Spark MLlib概述
Spark MLlib概述
- 机器学习
- 房价预测
- 模型选型
- 数据探索
- 数据提取
- 准备训练样本
- 模型训练
- 模型效果评估
机器学习
机器学习的过程 :
- 基于历史数据,机器会根据一定的算法,尝试从历史数据中挖掘并捕捉出一般规律
- 再把找到的规律应用到新产生的数据中,从而实现在新数据上的预测与判断
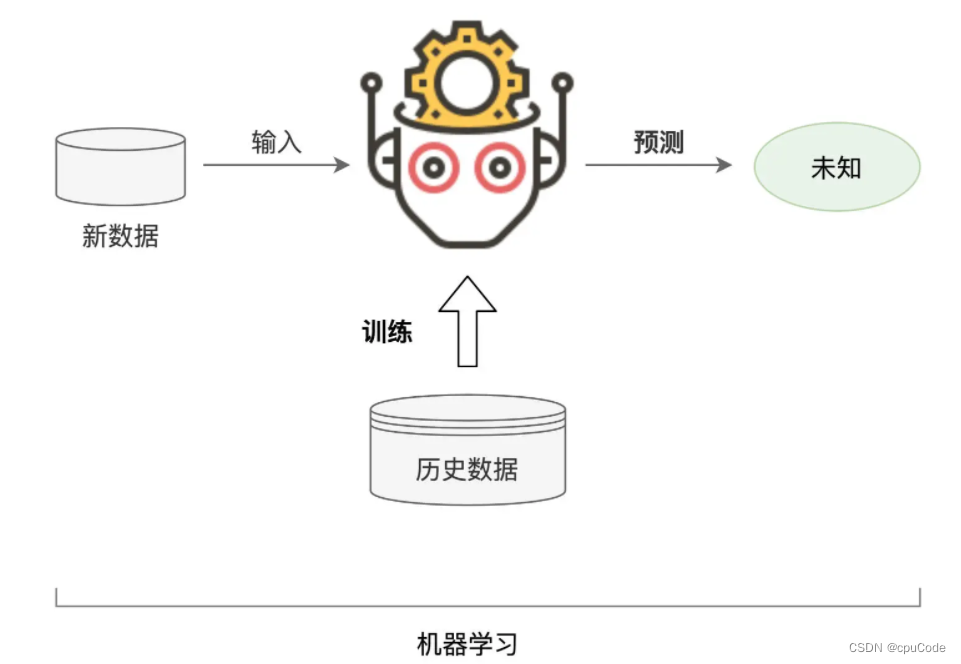
机器学习(Machine Learning): 一种计算过程:
- 对于给定的训练数据(Training samples),选择一种先验的数据分布模型(Models)
- 借助优化算法(Learning Algorithms)自动地持续调整模型参数(Model Weights / Parameters)
- 让模型不断逼近训练数据的原始分布
模型训练 (Model Training) : 调整模型参数的过程
- 根据优化算法,基于过往的计算误差 (Loss),优化算法以不断迭代的方式,自动地对模型参数进行调整
- 模型训练时 ,触发了收敛条件 (Convergence Conditions) ,就结束模型的训练过程
模型测试 (Model Testing) :
- 模型训练完成后,会用一份新的数据集 (Testing samples),来测试模型的预测能力,来验证模型的训练效果
机器学习开发步骤 :
- 数据加载 : SparkSession read API
- 数据提取 : DataFrame select 算子
- 数据类型转换 : DataFrame withColumn + cast 算子
- 生成特征向量 : VectorAssembler 对象及 transform 函数
- 数据集拆分 : DataFrame 的 randomSplit 算子
- 线性回归模型定义 : LinearRegression 对象及参数
- 模型训练 : 模型 fit 函数
- 训练集效果评估 : 模型 summaray 函数
房价预测
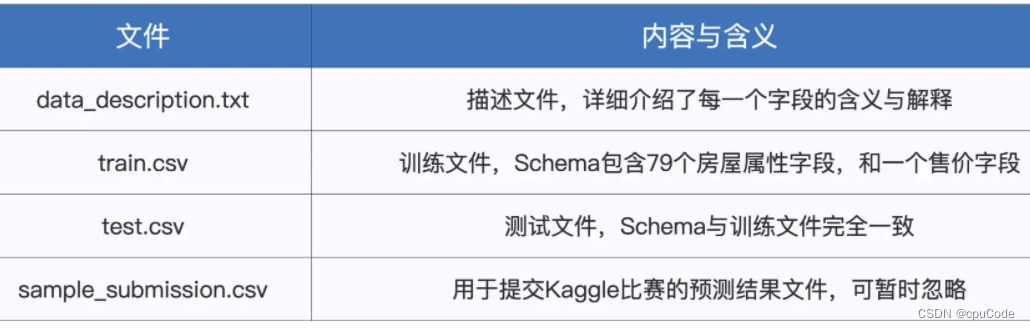
房屋数据中的不同文件 :
模型选型
机器学习分类 :
- 拟合能力 : 有线性模型 , 非线性模型
- 预测标 : 回归、分类、聚类、挖掘
- 模型复杂度 : 经典算法、深度学习
- 模型结构 : 广义线性模型、树模型、神经网络
房价预测的预测标的(Label)是房价,而房价是连续的数值型字段,所以用回归模型(Regression Model)来拟合数据
数据探索
要想准确预测房价,就要先确定那些属性对房价的影响最大
- 模型训练时,要选择那些影响大的因素,剔除那些影响小的干扰项
- 数据特征 (Features) : 预测标的相关的属性
- 特征选择 (Features Selection) : 选择有效特征的过程
特征选择时 , 先查看 Schema
import org.apache.spark.sql.DataFrameval rootPath: String = _
val filePath: String = s"${rootPath}/train.csv"// 从CSV文件创建DataFrame
val trainDF: DataFrame = spark.read.format("csv")
.option("header", true).load(filePath)trainDF.show
trainDF.printSchema
数据提取
选择对房价影响大的特征,要计算每个特征与房价之间的相关性
从 CSV 创建 DataFrame,所有字段的类型默认都是 String
- 训练模型时,只计算数值型数据 , 所以要把所有字段都转为整型
import org.apache.spark.sql.types.IntegerType// 提取用于训练的特征字段与预测标的(房价SalePrice)
val selectedFields: DataFrame = trainDF.select("LotArea", "GrLivArea", "TotalBsmtSF", "GarageArea", "SalePrice");// 将所有字段都转换为整 型Int
val typedFields = selectedFields.withColumn("LotAreaInt",col("LotArea").cast(IntegerType)).drop("LotArea").withColumn("GrLivAreaInt",col("GrLivArea").cast(IntegerType)).drop("GrLivArea").withColumn("TotalBsmtSFInt",col("TotalBsmtSF").cast(IntegerType)).drop("TotalBsmtSF").withColumn("GarageAreaInt",col("GarageArea").cast(IntegerType)).drop("GarageArea").withColumn("SalePriceInt",col("SalePrice").cast(IntegerType)).drop("SalePrice")typedFields.printSchema
/** 结果打印
root
|-- LotAreaInt: integer (nullable = true)
|-- GrLivAreaInt: integer (nullable = true)
|-- TotalBsmtSFInt: integer (nullable = true)
|-- GarageAreaInt: integer (nullable = true)
|-- SalePriceInt: integer (nullable = true)
*/
准备训练样本
把要训练的多个特征字段,捏合成一个特征向量(Feature Vectors)
import org.apache.spark.ml.feature.VectorAssembler// 待捏合的特征字段集合
val features: Array[String] = Array("LotAreaInt", "GrLivAreaInt", "TotalBsmtSFInt", "GarageAreaInt", "SalePriceInt")// 准备“捏合器”,指定输入特征字段集合,与捏合后的特征向量字段名
val assembler = new VectorAssembler().setInputCols(features).setOutputCol("featuresAdded")// 调用捏合器的transform函数,完成特征向量的捏合
val featuresAdded: DataFrame = assembler.transform(typedFields).drop("LotAreaInt").drop("GrLivAreaInt").drop("TotalBsmtSFInt").drop("GarageAreaInt")featuresAdded.printSchema
/** 结果打印
root
|-- SalePriceInt: integer (nullable = true)
|-- features: vector (nullable = true) // 注意,features的字段类型是Vector
*/
把训练样本按比例分成两份 : 一份用于模型训练,一份用于初步验证模型效果
- 将训练样本拆分为训练集和验证集
val Array(trainSet, testSet) = featuresAdded.randomSplit(Array(0.7, 0.3))
模型训练
用训练样本来构建线性回归模型
import org.apache.spark.ml.regression.LinearRegression// 构建线性回归模型,指定特征向量、预测标的与迭代次数
val lr = new LinearRegression().setLabelCol("SalePriceInt").setFeaturesCol("features").setMaxIter(10)// 使用训练集trainSet训练线性回归模型
val lrModel = lr.fit(trainSet)
迭代次数 :
- 模型训练是一个持续不断的过程,训练过程会反复扫描同一份数据
- 以迭代的方式,一次次地更新模型中的参数(Parameters, 权重, Weights),直到模型的预测效果达到一定的标准,才能结束训练
标准的制定 :
- 对于预测误差的要求 : 当模型的预测误差 < 预先设定的阈值时,模型迭代就收敛、结束训练
- 对于迭代次数的要求 : 不论预测误差是多少,只要达到设定的迭代次数,模型训练就结束
烘焙/模型训练的对比 :

完成模型的训练过程
import org.apache.spark.ml.regression.LinearRegression// 构建线性回归模型,指定特征向量、预测标的与迭代次数
val lr = new LinearRegression().setLabelCol("SalePriceInt").setFeaturesCol("features").setMaxIter(10)// 使用训练集trainSet训练线性回归模型
val lrModel = lr fit(trainSet)
模型效果评估
在线性回归模型的评估中,有很多的指标,用来量化模型的预测误差
- 最具代表性 : 均方根误差 RMSE(Root Mean Squared Error),用 summary 能获取模型在训练集上的评估指标
val trainingSummary = lrModel.summaryprintln(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
/** 结果打印
RMSE: 45798.86
*/
房价的值域在(34,900,755,000)之间,而预测是 45,798.86 。这说明该模型是欠拟合的状态
相关文章:
Spark MLlib概述
Spark MLlib概述机器学习房价预测模型选型数据探索数据提取准备训练样本模型训练模型效果评估机器学习 机器学习的过程 : 基于历史数据,机器会根据一定的算法,尝试从历史数据中挖掘并捕捉出一般规律再把找到的规律应用到新产生的数据中,从而…...
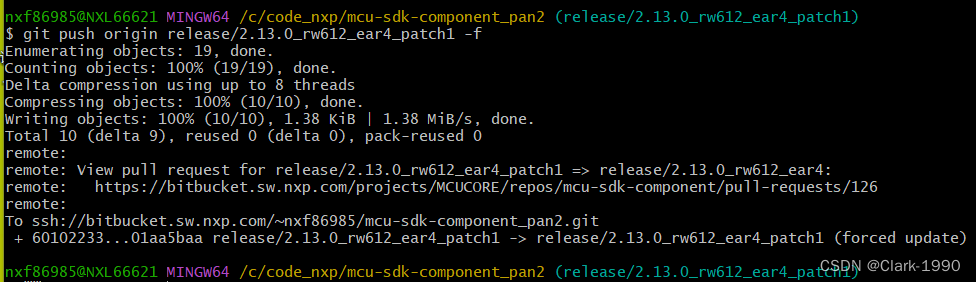
Git 命令行5步解决冲突方法(亲测有效)
总体步骤如下: git pull --rebase 解决冲突文件 file1.c。git add file1.cgit commit -m "*****" git pushgit rebase --continue ,此时冲突消失强推,git push origin xxxx -f 本人解决的例子如下: 第一步、拉取…...

在线帮助文档——让用户更方便地获取帮助
在当今互联网时代,人们在使用各种产品或服务时,难免会遇到问题或疑问,需要寻求帮助。而在线帮助文档则成为了一种方便、快捷、高效的解决问题的方式。Baklib作为一款优雅的云知识库构建平台,可以帮助公司在线制作各种类型的帮助文…...

一小时轻松掌握Git,看这一篇就足够
文章目录序言:版本控制分类一、Git环境配置下载卸载安装二、常用linux命令三、基本配置四、Git基本操作0.原理图1.项目创建及克隆方式一:本地仓库搭建方式二:克隆远程仓库2.文件操作3.配置ssh公钥4.分支5.push代码参考序言:版本控…...
spring cloud stream 自定义binder
背景xxx,关键字 binder stream ,解决多中间件通信及切换问题直接主菜:spring cloud stream 架构中间件 --- binder --- channel --- sink --- (处理)---source ---channel ---binder ---中间件 springcloudstream已自己集成了kafk…...
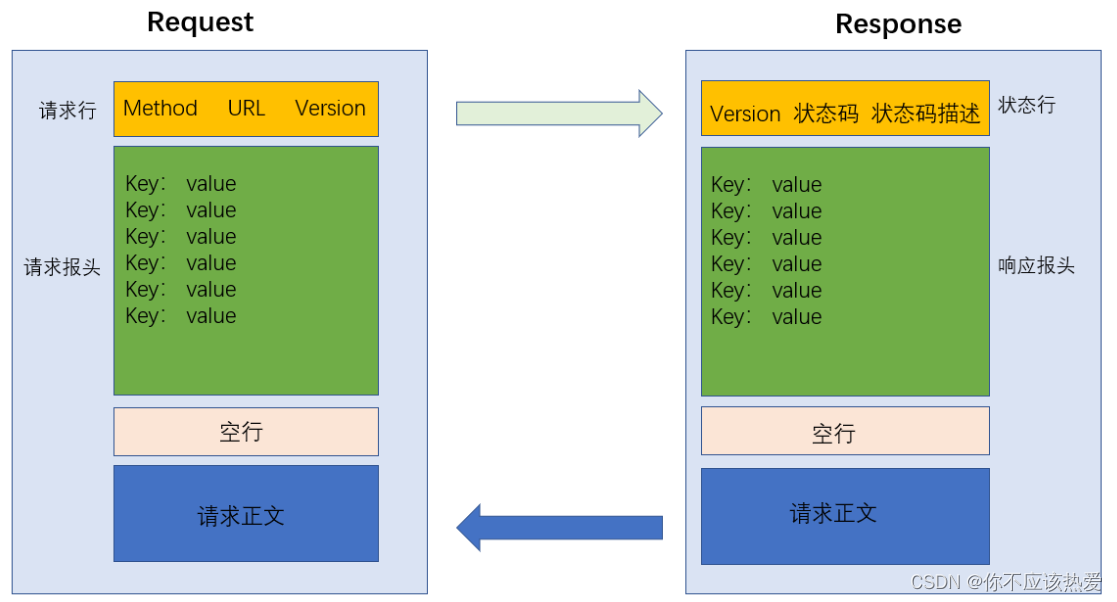
计算机网络之HTTP协议
目录 一、HTTP的含义 1.1 理解超文本 1.2 理解应用层协议 1.3 理解HTTP协议的工作过程 二、HTTP协议格式 2.1 抓包工具的使用 2.2 理解协议格式 2.2.1 请求协议格式 2.2.2. 响应格式请求 一、HTTP的含义 HTTP(全称为“超文本传输协议”)&#x…...

如何挖掘专利创新点?
“无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。” 对于广大的软件工程师来说…...

虚函数和纯虚函数
多态(polymorphism)是面向对象编程语言的一大特点,而虚函数是实现多态的机制。其核心理念就是通过基类访问派生类定义的函数。多态性使得程序调用的函数是在运行时动态确定的,而不是在编译时静态确定的。使用一个基类类型的指针或…...
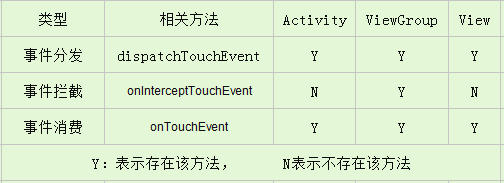
Framework源码面试——Handler与事件传递机制面试集合
Handler面试题 Handler的作用: 当我们需要在子线程处理耗时的操作(例如访问网络,数据库的操作),而当耗时的操作完成后,需要更新UI,这就需要使用Handler来处理,因为子线程不能做更新…...

iOS开发-bugly符号表自动上传发布自动化shell
这里介绍的是通过build得到的app文件和dSYM文件来打包分发和符号表上传。 通过Archive方式打包和获得符号表的方式以后再说。 一:bugly工具jar包准备 bugly符号表工具下载地址:(下载完成后放入项目目录下,如不想加入git可通过gitIgnore忽略…...

MySQL OCP888题解046-哪些语句会被记录到binlog
文章目录1、原题1.1、英文原题1.2、中文翻译1.3、答案2、题目解析2.1、题干解析2.2、选项解析3、知识点3.1、知识点1:binlog_format选项3.2、知识点2:Performance Schema(性能模式)4、总结1、原题 1.1、英文原题 You enable binary logging on MySQL S…...

【前端学习】D5:CSS进阶
文章目录前言系列文章目录1 精灵图Sprites1.1 为什么需要精灵图?1.2 精灵图的使用2 字体图标iconfont2.1 字体图标的产生2.2 字体图标的优点2.3 字体文件格式2.4 字体图标的使用2.5 字体图标的引入2.6 字体图标的追加3 CSS三角3.1 普通三角3.2 案例4 CSS用户界面样式…...

【bioinfo】融合检测软件FusionMap分析流程和报告结果
文章目录写在前面FusionMap融合检测原理FusionMap与其他软比较FusionMap分析流程FusionMap结果文件说明FusionMap mono CUP设置图片来源: https://en.wikipedia.org/wiki/Fusion_gene写在前面 下面主要内容是关于RNA-seq数据分析融合,用到软件是FusionMap 【Fusion…...

C++基础了解-17-C++日期 时间
C日期 & 时间 一、C日期 & 时间 C 标准库没有提供所谓的日期类型。C 继承了 C 语言用于日期和时间操作的结构和函数。为了使用日期和时间相关的函数和结构,需要在 C 程序中引用 头文件。 有四个与时间相关的类型:clock_t、time_t、size_t 和 …...

MOV压敏电阻的几种电路元件功能及不同优势讲解
压敏电阻,通常是电路为防护浪涌冲击电压而使用的一种电子元器件,相比其他的浪涌保护器来说,也有那么几个不一样的优势,那么,具体有哪些?以及关于它的作用,你都知道吗?以下优恩小编为…...
uniapp+uniCloud实战项目报修小程序开发
前言 本项目基于 uniapp uniCloud 云开发,简单易用,逻辑主要是云数据库的增删查改,页面大部分自写,部分使用uniUI, uView 组件库。大家可用于学习或者二次开发,有什么不懂的地方可联系 wechat:MrYe443。用…...

演唱会的火车票没了?Python实现12306查票以及zidong购票....
嗨害大家好!我是小熊猫~ 不知道大家抢到演唱会的门票没有呢? 不管抢到没有,火车票也是很重要的哇 24小时抢票不间断的那种喔~ ~ ~ 不然可就要走路去了喔~ 准备工作 环境 Python 3.8Pycharm 插件 谷歌浏览器驱动 模块 需要安装的第三方模块&am…...

Linux发行版本与发行版的简单的介绍
Linux linux下有很多发行的版本,或者称之为魔改版本。以下介绍一些常见的版本,以避免名词的混淆。 linux是提供了一个内核,就像是谷歌的内核一样,QQ浏览器就是使用的谷歌的内核,也算是一个发行版本。 Ubuntu&#x…...
前后端分离项目学习-vue+springboot 博客
前后端分离项目 文章总体分为2大部分,Java后端接口和vue前端页面 项目演示:www.markerhub.com:8084/blogs Java后端接口开发 1、前言 从零开始搭建一个项目骨架,最好选择合适,熟悉的技术,并且在未来易拓展…...
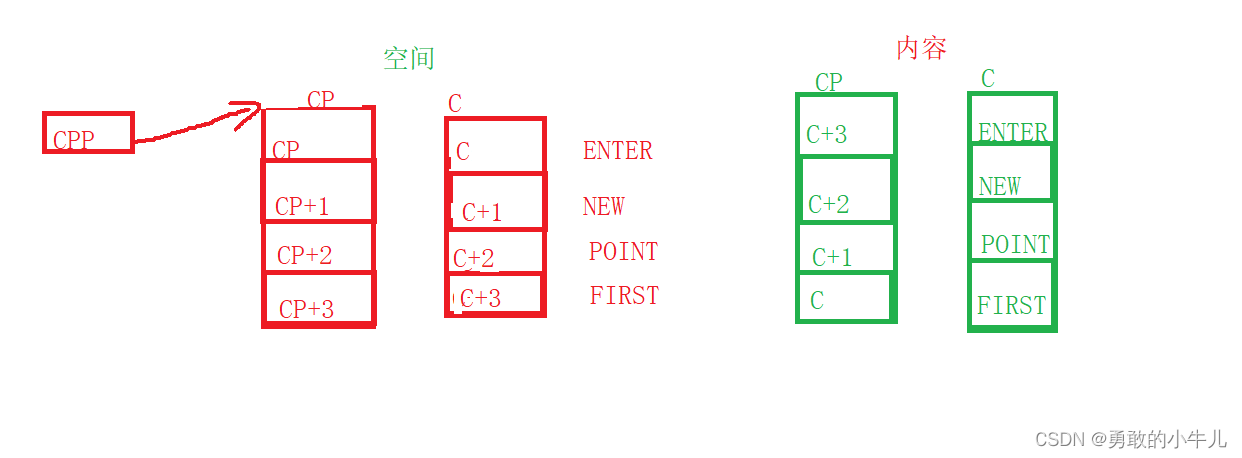
关于指针运算的一道题
目录 刚看到这道题的时候我也和大多数小白一样感到无从下手,但是在我写这篇博客的前几分钟开始我对这道题有了一点点的理解。所以我就想着趁热打铁,写一篇博客来记录一下我的想法。 题目如下: 画图: 逐一解答: 题一…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...