【Python】多线程与多进程学习笔记
本文是一篇学习笔记,学习内容主要来源于莫凡python的文档:https://mofanpy.com/tutorials/python-basic/threading/thread
多线程
线程基本结构
开启子线程的简单方式如下:
import threadingdef thread_job():print('This is a thread of %s' % threading.current_thread())def main():thread = threading.Thread(target=thread_job, ) # 定义线程thread.start() # 让线程开始工作if __name__ == '__main__':main()
线程阻塞
下面是一个双线程的示例,期望效果是先运行完两个子线程,再输出all done。
import threading
import timedef T1_job():print("T1 start\n")for i in range(10):time.sleep(0.1)print("T1 finish\n")def T2_job():print("T2 start\n")print("T2 finish\n")if __name__ == '__main__':thread_1 = threading.Thread(target=T1_job, name='T1')thread_2 = threading.Thread(target=T2_job, name='T2')thread_1.start() # 开启T1thread_2.start() # 开启T2print("all done\n")
输出:
T1 start
T2 start
all done
T2 finish
T1 finish
实际结果发现,主线程没有“等待”子线程执行完就已经结束。
为了达到预期效果,需要通过join()方法来设定线程阻塞。
下面再开启T2之前,插入thread_1.join()
if __name__ == '__main__':thread_1 = threading.Thread(target=T1_job, name='T1')thread_2 = threading.Thread(target=T2_job, name='T2')thread_1.start() # 开启T1thread_1.join() thread_2.start() # 开启T2print("all done\n")
输出:
T1 start
T1 finish
T2 start
all done
T2 finish
可以看到,T2在等待T1结束后再开始运行。
为了达到预期情况,可以使用1221的V型排布:
if __name__ == '__main__':thread_1 = threading.Thread(target=T1_job, name='T1')thread_2 = threading.Thread(target=T2_job, name='T2')thread_1.start()thread_2.start()thread_2.join()thread_1.join()print("all done\n")
输出:
T1 start
T2 start
T2 finish
T1 finish
all done
线程通信
在定义的子线程任务函数job中,无法通过return的方式将计算完成的结果返回出来。
此时,可以使用队列(Queue)这种数据结构来获取子线程的结果数据,实现线程之间的通信,下面是一个示例:
import threading
from queue import Queuedef job(l, q):for i in range(len(l)):l[i] = l[i] ** 2q.put(l)def multithreading():q = Queue()threads = []data = [[1, 2, 3], [3, 4, 5], [4, 4, 4], [5, 5, 5]]for i in range(4):t = threading.Thread(target=job, args=(data[i], q))t.start()threads.append(t)for thread in threads:thread.join()results = []for _ in range(4):results.append(q.get())print(results)if __name__ == '__main__':multithreading()
线程锁
为了防止多线程输出结果混乱,除了添加线程阻塞之外,还可以使用线程锁。
同时,线程锁还可以确保当前线程执行时,内存不会被其他线程访问,执行运算完毕后,可以打开锁共享内存。
下面是一个不添加线程锁的示例:
import threadingdef job1():global Afor i in range(10):A += 1print('job1', A)def job2():global Afor i in range(10):A += 10print('job2', A)if __name__ == '__main__':A = 0t1 = threading.Thread(target=job1)t2 = threading.Thread(target=job2)t1.start()t2.start()t1.join()t2.join()
输出:
job1 1
job1 2
job1 3
job1 4
job1 5
job1 6
job1 7
job1 8
job2job1 19
18
job2 29
job2 39job1
job2 50
job240
60
job2 70
job2 80
job2 90
job2 100
job2 110
添加线程锁之后:
import threadingdef job1():global A, locklock.acquire()for i in range(10):A += 1print('job1', A)lock.release()def job2():global A, locklock.acquire()for i in range(10):A += 10print('job2', A)lock.release()if __name__ == '__main__':lock = threading.Lock()A = 0t1 = threading.Thread(target=job1)t2 = threading.Thread(target=job2)t1.start()t2.start()t1.join()t2.join()
输出:
job1 1
job1 2
job1 3
job1 4
job1 5
job1 6
job1 7
job1 8
job1 9
job1 10
job2 20
job2 30
job2 40
job2 50
job2 60
job2 70
job2 80
job2 90
job2 100
job2 110
多进程
进程基本结构
import multiprocessing as mpdef job(a, d):print('aaaaa')if __name__ == '__main__':p1 = mp.Process(target=job, args=(1, 2))p1.start()p1.join()
进程通信
和多线程类似,进程之间同样可以通过队列queue形式进行通信,并且,在multiprocessing库中,直接包含了Queue()结构。
import multiprocessing as mpdef job(q):res = 0for i in range(1000):res += i + i ** 2 + i ** 3q.put(res) # queueif __name__ == '__main__':q = mp.Queue()p1 = mp.Process(target=job, args=(q,))p2 = mp.Process(target=job, args=(q,))p1.start()p2.start()p1.join()p2.join()res1 = q.get()res2 = q.get()print(res1 + res2)
进程池
进程池(Pool)就是将所要运行的东西,放到池子里,Python会自行解决多进程的问题。
下面是一个简单示例,processes参数指定进程池中的进程数。
import multiprocessing as mpdef job(x):return x * xdef multicore():pool = mp.Pool(processes=6)# res = pool.map(job, range(10))# print(res)res = pool.apply_async(job, (2,))print(res.get())if __name__ == '__main__':multicore()
进程池运算结果有两种获取方式:
- 第一种是
pool.map,在map()中需要放入函数和需要迭代运算的值,然后它会自动分配给CPU核,返回结果; - 第二种是
pool.apply_async(),在apply_async()中只能传递一个值,它只会放入一个核进行运算,但是传入值时要注意是可迭代的,所以在传入值后需要加逗号, 同时需要用get()方法获取返回值。
pool.apply_async()只能传递一个值,如果要传递多个值,可以使用迭代器,下面的代码通过迭代器实现了两种取值方式的等效结果:
import multiprocessing as mpdef job(x):return x * xdef multicore():pool = mp.Pool(processes=2)res = pool.map(job, range(10))print(res)res = pool.apply_async(job, (2,))# 用get获得结果print(res.get())# 迭代器,i=0时apply一次,i=1时apply一次等等multi_res = [pool.apply_async(job, (i,)) for i in range(10)]# 从迭代器中取出print([res.get() for res in multi_res])if __name__ == '__main__':multicore()
进程锁
在不同进程中,可以通过变量.value的方式共享变量内存。
如果多个进程对同一个变量进行操控,不加进程锁,就会让结果混乱。
下面是一个不加进程锁的示例:
import multiprocessing as mp
import timedef job(v, num):for _ in range(5):time.sleep(0.1) # 暂停0.1秒,让输出效果更明显v.value += num # v.value获取共享变量值print(v.value)def multicore():v = mp.Value('i', 0) # 定义共享变量p1 = mp.Process(target=job, args=(v, 1))p2 = mp.Process(target=job, args=(v, 3)) # 设定不同的number看如何抢夺内存p1.start()p2.start()p1.join()p2.join()if __name__ == '__main__':multicore()
输出:
1
2
3
4
7
8
11
14
17
20
添加进程锁之后:
import multiprocessing as mp
import timedef job(v, num, l):l.acquire() # 锁住for _ in range(5):time.sleep(0.1)v.value += num # 获取共享内存print(v.value)l.release() # 释放def multicore():l = mp.Lock() # 定义一个进程锁v = mp.Value('i', 0) # 定义共享内存p1 = mp.Process(target=job, args=(v, 1, l)) # 需要将lock传入p2 = mp.Process(target=job, args=(v, 3, l))p1.start()p2.start()p1.join()p2.join()if __name__ == '__main__':multicore()
输出:
1
2
3
4
5
8
11
14
17
20
进程锁保证了进程p1的完整运行,然后才进行了进程p2的运行。
多线程和多进程的效率对比
在python语言中,并无法做到实际的多线程,这是由于Python中内置了全局解释器锁(GIL),让任何时候只有一个线程进行执行。下面是一段具体解释:
尽管Python完全支持多线程编程, 但是解释器的C语言实现部分在完全并行执行时并不是线程安全的。 实际上,解释器被一个全局解释器锁保护着,它确保任何时候都只有一个Python线程执行。 GIL最大的问题就是Python的多线程程序并不能利用多核CPU的优势 (比如一个使用了多个线程的计算密集型程序只会在一个单CPU上面运行)。
在讨论普通的GIL之前,有一点要强调的是GIL只会影响到那些严重依赖CPU的程序(比如计算型的)。 如果你的程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适, 因为它们大部分时间都在等待。实际上,你完全可以放心的创建几千个Python线程, 现代操作系统运行这么多线程没有任何压力,没啥可担心的。
下面是一段测试程序,对比常规计算,双线程,双进程的计算效率:
import multiprocessing as mp
import threading as td
import timedef job(q):res = 0for i in range(1000000):res += i + i ** 2 + i ** 3q.put(res) # queuedef multicore():q = mp.Queue()p1 = mp.Process(target=job, args=(q,))p2 = mp.Process(target=job, args=(q,))p1.start()p2.start()p1.join()p2.join()res1 = q.get()res2 = q.get()print('multicore:', res1 + res2)def multithread():q = mp.Queue() # thread可放入process同样的queue中t1 = td.Thread(target=job, args=(q,))t2 = td.Thread(target=job, args=(q,))t1.start()t2.start()t1.join()t2.join()res1 = q.get()res2 = q.get()print('multithread:', res1 + res2)def normal():res = 0for _ in range(2):for i in range(1000000):res += i + i ** 2 + i ** 3print('normal:', res)if __name__ == '__main__':st = time.time()normal()st1 = time.time()print('normal time:', st1 - st)multithread()st2 = time.time()print('multithread time:', st2 - st1)multicore()print('multicore time:', time.time() - st2)输出:
normal: 499999666667166666000000
normal time: 0.9803786277770996
multithread: 499999666667166666000000
multithread time: 0.9883582592010498
multicore: 499999666667166666000000
multicore time: 1.4371891021728516
结果发现,双线程的所花时间和单线程相差不大,论证了python的多线程是“伪多线程”。然而,多进程的所花时间却更多,这是由于该运算较简单,启动线程的时间消耗过大。
把计算数扩大十倍,输出结果:
normal: 4999999666666716666660000000
normal time: 10.019219160079956
multithread: 4999999666666716666660000000
multithread time: 9.802824974060059
multicore: 4999999666666716666660000000
multicore time: 6.478690147399902
此时发现多进程的速度有了明显提升。
相关文章:

【Python】多线程与多进程学习笔记
本文是一篇学习笔记,学习内容主要来源于莫凡python的文档:https://mofanpy.com/tutorials/python-basic/threading/thread 多线程 线程基本结构 开启子线程的简单方式如下: import threadingdef thread_job():print(This is a thread of %…...

MySQL基础知识点
1.在Linux上安装好MySQL8.0之后,默认数据目录的具体位置是什么?该目录下都保存哪些数据库组件?在目录/usr/sbin、/usr/bin、/etc、/var/log 分别保存哪些组件? 答:默认数据目录:/var/lib/mysql。保存有mysq…...

代码随想录算法训练营第五十九天| 583. 两个字符串的删除操作、72. 编辑距离
Leetcode - 583dp[i][j]代表以i-1结尾的words1的子串 要变成以j-1结尾的words2的子串所需要的次数。初始化: "" 变成"" 所需0次 dp[0][0] 0, ""变成words2的子串 需要子串的长度的次数,所以dp[0][j] j, 同理,dp[i][0] …...

指针引用字符串问题(详解)
通过指针引用字符串可以更加方便灵活的使用字符串。 字符串的引用方式有两种,下面简单介绍一下这两种方法。 1.用字符数组来存放一个字符串。 1.1 可以通过数组名和下标来引用字符串中的一个字符。 1.2 还可以通过数组名和格式声明符%s输出整个字符串。 具体实…...
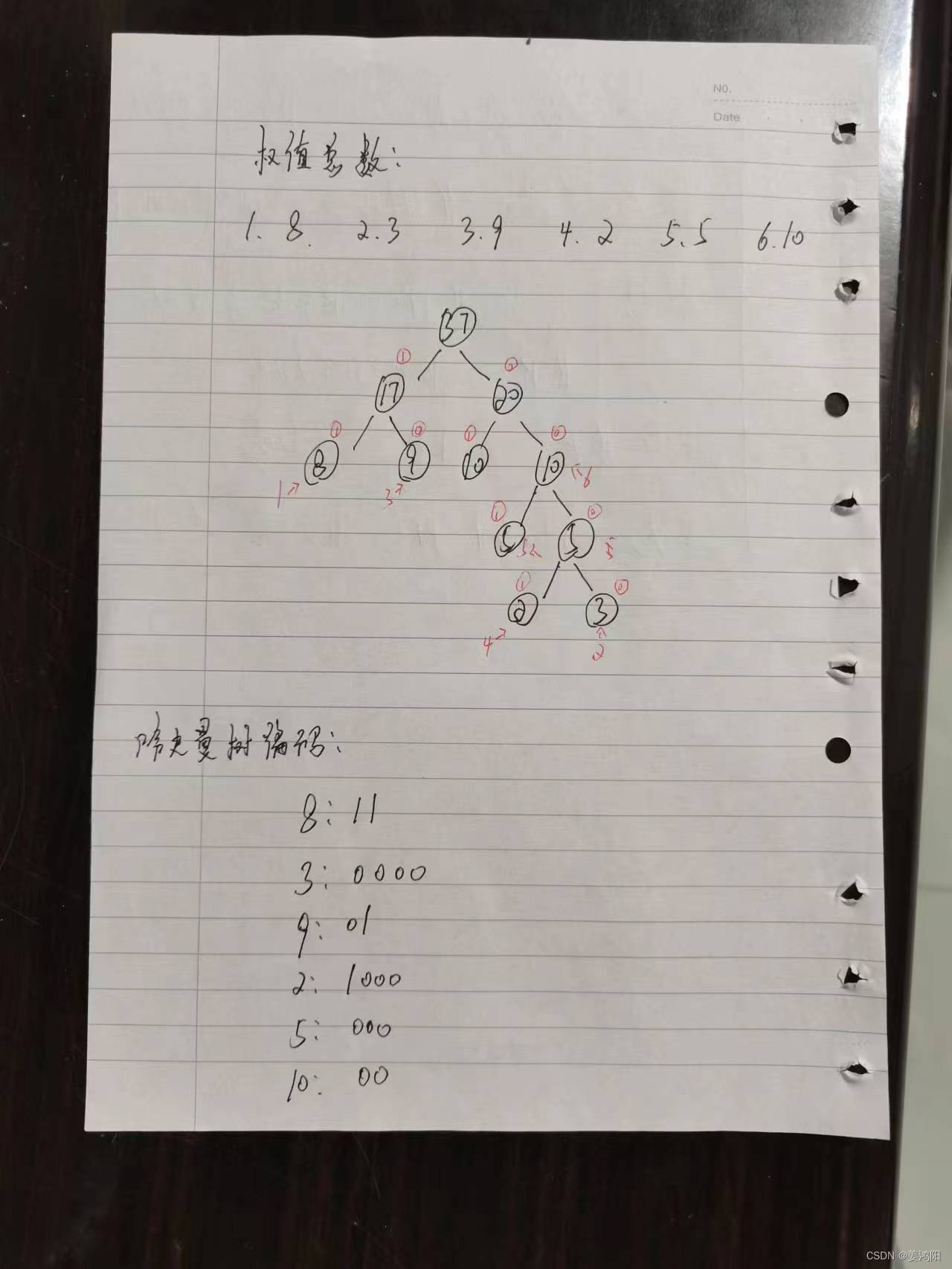
数据结构——哈夫曼树编程,输入权值实现流程图代码
一、须知 本代码是在数据结构——哈夫曼树编程上建立的,使用时需将代码剪切到C等软件中。需要输入权值方可实现流程图,但是还需要按照编程换算出的结果自己用笔画出流程图。 下面将代码粘贴到文章中,同时举一个例子:二、代…...
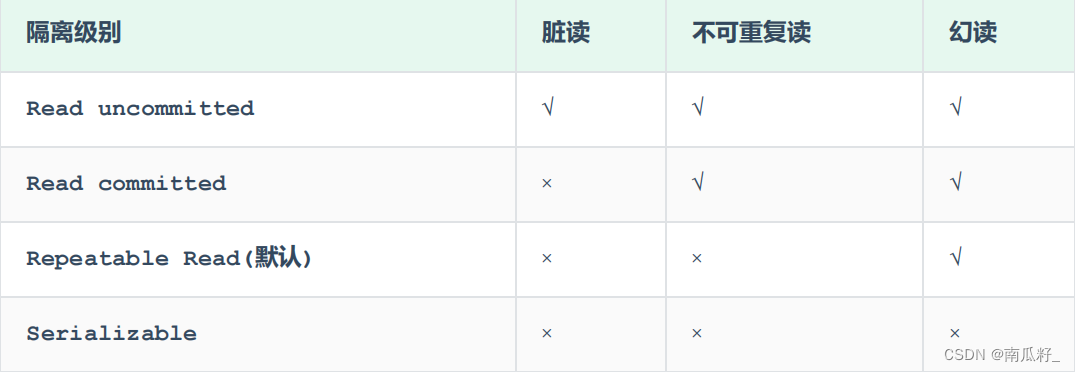
【MySQL】 事务
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...

Java测试——selenium常见操作(2)
这篇博客继续讲解一些selenium的常见操作 selenium的下载与准备工作请看之前的博客:Java测试——selenium的安装与使用教程 先创建驱动 ChromeDriver driver new ChromeDriver();等待操作 我们上一篇博客讲到,有些时候代码执行过快,页面…...
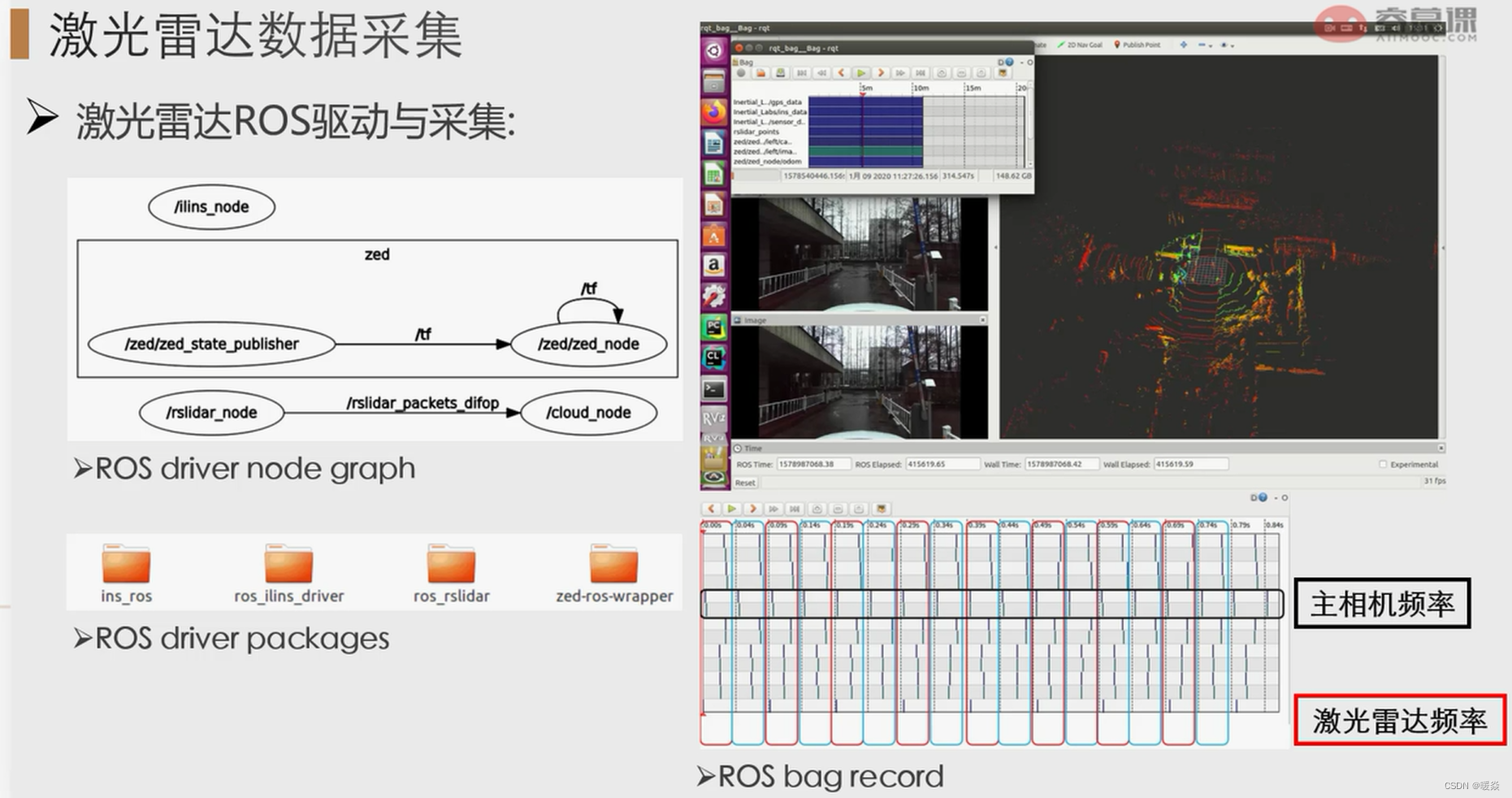
【三维点云】01-激光雷达原理与应用
文章目录内容概要1 激光雷达原理1.1 什么是激光雷达?1.2 激光雷达原理1.3 激光雷达分类三角法TOF法脉冲间隔测量法幅度调制的相位测量法相干法激光雷达用途2 激光雷达安装、标定与同步2.1 激光雷达安装方式考虑因素2.2 激光雷达点云用途2.3 数据融合多激光雷达数据融…...

自动驾驶感知——物体检测与跟踪算法|4D毫米波雷达
文章目录1. 物体检测与跟踪算法1.1 DBSCAN1.2 卡尔曼滤波2. 毫米波雷达公开数据库的未来发展方向3. 4D毫米波雷达特点及发展趋势3.1 4D毫米波雷达特点3.1.1 FMCW雷达角度分辨率3.1.2 MIMO ( Multiple Input Multiple Output)技术3.2 4D毫米波雷达发展趋势3.2.1 芯片级联3.2.2 专…...

C语言(内联函数(C99)和_Noreturn)
1.内联函数 通常,函数调用都有一定的开销,因为函数的调用过程包含建立调用,传递参数,跳转到函数代码并返回。而使用宏是代码内联,可以避开这样的开销。 内联函数:使用内联diamagnetic代替函数调用。把函数…...
理解与tensorflow2.0 代码实现 附完整代码)
图卷积神经网络(GCN)理解与tensorflow2.0 代码实现 附完整代码
图(Graph),一般用 $G=(V,E)$ 表示,这里的$V$是图中节点的集合,$E$ 为边的集合,节点的个数用$N$表示。在一个图中,有三个比较重要的矩阵: 特征矩阵$X$:维度为 $N\times D$ ,表示图中有 N 个节点,每个节点的特征个数是 D。邻居矩阵$A$:维度为 $N\times N$ ,表示图中 N…...
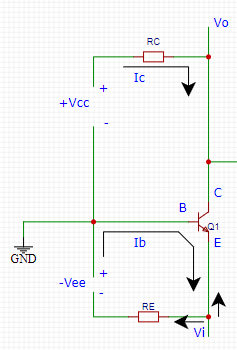
模电学习6. 常用的三极管放大电路
模电学习6. 常用的三极管放大电路一、判断三极管的工作状态1. 正偏与反偏的概念2. 工作状态的简单判断二、三种重要的放大电路1. 共射电路2. 共集电极放大电路3. 共基极放大电路一、判断三极管的工作状态 1. 正偏与反偏的概念 晶体管分P区和N区, 当P区电压大于N区…...
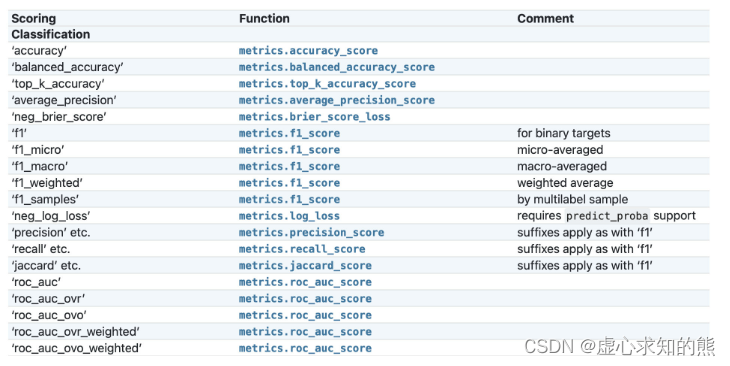
Lesson 6.6 多分类评估指标的 macro 和 weighted 过程 Lesson 6.7 GridSearchCV 的进阶使用方法
文章目录一、多分类评估指标的 macro 和 weighted 过程1. 多分类 F1-Score 评估指标2. 多分类 ROC-AUC 评估指标二、借助机器学习流构建全域参数搜索空间三、优化评估指标选取1. 高级评估指标的选用方法2. 同时输入多组评估指标四、优化后建模流程在正式讨论关于网格搜索的进阶…...
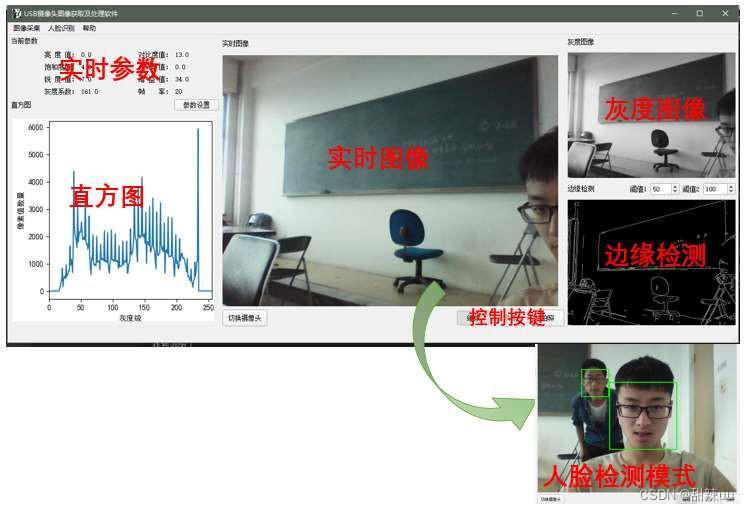
基于 Python 实时图像获取及处理软件图像获取;图像处理;人脸识别设计 计算机毕设 附完整代码+论文 +报告
界面结果:图像获取;图像处理;人脸识别 程序结构设计 图形用户界面设计与程序结构设计是互为表里的。或者说,程序结构设计是软件设计最本质、最核心的内容。徒有界面而内部逻辑结构混乱的软件一无是处。 Windows 操作系统是一款图形化的操作系统,相比于早期的计算机使用的命…...
前后端RSA互相加解密、加签验签、密钥对生成(Java)
目录一、序言二、关于PKCS#1和PKCS#8格式密钥1、简介2、区别二、关于JSEncrypt三、关于jsrsasign四、前端RSA加解密、加验签示例1、相关依赖2、cryptoUtils工具类封装3、测试用例五、Java后端RSA加解密、加验签1、CryptoUtils工具类封装2、测试用例六、前后端加解密、加验签交互…...

基于Java+SpringBoot+Vue前后端分离学生宿舍管理系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建、毕业项目实战、项目定制✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《S…...
)
前端高频面试题—JavaScript篇(二)
💻前端高频面试题—JavaScript篇(二) 🏠专栏:前端面试题 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享方向…...
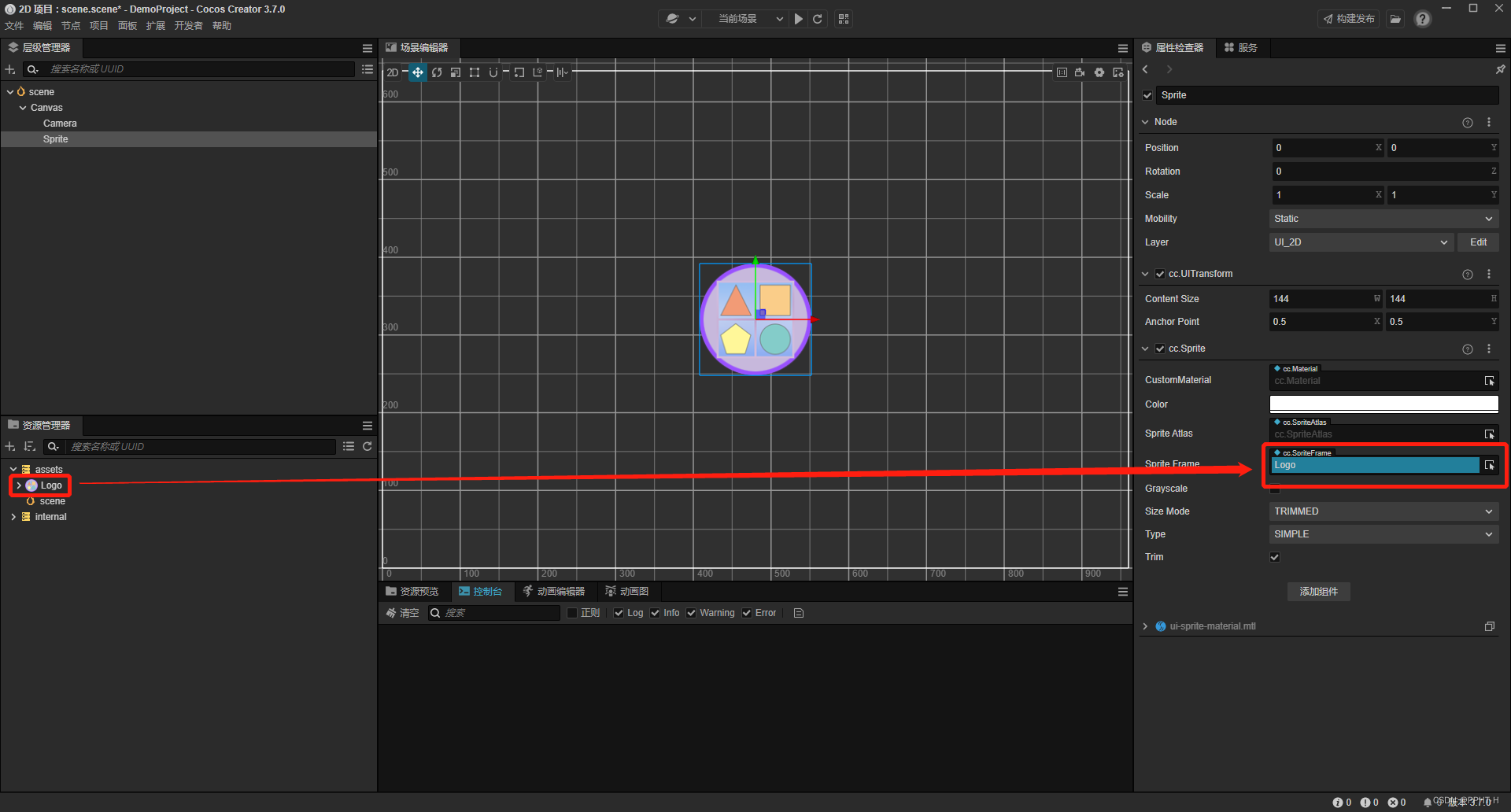
【微信小游戏开发笔记】第二节:Cocos开发界面常用功能简介
Cocos开发界面常用功能简介 本章只介绍微信小游戏开发时常用的功能,其他功能不常用,写多了记不住(其实是懒 -_-!): 层级管理器,用于操作各个节点。资源管理器,用于操作各种文件资源。场景编辑…...

3分钟,学会了一个调试CSS的小妙招
Ⅰ. 作用 用于调试CSS , 比控制台添更加方便,不需要寻找 ;边添加样式,边可以查看效果,适合初学者对CSS 的理解和学习; Ⅱ. 快速实现(两边) ① 显示这个样式眶 给 head 和 style 标签添加一个…...

【项目精选】基于jsp的健身俱乐部会员系统
点击下载源码 社会可行性 随着社会的发展和计算机技术的进步,人类越来越依赖于信息化的管理系统,这种系统能更加方便的获得信息以及处理信息。人们都改变了过去的思维,开始走向了互联网的时代,在 可行性小结 本章在技术可行性上…...

解锁MT7981潜能:OpenWrt 23.05下HC-G80双WAN口叠加与故障转移实战
1. 认识MT7981与HC-G80的硬件潜力 MT7981这颗芯片最近在路由器圈子里挺火的,作为联发科Filogic 820系列的中端方案,它最大的特点就是双核A53 1.3GHz CPU加上硬件级NAT加速。我实测过好几款搭载这个芯片的路由器,发现它的转发性能确实比同价位…...
)
从炸管到稳定调试:一个硬件工程师的十年Jlink隔离器避坑史(附V3.3.0通用版实测)
嵌入式调试隔离技术十年演进:从基础防护到高速兼容的实战之路 当我在2013年第一次目睹价值六位数的劳德巴赫仿真器因高压反冲变成"电子砖块"时,才真正理解调试隔离器在嵌入式开发中的分量。这不是简单的信号中转站,而是横亘在昂贵设…...

保姆级教程:IndexTTS-2-LLM从部署到生成语音的全流程实战
保姆级教程:IndexTTS-2-LLM从部署到生成语音的全流程实战 1. 项目介绍与核心优势 1.1 什么是IndexTTS-2-LLM? IndexTTS-2-LLM是一款基于大语言模型的智能语音合成系统,它能够将文字转换为自然流畅的语音。与传统的语音合成技术相比&#x…...

破解LLM应用开发困境:LangChain框架的创新实践与技术解析
破解LLM应用开发困境:LangChain框架的创新实践与技术解析 【免费下载链接】langchain LangChain是一个由大型语言模型 (LLM) 驱动的应用程序开发框架。。源项目地址:https://github.com/langchain-ai/langchain 项目地址: https://gitcode.com/GitHub_…...
数值模拟与计算流体动力学(...)
11.2版本:使用Flow3D进行高能量密度下选区激光熔化(SLM)数值模拟与计算流体动力学(...
11.2版本 使用流体力学软件flow3d 增材制造 additive manufacturing 选区激光熔化 SLM 数值模拟 计算流体动力学CFD Flow3d keyhole-induced pore 匙孔孔隙 可模拟单层单道、多道多层 该模型能够模拟高能量密度下产生的匙孔孔隙,与有些不能模拟高能量密度的模型完全…...

绕过苹果限制:聊聊Flutter热更新在Android端的那些‘野路子’与合规边界
Flutter热更新在Android端的实践探索与技术边界思考 热更新技术一直是移动开发领域的热门话题,尤其在快速迭代的业务场景中,能够显著提升问题修复效率。Flutter作为跨平台框架,其热更新机制与原生开发存在显著差异,更涉及不同平台…...
)
Keil开发必备:AStyle代码格式化插件一键配置指南(附最新参数详解)
Keil开发必备:AStyle代码格式化插件一键配置指南(附最新参数详解) 在嵌入式开发领域,代码风格的一致性往往被忽视,却直接影响团队协作效率和代码可维护性。Keil作为嵌入式开发的主流IDE,原生并未提供强大的…...

GD32F407实战:通过RS485与Ymodem协议实现远程IAP固件升级
1. 为什么需要远程IAP升级? 在工业物联网和分布式设备场景中,设备往往分布在不同的地理位置。想象一下,一个工厂里有上百台设备需要更新固件,如果每台都要用仿真器手动烧录,工程师得跑断腿。我去年负责的一个污水处理项…...

QNAP QVR Pro 严重漏洞可导致系统遭远程访问
聚焦源代码安全,网罗国内外最新资讯!编译:代码卫士威联通(QNAP)发布安全公告,修复了QVR Pro监控软件中的一个严重漏洞CVE-2026-22898,可导致远程未认证攻击者获得对受影响系统的未授权访问权限。…...

Flux Sea Studio 海景摄影生成工具:Git版本控制管理生成脚本与模型参数
Flux Sea Studio 海景摄影生成工具:Git版本控制管理生成脚本与模型参数 1. 引言 你有没有遇到过这样的情况?花了好几个小时,终于调出一组完美的参数,生成了一张惊艳的海景图。结果第二天想复现,或者想分享给团队伙伴…...