MySQL深分页,limit 100000,10 优化
文章目录
- 一、limit深分页为什么会变慢
- 二、优化方案
- 2.1 通过子查询优化(覆盖索引)
- 回顾B+树结构
- 覆盖索引
- 把条件转移到主键索引树
- 2.2 INNER JOIN 延迟关联
- 2.3 标签记录法(要求id是有序的)
- 2.4 使用between...and...
我们日常做分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。本文将分4个方案,讨论如何优化MySQL百万数据的深分页问题.
参考 实战!聊聊如何解决MySQL深分页问题
一、limit深分页为什么会变慢
表结构
CREATE TABLE account (id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',name varchar(255) DEFAULT NULL COMMENT '账户名',balance int(11) DEFAULT NULL COMMENT '余额',create_time datetime NOT NULL COMMENT '创建时间',update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (id),KEY idx_name (name),KEY idx_update_time (update_time) //索引
) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
执行的深分页SQL为
select id,name,balance from account where update_time> '2020-09-19' limit 100000,10;
这个SQL的执行时间如下:

执行完需要0.742秒,深分页为什么会变慢呢?如果换成 limit 0,10,只需要0.006秒哦

我们先来看下这个SQL的执行流程:
-
通过普通二级索引树idx_update_time,过滤update_time条件,找到满足条件的记录ID。
-
通过ID,回到主键索引树,找到满足记录的行,然后取出展示的列(回表)
-
扫描满足条件的100010行,然后扔掉前100000行,返回。
(每一条select语句都会从1遍历至当前位置,若跳转到第10000页,则会遍历100000条记录)

执行计划如下: 
SQL变慢原因有两个:
- limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说
limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。 limit 100000,10扫描更多的行数,也意味着回表更多的次数。
二、优化方案
2.1 通过子查询优化(覆盖索引)
因为以上的SQL,回表了100010次,实际上,我们只需要10条数据,也就是我们只需要10次回表其实就够了。因此,我们可以通过减少回表次数来优化。
回顾B+树结构
如何减少回表次数呢?我们先来复习下B+树索引结构
InnoDB中,索引分主键索引(聚簇索引)和二级索引
- 主键索引,叶子节点存放的是整行数据
- 二级索引,叶子节点存放的是主键的值。

覆盖索引
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
如何确定数据库成功使用了覆盖索引呢? —— 当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息

可以看到Extra中的Using index,表明我们成功使用了覆盖索引
把条件转移到主键索引树
如果我们把查询条件,转移回到主键索引树,那就不就可以减少回表次数啦。转移到主键索引树查询的话,查询条件得改为主键id了,之前SQL的update_time这些条件咋办呢?抽到子查询那里嘛~
子查询那里怎么抽的呢?因为二级索引叶子节点是有主键ID的,所以我们直接根据update_time来查主键ID即可,同时我们把 limit 100000的条件,也转移到子查询,完整SQL如下:
select id,name,balance FROM account where id >= (select a.id from account a where a.update_time >= '2020-09-19' limit 100000, 1) LIMIT 10; -- (可以加下时间条件到外面的主查询)
查询效果一样的,执行时间只需要0.038秒! 0.742秒 ——> 0.038秒

我们来看下执行计划 
由执行计划得知,子查询 table a查询是用到了idx_update_time索引。首先在索引上拿到了聚集索引的主键ID,省去了回表操作,然后第二查询直接根据第一个查询的ID往后再去查10个就可以了!

所谓的覆盖索引就是从普通索引树中就能查到的想要数据,而不需要通过回表从主键索引中查询其他列,能够显著提升性能。
因此,这个方案是可以的~
2.2 INNER JOIN 延迟关联
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,然后减少回表。不同点是,延迟关联使用了inner join代替子查询。
优化后的SQL如下:
SELECT acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.update_time >= '2020-09-19' ORDER BY a.update_time LIMIT 100000, 10) AS acct2 on acct1.id= acct2.id;
查询效果也是杠杆的,只需要0.034秒

执行计划如下:
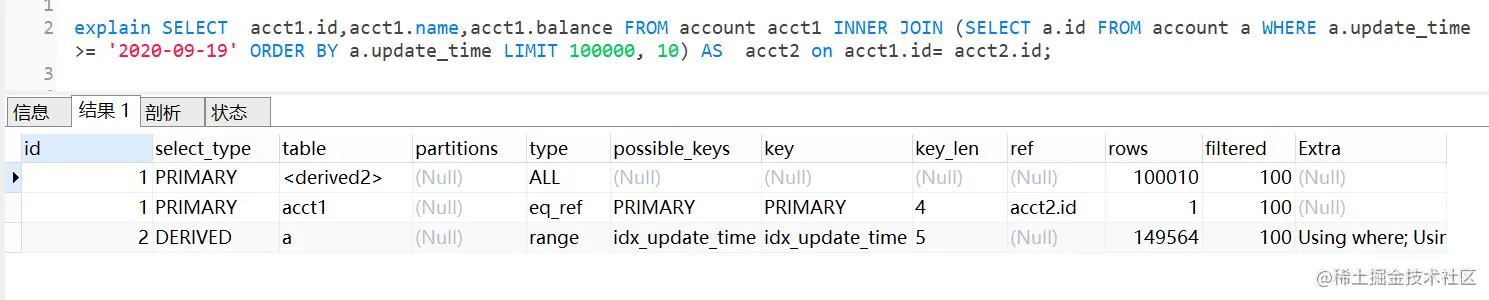
查询思路就是,先通过idx_update_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
2.3 标签记录法(要求id是有序的)
limit 深分页问题的本质原因就是:偏移量(offset)越大,mysql就会扫描越多的行,然后再抛弃掉。这样就导致查询性能的下降。
其实我们可以采用标签记录法,就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
select id,name,balance from account limit 1000000,10;
假设上一次记录到100000,则SQL可以优化为:
select id,name,balance FROM account where id > 100000 order by id limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引。但是你,这种方式有局限性:要求id是连续的、并且有序。
在有序的条件下,也可以使用比如创建时间等其他字段来代替主键id,但是前提是这个字段是建立了索引的。
id不是连续,我们可以通过order by让它连续
总之,使用条件过滤的方式来优化 limit 是有诸多限制的,一般还是推荐使用覆盖索引的方式来优化。
2.4 使用between…and…
很多时候,可以将limit查询转换为已知位置的查询,这样MySQL通过范围扫描between...and,就能获得到对应的结果。
select id,name,balance from account limit 1000000,10;
如果知道边界值为100000,100010后,就可以这样优化:
select id,name,balance FROM account where id between 100000 and 100010 order by id desc;
相关文章:
MySQL深分页,limit 100000,10 优化
文章目录 一、limit深分页为什么会变慢二、优化方案2.1 通过子查询优化(覆盖索引)回顾B树结构覆盖索引把条件转移到主键索引树 2.2 INNER JOIN 延迟关联2.3 标签记录法(要求id是有序的)2.4 使用between...and... 我们日常做分页需…...

Linux[高级管理]——使用源码包编译安装Apache网站
🏡作者主页:点击! 👨💻Linux高级管理专栏:点击! ⏰️创作时间:2024年5月31日14点20分 🀄️文章质量:96分 在Linux系统上编译和安装Apache HTTP Server是…...

Docker+JMeter+InfluxDB+Grafana 搭建性 能监控平台
JMeter原生报告的缺点: 无法实时共享 报告信息的展示不美观 需求方案 为了解决上述问题,可以通过 InfluxDB Grafana解决 : InfluxDB :是一个开源分布式指标数据库,使用 Go 语言编写,无需外部依赖 应用&am…...
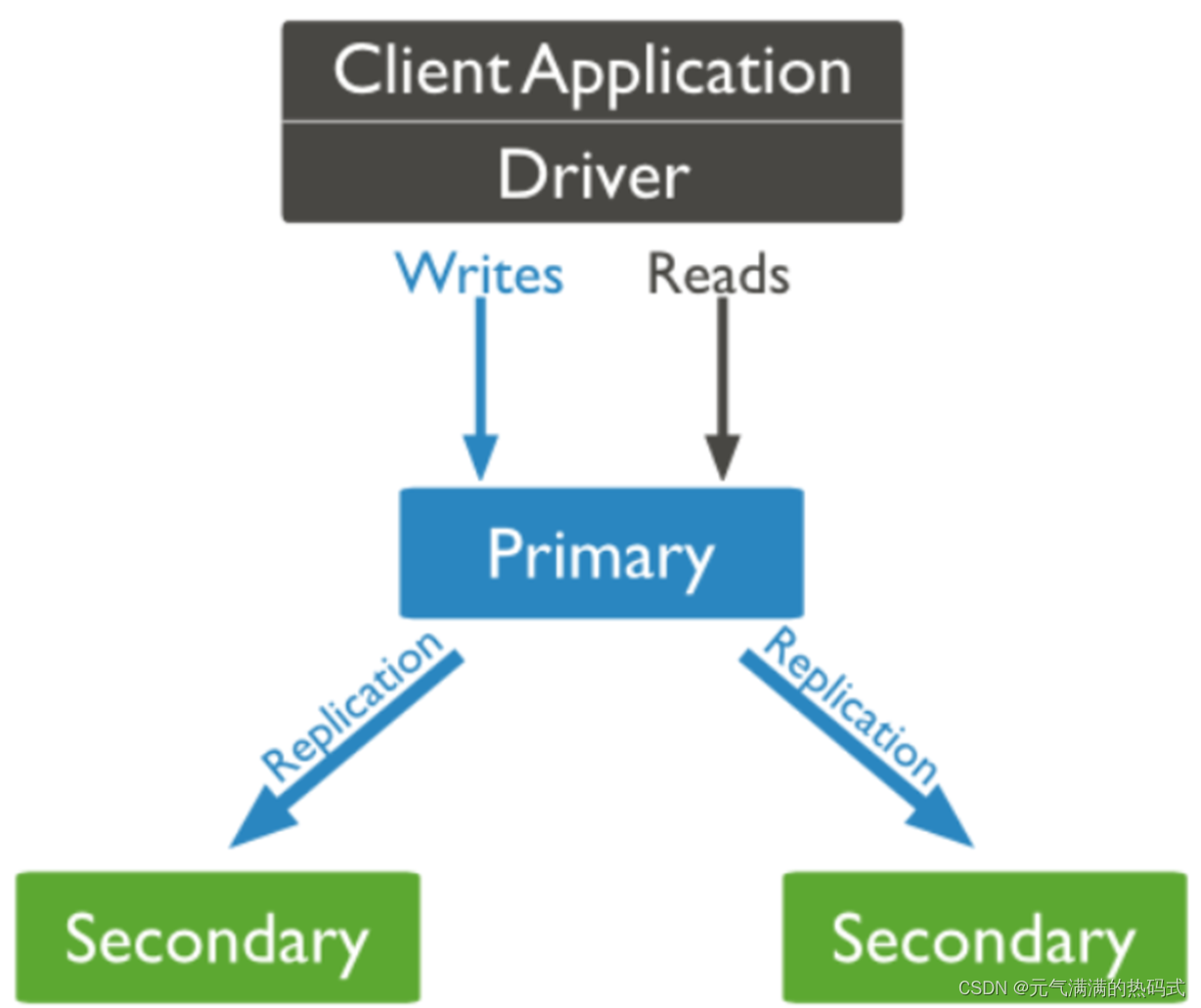
NoSQL实战(MongoDB搭建主从复制)
什么是复制集? MongoDB复制是将数据同步到多个服务器的过程; 复制集提供了数据的冗余备份并提高了数据的可用性,通常可以保证数据的安全性; 复制集还允许您从硬件故障和服务中断中恢复数据。 保障数据的安全性 数据高可用性 (2…...

【讯为Linux驱动开发】3.内核空间和用户空间
【问】内存空间的组成部分?? 内存空间分为内核空间和用户空间 1.内核空间控制硬件资源,提供系统调用接口,保护系统自身安全稳定 2.用户空间实现业务逻辑 【问】如何进入内核空间使用硬件资源? 1.系统调用 2.软中断 3.…...
AI论文:一键生成论文的高效工具
说到这个问题,那真的得看你对“靠谱”的定义是怎样的啦? 众所周知,写论文是一项极其耗时间的事情,从开始的选题到文献资料搜索查阅,大纲整理等等一大堆的繁杂工作是极艰辛的。用AI写论文就不一样了,自动化…...
申请医疗设备注册变更时,需要补充考虑网络安全的情况有哪些?
在申请医疗器械设备注册变更时,需要补充网络安全的情况主要包括以下几点: 网络安全功能更新:如果医疗器械的自研软件发生网络安全功能更新,或者合并网络安全补丁更新的情形,需要单独提交一份自研软件网络安全功能更新…...
)
打对钩的方式做人机验证(vue+javascript)
要实现一个通过打对钩方式的人机验证,并且让它不容易被破解,可以考虑以下几点: 动态生成选项和题目:每次生成的验证选项和题目都不一样,防止简单的脚本通过固定的答案绕过验证。使用图像和文字混合验证:增…...

可视化脚本用于使用MMDetection库进行图像的目标检测
# Copyright (c) OpenMMLab. All rights reserved. import asyncio from argparse import ArgumentParserfrom mmdet.apis import (async_inference_detector, inference_detector,init_detector, show_result_pyplot) import denseclip# 解析命令行参数 def parse_args():pars…...
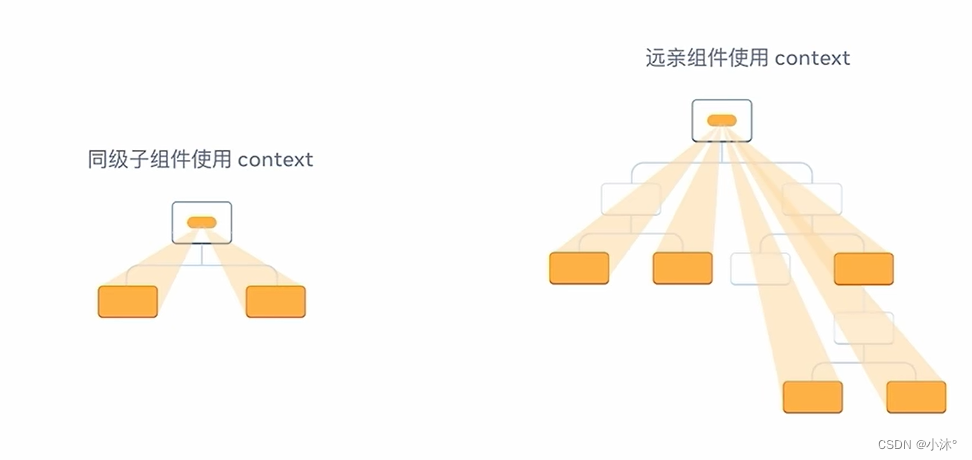
React-组件通信
组件通信 概念:组件通信就是组件之间的数据传递,根据组件嵌套关系的不同,有不同的通信方法 父传子 基础实现 实现步骤: 1.父组件传递数据-在子组件标签上绑定属性 2.子组件接收数据-子组件通过props参数接收数据 props说明 1.…...
低代码选型要注意什么问题?
低代码选型时,确实需要从多个角度综合考虑,以下是根据您给出的角度进行的分析和建议: 公司的人才资源: 评估团队中是否有具备编程能力的开发人员,以确保能够充分利用低代码平台的高级功能和进行必要的定制开发。考察实…...
fpga入门 串口定时1秒发送1字节
一、 程序说明 FPGA通过串口定时发送数据,每秒发送1字节,数据不断自增 参考小梅哥教程 二、 uart_tx.v timescale 1ns / 1psmodule uart_tx(input wire sclk,input wire rst_n,output reg uart_tx);parameter …...

总结一下自己,最近三年,我做了哪些工作
简单总结下吧,我算是业务架构师,确实对得起这个名字,经常冲在一线,业务和架构相关的东西都有做,系统比较复杂,不过逐步了解谁都会熟悉的 下面简单列一列我这三年的工作情况吧,也算是给自己一个交…...

SpringCloud Gateway基础入门与使用实践总结
官网文档:点击查看官网文档 Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关。但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,那就是SpringCloud Gateway一句话…...
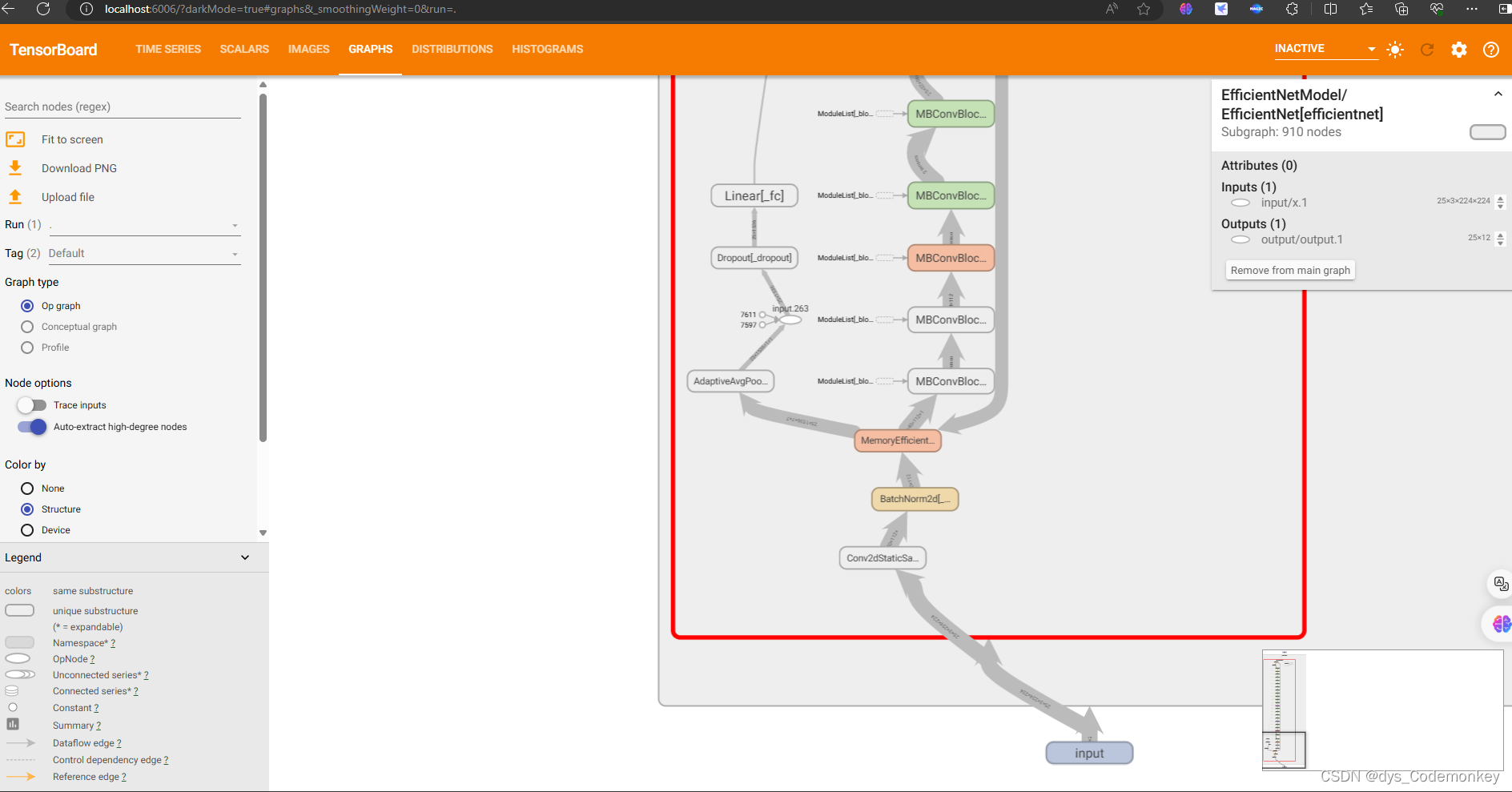
TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard 模块导入日志记录文件的创建训练中如何写入数据如何提取保存的数据调用TensorBoard面板可能会遇到的问题 模块导入 首先从torch中导入tensorboard的SummaryWriter日志记录模块 from torch.utils.tensorboard import SummaryWriter然后导入要用到的os库࿰…...

【Vue】普通组件的注册使用-全局注册
文章目录 一、使用步骤二、练习 一、使用步骤 步骤 创建.vue组件(三个组成部分)main.js中进行全局注册 使用方式 当成HTML标签直接使用 <组件名></组件名> 注意 组件名规范 —> 大驼峰命名法, 如 HmHeader 技巧…...
爬虫之反爬思路与解决手段
阅读时间建议:4分钟 本篇概念比较多,嗯。。 0x01 反爬思路与解决手段 1、服务器反爬虫的原因 因为爬虫的访问次数高,浪费资源,公司资源被批量抓走,丧失竞争力,同时也是法律的灰色地带。 2、服务器反什么…...
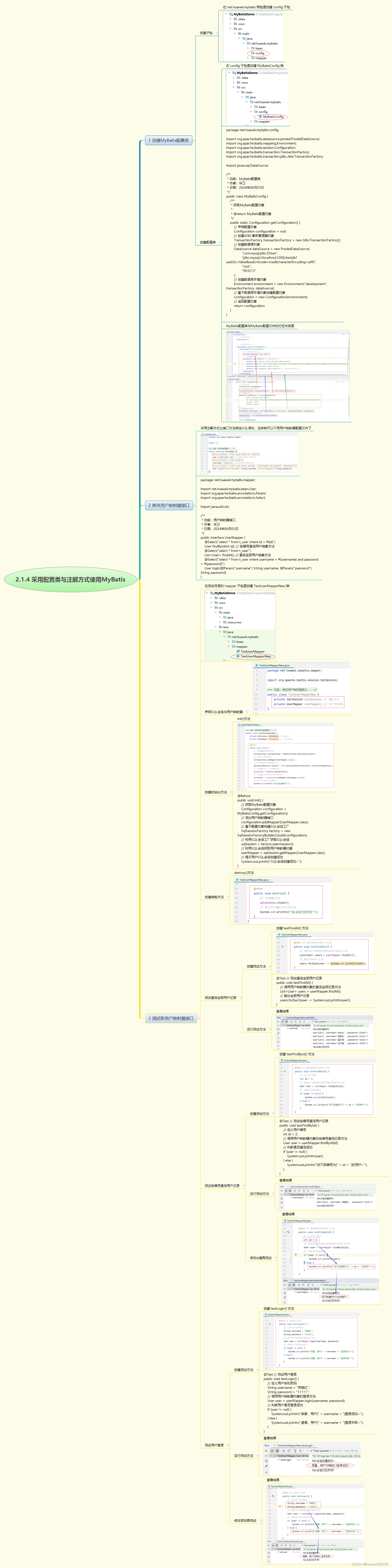
2.1.4 采用配置类与注解方式使用MyBatis
实战概述:采用配置类与注解方式使用MyBatis 创建MyBatis配置类 在net.huawei.mybatis.config包中创建MyBatisConfig类,用于配置MyBatis核心组件,包括数据源、事务工厂和环境设置。 配置数据源和事务 使用PooledDataSource配置MySQL数据库连接…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...