JVMの垃圾回收
在上一篇中,介绍了JVM组件中的运行时数据区域,这一篇主要介绍垃圾回收器
JVM架构图:
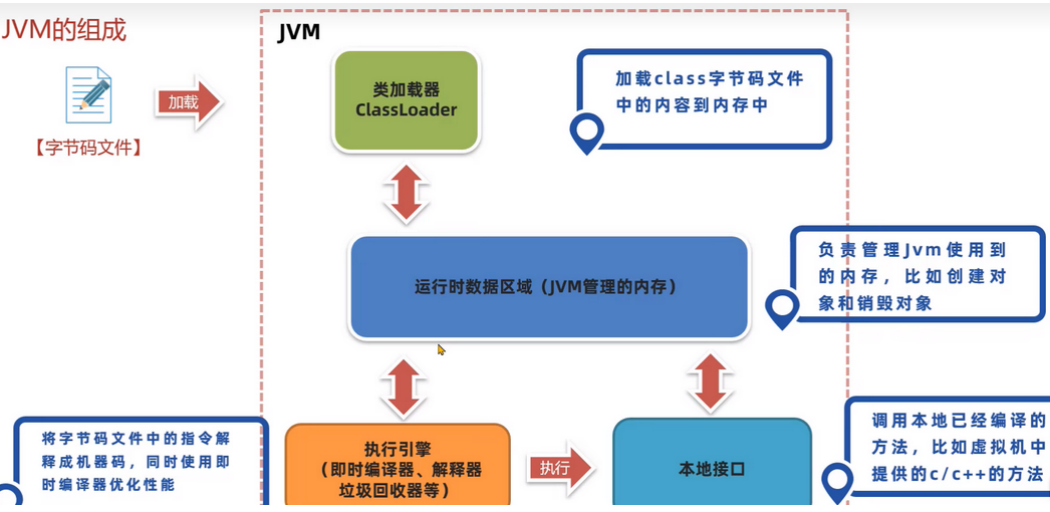
1、垃圾回收概述
在第一篇中介绍JVM特点时,有提到过内存管理,即Java语言相对于C,C++进行的优化,可以在适当的时机自动进行垃圾回收,而不需要手动的编写回收逻辑。
而JVM中的垃圾回收,主要体现在堆和方法区上。栈不存在垃圾回收的问题,因为栈帧之间的线程独立,并且方法在执行完后会弹出栈并且自动释放其中的内存。
1.1、方法区的垃圾回收
一般来说,方法区的垃圾回收体现在以下几点:
-
废弃常量的回收: 方法区中存储的常量包括字符串常量、类的静态常量等。当这些常量没有被引用时,它们就成为了废弃常量。垃圾回收器可以通过检查废弃常量并回收它们占用的内存空间。
-
无效的类的回收: 在JVM中加载的类信息存储在方法区中。当一个类不再被使用,例如类的实例已经全部被回收,那么该类就成为无效的类。垃圾回收器可以通过检查无效的类并回收相关的内存空间。
-
而判定一个类是否能被卸载,需要满足以下条件:
-
实例是否可达: 如果该类的所有实例都不再被任何活跃的引用链所持有,即没有任何途径可以从根对象(如静态变量、方法区中的常量等)到达该类的实例,那么该类的实例就成为了孤岛对象,可以被回收。
-
静态变量和静态方法是否引用: 如果该类的静态变量或静态方法仍然被其他地方引用,那么该类本身的类信息也会保持可达状态,无法被回收。因此,如果某个类的静态资源仍然被引用,即使该类的实例全部不可达,该类也无法被回收。
public class GcDemo3 {public static void main(String[] args) {Student.study();}
}class Student{public static void study(){System.out.println("我是一个学习java时长达到两年半的练习生");}
}没有unload:

-
类加载器的生命周期: 在Java中,类的卸载与类加载器密切相关。当一个类加载器不再需要加载某个类时,可以触发该类的卸载。只有当某个类的所有实例都不可达,并且对应的类加载器也不再存活时,才能够导致该类的卸载和回收。
案例:
public class ClassUnload {public static void main(String[] args) throws InterruptedException {try {ArrayList<Class<?>> classes = new ArrayList<>();ArrayList<URLClassLoader> loaders = new ArrayList<>();ArrayList<Object> objs = new ArrayList<>();for (int i = 0; i < 5; i++) {URLClassLoader loader = new URLClassLoader(new URL[]{new URL("file:D:\\Idea_workspace\\2024\\")});Class<?> clazz = loader.loadClass("com.itheima.my.A");Object o = clazz.newInstance();
// objs.add(o);
// loader = null;
// classes.add(clazz);
// loaders.add(loader);System.gc();}} catch (Exception e) {e.printStackTrace();}}
}
加入了两个JVM参数:
-XX:+TraceClassLoading: 打印加载信息
-XX:+TraceClassUnloading: 打印卸载信息

每次循环都会触发回收:

loader,class,a对应的实例都是强引用,按道理强引用是宁愿OOM也不会垃圾回收,案例中为什么每次循环都会触发回收?
虽然每次循环中新创建了URLClassLoader对象、加载了类、实例化了对象,但是在循环结束后,这些对象都会丢失引用。因为这些对象都是在循环内部被创建的局部变量,一旦循环结束,它们就会超出作用域而无法再被访问到。
把案例中的代码注释打开,则每次循环都将产生的对象放在对应的集合中,产生了引用,所以不会导致回收:

1.2、堆区的垃圾回收
堆的垃圾回收,取决于对象是否被引用:
例如我现在有两个类,A中引用了B,B中引用了A
public class A {B b;
}
public class B {A a;
}public class Demo1 {public static void main(String[] args) {A a = new A();B b = new B();a.b = b;b.a = a;a = null;b = null;}
}在JVM中是这样的结构:

那么将a和b指向堆的地址设置成为null,能否触发垃圾回收呢?取决于不同的分析方法:
1.2.1、引用计数法
每个对象都有一个与之关联的引用计数器,当有新的引用指向该对象时,计数器加1;当引用不再指向该对象时,计数器减1。当一个对象的引用计数器为0时,即没有任何引用指向它,可以判定该对象为垃圾,可以被回收。
在上面的案例中,a指向A的实例时,引用计数器就+1,A的实例又指向B实例中的a时,计数再次+1,b同理。
如果将a和b指向堆的地址设置成为null,仍然保留了A的实例指向B中的a,B的实例指向A中的b的引用,即这种循环引用的情况下引用计数器无法归零,这也是引用计数法的缺陷之一。
引用计数法的缺陷:
无法处理循环引用: 如果存在循环引用的情况,即一组对象相互引用形成了一个环,那么这些对象的引用计数器就永远不会为0,导致它们无法被回收,从而引发内存泄漏。
计数器更新开销较大: 每次引用发生变化时,需要对相关对象的引用计数器进行更新,这会增加额外的开销,并且会在多线程环境下引入并发访问的问题。
无法处理跨代引用: 在分代垃圾回收算法中,对象通常被分为不同的代,而引用计数法无法处理跨代引用的情况,可能导致一些对象被错误地回收或长时间无法回收。
1.2.2、可达性分析
该算法通过从一组根对象(如线程栈、静态变量等)出发,递归地遍历所有可访问的对象,标记它们为可达对象,而未被标记的对象则被认为是不可达的,可以被回收。
可达性分析主要包括以下几个步骤:
-
确定根对象: 首先确定一组根对象,通常包括活跃线程的栈帧、静态变量以及常量池中的对象等。这些根对象是程序中已知的起始点,是可以直接或间接访问到的对象。
-
遍历可达对象: 从根对象开始,对每一个对象进行遍历,找出其引用的对象,并标记这些对象为可达对象。然后对这些被标记的对象再次进行遍历,重复这个过程,直到无法找到新的可达对象为止。
-
标记未被访问到的对象: 在完成可达对象的遍历后,所有未被标记的对象都可以被认为是不可达的,即无法从根对象出发访问到的对象。
-
回收不可达对象: 将所有不可达对象进行回收,释放它们占用的内存空间。
图中栈中的a,b即是根对象,当将a和b指向堆的地址设置成为null,A和B的实例就已经被标记为不可达,尽管内部依旧存在循环引用,但是依旧会被回收。
2、四种引用
2.1、强引用
强引用是最常见的引用类型,如果一个对象有强引用存在,那么它就不会被垃圾回收器回收。即使出现内存不足的情况,JVM也不会回收被强引用指向的对象。
什么时候一个对象会存在强引用?
- 对象被赋值给一个变量:例如,通过Object obj = new Object();将一个对象赋值给一个变量 obj ,此时obj持有该对象的强引用。
- 对象作为参数传递给方法:例如,调用方法时,将对象作为参数传递给方法,方法内部持有该对象的强引用。
- 对象作为实例变量存储在其他对象中:例如,一个类中的实例变量引用了一个对象,那么该对象就具有强引用,只要该类的实例还存在。
- 对象被设置为数组元素:例如,通过byte[] bytes1 = new byte[1024 * 1024 * 100];将一个对象存储在数组中的某个元素位置,该对象就具有强引用。
案例:
public class Demo1 {public static void main(String[] args) {byte[] bytes1 = new byte[1024 * 1024 * 100];byte[] bytes2 = new byte[1024 * 1024 * 100];}
}
将最大堆内存设置成200M,上面的代码执行,如果过程中没有发生GC,就会内存溢出。

可以看到,强引用即使是内存不足的情况下,也不会进行回收:

2.2、软引用
软引用是一种相对强引用弱化了一些的引用类型。当系统内存不足时,JVM会尝试回收被软引用指向的对象,但并不是必然回收,在这样的情况下,只有当对象已经没有强引用指向它时才会被回收。使用软引用可以有效地实现缓存功能。
同样将最大堆大小设置为200M。
byte数组对象被包装成了软引用(这里为什么要在包装成软引用后把bytes设置为null呢?可以思考一下)。
public class SoftReferenceDemo2 {public static void main(String[] args) throws IOException {byte[] bytes = new byte[1024 * 1024 * 100];SoftReference<byte[]> softReference = new SoftReference<byte[]>(bytes);bytes = null;System.out.println(softReference.get());byte[] bytes2 = new byte[1024 * 1024 * 100];System.out.println(softReference.get());}
}当创建第二个byte数组时,由于内存空间不足,对被包装成软引用的byte数组对象进行了回收。

如果不将bytes设置为null,则不会对被包装成软引用的byte数组对象进行了回收,因为bytes有强引用指向它。
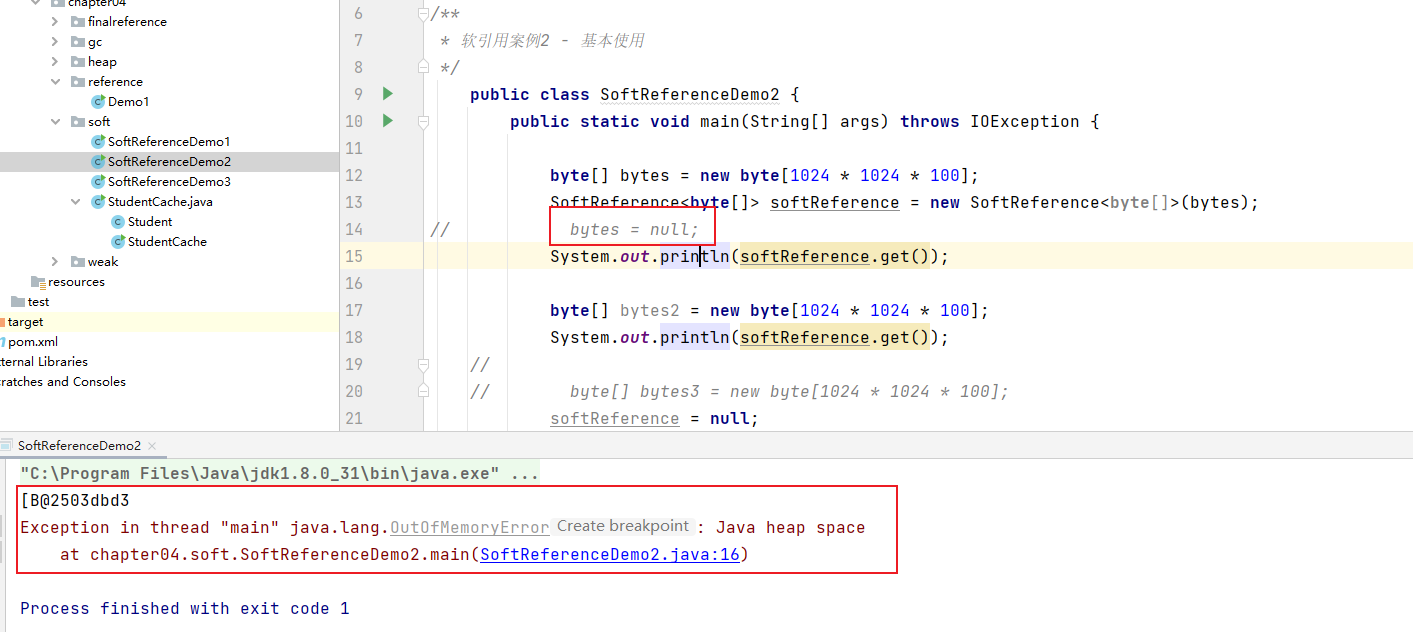

当被软引用SoftReference包装的实例对象被回收后,其容器SoftReference对象也要被回收,在SoftReference的构造方法中,提供了一个ReferenceQueue队列。
当被软引用SoftReference包装的实例对象被回收后,SoftReference对象会放入ReferenceQueue队列中

2.3、弱引用
弱引用比软引用的生命周期更短暂,一旦GC运行无论内存是否充足,被弱引用指向的对象就会被回收(如被包装成弱引用的原有对象具有强引用,依旧无法回收)。弱引用通常用于实现规范映射或者监听器模式。
public class Demo2 {public static void main(String[] args) {WeakReference<Object> weakReference = new WeakReference<>(new Object());System.out.println(weakReference.get());System.gc();System.out.println(weakReference.get());}
}
2.4、虚引用
虚引用是最弱的一种引用类型,它几乎没有实际作用,主要用于在对象被垃圾回收时收到一个系统通知。虚引用必须和引用队列(ReferenceQueue)一起使用。
PhantomReference<Object> phantomRef = new PhantomReference<>(new Object(), referenceQueue);此外还有一个finalize,它代表的是终结器引用。当对象被回收时,会将对象放入Finalizer类中的引用队列,并且稍后由FinalizerThread线程从队列中获取对象,执行finalize()方法,用于对象在被垃圾回收之前进行清理和释放资源操作。但是,具体的调用时间是不确定的,而且垃圾回收器也不保证一定会调用每个对象的finalize()方法。
finalize()方法是Object类中的,如果需要自定义逻辑只需要重写该方法。
案例:
可以在重写的finalize()方法中,再次将对象关联成强引用。
public class FinalizeReferenceDemo {public static FinalizeReferenceDemo reference = null;public void alive() {System.out.println("当前对象还存活");}@Overrideprotected void finalize() throws Throwable {try {System.out.println("finalize()执行了...");//设置强引用自救reference = this;} finally {super.finalize();}}public static void main(String[] args) throws Throwable {reference = new FinalizeReferenceDemo();test();test();}private static void test() throws InterruptedException {reference = null;//回收对象System.gc();//执行finalize方法的优先级比较低,休眠500ms等待一下Thread.sleep(500);if (reference != null) {reference.alive();} else {System.out.println("对象已被回收");}}
}由FinalizerThread线程从队列中获取对象:

小结:
日常程序开发中,创建出的对象绝大部分都是强引用,即使出现内存溢出,也不会对被强引用的对象进行垃圾回收。弱引用和软引用,区别在于前者是垃圾回收器只要发现了就会回收,后者是内存不足时才会被优先回收,但是共同点是,如果被包装成软/弱引用的原目标对象被强引用,则不会被回收。
3、垃圾回收算法
JVM常见的垃圾回收算法有:标记-清除算法,标记-整理算法,复制算法,分代回收算法。
无论哪一种算法,其核心思想是,先找到内存中存活的对象,然后清除其他的对象并释放内存,使得内存空间得以复用。
Java的垃圾回收是由单独负责GC的线程去执行的,但是在执行的过程中,都需要暂时停止用户线程(STW):

而评价一个垃圾回收算法的优劣,通常会关注以下几点:
-
内存利用效率:垃圾回收算法应该尽可能地高效利用内存,避免内存碎片化和内存泄漏问题。
-
垃圾回收的延迟:垃圾回收算法执行时,会导致程序停顿或延迟,这会影响系统的响应速度。因此,垃圾回收算法的评价中会考虑其对程序执行的影响,包括停顿时间的长短、频率等。
-
垃圾回收的吞吐量:垃圾回收算法应该尽可能地减少对程序的干扰,以提高程序的整体吞吐量。(垃圾回收的吞吐量,指用户执行代码的时间/GC时间)
-
碎片化处理能力:垃圾回收算法应该有效地处理内存碎片化问题,避免内存分配失败或者性能下降。
3.1、标记-清除算法
其核心思想在于,利用可达性分析,标记所有仍在使用中的对象,然后清除所有不可达的孤岛对象。(标记使用中的,清除未使用的)。
如图所示,C对象为不可达,会在下一次GC中被清除。
它的弊端在于,在清理过程中可能会存在内存碎片。
首先明白一点,内存是连续的,而未被标记即将被清理的对象,不会恰好都在一片连续的内存上,如图所示,红色部分代表被清理的对象。

由于内存碎片的存在,JVM同时会维护一个空余内存的链表,如果我要添加一个3字节的对象,可能会遍历到链表的尾部才能实现,如图所示,这样的效率就会较低。

3.2、标记-整理算法
为了解决上述内存碎片导致的相关问题,引入了标记-整理算法,相当于对标记-清除算法的一种改进。
其核心思想在于:通过可达性分析,将所有使用中的对象进行标记,然后对其进行整理,使其存放在一块连续的内存上,然后对所有未标记的对象进行清理:
标记阶段:

整理阶段:

但是依旧存在一些缺陷:
-
执行时间较长:标记-整理算法在整理阶段需要移动存活对象,这可能导致执行时间较长,尤其在内存使用较大时,整理操作对程序的停顿时间会更加明显。
-
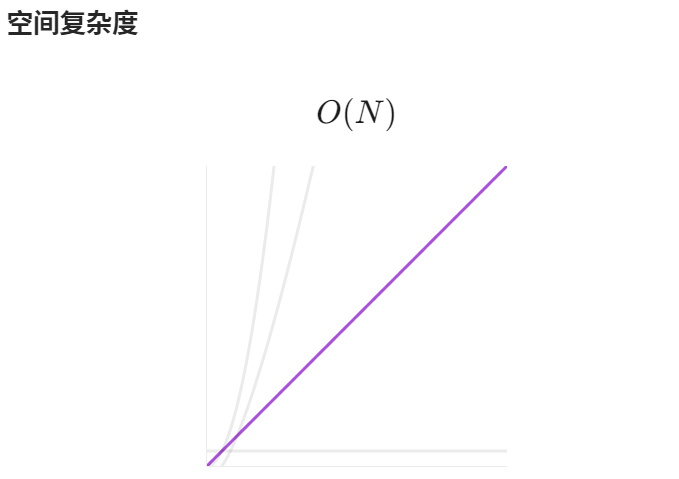
需要额外空间:标记-整理算法通常需要额外的空间来进行对象的移动操作,这可能会增加算法的空间复杂度,特别是当内存中存在大量存活对象时。
-
不适用于并发环境:标记-整理算法通常需要在整理阶段移动对象,这可能导致并发环境下的一些问题,比如需要暂停所有线程的执行,以保证整理操作的正确性。
3.3、复制算法
复制算法是另一种针对标记-清除算法的增强,其核心思想在于,将堆分为两个区域,分别是From和To,新创建的对象都在From中:
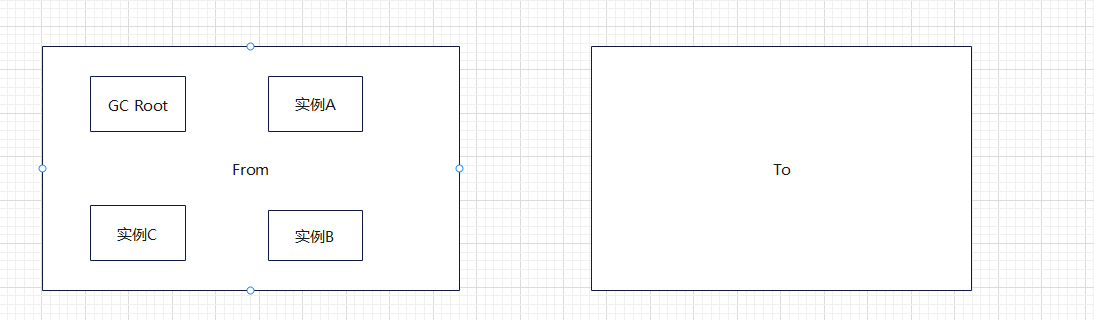
当需要GC时,将所有可达的对象放入To区域:

然后清理From区域:

最后将名称互换:

可达的对象在GC时都是在To空间。
复制算法的主要弊端在于:空间开销大,复制算法需要额外的一块同等大小的内存空间来进行存活对象的复制,这可能导致整体的内存利用率下降,特别是在内存空间受限的情况下。
3.4、分代回收算法
其核心思想是,将内存按代划分成新生代和老年代,其中新生代又由伊甸园区和From,To组成(复制算法):
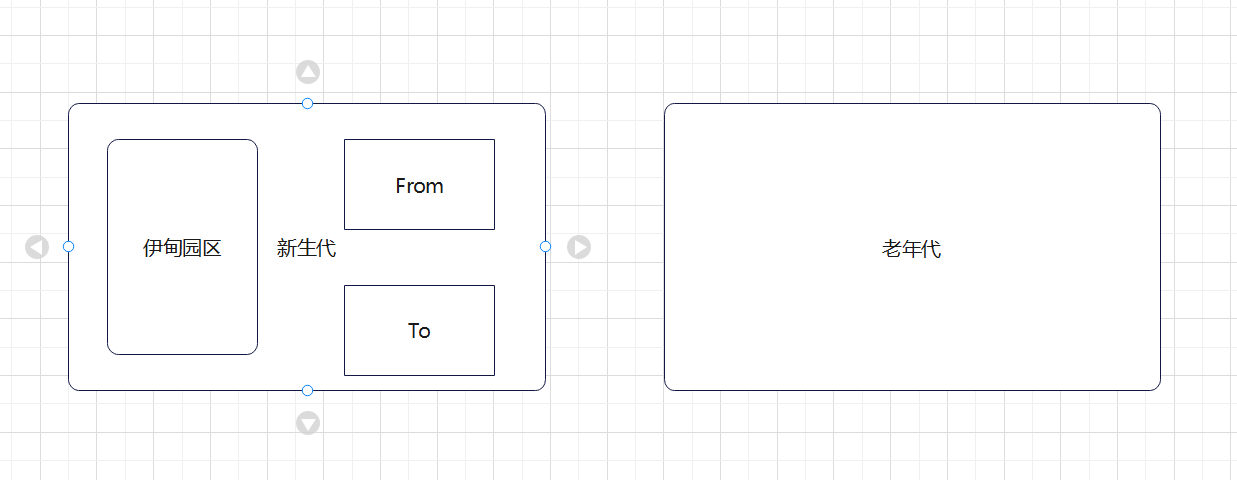
新创建的对象会被分配在伊甸园区,当伊甸园区空间充满后,会触发一次Minor GC回收掉不可达的对象,然后将剩下的对象放入To区,并且将From和To的名称互换。
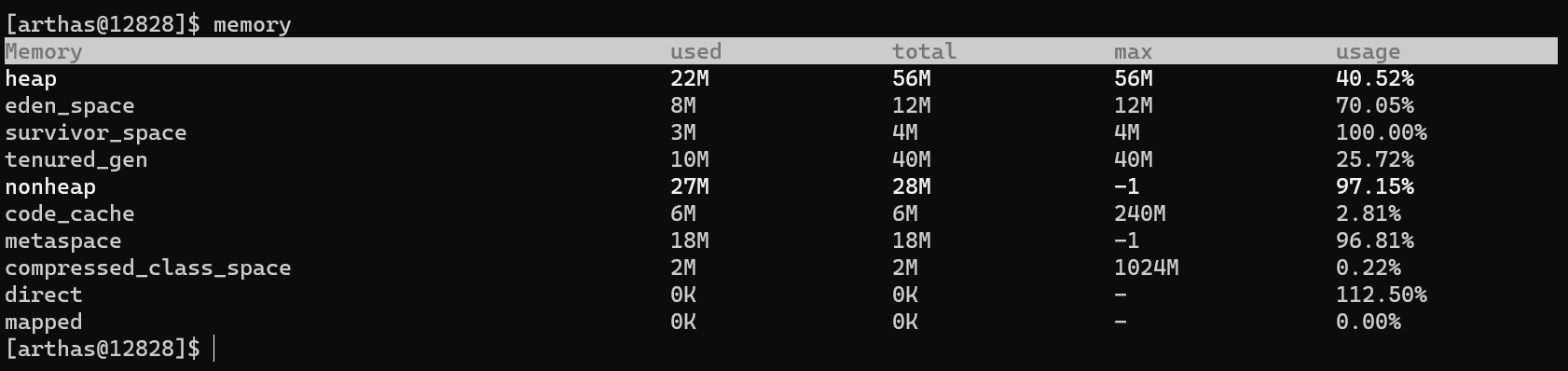
我们可以通过arthas工具查看一下这个过程:(JDK1.8版本需要添加JVM参数-XX:+UseSerialGC 表示使用Serial 和 SerialOld垃圾回收器,后面会说明)
public class GcDemo0 {public static void main(String[] args) throws IOException {List<Object> list = new ArrayList<>();int count = 0;while (true){System.in.read();System.out.println(++count);//每次添加1m的数据list.add(new byte[1024 * 1024 * 1]);}}
}然后通过arthas的memory命令查看(从上到下分别是伊甸园区,幸存者区,老年区):

同时我们也可以通过JVM命令自主设置这些区的大小:

我们进行如下设置:
-XX:+UseSerialGC -Xms60m -Xmn20m -Xmx60m -XX:SurvivorRatio=3 -XX:+PrintGCDetail
初始状态下,伊甸园区使用了8M
当我们添加了三次数据后触发了Minor GC:
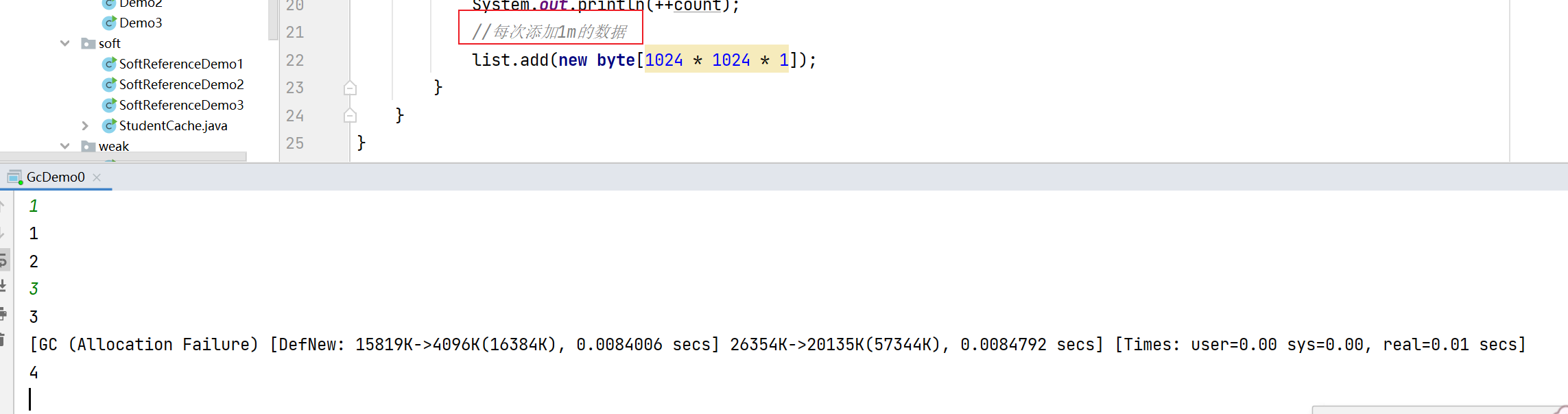
[GC (Allocation Failure) [DefNew: 15819K->4096K(16384K), 0.0084006 secs] 26354K->20135K(57344K), 0.0084792 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]:
- [GC (Allocation Failure) 表示这次垃圾回收是由于内存分配失败而触发的。
- [DefNew: 15819K->4096K(16384K)表示新生代(Young Generation)的垃圾回收情况。15819K是垃圾回收前新生代已使用的内存大小,4096K是垃圾回收后新生代已使用的内存大小,16384K是新生代总内存大小。
- 26354K->20135K(57344K)表示整个堆内存的垃圾回收情况。26354K是垃圾回收前堆内存已使用的大小,20135K是垃圾回收后堆内存已使用的大小,57344K是堆内存总大小。
- 0.0084006 secs:表示这次垃圾回收的实际耗时。
- [Times: user=0.00 sys=0.00, real=0.01 secs]:表示垃圾回收过程中消耗的CPU时间和实际时间。
垃圾回收前后的内存情况:

当某个对象在新生代存活过了最多15次垃圾回收(存在一种特殊情况:如果新生代的内存已满,即使年龄没有到达15,依旧会被放入老年代),JVM会认为它很难被回收,就会放入老年区中。 当老年代空间不足时,会先触发一次Minor GC,如果内存依旧不足,则会触发一次Full GC对新生代和老年代所有的垃圾进行回收,若Full GC后依旧无法回收老年代的垃圾,就会触发OOM错误。
老年代空间不足,并且触发了Minor GC依旧内存不足:

触发Full GC:

由于案例中的对象都是强引用,所以无法回收,再次向老年代放入则会触发OOM:

4、垃圾回收器
垃圾回收器是负责管理堆内存中对象的回收和内存释放的组件。JVM的垃圾回收器有多种不同的实现,通常新生代的垃圾回收器需要和老年代的垃圾回收器配合使用:
4.1、Serial&Serial Old
第一种组合方式是Serial(新生代)和Serial Old(老年代):
Serial、Serial Old是一个单线程的收集器,有一个专门用于GC的线程进行垃圾回收,过程中会暂停所有用户线程来进行垃圾回收。
区别在于,Serial使用的是复制算法,而Serial Old使用的是标记-整理算法。
如果需要使用该垃圾回收器,需要配合JVM参数:-XX:+UseSerialGC
可以通过arthas的dashboard命令查看:

4.2、ParNew&CMS(Serial Old)
第二种组合方式是ParNew(新生代)配合CMS(老年代)或Serial Old(老年代)
ParNew&Serial Old的组合,实际上是针对Serial&Serial Old的一种优化,使用多线程进行垃圾回收,ParNew使用的依旧是复制算法。
可通过JVM参数-XX:+UseParNewGC 使用:

CMS垃圾回收器在尽量减少停顿时间的同时进行垃圾回收。适用于对响应时间要求较高的应用。允许用户线程和垃圾回收线程在某些时刻同时运行。 使用的是标记-清除算法
执行主要分为四个阶段:
- 初始标记阶段:CMS会暂停所有应用线程来标记根对象。
- 并发标记阶段:CMS收集器会和应用程序线程并发地标记整个堆内存中的对象。
- 重新标记阶段:由于并发标记阶段没有暂停应用线程,某些对象可能发生改变,所以需要二次标记。(暂停所有应用线程)
- 并发清理阶段:与应用程序并发的执行,清理所有未被标记的对象。
它存在的缺陷:
- 因为使用的是标记-清除算法,所以会产生内存碎片。
- 在并发清理阶段,因为应用程序没有暂停,所以在清理的过程中也可能会存在新的垃圾。
- 如果老年代内存不足无法分配对象,CMS会退化为Serial Old单线程回收老年代。
4.3、Paraller Scavenge&Paraller Old
最后一种组合是Paraller Scavenge(新生代)配合Paraller Old(老年代)
Paraller Scavenge&Paraller Old组合,通过多线程并行地进行垃圾收集,将应用程序的暂停时间降到最低,以此来提高系统的吞吐量。Paraller Scavenge使用的是复制算法,Paraller Old使用的是标记-整理算法 ,在GC期间会暂停所有其他线程的执行。
在JDK1.8中,默认就是使用该组合进行垃圾回收,无需额外设置JVM参数。
同时这个组合允许自定义最大暂停时间、吞吐量以及自动调整内存大小:
- -XX:MaxGCPauseMillis= 设置最大暂停时间
- -XX:GCTimeRatio = 设置吞吐量
- -XX:+UseAdaptiveSizePolic 自动调整内存大小
4.4、G1垃圾回收
G1垃圾回收器是在JDK 7中引入的一种全新的垃圾回收器,并在JDK9中成为默认的垃圾回收器。
它具有以下的特点:
- 区域化内存管理:G1将堆内存划分为多个大小相等的区域,每个区域既可以用作新生代也可以用作老年代,这样就消除了新生代和老年代之间的严格划分。
- 并发和并行:G1垃圾回收器在标记、整理和清理阶段都可以利用并发和并行的方式进行垃圾回收,以减少暂停时间并提高吞吐量。
- 持续性垃圾回收:G1会根据应用程序的动态情况来选择哪些区域进行垃圾回收,以尽可能地减少垃圾回收的暂停时间。
- 可预测的暂停:G1通过一种叫做“垃圾优先(Garbage-First)”的算法来选择优先回收哪些区域,从而实现可预测的垃圾回收暂停时间。
在分代回收算法中,划分的新生代和老年代的内存空间是连续的:
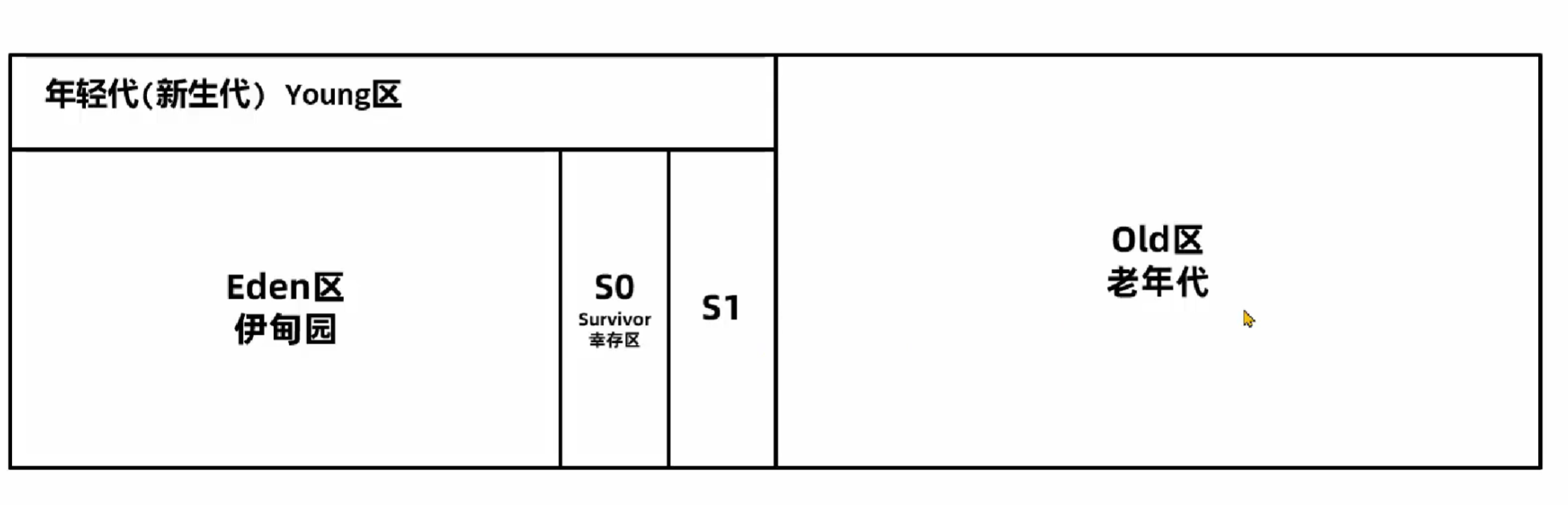
而在G1垃圾回收器中,新生代与新生代,老年代与老年代之间并非一定是一块完整的区域:

而是将堆划分为大小相同的区域,每个区域的大小可以通过堆大小/2048算得,也可以自己通过JVM参数进行设置:-XX:G1HeapRegionSize= ,但是参数的值必须是2的指数幂,并且最大为32。
在垃圾回收时,分为新生代回收和混合回收:
4.4.1、新生代回收
当新生代的空间达到60%时,会触发一次回收,使用的是复制算法 (标记伊甸园区和幸存者区,放入另一个幸存者区),但是为了兼顾最大暂停时间,通常不会对所有的垃圾进行回收。当某个对象的年龄到达15时会被放入老年代。
如果某个对象的大小大于该区域的1/2,例如某个区域分配的大小为4M,某个对象的大小为3M,这些对象会被集中存放入Homongous区中。
4.4.2、混合回收
当多次新生代回收后,总堆占有率达到阈值时,会触发混合回收,使用的是复制算法 ,
混合回收的阶段:
- 初始标记阶段:会暂停用户线程,标记所有GC Root引用的对象(不包含该对象的引用链)。
- 并发标记阶段:会和用户线程并发执行,将第一步中对象的引用链一并标记为存活。
- 最终标记阶段:会暂停用户线程,主要是标记第二步中发生引用改变漏标的对象。
- 并发清理阶段:会和用户线程并发执行,将存活的对象通过复制算法 复制到其他区域。
和CMS四个阶段的区别:
| CMS | 混合回收 | |
| 初始标记阶段 | 标记所有GC Root引用的对象 | 标记所有GC Root引用的对象 |
| 并发标记阶段 | 标记所有的对象 | 标记第一步中对象的引用链 |
| 最终(重新)标记阶段 | 标记第二步中错标,漏标的对象 | 标记第二步中发生引用改变漏标的对象,不管新创建和不再关联的对象 |
| 并发清理阶段 | 使用的是标记-清除算法 | 将存活的对象通过复制算法 复制到其他区域。 |
G1进行老年代回收时,也会优先清理存活度最低的区域,但是在清理的过程中,如果没有足够的区域去转移对象,就会触发Full GC,这时使用的是标记-整理算法。
总结
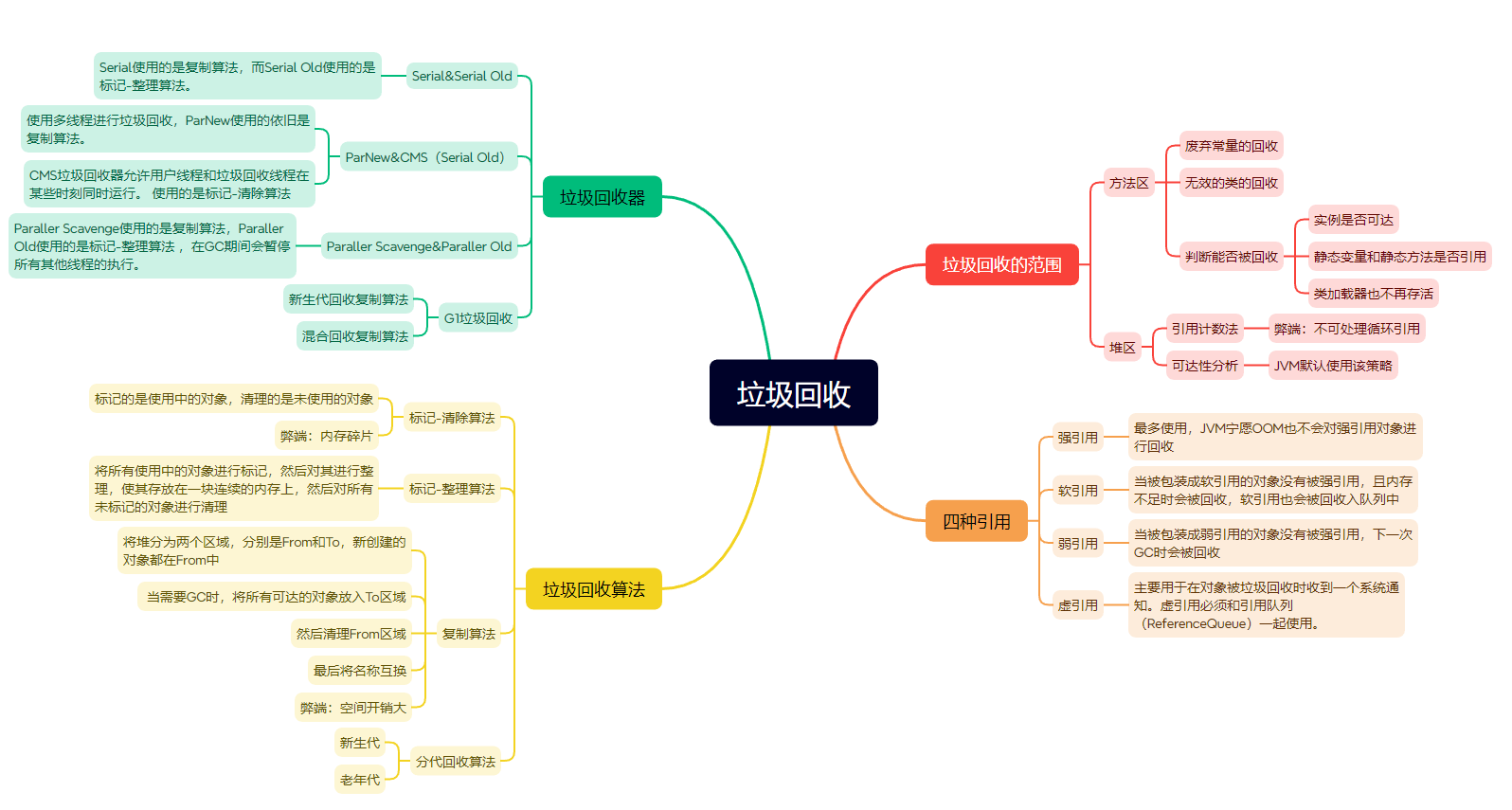
JVM基础篇完结
相关文章:
JVMの垃圾回收
在上一篇中,介绍了JVM组件中的运行时数据区域,这一篇主要介绍垃圾回收器 JVM架构图: 1、垃圾回收概述 在第一篇中介绍JVM特点时,有提到过内存管理,即Java语言相对于C,C进行的优化,可以在适当的…...

人工智能就业方向有哪些?
人工智能就业方向有哪些? 随着人工智能技术的不断发展,其应用领域也越来越广泛。对于想要进入人工智能领域的年轻人来说,选择一个合适的职业方向是至关重要的。今天给大家介绍六个热门的人工智能就业方向,分别是机器学习工程师、自然语言处理…...

自定义类型:枚举和联合体
在之前我们已经深入学习了自定义类型中的结构体类型 ,了解了结构体当中的内存对齐,位段等知识,接下来在本篇中将继续学习剩下的两个自定义类型:枚举类型与联合体类型,一起加油!! 1.枚举类型 …...

负载均衡加权轮询算法
随机数加权轮询算法 public int select() {int[] weights {10, 20, 50};int totalWeight weights[0] weights[1] weights[2];// 取随机数int offset ThreadLocalRandom.current().nextInt(totalWeight);for (int i 0; i < weights.length; i) {offset - weights[i];i…...
PyTorch 相关知识介绍
一、PyTorch和TensorFlow 1、PyTorch PyTorch是由Facebook开发的开源深度学习框架,它在动态图和易用性方面表现出色。它以Python为基础,并提供了丰富的工具和接口,使得构建和训练神经网络变得简单快捷。 发展历史和背景 PyTorch 是由 Fac…...

1千2初中英语语法题库ACCESS\EXCEL数据库
英语语法是针对英语语言进行研究后,系统地总结归纳出来的一系列语言规则。英语语法的精髓在于掌握语言的使用。比如词类有名词、代词、数词、感叹词等,时态有一般状态、进行状态、完成状态和完成进行状态四种,语态有主动语态、被动语态等。 …...
高德面试:为什么Map不能插入null?
在 Java 中,Map 是属于 java.util 包下的一个接口(interface),所以说“为什么 Map 不能插入 null?”这个问题本身问的不严谨。Map 部分类关系图如下: 所以,这里面试官其实想问的是:为…...

MySQL数据库主从配置
MySQL主从配置 1. 修改数据库my.cnf文件 修改数据库my.cnf文件,在文件中添加如下内容,其中主数据库的server-id必须要比从库的更小。 # 注册集群id server-id101 # 开启二进制日志文件 log-binmysql-bin # 设置日志格式 binlog-formatrow # 开启中继日…...

测试工程师经常使用的Python中的库,以及对应常用的函数
os (操作系统接口) 该库提供了许多与操作系统交互的函数,如文件处理、目录操作、进程管理等。 常用功能包括: os.name: 获取操作系统的名称。 os.path: 用于操作文件路径的模块,如os.path.join拼接路径。 os.mkdir: 创建目录。 os.remove: 删…...
【frp】服务端配置与systemd启动
ini配置的方式已经废弃。官方文档是toml 。阿里云ecs 部署服务端参考大神的文章 使用Frp配置内网访问(穿透) 0.54 版本 我现在用最新的0.58版本。systemd apt install systemdfrp服务端配置 /root/frp目录 vim frps.toml#服务绑定的IP与端口 bindAddr = "0.0.0.0" …...
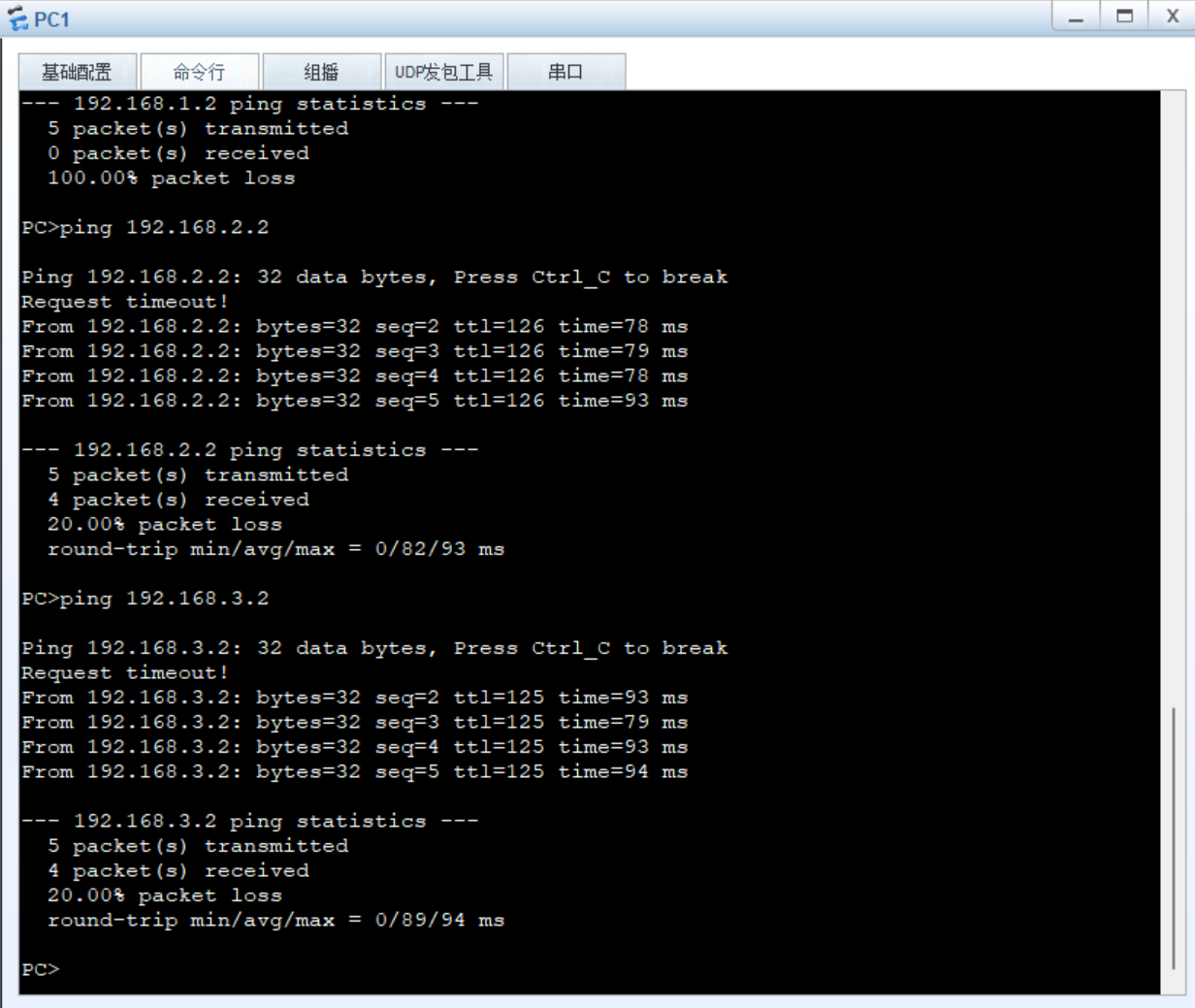
计算机网络学习实践:模拟RIP动态路由
计算机网络学习实践:模拟RIP动态路由 模拟动态路由RIP协议 1.实验准备 实验环境:华为模拟器ENSP 实验设备: 3个路由器,3个二层交换机(不是三层的),3个PC机 5个网段 192.168.1.0 255.255.…...

详解 Flink 的常见部署方式
一、常见部署模式分类 1. 按是否依赖外部资源调度 1.1 Standalone 模式 独立模式 (Standalone) 是独立运行的,不依赖任何外部的资源管理平台,只需要运行所有 Flink 组件服务 1.2 Yarn 模式 Yarn 模式是指客户端把 Flink 应用提交给 Yarn 的 ResourceMa…...

【UE5.1 角色练习】11-坐骑——Part1(控制大象移动)
前言 在上一篇(【UE5.1 角色练习】10-物体抬升、抛出技能 - part2)基础上创建一个新的大象坐骑角色,并实现控制该角色行走的功能。 效果 步骤 1. 在商城中下载“African Animal Pack”资产和“ANIMAL VARIETY PACK”资产导入工程中 2. 复…...

数据结构严蔚敏版精简版-线性表以及c语言代码实现
线性表、栈、队列、串和数组都属于线性结构。线性结构的基本特点是除第一个元素无直接前驱,最后一个元素无直接后继之外,其他每个数据元素都有一个前驱和后继。 1 线性表的定义和特点 如此类由n(n大于等于0)个数据特性相同的元素…...

【react】react项目支持鼠标拖拽的边框改变元素宽度的组件
目录 安装使用方法示例Props 属性方法示例代码调整兄弟div的宽度 re-resizable github地址 安装 $ npm install --save re-resizable这将安装re-resizable库并将其保存为项目的依赖项。 使用方法 re-resizable 提供了一个 <Resizable> 组件,它可以包裹任何…...
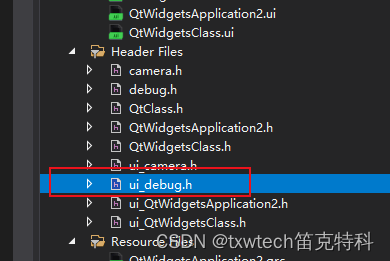
QT 创建文件 Ui 不允许使用不完整类型,可以尝试添加一下任何头文件
#include "debug.h" #include "qmessagebox.h" #pragma execution_character_set("utf-8") //QT 创建文件 Ui 不允许使用不完整类型,尝试添加一下任何头文件,或者添加ui_xx.h头文件 debug::debug(QWidget *parent) : QDialog(p…...

Python:深入探索其生态系统与应用领域
Python:深入探索其生态系统与应用领域 Python,作为一种广泛应用的编程语言,其生态系统之丰富、应用领域之广泛,常常令人叹为观止。那么,Python究竟涉及哪些系统?本文将从四个方面、五个方面、六个方面和七…...
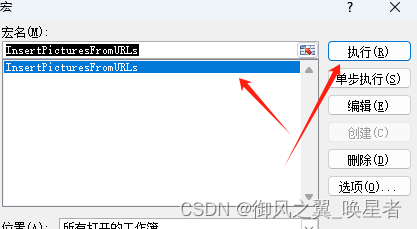
EXCEL从图片链接获取图片
step1: 选中图片地址列 step2:开发工具→Visual Basic 文件→导入 导入我制作的脚本(代码见文章末尾) 点击excel的小图标回到表格界面。 点击【宏】 选中刚才导入的脚本,点执行,等待完成。 代码本体: Sub InsertPict…...
)
Docker迁移默认存储目录(GPT-4o)
Docker在Ubuntu的默认存储目录是/var/lib/docker,要将 Docker 的默认存储目录迁移到指定目录(譬如大存储磁盘),可以通过修改 Docker 守护进程的配置文件来实现。 1.创建新的存储目录: 选择你想要存储 Docker 分层存储…...
植物大战僵尸杂交版2.0.88最新版安装包
游戏简介 游戏中独特的杂交植物更是为游戏增添了不少亮点。这些杂交植物不仅外观独特,而且拥有更强大的能力,能够帮助玩家更好地应对游戏中的挑战。玩家可以通过一定的条件和方式,解锁并培养这些杂交植物,从而不断提升自己的战斗…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...