Kafka 消息保留时长由 24 小时变更为 72 小时的影响分析
目录
- Kafka 消息保留时长由 24 小时变更为 72 小时的影响分析
- Kafka 消息存储机制
- 保留时长对生产速度的影响
- 保留时长对消费速度的影响
- 底层分析与优化建议
- 附加:将 Kafka 消息保留时长从 24 小时更改为 72 小时后,CPU 使用率从 40% 上升到 70% 的现象
- 1. 增加的磁盘 I/O 操作
- 2. 页缓存命中率降低
- 3. JVM 垃圾回收(GC)
- 4. Broker 负载增加
- 5. 网络 I/O
- 解决方案和优化建议
- 小总结
- 结论
Kafka 消息保留时长由 24 小时变更为 72 小时的影响分析
在 Kafka 中,消息的保留时长(retention period)决定了消息在 Kafka 集群中的保存时间。默认情况下,消息在主题中的分区内保存一段时间,超过这个时间后,消息将被删除或压缩。将消息保留时长从 24 小时变更为 72 小时对 Kafka 的生产速度和消费速度可能会有一些影响。以下从 Kafka 底层架构和运行机制来分析这些影响。
Kafka 消息存储机制
Kafka 将消息存储在磁盘上,每个主题(Topic)被分为多个分区(Partition),每个分区对应一个日志文件。消息会被追加到日志文件的末尾,Kafka 通过段文件(Segment File)来管理这些日志文件。
- Segment 文件:Kafka 会将每个分区的日志文件分割成多个段文件,这些段文件按时间顺序命名,并根据配置的保留时长进行删除或压缩。
- 索引文件:Kafka 为每个段文件维护了一个索引文件,用于快速查找消息的偏移量(Offset)。
保留时长对生产速度的影响
将消息保留时长从 24 小时增加到 72 小时,会增加 Kafka 集群中存储的消息数量。这对生产速度的影响主要表现在以下几个方面:
-
磁盘空间使用:
- 消息保留时间增加,意味着每个分区需要存储更多的消息,导致磁盘空间的使用增加。
- 如果磁盘空间不足,可能会导致 Kafka 无法继续写入新的消息,进而影响生产速度。
-
磁盘 I/O:
- 增加保留时长不会直接影响单条消息的写入速度,因为消息的写入操作是顺序追加的,Kafka 的设计使得写入速度非常快。
- 但在磁盘空间压力增大的情况下,磁盘 I/O 性能可能会下降,影响生产速度。
-
Segment 文件管理:
- 增加保留时长意味着需要管理更多的段文件,但 Kafka 对段文件的管理是异步进行的,不会直接影响生产速度。
保留时长对消费速度的影响
消费速度主要受到以下几个因素的影响:
-
读取性能:
- 增加保留时长后,消费速度理论上不会直接受到影响,因为消费者从特定的偏移量开始读取消息。
- 但如果消费者需要查找特定时间段的消息,更多的段文件可能会导致查找时间增加,从而间接影响消费速度。
-
磁盘 I/O 和缓存命中率:
- 更多的消息存储在磁盘上,可能会导致 Kafka 的页缓存命中率下降,增加磁盘 I/O 操作。
- 如果大量的消息存储在磁盘上,消费者读取这些消息时需要更多的磁盘读取操作,可能会导致消费速度下降。
-
分区压缩:
- 如果启用了日志压缩(Log Compaction),更多的段文件可能会增加压缩操作的复杂性和频率。
- 压缩操作需要额外的 CPU 和 I/O 资源,可能会间接影响消费速度。
底层分析与优化建议
-
磁盘管理:
- 确保 Kafka 集群有足够的磁盘空间,以应对消息保留时长增加带来的存储需求。
- 监控磁盘使用情况,提前预警并扩容,避免磁盘空间不足导致的写入失败。
-
硬件资源:
- 增加磁盘 I/O 性能,如使用更快的 SSD 磁盘,提高磁盘读写速度。
- 扩大 Kafka Broker 节点的数量,分散负载,提升整体性能。
-
参数调优:
- 合理设置 Kafka 的段文件大小(log.segment.bytes)和滚动策略(log.roll.ms),平衡段文件的数量和大小。
- 调整消费者的 fetch.min.bytes 和 fetch.max.wait.ms 参数,优化消息批量拉取的效率。
-
监控和报警:
- 使用 Kafka 的监控工具(如 Prometheus 和 Grafana)监控集群的性能指标,包括磁盘使用、I/O 性能、消息生产和消费速度等。
- 设置报警规则,及时发现和处理性能瓶颈。
附加:将 Kafka 消息保留时长从 24 小时更改为 72 小时后,CPU 使用率从 40% 上升到 70% 的现象
将 Kafka 消息保留时长从 24 小时更改为 72 小时后,CPU 使用率从 40% 上升到 70% 的现象可能是由多个因素引起的。以下是一些可能的原因及分析:
1. 增加的磁盘 I/O 操作
- 消息保留时长增加:更多的消息需要存储在磁盘上,Kafka 需要管理更多的段文件。这可能会导致磁盘 I/O 操作增加,从而增加 CPU 负载。
- 段文件压缩和清理:Kafka 会定期进行段文件的压缩和清理操作。这些操作需要大量的 CPU 和 I/O 资源。保留时长增加意味着需要处理更多的段文件,增加了压缩和清理的频率和复杂度。
2. 页缓存命中率降低
- 页缓存压力增加:随着保留的消息增多,Kafka 的页缓存压力增加。更多的数据需要频繁从磁盘读取而不是从内存中读取,导致更多的磁盘 I/O 操作,增加了 CPU 的使用率。
3. JVM 垃圾回收(GC)
- 内存管理负担增加:更多的消息保留在内存中,可能会增加 JVM 堆内存的使用。这会导致 JVM 的垃圾回收(GC)频率和时间增加,从而增加 CPU 使用率。
4. Broker 负载增加
- 增加的消费者请求:消费者可能需要处理更多的消息,导致更多的拉取请求(fetch requests),从而增加 Broker 的负载。
- 数据查找时间增加:消费者查找消息的时间增加,增加了 Broker 处理查找请求的时间和 CPU 负载。
5. 网络 I/O
- 数据传输负担:更多的数据需要传输,增加了网络 I/O 负担,间接增加了 CPU 的使用。
解决方案和优化建议
-
监控和分析:
- 使用 Kafka 的监控工具(如 Prometheus 和 Grafana)监控 Kafka 集群的各项性能指标,尤其是 CPU 使用率、磁盘 I/O 和 JVM GC 等。
- 分析 CPU 使用率上升的具体原因,确定是磁盘 I/O、JVM GC 还是其他原因导致。
-
优化硬件资源:
- 考虑使用更快的 SSD 磁盘,以提高磁盘读写速度,减少磁盘 I/O 对 CPU 的负担。
- 增加 Kafka Broker 的数量,分散负载,降低单个 Broker 的压力。
-
调整 Kafka 配置:
- 优化段文件大小(log.segment.bytes)和滚动策略(log.roll.ms),平衡段文件的数量和大小,减少段文件管理带来的 CPU 负担。
- 调整日志清理策略(log.cleaner.enable 和 log.cleaner.threads),减少日志清理操作对 CPU 的影响。
-
优化 JVM 设置:
- 调整 JVM 堆内存大小和垃圾回收策略,减少垃圾回收的频率和时间。
- 使用 G1 GC 或其他适合高并发、高吞吐量场景的垃圾回收器。
-
提高消息消费效率:
- 优化消费者的批量拉取(batch fetching)配置,提高单次拉取的消息数量,减少拉取请求的频率。
- 确保消费者能够高效地处理拉取到的消息,减少消费者处理延迟。
小总结
将 Kafka 消息保留时长从 24 小时增加到 72 小时,可能会导致 CPU 使用率增加,主要原因包括增加的磁盘 I/O 操作、降低的页缓存命中率、JVM 垃圾回收负担增加以及 Broker 负载增加。通过监控和分析具体原因,并优化硬件资源、Kafka 配置和 JVM 设置,可以有效减少 CPU 使用率,确保 Kafka 集群的高效运行。
这篇博客希望能够帮助你理解 Kafka 消息保留时长变更带来的影响,并提供相应的优化方案。如果你有任何疑问或需要进一步的帮助,请随时联系。
结论
将 Kafka 消息保留时长从 24 小时增加到 72 小时,会增加磁盘空间使用量,并可能间接影响生产和消费速度。通过合理的磁盘管理、硬件资源扩展和参数调优,可以有效应对这些影响,确保 Kafka 集群的稳定性和高效运行。
通过以上分析,希望能帮助你更好地理解 Kafka 消息保留时长变更带来的影响,并提供相应的优化方案。
相关文章:

Kafka 消息保留时长由 24 小时变更为 72 小时的影响分析
目录 Kafka 消息保留时长由 24 小时变更为 72 小时的影响分析Kafka 消息存储机制保留时长对生产速度的影响保留时长对消费速度的影响底层分析与优化建议附加:将 Kafka 消息保留时长从 24 小时更改为 72 小时后,CPU 使用率从 40% 上升到 70% 的现象1. 增加…...

MySQL A表的字段值更新为B表的字段值
MySQL A表的字段值更新为B表的字段值 准备数据表 create table person (id int unsigned auto_increment comment 主键 primary key,uuid varchar(32) not null comment 系统唯一标识符32个长度的字符串,mobile varchar(11) null comment 中国国内手机号,nickn…...

TCP 建链(三次握手)和断链(四次握手)
TCP 建链(三次握手)和断链(四次挥手) 背景简介建链(三次握手)断链(四次挥手)序号及标志位延伸问题为什么建立连接需要握手三次,两次行不行?三次握手可以携带数…...

SpringBoot集成JOOQ加Mybatis-plus使用@Slf4j日志
遇到个问题记录下,就是SpringBoot使用Mybatis和Mybatis-plus时可以正常打印日志,但是JOOQ的操作日志确打印不出来? 下面的解决方法就是将JOOQ的日志单独配置出来,直接给你们配置吧! 在项目的resources目录下创建日志…...

浅谈JavaScript中的对象赋值
目录 常见的对象赋值方式 直接赋值和对象扩展(浅拷贝)两种赋值方式区别 区别 联系 常见的对象赋值方式 1. 直接赋值:this.info this.deviceInfo,将一个对象的引用赋给另一个变量,它们引用同一个对象。 2. 对象扩…...

Java面试题-集合
Java面试题-集合 1、什么是集合?2、集合和数组的区别是什么?3、集合有哪些特点?4、常用的集合类有哪些?5、List, Set, Map三者的区别?6、说说集合框架底层数据结构?7、线程安全的集合…...
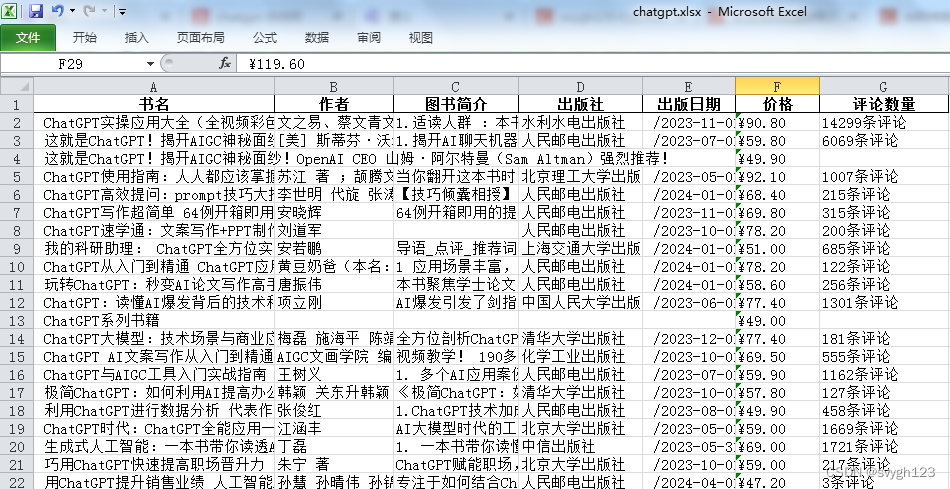
从当当网批量获取图书信息
爬取当当网图书数据并保存到本地,使用request、lxml的etree模块、pandas保存数据为excel到本地。 爬取网页的url为: http://search.dangdang.com/?key{}&actinput&page_index{} 其中key为搜索关键字,page_index为页码。 爬取的数据…...

python爬虫之JS逆向——网页数据解析
目录 一、正则 1 正则基础 元字符 基本使用 通配符: . 字符集: [] 重复 位置 管道符和括号 转义符 转义功能 转义元字符 2 正则进阶 元字符组合(常用) 模式修正符 re模块的方法 有名分组 compile编译 二、bs4 1 四种对象 2 导航文档树 嵌套选择 子节点、…...
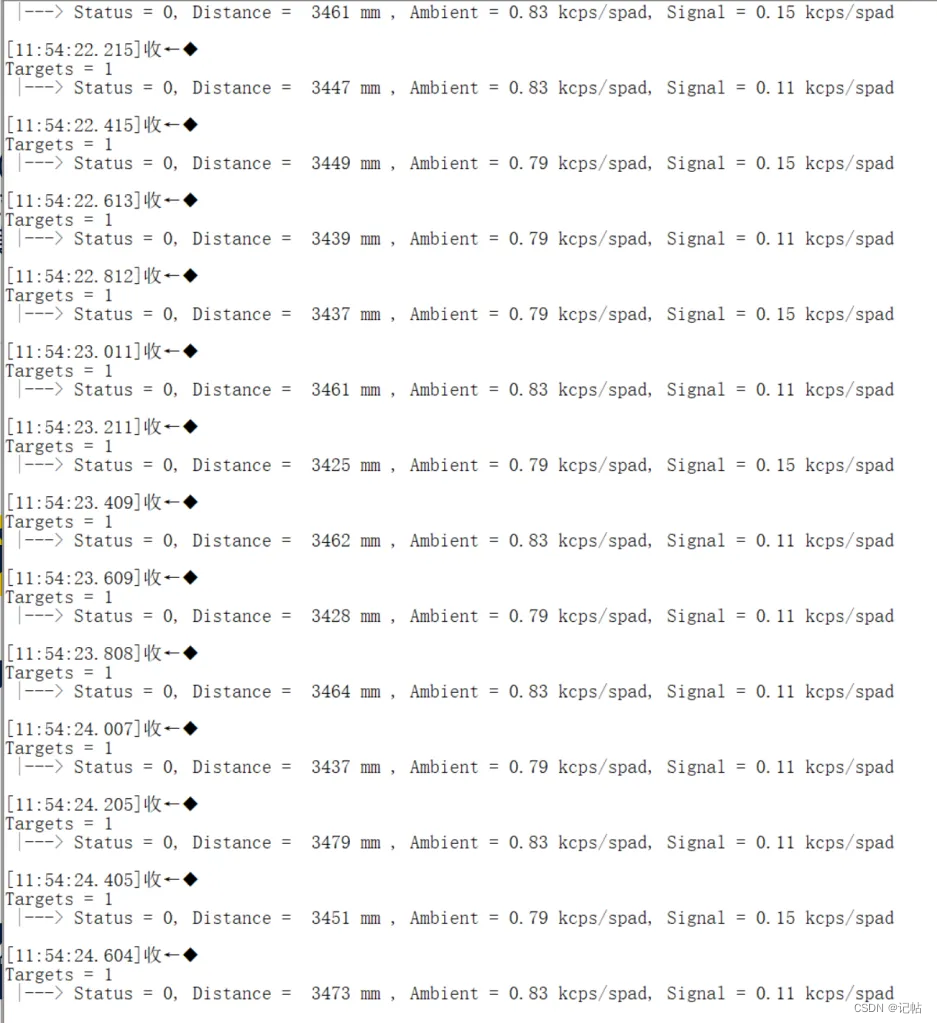
VL53L4CX TOF开发(2)----修改测距范围及测量频率
VL53L4CX TOF开发.2--修改测距范围及测量频率 概述视频教学样品申请完整代码下载测距范围测量频率硬件准备技术规格系统框图应用示意图生成STM32CUBEMX选择MCU串口配置IIC配置 XSHUTGPIO1X-CUBE-TOF1app_tof.c详细解释测量频率修改修改测距范围 概述 最近在弄ST和瑞萨RA的课程…...

C++之noexcept
目录 1.概述 2.noexcept作为说明符 3.noexcept作为运算符 4.传统throw与noexcept比较 5.原理剖析 6.总结 1.概述 在C中,noexcept是一个关键字,用于指定函数不会抛出异常。如果函数保证不会抛出异常,编译器可以进行更多优化,…...
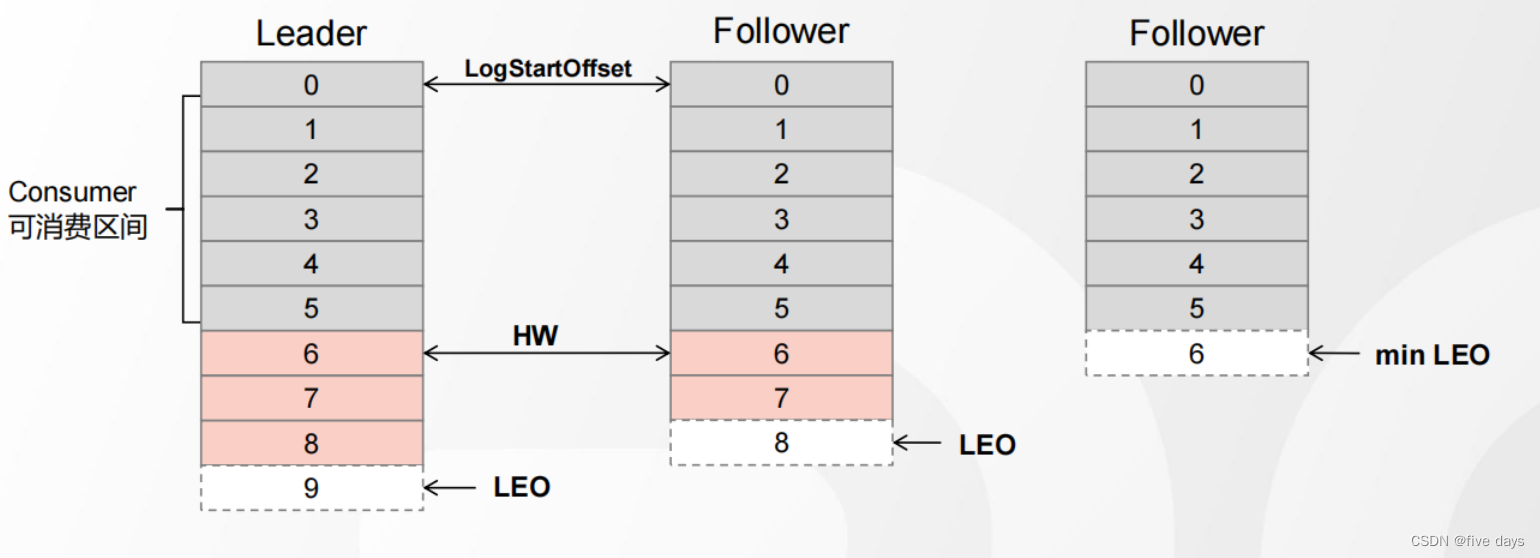
Kafka之Broker原理
1. 日志数据的存储 1.1 Partition 1. 为了实现横向扩展,把不同的数据存放在不同的 Broker 上,同时降低单台服务器的访问压力,我们把一个Topic 中的数据分隔成多个 Partition 2. 每个 Partition 中的消息是有序的,顺序写入&#x…...

RabbitMQ docker安装及使用
1. docker安装RabbitMQ docker下载及配置环境 docker pull rabbitmq:management # 创建用于挂载的目录 mkdir -p /home/docker/rabbitmq/{data,conf,log} # 创建完成之后要对所创建文件授权权限,都设置成777 否则在启动容器的时候容易失败 chmod -R 777 /home/doc…...

篇3:Mapbox Style Specification
接《篇2:Mapbox Style Specification》,继续解读Mapbox Style Specification。 目录 Spec Reference Root 附录: MapBox Terrain-RGB...
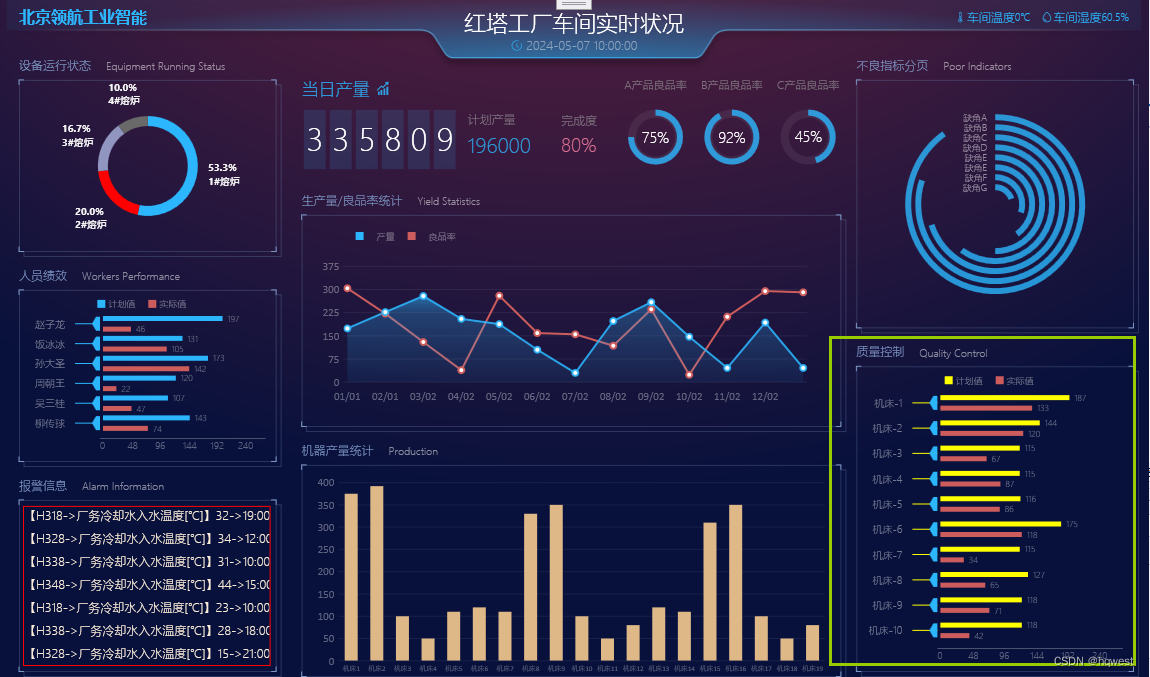
C#WPF数字大屏项目实战11--质量控制
1、区域划分 2、区域布局 3、视图模型 4、控件绑定 5、运行效果 走过路过,不要错过,欢迎点赞,收藏,转载,复制,抄袭,留言,动动你的金手指,财务自由...

第九十七节 Java面向对象设计 - Java Object.Finalize方法
Java面向对象设计 - Java Object.Finalize方法 Java提供了一种在对象即将被销毁时执行资源释放的方法。 在Java中,我们创建对象,但是我们不能销毁对象。 JVM运行一个称为垃圾收集器的低优先级特殊任务来销毁不再引用的所有对象。 垃圾回收器给我们一个…...
【scikit-learn009】异常检测系列:单类支持向量机(OC-SVM)实战总结(看这篇就够了,已更新)
1.一直以来想写下机器学习训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架OCSVM模型相关知识体系。 3.欢迎批评指正,欢迎互三,跪谢一键三连! 4.欢迎…...

网络管理与运维
文章目录 网络管理与运维概念:传统网络管理:基于SNMP集中管理:基于iMaster NCE的网络管理:传统网络管理方式: 基于SNMP集中管理:交互方式:MIB:版本:SNMPv3配置网管平台&a…...

数据库查询字段在哪个数据表中
问题的提出 当DBA运维多个数据库以及多个数据表的时候,联合查询是必不可少的。则数据表的字段名称是需要知道在哪些数据表中存在的。故如下指令,可能会帮助到你: 问题的处理 查找sysinfo这个字段名称都存在哪个数据库中的哪个数据表 SELEC…...

第 400 场 LeetCode 周赛题解
A 候诊室中的最少椅子数 计数:记录室内顾客数,每次顾客进入时,计数器1,顾客离开时,计数器-1 class Solution {public:int minimumChairs(string s) {int res 0;int cnt 0;for (auto c : s) {if (c E)res max(res, …...
数据结构与算法之Floyd弗洛伊德算法求最短路径
目录 前言 Floyd弗洛伊德算法 定义 步骤 一、初始化 二、添加中间点 三、迭代 四、得出结果 时间复杂度 代码实现 结束语 前言 今天是坚持写博客的第18天,希望可以继续坚持在写博客的路上走下去。我们今天来看看数据结构与算法当中的弗洛伊德算法。 Flo…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...
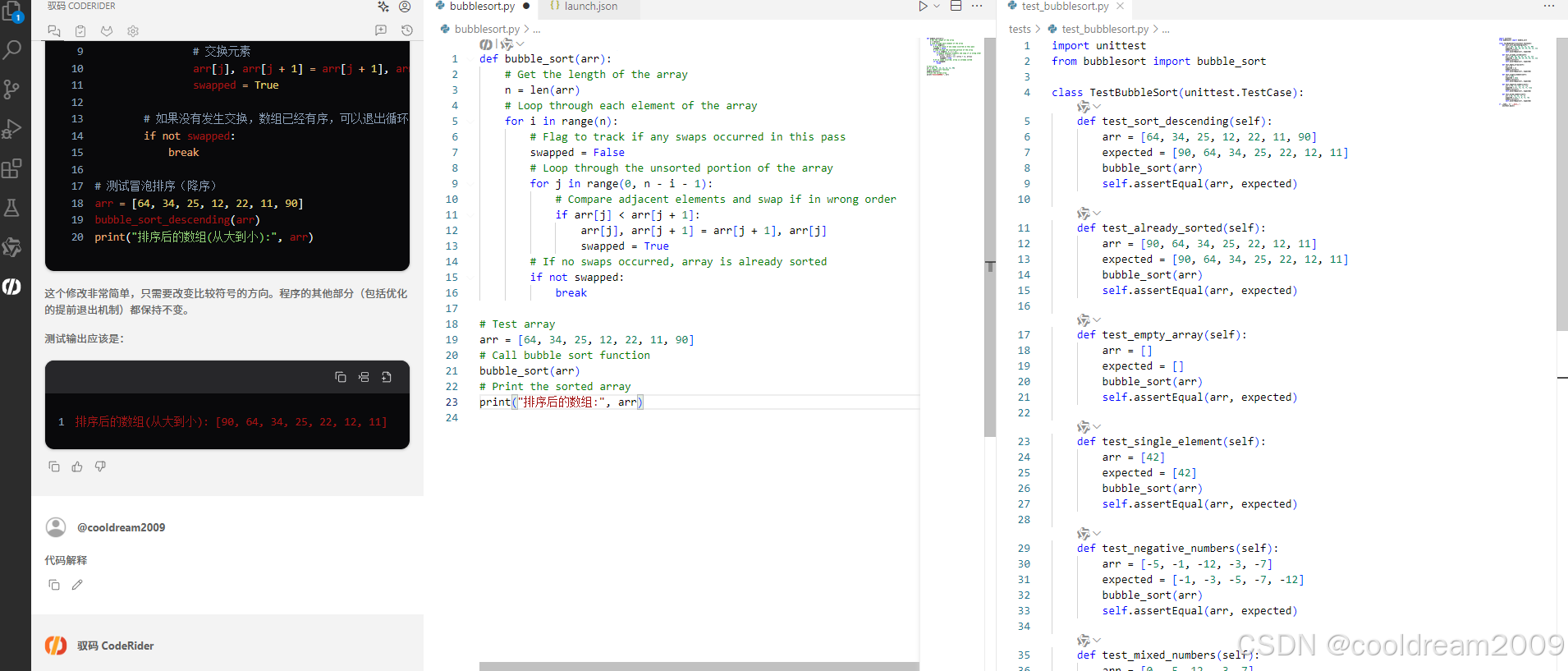
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...