MySQL索引与事务
前言👀~
紧接着数据库的相关知识,今天讲解MySQL面试中频繁被问到的知识点,索引与事务!!!
如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,如果内容有什么问题的话,欢迎各位评论纠正 🤞🤞🤞
个人主页:N_0050-CSDN博客
相关专栏:java SE_N_0050的博客-CSDN博客 java数据结构_N_0050的博客-CSDN博客

MySQL索引
面试中考察的重点!!!
首先我们知道在查询数据的时候,会先遍历表然后把当前的行数据和我们给的条件进行比较,看条件是否满足,满足条件我们保留,不满足则跳过,如果表的记录数不多还好,但是多的话,我们的效率不高且开销大,我们要知道数据库的存储数据是存储在硬盘上的,每次读取数据的时候就要去读取硬盘,所以开销很大,由此我们引出索引这个针对查询进行优化
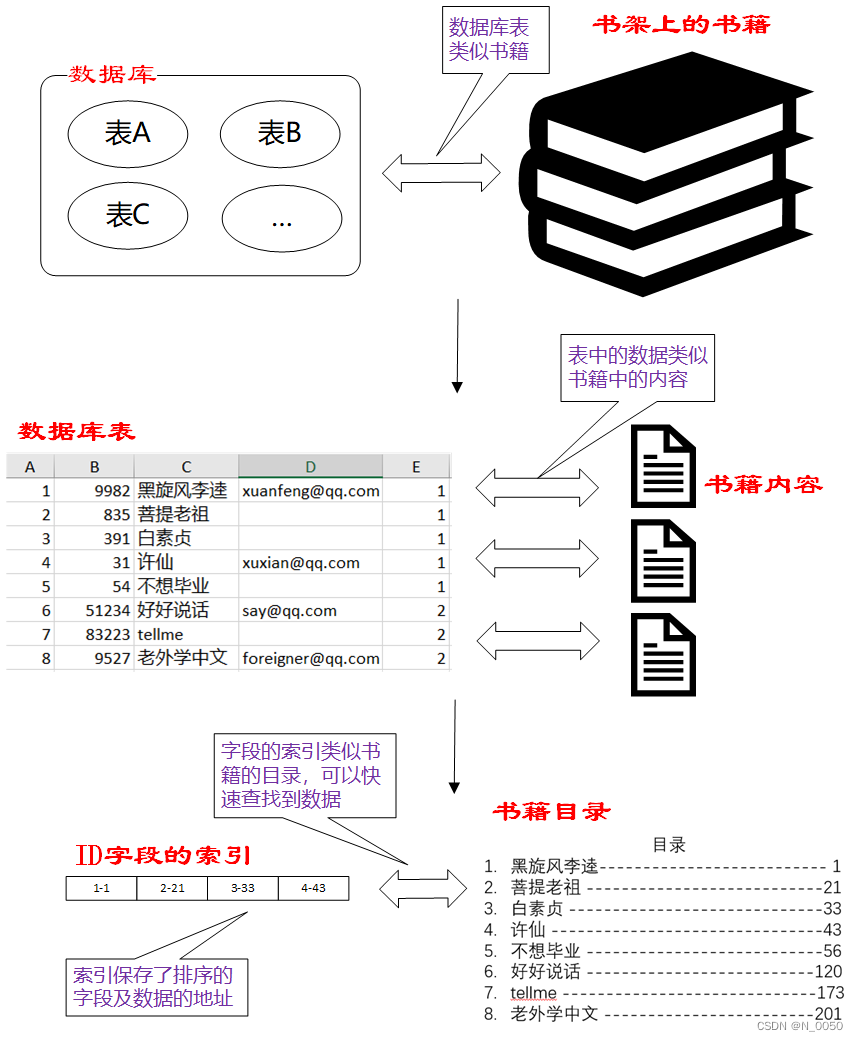
索引 属于是针对 查询操作 引入的 优化手段 可以通过索引来加快查询的速度,避免针对表进行遍历,索引通过使用特殊的数据结构,可以快速查找和访问数据库表中的记录,从而避免全表扫描,提高查询效率,可以把索引所起的作用想象成书籍目录,可用于快速定位、检索数据
索引是能提高查询速度的,但是也有代价:
1.占用更多的空间,生成索引,是需要一系列的数据结构,以及一系列的额外的数据,来存储到硬盘空间中的
2.能提高 查询速度,但是可能会降低 插入修改删除 的速度
索引使用场景:
1.数据量较大,且经常对这些列进行 条件查询
2.该数据库表的插入操作,及对 这些列的 修改 操作频率较低
3.索引会占用额外的 磁盘空间
反之,如果非条件查询列 或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引
索引的相关操作
有些情况下,我们这张表会自带索引,就是有时候索引是我们手动创建的,有时候是数据库自动创建的
手动索引:手动索引会增加数据库的维护成本,因为每次插入、更新或删除操作时,索引也需要更新,选择哪些字段创建手动索引需要考虑查询频率和性能需求,如果一个字段经常出现在查询条件中,手动为其创建索引是有意义的
什么时候数据库自动创建的呢?
主键约束、unique约束、外键约束,这些情况下会自动生成索引
为什么会自动生成呢?
主键 和 unique是要求数据不能出现重复的,怎么判断重不重复 通过查询,因为他们对数据进行操作的时候,都会先触发查询的操作,所以会涉及频繁的查询,为了优化查询的速度,就引入了索引
外键 因为子表要保证在父表那一列中存在,对子表进行操作的时候,就要去父表中查一查,判断记录是不是存在。反之,删除父表中的一条记录也要去子表中查一查,看看当前要操作的记录是不是在子表中被引用了,所以会涉及频繁的查询,为了优化查询的速度,就引入了查询
主键

unique

外键
父表和子表进行外键关联



有了这个索引后,后续在父表中删除一条记录,就拿着父表的id去子表中查,通过这个索引可以快速查到是否存在
1.查看索引
show index from 表名;
一个索引是针对 一个列 来指定的,只有针对这一列进行条件查询的时候,查询速度才能被索引优化
2.创建索引
create index 索引名字 on 表名(列名);
创建索引操作,是一个危险的操作
创建索引的时候,需要针对现有的数据,进行大规模的重新整理
如果当前表是一个空表,或者数据不多,创建索引没什么问题,如果这个表很大,数据很多,创建索引,很容易把数据库服务器给卡住,数据量很多的情况下创建索引,非要创建也不是不行,我们就需要一个新的数据库,然后把表结构和索引设置好,再把之前旧的数据库的数据导出来,然后导入到这个新的数据库中
3.删除索引
drop index 索引名 on 表名;
手动创建的索引,可以手动删除,如果是自动创建的索引(主键/外键,unique)不能删除的!!!
总结
(1)对于插入、删除数据频率高的表,不适用索引
(2)对于某列修改频率高的,该列不适用索引
(3)通过某列或某几列的条件查询频率高的,可以对这些列创建索引
索引背后的原理的理解
索引也是通过一定的数据结构来实现的,数据库引入的索引是一个改进的树形结构,B+树(N叉搜索树)
我们回顾个别适合查找的数据结构,首先是我们的哈希表,哈希表在进行查询的时候,时间复杂度接近O(1),但是呢我们要知道哈希表进行查询的时候,先计算出哈希值,然后再通过哈希函数计算出我们放在哪个index下,对于单条数据进行查询的时候速度是很快,但是对于我们在查询的时候添加一些条件呢?此时如果我们要查询1-100的数据,那我们要一个一个进行hash然后计算下标,那这效率和开销都不是很理想,所以MySQL没有将其作为索引的数据结构。
接着就是二叉搜索树,我们知道二叉搜索树在进行查询的效率也很高,因为它的左子树的节点都是满足小于我们根节点的值的条件,右子树的节点都是大于我们根节点的值,所以在最好的情况下时间复杂度为O(log2N 以二为底的对数),但是呢如果我们要找的数据在刚好在叶子节点呢,并且我们的数据有很多的时候,那我们树的高度就很高,此时我们的查询效率和开销都不理想,显然它也不适合作为索引的数据结构。
N叉搜索树
N叉搜索树:意思是有N个分叉,每个分叉代表一个区间 (二叉树两个分叉就每个节点下有两个子节点,对于N叉树就是每个分叉代表一个区间,区间存放着键值,当区间中的键值少了的时候会进行合并,多了的时候会进行拆分),可能有点绕,就这样理解区间就是节点,然后我们的节点存放多个键值,下面出现区间这个词的时候可以这样理解
例子:比如根节点中存放3个节点(10、20、30),然后每个节点对应一个区间,你存放了N个键值,就有N+1个键值,拿刚才的例子说,第一个区间就是存放小于值为10的键值,第二个区间就是存放值为10-20之间的键值,第三个区间就是值为20-30之间的键值,最后一个区间则是存放大于值为30的键值
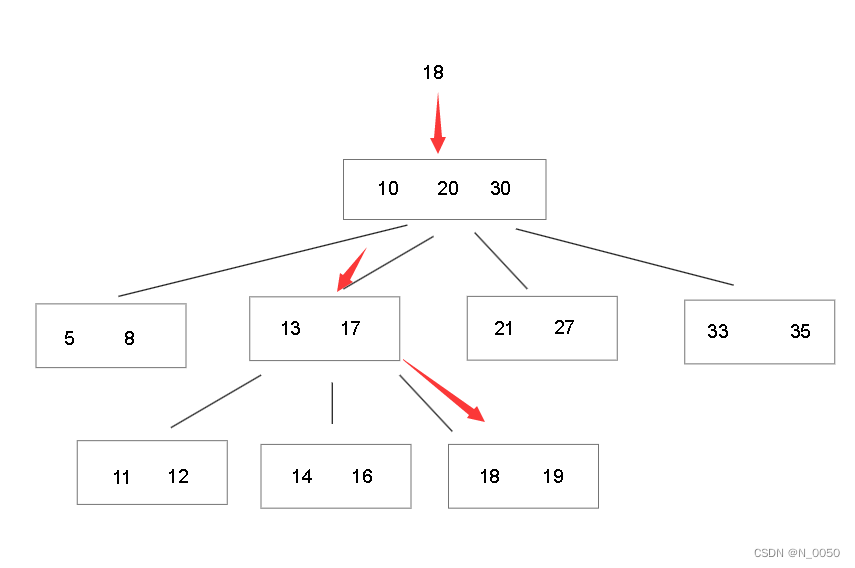
怎么找数据呢?照着图思考,如果我们要找18的话先从根节点中判断在哪个子节点中,很明显在拥有13和17这个键值的节点中,接着继续判断一眼就看出了18在大于17这个键值的节点,下面的B树也是这样的结构
B树
B树的特点
1.就是我们有的节点中有N个键值,就会有N+1个区间
2.B树节点中存储的数据可以理解为行数据,就是数据库表中的行数据
3.B树的开销大,B树会涉及大量读写,因为硬盘上读写1次成本相当于内存上读写1w次成本
B+树
B+树是相对于B树,做出了一定的改进 B+树也是N叉搜索树
B+树的根区间中的节点存放N个节点就有N个区间,有个约定就是保存的N个节点中有一个节点的值是最大的
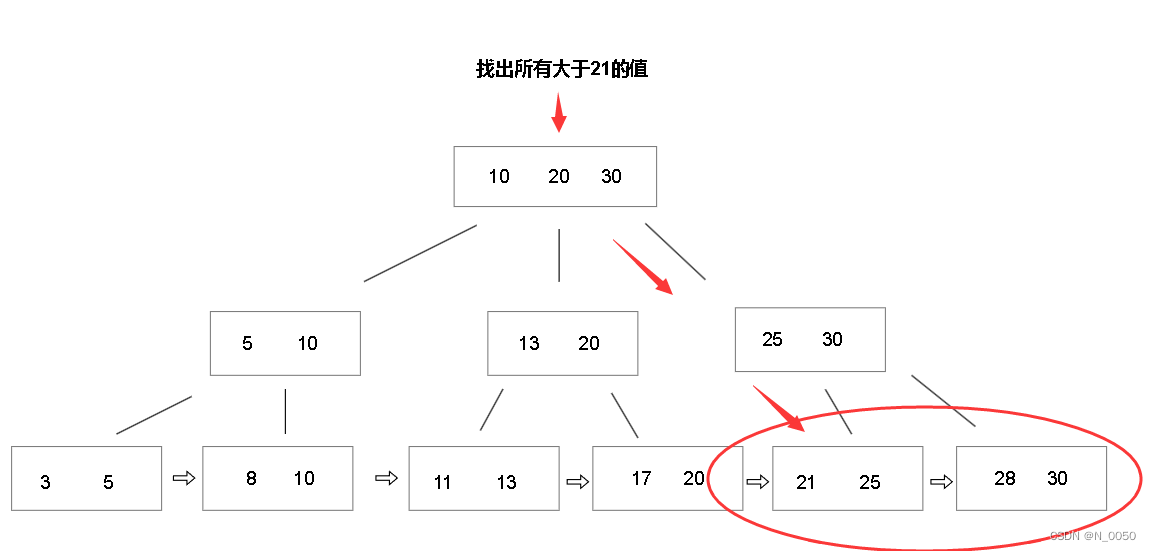
B+树的搜索步骤:比如我们要找所有大于21的值,照图思考,首先进入根节点进行判断,我们马上锁定在30这个值,然后我们去到它的子节点,接着找到25,再往下走,来到了叶子节点,这个节点包含了大于21的值,并且我们的叶子节点是链表结构组成的,这和前面的B树不同,因为B+树的叶子节点是链式结构,顺序读取范围内的所有数据时,只需要一次顺序扫描即可,就是说进入叶子节点的时候只需要一次硬盘IO就可以读取范围内的所有数据,因为叶子节点是链式结构,所以我们直接就可以找出所有大于21的值,而换做是B树的话,它还要回溯,回到上个节点接着判断,这样效率和开销和B+树比起来差多了。
B+树的查询时间开销是稳定的,比如你要查图中的8,即使一开始就找到了,它还是会往下走,走到叶子节点,所以对于B+树来说,所有的查询最后都会走到叶子节点进行查询,叶子节点中存放的是行的数据,非叶子节点中存放包含的是索引信息比如id我们就能很快定位到对应的数据
B+树的特点
1.B+树开销小并且查询效率高,特别是进范围查询
2.B+树的叶子节点才是存储我们的数据,而非叶子节点呢存储的是key,比如我们给id这列设置了主键然后生成索引了,我们的非叶子节点存储的就是这个id,这样应该能懂吧
注意:对于like %孙这种进行查找的话,不会触发索引,因为%这个具体是什么没法确定,而索引本质是靠大小关系进行排列,类似二分查找,实际是N分查找
事务(重要)
面试中考察的重点!!!
实际开发中有时候有些操作需要一次性完成,例如转账,如果转账的过程中我的钱扣了,但是对方没收到,这时候就需要用到事务
大多数情况下,我们在谈论事务的时候,如果没有特指分布式事务,往往指的就是数据库事务
事务也可以理解是一个数据库操作的单位,包含一个或多个数据库操作,这些操作要么都执行正确,要么"一个都不执行"
事务可以把多个sql语句打包成一个整体作为整体来执行(这样的特点称为"原子性"),可以保证这些sql语句要么都执行正确,要么"一个都不执行",一个都不执行并不是真正的一个都不执行,得执行了才知道失败,此时触发事务的回滚rollback
事务的操作
1.start transaction
2.执行sql语句 此时的sql语句具有原子性 打包成一个整体执行 要么都执行正确要么"一个都不执行"
3.commit和rollback 执行提交,如果出错了则执行回滚(主动触发)
回滚是怎么做到的呢?
通过记录日志的方式,记录事务中的关键操作(日志会记录我们在事务中的每一步操作,操作之前是一个什么样的结果,操作之后是一个什么样的结果都会被记录下来),这样的记录就是回滚的依据,什么意思呢你进行插入操作,后续回滚的时候就执行删除,反之,你执行删除操作,后续回滚的时候就执行插入
日志是什么?就是一些打印出来的内容存放在文件里,以文件的形式存放在磁盘里,即使系统崩溃,日志也不会丢失,系统可以通过读取日志文件恢复数据。在上述操作中,日志记录事务的每一步操作
事务的特性
我们知道mysql是一个客户端和服务器结构的程序,所以肯定会遇到多个客户端让服务器执行多个事务的情况,并且得出并发程度越高,整体效率越高。
什么是并发程度呢?指的是在多个任务的情况下,系统能够同时处理的任务的数量
1.原子性(A) 主要通过回滚的方式 保证这一系列的操作要么都执行正确,要么都"不执行"
2.一致性(C) 就刚才那个转账的例子,给某某转1000,你总不能转1000,某某收2000
事务的一致性很多时候是靠数据库(数据库管理系统DBMS)约束以及一系列的检查机制完成
精确解释就是事务执行前后,数据的状态从一个一致性的状态到另外一个一致性的状态,就是在执行事务前数据该是什么样子的就是什么样子的,执行事务后数据该是什么样子的也就是什么样子的,执行事务前后的数据要符合预期,保证数据库始终处于合法的状态,通过这种方式确保数据库的准确性
3.持久性(D) 事务做出的修改,都是在硬盘上持久保存的,即使重启了服务器,数据仍然还在,事务执行的修改也还是有效的
4.隔离性(I) 多个事务并发执行时,一个事务的执行不应影响其他事务的执行。即事务之间相互隔离。简单点说就是在一场考试中 我写我的 你写你的 它写它的 相互不影响
注意:只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!
并发执行多个事务引发的问题(重要)
1.脏读:可以这么理解就是事务A在进行写操作的时候,事务B进行读操作读取的是事务A未提交的数据,接着事务A又对数据进行了修改,之前事务B所读取的数据属于脏数据也可以说是无效数据,如果是串行化执行的话没什么问题,并发执行的话就会出现脏读
解决方式:对写操作加锁(只能进行写操作,不能进行读操作)只能在事务进行提交之后才能在进行读操作
并发程度降低,隔离性提高(就是两个事务之间的影响小了),效率降低,准确性提高
2.丢失更新:有两类丢失更新,第一类丢失更新就是第一个事务执行更新操作的后,第二个事务回滚了第一个事务的更新操作
第二类丢失更新就是两个事务都先执行读操作,然后都执行更新操作,会导致其中的一个事务更新的结果被覆盖了(最终谁的修改先提交,谁的修改就会被覆盖)
解决方式:使用读锁和写锁,确保事务A在读或写数据时,其他事务不能对数据进行操作。
3.不可重复读:事务A和事务B在对同一条数据执行操作的时候,例如事务A在对这条数据进行修改,事务B第一次读的时候是一个数据,第二次读的时候发现数据变了(前面加写锁后,事务在进行写操作的时候,另外一个事务不能读操作,但是没说一个事务在进行读的时候,另外一个事务不能执行写操作)。这个强调的是对单条记录的两次(多次)读操作受到的影响
解决方式:对读操作加锁 (只能进行读操作,不能进行写操作) 就是现在一个事务在进行读操作的时候,另外一个事务不能进行写操作了
并发程度降低,隔离性提高(就是两个事务之间的影响小了),效率降低,准确性提高
4.幻读:事务A在执行插入操作的时候,事务B在执行读的操作的时候,事务B第一次读的时候是一个结果集,第二次读取的一个结果集中突然多了条记录,就像幻觉一样。这个强调的是两次(多次)读操作对结果集的记录数受到的影响
解决方式:引入串行化的方式执行事务,此时并发所引发的所有问题都不存在了,并且此时的效率最低、隔离性最高、没有并发程度这一说因为都使用串行化执行了哪来的并发,准确性最高
不可重复读和幻读的区别:数据范围的区别,不可重复读我认为是对同一条数据进行操作,多次读操作同一条数据会有影响(注重数据的内容),而幻读呢是一个范围,执行两次读操作,一个结果集的记录数(注重数据的数量)会有影响
隔离级别
实际开发中,在不同的场景有时候我们需要效率高(例如点赞10000和10100、评论)有时候呢需要准确性高(例如充值、转账),这时候就引出隔离级别这个概念,mysql提供了四种隔离级别来应对不同的场景的不同要求,可以在mysql的配置文件中,修改隔离级别
默认的隔离级别是repeatable read(可重复读)
这四种隔离级别对应并发执行引发的一系列问题
1.read uncommitted(读未提交)此时并发程度最高、效率最高、隔离性最低、准确性最低,会引发脏读、不可重复读、幻读
2.read commit(读已提交)引入写加锁,只能读取已经提交的版本,此时并发程度降低、效率降低、隔离性提高、准确性提高,解决了脏读问题
3.repeatable read(可重复读)引入加锁和读加锁,读的时候不能写,写的时候不能读,此时并发程度再一步降低、效率也再一步降低、隔离性再提高、准确性也再提高,解决了脏读和不可重复读问题
4.serializable(串行化)按照串行的方式一个一个执行事务,此时没有并发程度这么一说,效率最低、隔离性最高、准确性最高
以上便是索引和事务的知识点,这一章的内容相当重要,面试中频繁出现,所以大家好好吸收和理解,知识量还是很多的,我们下一章再见爱心💕
相关文章:
MySQL索引与事务
前言👀~ 紧接着数据库的相关知识,今天讲解MySQL面试中频繁被问到的知识点,索引与事务!!! 如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,如果内容有什么问题的话,欢迎各位评论纠正…...

『大模型笔记』从基础原理出发提升深度学习性能
从基础原理出发提升深度学习性能 文章目录 一. 从基础原理出发提升深度学习性能1.1. 计算(compute)1.2. 带宽(Bandwidth)1.2.1 关于内存带宽成本的推理(Reasoning about Memory-Bandwidth Costs)1.3. 开销(Overhead)二. 总结三. 参考文献Making Deep Learning Go Brrrr F…...
【二叉树】Leetcode 222. 完全二叉树的节点个数【简单】
完全二叉树的节点个数 你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。 完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最…...

golang界面设计器,全网少见
今天登录govcl的网站,无意中看到有个简易UI设计器。 对于golang的UI专用设计器,还没在网上真正见过。 之前也用govcl来做过两三个桌面应用,好用是好用,不过要安装Lazarus的IDE来拖动设计UI,还要配置很多东西࿰…...
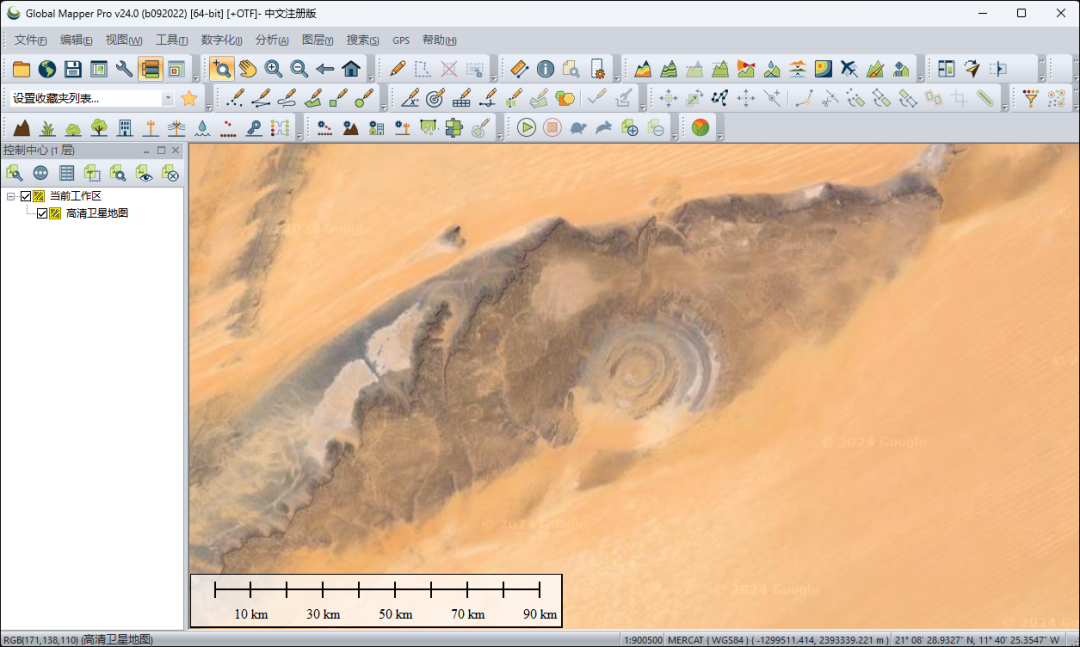
如何在GlobalMapper中加载高清卫星影像?
GlobalMapper在GIS行业几乎无人不知,无人不晓,但它可以直接加载卫星影像也许就不是每个人都知道的了。 这里就来分享一下如何在GlobalMapper中加载高清卫星影像,并可以在文末查看领取软件安装包和图源的方法。 如何加载高清图源 首先&…...

【机器学习】解锁AI密码:神经网络算法详解与前沿探索
👀传送门👀 🔍引言🍀神经网络的基本原理🚀神经网络的结构📕神经网络的训练过程🚆神经网络的应用实例💖未来发展趋势💖结语 🔍引言 随着人工智能技术的飞速发…...
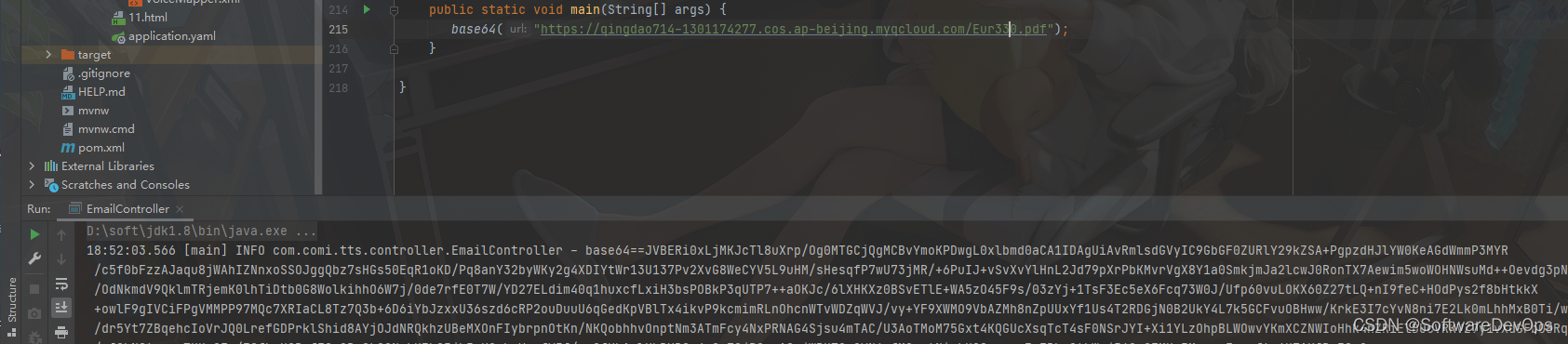
Java如何实现pdf转base64以及怎么反转?
问题需求 今天在做发送邮件功能的时候,发现邮件的附件部分,比如pdf文档,要求先把pdf转为base64,邮件才会发送。那接下来就先看看Java 如何把 pdf文档转为base64。 两种方式,一种是通过插件 jar 包的方式引入…...

动态规划5:62. 不同路径
动态规划解题步骤: 1.确定状态表示:dp[i]是什么 2.确定状态转移方程:dp[i]等于什么 3.初始化:确保状态转移方程不越界 4.确定填表顺序:根据状态转移方程即可确定填表顺序 5.确定返回值 题目链接:62. …...
-列表(List))
Python编程学习第一篇——Python零基础快速入门(五)-列表(List)
今天我们来一起学习Python的列表(list),Python中的列表(List)是一种有序、可变的数据结构,可以用来存储多个值。列表可以包含不同类型的数据,例如整数、浮点数、字符串等。以下是关于Python列表…...

c# - 运算符 << 不能应用于 long 和 long 类型的操作数
Compiler Error CS0019 c# - 运算符 << 不能应用于 long 和 long 类型的操作数 处理方法 特此记录 anlog 2024年5月30日...
)
问题排查|记录一次基于mymuduo库开发的服务器错误排查(回响服务器无法正常工作)
问题背景: 服务器程序如下: #include <mymuduo/TcpServer.h> #include <mymuduo/Logger.h>#include <string> #include <functional>class EchoServer { public:EchoServer(EventLoop *loop,const InetAddress &addr, con…...

中介模式实现聊天室
中介者模式的核心逻辑就是解耦对象‘多对多’的相互依赖关系。当遇到一大堆混乱的对象呈现“网状结构”,利用通过中介者模式解耦对象之间的通讯。 代码案例 抽象中介类 public abstract class AbstractChatRoom {public abstract void notice(String message , Us…...

游戏开发与游戏设计区别
游戏设计与游戏开发是两个紧密相关但有着不同重点的领域,通常需要不同的技能和流程。以下是对游戏设计与游戏开发的详细解释,以及两者的区别: 游戏设计是关于构思和规划游戏的内容、机制和体验的过程。 主要内容: 故事和情节:构…...
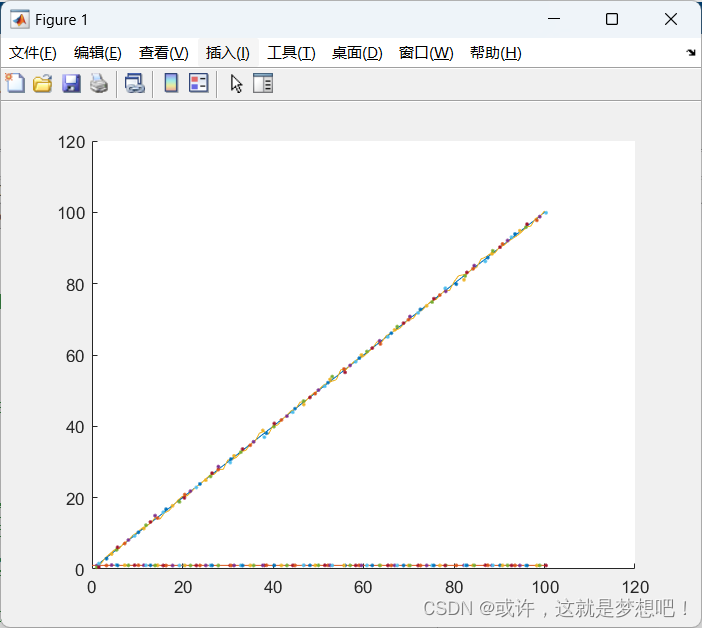
卡尔曼滤波算法的matlab实现
卡尔曼滤波算法的matlab实现 figure; hold on;Z(1:1:100); %观测值:第一秒观测1m 第二秒观测两米 匀速运动, 每秒1m, 最后拟合的也是速度 1m/splot(Z); plot([0,100], [1,1]);noiserandn(1,100)*0.5; %生成方差为1的高斯噪声 ZZnoise; % 加入噪声plot(Z);X[0;…...
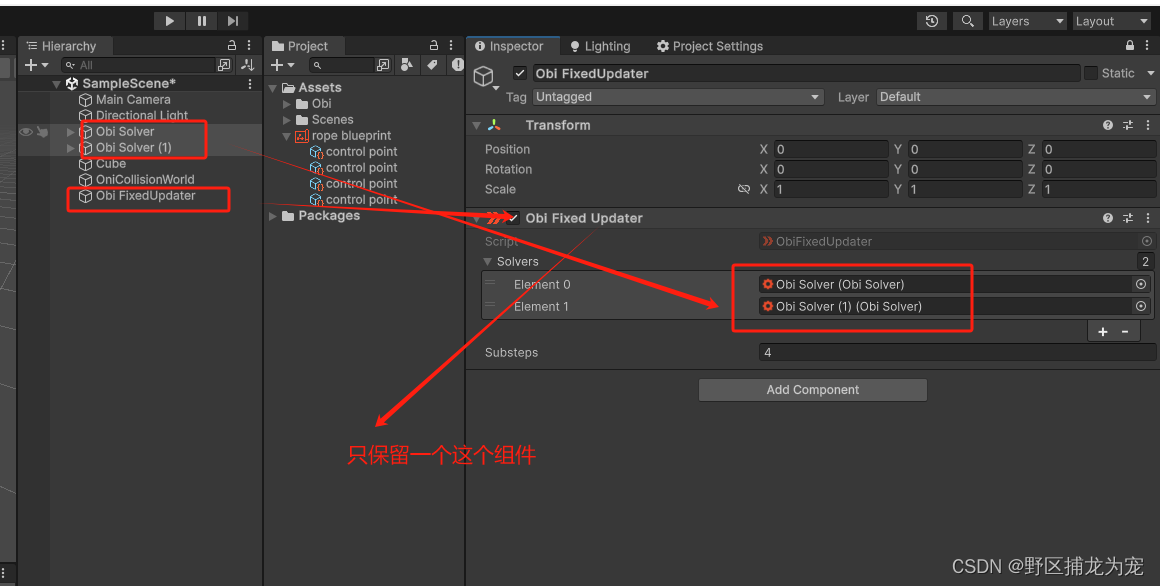
Unity Obi Rope失效
文章目录 前言一、WebGL端Obi Rope失效二、Obi Rope 固定不牢三、使用Obi后卡顿总结 前言 Obi 是一款基于粒子的高级物理引擎,可模拟各种可变形材料的行为。 使用 Obi Rope,你可以在几秒内创建绳索和杆子,同时完全控制它们的形状和行为&…...
基于Nginx和Consul构建自动发现的Docker服务架构——非常之详细
基于Nginx和Consul构建自动发现的Docker服务架构 文章目录 基于Nginx和Consul构建自动发现的Docker服务架构资源列表基础环境一、安装Docker1.1、Consul节点安装1.2、registrator节点安装 二、案例前知识点2.1、什么是Consul 三、基于Nginx和Consul构建自动发现的Docker服务架构…...

Gnu/Linux 系统编程 - 如何获取帮助及一个演示
Gnu/Linux 系统编程 - 如何获取帮助及一个演示 今天开始写 Gnu/Linux 环境下的系统编程,主要的用的语言是 C,主要是为了学习 C 语言,边学边写,这样的学习速度是比较快的。 今天就先介绍下如何在手头上没有任何资料的情况下&…...

ffmpeg 的sws_scale接口函数解析
ffmpeg 的 sws_scale 函数是 libswscale 库中的一个重要函数,用于进行图像的缩放和颜色空间转换。它的主要作用是将输入图像帧转换为另一种尺寸或颜色格式的输出图像帧。下面详细解析一下 sws_scale 函数的作用、参数等。 sws_scale 函数的作用 ffmpeg 的 sws_sca…...

MoonBit 本周新增类型标注语法、继续进行核心库 API 整理工作
MoonBit更新 类型标注增加了新的语法T? 来表示Option[T] struct Cell[T] {val: Tnext: Cell[T]? }fn f(x : Cell[T]?) -> Unit { ... }相当于 struct Cell[T] {val: Tnext: Option[Cell[T]] }fn f(x : Option[Cell[T]]) -> Unit { ... }旧的Option[T]仍然兼容&…...

YOLOv10训练自己的数据集
目录 0、引言 1、环境配置 2、数据集准备 3、创建配置文件 3.1、设置官方配置文件:default.yaml,可自行修改。 3.2、设置data.yaml 4、进行训练 4.1、方法一 4.2、方法二 5、验证模型 5.1、命令行输入 5.2、脚本运行 6、总结 0、引言 本文…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...