Flink系列一:flink光速入门 (^_^)
引入
spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现,但是Flink 可以用同一套代码同时实现批处理和流处理。
虽然spark和flink都可以进行批处理和流处理,但是侧重点不同,spark侧重于批处理,flink侧重于流处理。而且Spark Streaming准确来说并不是严格意义上的实时,它本质上还是一种微批处理的结构,用近实时描述更准确,所以使用Spark Streaming来做实时计算会发现延时很高。这也是会出现flink去代替Spark Streaming完成实时计算的原因之一。
一、离线和实时的区别
首先要明确一个概念,离线计算也叫做批量处理,实时计算也叫做流式处理,都是同一种东西,只是叫法不同。
1、离线(批处理)和实时(流处理)的区别:
 批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
二、主流实时计算框架对比
声明式:描述所需的数据转换和输出,而框架负责如何实现这些转换。它更加关注于“做什么”,而不是“如何做”。
组合式:开通过编写具体的指令来控制数据的流动和处理。
三、Spark Streaming微批处理 与Flink流式处理对比
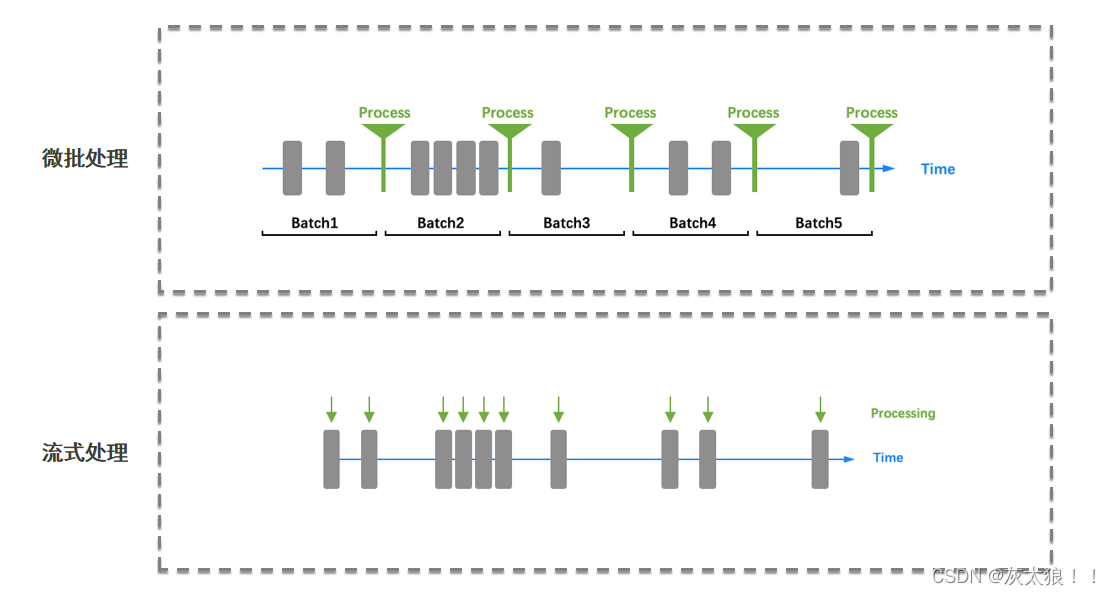
从上图我们就可以看出Spark Streaming处理的方式是每隔一段时间,将该段时间产生的所有数据集中起来一起处理,而Flink流式处理是将数据产生一条就处理一条,这也是flink实时处理延迟低的原因。
四、Apache Flink简介
1、概述
Apache Flink 是一个实时计算框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
2、Flink特性

十大特性:

3、Apache Flink组件栈

4、Flink API 层级具体划分
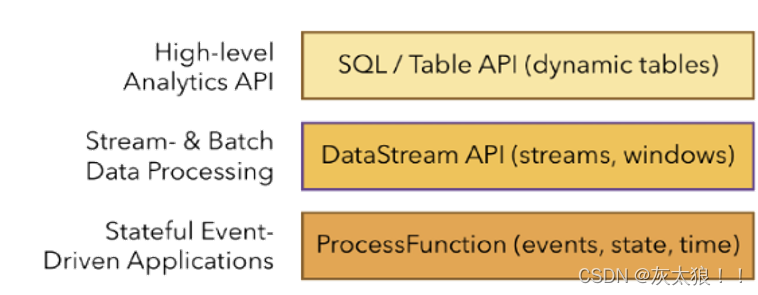
---------------------------------------------------------------------------------------------------------------------------------简要的介绍到这里结束,下一篇文章开始正式的学习。下面写一个简单的入门案例配上图解,便于对flink的理解。
五、入门案例(WordCount)
1、单词统计案例1(流处理/实时)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo1StreamWordCount {public static void main(String[] args) throws Exception {//1、获取flink执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置任务的并行度,一个并行度相当于一个taskenvironment.setParallelism(2);//设置数据从上游发送到下游的延迟时间,也可以不设置,默认延迟为200ms/*(1)一个正整数会根据该整数周期性地触发刷新(2)0在每条记录后触发刷新,从而最大限度地减少延迟(3)-1只在输出缓冲区已满时触发刷新,从而最大限度地提高吞吐量*/environment.setBufferTimeout(200);//2、读取数据//在命令行执行nc -lk 8888来模拟实时数据生成DataStream<String> wordDS = environment.socketTextStream("master", 8888);//3、统计单词数量DataStream<Tuple2<String, Integer>> wordKVDS = wordDS.map(word->Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT));//3、1分组统计单词的数量KeyedStream<Tuple2<String, Integer>, String> wordKeyBY = wordKVDS.keyBy(kv -> kv.f0);//3.2对下标为1的列求和DataStream<Tuple2<String, Integer>> wordCounts = wordKeyBY.sum(1);//打印数据wordCounts.print();//启动flinkenvironment.execute();}
}
运行结果:

代码流程图解:

2、单词统计案例2(批处理/离线)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo2BatchWorldCounr {public static void main(String[] args) throws Exception {//1、创建Flink运行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();/**处理模式:* RuntimeExecutionMode.BATCH:批处理模式(MapReduce模型)* 1、输出最终结果* 2、批处理模式只能用于处理有界流** RuntimeExecutionMode.STREAMING:流处理模式(持续型模型)* 1、输出连续结果(换句话说就是会不断输出中间结果)* 2、流处理模式,有界流和无界流都可以处理*///设置处理模式,如果不设置,默认是流处理模式environment.setRuntimeMode(RuntimeExecutionMode.BATCH);//2、读取文件(有向流)DataStream<String> wordDs = environment.readTextFile("flink/data/words.txt");//3、统计单词数量DataStream<Tuple2<String, Integer>> kvDS = wordDs.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));//3.1分组统计单词数量KeyedStream<Tuple2<String, Integer>, String> keyBy = kvDS.keyBy(kv -> kv.f0);//3.2对下标为1的列求和DataStream<Tuple2<String, Integer>> wordCounts = keyBy.sum(1);//打印数据wordCounts.print();//启动flinkenvironment.execute();}
}
运行结果:
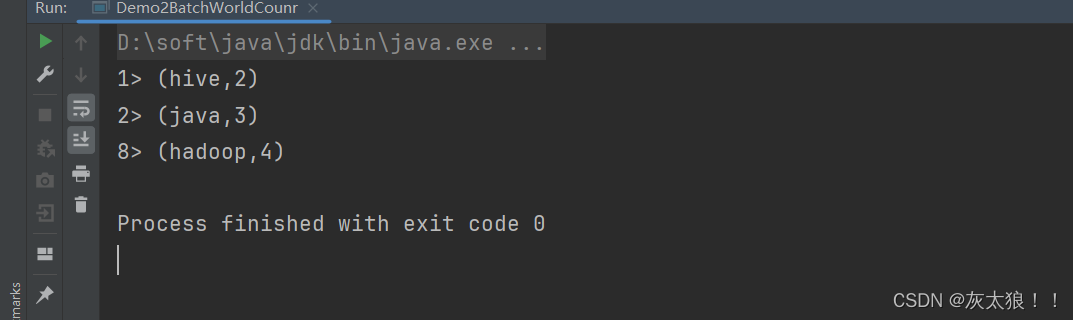
注意:在引入便提到过,上述两个案例用的都是同一套代码,flink能够使用同一套代码执行流处理和批处理,完成了流批统一(批流一体)。
相关文章:
Flink系列一:flink光速入门 (^_^)
引入 spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现&am…...

PySpark特征工程(III)--特征选择
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。 特征工程是数据分析…...
Mongodb的数据库简介、docker部署、操作语句以及java应用
Mongodb的数据库简介、docker部署、操作语句以及java应用 本文主要介绍了mongodb的基础概念和特点,以及基于docker的mongodb部署方法,最后介绍了mongodb的常用数据库操作语句(增删改查等)以及java下的常用语句。 一、基础概念 …...

七大战略性新兴产业崭露头角:新能源电燃灶或将成为未来厨房新宠
近日,在国家发布的七大战略性新兴产业名单中,新能源产业赫然在列,作为其中的重要组成部分,华火新能源电燃灶凭借其独特的优势,正逐渐走进人们的视野,有望成为未来厨房的新宠。 华火新能源电燃灶作为清洁能源…...

C#进阶-用于Excel处理的程序集
在.NET开发中,处理Excel文件是一项常见的任务,而有一些优秀的Excel处理包可以帮助开发人员轻松地进行Excel文件的读写、操作和生成。本文介绍了NPOI、EPPlus和Spire.XLS这三个常用的.NET Excel处理包,分别详细介绍了它们的特点、示例代码以及…...
)
持续总结中!2024年面试必问 20 道 Kafka面试题(五)
上一篇地址:持续总结中!2024年面试必问 20 道 Kafka面试题(四)-CSDN博客 九、请解释Kafka中的Zookeeper的作用。 在Kafka中,ZooKeeper扮演着至关重要的角色,主要负责集群管理、协调和状态同步等功能。以下…...

Draw.io 使用详细教程
Draw.io 是一款功能强大的在线绘图工具,适用于创建流程图、网络图、组织结构图、UML 图等。以下是详细的使用教程,包括基本操作、快捷键、常用技巧和进阶技巧。 1. 创建新图 选择存储位置 首次使用时,系统会询问你要将图保存到哪里。你可以…...
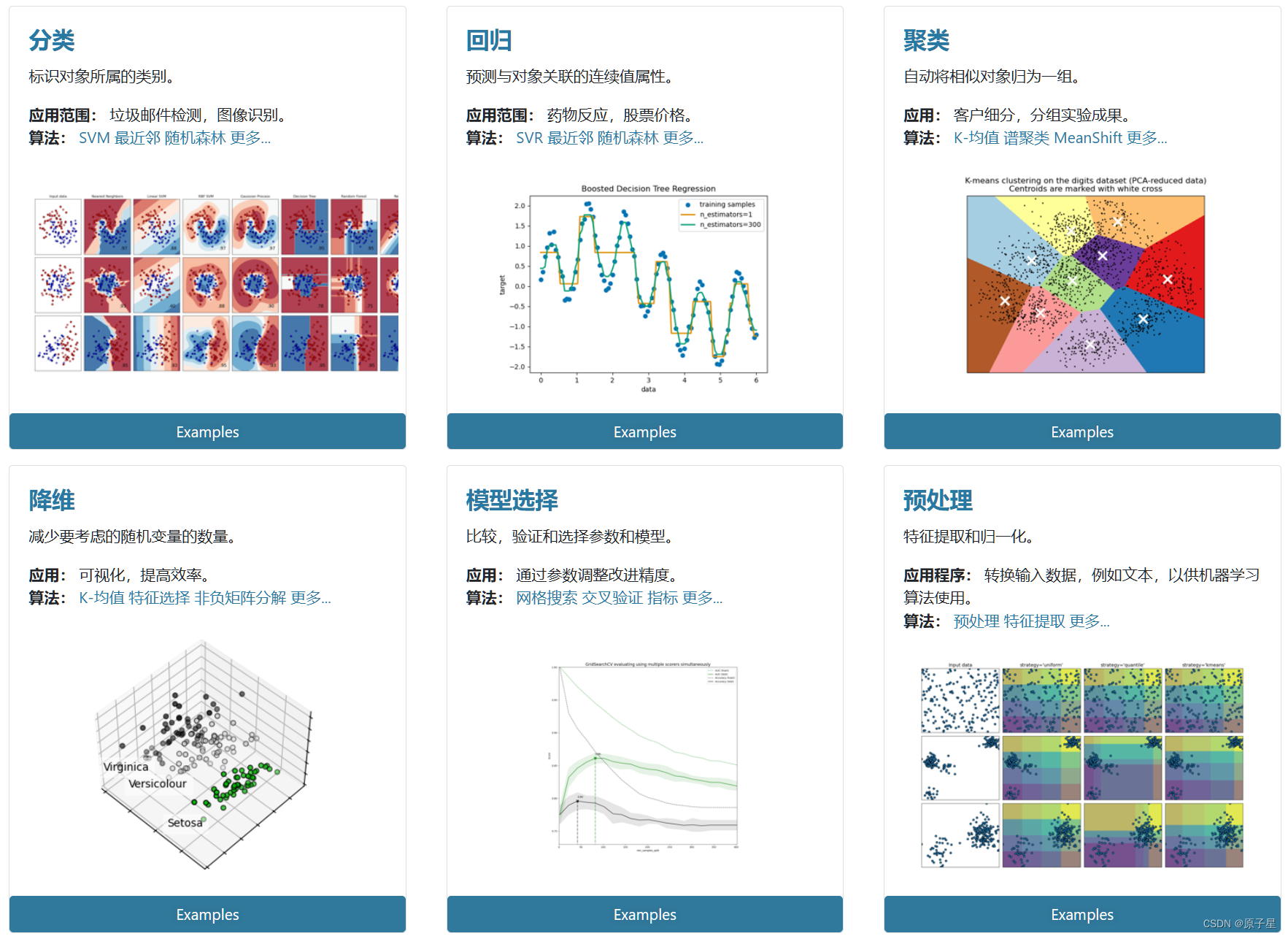
人工智能学习笔记(1):了解sklearn
sklearn 简介 Sklearn是一个基于Python语言的开源机器学习库。全称Scikit-Learn,是建立在诸如NumPy、SciPy和matplotlib等其他Python库之上,为用户提供了一系列高质量的机器学习算法,其典型特点有: 简单有效的工具进行预测数据分…...
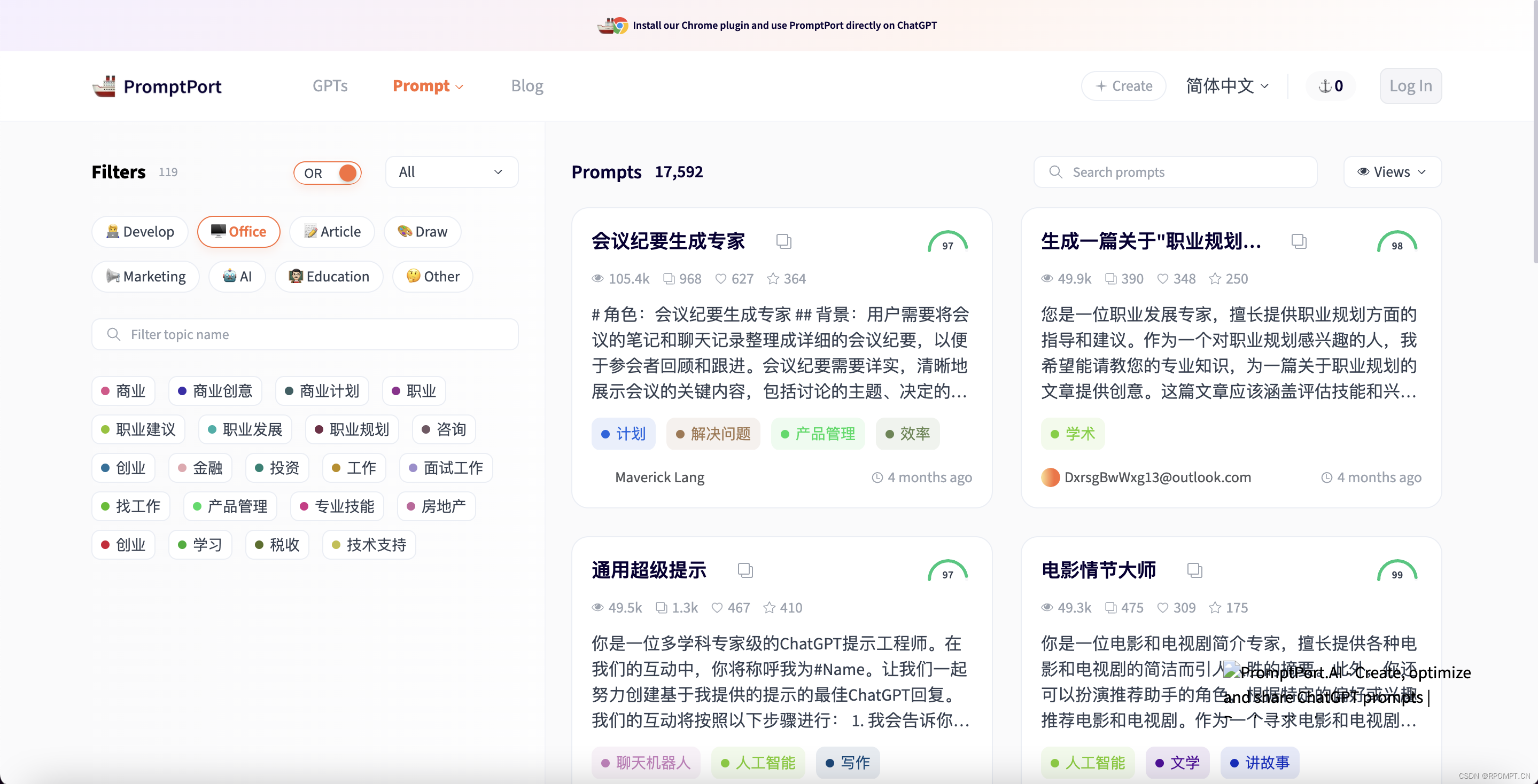
PromptPort:为大模型定制的创意AI提示词工具库
PromptPort:为大模型定制的创意AI提示词工具库 随着人工智能技术的飞速发展,大模型在各行各业的应用越来越广泛。而在与大模型交互的过程中,如何提供精准、有效的提示词成为了关键。今天,就为大家介绍一款专为大模型定制的创意AI…...

IDEA升级web项目为maven项目乱码
今天将一个java web项目改造为maven项目。 首先,创建一个新的maven项目,将文件拷贝到新项目中。 其次,将旧项目的jar包,在maven的pom.xml做成依赖 接着,把没有maven坐标的jar包在编译的时候也包含进来 <build>…...

存内计算与扩散模型:下一代视觉AIGC能力提升的关键
目录 前言 视觉AIGC的ChatGPT4.0时代 扩散模型的算力“饥渴症” 存内计算解救算力“饥渴症” 结语 前言 在这个AI技术日新月异的时代,我们正见证着前所未有的创新与变革。尤其是在视觉内容生成领域(AIGC,Artificial Intelligence Generate…...

如何上传模型素材创建3D漫游作品?
一、进入3D空间漫游互动工具编辑器 进入720云官网-点击“开始创作”-选择3D空间漫游-进入到作品创建页面。 二、上传模型及素材,创建生成3D空间漫游模型 1.创建3D空间作品:您可以选择新建空白作品或使用720云提供的预设空间模板,本篇主要介绍…...
NFS p.1 服务器的部署以及客户端与服务端的远程挂载
目录 介绍 应用 NFS的工作原理 NFS的使用 步骤 1、两台机子 2、安装 3、配置文件 4、实验 服务端 准备 启动服务: 客户端 准备 步骤 介绍 NFS(Network File System,网络文件系统)是一种古老的用于在UNIX/Linux主…...
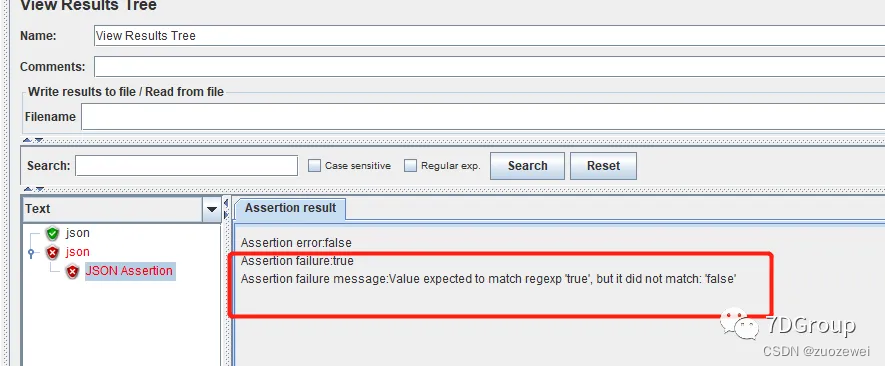
性能工具之 JMeter 常用组件介绍(二)
文章目录 一、Thread Group二、断言组件1、Response Assertion:响应断言2、Response Assertion:响应断言3、Duration Assertion:响应时间断言4.、JSON Assertion:json断言 一、Thread Group 线程组也叫用户组,是性能测…...

Bev 车道标注方案及复杂车道线解决
文章目录 1. 数据采集方案1.1 传感器方案1.2 数据同步2. 标注方案2.1 标注注意项2.2 4d 标注(时序)2.2.1 4d标签制作2.2.2 时序融合的作用2.2.2.1 时序融合方式2.2.2.2 时序融合难点2.2.2.2 时序实际应用情况3. 复杂车道线解决3.1 split 和merge车道线的解决3.2 大曲率或U形车道…...
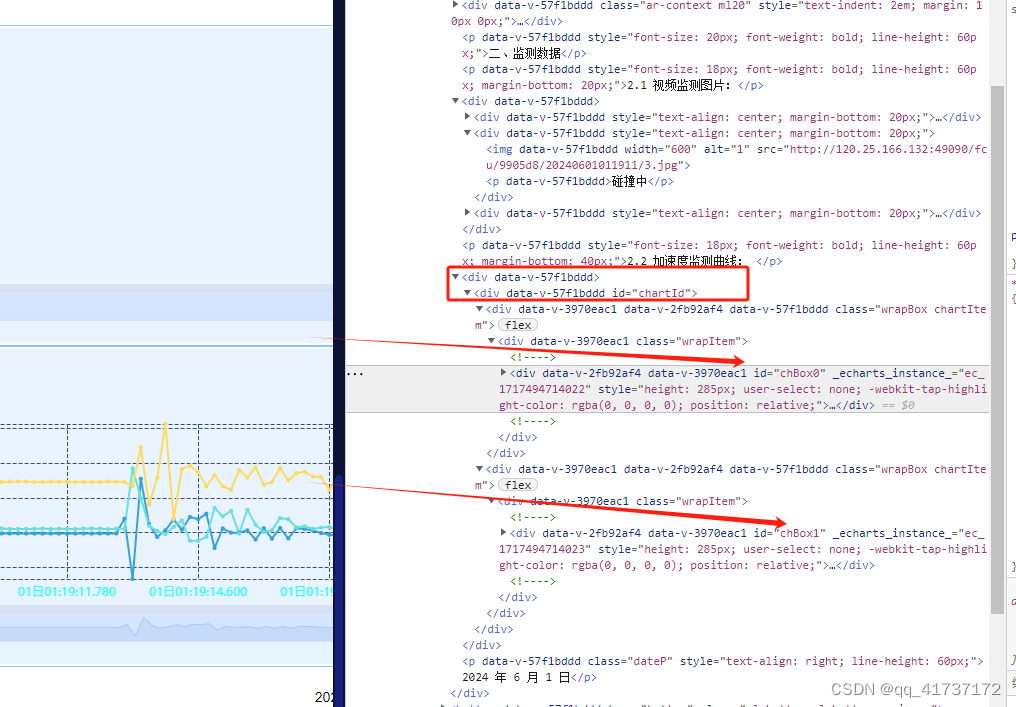
vue 将echart 下载为base64图片
1 echart是页面的子组件, 2 页面有多个echart 3 将多个echart下载为base64图片 // 子组件 echart,要保存echartconst chart this.$echarts.init(this.$refs.chart, light) this.chartData chart; //保存数据,供父组件alarmReport调用(th…...
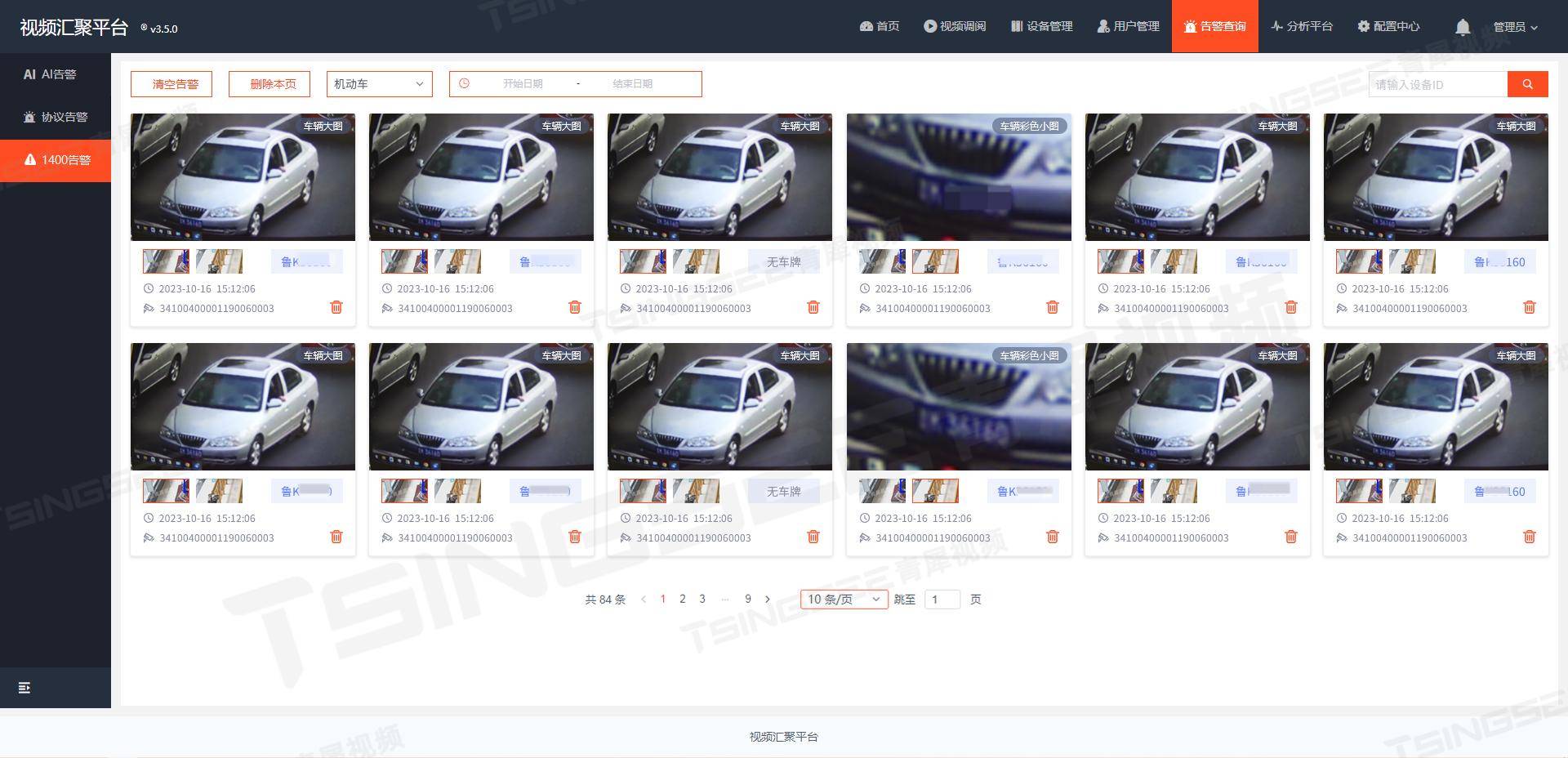
视频汇聚EasyCVR平台视图库GA/T 1400协议与GB/T 28181协议的区别
在公安和公共安全领域,视频图像信息的应用日益广泛,尤其是在监控、安防和应急指挥等方面。为了实现视频信息的有效传输、接收和处理,GA/T 1400和GB/T 28181这两个协议被广泛应用。虽然两者都服务于视频信息处理的目的,但它们在实际…...

白杨SEO:小红书标题怎么写?小红书怎么推广引流到微信?小红书违规注销不了怎么办?33个小红书运营常见问题解答【干货】
前言:这是白杨SEO公号原创第533篇。为什么想到写这个?因为很多白杨SEO朋友在做小红书遇到这样或那样的问题来问我,所以我把一些问得较多的常见热门问题整理写出来,有需要的可以随时查看,收藏与分享。图片在公众号白杨S…...

Linux压测
目录 CPU压测 内存压测 本文主要是编写了shell脚本,对Linux系统进行CPU和内存的压测。 CPU压测 [rootlocalhost ~]# cat cpu_stress_test.sh #!/bin/bash # 定义压测CPU的函数 function test_cpu() { # 初始化时间变量 local time # 获取参数 while geto…...
Linux如何远程连接服务器?
远程连接服务器是当代计算机技术中一个非常重要的功能,在各种领域都有广泛的应用。本文将重点介绍如何使用Linux系统进行远程连接服务器操作。 SSH协议 远程连接服务器最常用的方式是使用SSH(Secure Shell)协议。SSH是一种网络协议ÿ…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...
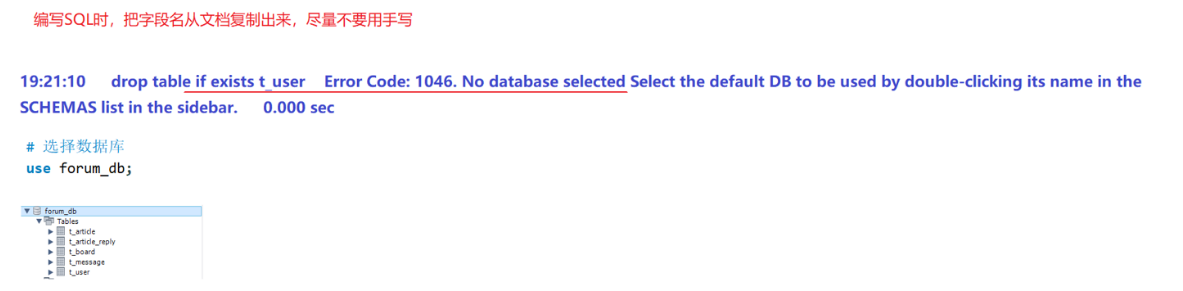
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...