算法:前缀和题目练习
目录
题目一:一维前缀和[模版]
题目二:二维前缀和[模版]
题目三:寻找数组的中心下标
题目四:除自身以外数组的乘积
题目五:和为K的子数组
题目六:和可被K整除的子数组
题目七:连续数组
题目八:矩阵区域和
题目一:一维前缀和[模版]

示例1
输入:
3 2 1 2 4 1 2 2 3
输出:
3 6
题目要求是:给一个数组,需要注意的是:下标是从1开始
查询时给下标l和r,返回下标从l到下标为r的元素的和
也就是:如果数组arr是[2, 4, 6],那么查询时如果是:1 2,那就返回6(2+4),如果是2 3,就返回10(4+6),如果是1 3,就返回12(2+4+6)
解法一:暴力解法
暴力解法很简单,即就是题目需要求哪段区间的和,那我就从这个区间的开始一直加到这个区间的结尾即可
时间复杂度:O(N*q)
假设每次询问的查询范围都是从头找到尾,所以是O(N)的,而q次询问,所以是O(q),嵌套起来就是O(N*q)
而这道题N和q的范围都是从1到10^5的,最差的情况,时间复杂度是10^10,是绝对会超时的
解法二:前缀和
前缀和:快速求出数组中某一个连续区间的和
这里的快速指查找时间复杂度为O(1),但是预处理一个前缀和数组的时间复杂度为O(N),所以使用前缀和后,时间复杂度变为O(N) + O(q)了,之所以不是相乘是因为这两个过程并没有嵌套在一起进行
要想使用前缀和,分为下面两步:
①预处理出来一个前缀和数组
数组有几个元素,前缀和数组dp就有几个元素
dp[i]就表示[1, i]区间内所有元素的和
也就是如果数组arr是[1, 2, 3],那么dp数组就是[1, 3, 6]
这里可以优化的一点是:每次算前i个数的和,不需要从1开始加,从i-1开始加即可,因为i-1位置的元素就表示前i-1个元素的和
所以dp[i]的公式是:dp[i] = dp[i+1] + arr[i]
②使用前缀和数组
使用前缀和数组也很简单:
即如果查找的是3~5区间的和,那么只需要使用dp[5] - dp[2],即就是下标为1~5的和,减去1~2的和,算出来就是3~5的和了
即就是查找[l, r]区间的和,则dp[r] - dp[l - 1]即可
下面讲个细节问题,为什么下标要从1开始计数
如果计算的是计算的是前两个元素的和,公式就变为了:dp[2] - dp[-1],这就会导致越界访问了,所以这种情况还需要处理边界情况,麻烦一些
而如果下标是从1开始的,那么如果计算的是前两个元素的和就是:dp[2] - dp[0],我们只需将dp数组中dp[0]的值置为0就能完美解决这个问题
代码如下:
#include <iostream>
#include <vector>
using namespace std;int main() {int n = 0,q = 0;cin >> n >> q;//读入数据vector<int> arr(n+1);vector<long long> dp(n+1);//防止溢出//预处理出来一个前缀和数组for(int i = 1; i < arr.size(); i++){cin >> arr[i];dp[i] = dp[i-1] + arr[i];}//使用前缀和数组int l = 0, r = 0;while(q--){cin >> l >> r;cout << dp[r] - dp[l-1] << endl;}return 0;
}题目二:二维前缀和[模版]

示例1
输入:
3 4 3 1 2 3 4 3 2 1 0 1 5 7 8 1 1 2 2 1 1 3 3 1 2 3 4
输出:
8 25 32
上述题目一是一维的前缀和,题目二是二维的前缀和
就以示例一来说明题意:
第一行的 3 4 3,表示有一个3行4列的矩阵,查询次数是3次
3行4列的矩阵为接下来输入的3行数据,即:
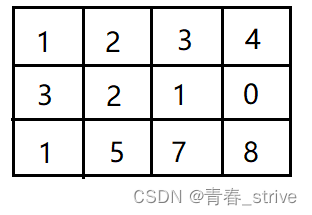
最后三行就表示所查询的三次内容,前两个数字表示一个坐标,后两个数字表示一个坐标
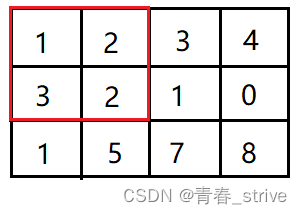
即1 1 2 2就表示(1,1)到(2,2)的这个矩形范围所有值的和,即下图红色区域:
解法一:暴力解法
每次询问时,都给出整个区间所有元素的和,因为是m行n列q此询问,所以时间复杂度是O(m*n*q),因为每次询问最差情况都要遍历数组一遍,是O(m*q),而询问q次,是嵌套关系,所以是O(m*n*q)
当然了,在看到这个时间复杂度后,我们就很容易可以判断出来,这个时间肯定超时了,所以接下来看解法二
解法二:前缀和
同样是分为两步
①预处理出前缀和矩阵
同样重新创建一个和原始矩阵相同规模的矩阵,不同的是新矩阵dp,每一个位置dp[i, j]表示的含义是:从[1, 1]到[i, j]这个位置所有元素的和
例如下图,如果想求这个矩阵中所有元素的和,那么可以分为下面四部分:

我们加入想求[1, 1]到[i, j]位置所有元素的和,只需要求A + B + C + D即可,也就是将ABCD这四个区域的元素之和相加,但是A好求,B、C不太好求,所以可以退而求其次,求A + B和A + C的值,此时多加了一遍A,只需最后减去即可,所以:
dp[i,j] = (A + B) + (A + C) + D - A = dp[i][j-1] + dp[i-1][j] + arr[i,j] - dp[i-1][j-1]
此时求dp[i,j]的时间复杂度就是O(1)的
②使用前缀和矩阵
所以按照上面的思想,如果想要求[x1, y1] ~ [x2, y2]的区域的元素和,也就是下面的D区域:
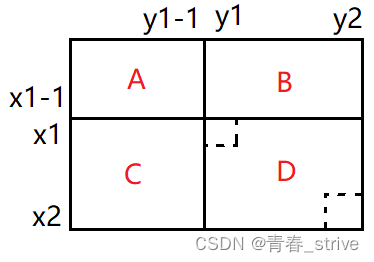
此时求D区域,就可以整体的A+B+C+D,再减去A+B+C,但是单独的B和C不好算,所以依旧使用A+B和B+C来计算,因为多减了一次A,所以最后再加上多减的那个A即可,公式即为:
dp[x2, y2] - dp[x1-1, y2] - dp[x2, y1-1] + dp[x1-1, y1-1]
根据上图可以轻松写出
由于需要先构建m行n列前缀和数组dp,所以时间复杂度是O(m*n),又因为每次查询只需要套一个公式,所以时间复杂度为O(1),需要查询q次,所以前缀和的时间复杂度为:O(m*n) + O(q)
上述第一个公式用于预处理出前缀和矩阵,第二个公式用于使用前缀和矩阵
代码如下:
#include <iostream>
#include <vector>
using namespace std;int main()
{//输入数据int n = 0,m = 0,q = 0;cin >> n >> m >> q;vector<vector<int>> arr(n+1,vector<int>(m+1));for(int i = 1; i <= n; i++)for(int j = 1; j <= m; j++)cin >> arr[i][j];//预处理前缀和矩阵vector<vector<long long>> dp(n+1,vector<long long>(m+1));//long long防止溢出for(int i = 1; i <= n; i++)for(int j = 1; j <= m; j++)dp[i][j] = dp[i-1][j] + dp[i][j-1] + arr[i][j] - dp[i-1][j-1];//使用前缀和矩阵dpint x1 = 0, y1 = 0, x2 = 0, y2 = 0;while(q--){cin >> x1 >> y1 >> x2 >> y2;cout << (dp[x2][y2]-dp[x1-1][y2]-dp[x2][y1-1]+dp[x1-1][y1-1]) << endl;}return 0;
}题目三:寻找数组的中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1, 7, 3, 6, 5, 6] 输出:3 解释: 中心下标是 3 。 左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 , 右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:
输入:nums = [1, 2, 3] 输出:-1 解释: 数组中不存在满足此条件的中心下标。
示例 3:
输入:nums = [2, 1, -1] 输出:0 解释: 中心下标是 0 。 左侧数之和 sum = 0 ,(下标 0 左侧不存在元素), 右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
解法一:暴力解法
每次枚举一个位置,都去将这个位置的左边和右边的元素都累加,去比较总和是否相同,这里的暴力解法的时间复杂度是O(N^2)的
因为枚举下标是O(N),求和也是O(N),所以是时间复杂度是O(N^2)
解法二:前缀和
此题使用的依旧是前缀和的思路,与前面不同的是,此题要求中心下标的左边元素和右边元素相加的和是相同的,所以这里可以引出前缀和数组 f 和后缀和数组 g
这里的前缀和数组的定义与前面的前缀和数组的定义是不同的,并不包含当前位置的值,所以也就进一步的说明,前缀和数组只是一个思想,并不是一个固定的格式
f[i] 表示从0加到i-1位置的元素和,g[i] 表示从i+1加到n-1位置的元素和
同样是分为下面的两步:
①预处理出前缀和、后缀和数组
首先我们明白,在此题中,f[i]表示 0 ~ i - 1 位置的元素的和,所以f[i-1]就是0~i-2位置的元素的和,还差一个nums[i-1],再加上即可,g[i]同理可得:
f[i] = f[i-1] + nums[i-1]
g[i] = g[i+1] + nums[i+1]
②使用前缀和、后缀和数组
在上面预处理出前缀和与后缀和数组后,只需枚举每个下标时,判断f[i]与g[i]是否相等即可,如果相等就表示该下标是数组的中心下标
下面是此题需要注意的两个细节问题:
第一、f[0]与g[n-1]都需要提前处理,因为如果不处理,f[0]的公式会出现f[-1],g[n-1]的公式会出现g[n],这两种情况都是导致越界访问
第二、预处理前缀和数组需要从左向右处理,而预处理后缀和数组则需要从后向前处理,因为前缀和数组计算时,每一个位置都需要前一个位置的值,而后缀和数组每一个位置都需要后一个位置的值
代码如下:
class Solution {
public:int pivotIndex(vector<int>& nums) {int n = nums.size();vector<int> f(n);vector<int> g(n);//预处理前缀和数组f,从下标1开始,下标0默认值是0for(int i = 1; i < n; i++)f[i] = f[i-1] + nums[i-1];//预处理后缀和数组g,从下标n-2开始,下标n-1默认值是0for(int i = n - 2; i >= 0; i--)g[i] = g[i+1] + nums[i+1];//使用数组for(int i = 0; i < n; i++)if(f[i] == g[i]) return i;return -1;}
};题目四:除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例 1:
输入: nums =[1,2,3,4]输出:[24,12,8,6]
示例 2:
输入: nums = [-1,1,0,-3,3] 输出: [0,0,9,0,0]
此题题意是比较好理解的, 例如示例一,数组nums元素是1、2、3、4,返回一个数组answer,在数组answer中,每一个元素的值都是nums中除了该位置的数外,其余所有元素的乘积,如下所示:
nums元素是[1, 2, 3, 4],所以answer数组中的第一个元素值为:2*3*4=24,第二个元素值为1*3*4=12,第三个元素值为:1*2*4=8,第四个元素的值为:1*2*3=6
所以answer数组的元素就为:[24, 12, 8, 6]
解法一:暴力解法
暴力解法也很简单,依次枚举每个位置,然后再求除了该位置外的所有元素的乘积,时间复杂度是O(N^2)的
因为枚举每个位置的时间复杂度是O(N),而其中还需要嵌套一个循环,是遍历其余元素,求其余元素的乘积,时间复杂度也是O(N),所以总的时间复杂度是O(N^2)
解法二:前缀积 + 后缀积
此题同样是需要使用前缀和的思想,但是每道题的前缀和处理思路都是根据实际情况来定的,此题中需要求一个answer数组,使得该数组的每一个元素的值都是nums数组中其余元素的乘积
所以如果要求i位置的值,就需要知道 0 ~ i-1 位置的元素的乘积,以及 i+1 ~ n-1 位置的元素的乘积,所以此题实际的解法可以称之为前缀积
根据上述的描述,我们可以知道,想要得到所需的answer数组,需要 i 下标之前的前缀积和 i 下标之后的后缀积
同样是分为下面的两步:
①预处理出前缀积、后缀积数组
前缀积数组用 f 表示,后缀积数组用 g 表示
f[i] 表示[0, i-1]区间内所有元素的积,
f[i] = f[i-1] * nums[i-1]
g[i] 表示[i+1, n-1]区间内所有元素的积,
g[i] = g[i+1] * nums[i+1]
②使用前缀积、后缀积数组
由于此题所要求的是得出一个answer数组,所以只需创建出一个大小与nums相同的数组,数组中每个元素都使用 f[i] * g[i]来得出最后的值
同样这里也有需要注意的细节问题
与上一题一样,f[0] 和 g[n-1] 都有可能出现越界访问的问题
因为 f[1] = f[0] * nums[0],而f[1]本身就应该等于 nums[0],1乘任意一个数还等于这个数,所以这里初始化 f[0] 为1,g[n-1]同理可得,也初始化为1
代码如下:
class Solution {
public:vector<int> productExceptSelf(vector<int>& nums) {int n = nums.size();vector<int> answer(n);//预处理前缀积数组 f 和后缀积数组 gvector<int> f(n), g(n);f[0] = g[n-1] = 1; // 处理细节问题for(int i = 1; i < n; i++)f[i] = f[i-1] * nums[i-1];for(int i = n - 2; i >= 0; i--)g[i] = g[i+1] * nums[i+1];//使用前缀积和后缀积数组for(int i = 0; i < n; i++)answer[i] = f[i] * g[i];return answer;}
};题目五:和为K的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
输入:nums = [1,1,1], k = 2 输出:2
示例 2:
输入:nums = [1,2,3], k = 3 输出:2
解法一:暴力解法
此题看题意,很容易想出暴力解法,即从第一个位置开始,依次向后枚举,一直累加,因为可能存在负数,所以每次都需要加到最后一个元素,第一个位置累加完毕,就从第二个位置加,加到最后一个元素位置,直到最后一个元素
暴力枚举可以将数组中可能存在的子数组枚举一遍,每次判断子数组的元素和是否等于k,从而解答此题
暴力枚举的时间复杂度是O(N^2)
根据上述所说,可能存在负数的情况,所以这里的数组是不具备单调性的,所以也就不能使用双指针(滑动窗口)优化
解法二:前缀和 + 哈希表
想要使用前缀和的思想,我们可以将子数组转变为以 i 位置为结尾的子数组,暴力解法是以 i 位置为开头的所有子数组,这两种遍历方式没有区别,一个是从前向后遍历,一个是从后向前遍历的
之所以使用以 i 结尾,是因为这样可以更好的使用前缀和的思想,因为此时可以预处理出前缀和数组sum,sum[i]就表示 i 之前的所有元素的和
因为需要找元素之和为k的子数组,而如果我们以i为结尾,从i开始遍历向前找和为k的子数组,那和暴力解法没区别,所以此时可以转换思路:
寻找和为k的子数组,当枚举到 i 位置后,我们可以根据sum[i]知道以 i 位置为结尾的数组前缀和是多少,那么想找到一个子数组的元素和为k,可以转换为:
当我们枚举到以 i 位置为结尾时,想找一个子数组,它的前缀和为sum[i] - k即可,如果能够找到一个子数组的前缀和为sum[i] - k,那么就变相的说明i之前的数组中,存在和为k的子数组,相当于将i结尾的数组分为了两部分,一部分是和为k的子数组,一部分是和为sum[i] - k的子数组
也就是说,我们想找和为k的A数组,转化思路后变为找到和为sum[i]-k的B数组,也就相当于找到了和为k的A数组
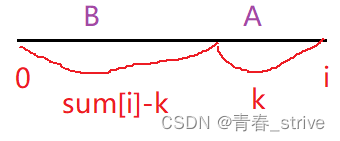
即需要找到在[0, i-1]这个区间中,有多少个前缀和为 sum[i] - k的子数组
那么在了解这个思想后,我们难道是直接创建一个前缀和数组,再找i位置之前有多少个子数组的和等于sum[i] - k吗,那么此时这个算法的时间复杂度也是O(N^2),依旧是遍历数组的思路
因为遍历i位置是O(N),再寻找和为sum[i] - k也是O(N),所以时间复杂度也是O(N^2),那么如何巧妙地解决这个问题呢,这里就需要用到哈希表这个思想了:
哈希表就是用于快速查找某个数的,所以我们可以将前缀和插入到哈希表里,统计前缀和出现的次数,所以哈希表存的就是int, int类型的,第一个int存的是前缀和,第二个int存的是前缀和出现的次数,此时就无需遍历数组寻找和为sum[i] - k的数组,只需要找哈希表中sum[i] - k所对应的数字即可
下面是细节问题:
①前缀和何时放入哈希表中?
是创建出前缀和数组,一股脑全放进去吗?是不能一开始就全放进哈希表中的,因为我们所计算的是 i 位置之前有多少个前缀和等于sum[i] - k,如果全放进入,是可能会统计到 i 位置之后的某些位置的前缀和数组也可能等于sum[i] - k
因此在计算 i 位置之前,哈希表中只保存 0~i-1 位置的前缀和
②不用真的创建出来一个前缀和数组
因为每次dp[i] = dp[i-1] + nums[i-1],每次只需要知道前一个位置的前缀和即可,所以此题中,只需使用一个变量sum标记之前的元素前缀和dp[i-1]是多少,计算完dp[i]后,把sum更新为dp[i]即可,所以在计算下一个dp[i]的时候,这个sum依旧是计算前的前缀和的值
③整个前缀和等于k的情况
也就是 0~i 这段区域的区间等于k,此时如果出现这种情况,我们按照上面的描述,就会在[0, -1]的区间内寻找,但是这个区间并不存在,而我们此时是存在这个等于k的情况的,所以需要特殊处理这种情况,因为整个数组的和为k,我们想找的sum[i] - k就变为0了,所以此时需要先设置hash[0] = 1,先在哈希表中存入这种情况
代码如下:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {unordered_map<int, int> hash;//统计前缀和出现的次数hash[0] = 1; //处理整个数组之和是k的情况int sum = 0, ret = 0;for(auto& it : nums){sum += it;//计算当前位置的前缀和if(hash.count(sum - k)) ret += hash[sum - k];//统计个数hash[sum]++;//将当前位置的前缀和放入哈希表中}return ret; }
};题目六:和可被K整除的子数组
给定一个整数数组 nums 和一个整数 k ,返回其中元素之和可被 k 整除的(连续、非空) 子数组 的数目。
子数组 是数组的 连续 部分。
示例 1:
输入:nums = [4,5,0,-2,-3,1], k = 5 输出:7 解释: 有 7 个子数组满足其元素之和可被 k = 5 整除: [4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
示例 2:
输入: nums = [5], k = 9 输出: 0
首先这道题在做之前,先解释两个数学知识:
①同余定理
同余定理指的是,如果 (a - b) / p = k .... 0,也就是说 (a - b) 能够整除 k,那就存在a%p == b%p
证明很简单,(a - b) = k*p -> a = b + k*p -> a % p = b % p
因为k*p % p = 0,所以得出上式
②负数除以整数的情况
举个例子: -4 % 3 == -1,但是在数学上,余数只有正的,所以如果想取得正余数,余数无论正负数的通用公式如下:
(a % p + p) % p
因为负数%正数,得出的结果是负数,如果想要正数就需要加上这个正数,又因为可能原本的结果就是正数,此时再%这个正数,如果原本就是正数的话,后面加的这个p就被抵消了
解法一:暴力解法
暴力枚举出所有的子数组,然后把子数组的和加起来,判断是否能被k整除,与上一题一样,此题依旧是不能使用滑动窗口来做优化的,因为可能存在负数,数组不是单调的
解法二:前缀和 + 哈希表
这道题和上一题同样的思想,使用前缀和 + 哈希表完成
同样是求i之前的子数组的元素之和能够整除k,也就是下图所示:
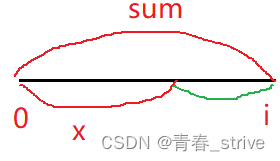
假设在 i 之前的这段绿色区域的元素之和,能够被 k 整除,而前面这段红色区域元素之和是 x
所以得到: (sum - x) % k = 0,根据同余定理,可以得到:sum % k == x % k
所以得到一个结论,如果后面的绿色区域能够被 k 整除,那么前面的这段红色区域,同样能被 k 整除,那么也就是说,在 [0, i-1] 这个区间内,有多少个前缀和的余数是sum % k的,就说明有多少个子数组是满足被 k 整除这个条件的
同样需要处理细节问题,其他和上一题一样,唯一有一个需要注意的是:哈希表同样是<int, int>,但是第一个int不是存的前缀和了,而是存的前缀和的余数
代码如下:
class Solution {
public:int subarraysDivByK(vector<int>& nums, int k) {unordered_map<int ,int> hash;hash[0] = 1; //特殊情况,如果整体的前缀和能被k整除int sum = 0, ret = 0;for(auto& it : nums){sum += it; //sum算出当前位置之前的前缀和int ans = (sum % k + k) % k; //求出修正后的余数if(hash.count(ans)) ret += hash[ans]; //统计结果hash[ans]++;}return ret;}
};题目七:连续数组
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。
示例 1:
输入: nums = [0,1] 输出: 2 说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。
示例 2:
输入: nums = [0,1,0] 输出: 2 说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。
首先先看这个题目要求,找含有相同数量的0和1的最长连续子数组,我们初始看这个题目要求感觉可能半天想不出来解法, 但是如果转换一下思路,将数组中的0全部换为-1,此时就变为了子数组中含有的1和-1的数量相同,那如果1和-1的数量相同,就说明相加为0了,此时就可以和前面的和为k的子数组那道题一样了,这道题就变为了:和为0的最长子数组了
虽然思想是一样的,但是却是有很多细节问题,如下所示:
①哈希表中存什么
哈希表同样是int, int,第一个int存的依然是前缀和,但是这里的第二个int存的是下标,因为需要知道这里的下标,才能算出这里的下标与
②什么时候存入哈希表
和上一题一样,都是在计算 i 位置之前,哈希表中只保存 0~i-1 位置的前缀和
③如果哈希表中出现重复的<sum, i>时,如何存
存的是第一次出现的值,因为如下图所示,绿色是符合要求的区域,而越早出现的符合要求的点越靠左,越靠左绿色的范围就越大, 即子数组的长度越长
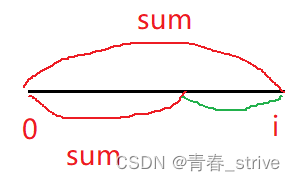
因为此时符合要求的子数组相加为0,所以左边的红色区域的和也就是sum,因此符合的点越靠左,绿色区域越大,即符合要求的子数组长度越长
④默认的整体的数组前缀和为0,如何存
因为如果在i位置之前有一个子数组满足条件,那么是在0~i-1的区域找满足条件的子数组,而此时整个数组都满足题意了,那么在前面就没有位置找了,所以就变成了在[0, -1]的区间找
当数组整体前缀和为0时,我们就需要在-1的位置寻找一个前缀和,因为存的是下标,所以存的是-1,所以此时计算长度时就能够满足这种特殊情况了
⑤最长子数组的长度怎么算
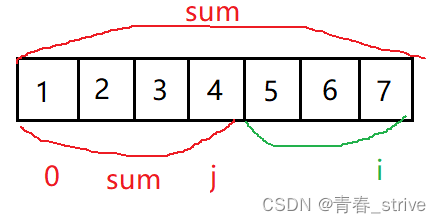
如上图所示,绿色区域是所求的子数组长度,所以长度计算就为:i - j
代码如下:
class Solution {
public:int findMaxLength(vector<int>& nums) {unordered_map<int, int> hash;hash[0] = -1; //处理特殊情况int sum = 0, ret = 0;for(int i = 0; i < nums.size(); i++){sum += nums[i] == 0 ? -1 : 1;//计算当前位置的前缀和,并把0全替换为-1if(hash.count(sum)) ret = max(i - hash[sum], ret);//这里需要加else,为了保证出现重复的sum,只保留第一次的,确保子数组长度最长else hash[sum] = i;}return ret;}
};题目八:矩阵区域和
给你一个 m x n 的矩阵 mat 和一个整数 k ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和:
i - k <= r <= i + k,j - k <= c <= j + k且(r, c)在矩阵内。
示例 1:
输入:mat = [[1,2,3],[4,5,6],[7,8,9]], k = 1 输出:[[12,21,16],[27,45,33],[24,39,28]]
示例 2:
输入:mat = [[1,2,3],[4,5,6],[7,8,9]], k = 2 输出:[[45,45,45],[45,45,45],[45,45,45]]
这道题的题意其实很简单,就是有一个m × n的矩阵,再给一个整数k,要求每一个位置都向上下左右扩展k个单位(超出的部分不算),扩展后的区域的元素之和,就是原位置的元素值,以示例一为例:
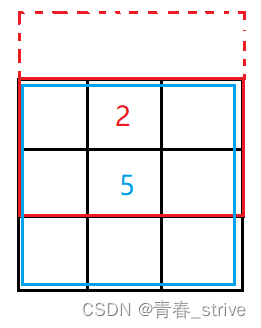
2号位置就是计算红色区域的元素和,上面虚线就表示超出的范围,忽略
5号位置就是计算蓝色区域的元素和
这道题就很明显是要用到二维前缀和了,需要在这里再次提醒,二维前缀和不需要背模版,只需要画图理解,很快就能自己现推一个公式出来,理解最重要!
对于此题来说,给一个坐标(i, j),那么这个坐标所对应需要计算的区域就是从(i-k, j-k)到(i+k, j+k),此时需要考虑是否会超出矩阵的范围,所以做如下处理:
x1 = max(0, i-k),x2 = min(m-1, i+k)
y1 = max(0, j-k),y2 = min(n-1, j+k)
上述讲解是用于求answer矩阵的每个位置对应的(x1,y1)和(x2,y2)坐标的,但是有一个细节问题需要注意:
在使用前缀和时,我们为了能够正常使用,数组的下标都是从1开始的,因为从0开始会出现越界访问的问题,而此题的下标是从0开始的,所以需要考虑下标的映射关系
题目中所给的mat矩阵是3×3的,而我们想正常使用前缀和,就得让坐标从1开始,也就是相比于mat矩阵,多加一行多加一列,所以mat和answer就变为下图所示:

由于dp数组多了一行一列,所以就会有下面这种情况:
我们想预处理dp二维数组中的(x, y)位置时,需要再mat中找的是(x-1, y-1)位置
并且形成最终的answer数组的(x, y)位置时,所需要dp数组中的位置又是(x+1, y+1)
此时就有两种处理思路:
第一种思路:在预处理dp数组时,在原始的公式中把每一个x1、x2、y1、y2都+1,这样才能对应到mat二维数组中的元素
但是这样处理比较麻烦,每一个位置都需要改
第二种思路:将刚刚计算的x1、x2、y1、y2是原始mat矩阵的下标,如果想在dp矩阵中找位置,每个后面都+1即可,这样就完成了上述操作,比较简便
x1 = max(0, i-k)+1,x2 = min(m-1, i+k)+1
y1 = max(0, j-k)+1,y2 = min(n-1, j+k)+1
代码如下:
class Solution {
public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {int m = mat.size(), n = mat[0].size();vector<vector<int>> dp(m+1, vector<int>(n+1));vector<vector<int>> answer(m, vector<int>(n));//预处理前缀和数组dpfor(int i = 1; i < m+1; i++)for(int j = 1; j < n+1; j++)dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i-1][j-1];//使用前缀和数组for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){int x1 = max(0, i-k) + 1, y1 = max(0, j-k) + 1;int x2 = min(m-1, i+k) + 1, y2 = min(n-1, j+k) + 1;answer[i][j] = dp[x2][y2] - dp[x2][y1-1] - dp[x1-1][y2] + dp[x1-1][y1-1];}}return answer;}
};前缀和题目到此结束
相关文章:
算法:前缀和题目练习
目录 题目一:一维前缀和[模版] 题目二:二维前缀和[模版] 题目三:寻找数组的中心下标 题目四:除自身以外数组的乘积 题目五:和为K的子数组 题目六:和可被K整除的子数组 题目七:连续数组 题…...
记录项目使用ts时引入js文件后导致项目运行空白问题
主要原因: 使用ts后开启了eslint检测,而js压缩文件引入的位置在eslint检测的文件内。导致eslint检测认为该文件为很大的文件,或eslint认为此文件内存在无法处理的语法结构等问题。 解决方法: 1、把文件移到eslint检测外的文件引入…...

Kafka消费者api编写教程
1.基本属性配置 输入new Properties().var 回车 //创建属性Properties properties new Properties();//连接集群properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092");//反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CL…...

什么情况下要配置DNS服务
什么是DNS 一、DNS就是域名解析 我们上网的方式通常都由ip地址组成,但是为了有个规范,而且我们也不可能去记住那么多一串Ip数字,首先域名就会比ip好记很多,其次固定性,一旦服务器换了,只要重新绑定域名对…...

华为端云一体化开发 (起步1.0)(HarmonyOS学习第七课)
官方文献: 为丰富HarmonyOS对云端开发的支持、实现端云联动,DevEco Studio推出了云开发功能,开发者在创建工程时选择云开发模板,即可在DevEco Studio内同时完成HarmonyOS应用/元服务的端侧与云侧开发,体验端云一体化协…...
数据结构之ArrayList与顺序表(上)
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏:数据结构(Java版) 顺序表的学习,点我 上面这篇博文是关于顺序表的基础知识,以及顺序表的实现。…...

Java 8 中的 Stream API,用于处理集合数据
Java 8 引入了 Stream API,使得处理集合数据变得更加简洁和高效。Stream API 允许开发者以声明式编程风格操作数据集合,而不是使用传统的迭代和条件语句。 一、基本概念 1.1 什么是 Stream Stream 是 Java 8 中的一个新抽象,它允许对集合数…...

106、python-第四阶段-3-设计模式-单例模式
不是单例类,如下: class StrTools():pass str1StrTools() str2StrTools() print(str1) print(str2) 运用单例,先创建一个test.py class StrTools():pass str1StrTools()然后创建一个hello.py,在这个文件中引用test.py中的对象&a…...
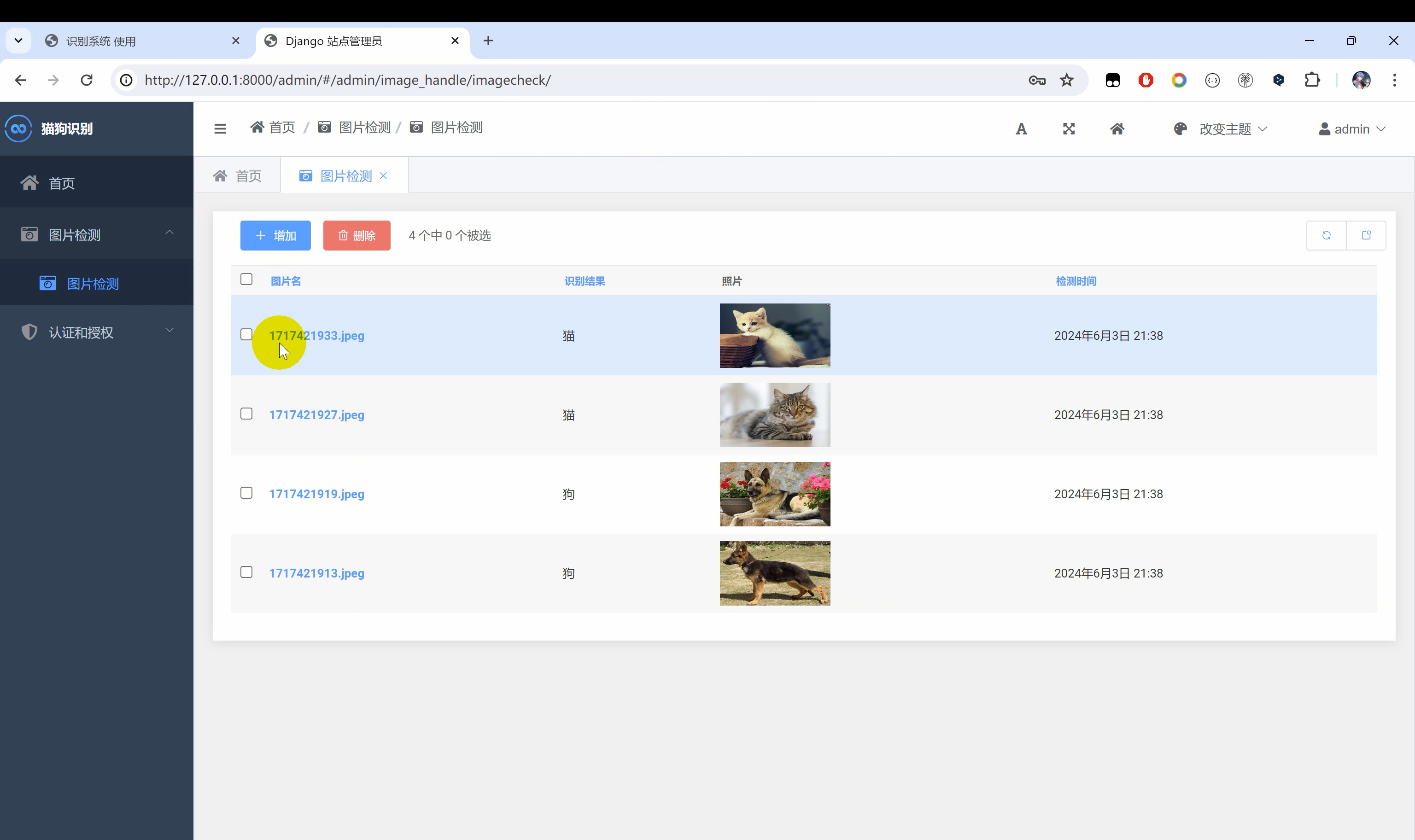
【猫狗识别系统】图像识别Python+TensorFlow+卷积神经网络算法+人工智能深度学习
猫狗识别系统。通过TensorFlow搭建MobileNetV2轻量级卷积神经算法网络模型,通过对猫狗的图片数据集进行训练,得到一个进度较高的H5格式的模型文件。然后使用Django框架搭建了一个Web网页端可视化操作界面。实现用户上传一张图片识别其名称。 一、前言 …...

记录汇川:红绿灯与HMI-ST
项目要求: 子程序: 子程序: 实际动作如下: 红绿灯与HMI-ST...

已解决java.nio.charset.CoderMalfunctionError: 编码器故障错误的正确解决方法,亲测有效!!!
已解决java.nio.charset.CoderMalfunctionError: 编码器故障错误的正确解决方法,亲测有效!!! 亲测有效 报错问题解决思路解决方法1. 检查和清理输入数据2. 选择正确的字符集3. 处理异常情况4. 更新Java版本或库5. 检查第三方库的依…...
Linux 中常用的设置、工具和操作
1.设置固定的ip地址步骤 1.1 添加IPADDR“所设置的固定ip地址” TYPE"Ethernet" PROXY_METHOD"none" BROWSER_ONLY"no" BOOTPROTO"static" DEFROUTE"yes" IPV4_FAILURE_FATAL"no" IPV6INIT"yes" IPV6…...

[论文笔记]AIOS: LLM Agent Operating System
引言 这是一篇有意思的论文AIOS: LLM Agent Operating System,把LLM智能体(代理)看成是操作系统。 基于大语言模型(LLMs)的智能代理的集成和部署过程中存在着许多挑战,其中问题包括代理请求在LLM上的次优调度和资源分配,代理和LLM之间在交互…...
)
2024全国高考作文题解读(文心一言 4.0版本)
新课标I卷 阅读下面的材料,根据要求写作。(60分) 随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少? 以上材料引发了你怎样的联想和思考?请写…...
【功能超全】基于OpenCV车牌识别停车场管理系统软件开发【含python源码+PyqtUI界面+功能详解】-车牌识别python 深度学习实战项目
车牌识别基础功能演示 摘要:车牌识别系统(Vehicle License Plate Recognition,VLPR) 是指能够检测到受监控路面的车辆并自动提取车辆牌照信息(含汉字字符、英文字母、阿拉伯数字及号牌颜色)进行处理的技术。车牌识别是现代智能交通…...

TESSENT2024.1安装
一、安装过程参考Calibre安装过程(此处省略,不再赘述) 二、安装license管理器: SiemensLicenseServer_v2.2.1.0_Lnx64_x86-64.bin 三、Patch补丁: tessent安装目录和license管理安装目录,执行FlexNetLic…...

【机器学习】原理与应用场景 Python代码展现
机器学习:原理、应用与实例深度解析 引言一、机器学习的基本原理二、机器学习的应用范围三、机器学习实例解析四、机器学习部分讲解五、机器学习的挑战与未来 引言 随着大数据和计算能力的飞速发展,机器学习(Machine Learning, ML࿰…...

Python怎么循环计数:深入解析与实践
Python怎么循环计数:深入解析与实践 在Python编程中,循环计数是一项基础且重要的技能。无论是处理列表、遍历文件,还是执行重复任务,循环计数都发挥着不可或缺的作用。本文将从四个方面、五个方面、六个方面和七个方面详细阐述Py…...

Facebook企业户 | Facebook公共主页经营
Facebook作为社交媒体巨头,拥有庞大的用户基数,因此,有效经营公共主页是获取持续流量、提升客户信任度和粘性、促进产品或服务销售与转化的关键。要优化Facebook主页,关注以下几点: 1、参与度是关键指标:因…...

排序数组 ---- 分治-归并
题目链接 题目: 分析: 用这道题来回顾一下归并排序的思想找到中间结点, 将数组分成两半, 运用递归的思想, 继续对一半进行分半, 分到最后剩一个元素, 再将左右数组合并, 合并两个有序数组, 是先分解, 再合并的过程在合并两个有序数组时, 需要一个额外的数组来记录, 为了避免每…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...
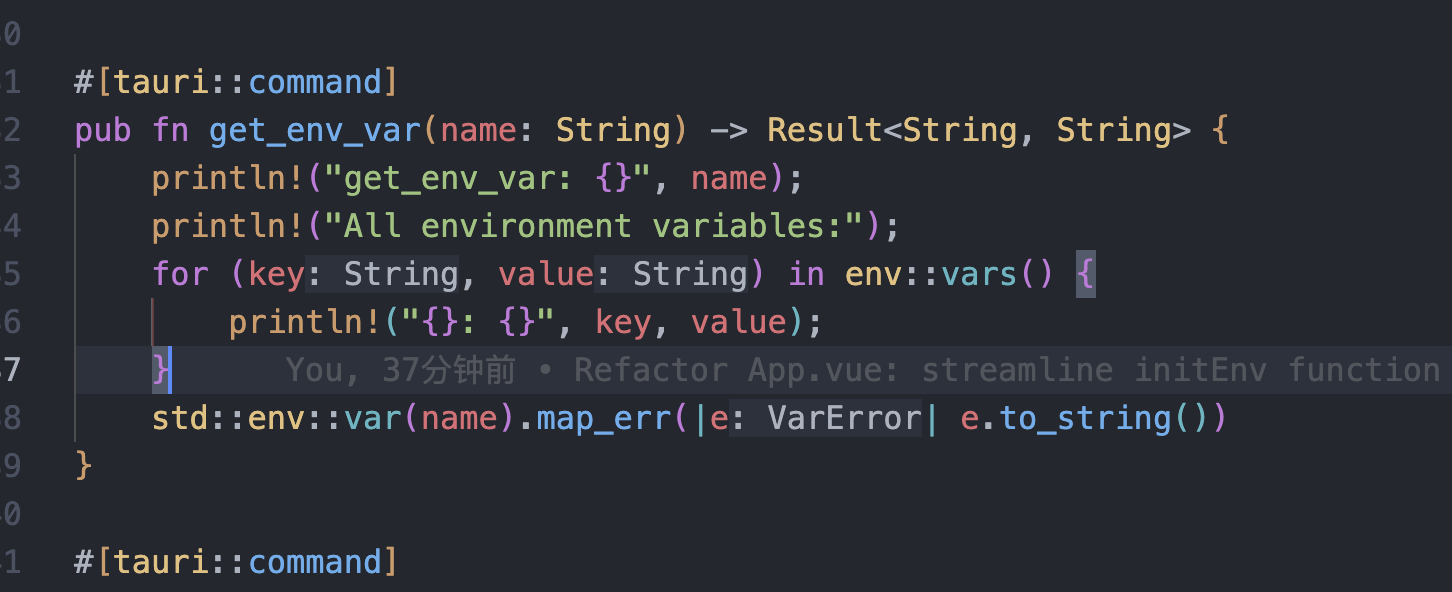
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...