:(1)最大的用户历史交互类别在推荐列表中占据主导地位。此外,与Amazon-Book相比,ML-1M上的分布更加多样化,这是因为在ML-1M中的大部分项目都有多个类别;(2)模型经常会产生偏差放大问题,并且增加推荐多数类别的占比。由于偏差放大,过滤气泡将会逐渐地增强,并且势必会限制了用户的喜好、隔离用户,并且导致组别的分割。
总结
作者发现,过滤气泡存在于用户以及项目特征一侧。涉及到项目特征的气泡是由在项目类别上的偏差交互导致的。作者提出了响应的用户特征控制以及项目特征控制。
3 用户可控推荐
3.1 UCRS的形式化
3.1.1 用户可控推荐系统
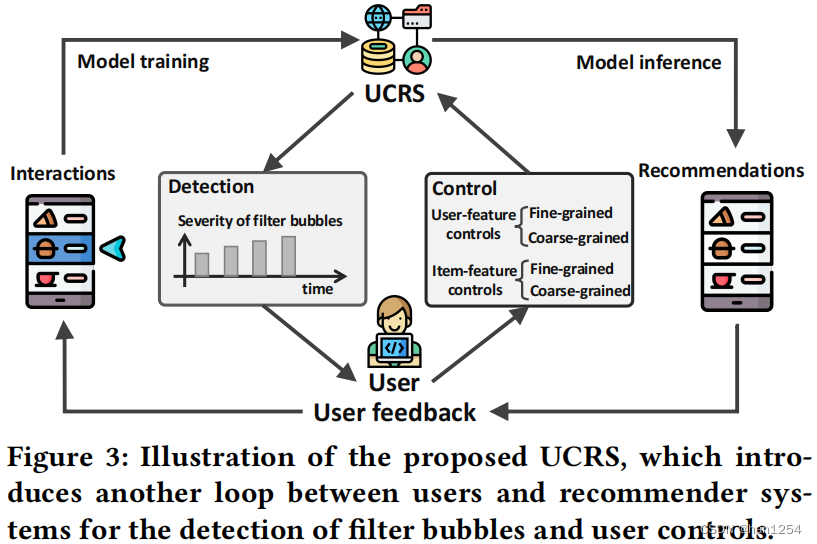
由图三所示,UCRS将“检测”和“控制”模块结合起来,将用户以及推荐系统之间的另一个循环引入。首先,检测模块被用来测量随时间加剧的过滤气泡的严重性,并且警告用户是否陷入过滤气泡中。如果用户想要消除过滤气泡,他们可以使用控制命令并且通过控制模块实时施加调整。
严格来讲,给定用户的历史交互DDD,传统的推荐系统模型旨在通过P(R∣D)P(R|D)P(R∣D)来预测推荐RRR。相反,UCRSUCRSUCRS额外地考虑到用户控制CCC以及在用户干预do(C)do(C)do(C)下估计P(R∣D,do(C))P(R|D,do(C))P(R∣D,do(C)),从因果的角度将干预形式化为四种控制。通过干预,用户可以快速地调整推荐,明显地降低历史主要类别中的项目,自由地跳出过滤气泡。作者基于用户以及项目特征,在细粒度和粗粒度的层次上将用户控制形式化为四种。
3.1.2 用户特征控制
将用户uuu的NNN个特征表示为xu=[xu1,⋯,xun,⋯,xuN]x_u=[x_u^1,\cdots, x_u^n,\cdots,x_u^N]xu=[xu1,⋯,xun,⋯,xuN],这里的xun∈{0,1}x_u^n\in \{0,1\}xun∈{0,1}表示用户uuu含有特征xnx^nxn。
细粒度用户特征控制
为了消除用户特征过滤气泡(例如,性别和年龄),作者设计了细粒度的用户特征控制,保证了UCRS推荐更多被其他用户组喜欢的项目。例如,三十岁中年用户可能对青少年喜欢的电影感兴趣。形式化地讲,为了计算用户uuu的P(R∣D,do(C))P(R|D,do(C))P(R∣D,do(C)),将控制形式化为do(C=cu(+x^,α))do(C=c_u(+\hat{x},\alpha))do(C=cu(+x^,α)),这里的cu(+x^,α)c_u(+\hat{x},\alpha)cu(+x^,α)是暴露更多被其他用户组x^\hat{x}x^喜欢项目的控制命令,cu(+x^,α)c_u(+\hat{x},\alpha)cu(+x^,α)需要用户uuu没有特征x^\hat{x}x^,即x^u=0\hat{x}_u=0x^u=0。此外,α∈[0,1]\alpha\in [0,1]α∈[0,1]是调整用户控制强度的系数。
粗粒度用户特征控制
用户可能简单地想要消除过滤气泡,并不喜欢其他用户组喜欢的项目。并且,一些用户可能并不知道哪个用户组更加具有吸引力。因此,作者提出了粗粒度用户特征控制,帮助用户跳出自己组别的过滤气泡。例如,中年用户可能并不希望推荐被严格限制在“年龄=30”上。在P(R∣D,do(C))P(R|D,do(C))P(R∣D,do(C))中的控制do(C)do(C)do(C)形式化为do(C=cu(−x‾,α))do(C=c_u(-\overline{x},\alpha))do(C=cu(−x,α)),这将会减少用户自己组别喜欢的项目x‾\overline{x}x,即x‾u=1\overline{x}_u=1xu=1。
3.1.3 项目特征控制
虽然用户特征控制可以削弱在用户特征上的过滤气泡,但是却忽略了由用户交互造成的过滤气泡。如图二(d)所示,推荐模型常常曝光历史多数类别。因此,为了补充用户特征控制,作者设计了项目特征控制来调整推荐。与用户特征类似,设项目iii的MMM个特征表示为hi=[hi1,⋯,him,⋯,hiM]h_i=[h_i^1,\cdots, h_i^m,\cdots, h_i^M]hi=[hi1,⋯,him,⋯,hiM],这里的him∈{0,1}h_i^m\in \{0, 1\}him∈{0,1}表示为项目iii拥有特征hmh^mhm。
细粒度项目特征控制
如果用户有目标项目类别(例如,更多浪漫电影),细粒度项目特征控制可以用来增加对它们的推荐。干预do(C)do(C)do(C)可以被表示为do(C=ci(+h^,β))do(C=c_i(+\hat{h},\beta))do(C=ci(+h^,β)),这里的h^\hat{h}h^是目标项目类别,β∈[0,1]\beta\in [0,1]β∈[0,1]是用来修改用户控制的强度。
粗粒度项目特征控制
相应的,作者提出粗粒度项目特征控制来减轻用户指定目标项目类别的负担。粗粒度项目特征控制的目标是减少用户历史交互中最大项目类别的推荐。干预可以表示为do(C=ci(−h‾,β))do(C=c_i(-\overline{h},\beta))do(C=ci(−h,β))。
3.2 UCRS的实现
3.2.1 过滤气泡监测
作者提出了一些度量方法来从不同的角度衡量过滤气泡的严重性,例如多样性以及隔离状态。在不同时间段,可以通过推荐系统设计的启发式规则来计算度量并且获得过滤气泡的严重性程度。然后,严重程度被展示给用户并且让用户决定是否控制过滤气泡。
覆盖性
过滤气泡经常减少推荐项目的多样性,因此可以结合广泛使用的多样性衡量方式:覆盖性(coverage),这种衡量计算推荐列表中的项目类别的数量。
隔离指标
除了基于多样性衡量的方式外,作者还提出了隔离指标(Isolation Index)[20]来衡量不同用户组别之间的隔离。给定两个用户组aaa和bbb,可以对推荐的隔离指标进行如下计算:
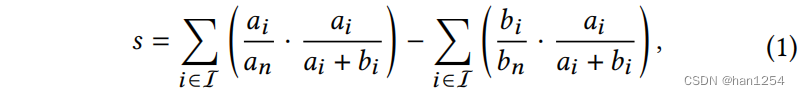
这里的I\mathcal{I}I是项目集合,aia_iai以及bib_ibi是接收到推荐项目iii的组aaa和组bbb中的用户数量。此外,an=∑i∈Iaia_n=\sum_{i\in \mathcal{I}}a_ian=∑i∈Iai是组aaa中受到项目曝光的总频率,bnb_nbn同理。最终,s∈[0,1]s\in [0,1]s∈[0,1]等于组别aaa中的加权平均项目曝光减去组别bbb的,权重为aiai+bi\frac{a_i}{a_i+b_i}ai+biai[20]。直觉上,sss捕获了两个组别之间的推荐隔离程度,值越高意味着越严重的隔离。如果有多个都别,采取任意两组之间的sss值的平均。
多数类别优势(MCD)
隔离指标适合于根据用户特征分组来计算组别隔离。对于项目特征,可以使用MCD来获得历史最大项目类别在推荐列表中的比例。在不同时间段MCD的增加,反映着在项目类别上的过滤气泡逐渐严重。
3.2.2 用户特征控制响应
如果用户旨在削弱过滤气泡,UCRS需要对用户控制实时响应,对于细粒度的用户特征控制do(C=cu(+x^,α))do(C=c_u(+\hat{x},\alpha))do(C=cu(+x^,α)),用户想要更多的被其他用户组别x^\hat{x}x^喜欢的项目。由此,UCRS事实上需要基于变动的用户特征来生成推荐。例如,年龄从30岁到18岁。从因果的视角,细粒度用户特征控制的目标是回答一个反事实问题:如果用户在一个反事实的组别x^\hat{x}x^,那么用户的推荐将会变成什么样子? 相似地,粗粒度用户特征控制是为了回答如果用户不在真实组别x‾\overline{x}x中,那么推荐将会变成什么样子? 为了回答该反事实问题,UCI框架需要识别在用户特征和推荐之间的因果联系,并且进行反事实推理。
产生推荐的因果视角
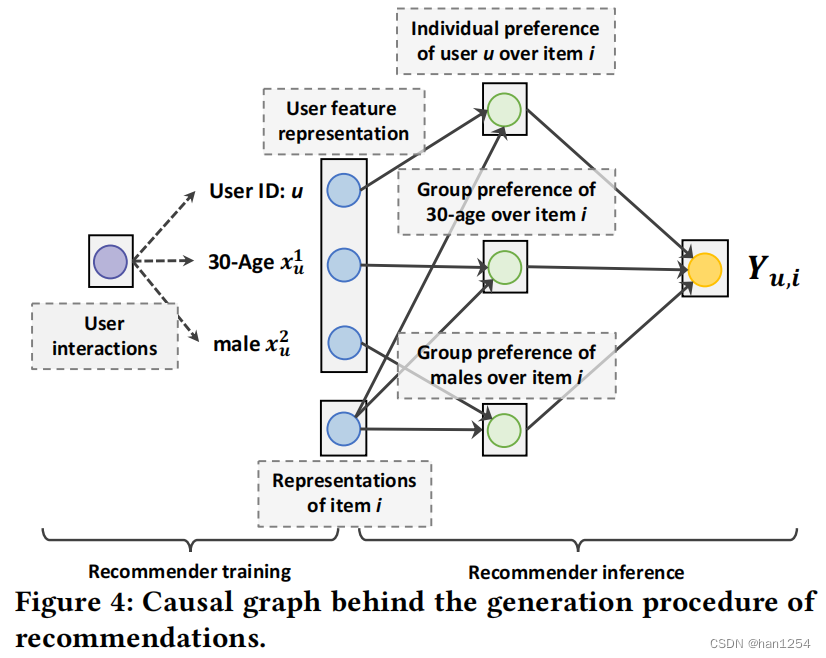
如图四所示,作者通过因果图分析了推荐产生的过程。对于大部分模型,推荐系统通过交互来学习用户表示,包括用户ID、年龄以及性别的表示。因此,对于用户uuu以及项目iii的表示被用来预测用户对项目的偏好概率,即Yu,i∈[0,1]Y_{u,i}\in [0,1]Yu,i∈[0,1]。Yu,iY_{u,i}Yu,i是个体ID和多组特征的偏好得分融合,组别偏好被对应用户组别内的用户分享。
为了回答细粒度用户特征控制的反事实问题,一个直觉上的解决方式是改变推荐器推理的用户特征,例如将年龄从30改为18。关于粗粒度用户特征控制,可以直接摒弃推理中的用户特征x‾\overline{x}x。然而,如图四所示,用户交互实际上是混杂因子,在推荐器训练过程中影响用户ID以及其他组别特征的表示。因此,在用户ID和组别特征之间存在联系。虽然组别特征被改变或者丢弃,第三十用户ID表示仍然将原始特征的过时兴趣进行了编码,这与用户控制不一致,并且阻碍了对目标用户组别的推荐。
为了移除混杂效应,流行的选择是混杂平衡[36]、后门调整以及前门调整。然而,混杂平衡和后门调整需要估计混杂因子在表示上的因果效应。这种估计是不可行的,原因如下:(1)用户交互处于一个动态的高纬空间,这里的新的交互持续增加;(2)用户交互对于表示的影响是由推荐器的训练过程决定的,不同的训练方式结果也不同。此外,前门调整需要发掘阻塞所有后门路径的媒介,这对于图四中的因果图并不适用。为了避免这些挑战,作者提出了直接减少在推理过程中用户ID表示对预测Yu,iY_{u,i}Yu,i的因果效应,这可以在不知道训练过程的情况下有效地减少过时表示的影响。
实现反事实推理
UCI框架首先使用反事实推理来估计用户ID表示的效应,然后从原始的预测Yu,iY_{u,i}Yu,i中扣除该效应。设想在反事实世界中**如果用户uuu没有ID表示,预测Yu^,iY_{\hat{u},i}Yu^,i会变成怎样。**这里的u^\hat{u}u^代表没有ID表示的用户表示。通过比较Yu,iY_{u,i}Yu,i和Yu^,iY_{\hat{u},i}Yu^,i,可以通过Yu,i−Yu^,iY_{u,i} - Y_{\hat{u},i}Yu,i−Yu^,i来衡量用户ID表示的效果。因此,可以在原始预测Yu,iY_{u,i}Yu,i中减除该效应,使用系数α\alphaα来控制减除的力度。
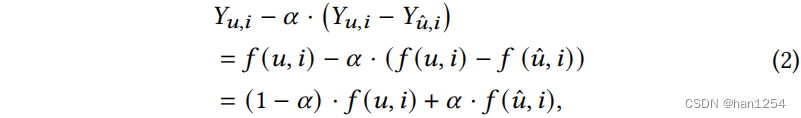
这里的f(⋅)f(\cdot)f(⋅)可以是任何使用用户以及项目表示来计算预测YYY的推荐方法。
UCI总结
UCI框架由两步组成,在推理时回答两个关于用户特征控制的问题:
(1)改变特定用户特征为x^\hat{x}x^,进行细粒度控制以及丢弃用户特征x‾\overline{x}x进行粗粒度控制;
(2)使用反事实推理,通过等式(2)来减弱过时用户ID表示的影响。
3.2.3 响应项目特征控制
项目特征控制的细粒度控制旨在增加目标项目类别h^\hat{h}h^,而粗粒度控制为了减少用户历史中最大历史类别h‾\overline{h}h。实际上,在这里询问了两个干预问题:如果用户想要更多目标类别h^\hat{h}h^的项目,推荐会变成怎样?以及用户不想要最大类别h‾\overline{h}h推荐又会变成怎样? 为了回答这些问题,UCI框架使用了一个用户可控的排序策略:
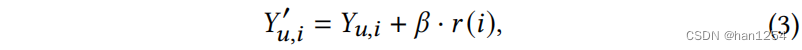
这里的Yu,i′Y_{u,i}'Yu,i′是修正的排序分数,β∈[0,1]\beta\in [0,1]β∈[0,1]是调整用户控制强度的系数。r(i)r(i)r(i)表示项目iii的正则项,

在细粒度控制下,r(i)r(i)r(i)鼓励推荐更多的目标类别h^\hat{h}h^中的项目,如果施加了粗粒度控制,则减少最大类h‾\overline{h}h。
目标类别预测
由于大量的项目类别的存在,用户在细粒度项目特征控制上来选择目标类是一种巨大负担。即使粗粒度控制部分消除了这种负担,但是可以通过对用户预测可能的目标类别来进一步减弱这种负担。如果用户希望减少历史最大类别,可以预测用户可能喜欢历史中的哪个项目类别,然后使用细粒度项目特征控制来改善粗粒度项目特征控制。
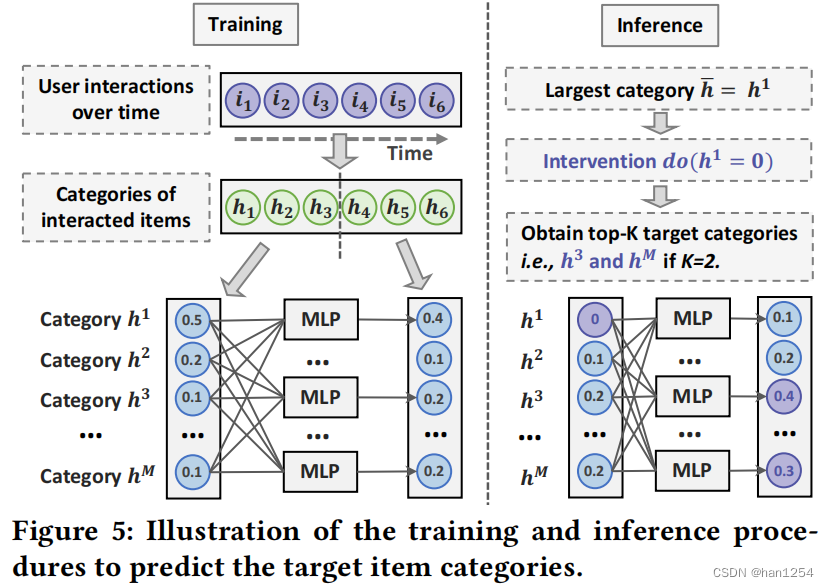
如图五所示,将用户的交互项目按照时间排序,然后将交互序列分成两部分,分别获得项目类别的分布。然后,使用多层感知机,根据第一部分来预测第二部分的分布。在训练过程中,MLPs使用所有用户的类别分布来捕获(1)时间兴趣转移(例如,在一些类别上逐渐增加的偏好),(2)项目类别之间的关系(例如,喜欢动作电影的用户可能也喜欢犯罪电影)。在推理阶段,使用第二部分的分布来预测top-K目标类别。此外,构造干预do(h‾=0)do(\overline{h}=0)do(h=0)来指示减少类别h‾\overline{h}h的用户控制。top-K项目类别被视为细粒度控制的目标项目。最终,UCI进一步通过使用目标类别预测来强化粗粒度项目特征控制。
UCI总结
在项目特征控制下,用户ID表示仍然将历史喜好进行编码,这与增加目标类别或者减少历史大部分类别的目标相冲突。因此,(1)UCI首先构建了反事实推理来减弱用户ID表示的因果效应。(2)对于粗粒度项目特征控制,UCI利用目标类别预测来获得top-K目标类别;(3)UCI采用了等式(3)中的排序策略来进行推荐。
4 实验
- RQ1. UCI如何通过四种用户控制来消除过滤气泡,调整推荐?
- RQ2. 用户如何使用系数(即α\alphaα和β\betaβ)来控制推荐?
- RQ3. 提出的反事实推理如何影响推荐?
4.1 实验设定
- 数据集
作者使用三种真实世界数据集来进行实验:DIGIX-Video、ML-1M以及Amazon-Book。
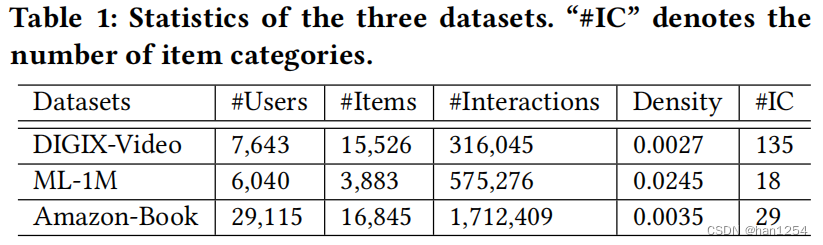
将评分大于等于4的项目作为积极样本。通过时间戳来排序交互,分割成80%、10%以及10%作为训练、验证以及测试集。对于每个交互,随机地采样一个未观测的交互来作为训练的负样本。
- 用户特征控制评估
由于线上测试的代价过大,作者设计了一种离线评估设定:(1)假设一些用户想要消除过滤气泡并且提供了四种控制;(2)根据用户控制,不同的推荐方法生成推荐;(3)在准确性以及消除过滤气泡的测量上进行评估。例如Isolation Index、MCD以及Coverage。
数据集
对于用户特征控制,使用DIGIX-Video来进行评估,因为该数据集拥有丰富的用户特征(例如,性别和年龄)以及视频类别。相反,Amazon-Book只有用户ID特征,ML-1M中的用户被数据集偏差严重地影响,77%的用户最喜欢的电影类别是“戏剧”和“喜剧”,10%的流行电影占据了52%的交互。因此,不同特征的用户表现出了相似的交互分布。因此。Amazon-Book和ML-1M不能很好地适应用户特征上的过滤气泡的评估。本工作中,作者在DIGIX-Video数据集的性别组和年龄组分别测试了细粒度和粗粒度的用户特征控制。用户在细粒度控制下以性别相反的群体为目标,并希望在粗粒度控制下跳出自己的年龄组。这是因为年龄组的数量更大,因此用户更有可能使用粗粒度控制,而不需要指定目标年龄组的负担。
基线
所有的基线以及提出的UCI都是模型无关的,这些模型在FM以及NFM两个代表性推荐模型上来进行比较。
(1)woUF,在没有用户特征的情况下训练模型,这可能会缓解推荐训练过程中不同用户组之间的隔离。
(2)changeUF使用训练好的推荐模型并且只改变用户特征为目标x^\hat{x}x^来进行推理。例如,将年龄从30变成18。changedUF被用来细粒度用户特征控制。
(3)maskUF摒弃了原始用户特征x‾\overline{x}x来进行粗粒度用户特征控制推理。
(4)Fairco[30]是一个用户可控的排序算法,追求项目组别之间的公平曝光推荐机会。
(5)Diversity[59]将重排序方法与最小化列表内相似性的多样化推荐结合。
测量
为了测量表现效果,使用全排序原型[49],并且top-10项目被返回作为推荐。采用Recall\textbf{Recall}Recall和NDCG\textbf{NDCG}NDCG来衡量精确性。为了确定过滤气泡的严重性,使用IsolationIndex\textbf{Isolation Index}Isolation Index以及Coverage\textbf{Coverage}Coverage来估计组别隔离程度以及推荐的多样性。此外,对于目标用户组上的细粒度用户特征控制,作者采用了DIS-EUC\textbf{DIS-EUC}DIS-EUC来比较用户和组别之间推荐的距离。
形式化来说,将x‾\overline{x}x和x^\hat{x}x^分别表示为用户uuu原始的以及目标的组别;du∈RMd_u \in \mathbb{R}^Mdu∈RM是用户uuu的推荐项目类别分布;g‾u∈RM\overline{g}_u\in \mathbb{R}^Mgu∈RM通过平均原始组别x‾\overline{x}x中的用户来表示相同的分布;g^∈RM\hat{g}\in \mathbb{R}^Mg^∈RM表示目标组别x^\hat{x}x^的相同分布。然后对用户uuu,计算DIS-EUC=dis(du,g^u)−dis(du,g‾u)\text{DIS-EUC}=\text{dis}(d_u,\hat{g}_u)-\text{dis}(d_u,\overline{g}_u)DIS-EUC=dis(du,g^u)−dis(du,gu),这里的dis(⋅)\text{dis}(\cdot)dis(⋅)使用欧拉距离。DIS-EUC衡量了用户到两个组别的距离差异,这里更大的距离标志着更严重的组别隔离以及过滤气泡。
- 评估项目特征控制
作者在从训练到测试数据集上产生偏好转变的用户上构造实验。对于每个用户,获得在训练以及测试数据集上最大的项目类别,然后根据不同的最大类别选择用户。这模拟了用户想要减弱历史过滤气泡并且想要更多的其他类别项目的场景。在DIGIX-Video、ML-1M以及Amazon-Book上选择的用户数量分别是4320、3806以及5155。
基线
通过下列方法为选择的用户生成推荐:
(1)woIF不适用项目特征训练FM和NFM;
(2)Fairco;
(3)Diversity;
(4)Reranking是一个UCI的变体,在等式(3)中只使用排序测量;
(5)C-UCI表示在粗粒度控制下进行目标类别预测的UCI策略;
(6)F-UCI表示在细粒度控制下的UCI,知道每个用户的目标类别,即测试集中的最大类别。
度量
对于模型表现的比较,作者使用了Recall、NDCG以及Coverage。此外,作者使用了一个新的度量Weighted NDCG(W-NDCG),该度量对目标类别中的正项目、非目标类中的正项目以及负项目分别分配NDCG分数2、1和0分。W-NDCG区分在目标类别和非目标类别中的正项目,并且偏好目标类别中的正项目。此外,作者使用了MCD以及Target Category Domination(TCD)来计分别算历史最大类别的比例以及推荐中用户的目标类别。
- 超参数设定
作者通过[22]中的设定来训练FM和NFM:用户/项目的表示大小为64;batch size为1024,使用Adagrad进行参数优化。学习率在{0.001,0.01,0.05}中进行搜索。NFM以及目标类别预测中的MLP的尺寸在{4,8,16,32}中进行微调,正则化系数在{0,0.1,0.2}中进行搜索。目标类别预测中的K从{1,2,……,5}中选择。此外,cu(⋅)c_u(\cdot)cu(⋅)和ci(⋅)c_i(\cdot)ci(⋅)对照组中的α\alphaα和β\betaβ分别在{0, 0.1,……,0.5}以及{0,0.01,……,0.1}中进行选择。在验证集中根据Recall值来选择最好的模型。
相关文章:
SIGIR22:User-controllable Recommendation Against Filter Bubbles
User-controllable Recommendation Against Filter Bubbles 摘要 推荐系统经常面临过滤气泡的问题:过度推荐基于用户特征以及历史交互的同质化项目。过滤气泡将会随着反馈循环增长,缩小了用户兴趣。现有的工作通常通过纳入诸如多样性和公平性等准确性之…...
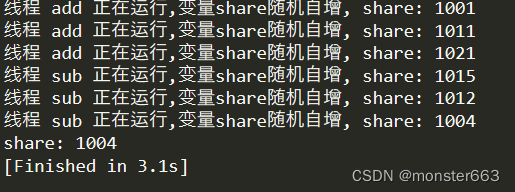
Python中的进程线程
文章目录前言多进程与多线程基本概念多进程multiprocessing 类对象进程池subprocess模块进程间通信多线程threading实现线程操作线程共享所有变量线程锁参考资料前言 又花了点时间学习了一下Python中的多线程与多进程的知识点,梳理一下供复习参考 多进程与多线程 …...

python(8):使用conda update更新conda后,anaconda所有环境崩溃----问题没有解决,不要轻易更新conda
文章目录0. 教训1. 问题:使用conda update更新conda后,anaconda所有环境崩溃1.1 问题描述1.2 我搜索到的全网最相关的问题----也没有解决3 尝试流程记录3.1 重新安装pip3.2 解决anaconda编译问题----没成功0. 教训 (1) 不要轻易使用conda update更新conda----我遇到…...

c++11 标准模板(STL)(std::multimap)(四)
定义于头文件 <map> template< class Key, class T, class Compare std::less<Key>, class Allocator std::allocator<std::pair<const Key, T> > > class multimap;(1)namespace pmr { template <class Key, class T…...

乐观锁及悲观锁
目录 1.乐观锁 (1).定义 (2).大体流程 (3).实现 (4).总结 2.悲观锁 (1).定义 (2).大体流程 (3).实现 (4).缺点 (5).总结 1.乐观锁 (1).定义 乐观锁在操作数据时非常乐观,认为别的线程不会同时修改数据所以不会上锁,但是在更新的时候会判断一…...

常见的锁策略
注意: 接下来讲解的锁策略不仅仅是局限于 Java . 任何和 "锁" 相关的话题, 都可能会涉及到以下内容. 这些特性主要是给锁的实现者来参考的.普通的程序猿也需要了解一些, 对于合理的使用锁也是有很大帮助的. 1.乐观锁 vs 悲观锁 悲观锁: (认为出现锁冲…...

springboot学习(八十) springboot中使用Log4j2记录分布式链路日志
在分布式环境中一般统一收集日志,但是在并发大时不好定位问题,大量的日志导致无法找出日志的链路关系。 可以为每一个请求分配一个traceId,记录日志时,记录此traceId,从网关开始,依次将traceId记录到请求头…...

10种ADC软件滤波方法及程序
10种ADC软件滤波方法及程序一、10种ADC软件滤波方法1、限幅滤波法(又称程序判断滤波法)2、中位值滤波法3、算术平均滤波法4、递推平均滤波法(又称滑动平均滤波法)5、中位值平均滤波法(又称防脉冲干扰平均滤波法&#x…...
第五章:Windows server加域
加入AD域:教学视频:https://www.bilibili.com/video/BV1xM4y1D7oL/?spm_id_from333.999.0.0首先我们选择一个干净的,也就是新建的没动过的Windows server虚拟机。我们将DNS改成域的ip地址,还要保证它们之间能ping的通,…...

Elasticsearch:获取 nested 类型数组中的所有元素
在我之前的文章 “Elasticsearch: object 及 nested 数据类型” 对 nested 数据类型做了一个比较详细的介绍。在实际使用中,你在构建查询时肯定会遇到一些问题。根据官方文档介绍,nested 类型字段在隐藏数组中索引其每个项目,这允许独立于索引…...

English Learning - Day53 作业打卡 2023.2.7 周二
English Learning - Day53 作业打卡 2023.2.7 周二引言1. 我必须承认,我之前学习没你用功。have to VS must2. 这跟我想得一样简单。3. 生活并不像它看上去那么顺风顺水,但也不会像我们想象得那么难。Look VS seem4. 你比去年高多了。5. 你关心你的工作胜…...

SpringMVC--注解配置SpringMVC、SpringMVC执行流程
注解配置SpringMVC 使用配置类和注解代替web.xml和SpringMVC配置文件的功能 创建初始化类,代替web.xml 在Servlet3.0环境中,容器会在类路径中查找实现javax.servlet.ServletContainerInitializer接口的类, 如果找到的话就用它来配置Servle…...

JavaScript中数组常用的方法
文章目录前言常用数组方法1、 join( )2、push()与 pop()3、shift()与 unshift()4、sort()5、reverse()6、slice(ÿ…...

ModuleNotFoundError: No module named ‘pip‘
项目场景:pip 错误 Traceback (most recent call last): File "E:\KaiFa\Python\Python38\lib\runpy.py", line 194, in _run_module_as_main return _run_code(code, main_globals, None, File "E:\KaiFa\Python\Python38\lib\runpy.py&qu…...
)
ROS2 入门应用 发布和订阅(C++)
ROS2 入门应用 发布和订阅(C)1. 创建功能包2. 创建源文件2.1. 话题发布2.2. 话题订阅3. 添加依赖关系4. 添加编译信息4.1. 添加搜索库4.2. 增加可执行文件4.3. 增加可执行文件位置5. 编译和运行1. 创建功能包 在《ROS2 入门应用 工作空间》中已创建和加…...

XSS漏洞,通过XSS实现网页挂马
**今天讲下通过XSS实现网页挂马~*,目的是了解安全方面知识,提升生活网络中辨别度 原理: 实验分为两部分: 1、通过Kali linux,利用MS14_064漏洞,制作一个木马服务器。存在该漏洞的用户一旦通过浏览器访问木…...
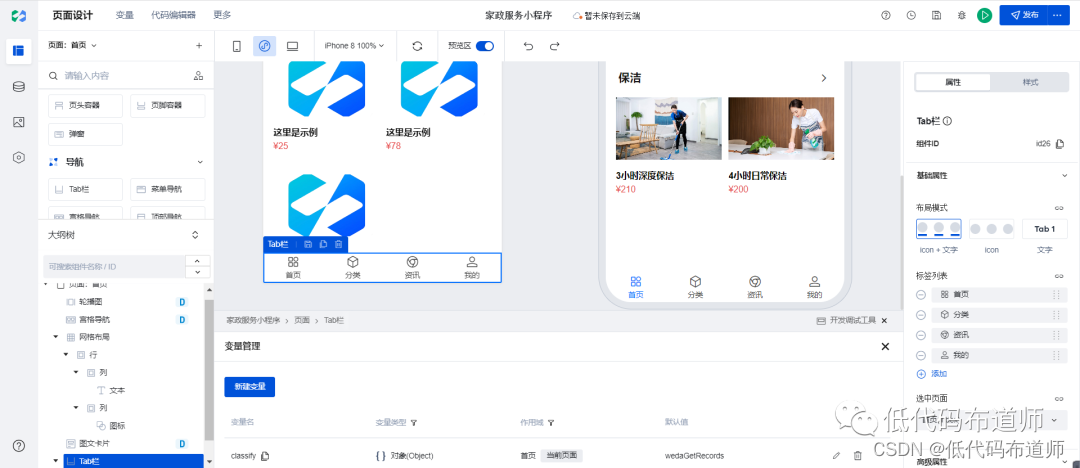
家政服务小程序实战教程09-图文卡片
小程序还有一类需求就是展示服务的列表,我们这里用图文卡片组件来实现,我们先要添加一个标题,使用网格布局来实现 第一列添加一个文本组件,第二列添加一个图标组件 修改文本组件的文本内容,设置外边距 设置第二列的样式…...
国内唯一一部在CentOS下正确编译安装和使用RediSearch的教程
开篇 Redis6开始增加了诸多激动人心的模块,特别是:RedisJSON和RediSearch。这两个模块已经完全成熟了。它们可以直接使用我们的生产上的Redis服务器来做全文搜索(二级搜索)以取得更廉价的硬件成本、同时在效率上竟然超过了Elastic…...

前端对于深拷贝和浅拷贝的应用和思考
浅拷贝 浅拷贝 : 浅拷贝是指对基本类型的值拷贝,以及对对象类型的地址拷贝。它是将数据中所有的数据引用下来,依旧指向同一个存放地址,拷贝之后的数据修改之后,也会影响到原数据的中的对象数据。最简单直接的浅拷贝就…...

Java基础常见面试题(三)
String 字符型常量和字符串常量的区别? 形式上: 字符常量是单引号引起的一个字符,字符串常量是双引号引起的若干个字符; 含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算;字符串常量代表一个地址值…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...