Stable Diffusion——四种模型 LoRA(包括LyCORIS)、Embeddings、Dreambooth、Hypernetwork
目前 Stable diffusion 中用到主要有四种模型,分别是 Textual Inversion (TI)以 Embeddings 为训练结果的模型、Hypernetwork 超网络模型、LoRA(包括 LoRA 的变体 LyCORIS)模型、Dreambooth 模型。
视频博主 koiboi 用图 形拓扑图来讲解了这四种 SD 模型的异同,并配有全程的视频讲解:koiboi 对四大SD模型的视频讲解。

看完这个视频,非专业技术人员也可以对 SD 的四种微调模型的原理有所了解。虽然这并不算什么深入详细解剖的论文级别的讲解,但足够形象生动易懂。如果你还想更深入更地了解四种模型的细节可以详细阅览每一种模型的详细介绍,分别在下面四篇文章链接中:
- Textual Inversion (Embeddings)网络与模型请查看此篇:7号床:Stable Diffusion 模型——Textual Inversion(TI)文本翻转和 Embedding 嵌入
- Hypernetwork 超网络与模型请查看此篇:7号床:Stable Diffusion 模型——Hypernetwork 超网络
- LoRA 与 LyCORIS 网络与模型请查看此篇:7号床:Stable Diffusion 模型——LoRA 模型
- Dreambooth 网络与模型请查看此篇:7号床:Stable Diffusion 模型——Dreambooth 模型
注:关于这四种模型的详细训练方法和参数等细节可以在各文章中查看对应的链接。
有关Stable Diffusion的详细讲解,请查看此篇:Stable Diffusion 稳定扩散模型最详细解释
以下是对 koiboi 视频中四个模型的简要介绍:
1. Textual Inversion (TI)(Embeddings)
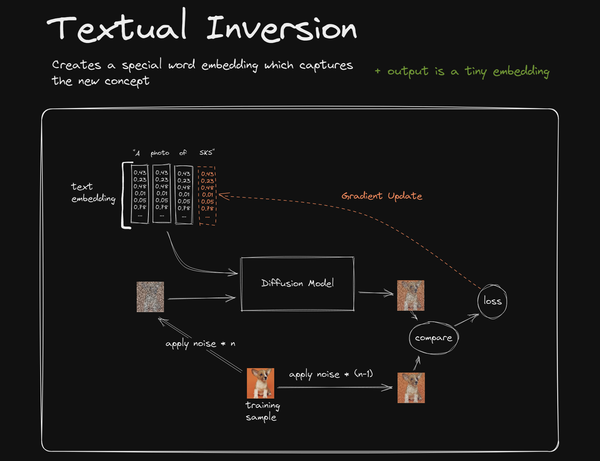
图1
首先看这样一个提示词:“A photo of SKS.”。
作者希望在给 SD 输入这样的提示词时,运用训练的模型可以产生一只特殊的柯基犬的形象,这只柯基犬名叫“SKS”。
所以,他首先需要训练这个柯基犬形象的模型,于是他给这个模型起一个特殊的名字: “SKS”。“SKS” 既是这个模型的名称,也是这个模型在作图过程中的关键词(或称触发词 trigger word )。
(注:起“SKS”这样奇特的名字是有意义的,这是为了和其他通用词汇的名字区分开来,以免发生”语言漂移“(Language Drift),即模型在生图过程中分不清你的意图到底是要生成这个特殊的柯基犬造型还是要生成一只半自动步枪。可是,”SKS“为半自动步枪的意思,不知道他为啥要起这个名字,或许这就是他家柯基犬的真实名字吧。所以,其实选择”SKS“这个名称并不明智,虽然它看起来很生僻,但是仍然没有避开”半自动步枪”的意思。要找到独特的名称其实不难,比如“Skkkk”。所以当你起这个特殊名字之前最好在搜索引擎中查查看。)
训练过程:
训练过程按照 koiboi 提供的拓扑图1 中的描述是这样的。
- 首先用这只柯基犬的照片(若干张)作为训练图像(图1 中 training sample )生成含有某个强度级别噪点含量的噪点图(图1 中 apply noise * n );
- 同时生成含有某个强度低一级的噪点含量的噪点图(图1 中 apply noise * (n-1) );
- 然后把步骤 1 中的含有 n 级别噪点的噪点图和关键词“SKS”一同输入给 Diffusion Model ,让 Diffusion Model 进行去噪点操作,得到一个从 n 级别去除一定噪点到 n-1 级别的相对少一些噪点的图像(图1 中 Diffusion Model 模块右侧的柯基犬图)
- 然后把步骤 3 生成的 n-1 级别图像和步骤 2 生成的 n-1 级别图进行比较生成一个 loss (损失,即差异化描述)。(注:起初由于 text embedding 模块并不清楚 SKS 具体指的是这种特殊的柯基犬,所以会随机生成各种输出的结果,即某种随机的向量。这样的向量作为输入给 Diffusion Model 模块,自然导致 Diffusion Model 模块输出的 n-1 噪点级别的图像与步骤 2 中产生的 n-1 噪点级别的图像极为不像。但这便是训练开始的第一步,之后系统会逐渐自动调整参数,以使得这两个图像越来越相近,这便是所有模型训练的基本逻辑。)
- 系统自动调整参数的过程是这样的:系统把这个 loss 通过 Gradient Update 的方式反馈给 text embedding 模块,以期该模块能够根据这个差异 loss 校正针对“SKS”的输出。这样当校正后的“SKS”的输出再次输入给中间的 Diffusion Model 模块后,能够使得 Diffusion Model 输出 n-1 图像能够和步骤 2 中生成的 n-1 图像更接近。
- 以上过程反复多次后,text embedding 模块会逐渐地学会如何正确地解析“SKS”这个特殊词汇,以便在 text embedding 模块在输出“SKS”所代表的向量输入给 Diffusion Model 模块后,Diffusion Model 模块可以生成一个与步骤 2 提供的 n-1 图像极为相似的图像。至此,text embedding 的训练过程就结束了。
这样的训练过程便称为 Textual Inversion(如果直译的话为“文本翻转”,缩写为TI。一般以 embeddings ,即 TI 的训练结果为这种模型的称呼。)。
训练后产生一个 embeddings 模型文件。在实际生图阶段,需要加载这个 embeddings 模型文件,该文件会对 SD 系统中 text embedding 模块产生一个类似插件的影响(图1 中 text embedding 模块的橙色部分)。当输入给 SD 系统提示词:“A photo of SKS.” 后, text embedding 模块便解析出了特殊的 “SKS”向量给 Diffusion Model 模块,从而生成出我们想要的特殊的柯基犬图像。
2. Hypernetwork
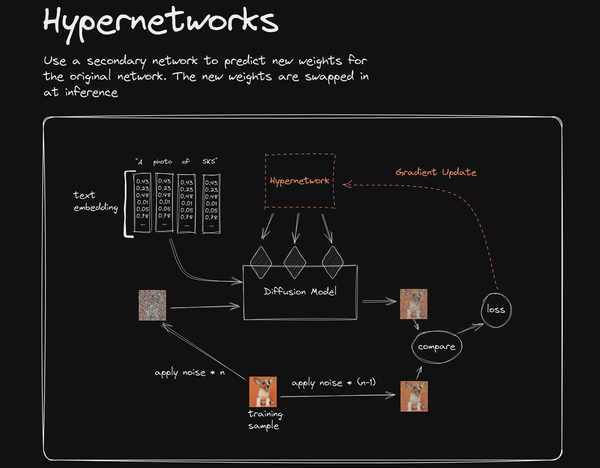
图2
Hypernetwork 的总体训练思路同 Textual Inversion 是接近的,只是此时 loss 通过 Gradient Update 反馈的目标发生了变化,从 text embedding 模块转变成了一个单独的附加的小神经网络 Hypernetwork,这个小的神经网络一般译为“超网络”(图2 中橙色虚线方框即为这个小神经网络)。
这个 Hypernetwork 超网络劫持了 Diffusion Model 模块中的三个矩阵(图2 中三个菱形块,具体来说是 U-Net 噪声预测器中的交叉注意层之前的 Q、K、V 三矩阵中的 K 和 V 矩阵),并修改了数据,使得 Diffusion Model 模块生图时发生变化。
(注:有关注意力层的 Q、K、V 三矩阵是一个十分有意思的知识点,这个知识点也是目前最火爆的 GPT 的核心 Transformer 大模型的灵魂所在。所以感兴趣的可以去单独了解,推荐此篇:Q、K、V 与 Multi-Head Attention 多头注意力机制。)
Hypernetwork 模型训练结束后,会生成一个 Hypernetwork 模型(图2 中橙色虚线方框)。在实际生图阶段,需要加载这个 Hypernetwork 模型,并在提示词中用专门的提示词公式来表达这一模型要发挥作用,于是该模型就会对 SD 系统中 Diffusion Model 模块在生图时产生一个劫持并修改数据的效应,这样的劫持修改使得 Diffusion Model 模块生图时发生变化,从而能够让 SD 生成出我们想要的特殊的柯基犬图像。
3. LoRA
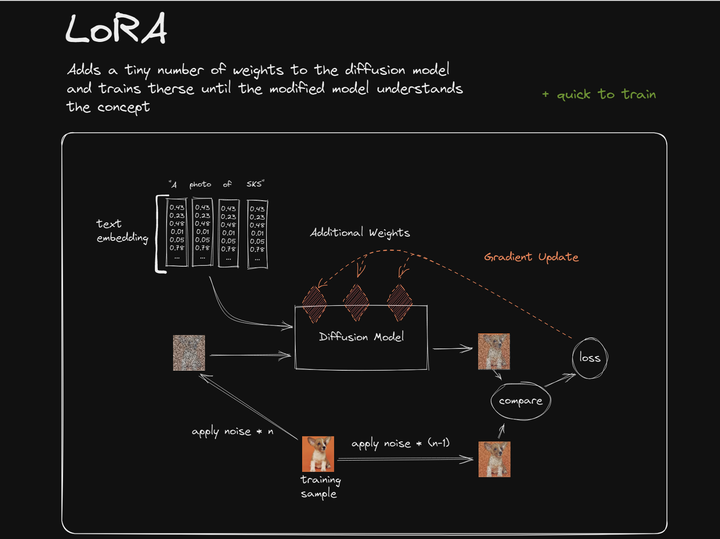
图3
LoRA 的总体训练思路同 Textual Inversion 和 Hypernetwork 都是接近的(其实这一训练框架与生图框架本身就是 SD 的核心架构,各种模型训练只是在利用这一架构中各个可以微调的环节来进行某些类似插件效应的改变而已。),只是此时 loss 通过 Gradient Update 反馈的目标落在了 Diffusion Model 模块中 Q、K、V 三个矩阵本身的身上。
与 Hypernetwork 劫持并修改 Q、K、V 三矩阵输入数据的方式不同,LoRA 是直接生成属于自己风格的 Q、K、V 三矩阵作为模型(图3 中三个橙色菱形),作为对原有模型中 Q、K、V 的叠加,也可以理解为原有 Diffusion Model 模块中 Q、K、V 三矩阵的额外“插件”。
这三个橙色菱形“插件”所组成的模型文件,便是 LoRA 的模型文件了。在实际生图过程中,需要加载这个 LoRA 模型文件,并用专门的提示词公式来表达这一模型要发挥作用。于是便能影响 SD 模型的整体输出,生成我们想要的独特柯基犬图像了。
LyCROIS,英文全称 LoRA beyond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. ,可以翻译为:用另一种超越常规的 Rankadaptation “秩自适应”的方法来实现 SD 稳定扩散。可以说 LyCORIS 是 LoRA 的思路的进一步扩展,是升级换代的 LoRA,通常比 LoRA 更有表现力,可以捕捉更多的训练图像的细节。LyCORIS 属于一系列类 LoRA 方法的总称,目前至少分为以下几种:Standard、LyCROIS/LoKr、LyCROIS/LoHa、LyCROIS/LoCon、LyCROIS/iA3、LyCROIS/DyLoRA、LoRA-FA。
4. Dreambooth
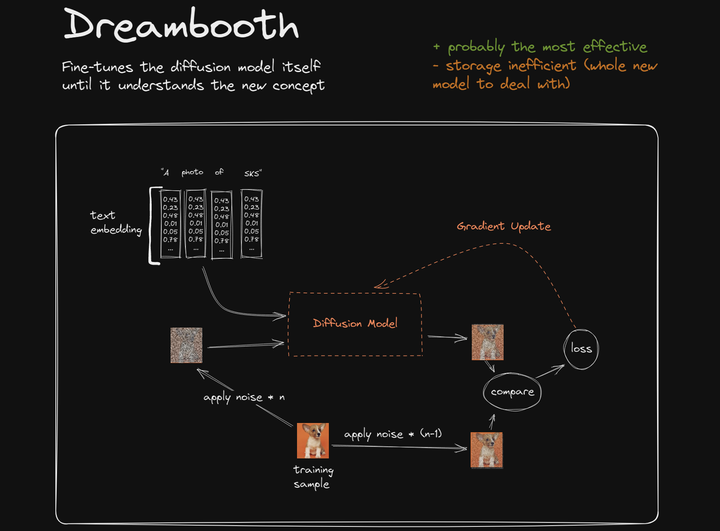
图4
同样,Dreambooth 的总体训练思路接近以上三个模型的总体架构,只是 loss 通过 Gradient Update 反馈的目标直接落在了 Diffusion Model 模块本身。要知道 Diffusion Model 模块是 SD 的最核心部分,也是最主体部分。 loss 通过 Gradient Update 直接作用在这里,则导致 Diffusion Model 模块中数以亿计的参数发生微调以适应新的特征(独特柯基犬特征)。很明显这样的训练方式将耗费大量的算力资源,生成出的模型相当于 Diffusion Model 基础模型的变种文件,即为 Dreambooth 模型文件,文件体积也很大,通常在 2G 到 5G 左右。但也由于直接在基础模型上微调,所以导致 Dreambooth 模型在 SD 生图过程中的输出效果很细腻很高效。
在实际生图过程中,需要加载这个 Dreambooth 模型文件,无需要额外在提示词中描述这个模型文件的特殊提示词,系统会按照基础大模型文件同样的待遇来进行生图。
总结
最后,为了方便区分四种训模型以及 SD 基础大模型之间的不同属性,我特地做了下面的表格:
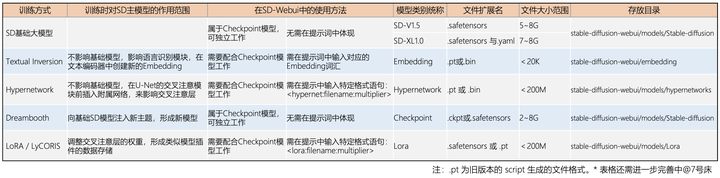
SD基础大模型与微调模型(原创图标,转载请注明出处,谢谢)
其中最主流的模型训练方式为 Dreambooth 和 LoRA(以及 LoRA 的变体 LyCORIS)。就训练时间与实用度而言,平均打分为 Dreambooth > LoRA > HyperNetwork > Embedding。Checkpoint 模型、Embeddings 模型、LoRA 模型较受欢迎,Hypernetworks 模型则有被淘汰的趋势。
这里还有模型训练方面其他一些需要考量的因素:
- 如果你有成千上万张图片的训练集,并且希望得到更精确的模型微调,而且你并不拘泥于某一种具体的人物风格、画风等等,Dreambooth 仍然是最好的选择。
- 在四类模型中,Dreambooth 是对模型本身变动最大的。它可以被理解为基础模型和 LoRA 模型的合体,它改变了基础模型的部分权重,并将新的内容权重添加其中,同时又保留了基础模型中的那些未被变动过的部分,所以最终导致它的模型文件体积比较大。
- 可以用几个 LoRA 一同使用,这样就可以不局限于某一个 LoRA 只关注某一个具体的风格和角色了。
- Hypernetworks 和 LoRA 基本上都是来源于同一篇研究论文。但 Hypernetworks 超网络基本上算是过时的老旧 Alpha 测试版本,而 LoRA 算是成型的如今最流行的版本。相对于 Dreambooth 来说,Hypernetworks 和 LoRA 都很小,并且它们只是在原有模型基础上进行了某种插件式的变动,以达到效果,所以它们都无法单独使用。
- Base Model 基础的大模型也可以称作 Full Models ,因为这个模型中包含了 SD 种的所有参数,所以称为“Full”。比如 SDXL 基础大模型,文件名: sd_xl_base_1.0.safetensors 。这种是从 0 开始学习起来的,不需要依赖任何其他模型而完全从海量的训练集中耗费了大量的算力资源与时间训练出来的大模型。这种模型很明显不是普通人或普通机构可以支撑起来的。通常数据集都是以亿为单位,一次训练费用动辄百万美金起步,但它是模型金字塔的底层基座。
- 在模型训练过程中,如果您将“混合精度”和“保存精度”设置错误,则可能会遇到“ValueError: bf16 mixed precision requires PyTorch >= 1.10 and a supported device”报错。此设置与软件中的浮点格式数值有关。如果您遇到这个错误,这很可能意味着在没有能够支持的 GPU 的情况下错误地设置了 bf16 浮点格式,。如果是这种情况,将“混合精度”和“保存精度”都设置为 fp16,然后再次启动训练过程。详细训练内容和方法参数等请参考本文中所列的四种模型各自的介绍。
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!


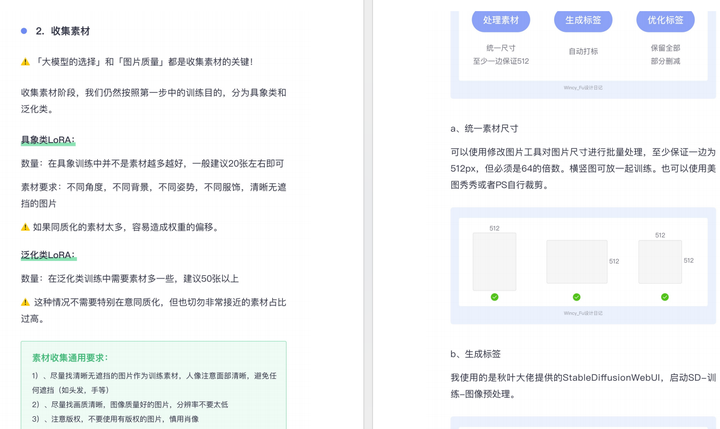
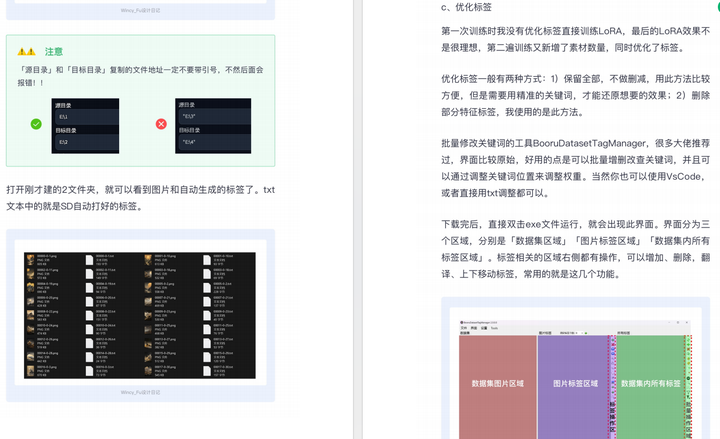
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

相关文章:
Stable Diffusion——四种模型 LoRA(包括LyCORIS)、Embeddings、Dreambooth、Hypernetwork
目前 Stable diffusion 中用到主要有四种模型,分别是 Textual Inversion (TI)以 Embeddings 为训练结果的模型、Hypernetwork 超网络模型、LoRA(包括 LoRA 的变体 LyCORIS)模型、Dreambooth 模型。 视频博主 koiboi 用…...
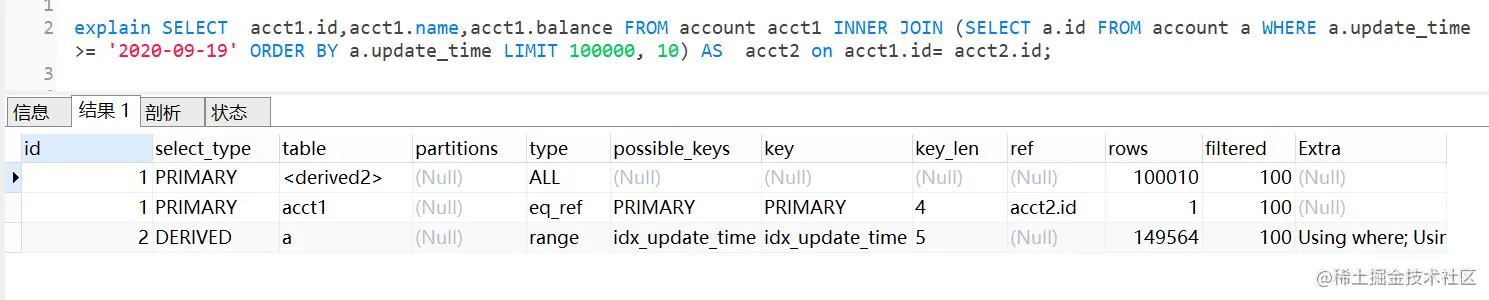
MySQL深分页,limit 100000,10 优化
文章目录 一、limit深分页为什么会变慢二、优化方案2.1 通过子查询优化(覆盖索引)回顾B树结构覆盖索引把条件转移到主键索引树 2.2 INNER JOIN 延迟关联2.3 标签记录法(要求id是有序的)2.4 使用between...and... 我们日常做分页需…...

Linux[高级管理]——使用源码包编译安装Apache网站
🏡作者主页:点击! 👨💻Linux高级管理专栏:点击! ⏰️创作时间:2024年5月31日14点20分 🀄️文章质量:96分 在Linux系统上编译和安装Apache HTTP Server是…...

Docker+JMeter+InfluxDB+Grafana 搭建性 能监控平台
JMeter原生报告的缺点: 无法实时共享 报告信息的展示不美观 需求方案 为了解决上述问题,可以通过 InfluxDB Grafana解决 : InfluxDB :是一个开源分布式指标数据库,使用 Go 语言编写,无需外部依赖 应用&am…...
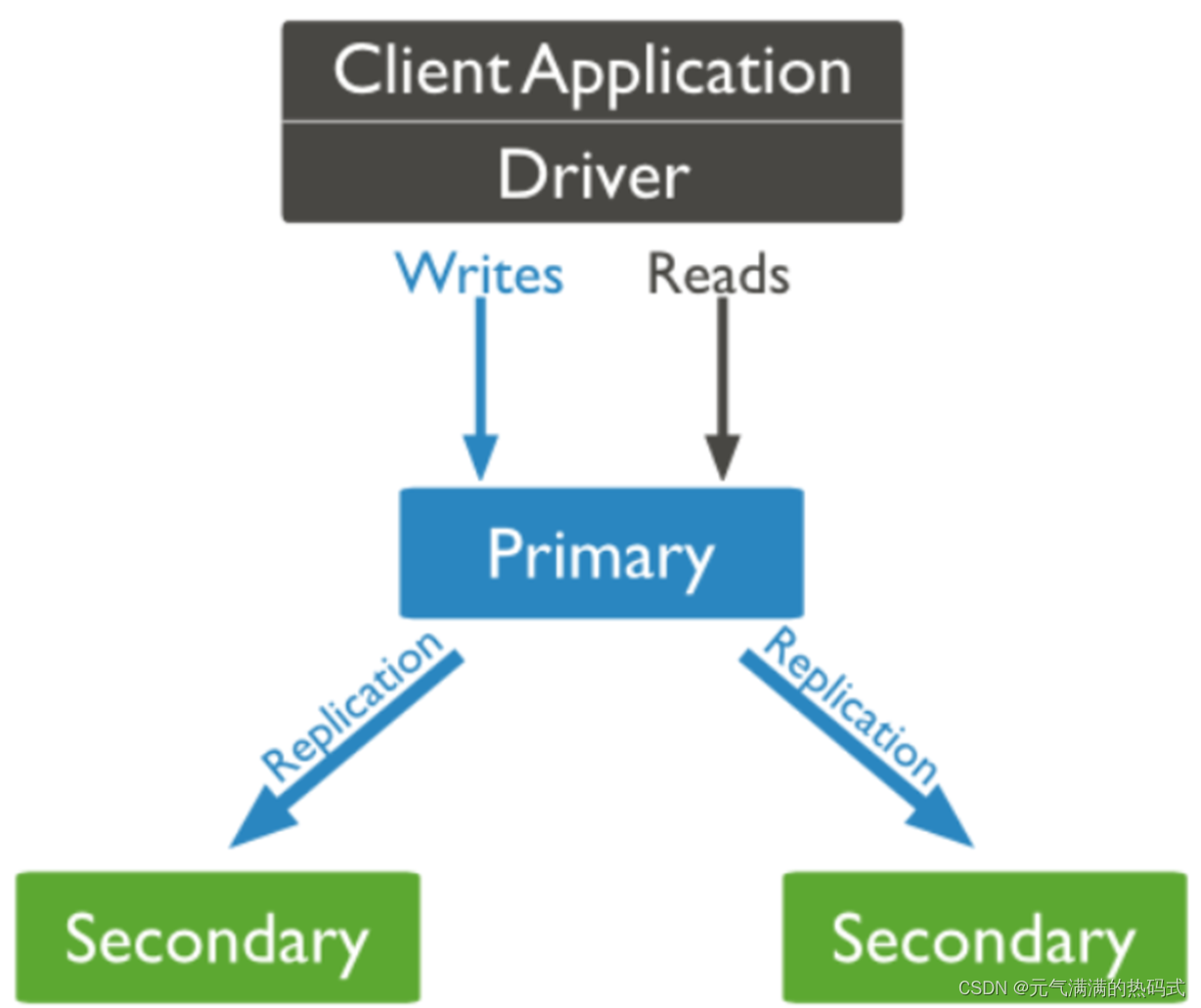
NoSQL实战(MongoDB搭建主从复制)
什么是复制集? MongoDB复制是将数据同步到多个服务器的过程; 复制集提供了数据的冗余备份并提高了数据的可用性,通常可以保证数据的安全性; 复制集还允许您从硬件故障和服务中断中恢复数据。 保障数据的安全性 数据高可用性 (2…...

【讯为Linux驱动开发】3.内核空间和用户空间
【问】内存空间的组成部分?? 内存空间分为内核空间和用户空间 1.内核空间控制硬件资源,提供系统调用接口,保护系统自身安全稳定 2.用户空间实现业务逻辑 【问】如何进入内核空间使用硬件资源? 1.系统调用 2.软中断 3.…...
AI论文:一键生成论文的高效工具
说到这个问题,那真的得看你对“靠谱”的定义是怎样的啦? 众所周知,写论文是一项极其耗时间的事情,从开始的选题到文献资料搜索查阅,大纲整理等等一大堆的繁杂工作是极艰辛的。用AI写论文就不一样了,自动化…...
申请医疗设备注册变更时,需要补充考虑网络安全的情况有哪些?
在申请医疗器械设备注册变更时,需要补充网络安全的情况主要包括以下几点: 网络安全功能更新:如果医疗器械的自研软件发生网络安全功能更新,或者合并网络安全补丁更新的情形,需要单独提交一份自研软件网络安全功能更新…...
)
打对钩的方式做人机验证(vue+javascript)
要实现一个通过打对钩方式的人机验证,并且让它不容易被破解,可以考虑以下几点: 动态生成选项和题目:每次生成的验证选项和题目都不一样,防止简单的脚本通过固定的答案绕过验证。使用图像和文字混合验证:增…...

可视化脚本用于使用MMDetection库进行图像的目标检测
# Copyright (c) OpenMMLab. All rights reserved. import asyncio from argparse import ArgumentParserfrom mmdet.apis import (async_inference_detector, inference_detector,init_detector, show_result_pyplot) import denseclip# 解析命令行参数 def parse_args():pars…...
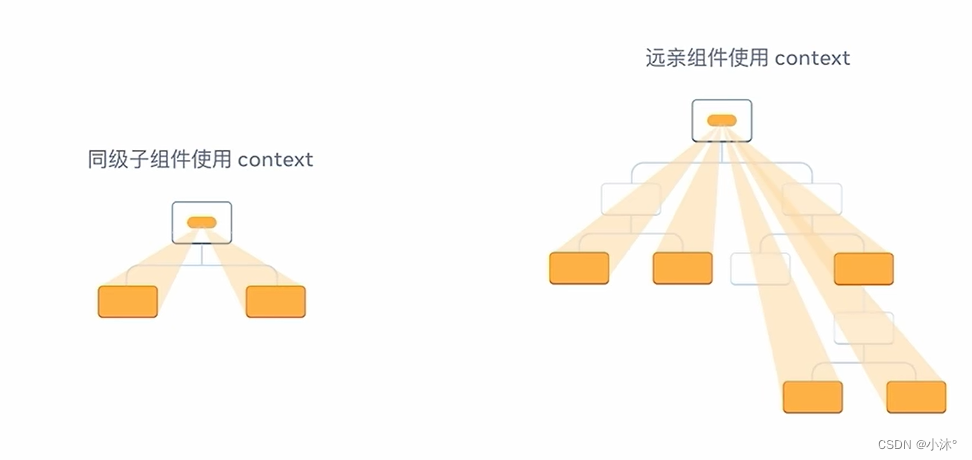
React-组件通信
组件通信 概念:组件通信就是组件之间的数据传递,根据组件嵌套关系的不同,有不同的通信方法 父传子 基础实现 实现步骤: 1.父组件传递数据-在子组件标签上绑定属性 2.子组件接收数据-子组件通过props参数接收数据 props说明 1.…...
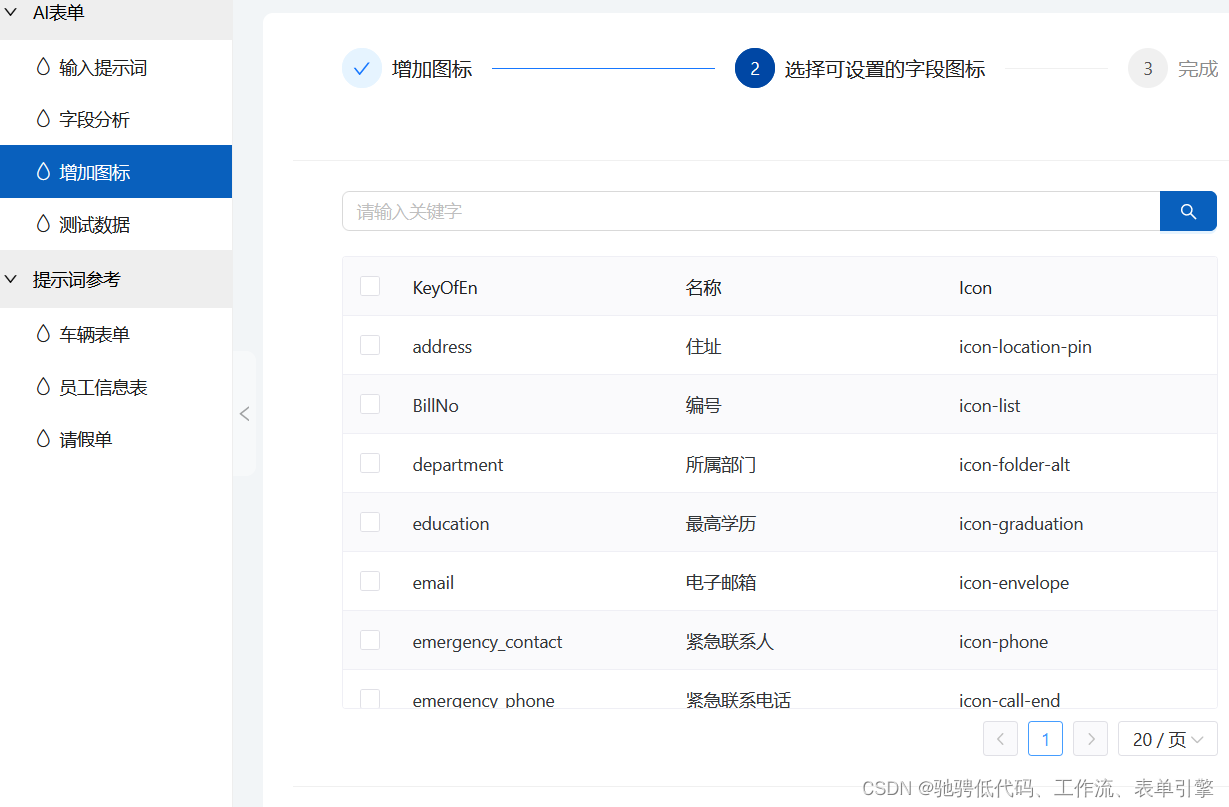
低代码选型要注意什么问题?
低代码选型时,确实需要从多个角度综合考虑,以下是根据您给出的角度进行的分析和建议: 公司的人才资源: 评估团队中是否有具备编程能力的开发人员,以确保能够充分利用低代码平台的高级功能和进行必要的定制开发。考察实…...
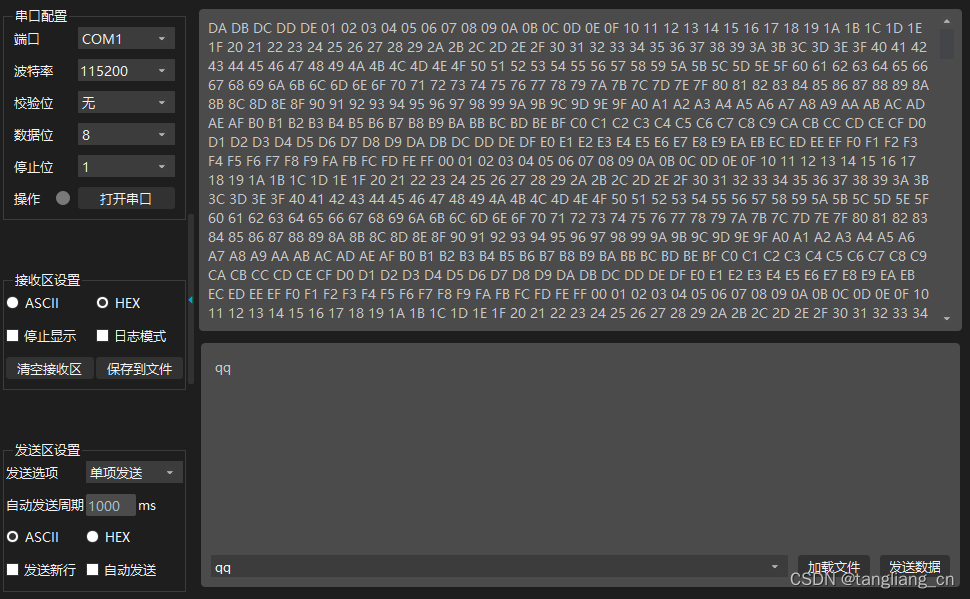
fpga入门 串口定时1秒发送1字节
一、 程序说明 FPGA通过串口定时发送数据,每秒发送1字节,数据不断自增 参考小梅哥教程 二、 uart_tx.v timescale 1ns / 1psmodule uart_tx(input wire sclk,input wire rst_n,output reg uart_tx);parameter …...

总结一下自己,最近三年,我做了哪些工作
简单总结下吧,我算是业务架构师,确实对得起这个名字,经常冲在一线,业务和架构相关的东西都有做,系统比较复杂,不过逐步了解谁都会熟悉的 下面简单列一列我这三年的工作情况吧,也算是给自己一个交…...

SpringCloud Gateway基础入门与使用实践总结
官网文档:点击查看官网文档 Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关。但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,那就是SpringCloud Gateway一句话…...
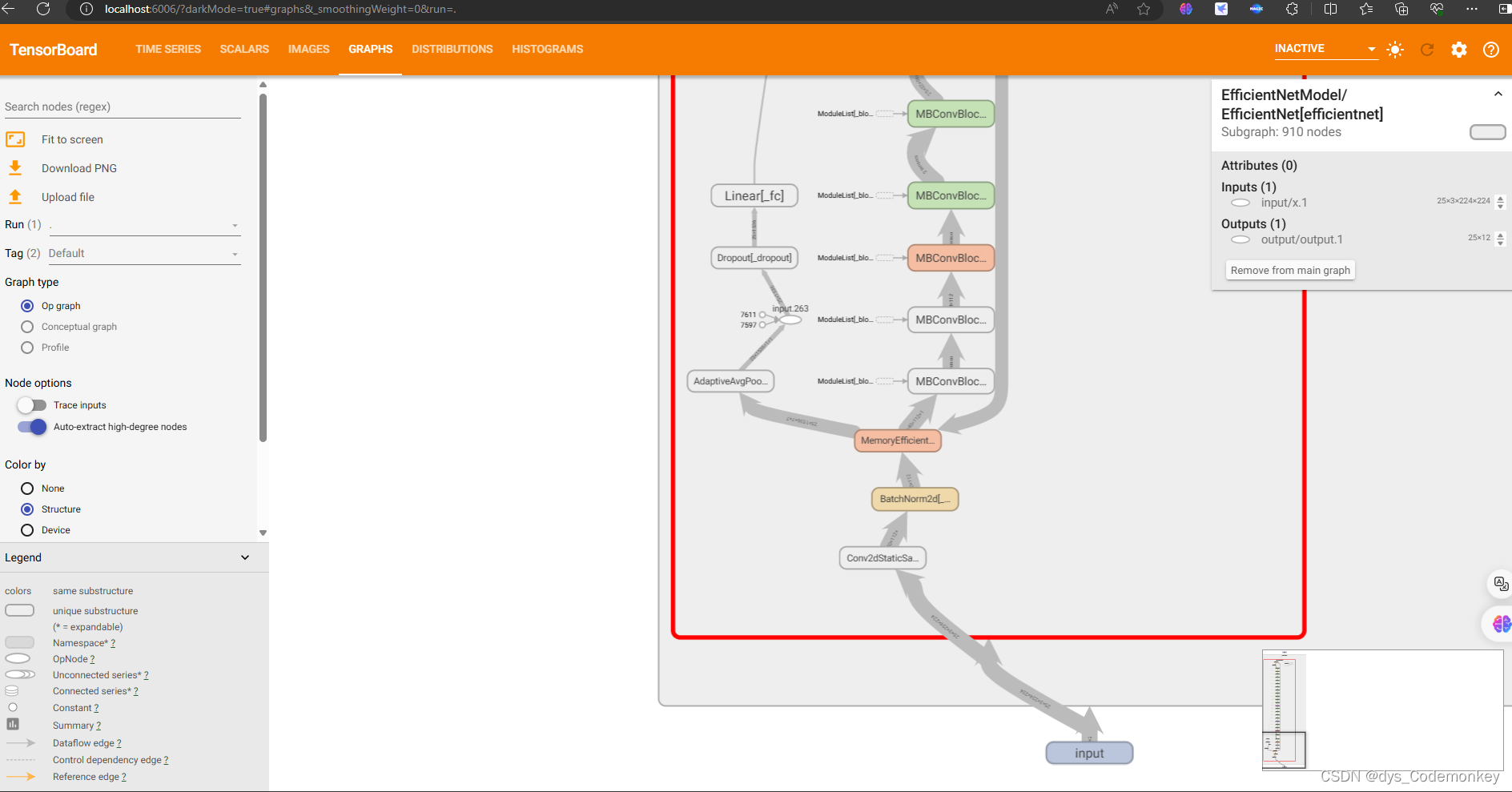
TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard 模块导入日志记录文件的创建训练中如何写入数据如何提取保存的数据调用TensorBoard面板可能会遇到的问题 模块导入 首先从torch中导入tensorboard的SummaryWriter日志记录模块 from torch.utils.tensorboard import SummaryWriter然后导入要用到的os库࿰…...

【Vue】普通组件的注册使用-全局注册
文章目录 一、使用步骤二、练习 一、使用步骤 步骤 创建.vue组件(三个组成部分)main.js中进行全局注册 使用方式 当成HTML标签直接使用 <组件名></组件名> 注意 组件名规范 —> 大驼峰命名法, 如 HmHeader 技巧…...
爬虫之反爬思路与解决手段
阅读时间建议:4分钟 本篇概念比较多,嗯。。 0x01 反爬思路与解决手段 1、服务器反爬虫的原因 因为爬虫的访问次数高,浪费资源,公司资源被批量抓走,丧失竞争力,同时也是法律的灰色地带。 2、服务器反什么…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...
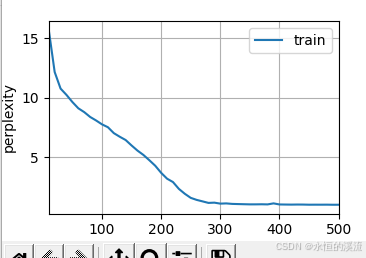
李沐--动手学深度学习--GRU
1.GRU从零开始实现 #9.1.2GRU从零开始实现 import torch from torch import nn from d2l import torch as d2l#首先读取 8.5节中使用的时间机器数据集 batch_size,num_steps 32,35 train_iter,vocab d2l.load_data_time_machine(batch_size,num_steps) #初始化模型参数 def …...