MySQL经典练习50题(上)(解析版)
所有笔记、生活分享首发于个人博客
想要获得最佳的阅读体验(无广告且清爽),请访问本篇笔记
MySQL经典练习50题(上)
创建数据库和表
-- 建 表
-- 学 生 表
CREATE TABLE `Student`(
`s_id` VARCHAR(20),
`s_name` VARCHAR(20) NOT NULL DEFAULT '',
`s_birth` VARCHAR(20) NOT NULL DEFAULT '',
`s_sex` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`s_id`)
);
-- 课程表
CREATE TABLE `Course`(
`c_id` VARCHAR(20),
`c_name` VARCHAR(20) NOT NULL DEFAULT '',
`t_id` VARCHAR(20) NOT NULL,
PRIMARY KEY(`c_id`)
);
-- 教师表
CREATE TABLE `Teacher`(
`t_id` VARCHAR(20),
`t_name` VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY(`t_id`)
);
-- 成绩表
CREATE TABLE `Score`(
`s_id` VARCHAR(20),
`c_id` VARCHAR(20),
`s_score` INT(3),
PRIMARY KEY(`s_id`,`c_id`)
);-- 插 入 学 生 表 测 试 数 据
insert into Student values('01' , '赵雷','1990-01-01','男');
insert into Student values('02' , '钱电','1990-12-21','男');
insert into Student values('03' , '孙风','1990-05-20','男');
insert into Student values('04' , '李云','1990-08-06','男');
insert into Student values('05' , '周梅','1991-12-01','女');
insert into Student values('06' , '吴兰','1992-03-01','女');
insert into Student values('07' , '郑竹','1989-07-01','女');
insert into Student values('08' , '王菊','1990-01-20','女');
-- 课 程 表 测 试 数 据
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
-- 教 师 表 测 试 数 据
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
-- 成 绩 表 测 试 数 据
insert into Score values('01' , '01' , 80);
insert into Score values('01' , '02' , 90);
insert into Score values('01' , '03' , 99);
insert into Score values('02' , '01' , 70);
insert into Score values('02' , '02' , 60);
insert into Score values('02' , '03' , 80);
insert into Score values('03' , '01' , 80);
insert into Score values('03' , '02' , 80);
insert into Score values('03' , '03' , 80);
insert into Score values('04' , '01' , 50);
insert into Score values('04' , '02' , 30);
insert into Score values('04' , '03' , 20);
insert into Score values('05' , '01' , 76);
insert into Score values('05' , '02' , 87);
insert into Score values('06' , '01' , 31);
insert into Score values('06' , '03' , 34);
insert into Score values('07' , '02' , 89);
insert into Score values('07' , '03' , 98);表关系
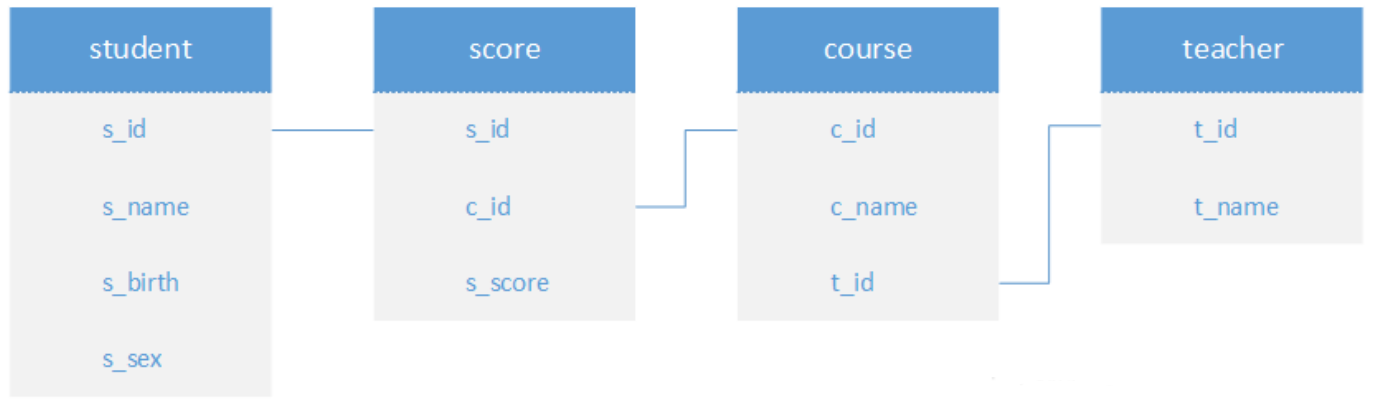
经典50题
查询"01"课程比"02"课程成绩高的学生的信息及课程分数
select s.*,sc1.s_score,sc2.s_score
from student s
join score sc1 on s.s_id=sc1.s_id and sc1.c_id='01'
join score sc2 on s.s_id=sc2.s_id and sc2.c_id='02'
where sc1.s_score>sc2.s_score
需要连接 student 和 score 表,其中 score 表需要连接两次,因为我们需要对比两个课程的成绩。
然后,这将返回一个结果集,其中每一行都包含学生的信息,以及他们对应的 “01” 课程和 “02” 课程的成绩。但是,我们仍然需要进一步筛选那些 “01” 课程比 “02” 课程成绩高的学生。为此,我们需要在 WHERE 子句中添加一个条件
查询“01”课程比“02”课程成绩低的学生的信息及课程分数(题目 1 是成绩高)
select s.*,sc1.s_score,sc2.s_score
from student s
join score sc1 on s.s_id=sc1.s_id and sc1.c_id='01'
join score sc2 on s.s_id=sc2.s_id and sc2.c_id='02'
where sc1.s_score<sc2.s_score
同上
查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
SELECT s.s_id, s.s_name, AVG(sc.s_score) AS avg_score
FROM student s
LEFT JOIN score sc ON s.s_id = sc.s_id
GROUP BY s.s_id
HAVING avg_score >= 60;
先group by分组再用 having过滤
- 连接两个表 student 和 score 表,使用 JOIN 连接, score 表中要和同学表关联。
- 对学生编号进行分组。
- 计算每位学生的平均成绩。
- 筛选出平均成绩大于等于 60 分的学生
查询平均成绩小于 60 分的同学的学生编号和学生姓名和平均成绩(包括有成绩的和无成绩的)
SELECT s.s_id, s.s_name, AVG(IFNULL(sc.s_score, 0)) AS avg_score
FROM student s
LEFT JOIN score sc ON s.s_id = sc.s_id
GROUP BY s.s_id
HAVING avg_score < 60;
ROUND 函数,用于把数值字段舍入为指定的小数位数。
IFNULL 函数是 MySQL 控制流函数之一,它接受两个参数,如果不是 NULL,则返回第一个参数。 否则,IFNULL 函数返回第二个参数。 两个参数可以是文字值或表达式。
- 从 student 表中查询学生编号和学生姓名,使用 LEFT JOIN 连接 score 表,因为有些学生可能没有成绩记录,使用 LEFT JOIN 可以保证这些学生也能被查询到。
- 使用 IFNULL 函数将无成绩的记录的成绩值设为 0,这样可以保证所有学生都有成绩值。
- 使用 AVG 函数计算每个学生的平均成绩。
- 使用 GROUP BY 对学生编号进行分组,以便计算每个学生的平均成绩。
- 使用 HAVING 过滤出平均成绩小于 60 分的学生。
查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
SELECT s.s_id, s.s_name, COUNT(sc.c_id) AS course_count, SUM(sc.s_score) AS total_score
FROM student s
LEFT JOIN score sc ON s.s_id = sc.s_id
GROUP BY s.s_id, s.s_name;
- 从 student 表中查询学生编号和学生姓名,使用 LEFT JOIN 连接 score 表,因为有些学生可能没有选课记录,使用 LEFT JOIN 可以保证这些学生也能被查询到。
- 使用 COUNT 函数计算每个学生的选课总数。
- 使用 SUM 函数计算每个学生所有课程的总成绩。
- 使用 GROUP BY 对学生编号和学生姓名进行分组,以便计算每个学生的选课总数和所有课程的总成绩。
查询”李”姓老师的数量
SELECT COUNT(*) as cnt_name_li
FROM teacher
WHERE t_name like "李%"
- 从 teacher 表中查询所有老师的信息。
- 使用 WHERE 子句过滤出姓”李”的老师,使用 LIKE 运算符和通配符%实现模糊匹配。
- 使用 COUNT 函数计算符合条件的老师数量。
COUNT()函数只计算非 NULL 值,如果要计算 NULL 值,可以使用 COUNT(*)
查询学过”张三”老师授课的同学的信息
SELECT s.*, t.t_name
FROM student s
LEFT JOIN score sc ON s.s_id = sc.s_id
LEFT JOIN course co ON sc.c_id = co.c_id
LEFT JOIN teacher t ON co.c_id = t.t_id
WHERE t.t_name = '张三'
就是字面意思
查询没学过”张三”老师授课的同学的信息
## 查询没学过"张三"老师授课的同学的信息
SELECT s.*
FROM student s
WHERE s.s_id NOT IN (SELECT DISTINCT s.s_idFROM student sINNER JOIN score sc ON s.s_id = sc.s_idINNER JOIN course c ON sc.c_id = c.c_idINNER JOIN teacher t ON c.t_id = t.t_idWHERE t.t_name = '张三'
)
- 从 student 表中查询学生的信息。
- 使用子查询查询学过”张三”老师授课的同学的信息。
- 在子查询中,使用 INNER JOIN 连接 score 表、course 表和 teacher 表,以便查询学过”张三”老师授课的课程的学生信息。
- 使用 DISTINCT 关键字去重,以便查询不重复的学生信息。
- 使用 NOT IN 子句过滤出没学过”张三”老师授课的同学的信息。
- 最终查询结果包括学生的学号和姓名。
查询学过编号为”01”并且也学过编号为”02”的课程的同学的信息
SELECT s.*
FROM student s
INNER JOIN score sc1 ON s.s_id = sc1.s_id AND sc1.c_id = '01'
INNER JOIN score sc2 ON s.s_id = sc2.s_id AND sc2.c_id = '02';
- 从 student 表中查询学生的信息。
- 使用 INNER JOIN 连接 score 表两次,以便查询学过编号为”01”和”02”的课程的学生信息。
- 在第一次 INNER JOIN 中,使用 AND 条件将学生 ID 和课程 ID 进行连接。
- 在第二次 INNER JOIN 中,使用 AND 条件将学生 ID 和课程 ID 进行连接。
- 最终查询结果包括学生的学号和姓名
查询学过编号为”01”但是没有学过编号为”02”的课程的同学的信息
SELECT s.*,sc1.c_id sc1,sc2.c_id sc2
FROM student s
INNER JOIN score sc1 ON s.s_id = sc1.s_id AND sc1.c_id = '01'
LEFT JOIN score sc2 ON s.s_id = sc2.s_id AND sc2.c_id = '02'
WHERE sc2.c_id IS NULL;
- 从 student 表中查询学生的信息。
- 使用 INNER JOIN 连接 score 表,以便查询学过编号为”01”的课程的学生信息。
- 在 INNER JOIN 中,使用 AND 条件将学生 ID 和课程 ID 进行连接。
- 使用 LEFT JOIN 连接 score 表,以便查询没学过编号为”02”的课程的学生信息。
- 在 LEFT JOIN 中,使用 AND 条件将学生 ID 和课程 ID 进行连接。
- 使用 WHERE 子句过滤出没学过编号为”02”的课程的学生信息,即 sc2.c_id 为 NULL 的学生信息。
- 最终查询结果包括学生的学号和姓名。
查询没有学完全部课程的同学的信息
SELECT s.*,count(*) AS cs_count
FROM student s
LEFT JOIN score sc ON s.s_id=sc.s_id
GROUP BY s.s_id
HAVING COUNT(DISTINCT sc.c_id)<(SELECT COUNT(*) FROM course)
GROUP BY 筛选 HAVING 过滤出选课数量小于总课程数的人
查询至少有一门课与学号为”01”的同学所学相同的其他同学的信息
SELECT DISTINCT s.s_id, s.s_name
FROM student s
INNER JOIN score sc ON s.s_id = sc.s_id
WHERE s.s_id <> '01' AND sc.c_id IN
(SELECT c_id FROM score WHERE s_id = '01'
);
首先,找到学号为”01”的同学所选修的课程 ID(c_id)。通过 score 表,查询学号为”01”的同学所学的所有课程 ID。
接下来,找到除了学号为”01”的同学之外,选修了上述查询结果中课程 ID 的其他同学。通过 score 表和 student 表的联结,查询选修了与学号为”01”的同学所学相同课程的其他同学的学生 ID(s_id)。
补充:
s.s_id <> ‘01’表示查询条件,其中<>表示不等于的意思。所以 s.s_id <> ‘01’的意思是要筛选出学生 ID(s_id)不等于’01’的学生。换句话说,它将排除学号为’01’的同学,以保证查询结果只包括除了学号为’01’的同学之外的其他同学的信息
查询和”01”号的同学学习的课程完全相同的其他同学的信息
SELECT *
FROM studentWHERE s_id IN (SELECT s_idFROM scoreWHERE s_id != 1AND c_id IN (SELECT c_id FROM score WHERE s_id = 1)GROUP BY s_idHAVING COUNT(c_id) = (SELECT COUNT(c_id) FROM score WHERE s_id = 1)
)
- student 表和 score 表自我连接,得到所有学生的学号和选课信息。
- 对于学号为”01”的学生,筛选出它所选修的课程信息。
- 排除学号为”01”的学生,得到其他学生的学号和选课信息。
- 将其他学生和”01”学生的选课信息进行匹配,得到和”01”学生选课完全相同的其他学生。
- 对这些学生的信息进行聚合,通过计数器比较这些学生选课的数量是否和”01”学生的一致,得到和”01”学生选课完全相同的其他学生的信息
查询没学过”张三”老师讲授的任一门课程的学生姓名
SELECT stu.s_name
FROM student stu
WHERE stu.s_id NOT IN (SELECT sc.c_idFROM score scINNER JOIN course co on sc.c_id = co.c_idINNER JOIN teacher t on co.t_id = t.t_idWHERE t_name = '张三'
)
- 子查询中,通过 INNER JOIN 将 score、course 和 teacher 三个表连接起来,找到所有由”张三”老师讲授的课程对应的学生编号。
- 在主查询中,使用 NOT IN 语句找到所有没有在子查询中出现过的学生编号。
- 最终查询结果中,只包含学生姓名,而不包含其他信息
查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECT s.s_id, s.s_name, AVG(sc.s_score) as avg_score
FROM student s INNER JOIN score sc ON s.s_id = sc.s_id
WHERE sc.s_score < 60
GROUP BY s.s_id, s.s_name
HAVING COUNT(sc.s_id) >= 2;
1.先使用 JOIN 连接了 student 表和 score 表,以便进行跨表查询。 2.然后使用 WHERE 子句筛选出成绩小于 60 分的记录,代表不及格。 3.接着使用 GROUP BY 对学生的学号和姓名进行分组,方便后续对同一学生的成绩进行平均值计算。 4.最后使用 HAVING 子句筛选出至少有两门不及格课程的学生,并使用 AVG 函数计算出平均成绩。查询结果包括学生的学号、姓名和平均成绩
检索”01”课程分数小于 60,按分数降序排列的学生信息
SELECT s.*,sc.s_score
FROM student s
JOIN score sc ON s.s_id=sc.s_id
WHERE sc.s_score<60 AND sc.c_id = "01"
ORDER BY sc.s_score DESC
- 将学生表和分数表连接
- where 过滤条件
- order by降序输出
按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SELECTs.s_id AS 学号,-- 选取学生表 student 中的 s_id 列并将其重命名为 "学号"s.s_name AS 姓名,-- 选取学生表 student 中的 s_name 列并将其重命名为 "姓名"SUM(CASE c_id WHEN 1 THEN s_score ELSE 0 END) AS 语文,-- 计算学生表 student 中的 s_score 列,c_id 为 1 的行数之和,将其命名为 "语文"SUM(CASE c_id WHEN 2 THEN s_score ELSE 0 END) AS 数学,-- 计算学生表 student 中的 s_score 列,c_id 为 2 的行数之和,将其命名为 "数学"SUM(CASE c_id WHEN 3 THEN s_score ELSE 0 END) AS 英语,-- 计算学生表 student 中的 s_score 列,c_id 为 3 的行数之和,将其命名为 "英语"IFNULL(ROUND(AVG(s_score), 2), 0) AS 平均成绩-- 计算学生表 student 中的 s_score 列的平均值,并将结果四舍五入保留两位小数,若结果为 NULL,则返回 0,并将其命名为 "平均成绩"
FROM student s
LEFT JOIN score sc ON s.s_id = sc.s_id
GROUP BY s.s_id, s.s_name
-- 按照学生表 student 中的 s_id,s.s_name 分组
ORDER BY 平均成绩 DESC;
-- 按照 "平均成绩" 列进行降序排序
看注解
CASE …WHEN…THEN…ELSE… 看作是if else叭
将sum与case结合使用,可以实现分段统计
查询各科成绩最高分、最低分和平均分,以如下形式显示
课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
– 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
selectc.c_id as 课程ID,c.c_name as 课程name,max(s_score) as 最高分,min(s_score) as 最低分,round(avg(s_score), 2) as 平均分,concat(round(sum(case when s_score >= 60 then 1 else 0 end) / count(*) * 100, 2), '%') as 及格率,concat(round(sum(case when s_score between 70 and 80 then 1 else 0 end) / count(*) * 100, 2), '%') as 中等率,concat(round(sum(case when s_score between 80 and 90 then 1 else 0 end) / count(*) * 100, 2), '%') as 优良率,concat(round(sum(case when s_score >= 90 then 1 else 0 end) / count(*) * 100, 2), '%') as 优秀率
from course c
inner join score s on c.c_id = s.c_id
group by c.c_id,c.c_name
concat 表示连接字符的意思
按各科成绩进行排序,并显示排名
SELECT s.s_id,s.s_name,c.c_name,sc.s_score,RANK() OVER (PARTITION BY sc.c_id ORDER BY sc.s_score DESC) AS score_rank
FROM Student AS s
JOIN Score AS sc ON s.s_id = sc.s_id
JOIN Course AS c ON sc.c_id = c.c_id
ORDER BY c.c_name, score_rank;
SELECT s.s_id, s.s_name, c.c_name, sc.s_score, ...:选择学生的学号(s.s_id)、姓名(s.s_name)、课程名称(c.c_name)和成绩(sc.s_score)。RANK() OVER (PARTITION BY sc.c_id ORDER BY sc.s_score DESC) AS score_rank:使用窗口函数RANK()来为每个科目的成绩分配排名。PARTITION BY sc.c_id表示排名是按课程ID分组的,ORDER BY sc.s_score DESC表示成绩高的排名在前。FROM Student AS s:指定查询的主表为Student表,并使用别名s。JOIN Score AS sc ON s.s_id = sc.s_id:通过内连接将Student表和Score表连接起来,以便能够查询到每个学生的成绩。JOIN Course AS c ON sc.c_id = c.c_id:通过内连接将Score表和Course表连接起来,以便能够查询到课程名称。ORDER BY c.c_name, score_rank:对查询结果首先按课程名称进行排序,然后按排名排序。这样,每个科目的学生成绩都会按排名顺序显示。
PARTITION BY是 SQL 中的一个子句,它与窗口函数一起使用,用于指定窗口函数的分区条件。如果需要处理成绩并列的情况,可以将
RANK()替换为DENSE_RANK(),这样即使有成绩相同的情况,排名也不会跳过数字
查询学生的总成绩并进行排名
SELECT s.s_name,SUM(IFNULL(sc.s_score,0)) AS '总成绩',
RANK() OVER(ORDER BY SUM(sc.s_score) DESC) AS '排名'
FROM Student s
LEFT JOIN Score sc ON s.s_id=sc.s_id
GROUP BY s.s_name
- SELECT 子句中使用 RANK 函数计算分组排序排名,窗口函数通常会在 ORDER BY 子句中使用。在这个 SQL 语句中,使用 RANK() OVER (ORDER BY SUM(score.s_score) DESC) AS 排名表示对 SUM(score.s_score)的降序排列。
- 通过 JOIN 将 score 表和 student 表连接,获取每个学生的成绩信息和学生姓名。
- 使用 GROUP BY 这个子句将查询结果分组为每个学生,并用 SUM 聚合函数计算每个学生的总分。
查询不同老师所教不同课程平均分从高到低显示
SELECT t.t_name,c.c_name,AVG(sc.s_score) AS"平均分"
FROM teacher t
LEFT JOIN course c ON t.t_id = c.c_id
LEFT JOIN score sc ON c.c_id = sc.c_id
GROUP BY t.t_name,c.c_name
ORDER BY AVG(sc.s_score) DESCs
这个比较简单就没什么好说的
查询所有课程的成绩第 2 名到第 3 名的学生信息及该课程成绩
SELECT student.s_id, student.s_name, student.s_sex, student.s_birth,score.s_score, course.c_name
FROM (SELECT s_id, c_id, s_score,DENSE_RANK() OVER (PARTITION BY c_id ORDER BY s_score DESC) AS `rank`FROM score
) score
JOIN student ON score.s_id = student.s_id
JOIN course ON score.c_id = course.c_id
WHERE score.`rank` BETWEEN 2 AND 3;
- 首先,我们需要为每个学生在每门课程中的成绩计算排名,为此需要使用窗口函数来计算排名。
- 在 SQL 中,计算排名的方法是使用 ROW_NUMBER() 或 DENSE_RANK() 等窗口函数完成。这里我们使用 DENSE_RANK() 函数,该函数按照指定的顺序为每一行分配一个排名号。
- 在计算排名时,注意到需要在每门课程内进行排名,因此我们需要根据课程编号进行分组,这可以使用 PARTITION BY 关键字来实现。
- 对成绩降序排列,这样排名靠前的成绩排在前面,方便后面筛选排名信息。
- 完成为每门课程内学生成绩的排名计算。
- 接下来,我们需要将排名和学生信息、课程信息进行 JOIN,以便查询出每个学生的详细信息和其在课程中的排名情况。
- 最后,我们需要在上述 SQL 语句基础上增加 WHERE 子句,筛选出排名在第二名和第三名的学生记录
统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
SELECTcourse.c_id, course.c_name,COUNT(IF(s_score BETWEEN 85 AND 100, 1, NULL)) AS '100-85',COUNT(IF(s_score BETWEEN 70 AND 84, 1, NULL)) AS '85-70',COUNT(IF(s_score BETWEEN 60 AND 69, 1, NULL)) AS '70-60',COUNT(IF(s_score BETWEEN 0 AND 59, 1, NULL)) AS '0-60',CONCAT(ROUND(COUNT(IF(s_score BETWEEN 85 AND 100, 1, NULL)) / COUNT(*) * 100, 2), '%') AS '100-85(%)',CONCAT(ROUND(COUNT(IF(s_score BETWEEN 70 AND 84, 1, NULL)) / COUNT(*) * 100, 2), '%') AS '85-70(%)',CONCAT(ROUND(COUNT(IF(s_score BETWEEN 60 AND 69, 1, NULL)) / COUNT(*) * 100, 2), '%') AS '70-60(%)',CONCAT(ROUND(COUNT(IF(s_score BETWEEN 0 AND 59, 1, NULL)) / COUNT(*) * 100, 2), '%') AS '0-60(%)'
FROM course
JOIN score ON course.c_id = score.c_id
GROUP BY course.c_id, course.c_name;
首先,我们需要计算出每门课程中各个分数段(100-85,85-70,70-60,0-60)的学生人数以及每个分数段所占百分比(即分数段的人数占总人数的比例)。这可以通过统计成绩表中不同分数段的学生人数来完成。
为了实现该目标,我们可以使用 IF 函数对每个成绩进行分类,然后将每个分数段中成绩符合要求(如成绩在 85-100 分之间)的学生计数为 1。这样,我们可以通过统计不同成绩分类的总数来获得每个分数段的学生人数。
在查询语句中,我们采用了以下方式统计不同分数段中的学生人数和所占百分比:
- 首先使用 JOIN 连接了学生表(student)、课程表(course)和成绩表(score),按照课程编号进行分组。
- 使用 COUNT 函数和 IF 函数组合的方式来计算各个分数段中成绩符合要求的学生人数,例如:
COUNT(IF(s_score BETWEEN 85 AND 100, 1, NULL)) AS '100-85'SQL该语句用于统计成绩在 85-100 分之间的学生人数,并将统计结果重命名为 “100-85”。
- 将以上计算结果按照课程编号和课程名称进行分组,我们可以获得每门课程中各个分数段的学生人数。
- 使用 ROUND 函数和字符串拼接的方式将每个分数段的百分比表示为一个字符串,这里我们使用 CONCAT 函数对字符串进行拼接,例如:
CONCAT(ROUND(COUNT(IF(s_score BETWEEN 85 AND 100, 1, NULL)) / COUNT(*) * 100, 2), '%') AS '100-85(%)'PLSQL该语句用于将成绩在 85-100 分之间的学生人数转换为百分比,并将转换结果与一个百分号字符串相拼接,形成最终结果,例如 93.45%。
最终查询结果将包含以下列:课程编号(c_id)、课程名称(c_name)、100-85 分数段内的人数(100-85)、85-70 分数段内的人数(85-70)、70-60 分数段内的人数(70-60)、0-60 分数段内的人数(0-60)、各个分数段所占百分比的字符串表示,例如 12.34%(100-85(%))。
查询学生平均成绩及其名次
SELECT s.s_name,ROUND(AVG(sc.s_score),2) AS '平均成绩',
ROW_NUMBER()OVER(ORDER BY AVG(sc.s_score) DESC) AS '排名'
FROM Student s
LEFT JOIN Score sc ON s.s_id=sc.s_id
GROUP BY s.s_name
连接两张表,求平均成绩、排名
按照姓名分组
查询各科成绩前三名的记录
SELECT r.c_name,r.rank_num,s.s_name,r.s_score
FROM
(SELECT c.c_name,sc.s_id,sc.s_score,
ROW_NUMBER()OVER(PARTITION BY c.c_name ORDER BY sc.s_score DESC) AS rank_num
FROM Course c
LEFT JOIN Score sc ON c.c_id=sc.c_id)r
JOIN Student s ON r.s_id=s.s_id and r.rank_num<=3
- 在子查询中对总成绩倒序排名
- 连接学生表后查询前三名
相关文章:
MySQL经典练习50题(上)(解析版)
所有笔记、生活分享首发于个人博客 想要获得最佳的阅读体验(无广告且清爽),请访问本篇笔记 MySQL经典练习50题(上) 创建数据库和表 -- 建 表 -- 学 生 表 CREATE TABLE Student( s_id VARCHAR(20), s_name VARCHAR(2…...

每日一题33:数据统计之广告效果
一、每日一题 返回结果示例如下: 示例 1: 输入: Ads 表: ------------------------- | ad_id | user_id | action | ------------------------- | 1 | 1 | Clicked | | 2 | 2 | Clicked | | 3 | 3 | Viewed…...

52、有边数限制的最短路
有边数限制的最短路 题目描述 给定一个n个点m条边的有向图,图中可能存在重边和自环, 边权可能为负数。 请你求出从1号点到n号点的最多经过k条边的最短距离,如果无法从1号点走到n号点,输出impossible。 注意:图中可…...
Spring boot实现基于注解的aop面向切面编程
Spring boot实现基于注解的aop面向切面编程 背景 从最开始使用Spring,AOP和IOC的理念就深入我心。正好,我需要写一个基于注解的AOP,被这个注解修饰的参数和属性,就会被拿到参数并校验参数。 一,引入依赖 当前sprin…...

MySQL之查询性能优化(四)
查询性能优化 MySQL客户端/服务器通信协议 一般来说,不需要去理解MySQL通信协议的内部实现细节,只需要大致理解通信协议是如何工作的。MySQL客户端和服务器之间的通信协议是"半双工"的,这意味着,在任何一个时刻&#…...

定时任务详解
文章目录 定时任务详解JDK自带第三方任务调度框架java有哪些定时任务的框架为什么需要定时任务定时任务扫表的方案有什么缺点Quartzxxl-jobxxl-job详解 elastic-job 定时任务详解 在定时任务中,操作系统或应用程序会利用计时器或定时器来定期检查当前时间是否达到了…...
)
OnlyOffice DocumentServer 8.0.1编译破解版本(¥100)
OnlyOffice DocumentServer 8.0.1编译破解版本(¥100) 破解20人数限制 更换中文字体 修改源码,根据业务自定义服务 根据源码在本机启动项目,便于开发 将编译好的服务打包docker镜像运行 提供各种docker镜像包&…...

Android 应用权限
文章目录 权限声明uses-permissionpermissionpermission-grouppermission-tree其他uses-feature 权限配置 权限声明 Android权限在AndroidManifest.xml中声明,<permission>、 <permission-group> 、<permission-tree> 和<uses-permission>…...

MATLAB 匿名函数
定义匿名函数定义匿名函数的基本语法如下:示例示例 1:简单数学运算示例 2:字符串操作示例 3:作为参数传递 匿名函数的高级用法使用函数句柄定义多输出函数使用局部变量使用嵌套匿名函数 注意事项 匿名函数( Anonymous…...

Java 新手入门:基础知识点一览
Java 新手入门:基础知识点一览 想要踏入 Java 的编程世界?别担心,这篇文章将用简单易懂的表格形式,带你快速了解 Java 的基础知识点。 一、Java 是什么? 概念解释Java一种面向对象的编程语言,拥有跨平台、…...
三维模型轻量化工具:手工模型、BIM、倾斜摄影等皆可用!
老子云是全球领先的数字孪生引擎技术及服务提供商,它专注于让一切3D模型在全网多端轻量化处理与展示,为行业数字化转型升级与数字孪生应用提供成套的3D可视化技术、产品与服务。 老子云是全球领先的数字孪生引擎技术及服务提供商,它专注于让…...
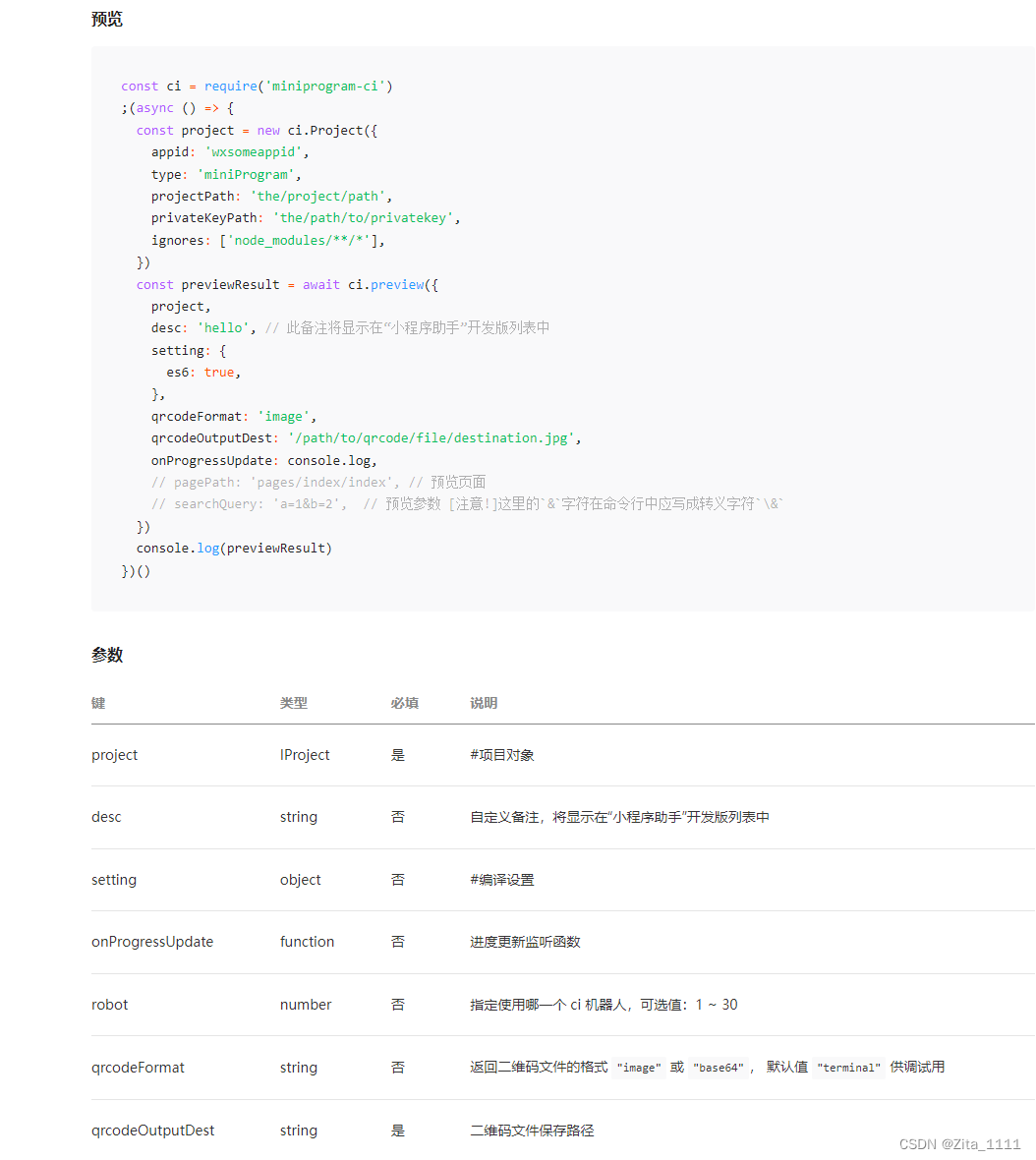
小程序CI/CD之自动化打包预览并钉钉通知发布进程
小程序打包方式分为两种:手动打包、自动打包 那如何实现 自动打包 呐?我们今天就来聊一聊! 首先,很重要,看 官方文档 这里提到今天我们要聊的“主角” miniprogram-ci miniprogram-ci 是从微信开发者工具中抽离的关于…...

C++使用QtHttpServer开发服务端Server的Http POST接口和客户端Client示例
Client HTTP POST 假设http://127.0.0.1:8888/post/是一个能够接受POST请求的路径,我们想要向它提交一段json数据,用Qt可以这样实现: Suppose we want to make an HTTP POST with json body to http://127.0.0.1:8888/post/. QCoreApplica…...
计算机基础(8)——音频数字化(模电与数电)
💗计算机基础系列文章💗 👉🍀计算机基础(1)——计算机的发展史🍀👉🍀计算机基础(2)——冯诺依曼体系结构🍀👉ἴ…...
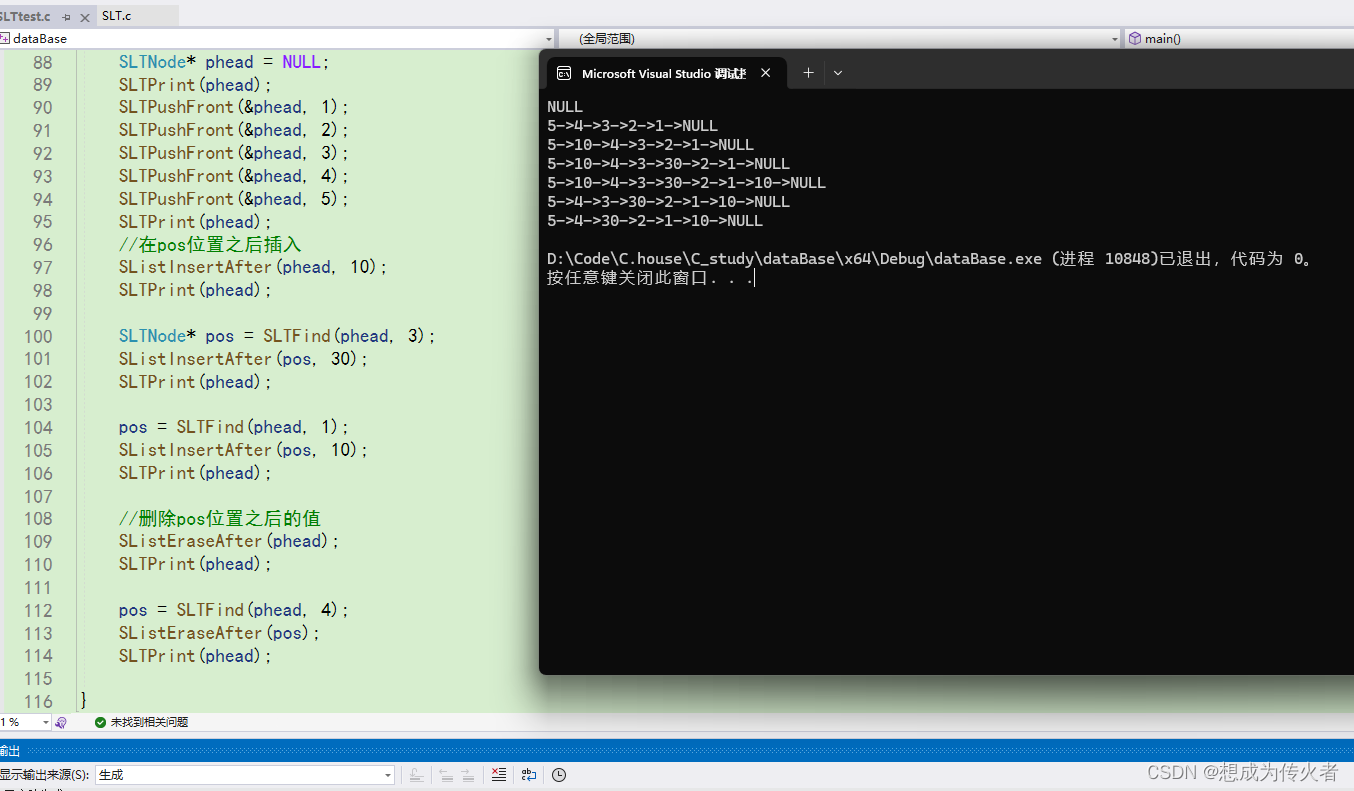
手搓单链表(无哨兵位)(C语言)
目录 SLT.h SLT.c SLTtest.c 测试示例 单链表优劣分析 SLT.h #pragma once#include <stdio.h> #include <assert.h> #include <stdlib.h>typedef int SLTDataType;typedef struct SListNode {SLTDataType data;struct SListNode* next; }SLTNode;//打印…...

代码随想录算法训练营第18天|二叉树
513. 找树左下角的值 最左边的结点的特性 1.只能是叶子结点, 2.必须考虑是最底层,所以要考虑树的深度 3.同样的深度考虑左子树 考虑迭代法,层序遍历 递归优点难搞的 /*** Definition for a binary tree node.* function TreeNode(val, left, righ…...

使用tftpd更新开发板内核
我们升级内核可以通过原厂提供的升级软件来进行,比如瑞芯微的RKDevTool.exe,只不过这种方式必须通过指定的OTG升级口,还得借助按键进入loader模式后才可以。 其实还可以利用一些通用的工具来进行升级,比如tftpd工具。 下载地址p…...

MySQL数据库整体知识点简述
目录 第一章:数据库系统概述 第二章:信息与数据模型 第3章 关系模型与关系规范化理论 第四章——数据库设计方法 第六-七章——MySQL存储引擎与数据库操作管理 第九章——索引 第10章——视图 第11章——MySQL存储过程与函数 第12章——MySQL 触…...
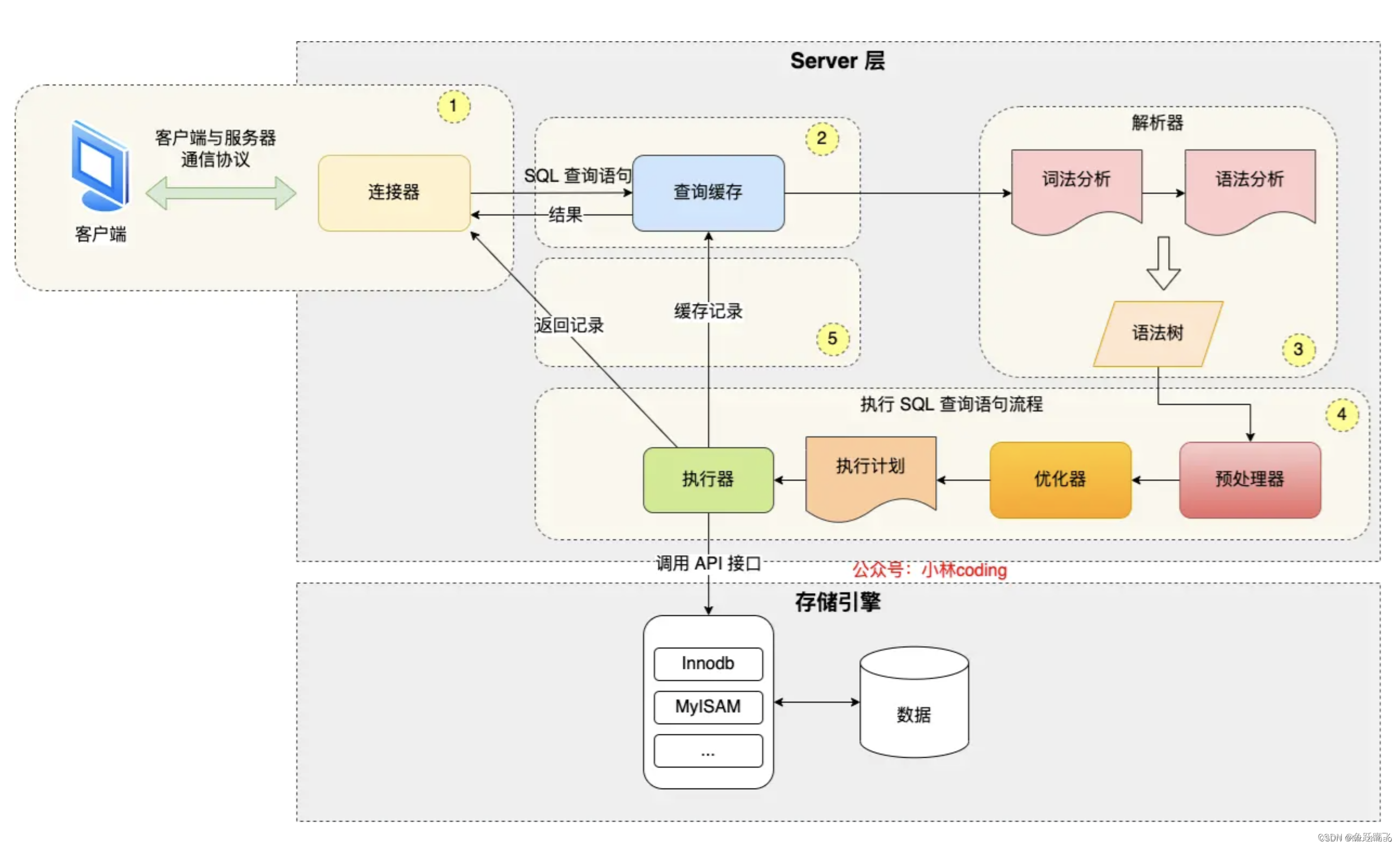
深入理解MySQL索引下推优化
在MySQL中,索引的使用对于查询性能至关重要。然而,即使有合适的索引,有时查询性能仍然不尽如人意。索引下推(Index Condition Pushdown,ICP)是一项能够进一步优化查询性能的技术。本文将详细讲解索引下推的…...
论文降重技巧:AI工具如何助力论文原创性提升?
论文降重一直是困扰各界毕业生的“拦路虎”,还不容易熬过修改的苦,又要迎来降重的痛。 其实想要给论文降重达标,我有一些独家秘诀。话不多说直接上干货! 1、同义词改写(针对整段整句重复) 这是最靠谱也是…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...
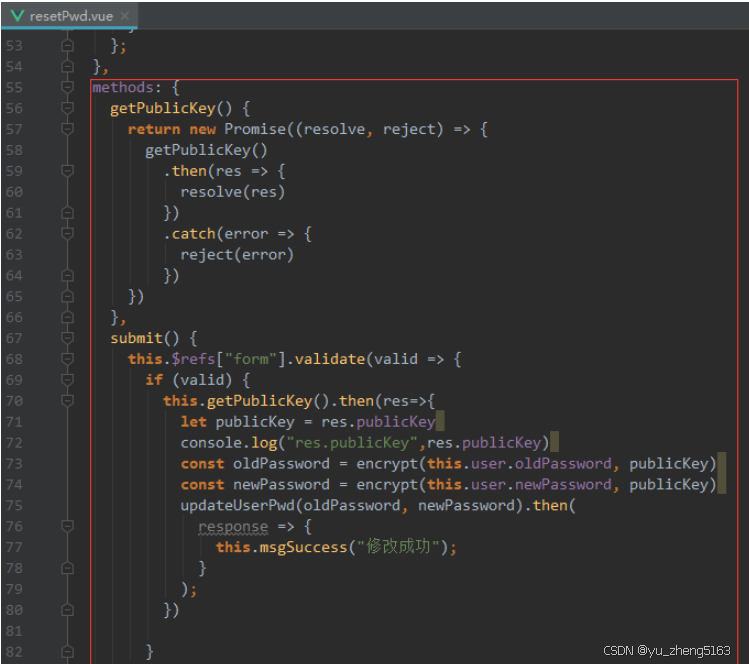
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...
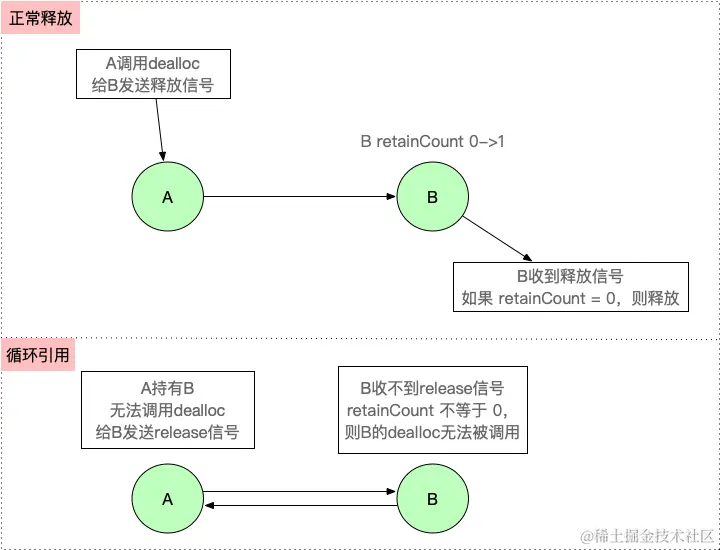
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...