6、架构-服务端缓存
为系统引入缓存之前,第一件事情是确认系统是否真的需要缓 存。从开发角度来说,引入缓存会提 高系统复杂度,因为你要考虑缓存的失效、更新、一致性等问题;从运维角度来说,缓存会掩盖一些缺 陷,让问题在更久的时间以后,出现在距离发生现场更远的位置上; 从安全角度来说,缓存可能会泄漏某些保密数据,也是容易受到攻击 的薄弱点。冒着上述种种风险,仍能说服你引入缓存的理由,总结起 来无外乎以下两种。
- 为缓解CPU压力而引入缓存:譬如把方法运行结果存储起来、 把原本要实时计算的内容提前算好、对一些公用的数据进行复用,这 可以节省CPU算力,顺带提升响应性能。
- 为缓解I/O压力而引入缓存:譬如把原本对网络、磁盘等较慢 介质的读写访问变为对内存等较快介质的访问,将原本对单点部件 (如数据库)的读写访问变为对可扩缩部件(如缓存中间件)的访 问,顺带提升响应性能。
请注意,缓存虽然是典型以空间换时间来提升性能的手段,但它 的出发点是缓解CPU和I/O资源在峰值流量下的压力,“顺带”而非 “专门”地提升响应性能。这里的言外之意是如果可以通过增强CPU、 I/O本身的性能(譬如扩展服务器的数量)来满足需要的话,那升级硬 件往往是更好的解决方案,即使需要一些额外的投入成本,也通常要 优于引入缓存后可能带来的风险。
缓存属性
有不少软件系统最初的缓存功能是以HashMap或者 ConcurrentHashMap为起点演进的。当开发人员发现系统中某些资源的 构建成本比较高,而这些资源又有被重复使用的可能时,会很自然地 产生“循环再利用”的想法,将它们放到Map容器中,待下次需要时取 出重用,避免重新构建,这种原始朴素的复用就是最基本的缓存。不 过,一旦我们专门把“缓存”看作一项技术基础设施,一旦它有了通 用、高效、可统计、可管理等方面的需求,其中要考虑的因素就变得 复杂起来。通常,我们设计或者选择缓存至少会考虑以下四个维度的 属性。
- 吞吐量:缓存的吞吐量使用OPS值(每秒操作数,Operation per Second,ops/s)来衡量,反映了对缓存进行并发读、写操作的效率, 即缓存本身的工作效率高低。
- 命中率:缓存的命中率即成功从缓存中返回结果次数与总请求 次数的比值,反映了引入缓存的价值高低,命中率越低,引入缓存的 收益越小,价值越低。
- 扩展功能:即缓存除了基本读写功能外,还提供哪些额外的管 理功能,譬如最大容量、失效时间、失效事件、命中率统计,等等。
- 分布式缓存:缓存可分为“进程内缓存”和“分布式缓存”两 大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存 的数据不能在各服务节点中共享,后者则相反。
吞吐量
缓存的吞吐量只在并发场景中才有统计的意义,因为若不考虑并 发,即使是最原始的、以HashMap实现的缓存,访问效率也已经是常量 时间复杂度(即O(1)),其中涉及碰撞、扩容等场景的处理属于数据 结构基础,这里不再展开。但HashMap并不是线程安全的容器,如果要 让它在多线程并发下正确地工作,就要用 Collections.synchronizedMap进行包装,这相当于给Map接口的所有 访问方法都自动加全局锁;或者改用ConcurrentHashMap来实现,这相 当于给Map的访问分段加锁(从JDK 8起已取消分段加锁,改为 CAS+Synchronized锁单个元素)。无论采用怎样的实现方法,这些线 程安全措施都会带来一定的吞吐量损失。
命中率与淘汰策略
有限的物理存储决定了任何缓存的容量都不可能是无限的,所以 缓存需要在消耗空间与节约时间之间取得平衡,这要求缓存必须能够 自动或者人工淘汰掉缓存中的低价值数据。考虑到由人工管理的缓存 淘汰主要取决于开发者如何编码,不能一概而论,这里只讨论由缓存 自动进行淘汰的情况。笔者所说的“缓存如何自动地实现淘汰低价值 目标”,现在被称为缓存的淘汰策略。
在了解缓存如何实现自动淘汰低价值数据之前,首先要定义怎样 的数据才算是“低价值”。由于缓存的通用性,这个问题的答案必须 是与具体业务逻辑无关的,只能从缓存工作过程收集到的统计结果来 确定数据是否有价值,通用的统计结果包括但不限于数据何时进入缓 存、被使用过多少次、最近什么时候被使用,等等。一旦确定选择何 种统计数据,就决定了如何通用地、自动地判定缓存中每个数据的价 值高低,也相当于决定了缓存的淘汰策略是如何实现的。目前,最基 础的淘汰策略实现方案有以下三种。
- FIFO(First In First Out):优先淘汰最早进入被缓存的数据。 FIFO的实现十分简单,但一般来说它并不是优秀的淘汰策略,越是频 繁被用到的数据,往往会越早存入缓存之中。如果采用这种淘汰策 略,很可能会大幅降低缓存的命中率。
- LRU(Least Recent Used):优先淘汰最久未被访问过的数据。 LRU通常会采用HashMap加LinkedList的双重结构(如LinkedHashMap) 来实现,以HashMap来提供访问接口,保证常量时间复杂度的读取性 能,以LinkedList的链表元素顺序来表示数据的时间顺序,每次缓存命 中时把返回对象调整到LinkedList开头,每次缓存淘汰时从链表末端开 始清理数据。对大多数的缓存场景来说,LRU明显要比FIFO策略合 理,尤其适合用来处理短时间内频繁访问的热点对象。但是如果一些 热点数据在系统中被频繁访问,只是最近一段时间因为某种原因未被 访问过,那么这些热点数据此时就会有被LRU淘汰的风险,换句话 说,LRU依然可能错误淘汰价值更高的数据。
- LFU(Least Frequently Used):优先淘汰最不经常使用的数据。 LFU会给每个数据添加一个访问计数器,每访问一次就加1,需要淘汰 时就清理计数器数值最小的那批数据。LFU可以解决上面LRU中热点数 据间隔一段时间不访问就被淘汰的问题,但同时它又引入了两个新的 问题。第一个问题是需要对每个缓存的数据专门维护一个计数器,每 次访问都要更新,但这样做会带来高昂的维护开销;另一个问题是不 便于处理随时间变化的热度变化,譬如某个曾经频繁访问的数据现在 不需要了,但很难自动将它清理出缓存。
缓存的淘汰策略直接影响缓存的命中率,没有一种策略是完美 的、能够满足系统全部需求的。不过,随着淘汰算法的不断发展,近 年来的确出现了许多相对性能更好、也更复杂的新算法。以LFU为例, 针对它存在的两个问题,近年来提出的TinyLFU和W-TinyLFU算法就会 有更好的效果。
分布式缓存
相比缓存数据在进程内存中读写的速度,一旦涉及网络访问,由 网络传输、数据复制、序列化和反序列化等操作所导致的延迟要比内 存访问高得多,所以对分布式缓存来说,处理与网络相关的操作是对 吞吐量影响更大的因素,往往也是比淘汰策略、扩展功能更重要的关 注点,这也决定了尽管有Ehcache、Infinispan这类能同时支持分布式 部署和进程内部署的缓存方案,但通常进程内缓存和分布式缓存选型 时会有完全不同的候选对象及考察点。在我们决定使用哪种分布式缓 存前,首先必须确定自己的需求是什么。
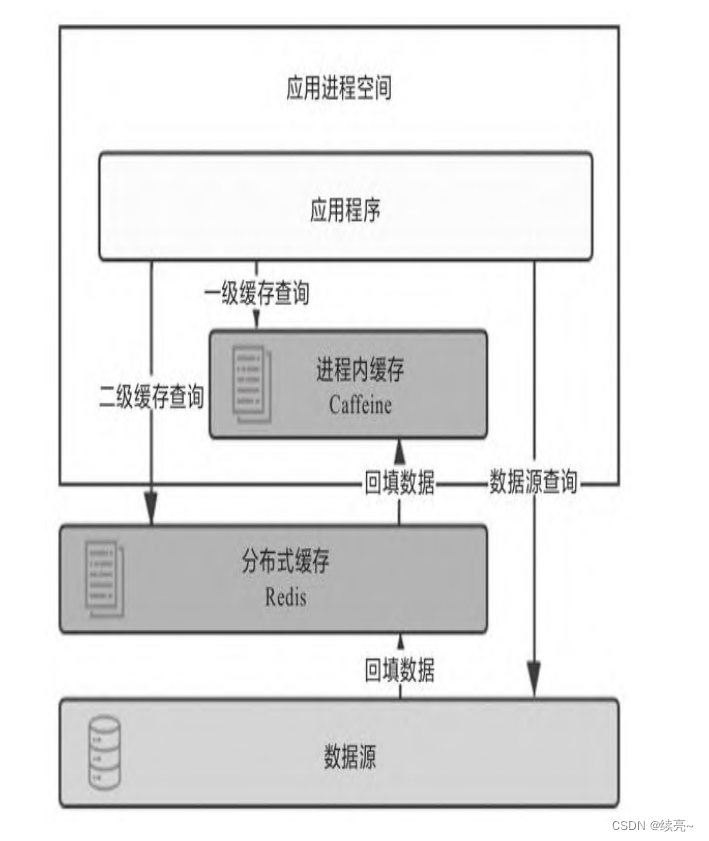
尽管多级缓存结合了进程内缓存和分布式缓存的优点,但它的代 码侵入性较大,需要由开发者承担多次查询、多次回填的工作,也不 便于管理,如超时、刷新等策略都要设置多遍,数据更新更是麻烦, 很容易出现各个节点的一级缓存以及二级缓存中数据不一致的问题。 所以,必须“透明”地解决以上问题,才能使多级缓存具有实用的价 值。一种常见的设计原则是变更以分布式缓存中的数据为准,访问以 进程内缓存的数据优先。大致做法是当数据发生变动时,在集群内发 送推送通知(简单点的话可采用Redis的PUB/SUB,求严谨的话可引入 ZooKeeper或etcd来处理),让各个节点的一级缓存中的相应数据自动 失效。当访问缓存时,提供统一封装好的一、二级缓存联合查询接 口,接口外部是只查询一次,接口内部自动实现优先查询一级缓存, 未获取到数据再自动查询二级缓存的逻辑。
缓存风险
1.缓存穿透
缓存的目的是缓解CPU或者I/O的压力,譬如对数据库做缓存,大 部分流量都从缓存中直接返回,只有缓存未能命中的数据请求才会流 到数据库中,这样数据库压力自然就减小了。但是如果查询的数据在 数据库中根本不存在,缓存里自然也不会有,这类请求的流量每次都 不会命中,且每次都会触及末端的数据库,缓存就起不到缓解压力的 作用了,这种查询不存在的数据的现象被称为缓存穿透。
缓存穿透有可能是业务逻辑本身就存在的固有问题,也有可能是 恶意攻击所导致。为了解决缓存穿透问题,通常会采取下面两种办 法。
- 对于业务逻辑本身不能避免的缓存穿透,可以约定在一定时间 内对返回为空的Key值进行缓存(注意是正常返回但是结果为空,不 应把抛异常的也当作空值来缓存),使得在一段时间内缓存最多被穿 透一次。如果后续业务在数据库中对该Key值插入了新记录,那应当 在插入之后主动清理掉缓存的Key值。如果业务时效性允许的话,也 可以对缓存设置一个较短的超时时间来自动处理。
- 对于恶意攻击导致的缓存穿透,通常会在缓存之前设置一个布 隆过滤器来解决。所谓恶意攻击是指请求者刻意构造数据库中肯定不 存在的Key值,然后发送大量请求进行查询。布隆过滤器是用最小的 代价来判断某个元素是否存在于某个集合的办法。如果布隆过滤器给 出的判定结果是请求的数据不存在,直接返回即可,连缓存都不必去 查。虽然维护布隆过滤器本身需要一定的成本,但比起攻击造成的资 源损耗仍然是值得的。
2.缓存击穿
我们都知道缓存的基本工作原理是首次从真实数据源加载数据, 完成加载后回填入缓存,以后其他相同的请求就从缓存中获取数据, 以缓解数据源的压力。如果缓存中某些热点数据忽然因某种原因失效 了,譬如由于超期而失效,此时又有多个针对该数据的请求同时发送 过来,这些请求将全部未能命中缓存,到达真实数据源中,导致其压 力剧增,这种现象被称为缓存击穿。要避免缓存击穿问题,通常会采 取下面两种办法。
- 加锁同步,以请求该数据的Key值为锁,使得只有第一个请求 可以流入真实的数据源中,对其他线程则采取阻塞或重试策略。如果 是进程内缓存出现问题,施加普通互斥锁即可,如果是分布式缓存中 出现问题,就施加分布式锁,这样数据源就不会同时收到大量针对同 一个数据的请求了。
- 热点数据由代码来手动管理。缓存击穿是仅针对热点数据自动 失效才引发的问题,对于这类数据,可以直接由开发者通过代码来有 计划地完成更新、失效,避免由缓存的策略自动管理。
3.缓存雪崩
缓存击穿是针对单个热点数据失效,由大量请求击穿缓存而给真 实数据源带来压力。还有一种可能更普遍的情况,即不是针对单个热 点数据的大量请求,而是由于大批不同的数据在短时间内一起失效, 导致这些数据的请求都击穿缓存到达数据源,同样令数据源在短时间 内压力剧增。 出现这种情况,往往是因为系统有专门的缓存预热功能,或者大 量公共数据是由某一次冷操作加载的,使得由此载入缓存的大批数据 具有相同的过期时间,在同一时刻一起失效;也可能是因为缓存服务 由于某些原因崩溃后重启,造成大量数据同时失效。这种现象被称为 缓存雪崩。要避免缓存雪崩问题,通常会采取下面三种办法。
- 提升缓存系统可用性,建设分布式缓存的集群
- 启用透明多级缓存,这样各个服务节点一级缓存中的数据通常 会具有不一样的加载时间,也就分散了它们的过期时间。
- 将缓存的生存期从固定时间改为一个时间段内的随机时间,譬 如原本是1h过期,在缓存不同数据时,可以设置生存期为55min到 65min之间的某个随机时间。
4.缓存污染
缓存污染是指缓存中的数据与真实数据源中的数据不一致的现象。这种情况通常是由于开发者在更新缓存时操作不规范造成的,可能导致数据的不一致性。虽然缓存通常不追求强一致性,但最终一致性仍然是必须的。
造成缓存污染的常见原因
- 更新缓存不规范:开发者从缓存中获得某个对象并更新其属性,但由于某些原因(如业务异常回滚),最终未能成功写入数据库,导致缓存中的数据是新的,但数据库中的数据是旧的。
- 操作顺序错误:如果更新操作的顺序不正确,例如先失效缓存后写数据源,可能会导致缓存和数据源的不一致。
提高缓存一致性的设计模式
为了尽可能地提高使用缓存时的一致性,以下几种常见的设计模式可以帮助管理缓存更新:
-
Cache Aside:
- 读数据:先读缓存,如果缓存中没有,再读数据源,然后将数据放入缓存,再响应请求。
- 写数据:先写数据源,然后失效缓存。
这种模式的关键在于:
- 先后顺序:必须先写数据源后失效缓存。如果先失效缓存后写数据源,可能在缓存失效和数据源更新之间存在时间窗口,此时新的查询请求会读到旧的数据并重新填充到缓存中,导致数据不一致。
- 失效缓存:而不是尝试更新缓存,因为更新过程中数据源可能会被其他请求再次修改,处理多次赋值的时序问题非常复杂。失效缓存可以避免这种情况,确保下次读取时自动回填最新的数据。
-
Read/Write Through:
- 读数据:先读缓存,如果没有,再读数据源,并将数据写入缓存。
- 写数据:先写缓存,再写数据源。
这种模式保证了缓存和数据源的一致性,但实现起来比较复杂,可能会带来性能开销。
-
Write Behind Caching:
- 读数据:先读缓存,如果没有,再读数据源,并将数据写入缓存。
- 写数据:先写缓存,然后异步地将数据写入数据源。
这种模式通过异步更新数据源,提高了写操作的性能,但在数据源更新的延迟期间,可能会导致数据不一致。
Cache Aside 模式的局限性
Cache Aside 模式虽然简洁且成本低,但依然不能完全保证一致性。例如,当某个从未被缓存的数据请求直接流到数据源,如果数据源的写操作发生在查询请求之后但回填到缓存之前,缓存中回填的内容可能与数据库的实际数据不一致。然而,这种情况的发生概率较低,Cache Aside 模式仍然是一个低成本且相对可靠的解决方案。
通过以上设计模式,可以在一定程度上减少缓存污染,确保缓存与数据源之间的一致性,但完全避免是不现实的,特别是在高并发和复杂业务场景下。
相关文章:
6、架构-服务端缓存
为系统引入缓存之前,第一件事情是确认系统是否真的需要缓 存。从开发角度来说,引入缓存会提 高系统复杂度,因为你要考虑缓存的失效、更新、一致性等问题;从运维角度来说,缓存会掩盖一些缺 陷,让问题在更久的…...

服务器遭遇UDP攻击时的应对与解决方案
UDP攻击作为分布式拒绝服务(DDoS)攻击的一种常见形式,通过发送大量的UDP数据包淹没目标服务器,导致网络拥塞、服务中断。本文旨在提供一套实用的策略与技术手段,帮助您识别、缓解乃至防御UDP攻击,确保服务器稳定运行。我们将探讨监…...

美团发布2024年一季度财报:营收733亿元,同比增长25%
6月6日,美团(股票代码:3690.HK)发布2024年第一季度业绩报告。受益于经济持续回暖和消费复苏,公司各项业务继续取得稳健增长,营收733亿元(人民币,下同),同比增长25%。 财报显示,一季度,美团继续…...

sql注入-布尔盲注
布尔盲注(Boolean Blind SQL Injection)是一种SQL注入攻击技术,用于在无法直接获得查询结果的情况下推断数据库信息;它通过发送不同的SQL查询来观察应用程序的响应,进而判断查询的真假,并逐步推断出有用的信…...

docker-compose部署 kafka 3.7 集群(3台服务器)并启用账号密码认证
文章目录 1. 规划2. 服务部署2.1 kafka-012.2 kafka-022.3 kafka-032.4 启动服务 3. 测试3.1 kafkamap搭建(测试工具)3.2 测试 1. 规划 服务IPkafka-0110.10.xxx.199kafka-0210.10.xxx.198kafka-0310.10.xxx.197kafkamp10.10.xxx.199 2. 服务部署 2.1…...

LeetCode-704. 二分查找【数组 二分查找】
LeetCode-704. 二分查找【数组 二分查找】 题目描述:解题思路一:注意开区间和闭区间背诵版:解题思路三: 题目描述: 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target …...

Rust 性能分析
都说Rust性能好,但是也得代码写得好,猜猜下面两个代码哪个快 . - 力扣(LeetCode) use std::collections::HashMap; use lazy_static::lazy_static;lazy_static! {static ref DIGIT: HashMap<char, usize> {let mut m HashMap::new();for c in …...

Gradle和Maven都是广泛使用的项目自动化构建工具
Gradle和Maven都是广泛使用的项目自动化构建工具,但它们在多个方面存在差异。以下是关于Gradle和Maven的详细对比: 一、构建脚本语言 Maven:使用XML作为构建脚本语言。XML的语法较为繁琐,不够灵活,对于复杂的构建逻辑…...

Seed-TTS语音编辑有多强?对比实测结果让你惊叹!
GLM-4-9B 开源系列模型 前言 就在最近,ByteDance的研究人员最近推出了一系列名为Seed-TTS的大规模自回归文本转语音(TTS)模型,能够合成几乎与人类语音无法区分的高质量语音。那么Seed-TTS的表现究竟有多强呢?让我们一起来感受下Seed-TTS带来的惊喜吧! 介绍Seed-TTS…...
Vue3——实现word,pdf上传之后,预览功能(实测有效)
vue-office/pdf - npm支持多种文件(**docx、excel、pdf**)预览的vue组件库,支持vue2/3。也支持非Vue框架的预览。. Latest version: 2.0.2, last published: a month ago. Start using vue-office/pdf in your project by running npm i vue-office/pdf. There are …...
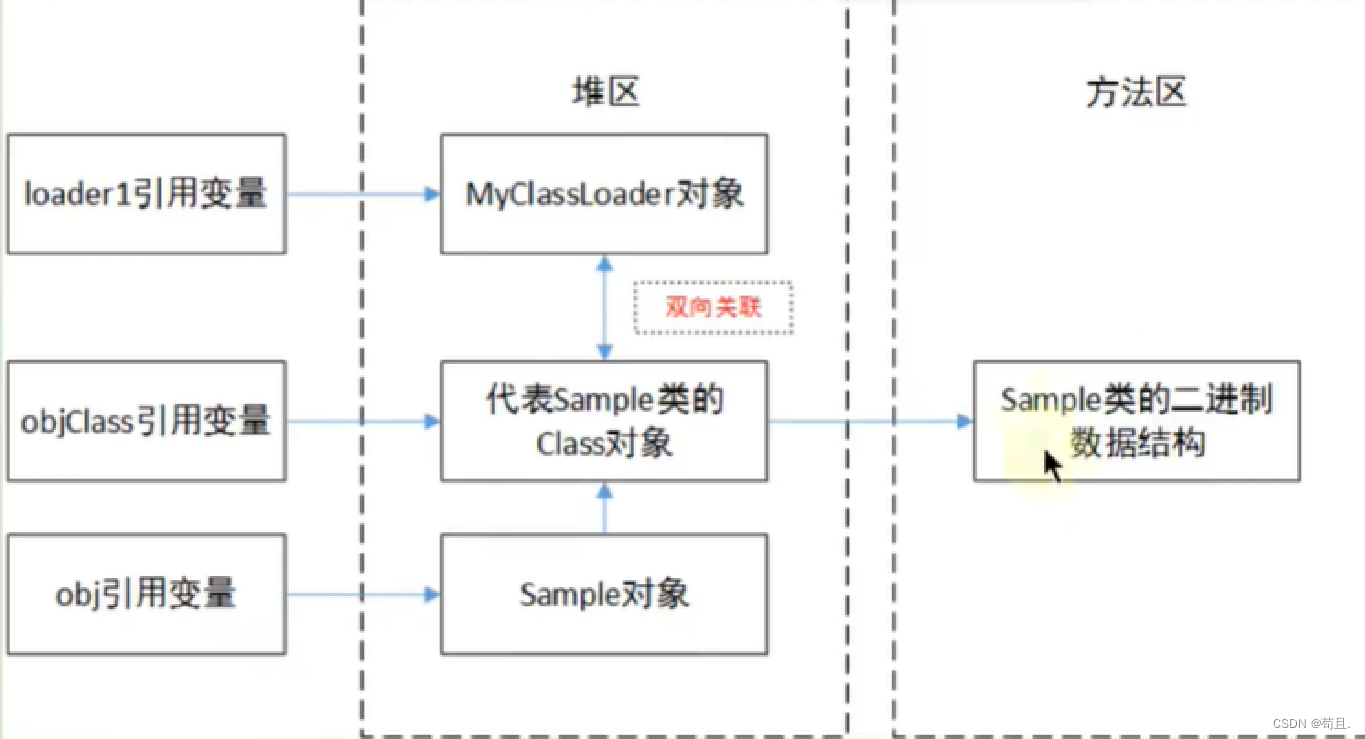
JVM之【类的生命周期】
首先,请区分Bean的声明周期和类的声明周期。此处讲的是类的声明周期 可以同步观看另一篇文章JVM之【类加载机制】 概述 在Java中数据类型分为基本数据类型和引用数据类型 基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载 按照]ava虚拟机…...

分库分表场景下,如何设计与实现一种高效的分布式ID生成策略
在构建大规模分布式系统时,随着数据量的爆炸式增长,单个数据库往往难以承载如此庞大的数据存储与访问需求。这时,分库分表便成为一种有效的解决方案,它通过将数据分散存储在多个数据库或表中,从而提高系统的处理能力和…...
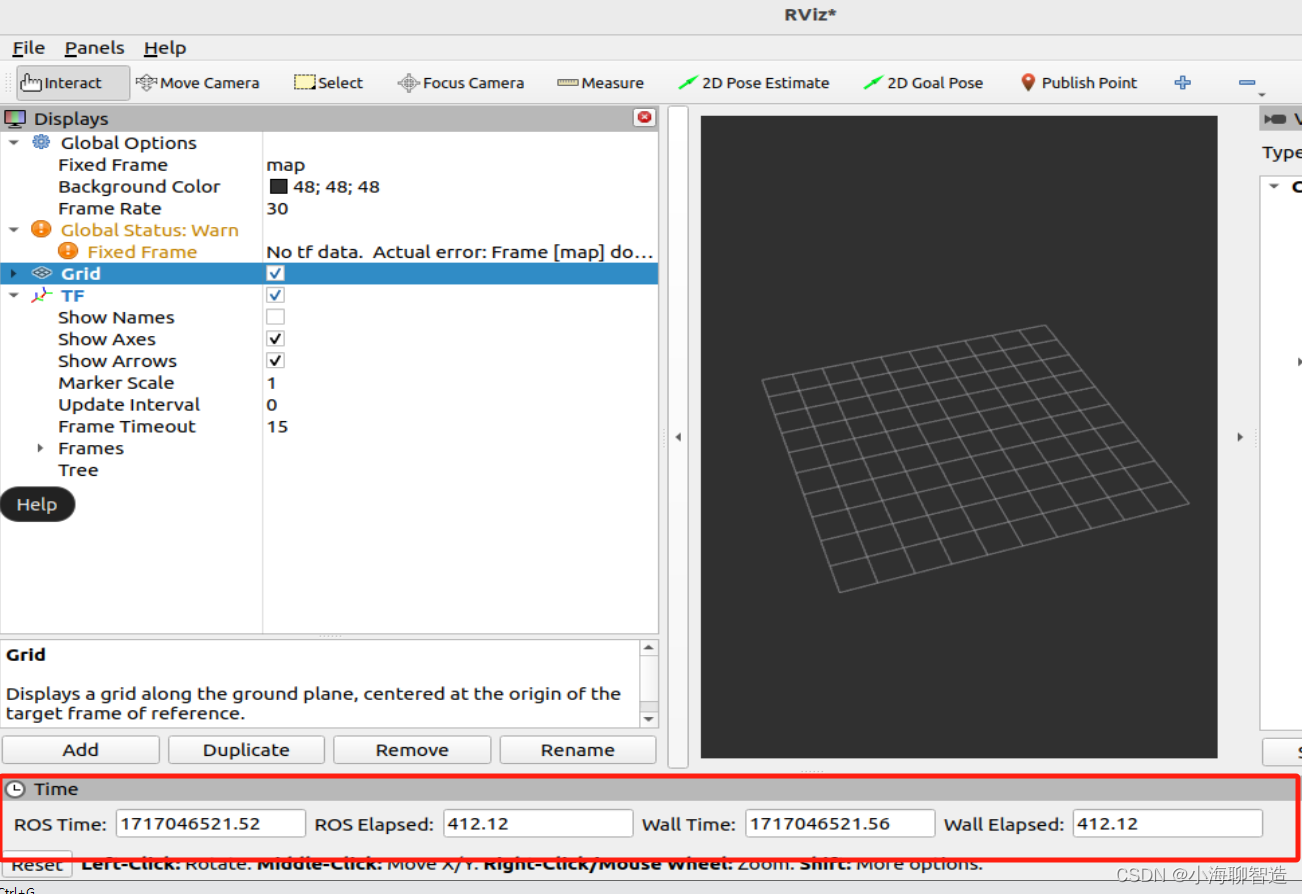
机器人系统ros2-开发学习实践16-RViz 用户指南
RViz 是 ROS(Robot Operating System)中的一个强大的 3D 可视化工具,用于可视化机器人模型、传感器数据、路径规划等。以下是RViz用户指南,帮助你了解如何使用RViz来进行机器人开发和调试。 启动可视化工具 ros2 run rviz2 rviz2…...
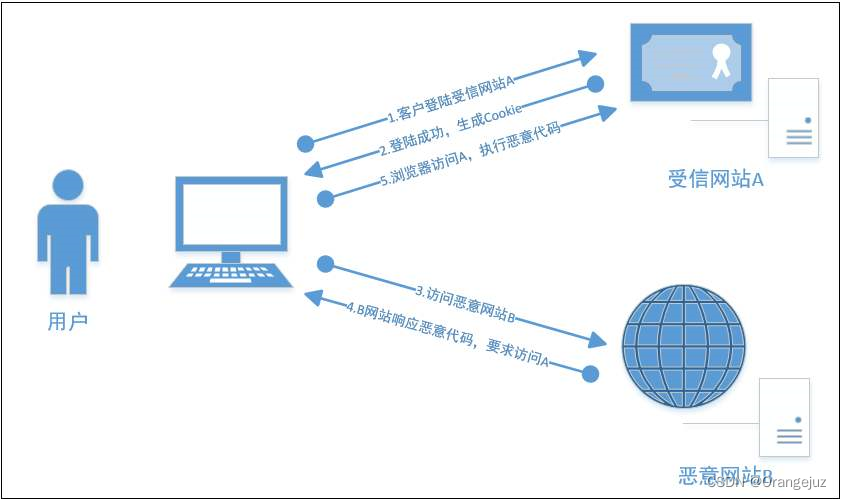
安全测试 之 安全漏洞 CSRF
1. 背景 安全测试是在功能测试的基础上进行的,它验证软件的安全需求,确保产品在遭受恶意攻击时仍能正常运行,并保护用户信息不受侵犯。 2. CSRF 定义 CSRF(Cross-Site Request Forgery),中文名为“跨站请…...

交易中的预测和跟随
任何的交易决策,一定是基于某种推理关系的,这种推理关系是基于t时刻之前的状态,得到t时刻之后的结果,我们基于这种推理关系,根据当前的状态,形成了未来结果的某种预期,然后基于这种预期采取相应…...

vs2022专业版永久密钥
vs2022专业版永久密钥: vs2022专业版永久密钥: Visual Studio 2022 Enterprise:VHF9H-NXBBB-638P6-6JHCY-88JWH Visual Studio 2022 Professional:TD244-P4NB7-YQ6XK-Y8MMM-YWV2J...
MongoDB环境搭建
一.下载安装包 Download MongoDB Community Server | MongoDB 二、双击下载完成后的安装包开始安装,除了以下两个部分需要注意操作,其他直接next就行 三.可视化界面安装 下载MongoDB-compass,地址如下 MongoDB Compass Download (GUI) | M…...

数据结构【队列】
队列的的概念 队列是一种特殊的线性表,特殊之处在于它只允许在表的头部进行删除操作,而在表的尾部进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中…...
微信小程序上架,AI类目审核(AI问答、AI绘画、AI换脸)
小程序对于生成式AI类目的产品上架审核较为严格,这也是近两年新增了几个类目,一旦小程序中涉及生成式AI相关的内容,如果你选择相应类目,但审核被划归为这一类,都需要准备此类目的审核,才能正常上架。 如果…...

Vue3学习记录(第一天)
Vue3学习记录_第一天 背景说明记录Vue3实现响应式前端的反射前端对象的属性赋值Vue3响应式实现过程稿前端移除对象的属性 背景 本次学习主要是看视频学习, 没有跟练, 但是很多知识点感觉又容易忘记. 所以通过笔记的方式输出一下. 说明 估计只能自己看懂, 如果能提供一些其他…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...