软件杯 题目:基于深度学习的中文对话问答机器人
文章目录
- 0 简介
- 1 项目架构
- 2 项目的主要过程
- 2.1 数据清洗、预处理
- 2.2 分桶
- 2.3 训练
- 3 项目的整体结构
- 4 重要的API
- 4.1 LSTM cells部分:
- 4.2 损失函数:
- 4.3 搭建seq2seq框架:
- 4.4 测试部分:
- 4.5 评价NLP测试效果:
- 4.6 梯度截断,防止梯度爆炸
- 4.7 模型保存
- 5 重点和难点
- 5.1 函数
- 5.2 变量
- 6 相关参数
- 7 桶机制
- 7.1 处理数据集
- 7.2 词向量处理seq2seq
- 7.3 处理问答及答案权重
- 7.4 训练&保存模型
- 7.5 载入模型&测试
- 8 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文对话问答机器人
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目架构
整个项目分为 数据清洗 和 建立模型两个部分。
(1)主要定义了seq2seq这样一个模型。
首先是一个构造函数,在构造函数中定义了这个模型的参数。
以及构成seq2seq的基本单元的LSTM单元是怎么构建的。
(2)接着在把这个LSTM间单元构建好之后,加入模型的损失函数。
我们这边用的损失函数叫sampled_softmax_loss,这个实际上就是我们的采样损失。做softmax的时候,我们是从这个6000多维里边找512个出来做采样。
损失函数做训练的时候需要,测试的时候不需要。训练的时候,y值是one_hot向量
(3)然后再把你定义好的整个的w[512*6000]、b[6000多维],还有我们的这个cell本身,以及我们的这个损失函数一同代到我们这个seq2seq模型里边。然后呢,这样的话就构成了我们这样一个seq2seq模型。
函数是tf.contrib.legacy_seq2seq.embedding_attention_seq2seq()
(4)最后再将我们传入的实参,也就是三个序列,经过这个桶的筛选。然后放到这个模型去训练啊,那么这个模型就会被训练好。到后面,我们可以把我们这个模型保存在model里面去。模型参数195M。做桶的目的就是节约计算资源。
2 项目的主要过程
前提是一问一答,情景对话,不是多轮对话(比较难,但是热门领域)
整个框架第一步:做语料
先拿到一个文件,命名为.conv(只要不命名那几个特殊的,word等)。输入目录是db,输出目录是bucket_dbs,不存在则新建目录。
测试的时候,先在控制台输入一句话,然后将这句话通过正反向字典Ids化,然后去桶里面找对应的回答的每一个字,然后将输出通过反向字典转化为汉字。
2.1 数据清洗、预处理
读取整个语料库,去掉E、M和空格,还原成原始文本。创建conversion.db,conversion表,两个字段。每取完1000组对话,插入依次数据库,批量提交,通过cursor.commit.
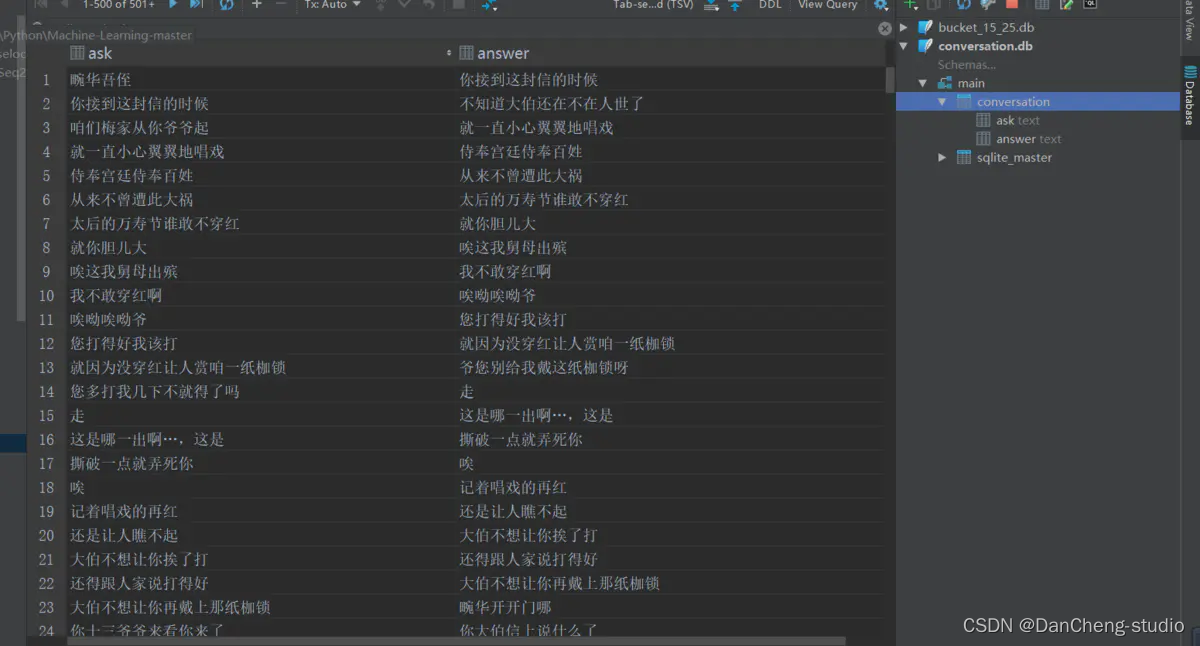
2.2 分桶
从总的conversion.db中分桶,指定输入目录db, 输出目录bucket_dbs.
检测文字有效性,循环遍历,依次记录问题答案,每积累到1000次,就写入数据库。
for ask, answer in tqdm(ret, total=total):if is_valid(ask) and is_valid(answer):for i in range(len(buckets)):encoder_size, decoder_size = buckets[i]if len(ask) <= encoder_size and len(answer) < decoder_size:word_count.update(list(ask))word_count.update(list(answer))wait_insert.append((encoder_size, decoder_size, ask, answer))if len(wait_insert) > 10000000:wait_insert = _insert(wait_insert)break
将字典维度6865未,投影到100维,也就是每个字是由100维的向量组成的。后面的隐藏层的神经元的个数是512,也就是维度。
句子长度超过桶长,就截断或直接丢弃。
四个桶是在read_bucket_dbs()读取的方法中创建的,读桶文件的时候,实例化四个桶对象。
2.3 训练
先读取json字典,加上pad等四个标记。
lstm有两层,attention在解码器的第二层,因为第二层才是lstm的输出,用两层提取到的特征越好。
num_sampled=512, 分批softmax的样本量(
训练和测试差不多,测试只前向传播,不反向更新
3 项目的整体结构
s2s.py:相当于main函数,让代码运行起来
里面有train()、test()、test_bleu()和create_model()四个方法,还有FLAGS成员变量,
相当于静态成员变量 public static final string
decode_conv.py和data_utils.py:是数据处理
s2s_model.py:
里面放的是模型
里面有init()、step()、get_batch_data()和get_batch()四个方法。构造方法传入构造方法的参数,搭建S2SModel框架,然后sampled_loss()和seq2seq_f()两个方法
data_utils.py:
读取数据库中的文件,并且构造正反向字典。把语料分成四个桶,目的是节约计算资源。先转换为db\conversation.db大的桶,再分成四个小的桶。buckets
= [ (5, 15), (10, 20), (15, 25), (20, 30)]
比如buckets[1]指的就是(10, 20),buckets[1][0]指的就是10。
bucket_id指的就是0,1,2,3
dictionary.json:
是所有数字、字母、标点符号、汉字的字典,加上生僻字,以及PAD、EOS、GO、UNK 共6865维度,输入的时候会进行词嵌入word
embedding成512维,输出时,再转化为6865维。
model:
文件夹下装的是训练好的模型。
也就是model3.data-00000-of-00001,这个里面装的就是模型的参数
执行model.saver.restore(sess, os.path.join(FLAGS.model_dir,
FLAGS.model_name))的时候,才是加载目录本地的保存的模型参数的过程,上面建立的模型是个架子,
model = create_model(sess, True),这里加载模型比较耗时,时间复杂度最高
dgk_shooter_min.conv:
是语料,形如: E
M 畹/华/吾/侄/
M 你/接/到/这/封/信/的/时/候/
decode_conv.py: 对语料数据进行预处理
config.json:是配置文件,自动生成的
4 重要的API
4.1 LSTM cells部分:
cell = tf.contrib.rnn.BasicLSTMCell(size)cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers)对上一行的cell去做Dropout的,在外面裹一层DropoutWrapper
构建双层lstm网络,只是一个双层的lstm,不是双层的seq2seq
4.2 损失函数:
tf.nn.sampled_softmax_loss( weights=local_w_t,
b labels=labels, #真实序列值,每次一个
inputs=loiases=local_b,
cal_inputs, #预测出来的值,y^,每次一个
num_sampled=num_samples, #512
num_classes=self.target_vocab_size # 原始字典维度6865)
4.3 搭建seq2seq框架:
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(encoder_inputs, # tensor of input seq 30decoder_inputs, # tensor of decoder seq 30tmp_cell, #自定义的cell,可以是GRU/LSTM, 设置multilayer等num_encoder_symbols=source_vocab_size,# 编码阶段字典的维度6865num_decoder_symbols=target_vocab_size, # 解码阶段字典的维度 6865embedding_size=size, # embedding 维度,512num_heads=20, #选20个也可以,精确度会高点,num_heads就是attention机制,选一个就是一个head去连,5个就是5个头去连output_projection=output_projection,# 输出层。不设定的话输出维数可能很大(取决于词表大小),设定的话投影到一个低维向量feed_previous=do_decode,# 是否执行的EOS,是否允许输入中间cdtype=dtype)4.4 测试部分:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs,
self.decoder_inputs,
targets,
self.decoder_weights,
buckets,
lambda x, y: seq2seq_f(x, y, True),
softmax_loss_function=softmax_loss_function
)
4.5 评价NLP测试效果:
在nltk包里,有个接口叫bleu,可以评估测试结果,NITK是个框架
from nltk.translate.bleu_score import sentence_bleu
score = sentence_bleu(
references,#y值
list(ret),#y^
weights=(1.0,)#权重为1
)
4.6 梯度截断,防止梯度爆炸
clipped_gradients, norm = tf.clip_by_global_norm(gradients,max_gradient_norm)
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
通过权重梯度的总和的比率来截取多个张量的值。t_list是梯度张量, clip_norm是截取的比率,这个函数返回截取过的梯度张量和一个所有张量的全局范数
4.7 模型保存
tf.train.Saver(tf.global_variables(), write_version=tf.train.SaverDef.V2)
5 重点和难点
5.1 函数
def get_batch_data(self, bucket_dbs, bucket_id):
def get_batch(self, bucket_dbs, bucket_id, data):
def step(self,session,encoder_inputs,decoder_inputs,decoder_weights,bucket_id):
5.2 变量
batch_encoder_inputs, batch_decoder_inputs, batch_weights = [], [], []
6 相关参数
model = s2s_model.S2SModel(data_utils.dim, # 6865,编码器输入的语料长度data_utils.dim, # 6865,解码器输出的语料长度buckets, # buckets就是那四个桶,data_utils.buckets,直接在data_utils写的一个变量,就能直接被点出来FLAGS.size, # 隐层神经元的个数512FLAGS.dropout, # 隐层dropout率,dropout不是lstm中的,lstm的几个门里面不需要dropout,没有那么复杂。是隐层的dropoutFLAGS.num_layers, # lstm的层数,这里写的是2FLAGS.max_gradient_norm, # 5,截断梯度,防止梯度爆炸FLAGS.batch_size, # 64,等下要重新赋值,预测就是1,训练就是64FLAGS.learning_rate, # 0.003FLAGS.num_samples, # 512,用作负采样forward_only, #只传一次dtype){"__author__": "qhduan@memect.co","buckets": [[5, 15],[10, 20],[20, 30],[40, 50]],"size": 512,/*s2s lstm单元出来之后的,连的隐层的number unit是512*/"depth": 4,"dropout": 0.8,"batch_size": 512,/*每次往里面放多少组对话对,这个是比较灵活的。如果找一句话之间的相关性,batch_size就是这句话里面的字有多少个,如果要找上下文之间的对话,batch_size就是多少组对话*/"random_state": 0,"learning_rate": 0.0003,/*总共循环20次*/"epoch": 20,"train_device": "/gpu:0","test_device": "/cpu:0"}7 桶机制
7.1 处理数据集
语料库长度桶结构
(5, 10): 5问题长度,10回答长度
每个桶中对话数量,一问一答为一次完整对话
Analysis
(1) 设定4个桶结构,即将问答分成4个部分,每个同种存放对应的问答数据集[87, 69, 36,
8]四个桶中分别有87组对话,69组对话,36组对话,8组对话;
(2) 训练词数据集符合桶长度则输入对应值,不符合桶长度,则为空;
(3) 对话数量占比:[0.435, 0.78, 0.96, 1.0];
7.2 词向量处理seq2seq
获取问答及答案权重
参数:
- data: 词向量列表,如[[[4,4],[5,6,8]]]
- bucket_id: 桶编号,值取自桶对话占比
步骤:
- 问题和答案的数据量:桶的话数buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
- 生成问题和答案的存储器
- 从问答数据集中随机选取问答
- 问题末尾添加PAD_ID并反向排序
- 答案添加GO_ID和PAD_ID
- 问题,答案,权重批量数据
- 批量问题
- 批量答案
- 答案权重即Attention机制
- 若答案为PAD则权重设置为0,因为是添加的ID,其他的设置为1
Analysis
-
(1) 对问题和答案的向量重新整理,符合桶尺寸则保持对话尺寸,若不符合桶设定尺寸,则进行填充处理,
问题使用PAD_ID填充,答案使用GO_ID和PAD_ID填充; -
(2) 对问题和答案向量填充整理后,使用Attention机制,对答案进行权重分配,答案中的PAD_ID权重为0,其他对应的为1;
-
(3) get_batch()处理词向量;返回问题、答案、答案权重数据;
返回结果如上结果:encoder_inputs, decoder_inputs, answer_weights.
7.3 处理问答及答案权重
参数:session: tensorflow 会话.encoder_inputs: 问题向量列表decoder_inputs: 回答向量列表answer_weights: 答案权重列表bucket_id: 桶编号which bucket of the model to use.forward_only: 前向或反向运算标志位
返回:一个由梯度范数组成的三重范数(如果不使用反向传播,则为无)。平均困惑度和输出
Analysis
-
(1) 根据输入的问答向量列表,分配语料桶,处理问答向量列表,并生成新的输入字典(dict), input_feed = {};
-
(2) 输出字典(dict), ouput_feed = {},根据是否使用反向传播获得参数,使用反向传播,
output_feed存储更新的梯度范数,损失,不使用反向传播,则只存储损失; -
(3) 最终的输出为分两种情况,使用反向传播,返回梯度范数,损失,如反向传播不使用反向传播,
返回损失和输出的向量(用于加载模型,测试效果),如前向传播;
7.4 训练&保存模型
步骤:
-
检查是否有已存在的训练模型
-
有模型则获取模型轮数,接着训练
-
没有模型则从开始训练
-
一直训练,每过一段时间保存一次模型
-
如果模型没有得到提升,减小learning rate
-
保存模型
-
使用测试数据评估模型
global step: 500, learning rate: 0.5, loss: 2.574068747580052 bucket id: 0, eval ppx: 14176.588030763274 bucket id: 1, eval ppx: 3650.0026667220773 bucket id: 2, eval ppx: 4458.454110999805 bucket id: 3, eval ppx: 5290.083583183104
7.5 载入模型&测试
(1) 该聊天机器人使用bucket桶结构,即指定问答数据的长度,匹配符合的桶,在桶中进行存取数据;
(2) 该seq2seq模型使用Tensorflow时,未能建立独立标识的图结构,在进行后台封装过程中出现图为空的现象;
从main函数进入test()方法。先去内存中加载训练好的模型model,这部分最耗时,改batch_size为1,传入相关的参数。开始输入一个句子,并将它读进来,读进来之后,按照桶将句子分,按照模型输出,然后去查字典。接着在循环中输入上句话,找对应的桶。然后拿到的下句话的每个字,找概率最大的那个字的index的id输出。get_batch_data(),获取data [('天气\n', '')],也就是问答对,但是现在只有问,没有答get_batch()获取encoder_inputs=1*10,decoder_inputs=1*20 decoder_weights=1*20step()获取预测值output_logits,

8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
软件杯 题目:基于深度学习的中文对话问答机器人
文章目录 0 简介1 项目架构2 项目的主要过程2.1 数据清洗、预处理2.2 分桶2.3 训练 3 项目的整体结构4 重要的API4.1 LSTM cells部分:4.2 损失函数:4.3 搭建seq2seq框架:4.4 测试部分:4.5 评价NLP测试效果:4.6 梯度截断…...

UI学习笔记(一)
UI学习 一:UIView基础frame属性隐藏视图对象:UIView的层级关系 二:UIWindow对象三:UIViewController基础UIViewController使用 四:定时器与视图移动五:UISwitch控件六:滑动条和进度条七…...
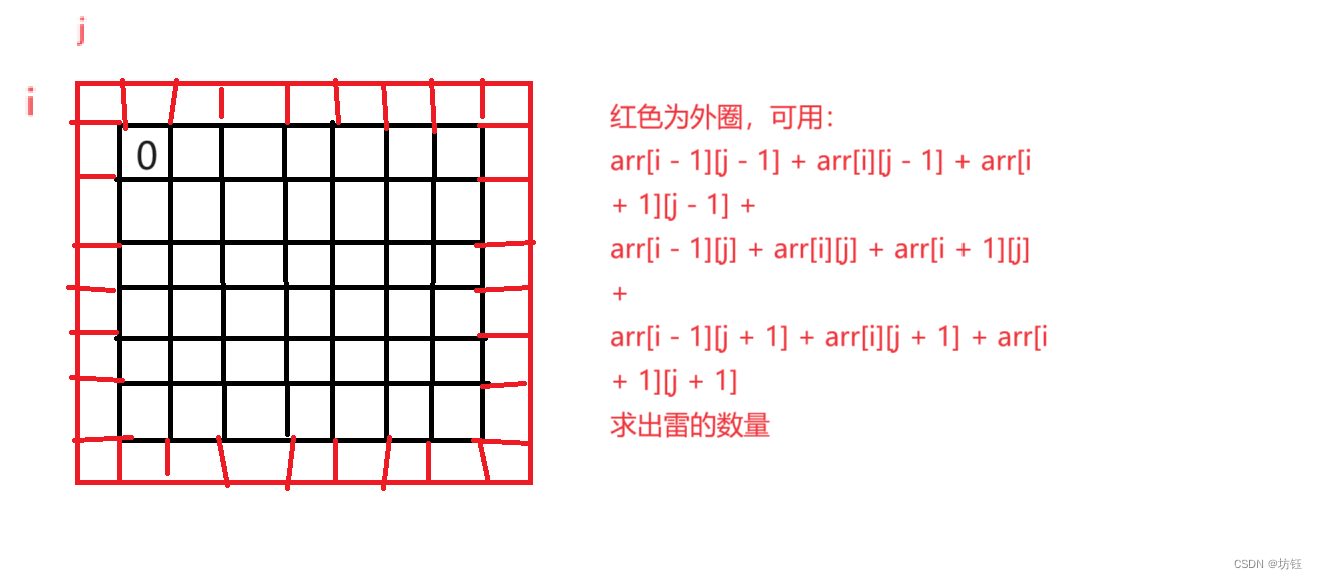
【C语言训练题库】扫雷->简单小游戏!
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 目录 1. 题目 2. 解析 3. 代码 4. 小结 1. 题目 小sun上课的时候非常喜欢玩扫雷。他现小sun有一个初始的雷矩阵,他希望你帮他生成一个扫雷矩阵。 扫雷…...

WMS仓储管理系统高效驱动制造企业物料管理
在现代制造业的快速发展中,仓储管理作为供应链的核心环节,其效率直接影响到企业的生产力和市场竞争力。随着科技的进步,实施WMS仓储管理系统逐渐成为推动仓储管理向智能化转型的关键力量。本文将深入探讨WMS仓储管理系统如何以创新的方式驱动…...

python使用appium打开程序后,为什么没有操作后程序就自动退出了
当使用Appium打开应用程序并在没有执行任何操作后它自动退出,这可能是由于几个不同的原因。以下是一些可能的原因和相应的解决方案: 应用程序的默认行为: 有些应用程序在启动后如果没有用户交互,可能会因为超时或其他逻辑而自动关…...

MacBook M系列芯片安装php8.2
适用于M1\M2\M3等系列的MacBook,记录下安装过程 安装brew 打开终端,执行如下命令: /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"安装zsh(非必须) …...
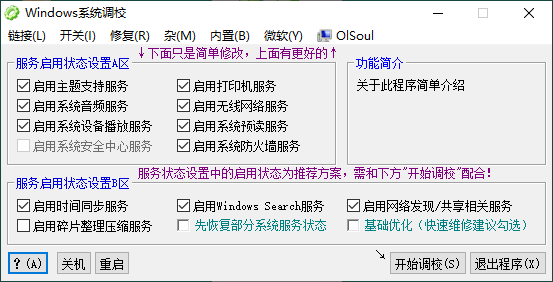
OlSoul系统调校程序v2024.06.05
软件介绍 OlSoul是一款能够适配用于Win各个系统的系统调校软件,OlSoul内置有众多调校功能可以直接使用,如有启用无线网络功能、启用打印机功能、系统快速休眠与休眠开关、快捷方式小箭头去除功能等,具体的调校功能多达几十项,可自…...

图像特征提取 python
1. 边缘检测 (Edge Detection) 1.1 Sobel 算子 Sobel 算子是一种边缘检测算子,通过计算图像梯度来检测边缘。 import cv2 import numpy as np# 读取图像 image cv2.imread(image.jpg, 0)# 应用 Sobel 算子 sobel_x cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize5)…...

width: 100%和 width: 100vw这两种写法有什么区别
width: 100%; 和 width: 100vw; 是两种不同的 CSS 写法,它们在实际应用中会有不同的效果。以下是这两种写法的主要区别: width: 100%; 定义:将元素的宽度设置为其包含块(通常是父元素)宽度的 100%。效果:元…...

如何在另一台电脑上使用相同的Python环境和依赖包
如果您想在另一台电脑上使用相同的Python环境和依赖包,有几种方法可以实现: 使用requirements.txt: 在您当前的虚拟环境中,您可以使用pip freeze > requirements.txt命令生成一个包含所有已安装包及其版本的文件。然后&#x…...
)
Vue3 响应式 API:工具函数(一)
isRef() isRef 是一个简单的工具函数,它接受一个参数并返回一个布尔值,指示该参数是否是一个由 ref 创建的响应式引用。 在某些情况下,你可能需要编写一些通用逻辑或函数,这些逻辑或函数需要处理不同类型的响应式数据(…...

开发常用软件
开发相关 代码编译 Visual Studio 2019 Visual Studio 2022 代码测试工具 LINQPad Premium 5 LINQPad 7 打包工具 Advanced Installer 反编译工具 ILSpy dnSpy spy 数据库相关 SQLite Expert Professional 5 DLL扫描工具 depends 界面设计 SvgToXaml Materi…...

conntrack如何限制您的k8s网关
1.1 conntrack 介绍 对于那些不熟悉的人来说,conntrack简单来说是Linux内核的一个子系统,它跟踪所有进入、出去或通过系统的网络连接,允许它监控和管理每个连接的状态,这对于诸如NAT(网络地址转换)、防火墙和保持会话连续性等任务至关重要。它作为Netfilter的一部分运行,…...
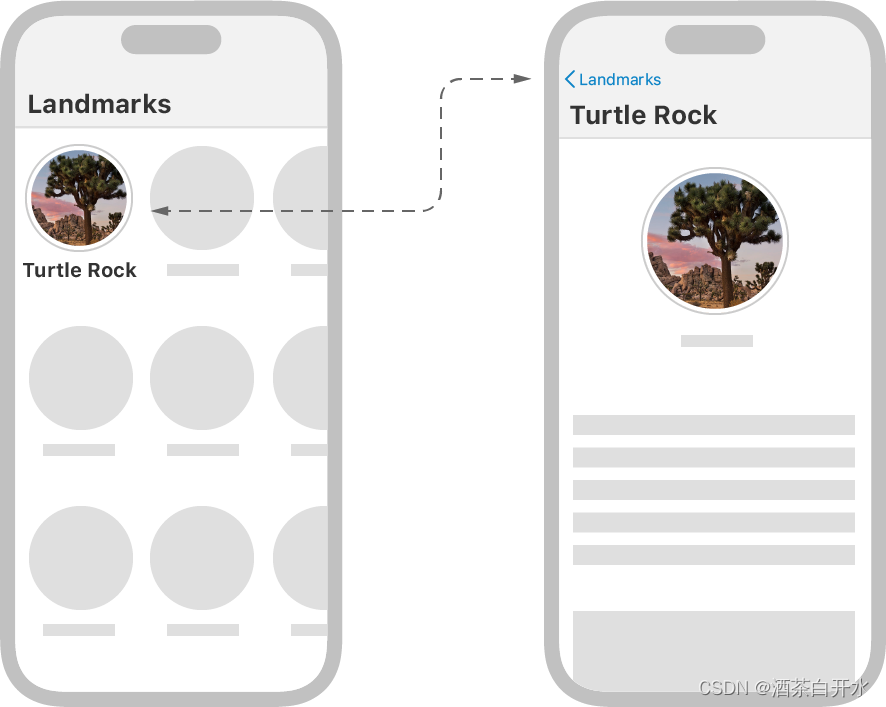
SwiftUI六组合复杂用户界面
代码下载 应用的首页是一个纵向滚动的地标类别列表,每一个类别内部是一个横向滑动列表。随后将构建应用的页面导航,这个过程中可以学习到如果组合各种视图,并让它们适配不同的设备尺寸和设备方向。 下载起步项目并跟着本篇教程一步步实践&a…...
高考分数查询结果自动推送至微信
又是一年高考时,祝各位学子金榜题名,天遂人愿! 在您阅读以下内容时,请注意:各省查分API接口可能不相同,本人仅就技术层面谈谈, 纯属无聊,因为实用意义不大,毕竟一年一次,…...
flask_sqlalchemy时间缓存导致datetime.now()时间不变问题
问题是这样的,项目在本地没什么问题,但是部署到服务器过一阵子发现,这个时间会在某一刻定死不变。 重启uwsgi后,发现第一条数据更新到了目前最新时间,过了一会儿再次发送也变了时间,但是再过几分钟再发就会…...

使用 PAI-DSW x Free Prompt Editing图像编辑算法,开发个人AIGC绘图小助理
教程简述 在本教程中,您将学习在阿里云交互式建模平台PAI-DSW x Free Prompt Editing(CVPR2024中选论文算法)图像编辑算法,开发个人AIGC绘图小助理,实现文本驱动的图像编辑功能单卡即可完成AIGC图片风格变化、背景变化…...
Nginx03-动态资源和LNMP介绍与实验、自动索引模块、基础认证模块、状态模块
目录 写在前面Nginx03案例1 模拟视频下载网站自动索引autoindex基础认证auth_basic模块状态stub_status模块模块小结 案例2 动态网站(部署php代码)概述常见的动态网站的架构LNMP架构流程数据库Mariadb安装安全配置基本操作 PHP安装php修改配置文件 Nginx…...
- 微服务(9))
山东大学软件学院项目实训-创新实训-基于大模型的旅游平台(二十九)- 微服务(9)
目录 12. ElastisSearch 12.1 安装es 12.2 部署kibana 12.2.1 部署 12.2. 2 DevTools 12.3 索引库操作 12.3.1 mapping映射 12.3.2 创建索引库 12.3.3 查询索引库 12.3.4 删除索引库 12.3.5 修改索引库 12.4 文档操作 12.4.1 新增文档 12.4.2 查询文档 12.4.3 删…...
Matplotlib常见图汇总
Matplotlib是python的一个画图库,便于数据可视化。 安装命令 pip install matplotlib 常用命令: 绘制直线,连接两个点 import matplotlib.pyplot as plt plt.plot([0,5],[2,4]) plt.show() 运行结果如下: 多条线:…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...