计算机中信息的表示和处理 整数和小数的二进制表示
信息的表示和处理
- 整数
- 进制
- 字
- 移位运算
- 无符号数和有符号数
- 加法运算
- 小数
- 定点表示
- IEEE 浮点表示
- 规格化和非规格化
- 舍入
- 浮点运算
- 现代计算机存储和处理的信息以二值信号表示,这些二进制数字称为位,为什么要用二进制来进行编码?因为二进制只有1和0两种状态,正好可以用高低电平来表示,同时可以数值之间可以方便的进行逻辑和算数运算,否则如果用人类容易理解的十进制编码,那机器如何识别这10个状态呢?比较困难
- 大多数计算机用8位的块(比特),或者说1字节作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存(virtual memory),内存中每一个字节都有一个唯一数字标识,称为它的地址(address)
整数
进制
- 二进制(Binary)(Binary)(Binary)后缀是BBB,十进制(Decimal)(Decimal)(Decimal)后缀是DDD,八进制(Octal)(Octal)(Octal)后缀是OOO,十六进制(Hex)(Hex)(Hex)后缀是HHH
- 这里相信读者对任意进制转十进制以及十进制转任意进制(整数和小数部分分开处理然后拼起来)并不陌生,简单说一下二进制和八进制或者十六进制的互相转化,比如下面这个十六进制数
0x39A7F80x39A7F80x39A7F8 - 怎么把它转化成二进制数?最简单的办法就是一位一位转换,比如333可以转换成(0011)2(0011)_2(0011)2,999可以转化成100110011001这样转化下去,拼起来就可以得到结果如下
0011100110100111111110000011\ 1001\ 1010\ 0111\ 1111\ 10000011 1001 1010 0111 1111 1000 - 二进制转十六进制一个道理
字
- 在Windows系统中我们也许知道有32位和64位的区别,那么这个区别到底是什么呢?事实上,每台计算机都有一个字长(word size),指明指针数据的标称大小(nominal size),字长决定的最重要的系统参数就是虚拟地址空间的访问最大大小,也就是说,对于一个字长为www的机器而言,虚拟地址的范围就是0−2w−10-2^w-10−2w−1,程序最多访问2w2^w2w个字节,那么32位系统的虚拟地址空间就是2322^{32}232个字节,大概是4GB
- 那么问题来了,跨越多字节的程序对象如何处理呢?答案应该是使用地址来找到这个对象,同时还要知道如何在内存中排列这些字节。因为几乎所有的机器上多字节对象都被存储位连续的字节序列,对象的地址为所使用字节中最小的地址
- 有两种方法排列这些字节,要么从低到高,称为小端法(little endian),要么从高到低,称为大端法(big endian),这里的高低可以这样理解,比如数字123456,1属于高,6属于低。有时候这会造成问题,比如网络传输数据的时候,不同方法的机器可能导致传输字节反序,这需要注意,我们可以看下面这个例子
#include <bits/stdc++.h>using namespace std;typedef unsigned char *byte_pointer;void show_bytes(byte_pointer start, size_t len){size_t i;// unsigned intfor(int i=0;i<len;i++){printf(" %.2x", start[i]);// start是val的首地址,因为两个十六进制位占1个字节,所以输出两位}printf("\n");
}
int main(){int val = 0x87654321;byte_pointer valp = (byte_pointer) &val;// 取地址show_bytes(valp, 1);// 21show_bytes(valp, 2);// 21 43show_bytes(valp, 3);// 21 43 65return 0;
}
- 可以测试一下运行结果,小端法机器输出如上图
- 我们可以用C语言的运算符
sizeof来确定对象使用的字节数
移位运算
- 默认读者使用过移位运算,大概知道怎么回事,C语言移位有左移和右移,左移就是末位补0,高位舍弃;右移有两种,算数右移和逻辑右移,但C语言没有明确规定,逻辑右移是在左端补0,算数右移是在左端补最高位的值,比如现在最高位是1,那就在左端全补1,也就是说算数右移不改变数的正负
- 而Java中规定明确,
x>>k表示算数右移,x>>>k表示逻辑右移
无符号数和有符号数
- 假设一个整数数据类型有www位,我们可以把位向量写成x⃗\vec{x}x,表示整个向量,那么整个数字就是[xw−1,xw−2,⋯,x0][x_{w-1},x_{w-2},\cdots,x_{0}][xw−1,xw−2,⋯,x0],表示向量中的每一位,所以对于一个无符号数有B2Uw(x⃗)=∑i=0w−1xi2iB2U_{w}(\vec{x})=\sum_{i=0}^{w-1}x_i2^iB2Uw(x)=i=0∑w−1xi2i其中B2UwB2U_{w}B2Uw表示BinarytoUnsignedBinary\ to\ UnsignedBinary to Unsigned,长度为www,这个函数是一个双射,意思就是正向一对一,反向也一对一,所以我们可以用每一个数表示一个状态,进行状态压缩
- 对于有符号数,一般计算机表示方式是补码形式,我们用函数B2Tw(BinarytoTwo′s−complement)B2T_w(Binary\ to\ Two's-complement)B2Tw(Binary to Two′s−complement)表示,补码编码的定义如下,对向量x⃗=[xw−1,xw−2,⋯,x0\vec{x}=[x_{w-1},x_{w-2},\cdots,x_0x=[xw−1,xw−2,⋯,x0],有B2Tw(x⃗)=−xw−12w−1+∑i=0w−2xi2iB2T_w(\vec{x})=-x_{w-1}2^{w-1}+\sum_{i=0}^{w-2}x_i2^iB2Tw(x)=−xw−12w−1+i=0∑w−2xi2i
- 有符号数的另外两种标准的表示方法是原码和反码,原码(Sign−Magnitude)(Sign-Magnitude)(Sign−Magnitude)的最高有效位是符号位,用来确定剩下的位是正权还是负权,有B2Sw(x⃗)=(−1)xw−1×(∑i=0w−2xi2i)B2S_w(\vec{x})=(-1)^{x_{w-1}}\times (\sum_{i=0}^{w-2}x_i2^i)B2Sw(x)=(−1)xw−1×(i=0∑w−2xi2i)
- 反码(One′sComplement)(One's\ Complement)(One′s Complement)表示的话,最高有效位的权比补码多了个1,表示如下B2Ow(x⃗)=−xw−1(2w−1−1)+∑i=0w−2xi2iB2O_w(\vec{x})=-x_{w-1}(2^{w-1}-1)+\sum_{i=0}^{w-2}x_i2^iB2Ow(x)=−xw−1(2w−1−1)+i=0∑w−2xi2i
- 但是你会发现原码和反码在表示0的时候都有两种情况,原码是因为最高位表示符号,是不是1对于0无影响,反码是因为最高有效位权多了个1,导致所有位都是1的时候值变成了0
- 对于很多国内教材,讲到补码的时候会说,对于一个正整数,补码和原码相同(原码就是这个数转化成二进制),对负整数来说,补码是原码取反+1,从上面的公式中可以轻松推出这一结论
- C语言中的强制类型转换非常简单,就是位表示不会改变,只是改变了解释这些位的方式,那么如果一个有符号的负数转化成一个无符号的数就可能变成一个大正数,如果位不够要进行扩展,扩展可能是零扩展也可能是符号扩展,这个和逻辑右移与算数右移比较类似,如果位太多要截断,这里书中有详细介绍,我就不求甚解了
加法运算
- 显然由于计算机字长和内存的限制,一个数字不能无限制的增大,否则就会失去它原本的意义,加法实际上就是超过部分舍掉就完事了,两个无符号数加法公式如下x+wuy={x+y,x+y<2w正常x+y−2w,2w≤x+y<2w+1溢出x+{^u_w}y=\begin{cases}x+y,\quad &x+y\lt 2^w &正常 \\ x+y-2^w,&2^w\leq x+y\lt2^{w+1} &溢出 \end{cases}x+wuy={x+y,x+y−2w,x+y<2w2w≤x+y<2w+1正常溢出
- 补码加法同理x+wty={x+y−2w,2w−1≤x+y正溢出x+y,−2w−1≤x+y<2w−1正常x+y+2w,x+y<−2w−1负溢出x+{^t_w}y=\begin{cases}x+y-2^w,\quad &2^{w-1}\leq x+y &正溢出 \\ x+y,&-2^{w-1}\leq x+y\lt2^{w-1} &正常\\x+y+2^w,&x+y\lt -2^{w-1} &负溢出\end{cases}x+wty=⎩⎨⎧x+y−2w,x+y,x+y+2w,2w−1≤x+y−2w−1≤x+y<2w−1x+y<−2w−1正溢出正常负溢出
- 上面的公式简单来说就是,你就直接加,超出位数就不要了,得到的答案就是运算结果
小数
定点表示
- 小数转化为二进制比较容易,对于整数部分,按照整数转化为二进制的方式进行转化;对于小数部分,通常采用的方法是乘222取整,直到符合的位数
- 这是定点表示的方法,但是对于类似1×21001\times2^{100}1×2100这样非常巨大的数字,我们不能够使用定点表示的方法,接下来看如何使用浮点表示
IEEE 浮点表示
- 浮点数对形如V=x×2yV=x\times 2^yV=x×2y的有理数进行编码,换句话说就是将小数转换为二进制表示,然后再对其进行编码,乘2y2^y2y是什么意思?就是二进制移位
IEEE浮点标准用V=(−1)s×M×2EV=(-1)^s\times M\times 2^EV=(−1)s×M×2E的形式来表示一个数
- 符号(sign),s决定这个数是正数还是负数,而对于数值0的符号位解释作为特殊情况处理
- 尾数(significand),M是一个二进制小数,它的范围是1∼2−ε1\sim2-\varepsilon1∼2−ε,或者是0∼1−ε0\sim1-\varepsilon0∼1−ε
- 阶码(exponent),E的作用是对浮点数加权,这个权重是2的E次幂(可能是负数)
将浮点数的位表示划分为三个字段,分别对这些值进行编码,分为单精度(32位的float)和双精度(64位的double)
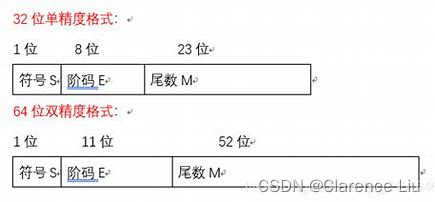
- 根据上图可以解决一个问题,那就是单精度和双精度数能精确到小数点后多少位,根据即将要讲到的规格化定义,尾数表示的是2M+12^{M+1}2M+1,所以显然单精度能表示到224=167772162^{24}=16777216224=16777216,这个数在10710^7107和10810^8108之间,排除掉最后一位的舍入问题,单精度能精确到小数点后666位;同理双精度能表示到253=90071992547409922^{53}=9007199254740992253=9007199254740992,在101610^{16}1016和101710^{17}1017之间,所以能精确到小数点后151515位
规格化和非规格化
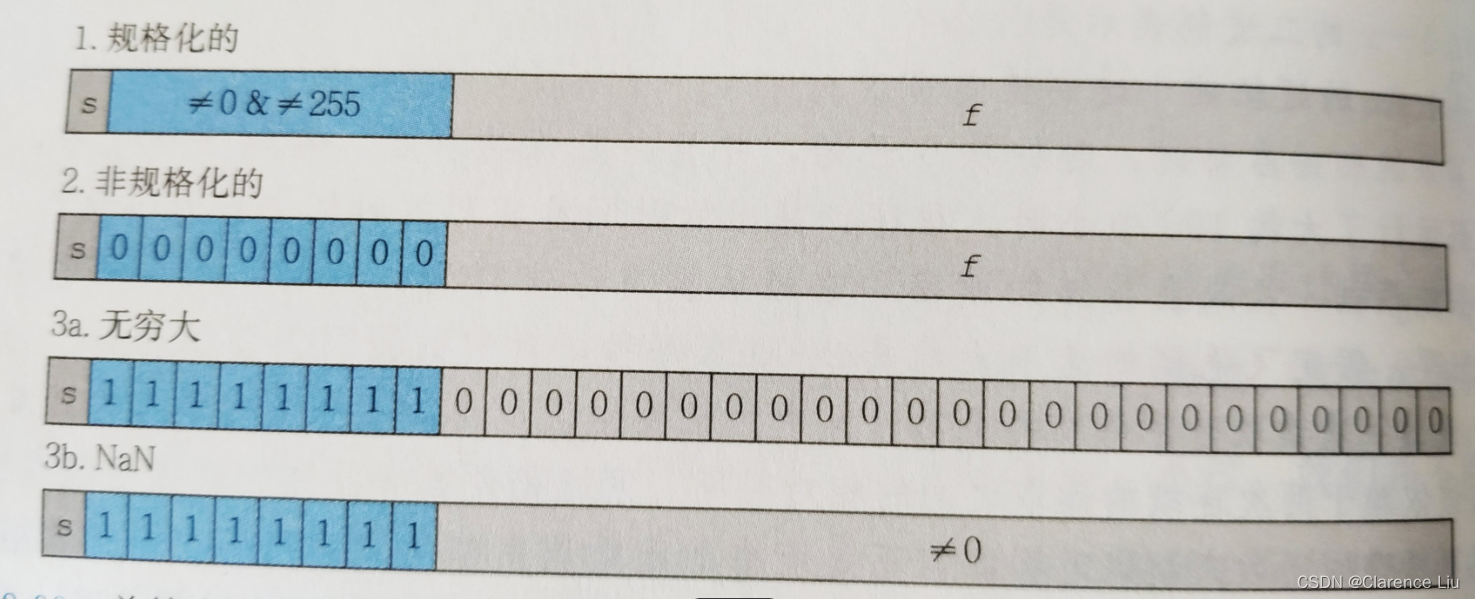
下面对上图进行一些解释
- 根据阶码,引入了规格化和非规格化的概念,如果阶码的所有二进制位不全为0,也不全为1,那么就说这个二进制小数是规格化的,但是在这种情况下,阶码字段被解释成以偏置(biased)形式表示的有符号整数,也就是说,阶码的值是E=e−BiasE=e-BiasE=e−Bias,其中eee是无符号数,而BiasBiasBias是一个等于2k−1−12^{k-1}-12k−1−1(单精度127,双精度1023)的偏置值。由此,指数的取值范围对于单精度是−126∼+127-126\sim+127−126∼+127,双精度是−1022∼+1023-1022\sim+1023−1022∼+1023,小数字段fracfracfrac被解释为描述小数值fff,这个fff的范围是[0,1)[0,1)[0,1),二进制表示为0.fn−1...f1f00.f_{n-1}...f_1f_00.fn−1...f1f0,正常情况下是这样,但是我们可以通过调整阶码EEE让这个二进制数变成1.fn−1fn−2...f01.f_{n-1}f_{n-2}...f_01.fn−1fn−2...f0,这样,这个开头的111不需要记录,就提高了1位的精度位,这就是规格化表示
- 对于非规格化,阶码域就全是0,阶码值是E=1−BiasE=1-BiasE=1−Bias,这样设置阶码值的意义是从规格化到非规格化能够平滑转换,而尾数的值是M=fM=fM=f,也就是小数字段的值,不包括隐含的开头的1,因为规格化数后面的二进制小数是1.几,所以没办法表示0,那么非规格化就可以表示0.00.00.0,但是如果符号位是1的话,得到的就是−0.0-0.0−0.0,IEEE浮点格式对这两种数也有它自己的规定,另外一个就是逐渐下溢,可以表示非常接近于0.0的数
- 当阶码所有位都是1的时候,如果小数域都是0,那么这个数就表示无穷,不都是0就表示NaN(Not a Number),如果有两个非常大的数相乘,那么得到的结果就会是inf,也就是无穷
舍入
- 因为浮点数只能近似表示实数,所以需要考虑如何进行舍入,一般有四种舍入方式,下面以舍入到整数为例
- 向上舍入,很简单,比如1.2,向上舍入就是2,如果是-1.2向上舍入就是-1,就是往大了取
- 向下舍入,和第一个相反,1.2向下舍入是1,-1.2向下舍入是-2
- 向零舍入,1.2向零舍入就是1,-1.2向零舍入就是-1
- 向偶数舍入,这个比较特殊,它将数字向上或者向下舍入,使得最终结果是距离这个数字最近的数;如果距离相等则舍入到有效数字的最后一位是一个偶数的数,比如说1.4会舍入到1,因为1.4处于1和2之间,而它距离1比较近,所以舍入到1;如果是1.5,因为它距离1和2一样近,这个时候因为1是个奇数,所以需要舍入到2,如果是2.5则向下舍入到2。那么为什么要引入这样奇怪的方式呢?主要是避免大量的向上或者向下取整带来的统计偏差,相当于取了一个平均值
浮点运算
- 对阶,目的是让两个操作数的小数点位置对齐,使得两个数的阶码相等,这样我们先求阶差,然后以小阶向大阶对齐的原则,具体操作过程就是尾数右移,给阶码腾出空间,这样尾数的低位数就会丢失,这也就说明了为什么要以小阶向大阶对齐,如果返回来那么势必要左移,这样尾数的高位就要丢失,产生错误,因为低位丢失误差较小,高位丢失误差很大
- 尾数求和,将对阶之后的尾数按照定点数加(减)运算规则运算。运算后的尾数不一定是规格化的,因此,浮点数的加减运算需要进一步进行规格化处理
- 规格化,IEEE 754规格化尾数的形式是±1.\pm1.±1.x⋯\cdots⋯x,但是尾数加减之后不一定能得到这种情况,可能小数点之前好几位,或者小数点前面是0,这时候需要进行规格化处理,具体方法是左规和右规,直到最高位1移动到小数点前作为隐藏位,这个在前面的规格化中已经说过
- 舍入,因为前面对尾数进行了一些右移操作,可能会造成一些浮点误差,为了保证运算精度,一般将低位移出的两位保留下来,参加中间过程的运算,最后将运算结果进行舍入,还原表示成IEEE 754格式,常见的舍入方法有0舍1入法(舍去的尾数最高位如果是1则对新的尾数+1,否则不动,但是这样可能使尾数溢出,此时需要再做一次右规)、恒置1法(只要因移位而丢失的位中有1就把尾数末位置1)和截断法(恒舍法)(直接截取所需位数,丢弃后面的所有位)
- 溢出判断,看指数是不是超过了最大允许值或者低于最小允许值,如果是这样的话就发生了溢出,进行相应的处理
阿贝尔群:又称交换群或加群,它由自身的集合G和二元运算*组成,它除了满足一般的群公理,即运算的结合律、G有单位元、所有G的元素都有逆元之外,还满足交换律公理。因为阿贝尔群的群运算满足交换律和结合律,群元素乘积的值与乘法运算时的次序无关,换句话说对于任意的a,b∈Ga,b\in Ga,b∈G,都有ab=baab=baab=ba,或者说a+b=b+aa+b=b+aa+b=b+a
- 可以看出整数加法形成了一个阿贝尔群,而浮点数加法由于可能溢出到无穷大并不满足结合律所以不是一个阿贝尔群,这个需要注意
未完待续
相关文章:
计算机中信息的表示和处理 整数和小数的二进制表示
信息的表示和处理整数进制字移位运算无符号数和有符号数加法运算小数定点表示IEEE 浮点表示规格化和非规格化舍入浮点运算现代计算机存储和处理的信息以二值信号表示,这些二进制数字称为位,为什么要用二进制来进行编码?因为二进制只有1和0两种…...

Chapter2.2:线性表的顺序表示
该系列属于计算机基础系列中的《数据结构基础》子系列,参考书《数据结构考研复习指导》(王道论坛 组编),完整内容请阅读原书。 2.线性表的顺序表示 2.1 顺序表的定义 线性表的顺序存储亦称为顺序表,是用一组地址连续的存储单元依次存储线性表…...

老马闲评数字化「4」做数字化会不会被供应商拿捏住
原文作者:行云创新CEO 马洪喜 导语 开年过后业务特别的繁忙,出差也比较多,所以有段时间没更新了,对不住大家! 上一集(您可以查看“行云创新”主页阅读原文)咱们聊了数字化转型的“想转、急转、…...

robosuite添加无碰撞的模型
1 前言 最近在使用robosuite时,需要在仿真环境中可视化物体的目标位置,从而方便观察训练情况,可视化的物体有以下要求: 形状尺寸与操作的物体一样半透明只有visual,不与场景其他物体有碰撞可以在每次step后设置位置,且固定在设定的位置,不受重力影响 2 方法 找了半天,最终确…...
JS学习笔记day03
今日内容 零、 复习昨日 CSS 美化,复用,样式文件和表现文件分离便于维护 选择器 {属性:值;…} 引入css 内联文件内部使用style标签外部文件 <link href"路径" rel"stylesheet" type"text/css"> 选择器 基本 idclass标签名 属性 标签名…...
)
离散数学笔记_第一章:逻辑和证明(3)
1.3 命题等价式1.3.1 逻辑等价式 1.3.2 条件命题和双条件命题的逻辑等价式 1.3.3 德摩根律 1.3.4 可满足性 可满足的 不可满足的 可满足性问题的解 1.3.5析取范式(基本积之和),合取范式(基本和之积)1.3.6合式公式1…...

软件测试分类知识分享,第三方软件测试机构收费贵不贵?
软件测试可以很好的检验软件产品的质量以及规避产品上线之后可能会发生的错误,随着技术的发展,软件测试已经是一个完整且体系庞大的测试活动,不同的测试领域有着不同的测试方法、技术与名称,那么具体有哪些分类呢? 一、软件测试…...
爬虫(二)解析数据
文章目录1. Xpath2. jsonpath3. BeautifulSoup4. 正则表达式4.1 特殊符号4.2 特殊字符4.3 限定符4.3 常用函数4.4 匹配策略4.5 常用正则爬虫将数据爬取到后,并不是全部的数据都能用,我们只需要截取里面的一些数据来用,这也就是解析爬取到的信…...

【C++、C++11】可变参数模板、lambda表达式、包装器
文章目录📖 前言1. 可变参数模板1.1 万能模板:1.2 完美转发:1.3 可变参数模板的使用:1.4 emplace_back:2. lambda表达式2.1 lambda表达式的定义:2.2 lambda表达式的用法:2.2 - 1 捕捉列表的用法…...

外贸主机测评
一、俄罗斯vps 服务商: JUSTG: Home - Sun Network Company Limited LOCVPS: LOCVPS 全球云 - 十年老牌 为跨境外贸/远程办公/网站建设提供澎湃动力 JUSTHOST: justhost.ru RUVDS: Gcorelabs: 二、主机测评指标: 1、速度、延迟、丢包、路由测试…...

Meta CTO:Quest 2生命周期或比预期更久
前不久,Meta未来4年路线图遭曝光,泄露了该公司正在筹备中的一些AR/VR原型。除此之外,还有消息称Quest Pro或因销量不佳,而不再迭代。毫无疑问,Meta的一举一动持续受到行业关注,而面对最近的爆料,…...

Vector - CAPL - 文件处理函数
在当前平台化的趋势下,就算是协议层测试依然需要适配各种各样的项目,也需要处理各类型的文件,那我们如何对文件进行读取、写入、修改等类型的操作呢?今天我们就会介绍此类型的函数,主要适用于text、bin文件的处理。 打开文件 Open...

实力加持!RestCloud完成多方国产化适配,携手共建信创生态
近年来,随着数字化建设进入深水区,企事业单位对信息安全重视程度与日俱增,核心技术自主可控已成为时代呼唤,国产化浪潮日益汹涌澎湃。近日,RestCloud在国产化方面取得新进展,完成了全部产品线信创环境的多方…...

Unity 3D GUI教程||OnGUI TextArea 控件||OnGUI ScrollView 控件
OnGUI TextArea 控件 Unity 3D TextArea 控件用于创建一个多行的文本编辑区。用户可以在多行文本编辑区编辑文本内容。 该控件可以对超出控件宽度的文本内容实现换行操作。 TextArea 控件同样会将当前文本编辑区中的文本内容以字符串形式返回。 开发人员可以通过创建 Strin…...
Leetcode.828 统计子串中的唯一字符
题目链接 Leetcode.828 统计子串中的唯一字符 Rating : 2034 题目描述 我们定义了一个函数 countUniqueChars(s)来统计字符串 s中的唯一字符,并返回唯一字符的个数。 例如:s "LEETCODE",则其中 "L", "…...

Hibernate 相关特性
1. Hibernate一般使用hql进行查询,但也有sql执行的方法 Native sql 查询,。需要注意的是,使用Native SQL查询可能会破坏Hibernate的缓存机制,并可能导致性能问题 String sql "SELECT * FROM users WHERE age > :age"; Query …...

【研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit8】
Unit1 Descartes Was Wrong 笛卡尔错了:“他人在,故我在” Unit2 Are we ready for the next volcanic catastrophe?我们准备好应对下一次火山灾难了吗? Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见 unit4 Magic Nu…...

ListView 控件的使用
第一步:找到ListView的控件通过findViewById 找到ListView的控件 ListView listView findViewById(R.id.listView);第二步:创建Bean类 得到set和get的方法解析获取的数据创建Bean类 得到set和get的方法public class Bean {String nanm""; pub…...
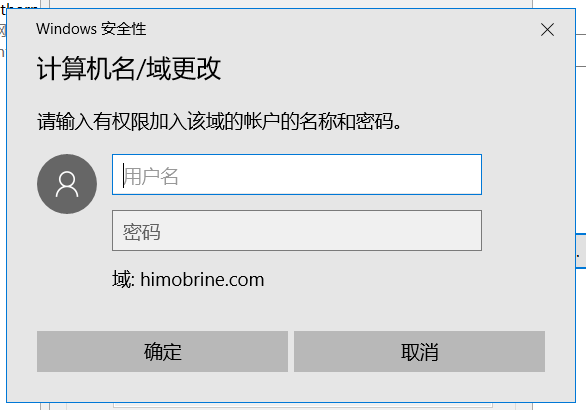
域控制器搭建以及成员加入
需要iso:windows server 2016软件使用:vmwarewindows server 2016系统搭建自己选iso,一直下一步就可以安装完成。(记得要设置密码)(密码要求大小写字母数字符号)等待就能安装完成。安装和配置Ac…...
利用 MLP(多层感知器)和 RBF(径向基函数)神经网络解决的近似和分类示例问题(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 1、径向基神经网络 径向基函数网络是由三层构成的前向网络:第一层为输入层,节点个数的能与输入的维数&…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...