TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard
- 模块导入
- 日志记录文件的创建
- 训练中如何写入数据
- 如何提取保存的数据调用TensorBoard面板
- 可能会遇到的问题
模块导入
首先从torch中导入tensorboard的SummaryWriter日志记录模块
from torch.utils.tensorboard import SummaryWriter
然后导入要用到的os库,当然你们也要导入自己模型训练需要用到的库
import os
日志记录文件的创建
import oslog_dir = 'runs/EfficientNet_B3_experiment2'# 检查目录是否存在
if os.path.exists(log_dir):# 如果目录存在,获取目录下的所有文件和子目录列表files = os.listdir(log_dir)# 遍历目录下的文件和子目录for file in files:# 拼接文件的完整路径file_path = os.path.join(log_dir, file)# 判断是否为文件if os.path.isfile(file_path):# 如果是文件,删除该文件os.remove(file_path)elif os.path.isdir(file_path):# 如果是目录,递归地删除目录及其下的所有文件和子目录for root, dirs, files in os.walk(file_path, topdown=False):for name in files:os.remove(os.path.join(root, name))for name in dirs:os.rmdir(os.path.join(root, name))os.rmdir(file_path)# 创建新的SummaryWriter
writer = SummaryWriter(log_dir)
这个代码会自动创建并更新日志文件目录,请谨慎使用,记得改
log_dir = 'runs/EfficientNet_B3_experiment2'路径名字小心把之前保存好的数据删除了
之后模型训练的数据将会写入到log_dir这个路径文件中,在由TensorBoard张量板调用显示数据
训练中如何写入数据
for epoch in range(num_epochs):model.train()running_loss = 0.0correct = 0total = 0start_time = time.time()for images, labels in train_loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 记录学习率current_lr = optimizer.param_groups[0]['lr']writer.add_scalar('Learning Rate', current_lr, epoch)# 记录梯度范数total_norm = 0for p in model.parameters():param_norm = p.grad.data.norm(2)total_norm += param_norm.item() ** 2total_norm = total_norm ** 0.5writer.add_scalar('Gradient Norm', total_norm, epoch)running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()train_loss = running_loss / len(train_loader)train_accuracy = 100 * correct / total# 记录训练损失和准确率writer.add_scalar('Training Loss', train_loss, epoch)writer.add_scalar('Training Accuracy', train_accuracy, epoch)# 记录模型参数的直方图for name, param in model.named_parameters():writer.add_histogram(name, param, epoch)# 记录网络结构(通常只需要记录一次)if epoch == 0:writer.add_graph(model, images.to(device))# 记录输入图片img_grid = torchvision.utils.make_grid(images)writer.add_image('train_images', img_grid, epoch)# 使用matplotlib记录渲染的图片fig, ax = plt.subplots()ax.plot(np.arange(len(labels)), labels.cpu().numpy(), 'b', label='True')ax.plot(np.arange(len(predicted)), predicted.cpu().numpy(), 'r', label='Predicted')ax.legend()writer.add_figure('predictions vs. actuals', fig, epoch)# 验证模型model.eval()val_loss = 0.0correct = 0total = 0all_preds = []all_labels = []with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())total += labels.size(0)correct += (predicted == labels).sum().item()val_loss /= len(test_loader)val_accuracy = 100 * correct / totalif val_accuracy > best_val_accuracy:# 当新的最佳验证准确率出现时,保存模型状态字典best_val_accuracy = val_accuracybest_model_state_dict = model.state_dict()# 记录验证损失和准确率writer.add_scalar('Validation Loss', val_loss, epoch)writer.add_scalar('Validation Accuracy', val_accuracy, epoch)# 记录多条曲线writer.add_scalars('Loss', {'train': train_loss, 'val': val_loss}, epoch)writer.add_scalars('Accuracy', {'train': train_accuracy, 'val': val_accuracy}, epoch)# 打印每个epoch的训练和验证结果print(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, 'f'Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_accuracy:.2f}%, 'f'Time: {time.time() - start_time:.2f}s')
以上代码分别记录了

如何提取保存的数据调用TensorBoard面板
在终端输入以下代码
tensorboard --logdir='修改为自己的log_dir路径'
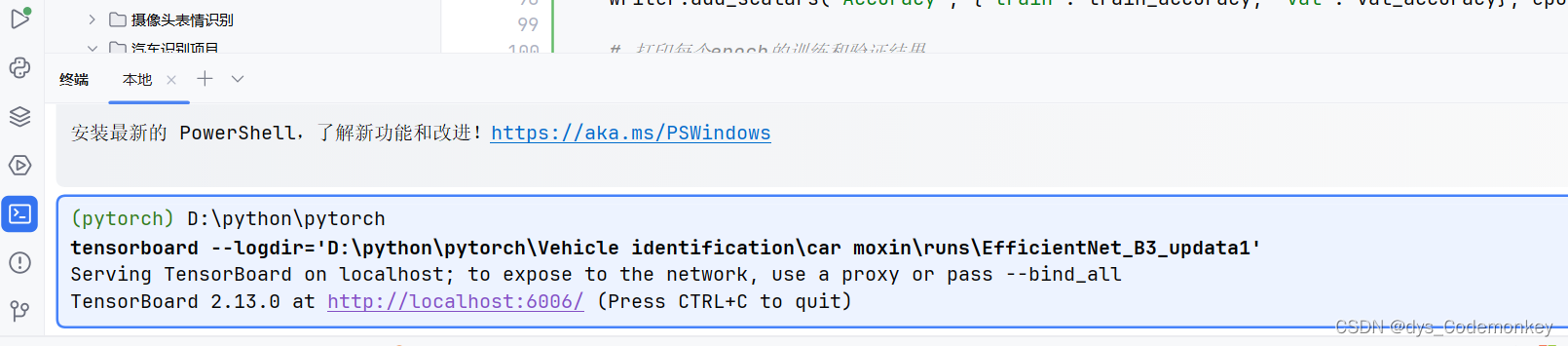
然后点击 http://localhost:6006/就可以成功加载面板了
可能会遇到的问题
如果数据读取失败那么请检查数据路径是否正确
注意数据文件中不能有任何中文
相关文章:
TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard 模块导入日志记录文件的创建训练中如何写入数据如何提取保存的数据调用TensorBoard面板可能会遇到的问题 模块导入 首先从torch中导入tensorboard的SummaryWriter日志记录模块 from torch.utils.tensorboard import SummaryWriter然后导入要用到的os库࿰…...

【Vue】普通组件的注册使用-全局注册
文章目录 一、使用步骤二、练习 一、使用步骤 步骤 创建.vue组件(三个组成部分)main.js中进行全局注册 使用方式 当成HTML标签直接使用 <组件名></组件名> 注意 组件名规范 —> 大驼峰命名法, 如 HmHeader 技巧…...
爬虫之反爬思路与解决手段
阅读时间建议:4分钟 本篇概念比较多,嗯。。 0x01 反爬思路与解决手段 1、服务器反爬虫的原因 因为爬虫的访问次数高,浪费资源,公司资源被批量抓走,丧失竞争力,同时也是法律的灰色地带。 2、服务器反什么…...
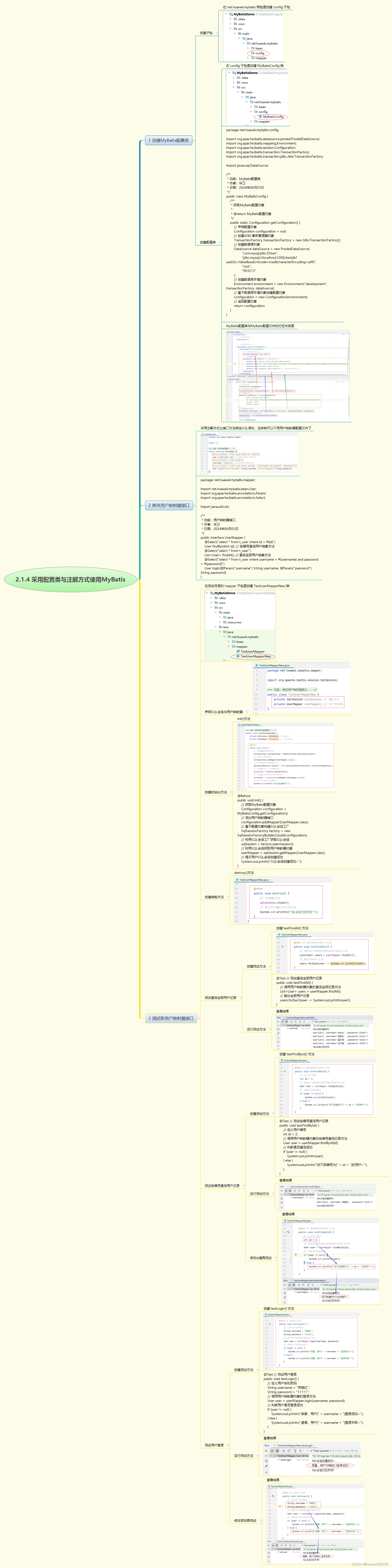
2.1.4 采用配置类与注解方式使用MyBatis
实战概述:采用配置类与注解方式使用MyBatis 创建MyBatis配置类 在net.huawei.mybatis.config包中创建MyBatisConfig类,用于配置MyBatis核心组件,包括数据源、事务工厂和环境设置。 配置数据源和事务 使用PooledDataSource配置MySQL数据库连接…...
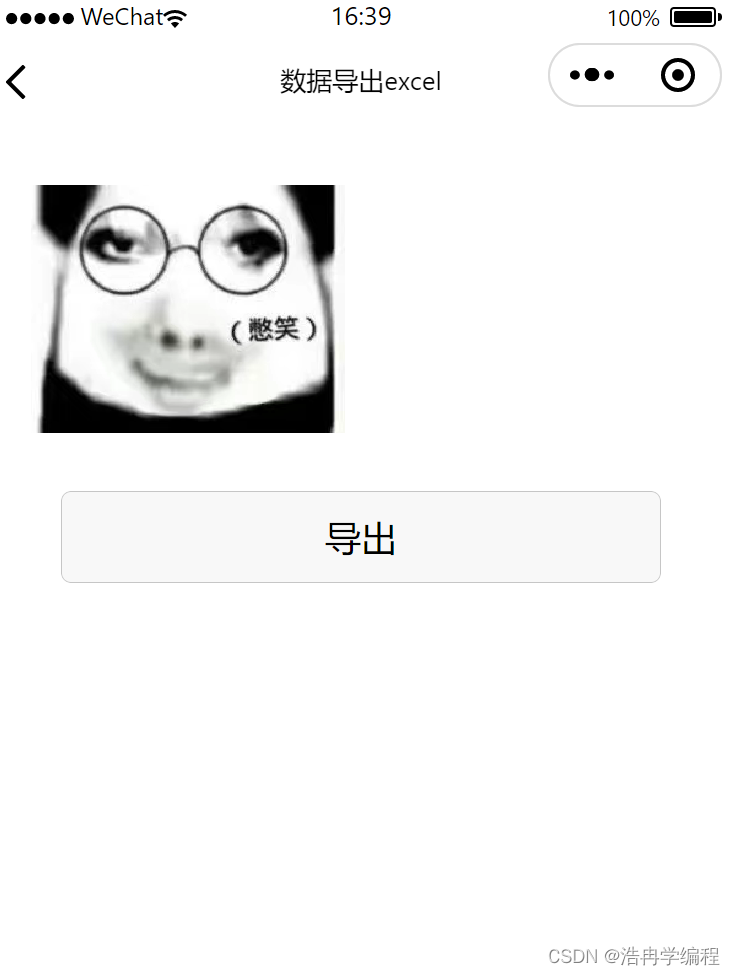
微信小程序云开发实现利用云函数将数据库表的数据导出到excel中
实现目标 将所有订单信息导出到excel表格中 思路 1、在页面中bindtap绑定一个导出点击事件daochu() 2、先获取所有订单信息,并将数据添加到List数组中 3、传入以List数组作为参数,调用get_excel云函数 4、get_excel云函数利用node-xlsx第三方库&#…...

python 字符串(str)、列表(list)、元组(tuple)、字典(dict)
学习目标: 1:能够知道如何定义一个字符串; [重点] 使用双引号引起来: 变量名 "xxxx" 2:能够知道切片的语法格式; [重点] [起始: 结束] 3:掌握如何定义一个列表; [重点] 使用[ ]引起来: 变量名 [xx,xx,...] 4:能够说出4个列表相关的方法; [了解] ap…...

【源码】SpringBoot事务注册原理
前言 对于数据库的操作,可能存在脏读、不可重复读、幻读等问题,从而引入了事务的概念。 事务 1.1 事务的定义 事务是指在数据库管理系统中,一系列紧密相关的操作序列,这些操作作为一个单一的工作单元执行。事务的特点是要么全…...

技巧:合并ZIP分卷压缩包
如果ZIP压缩文件文件体积过大,大家可能会选择“分卷压缩”来压缩ZIP文件,那么,如何合并zip分卷压缩包呢?今天我们分享两个ZIP分卷压缩包合并的方法给大家。 方法一: 我们可以将分卷压缩包,通过解压的方式…...
数据挖掘 | 实验三 决策树分类算法
文章目录 一、目的与要求二、实验设备与环境、数据三、实验内容四、实验小结 一、目的与要求 1)熟悉决策树的原理; 2)熟练使用sklearn库中相关决策树分类算法、预测方法; 3)熟悉pydotplus、 GraphViz等库中决策树模型…...

Python机器学习预测区间估计工具库之mapie使用详解
概要 在数据科学和机器学习领域,预测的不确定性估计是一个非常重要的课题。Python的mapie库是一种专注于预测区间估计的工具,旨在提供简单易用的接口来计算和评估预测的不确定性。通过mapie库,用户可以为各种回归和分类模型计算预测区间,从而更好地理解模型预测的可靠性。…...

Linux基础指令磁盘管理002
LVM(Logical Volume Manager)是Linux系统中一种灵活的磁盘管理和存储解决方案,它允许用户在物理卷(Physical Volumes, PV)上创建卷组(Volume Groups, VG),然后在卷组上创建逻辑卷&am…...

Python怎么添加库:深入解析与操作指南
Python怎么添加库:深入解析与操作指南 在Python编程中,库(Library)扮演着至关重要的角色。它们为我们提供了大量的函数、类和模块,使得我们可以更高效地编写代码,实现各种功能。那么,Python如何…...

Python | 虚拟环境的增删改查
mkvirtualenv创建虚拟环境 mkvirtualenv是用于在Pyhon中创建虚拟环境的命令。它通过使用vitualenv库来创建一个隔离的Python环境,以便您可以安装特定版本的Python包,而不会影响全局Python环境。 使用方法: 安装virtualenv:pip install vir…...

【MySQL数据库】:MySQL内外连接
目录 内外连接和多表查询的区别 内连接 外连接 左外连接 右外连接 简单案例 内外连接和多表查询的区别 在 MySQL 中,内连接是多表查询的一种方式,但多表查询包含的范围更广泛。外连接也是多表查询的一种具体形式,而多表查询是一个更…...

C# FTP/SFTP 详解及连接 FTP/SFTP 方式示例汇总
文章目录 1、FTP/SFTP基础知识FTPSFTP 2、FTP连接示例3、SFTP连接示例4、总结 在软件开发中,文件传输是一个常见的需求。尤其是在不同的服务器之间传输文件时,FTP(文件传输协议)和SFTP(安全文件传输协议)成…...

二、【源码】实现映射器的注册和使用
源码地址:https://github.com/mybatis/mybatis-3/ 仓库地址:https://gitcode.net/qq_42665745/mybatis/-/tree/02-auto-registry-proxy 实现映射器的注册和使用 这一节的目的主要是实现自动注册映射器工厂 流程: 1.创建MapperRegistry注册…...
Android Compose 十:常用组件列表 监听
1 去掉超出滑动区域时的拖拽的阴影 即 overScrollMode 代码如下 CompositionLocalProvider(LocalOverscrollConfiguration provides null) {LazyColumn() {items(list, key {list.indexOf(it)}){Row(Modifier.animateItemPlacement(tween(durationMillis 250))) {Text(text…...
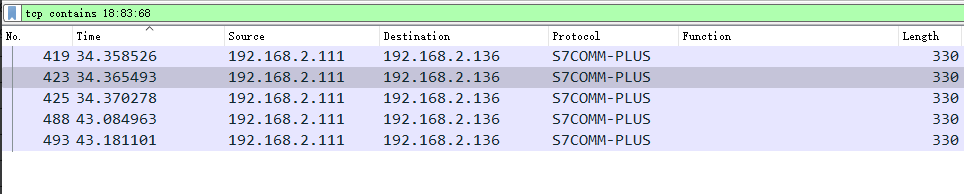
Wireshark 如何查找包含特定数据的数据帧
1、查找包含特定 string 的数据帧 使用如下指令: 双引号中所要查找的字符串 frame contains "xxx" 查找字符串 “heartbeat” 示例: 2、查找包含特定16进制的数据帧 使用如下指令: TCP:在TCP流中查找 tcp contai…...
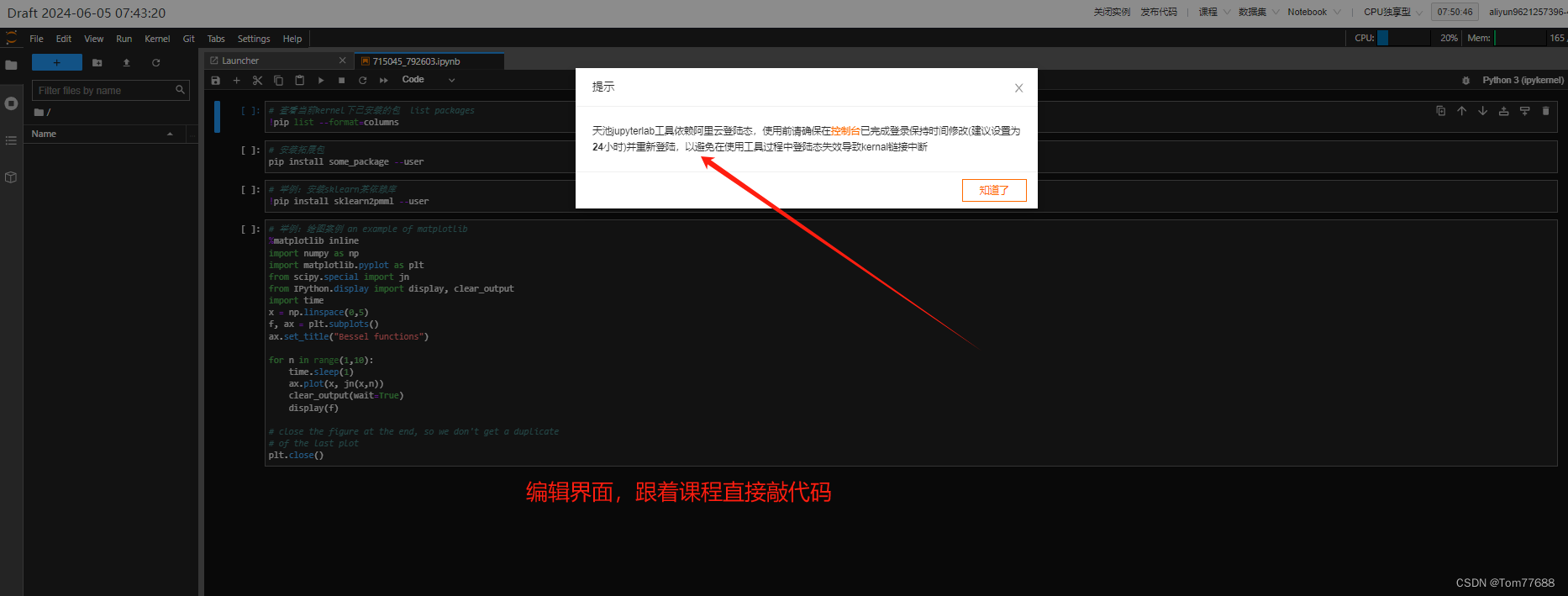
【深度学习入门篇一】阿里云服务器(不需要配环境直接上手跟学代码)
前言 博主刚刚开始学深度学习,配环境配的心力交瘁,一塌糊涂,不想配环境的刚入门的同伴们可以直接选择阿里云服务器 阿里云天池实验室,在入门阶段跑个小项目完全没有问题,不要自己傻傻的在那配环境配了半天还不匹配&a…...

app,waf笔记
API攻防 知识点: 1、HTTP接口类-测评 2、RPC类接口-测评 3、Web Service类-测评 内容点: SOAP(Simple Object Access Protocol)简单对象访问协议是交换数据的一种协议规范,是一种轻量级的、简单的、基于XML&#…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...
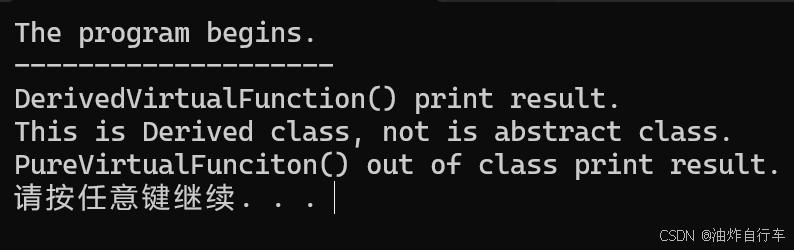
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...