Redis数据结构HyperLogLog以及布隆过滤器
HyperLogLog
引言
在开始之前,先思考一个常见的业务问题:如果负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的UV数据,然后来开发这个统计模块,需要如何实现?
如果统计PV非常好办,给每个网页一个独立的Redis计数器即可,这个计数器的key后缀加上当天的日期。这样每次一个请求,incrby一次,最终就可以统计出所有的PV数据。
但是UV不一样,他要去重,同一个用户一天之内的多次访问请求只能计数一次,这就要求每一个网页请求都需要带上用户ID。无论是登录用户还是未登录用户都需要一个唯一ID来标识。也许你已经想到了一个简单的方案,那就是为每一个页面设置一个独立的set集合来存储所有当天访问过此页面的用户ID,当一个请求过来时,使用sadd将用户ID塞进去即可,通过scard可以取出这个集合的大小,这个数字就是这个页面的UV数据。
但是,如果页面的访问量非常大,比如一个爆款页面几千万的UV,此时就需要一个很大的set集合来统计,这非常浪费空间。如果这样的页面很多,那么所需要的存储空间是惊人的。为了这样一个去重功能耗费如此多的存储空间,其结果必然是不值得。其实,老板需要的数据不需要太精确,105w和106w这两个数字对于老板们来说并没有多大区别,因此,需要探讨一种更好的解决方案。
因此,本文主要讨论,Redis提供的HyperLogLog来解决这个问题。HyperLogLog提供不精确的去重计数方案,其标准误差是0.81%,这样的精确度足够满足很多UV需求。
使用方法
HyperLogLog提供了两个指令pfadd和pfcount,一个是增加计数,一个是获取计数。pfadd用法和set集合的sadd一样,来一个用ID,就将用户ID塞进去即可。pfcount和scard用法一样,直接获取计数值。
127.0.0.1:6379> pfadd codehole user1
(integer) 1
127.0.0.1:6379> pfcount codehole
(integer) 1
127.0.0.1:6379> pfadd codehole user2
(integer) 1
127.0.0.1:6379> pfcount codehole
(integer) 2
127.0.0.1:6379> pfadd codehole user3 user4 user5 user6
(integer) 6
简单试了一下,发现还蛮精确的,一个没多一个也没少,接下来,使用脚本,灌入更多的数据,看看是否还可以继续精确下去,如果不能精确,差距有多大。
public class PfTest {public static void main(String[] args) {Jedis jedis = new Jedis();for (int i = 0; i < 100000; i++) {jedis.pfadd("codehole", "user" + i);long total = jedis.pfcount("codehole");if (total != i + 1) {System.out.printf("%d %d\n", total, i + 1);break;}}jedis.close();}
}
当加入10w数据的时候,输出结果为99723,差了277,按照百分比是0.277%。当再次运行这个脚本的时候输出结果仍然是99723(redis运行过一次已经存在数据的情况下),说明他确实具备去重功能。
pfmerge
HyperLogLog除了上面的pfadd和pfcount之外,还提供了第三个指令pfmerge,用于将多个pf计数值累加在一起形成一个新的pf值。比如在网站中我们有两个内容差不多的页面,需要将这两个页面的数据进行合并,其中页面的UV访问量也需要合并,那么这个时候pfmerge就可以派上用场。
布隆过滤器
引言
上文讲述了使用HyperLogLog数据结构来进行估数,可以解决很多精确度不高的统计需求。但是,如果我们想知道某一个值是不是已经在HyperLogLog结构里面了,他就无能为力,他只提供pfadd和pfcount方法,没有提供pfcontains方法。
举个使用场景,我们在使用新闻客户端看新闻时,他会给我们不停的推荐新的内容,他每次推荐时要去重,去掉那些已经看过的内容。新闻客户端的推荐系统如何实现推送去重?
很容易想到服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。问题是当用户量很大,每个用户看过的新闻又很多的情况下,这种方式,推荐系统的去重工作在性能上跟得上吗?

实际上,如果历史记录存储在关系数据库里,去重就需要频繁的对数据库进行exists查询,当系统并发量很高时,数据库是很难扛住压力的。
如果将如此多的历史记录全部缓存起来,那得浪费多大存储空间。而且这个存储空间是随着时间线性增长,很难长时间撑的住。但是不缓存的话,性能又跟不上,此时该如何解决。
这时,布隆过滤器(Bloom Filter)闪亮登场,他就是专门用来解决去重问题的。他在起到去重的同时,在空间上还能节省90%以上,只是稍微有点不精确,也就是有一定的误判概率。
布隆过滤器是什么
布隆过滤器可以理解为一个不怎么精确的set结构,当使用它的contains方法判断某个对象是否存在时,他可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合适,他的精确度可以控制的相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当他说不存在时,那就肯定不存在。套在上面的使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,他也会过滤掉极小一部分,但是绝大多数心能容他都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
Redis中的布隆过滤器
Redis官方提供的布隆过滤器到了Redis4.0提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到Redis Server中,给Redis提供了强大的布隆去重功能。
布隆过滤器基本使用
布隆过滤器有三个基本指令,bf.add添加元素,bf.exists查询元素是否存在,他的用法和set集合的sadd和sismember差不多。bf.add一次只能添加一个元素,如果想要一次添加多个,就需要用到bf.madd指令。同样如果需要一次查询多个元素是否存在,就需要使用bf.mexists指令。
127.0.0.1:6379> bf.add codehole user1
(integer) 1
127.0.0.1:6379> bf.add codehole user2
(integer) 1
127.0.0.1:6379> bf.add codehole user3
(integer) 1
127.0.0.1:6379> bf.exists codehole user1
(integer) 1
127.0.0.1:6379> bf.exists codehole user2
(integer) 1
127.0.0.1:6379> bf.exists codehole user4
(integer) 0
代码测试
public class BloomTest {public static void main(String[] args) {Client client = new Client();client.delete("codehole");for (int i = 0; i < 100000; i++) {client.add("codehole", "user" + i);boolean ret = client.exists("codehole", "user" + (i + 1));if (ret) {System.out.println(i);break;}}client.close();}
}
运行后,可以看到输出214,即到第214的时候,就出现了误判。那么如何测量误判率呢?我们先随机出一堆字符串,然后切分为2组,将其中一组塞入布隆过滤器,然后判断另外一组的字符串存在与否,取误判的个数和字符串总量一半的百分比作为误判率。
代码如下:
pom中添加依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.9.0</version></dependency><dependency><groupId>com.redislabs</groupId><artifactId>jrebloom</artifactId><version>2.2.2</version></dependency>
package example;
import io.rebloom.client.Client;
import redis.clients.jedis.Jedis;class BloomRedis {private Client client;private Jedis jedis;private int capacity = 20000;// 容错率,只能设置0 < error rate range < 1 不然直接会异常!private double errorRate = 0.01;public BloomRedis() {jedis = new Jedis("127.0.0.1", 6379);client = new Client(jedis);}public void count(String key) {if (!jedis.exists(key)) {client.createFilter(key, capacity, errorRate);}int realCapacity = 20000;for (int i = 0; i < realCapacity; i++) {client.bfInsert(key, String.valueOf(i));}System.out.println("存入元素为=={" + realCapacity + "}");// 统计误判次数int count = 0;// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率for (int i = capacity; i < realCapacity * 2; i++) {if (client.exists(key, String.valueOf(i))) {count++;}}System.out.println("误判元素为=={" + count + "}");// 删除过滤器client.delete(key);}
}
class ExampleTest {public static void main(String[] args) {BloomRedis bloomRedis = new BloomRedis();bloomRedis.count("codehole");}
}
输出结果:
存入元素为=={20000}
误判元素为=={174}
设置处理容量为20000,容错率为0.01的情况下,输出结果最终错误率为0.0087。
一组其他测试数据
//当realCapacity为5000,capacity 20000,错误率为0
//当realCapacity为10000,capacity 20000,错误率为0
//当realCapacity为20000,capacity 20000,错误率为0.08
//当realCapacity为40000,capacity 20000,错误率为0.5
//当realCapacity为40000,capacity 80000,错误率为0
注意事项
布隆过滤器的initial_size估计的越大,会浪费存储空间,估计的过小,就会影响准确率,用户在使用之前一定要尽可能的精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会高出估计值很多。
布隆过滤器的error_rate越小,需要的存储空间越大,对于不需要过于精确的场合,error_rate设置稍大一点也无伤大雅。比如在新闻去重上而言,误判率高一点只会让小部分文章不能让合适的人看到。文章的整体阅读量不会因为这点误判率就带来巨大的改变。
布隆过滤器原理
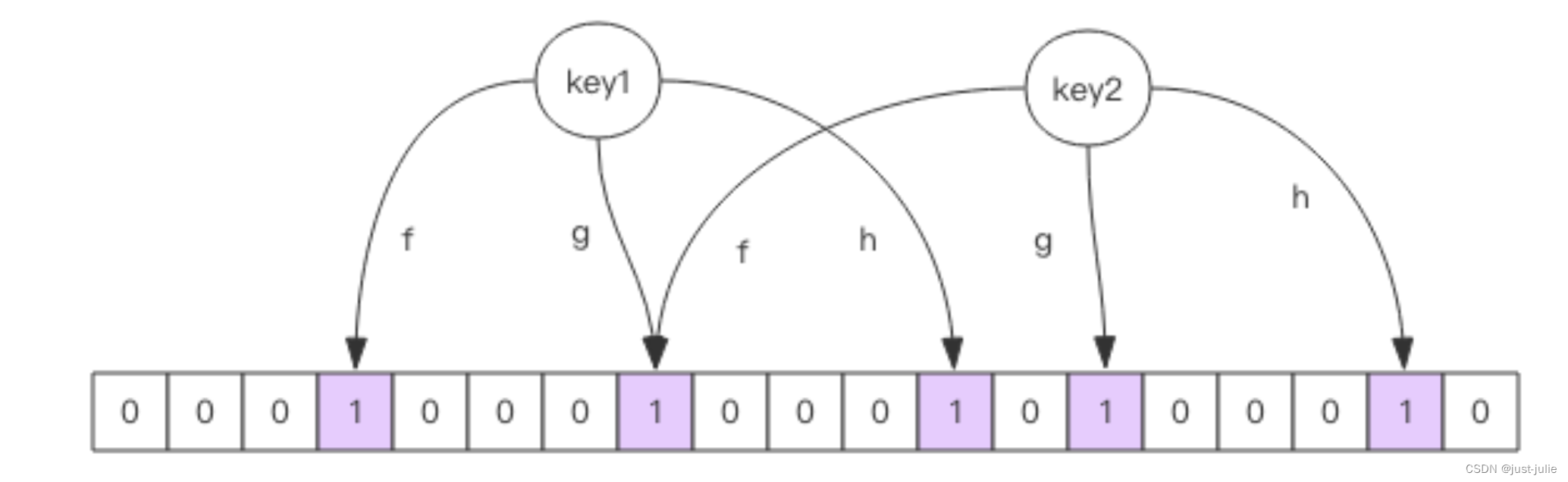
每个布隆过滤器对应到Redis的数据结构里面就是一个大型的位数组和几个不一样的无偏hash函数。所谓无偏就是能够把元素的hash值算的比较均匀。
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash算的一个整数索引值然后对位数组长度进行取模运算得到一个位置。每个hash函数都会算得一个不同的位置,再把位数组的这几个位置都置为1,就完成了add操作。
向布隆过滤器询问key是否存在时,跟add一样,也会把hash的几个位置(对一个值进行多次hash,每次hash计算得出在位数组中的一个索引,多个hash得到多个索引,每个索引位置在位数组中都是1那这个值就是存在)都算出来,看看位数组中这几个位置是否都为1.只要有一个为0,那么说明布隆过滤器这个key不存在。如果都是1,这不能说明这个key一定存在,只是极有可能存在,因为这些位置为1可能是因为其他的key存在所致。
使用时不要让实际元素大于初始化大小,当实际元素开始超出初始化大小时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器。再将所有的历史元素批量add进去(这就要求我们在其他的存储器中记录所有的历史数据)。因为error_rate不会因为数量超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
空间占用估计
布隆过滤器有两个参数,第一个是预计元素的数量n,第二个是错误率f。公示根据这两个输入得到两个输出,第一个输出是位数组的长度1,也就是需要的存储空间大小(bit),第二个输出是hash函数的最佳数量k。hash函数的数量也会直接影响到错误率,最佳的数量会有最低的错误率。
k = 0.7 * (1/n)
f = 0.6185 ^ (1/n)
从公式中可以看出
- 位数组相对越长(1/n),错误率 f 越低,这个和直观上理解一致。
- 位数组相对越长(1/n),hash函数需要的最佳数量也越多,影响计算效率。
- 当一个元素平均需要1个字节(8bit)的指纹空间时(1/n =8),错误率大约为0.02.
- 错误率为10%,一个元素需要的平均指纹空间为4.792个bit,大约为5 bit.
- 错误率为1%,一个元素需要的平均指纹空间为9.585个bit,大约为10 bit。
- 错误率为 0.1%,一个元素需要的平均指纹空间为 14.377 个 bit,大约为 15 bit。
此时,也许会想,如果一个元素需要占据15个bit,那相对set集合的空间优势是不是就没有那么明显了?这里需要明确的是,set会存储每个元素的内容,而布隆过滤器仅仅存储元素的指纹。元素的内容大小就是字符串的长度,他一般会有多个字节,甚至是几十个字节,每个元素还需要一个指针被set集合来引用,这个指针又会占去4个字节或者8个字节,取决于系统是32bit还是64bit。而指纹空间只有接近2个字节,所以布隆过滤器的优势还是非常明显的。
推荐使用布隆过滤器计算需要提供的存储空间。
实际元素超出时,误判率会怎样变化
当实际元素超出预计元素时,误判率变化需要引用下述计算公式。引入参数 t 表示实际元素和预计元素的倍数 t。
f = (1-0.5^t )^k. #极限近似,k是hash函数的最佳数量
当t增大时,错误率 f 也会跟着增大,分别选择错误率为 10%,1%,0.1%的k值,观察他的曲线
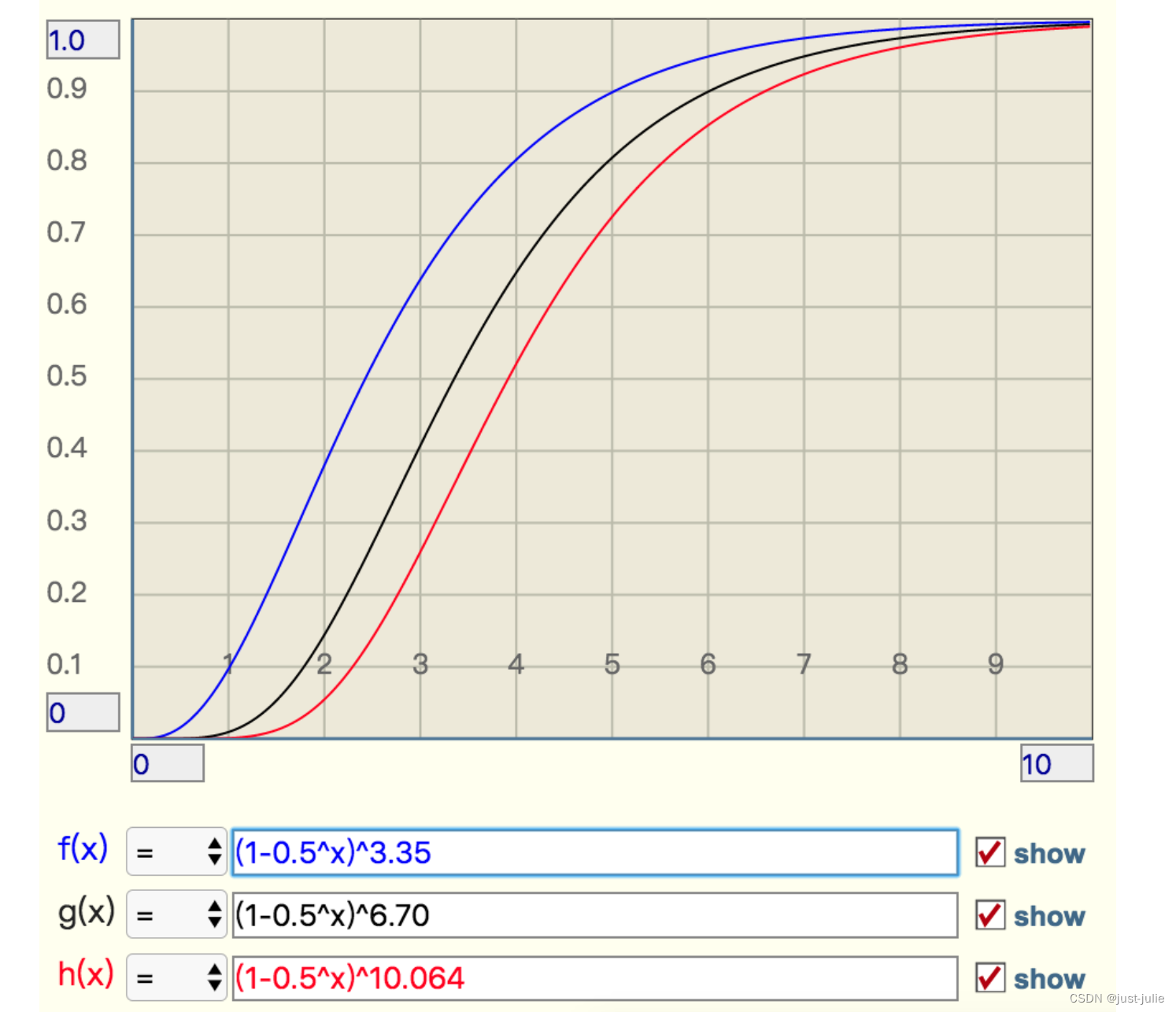
从这个图中可以看出曲线还是比较陡峭的
错误率为10%时,倍数比为2时,错误率就会升至40%,这就比较危险了
错误率为1%时,倍数比为2时,错误率升至15%。
错误率为0.1%,倍数比为2时,错误率升至5%。
布隆过滤器的其他应用
在爬虫系统中,我们需要对URL进行驱虫,已经爬过的网页就可以不用爬了,但是URL太多了,几千万几个亿。如果用一个集合装下这些URL地址那是非常浪费空间的,这时候就可以考虑使用布隆过滤器,他可以大幅降低去重存储消耗,只不过也会使得爬虫系统错误少量的页面。
布隆过滤器在NoSql数据库领域使用非常广泛,我们平时用到的Hbase、Cassandra还有LevelDB、RocksDB内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库IO请求数量,当用户来查询某个row时,可以先通过内存中的布隆过滤器过滤掉大量不存在的row请求,然后再去磁盘进行查询。
邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮箱目录中,这个就是误判所致,概率很低。
相关文章:
Redis数据结构HyperLogLog以及布隆过滤器
HyperLogLog 引言 在开始之前,先思考一个常见的业务问题:如果负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的UV数据,然后来开发这个统计模块,需要如何实现? 如果统计PV非常好办&…...
C++——从C语言快速入门
目录 一、数组 1、声明数组 2、初始化数组 3、访问数组元素 4、示例 5、注意事项 6、数组小练习 计算器支持加减乘除 数组找最大值 二、指针 三、字符串 string 类型 一、数组 在 C 中,数组是一种存储固定大小的相同类型元素的序列。数组的所有元素都存…...

thinkpad T440p ubuntu-slam软件安装记录
安装问题 1.ubuntu20.04安装后提示"x86/cpu:VMX(outside TXT) disabled by BIOS" 这是虚拟化被禁止了,到BIOS里去把Virtualization选项打开即可。 2.ACPI Error:Needed type[Reference],found [Integer] 等错误 link这篇博客中提到该问题,…...
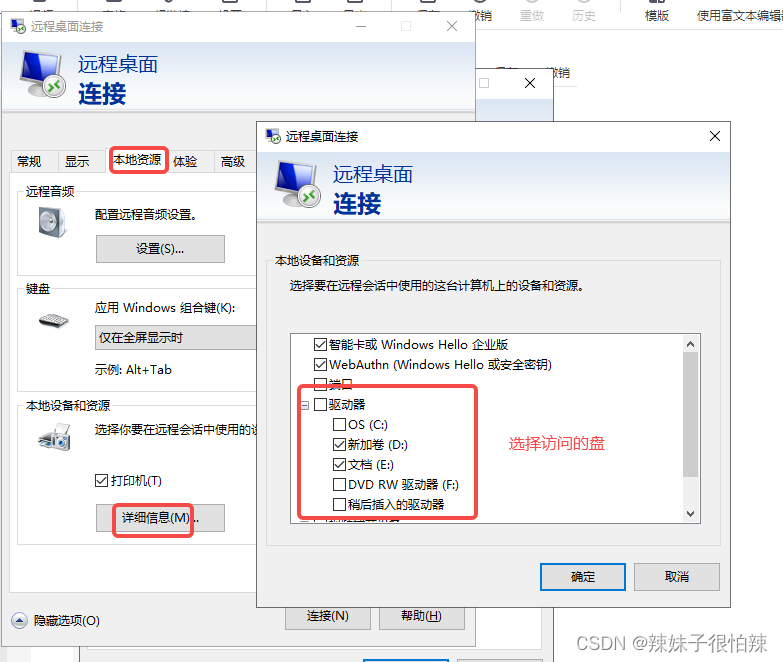
本地电脑访问windows server系统服务器 并传输文件
1、 mstsc 命令打开远程桌面连接。 2、填入登入的用户密码,在本地资源中设置需要共享的盘。登入成功后就可以在服务器与本地电脑互传文件了。...
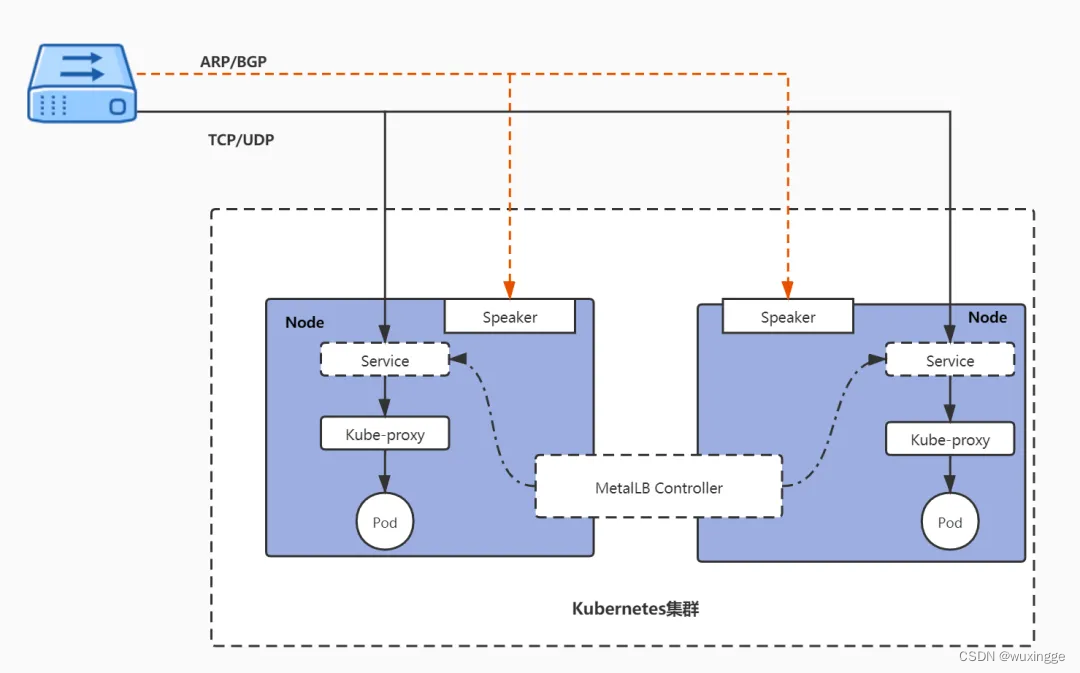
kubernetes负载均衡---MetalLB
https://github.com/metallb/metallb 参考 : https://mp.weixin.qq.com/s/MBOWfcTjFMmgJFWw-FIk0Q 自建的Kubernetes集群,默认情况下是不支持负载均衡的。当需要提供服务的外部访问时,可使用 Ingress、NodePort等方式。他们都存在一些问题 …...
)
Python面试宝典:Python中与设计模式相关的面试笔试题(1000加面试笔试题助你轻松捕获大厂Offer)
Python面试宝典:1000加python面试题助你轻松捕获大厂Offer【第二部分:Python高级特性:第二十二章:代码设计和设计模式:第二节:设计模式】 第二十二章:代码设计和设计模式第二节:设计模式创建型模式结构型模式行为型模式python中与设计模式相关的面试笔试题面试题1面试题…...
以sqlilabs靶场为例,讲解SQL注入攻击原理【18-24关】
【less-18】 打开时,获取了自己的IP地址。,通过分析源码知道,会将用户的user-agent作为参数记录到数据库中。 提交的是信息有user-Agent、IP、uname信息。 此时可以借助Burp Suite 工具,修改user_agent,实现sql注入。…...
【已有项目版】uniapp项目发版pda -- Android Studio
必备资料清单: 构建完成的app项目 在HBuilderX开发的uniapp项目 .keystore文件 文章目录 1. 安装Android Studio:https://developer.android.google.cn/studio?hlzh-cn2. 安装Android 离线SDK:https://nativesupport.dcloud.net.cn/AppDocs…...

三维重建,谁才是顶流?
3DGS技术是近年来计算机视觉领域最具突破性的研究成果之一。它不仅在学术界引起了广泛关注,成为计算机视觉、SLAM等领域的研究热点,而且每天都有大量基于Gaussian Splatting的新研究问世。此外,3DGS技术在商业应用方面也取得了显著进展&#…...
s32k314【入门新手篇】-开发环境安装【ds32开发平台】
软件包下载 登录nxp官网下载:https://www.nxp.com/ 然后输入关键字:S32 查看 下载安装包 以上三步请先注册好并登录你的个人账号 下载完之后如下: 软件安装 eb安装并激活【试用版】 激活 2 安装ds 弹出什么就安装什么就好了。 …...
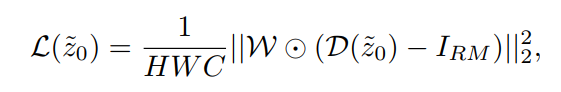
DiffBIR论文阅读笔记
这篇是董超老师通讯作者的一篇盲图像修复的论文,目前好像没看到发表在哪个会议期刊,应该是还在投,这个是arxiv版本,代码倒是开源了。本文所指的BIR并不是一个single模型对任何未知图像degradation都能处理,而是用同一个…...
基于STM32的位置速度环PID控制伺服电机转动位置及程序说明
PID控制原理 PID控制原理是一种广泛应用于工业自动化和其他领域的控制算法。PID控制器的名字来源于其三个主要组成部分:比例(Proportional)、积分(Integral)和微分(Derivative)。PID控制器实现…...

操作失败——后端
控制台观察,页面发送的保存菜品的请求 返回的response显示: ---------- 我开始查看明明感觉都挺正常,没啥错误,就是查不出来。结果后面电脑关机重启后,隔一天看,就突然可以了。我觉着可能是浏览器的缓存没…...

基于SSM的“学校访客登记系统”的设计与实现(源码+数据库+文档)
基于SSM的“学校访客登记系统”的设计与实现(源码数据库文档) 开发语言:Java 数据库:MySQL 技术:SSM 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 平台架构图 系统首页 校园公告信息界面 留言板管理界面 家庭来…...

linux配置IP、子网掩码、网关
linux虚拟机配置IP、子网掩码、网关 本方法适用于 Ubuntu 18.04 之后的版本。 例1: 配置信息: IP:10.100.100.23 子网掩码:255.255.255.240 网关:10.100.100.56 1、打开网络配置文件 01-network-manager-all.yaml sudo vi /etc/netplan/01-network-…...
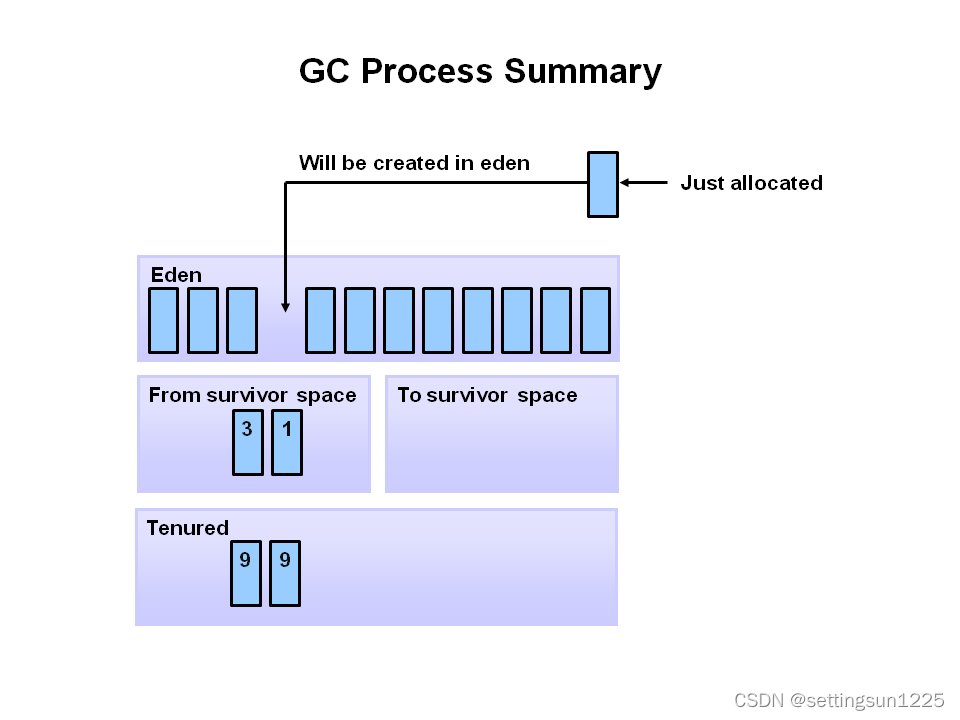
Java 垃圾回收
文章目录 1 Java 垃圾回收1.1 JVM1.2 Java 对象生命周期 2 如何判断一个对象可被回收2.1 引用计数算法2.2 可达性分析算法 3 垃圾回收过程3.1 总体过程3.2 为什么要进行世代垃圾回收?3.3 分代垃圾回收过程 在 C 和 C 中,许多对象要求程序员声明他们后为其…...

多客陪玩系统-开源陪玩系统平台源码-支持游戏线上陪玩家政线下预约等多场景应用支持H5+小程序+APP
多客陪玩系统-开源陪玩系统平台源码-支持游戏线上陪玩家政按摩线下预约等多场景应用支持H5小程序APP 软件架构 前端:Uniapp-vue2.0 后端:Thinkphp6 前后端分离 前端支持: H5小程序双端APP(安卓苹果) 安装教程 【商业…...
书生·浦语大模型全链路开源体系-笔记作业2
全部写成了shell脚本,可以一键执行。 笔记: 1. 环境安装(InternStudio开发机) # 1. 创建conda环境 studio-conda -o internlm-base -t demo # 2. 激活conda环境 conda activate demo # 3. 安装额外的依赖 pip install huggingface-hub0.17.3 pip inst…...

手把手教你发布你的第一个npm插件包
在开源的世界里,npm(Node Package Manager)不仅是JavaScript生态中不可或缺的一部分,也是全球最大的软件注册表,它使得分享和复用代码变得异常简单。如果你有一个很棒的想法或者实用的功能想要封装成一个npm包供他人使…...

Docker-compose 编排lnmp(dockerfile) 完成Wordpress
一、部署 Nginx 镜像 1. 建立工作目录 mkdir /opt/lnmp/nginx -pcd /opt/lnmp/nginx#上传 nginx 安装包 nginx-1.12.0.tar.gz#上传 wordpress 服务包 wordpress-4.9.4-zh_CN.tar.gz mkdir /opt/lnmp/nginx/htmltar zxvf wordpress-4.9.4-zh_CN.tar.gz -C /opt/lnmp/nginx/html…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...